一种基于工况识别的烧结点火温度建模预测方法与流程
[0001]
本发明涉及烧结点火技术领域,尤其涉及一种基于工况识别的烧结点火温度建模预测方法。
背景技术:
[0002]
钢铁行业是国民经济发展的重要基础产业,烧结生产是炼铁流程中的一道重要工序,是人工富矿的主要途径,产生的烧结矿用于高炉冶炼,烧结矿质量及产量对高炉生产有直接影响,进而影响整个炼铁生产的效果。烧结生产工艺一般包括配料、混合制粒、偏析布料、点火、抽风烧结、冷却、破碎筛分等过程,烧结点火是烧结生产中的一个重要流程,点火的效果会深刻影响烧结矿质量与产量。烧结燃烧过程开始于烧结机点火炉中的点火操作,点火的目的是点燃混合料表面的固体燃料,最终获得优质的烧结矿。点火过程的主要衡量指标之一是点火温度,如果温度偏低,则表层烧结矿强度差,甚至不能形成烧结矿;如果温度偏高,则将使表层烧结矿过熔,得不到满意质量的烧结矿,而且很容易造成燃料不必要的浪费。
[0003]
当前,对于烧结点火过程预测建模的研究,往往忽略了烧结点火过程所用煤气的热值在长时间尺度下存在较大变化的现象,都默认煤气热值不变,但通过对高炉煤气与焦炉煤气出厂时的热值检测,发现这些煤气都存在短期变化小,长期变化大的特点,该现象导致了烧结点火过程的长时间尺度下多工况特性。已提出的烧结点火温度预测模型基本上都属于单一建模方式,没有点火过程多工况下建模的研究,由于点火过程的多工况特性,建立的点火温度单一预测模型无法适应长时间尺度下不断变化的点火过程工况,因此,单一预测模型无法做到长期准确的点火温度预测,即在长时间尺度下无法保证预测的准确性,只能在短期内(即工况稳定时)有效,模型的实用性大大降低。
[0004]
因此,想要达到长时间尺度下更精确的点火温度预测效果,就需要通过对能反映煤气热值变化的相关烧结生产数据进行有效聚类,以实现对点火过程工况变化的有效识别,并能搭建出适用于多工况下更精确的组合预测模型,保证预测模型能根据点火过程实时数据进行有效的工况识别与准确的点火温度预测。
[0005]
当前,我国的烧结能耗水平仍然落后国际先进水平很多的情况下,研究烧结点火过程并优化烧结点火控制,能起到节约能耗、减少温室气体排放的作用,而点火过程智能控制研究的重要基础是精确的点火温度预测模型。对于点火温度预测模型的研究,大多都只能在短时间尺度工况稳定的情况下才有好的预测效果,而在长时间尺度工况发生变化的情况下,预测效果会变差。因此,研究烧结点火过程的预测模型具有极佳的经济效益,对烧结点火的特性研究、建模、控制和优化技术具有重要的现实意义。
技术实现要素:
[0006]
有鉴于此,本发明目的是提供一种基于工况识别的烧结点火温度建模预测方法,包括以下步骤:
[0007]
s1、采用fcm聚类的方法对点火过程的多工况进行聚类识别,得到每种工况下的数据集,包括当前时刻的点火温度t、空气流量q
a
、影响高炉煤气流量q
b
以及焦炉煤气流量q
c
;
[0008]
s2、对步骤s1中的每种工况进行dbi指标计算,确定烧结点火过程的工况数;
[0009]
s3、基于每种工况的数据集,搭建s2确定的每种特定工况下的点火温度预测模型;
[0010]
s4、根据不同的工况类别,切换相对应的预测模型,实现点火温度的预测。
[0011]
本发明提供的技术方案带来的有益效果是:克服了点火过程工况变化时单一预测模型精度变差的缺陷,能够根据实时反馈数据计算并判断点火过程工况是否发生改变,若发生改变,则可识别出当前工况并切换到相应的预测模型进行预测,保证了长时间尺度各种工况条件下点火温度都能被最适合的pso-elman预测模型所预测,从而保持长期高效的预测精度。
附图说明
[0012]
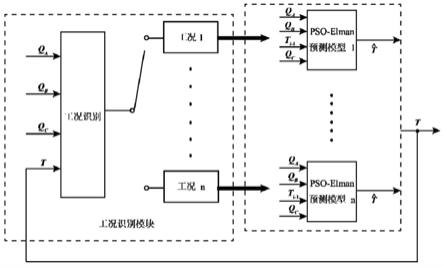
图1是本发明一种基于工况识别的烧结点火温度建模预测方法的结构图;
[0013]
图2是本发明一种基于工况识别的烧结点火温度建模预测方法中elman神经网络结构图;
[0014]
图3是本发明一种基于工况识别的烧结点火温度建模预测方法中预测结果对比图。
具体实施方式
[0015]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述。
[0016]
请参考图1,本发明提供了一种基于工况识别的烧结点火温度建模预测方法,包括以下几个步骤:
[0017]
s1、采用fcm聚类的方法对点火过程的多工况进行聚类,确定工况类别;
[0018]
烧结点火过程是一个多干扰、影响参数众多的复杂工业生产过程,具有时间延迟性、大滞后性、非线性等特点,影响点火温度t的主要参数如下表1所示:
[0019]
表1.烧结点火过程主要参数
[0020]
[0021]
其中,高炉煤气阀门开度v
b
、高炉煤气压力p
b
、焦炉煤气阀门开度v
c
、焦炉煤气压力p
c
分别影响高炉煤气流量q
b
与焦炉煤气流量q
c
的大小。在点火过程中,点火炉中的混合气体燃烧产生的热量直接决定了点火温度的高低,通常点火温度t正比于燃烧产生的热量e,因此,影响烧结点火温度的直接参数如下所示
[0022]
t
∝
e=h
b
*q
b
+h
c
*q
c
[0023]
因此,若要实现对点火温度的长期精确预测,不仅要考虑煤气流量这一影响参数(通常由于煤气压力波动导致煤气流量变化),还要考虑另外的直接影响因素——煤气热值,但由于烧结厂一般没有安装煤气热值检测仪,所以无法实时测量煤气热值变化,这也是已提出的预测方法中不考虑煤气热值影响的主要原因。而煤气热值长时间尺度变化小、长时间尺度变化大的特点,可以认为不检测煤气热值的情况下,点火过程存在长时间尺度下的多工况特性。
[0024]
采用欧式距离为聚类指标的fcm目标函数及其约束条件如下:
[0025][0026][0027]
其中,x
i
为第i个样本,c
j
为第j个聚类中心,u
ij
为第i个样本对于第j类的隶属度,l为聚类数目,n为样本数,m∈[1,∞)为模糊权重系数;
[0028]
fcm聚类算法是一种不确定建模与数据聚类的有效工具,本发明采用fcm聚类的方法对点火过程的多工况进行聚类识别,聚类的输入量x
j
需要能反应点火过程工况的变化,即反映高炉煤气热值与焦炉煤气热值的大小,煤气热值相近的数据被聚为一类,可视为同一工况。本发明设计的fcm聚类的输入变量x
i
如下:
[0029][0030]
其中,t
i
、q
a(i)
、q
b(i)
以及q1分别表示数据集中的第i个点火温度、空气流量、高炉煤气流量以及焦炉煤气流量,x
i
表示单位时间单位煤气流量下,第i个点火温度的变化程度。
[0031]
s2、对步骤s1中的每种工况进行dbi指标计算,确定烧结点火过程的工况数;
[0032]
对于fcm聚类算法而言,聚类数的选择会极大的影响最终的聚类效果,聚类数过大或过小都对聚类效果造成负面影响,找出正确的聚类数通常依赖于数据集分布情况,也依赖于用户要求的聚类分辨率。因此,聚类数是fcm算法的一大核心参数,也是决定fcm聚类效果的关键,在设计fcm算法时需要合理设定聚类数,而这也是使用fcm算法时的一大难点。目前,最优聚类数确定的一些比较流行的方法是通过聚类有效性评价指标来评估,指标的核心思想是聚类的效果需达到类内高的相似度和类间低的相似度。
[0033]
对于fcm最佳聚类数的确定,本发明设计了davies-bouldin index(dbi)作为fcm
聚类有效性评价的标准,比较不同聚类数下fcm的dbi数值,以确定最佳的聚类数,进而确定烧结点火过程最可能的工况数,所述最佳聚类数确定方法具体如下:
[0034]
s21、定义距离函数d
ij
,表示第i类与第j类之间的聚类中心距离,公式如下:
[0035][0036]
其中,a
ki
与a
kj
分别为第i类聚类中心与第j类聚类中心的第k维数值,n为每个样本的维数;
[0037]
s22、定义一个类间离散度s
i
,表示第i类样本之间的离散度,公式如下:
[0038][0039]
其中,x
j
为第i类数据中第j个样本;m
i
代表属于第i类数据的样本总数,s
i
代表类内样本与聚类中心间距离的平均值,c
i
为第i类聚类中心;
[0040]
s23、定义一个相似度r
ij
,表示第i类与第j类之间的类间相似度;
[0041][0042]
s23、计算每个类与其他类之间的相似度,并选择其中的最大值作为该类的最大类间相似度,指标dbi定义为所有类的最大类间相似度的平均值如下:
[0043][0044]
其中,l为聚类数目,r
ij
为相似度;
[0045]
s24、为了找出fcm工况识别模块的最佳聚类数(工况数),本发明使用来自于实际烧结厂的生产数据作为fcm聚类以及dbi评价指标的训练数据。通过仿真计算与分析,不同聚类数下的dbi数值如表2所示,可知聚类数为5时,fcm聚类效果最佳,所以工况识别模块的工况数应该设定为5。
[0046]
表2不同聚类数的dbi
[0047][0048]
s3、基于每种工况的数据集,搭建s2确定的每种特定工况下的点火温度预测模型;
[0049]
基于聚类后得到的不同组实际数据,每种特定工况下的点火温度预测模型可被训练搭建,本发明搭建每种工况下的pso-elman预测模型,以准确预测每种工况下的点火温度。
[0050]
当前,神经网络被广泛应用于模型预测,而elman神经网络动态递归网络,适用于影响因素复杂多变的烧结点火过程。本发明通过分组后的实际生产数据训练搭建了四输入一输出的elman神经网络点火温度预测模型,空气流量q
a
、影响高炉煤气流量q
b
、焦炉煤气流量q
c
和前一时刻的点火温度t
i-1
,输出量为当前时刻的点火温度t,设计的elman神经网络结
构如图2所示.
[0051]
本发明采用了擅长于全局搜索的pso算法来分配elman神经网络的初始权重,并在全局解空间中定位到一个合适的搜索空间,以提升bp算法的效果。最终,一个混合训练算法的神经网络预测模型——pso-elman点火温度预测模型被搭建出来,通过将聚类后得到的不同组数据分别进行训练建模,得到了五个工况切换的pso-elman预测模型。
[0052]
s4、根据工况识别模块对实时反馈数据的计算结果,判断当前所处的工况,以切换到其中最合适的预测模型进行点火温度的预测,从而提高长时间尺度点火温度的预测精度。
[0053]
为了证明该模型更佳的预测性能,本发明选取了不区分工况的单bp预测模型与单pso-elman预测模型做对比实验,采用相同训练集与测试集的三种预测模型最终对比实验效果如图3所示。
[0054]
从图中可清晰看出三种预测模型的预测效果,其中只有基于工况识别的pso-elman工况预测模型能在长时间尺度下精确稳定的控制点火温度,而对比单预测模型的效果,单pso-elman预测模型也要好于单bp预测模型,为了更清晰的对比三种预测模型的预测误差,表3计算并统计了这三类预测模型的预测误差相关参数。
[0055]
表3.预测误差统计
[0056][0057]
因此,本发明设计的基于工况识别的点火温度预测方法在长时间尺度下保持了较高的预测性能,比传统的单模型预测方法要更高效。
[0058]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1