基于相像系数和DBSCAN的雷达辐射源数据清洗方法
本发明属于通信
技术领域:
,更进一步涉及雷达信号处理
技术领域:
中的一种基于相像系数和基于密度的含噪数据空间聚类算法dbscan(density-basedspatialclusteringofapplicationswithnoise)的雷达辐射源数据清洗方法。本发明可用于电子情报侦察、电子支援和威胁告警系统中对雷达接收的辐射源信号中噪声数据进行清洗。
背景技术:
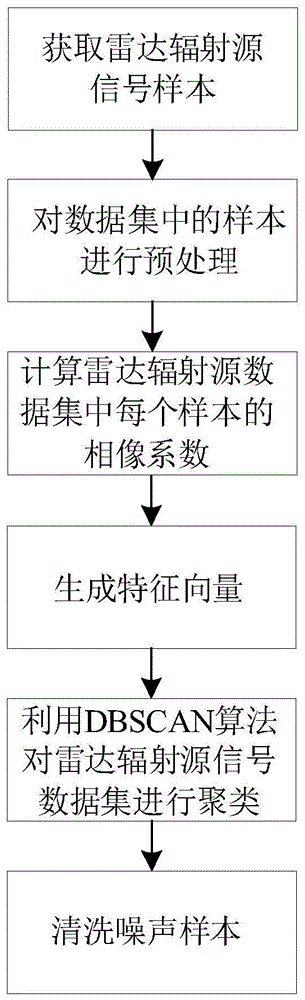
:随着雷达技术的快速发展,电磁环境复杂越来越复杂,电子侦察设备截获到的辐射源信号数目不断增加,噪声数据与有效数据混合在一起,导致获取战场态势信息的难度加大。另一方面,当今雷达对抗领域,有不少研究学者将人工智能、数据挖掘等领域的方法引入,这些高性能的数据驱动算法对数据质量的要求也更高。因此,对原始雷达辐射源信号进行数据清洗,提高数据质量,具有重要意义。目前,所提出的数据清洗方法大多用于二维表、时间序列、图像等类型的数据,主要应用于医疗、能源、零售、汽车、金融等领域。但对雷达辐射源数据,现有的数据清洗方法并不适用。上海铼锶信息技术有限公司在其申请的专利文献“一种样本数据清洗方法及系统”(专利申请号201910239561.x,申请公布号cn111651433a)中公开了一种样本数据清洗方法。该方法的具体步骤是,(1)根据神经网络模型,获取测试图片集中的每一张测试图片的多维测试特征向量;(2)获取选取的典型图片中的多维参考特征向量;(3)根据k最近邻算法、多维测试特征向量和多维参考特征向量,生成正样本测试图片集和负样本测试图片集,并训练得到细粒度二分类器;(4)根据所述细粒度二分类器对待清洗图片数据进行类别预测,获取每一张待清洗图片数据的类别预测的置信度;(5)根据一预设的置信度区间及所述每一张待清洗图片数据的类别预测的置信度,进行样本数据清洗。该方法能得到更优的正样本测试图片集和样本图片集,实现了自动化清洗数据。但是,该方法仍然存在的不足之处是,仅能对图像数据进行处理,而雷达辐射源数据是具有特定脉间和脉内调制方式的时域序列,该方法无法对其进行数据清洗。技术实现要素:本发明的目的在于针对上述现有技术存在的不足,提出一种基于相像系数和dbscan的雷达辐射源数据清洗方法,解决现有数据清洗方法无法处理雷达辐射源数据的问题。实现本发明目的的技术思路是:本发明提取雷达辐射源信号的相像系数作为特征,利用dbscan聚类算法对数据进行聚类划分,检测并剔除噪声数据,克服了现有技术无法对雷达辐射源信号数据进行数据清洗的问题。首先提取辐射源信号的包络,之后求取包络的矩形相像系数和三角形相像系数作为特征,形成特征向量,最后利用dbscan算法对特征数据进行聚类划分,区分噪声信号和脉冲信号,剔除噪声信号。本发明的具体步骤如下:(1)获取雷达辐射源信号样本:(1a)利用低通滤波器,将雷达接收机接收的雷达高频脉冲信号变频为中频信号;(1b)采用不低于500hz的采样频率,从中频信号中采集至少500个样本组成雷达辐射源信号数据集;(2)对数据集中的样本进行预处理:(2a)利用归一化香农能量包络提取算法,提取雷达辐射源信号数据集中每个样本的包络值;(2b)利用min-max归一化法,对雷达辐射源信号数据集中每个样本的包络值进行归一化处理;(3)计算雷达辐射源数据集中每个样本的相像系数:(3a)利用矩形相像系数公式,计算雷达辐射源信号数据集中每个样本的矩形相像系数;(3b)利用三角形相像系数公式,计算雷达辐射源信号数据集中每个样本的三角形相像系数;(4)生成特征向量:将雷达辐射源信号数据集中每个样本的矩形相像系数与其三角形相像系数首尾相接生成该样本特征向量;(5)利用dbscan算法对雷达辐射源信号数据集进行聚类:(5a)从雷达辐射源信号数据集中随机选取一个未处理样本作为当前处理样本,计算当前处理样本特征向量与雷达辐射源数据集中每个样本特征向量的欧式距离,并从中选出欧氏距离小于邻域半径ε的所有样本并统计其个数α后执行步骤(5b),其中,邻域半径ε的大小与雷达辐射源数据集中的样本总数成正相关;(5b)判断α是否大于或等于邻域参数minpts,若是,则执行步骤(5c),否则,执行步骤(5i),其中,邻域参数minpts的大小与邻域半径ε成负相关;(5c)将当前处理样本与所选出的欧氏距离小于邻域半径ε的所有样本放入空集m中,并将m集中所有样本标记为未处理样本后执行步骤(5d);(5d)从m集中取出一个未处理的样本作为被操作样本λ,计算被操作样本λ的特征向量分别与雷达辐射源信号数据集中每个样本特征向量的欧式距离,并从中选出欧式距离小于邻域半径ε的所有样本并统计其个数β,将被操作样本λ标记为已处理样本后执行步骤(5e);(5e)判断β是否大于或等于minpts,若是,执行步骤(5f),否则,执行步骤(5g);(5f)将欧式距离小于邻域半径ε的所有样本放入m集中,并将其标记为未处理样本后执行步骤(5g);(5g)判断是否选完m集中所有未处理样本,若是,则执行步骤(5h),否则,执行步骤(5d);(5h)将m集中所有已处理的样本组成一个聚类簇后执行步骤(5i);(5i)判断雷达辐射源数据集中是否全为已处理样本,若是,得到每个样本对应的聚类簇后执行步骤(6),否则,执行步骤(5a);(6)清洗噪声样本:(6a)从每个聚类簇中随机抽取20个样本,分别找出其中矩形相像系数大于0.9的样本并统计其个数;(6b)找出20个样本中矩形相像系数大于0.9的样本个数最多的聚类簇,将该聚类簇中所有样本从雷达辐射源信号数据集中删除,得到清洗后的雷达辐射源信号数据集。与现有技术相比,本发明具有以下优点:第一,由于本发明将计算得到的雷达辐射源数据集中每个样本的相像系数,作为该样本的特征值,该特征值能有效反应噪声样本和脉冲样本间的差异,且仅需要计算每个样本矩形和三角形相像系数两个特征,计算简单,使得本发明能有效、快速地剔除雷达辐射源数据集中的噪声数据。第二,由于本发明利用dbscan算法对雷达辐射源信号数据集进行聚类,能有效剔除雷达辐射源数据集中的噪声数据,克服了现有技术无法对雷达辐射源数据进行数据清洗的问题,使得本发明能获得含噪声样本更少、数据质量更高的雷达辐射源数据集。附图说明图1是本发明的流程图。具体实施方式下面结合附图1,对本发明具体实现步骤作进一步的描述。步骤1,获取雷达辐射源信号样本。利用低通滤波器,将雷达接收机接收的雷达高频脉冲信号变频为中频信号。采用不低于500hz的采样频率,从中频信号中至少采集500个样本组成雷达辐射源信号数据集。步骤2,对数据集中的样本进行预处理。利用归一化香农能量包络提取算法,提取雷达辐射源信号数据集中每个样本的包络值。所述归一化香农能量包络提取算法的具体步骤如下:第1步,按照下式,对雷达辐射源信号数据集中每个样本的每个采样点进行归一化处理:其中,表示雷达辐射源信号数据集中第j个样本中第i个采样点的归一化值,xj(i)表示雷达辐射源信号数据集中第j个样本中第i个采样点的幅度值,xj表示雷达辐射源信号数据集中第j个样本中由所有采样点的幅度值组成的序列,max(·)表示求最大值操作,|·|表示取绝对值操作。第2步,按照下式,计算雷达辐射源信号数据集中每个样本的每个采样点的香农能量:其中,ej(i)表示雷达辐射源信号数据集中第j个样本中第i个采样点的香农能量,log(·)表示以10为底的对数操作。第3步,按照下式,对雷达辐射源信号数据集中每个样本的每个采样点的香农能量进行加窗平滑处理:其中,表示雷达辐射源信号数据集中第j个样本中第i个采样点平滑后的香农能量,n表示加窗平滑处理窗内的采样点数,取值为200,σ表示求和操作。第4步,按照下式,计算雷达辐射源信号数据集中每个样本的每个采样点的包络值:其中,pj(i)表示雷达辐射源信号数据集中第j个样本中第i个采样点的包络值,表示雷达辐射源信号数据集中第j个样本中由所有采样点的平滑后的香农能量组成的序列,mean(·)表示取均值操作,s(·)表示取标准差操作。利用min-max归一化法,对雷达辐射源信号数据集中每个样本的包络值进行归一化处理。所述min-max归一化法如下:其中,表示雷达辐射源信号数据集中第j个样本中第i个采样点包络的归一化值,pj表示雷达辐射源信号数据集中第j个样本中由所有采样点的包络值组成的序列,min(·)表示求最小值操作。步骤3,计算雷达辐射源数据集中每个样本的相像系数。利用下述矩形相像系数公式,计算雷达辐射源信号数据集中每个样本的矩形相像系数:其中,cj表示雷达辐射源信号数据集中第j个样本的矩形相像系数,m表示雷达辐射源信号数据集中样本的采样点数,sj(k)表示雷达辐射源信号数据集中第j个样本所有的采样点归一化包络值组成的序列,u(k)表示一个采样点数为m,每个采样值均为1的矩形参考序列,表示求平方根操作。利用下述三角形相像系数公式,计算雷达辐射源信号数据集中每个样本的三角形相像系数:其中,ij表示雷达辐射源信号数据集中第j个样本的三角形相像系数,t(n)表示一个采样点数为m的三角形参考序列。步骤4,生成特征向量。将雷达辐射源信号数据集中每个样本的矩形相像系数与其三角形相像系数首尾相接生成该样本特征向量。步骤5,利用dbscan算法对雷达辐射源信号数据集进行聚类。第1步,从雷达辐射源信号数据集中随机选取一个未处理样本作为当前处理样本,计算当前处理样本特征向量与雷达辐射源数据集中每个样本特征向量的欧式距离,并从中选出欧氏距离小于邻域半径ε的所有样本并统计其个数α后执行第2步,其中,邻域半径ε的大小与雷达辐射源数据集中的样本总数成正相关。第2步,判断α是否大于或等于邻域参数minpts,若是,则执行第3步,否则,执行第九步,其中,邻域参数minpts的大小与邻域半径ε成负相关。第3步,将当前处理样本与所选出的欧氏距离小于邻域半径ε的所有样本放入空集m中,并将m集中所有样本标记为未处理样本后执行第4步。第4步,从m集中取出一个未处理的样本作为被操作样本λ,计算被操作样本λ的特征向量分别与雷达辐射源信号数据集中每个样本特征向量的欧式距离,并从中选出欧式距离小于邻域半径ε的所有样本并统计其个数β,将被操作样本λ标记为已处理样本后执行第5步。第5步,判断β是否大于或等于minpts,若是,执行第6步,否则,执行第7步。第6步,将欧式距离小于邻域半径ε的所有样本放入m集中,并将其标记为未处理样本后执行第7步。第7步,判断是否选完m集中所有未处理样本,若是,则执行第8步,否则,执行第4步。第8步,将m集中所有已处理的样本组成一个聚类簇后执行第9步。第9步,判断雷达辐射源数据集中是否全为已处理样本,若是,得到每个样本对应的聚类簇后执行步骤6,否则,执行第1步。步骤6,清洗噪声样本。从每个聚类簇中随机抽取20个样本,找出其中矩形相像系数大于0.9的样本,并统计其个数。找出20个样本中矩形相像系数大于0.9的样本个数最多的聚类簇,将该聚类簇中所有样本从雷达辐射源信号数据集中删除,得到清洗后的雷达辐射源信号数据集。下面结合仿真实验对本发明的效果做进一步的说明:1.仿真条件:本发明的仿真实验的硬件平台为:处理器为intel(r)corei5-8300h,主频为2.30ghz、内存8gb。本发明的仿真实验的软件平台为:windows10操作系统,matlabr2018a。本发明仿真实验所使用的数据是由一个雷达模拟器采集5000个样本组成雷达辐射源数据集,该数据集中含噪声信号和脉冲信号两种类型的样本,对不同类型的样本人工标注了不同的标签,其中标注为噪声标签样本有3796个,脉冲标签样本有1204个。2.仿真内容及结果分析:本发明的仿真实验是采用本发明的方法对数据集中的5000个样本进行数据清洗,将噪声信号样本从数据集中删除,保留脉冲信号样本。以人工标注的标签为基准,统计正确删除和错误删除的样本个数,用正确删除的样本个数除以样本总数5000得到本发明方法数据清洗的正确率,将所有计算结果绘制成表1。表1实测数据样本标注情况统计表总样本数正确删除样本数错误删除样本数正确率(%)500049901099.8%从表1可见,本发明对雷达辐射源数据清洗的正确率能达到99.8%,基本达到了人工清洗的水平。因此,本发明能有效清洗去除噪声样本,提高数据质量。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1