一种基于深度学习的纯视觉轻量手语识别系统的制作方法
本发明涉及手语识别技术领域,尤其涉及一种基于深度学习的纯视觉轻量手语识别系统。
背景技术:
手语是聋哑人与健听人之间重要的沟通方式,为了促进聋哑人与健听人的沟通便利性,设计一款能够在移动端实时运行的手语识别系统显得尤为重要。但由于手语语义丰富、动作幅度相比于其他人体行为具有局部性和细节性,同时又受到光照、背景及运动速度等影响,传统的模式识别及机器学习方法难以实现较理想的精度与鲁棒性。此外,受限于移动端的硬件条件包括cpu、gpu及内存等,运算量较大的实验室环境下的手语识别算法难以部署在移动端并实现高效运行。
对于连续语句手语识别任务,近年来基于图像的深度学习方法取得越来越好的成绩。连续语句手语识别需要建立更为可靠的长期时序依赖。通常采用双向长短时记忆网络模型更好的对手语长时序序列进行上下文语义信息的建模。相比于blstm网络模型的复杂度,基于1维卷积网络模型和3维卷积网络模型的连续手语识别避开了blstm网络的复杂建模,在同样能进行时序建模的基础上节省了复杂的计算量。以往的手语语句时序分割方法过程复杂、误判率高,近年来学者们逐渐绕开了时序分割,将语音识别领域的时序对齐算法ctc引入手语识别领域并取得不错的效果。
现有的实现方案通常利用带有传感器的手环或手套采集手部的运动、位置等信息,将这些信息传输到云端,再由云端通过模式识别、机器学习或深度学习方法从这些信息中提取手语词信息,最后再生成句子。对于上述现有技术方案,由于需要额外的硬件辅助,这种方法不仅使用成本高、使用便利性差、难以大面积推广,而且识别精度低、鲁棒性差。识别算法复杂,难以部署到手机上实时运行。
针对这些问题,本发明提出一种基于深度学习的纯视觉轻量手语识别系统。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于深度学习的纯视觉轻量手语识别系统。
为了实现上述目的,本发明采用了如下技术方案:
一种基于深度学习的纯视觉轻量手语识别系统,包括数据获取、手势特征提取、时序特征提取和句子生成,所述数据获取为待识别手语视频的获取及图像预处理,所述手势特征提取为从手语视频中各帧获取手势特征向量,所述时序特征提取为从手势特征向量序列中提取手语词信息,所述句子生成为对所有手语词信息按照上下文组合成文本句子;
识别系统还包括以下使用步骤:
s1,应用程序打开手机相机拍摄获取手语视频、或者从文件夹中直接获取手语视频,点击开始识别按钮片刻后,将手语识别结果显示在屏幕上;
s2,获取到手语视频后,首先进行四倍下采样得到的图像序列作为手语识别模型的源输入,进行八倍下采样得到的图像序列作为人体检测模型的源输入,预测出人体坐标,再以人体为中心裁剪源输入图像并缩放至高224、宽224个像素,最后进行归一化,数据准备完毕;
s3,在手势特征提取部分,首先第一个特征提取层采用一个2d卷积层和一个最大池化层用于缩放图像,利于减少计算量,具体参数为:卷积核大小7x7、步长2、全零填充3、通道64,第二个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道64,第三个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道128,第四个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道256,第五个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道512。最后跟着一层全局平均池化层,手势特征提取部分最终输出一系列长度为512的特征向量;
s4,在时序特征提取部分,先接入一个1d卷积层,再接入一个最大池化层,最后接入一个1d卷积层;
s5,在句子生成部分,采用一个blstm层,将上述得到的手语词信息作为输入,根据上下文环境输出手语句子信息,再经过一个全连接层映射到预测空间,最后经过ctcbeamsearch解码即可得到预测结果。
本发明再一方面提出了一种手机,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种平板电脑,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种pc电脑,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种服务器,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
与现有技术相比,本发明的有益效果是:
本发明巧妙使用两个1dcnn层作为短距离时序提取器,从而输出手语词信息,不仅运算量小而且运算速度快。
本发明使用一个blstm层作为长距离时序提取器,既能捕捉正向信息又能捕捉反向信息,使输出的句子信息更加准确通顺。blstm层后接入一个全连接层,直接输出预测结果,简单高效。
本发明只需要输入图像数据即可通过运算输出句子,无需额外附加信息,总体网络结构简单高效,训练周期短,适合在移动端部署。只需要一个终端设备即可运行该程序,大大提高了使用便利性,有利于大面积推广。
附图说明
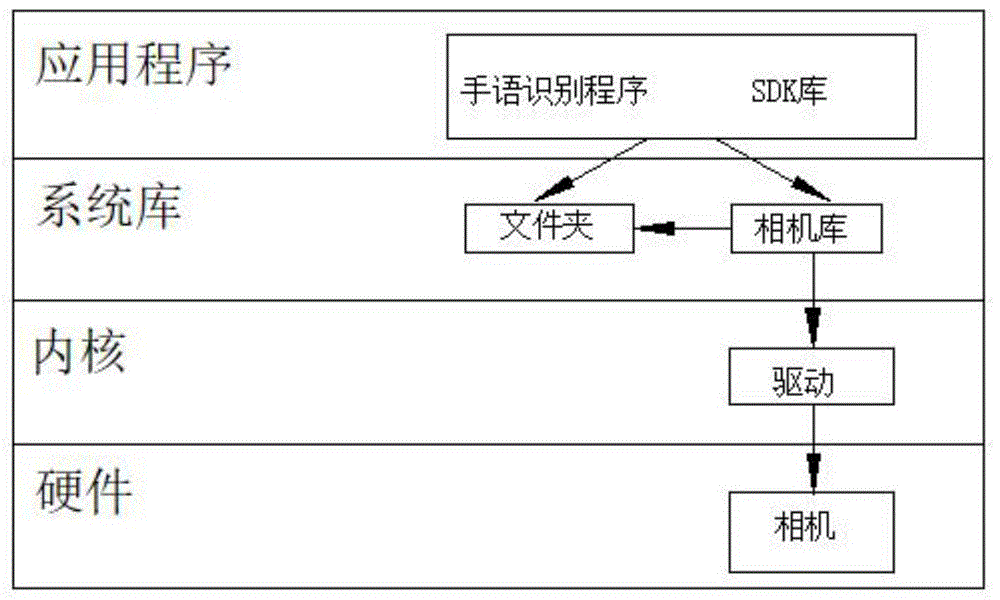
图1为一个实施例中手语识别系统部署于手机端的应用程序框架图。
图2为一个实施例中手语识别系统的流程示意图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例
参照图1-2,本发明提出的一种基于深度学习的纯视觉轻量手语识别系统,包括数据获取、手势特征提取、时序特征提取和句子生成,所述数据获取为待识别手语视频的获取及图像预处理,所述手势特征提取为从手语视频中各帧获取手势特征向量,所述时序特征提取为从手势特征向量序列中提取手语词信息,所述句子生成为对所有手语词信息按照上下文组合成文本句子;
识别系统还包括以下使用步骤:
s1,应用程序打开手机相机拍摄获取手语视频、或者从文件夹中直接获取手语视频,点击开始识别按钮片刻后,将手语识别结果显示在屏幕上;
s2,获取到手语视频后,首先进行四倍下采样得到的图像序列作为手语识别模型的源输入,进行八倍下采样得到的图像序列作为人体检测模型的源输入,预测出人体坐标,再以人体为中心裁剪源输入图像并缩放至高224、宽224个像素,最后进行归一化,数据准备完毕;
s3,在手势特征提取部分,首先第一个特征提取层采用一个2d卷积层和一个最大池化层用于缩放图像,利于减少计算量,具体参数为:卷积核大小7x7、步长2、全零填充3、通道64,第二个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道64,第三个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道128,第四个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道256,第五个特征提取层采用两个基础残差块,具体参数为:卷积核大小3x3、步长1、全零填充1、通道512。最后跟着一层全局平均池化层,手势特征提取部分最终输出一系列长度为512的特征向量;
s4,在时序特征提取部分,先接入一个1d卷积层,再接入一个最大池化层,最后接入一个1d卷积层,由于两层卷积和一层池化的作用,1dcnn有助于提取短距离时序特征,因此经过1dcnn层后输出即为手语词信息;
s5,在句子生成部分,采用一个blstm层,将上述得到的手语词信息作为输入,根据上下文环境输出手语句子信息,再经过一个全连接层映射到预测空间,最后经过ctcbeamsearch解码即可得到预测结果。
本发明再一方面提出了一种手机,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种平板电脑,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种pc电脑,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明再一方面提出了一种服务器,包括以上所述的基于深度学习的纯视觉轻量手语识别系统。
本发明巧妙使用两个1dcnn层作为短距离时序提取器,从而输出手语词信息,不仅运算量小而且运算速度快。本发明使用一个blstm层作为长距离时序提取器,既能捕捉正向信息又能捕捉反向信息,使输出的句子信息更加准确通顺。blstm层后接入一个全连接层,直接输出预测结果,简单高效。本发明采用了2dcnn+1dcnn+blstm+ctc的网络结构,只需要输入图像数据即可通过运算输出句子,无需额外附加信息。总体网络结构简单高效,训练周期短,适合在移动端部署。由于只需要一台具备摄像头的终端设备例如手机即可运行该程序,大大提高了使用便利性,有利于大面积推广。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!