数据申报方法及管理系统与流程
本公开属于医疗数据处理技术领域,更具体地,涉及一种数据申报方法及管理系统。
背景技术:
基层医疗服务中心公共卫生防疫体系的主要工作内容是对辖区内重点防疫人群(儿妇老慢重)基本情况、医疗情况追踪、药物需求基本情况等情况进行随访调研。目前,基层医疗服务中心的随访人员主要是通过座机或手机与辖区内重点防疫人口进行电话沟通,根据相关领导部门的数据填报内容进行询问,通过手工记录内容主诉的方式将询问结果一一记录,再手工填入各个上报表格中。在填写中存在数据输入慢、手工笔记内容有丢失、填写表格内容不符合要求等,大大影响了上报内容质量,造成效率低,且数据错误多的问题。同时增加基层医疗服务人员的工作量。
基层医疗服务中心的随访人员的工作方式是随访人员拨打电话,与被访者交谈的过程中在记录本上记录,每天下班后随访人员再将记录的内容逐一填入各个上报表格。现在的工作模式存在以下问题:
1.随访人员记录方式是人工方式,存在记录内容上有缺失或错误的问题;
2.随访人员进行随访时会有漏人或漏项的风险;
3.上报表格数量多,在填报的时候存在人工数据输入失误的风险;
4.随访人员的计算机使用水平普遍不高,数据输入慢,效率低,人工成本高;
5.随访原始数据主要依靠excel表格存储,只能依靠人工搜索,搜索效率低;
6.没有数据统计分析软件,需要人工统计,用时长,效率低;
7.上报数据维护困难。
技术实现要素:
有鉴于此,本公开实施例提供了一种数据申报方法及管理系统,至少解决现有技术中工作效率低且数据错误多问题。
第一方面,本公开实施例提供了一种数据申报方法,包括:
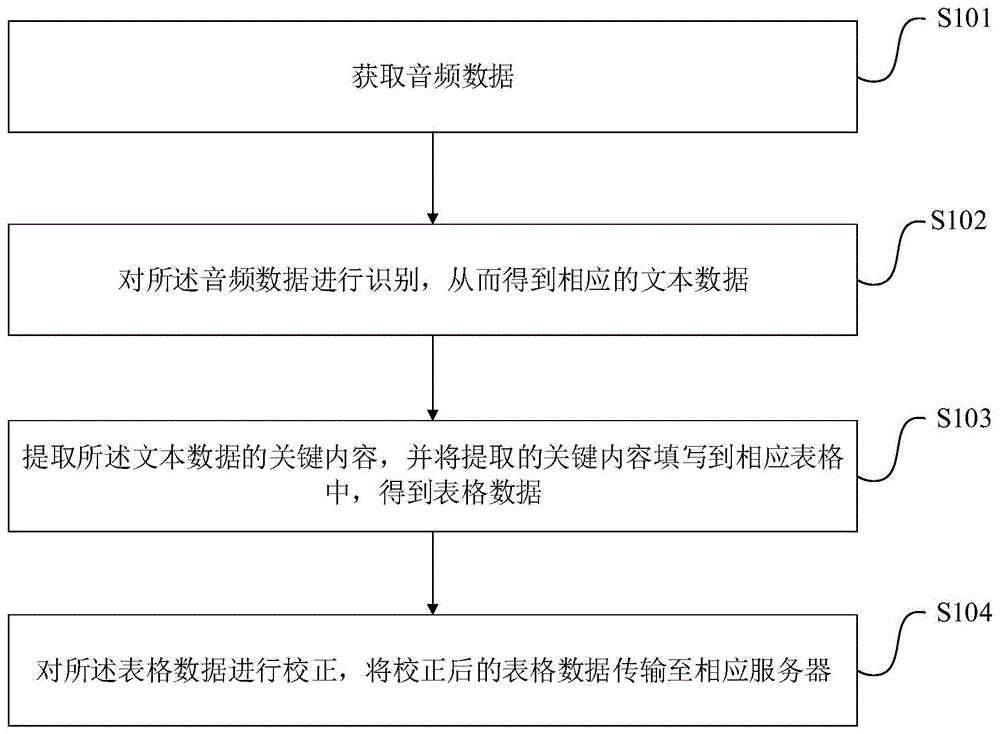
获取音频数据;
对所述音频数据进行识别,从而得到相应的文本数据;
提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据;
对所述表格数据进行校正,将校正后的表格数据传输至相应服务器。
可选的,所述对所述音频数据进行识别,从而得到相应的文本数据,包括:
对所述音频数据进行特征提取,得到特征数据;
将所述特征数据与预配置的模型库的数据进行对比,从而得到相应的文本数据。
可选的,提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据,包括:
对所述文本数据进行自然语言处理,从而提取文本数据的关键内容;
将关键内容填入表格的相应位置。
可选的,提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据,包括:
基于预训练的语义模型在所述文本数据提取键内容。
可选的,所述对所述表格数据进行校正,包括:
记录校正过程中修改的数据,基于所述修改的数据对语义模型中的主诉抽取规则和语义规则进行调整。
可选的,所述对所述音频数据进行识别,从而得到相应的文本数据,包括:
将得到的文本数据实时显示。
第二方面,本公开实施例还提供了一种数据管理系统,使用第一方面任一所述的数据申报方法,包括:
基础设施层:为整个系统运行提供基础支撑;
数据层:为应用层提供基础数据支撑;
支撑层:为上层的应用层提供工具组件支撑;
应用层:用户提供了应用服务;
展现层:显示系统数据。
可选的,所述基础设施层包括:服务器设备、存储设备、网络设备、安全设备、数据库和操作系统。
可选的,所述数据层包括:原始内容文本库、主诉文本数据库、用户行为数据和被访者信息库;
所述支撑层包括:用户管理组件、自定义表单工具、语音识别模块、自然语言处理模块和结构化数据学习模块;
所述应用层为用户提供数据上报、被访者信息维护、上报表单维护、统计分析和系统管理;
所述展现层为通过客户端展示。
可选的,所述客户端内存储被访者信息,所述被访者信息包括,被访者联系方式、类别、疾病史和/或治疗史;
所述客户端存储被访者列表,通过被访者列表选择被访者进行通话。
本公开通过对音频数据进行识别,从而转换为相应的文本数据,在文本数据中提取关键内容,完成表格填写,并对填写的表格进行校正后传输至相应服务器,从而达到提高效率,并降低数据错误的目的。
本公开的其它特征和优点将在随后具体实施方式部分予以详细说明。
附图说明
通过结合附图对本公开示例性实施方式进行更详细的描述,本公开的上述以及其它目的、特征和优势将变得更加明显,其中,在本公开示例性实施方式中,相同的参考标号通常代表相同部件。
图1示出了本公开的一个实施例的数据申报方法的流程图;
图2示出了本公开的一个实施例的数据管理系统架构示意图;
图3示出了本公开的一个实施例的数据管理系统业务流程示意图。
具体实施方式
下面将更详细地描述本公开的优选实施方式。虽然以下描述了本公开的优选实施方式,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。
实施例一:
如图1所示,一种数据申报方法,包括:
步骤s101:获取音频数据;
步骤s102:对所述音频数据进行识别,从而得到相应的文本数据;
步骤s103:提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据;
步骤s104:对所述表格数据进行校正,将校正后的表格数据传输至相应服务器。
可选的,所述对所述音频数据进行识别,从而得到相应的文本数据,包括:
对所述音频数据进行特征提取,得到特征数据;
将所述特征数据与预配置的模型库的数据进行对比,从而得到相应的文本数据。
可选的,提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据,包括:
对所述文本数据进行自然语言处理,从而提取文本数据的关键内容;
将关键内容填入表格的相应位置。
可选的,提取所述文本数据的关键内容,并将提取的关键内容填写到相应表格中,得到表格数据,包括:
基于预训练的语义模型在所述文本数据提取键内容。
可选的,所述对所述表格数据进行校正,包括:
记录校正过程中修改的数据,基于所述修改的数据对语义模型中的主诉抽取规则和语义规则进行调整。
可选的,所述对所述音频数据进行识别,从而得到相应的文本数据,包括:
将得到的文本数据实时显示。
在一个具体的应用场景中,
随访数据采集的数据是随访人员与被访者通话的音频数据,采集方式可分为2种:手机app和pc客户端。
1.手机app:
手机app功能将包含被访者基本信息维护、拨打电话、查看通话内容、查看主诉等。随访人员通过无线网络(wifi)或移动数据网络将通话音频数据传输到服务器端,再由服务器端的语音识别软件对音频文件进行流处理,生成文本文件。
(1)被访者基本信息维护:
随访人员可在手机上新增、修改、删除和查看被访者基本信息,例如姓名、年龄、性别、电话、随访类别(例如儿妇慢老重)、疾病史、治疗史等。
(2)拨打电话:
随访人员通过随访人员列表选择被访者姓名即可拨打电话,无需查看被访者信息后再手动拨号。如遇姓名相同,随访人员可点击姓名旁的详细查看随访者的详细信息,判断是否为需要联系的随访者。
(3)查看通话内容:
通话开始后,手机屏幕上会弹出一个新的对话框,“准实时”反馈服务器端通过语音识别转换的文本内容,将以对话方式展示,类似微信的聊天界面。
(4)查看主诉:
当通话结束后,显示通话内容的对话框关闭,自动弹出本次随访的主诉内容,并保留在被访者的随访记录中,随访人员可通过查询被访者随访记录查看主诉内容。
2.pc客户端:
pc客户端与app功能类似,同样包含被访者基本信息维护、拨打电话、查看通话内容、查看主诉等。pc客户端采用网络虚拟拨号方式拨打被访者电话,与电信运营商合作,将来电号码显示为医疗服务中心座机号码,随访人员通过耳麦的方式与被访者通话。音频数据通过局域网的方式传输到服务器端。
语音识别:随访人员与被访者通话的音频数据通过局域网或移动网络传输到服务器端,进入语音识别模块,通过语音识别软件的辨识,输出通话内容的文本文件,将转换好的文本文件实时传输到pc客户端或手机app上,使随访人员可以实时看到对话内容。通话结束后,通话内容文本文件将存储在随访原始数据库中,随访人员可随时调阅通话内容文本文件。
自然语言处理(语义识别):自然语言处理(语义识别)模块中包含语义词典、分词规则、语法规则等基础文件,语义的定义、分词的划分将根据随访工作的业务需要和特点进行设置。根据数据上报的需要,制定提取规则,提取通话文本的主诉,形成主诉文本文件,存放于主诉数据库中。可设置时长间隔(例如1分钟或2分钟),同步分析处理通话文本文件内容,随时提取主诉。主诉提取后,将自动按照上报表格相应位置填入。
数据上报:数据上报主要包含上报表格审核和数据查询。
由于上报表格数量和种类较多,随访人员需要在上报前逐个检查,保证上报内容准确。当检查发现上报内容出现问题时,首先查看主诉文本文件,如果主诉文本文件内容不清晰准确,则需要查看相关通话文本文件的全部内容。随访人员可根据具体情况对上报表格中的错误进行修改,修改的内容将被系统记录,作为机器学习的样本。
机器学习:基层医疗服务机构每天需要向上级单位上报各类数据,因此上报的表格种类很多,这样就为机器学习提供了庞大的样本库。在系统使用初期,很大可能填写的数据信息不符合上报标准和要求,需要随访人员手动修改,系统在记录下用户的行为后,可根据学习规则,自动调整主诉抽取规则和语义规则,逐渐完善主诉提取规则,提升主诉提取的准度和精度。
本实施例利用智能数据提取、语义分析、机器学习等技术,从语音采集、语义分析、数据展示到数据统计,对随访和上报业务进行全生命周期管理,减少随访人员的工作量,提升工作效率,降低上报内容错误率,提高了上报数据的质量。
实施例二:
如图2所示,本公开实施例还提供了一种数据管理系统,使用第一方面任一所述的数据申报方法,包括:
基础设施层:为整个系统运行提供基础支撑;
数据层:为应用层提供基础数据支撑;
支撑层:为上层的应用层提供工具组件支撑;
应用层:用户提供了应用服务;
展现层:显示系统数据。
可选的,所述基础设施层包括:服务器设备、存储设备、网络设备、安全设备、数据库和操作系统。
可选的,所述数据层包括:原始内容文本库、主诉文本数据库、用户行为数据和被访者信息库;
所述支撑层包括:用户管理组件、自定义表单工具、语音识别模块、自然语言处理模块和结构化数据学习模块;
所述应用层为用户提供数据上报、被访者信息维护、上报表单维护、统计分析和系统管理;
所述展现层为通过客户端展示。
可选的,所述客户端内存储被访者信息,所述被访者信息包括,被访者联系方式、类别、疾病史和/或治疗史;
所述客户端存储被访者列表,通过被访者列表选择被访者进行通话。
1.基础设施层:为整个系统运行提供基础支撑,包含服务器设备、存储设备、网络设备、安全设备、数据库和操作系统。
2.数据层:为应用层提供基础数据支撑,包含原始内容文本库、主诉文本数据库、用户行为数据、被访者信息库等。
3.支撑层:支撑层为上层的应用层提供各种工具组件支撑,包含用户管理组件、自定义表单工具、语音识别模块、自然语言处理模块、结构化数据学习模块等。
4.应用层:应用层为用户提供了数据上报、被访者信息维护、上报表单维护、统计分析、系统管理等应用子系统。
5.展现层:通过手机app和pc客户端中展示。
主要业务流程如图3所示,在随访人员与被访者通话过程中,系统将采集到的对话音频进行流处理,由语音识别软件将音频翻译为文本文件,实时传输给随访人员。根据上报数据要求建立数据主诉提取模型,利用语义识别软件将文本内容进行分析处理,提取主诉(上报医疗数据的主要描述,例如慢性疾病名称、用药量、用药间隔等),填入上报表格的相应位置。随访人员在上报前需要对表格内的每一项上报内容做人工审核,将不符合上报标准或描述有问题的内容手动修改,确认无误后上报。系统记录每一条人工修改的内容,并对照相应的随访文本进行比对,进行机器学习,逐步完善语义分析模型,逐渐更加精准的提取主诉。
基层医疗服务中心数据智能申报系统实现了用信息化手段替代人工作业方式,从信息采集入手,利用人工智能方式采集、输入数据,避免了在数据采集过程中由于人为原因导致数据不全或有误的问题,也解决了由于操作人员计算机水平不高而引发数据输入效率低。在数据管理方面,系统可以将原始数据(音频数据转成的文本文件)、过程数据、结果数据等所有数据进行管理,保证数据的完整性和可靠性,在日常工作中,方便随访人员随时快速高效查询相关数据,同时利用统计分析功能,对辖区内公共医疗情况进行统计分析。
以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!