基于远程监督的新闻情感实体抽取方法
本发明属于计算机人工智能领域,具体为一种基于远程监督的新闻情感实体抽取方法。
背景技术:
面向新闻领域的命名实体识别由于独特的应用背景和文本表达方式,研究者们对其开展了探索。冯蕴天等提出了人员、军衔、军职、军用机构、设施等实体分类原则,基于战斗文书、执勤文书、军用文书等规范的文本构建语料库。其使用少量的人工标注训练语料对crf模型进行训练,训练的模型对未标注的测试语料进行实体识别,模型在测试语料上得到f值为90.9%的识别效果。游飞等针对武器命名实体进行识别,建立了基于dnn的武器实体识别模型,模型以固定维度的词向量和词性向量作为输入,通过非线性变换学习得到上下文特征。模型在来自环球网、中华网等7500篇新闻建立的语料上训练,f值达到91.02%。王学峰等将命名实体划分为部队、地名、机构、武器、设施、时间、环境与数量8种类别,提出一种基于字级别表征、结合bilstm和crf的实体识别模型(character-bilstm-crf),模型基于未公开的30余份联合作战演习想定文档与指挥所演练想定文档构建的语料集进行训练,f值达到98%。此外,研究人员们也探索了应用卷积神经网络生成字向量,并结合bilstm和crf建立新闻领域命名实体的方法。面向非公开的作战文书中的命名实体识别,基于嵌套分类原则将命名实体分为位置、部队、人员、物品、数字5大类以及地名、编制等13个小类,采用上述cnn-bilstm-crf模型,在100篇未公开的作战文书构建的语料集上的实验得到了较高的召回率和f值。
基于规则、字典以及统计学习模型的传统情感实体识别方法依赖于规则设计和特征工程,虽然取得了较高的召回率,但是规则的制定和特征的抽取需要丰富的领域知识以及大量的人工成本,且很难针对所有问题制定统一的模板和规则。近年来,在计算能力和文本分布式表示技术支持下,基于深度神经网络(deepneuralnetwork,dnn)的情感实体识别方法在通用领域以及法律、医学、生物化学、金融等特定领域取得了突破性的进展。相比较于其他领域的情感实体识别研究,新闻领域情感实体识别面临以下问题和挑战:
实体识别任务中往往存在实体边界难以界定的问题。例如在保险领域,可以将“中国人寿保险”当作一个实体,也可以认为是“中国”和“人寿保险”2个实体。然而领域的专业性使得实体间的界限更加难以确定,例如,“英国皇家海军”可以认为是组织实体,同样也可以认为“英国”是地名实体,“皇家海军”是组织实体;“俄军图-160战略轰炸机”可以认为是武器装备实体,同样也可以认为“俄军”是组织实体,“图-160战略轰炸机”是武器装备实体。
实体识别任务中同样存在实体简化表达的现象。相较于其他领域,新闻领域因领域的独特性、专业性,其情感实体简化表达后晦涩难懂,没有一定的规律性。
基于crf等统计模型的命名实体识别技术依赖于领域专家完成大量的人工特征选取工作;基于长短时记忆神经网络等模型的领域命名实体方法,需要在模型训练的过程中依靠庞大的语料库构建词向量。
医学领域的电子病历、法律领域的判决书与起诉书都具有严格的格式和表达规范,基于规则的识别方法就可以获得优秀的识别效果。以微博为代表的社交媒体数据表达不规范,存在大量的口语表达,没有特定的规则,识别实体难度较大。
目前没有面向新闻领域的公开语料数据集和实体分类标准,阻碍了开源情报的研究工作。
技术实现要素:
本发明的目的在于提供了一种基于远程监督的新闻情感实体抽取方法。
实现本发明目的的技术方案为:一种基于远程监督的新闻情感实体抽取方法,包括以下步骤:
步骤1:采用爬虫技术,爬取官方新闻网站新闻预料并缓存至本地仓库;
步骤2:对爬取的新闻语料进行预处理,获得切分成句的新闻预料;
步骤3:构建关键实体知识库,根据知识库对切分成句的新闻预料进行自动标注;
步骤4:利用标注了的新闻预料对情感句抽取模型进行训练使其具备对输入句子进行自动情感判断的能力;
步骤5:利用步骤4抽取出情感句,将情感句作为情感实体抽取模型的训练集进行训练,使其具备抽取句中情感的持有者、表达对象、事件的能力;
步骤6:采用步骤1、步骤2的方法爬取新闻语料并切分成句,将切分成句的新闻语料输入训练好的情感句抽取模型抽取情感句,并将抽取的情感句输入训练好的情感实体抽取模型,获得情感实体。
优选地,爬取官方新闻网站相关新闻的具体方法为:
通过解析官方网站带关键字的搜索结果,获取与事件相关的新闻网址;
根据新闻网址解析新闻内容,获取新闻的标题、时间、具体内容并缓存至本地仓库。
优选地,对爬取的新闻语料进行预处理包括:
将爬取的新闻语料从进行数据清洗,去除冗余以及与主题无关的脏数据;
以标点符号作为标志对本地仓库中的新闻语料进行句子划分。
优选地,构建的关键实体知识库为人物、组织、国家、事件实体知识库。
优选地,根据知识库对切分成句的新闻预料进行自动标注的原则为:当句子中出现超过n个知识库实体时标注为带情感句,n为设定的自然数。
优选地,所述情感句抽取模型包括字向量表达层、softmax分类层,分别具体为:
所述字向量表达层采用bert预训练模型,用于对切分成句的新闻文本数据中的每个字进行特征提取得到字特征;
所述softmax分类层用于预测输出类别上的概率分布并解码标签,通过预测结果判断输入句子是否为情感句。
优选地,所述情感实体抽取模型包括字向量层、编码器、解码器,分别具体为:
所述字向量层采用bert预训练模型,用于获得情感句的子特征;
所述编码器采用双向的长短时记忆神经网络,用于提取输入文本的语义特征;
所述解码器采用条件随机场,用于将语义特征解码成对应的标签,根据预测的标签值,获取对应的实体位置与实体类别
本发明与现有技术相比,其显著优点为:
本发明在有大量无标记样本的情况下,采用远程监督的方式为大量样本生成带噪声的数据集供模型训练,大大减少的了人工标注的成本,提高了模型训练的效率;
本发明面向新闻领域,针对特别新闻领域带来的难题和挑战,设计了基于bert字向量的情感句抽取技术,将实体抽取的目标集中在更有意义的范围中,大大提高了实体抽取的效率;
本发明基于多模型融合的实体抽取网络,结合专家知识库,抽取情感句中的情感持有者、情感表达对象、相关事件信息,为新闻领域的情感分析、舆情分析奠定了前置任务的基础。
附图说明
图1本发明流程图。
图2情感句抽取模型训练测试流程。
图3情感实体抽取模型训练测试流程。
图4lstm结构图。
图5crf结构图。
具体实施方式:
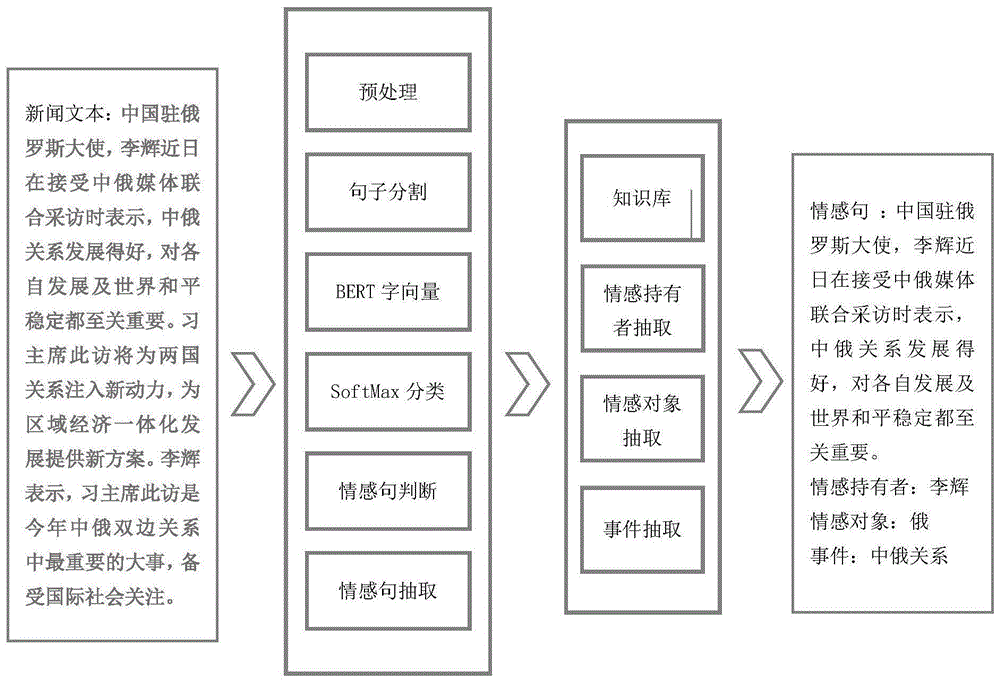
一种基于远程监督的新闻情感实体抽取方法,如图1所示,包括以下步骤:
步骤1:采用爬虫技术,爬取官方新闻网站新闻预料并缓存至本地仓库;
采用爬虫技术,针对热点新闻事件,爬取环球网、网易新闻、新华日报等官方新闻网站的相关新闻预料。具体方法为:通过解析官方网站带关键字的搜索结果,获取与事件相关的新闻网址、根据新闻网址解析新闻内容,获取新闻的标题、时间、具体内容等数据缓存至本地仓库。
步骤2:对爬取的新闻语料进行预处理,获得切分成句的新闻预料;
将爬取的新闻语料从本地仓库中读出进行数据清洗,去除冗余以及与主题无关的脏数据。将新闻中无用重复的语句删除。将清洗后的数据结构化存储以便算法模型的训练。
以标点符号“。”、“?”、“!”、“……”,“”作为标志对数据库中的数据进行句子划分。
步骤3:构建关键实体知识库,根据知识库对切分成句的新闻预料进行自动标注;
根据本地仓库中的数据,建立人物、组织、国家、事件等关键实体知识库。根据关键实体知识库对切分成句的新闻进行自动的标注。标注原则为:当句子中出现超过n个知识库实体时标注为带情感句。n为可调整的参数,通过这种远程监督的方式,可以获取大量带噪声的训练数据。
步骤4:利用标注了的新闻预料对情感句抽取模型进行训练使其具备对输入句子进行自动情感判断的能力;
如图2所示,将切分成句的新闻文本数据按照二八原则分为训练集和测试集,利用训练集训练情感句抽取模型,使用测试集对训练好的模型进行准确率与性能分析。
进一步的实施例中,所述情感句抽取模型包括字向量表达层、softmax分类层。
具体地,所述字向量表达层采用bert预训练模型,所述bert预训练模型利用transformer编码器作为语言模型,采用“遮蔽语言模型”和下一句预测机制用以克服当前大多数词向量生成模型单向性的问题。利用bert预训练模型对切分成句的新闻文本数据si={xi1,xi2,...,xik}中的每个字进行特征提取得到字特征:xij=(e1,e2,...,em)。其中si表示在数据集中第i个句子,xik表示句子中第k个字,xij表示第i个句子的第j个字的字向量表示,em表示xij中第m个的数值。综上所示,每个句子经过字向量表示层后,其中的每个字都会由m维的字向量特征组成,从而可以表示为:
具体地,softmax分类层作为情感句分类的分类器,将网络的输出归一化为预测输出类别上的概率分布,将输出的结果映射到(0,1)的值,表示为:
其中
通过情感句抽取模型从长文本的新闻中,抽取出带有情感倾向的句子。
步骤5:利用步骤4抽取出情感句,将情感句作为情感实体抽取模型的训练集进行训练,使其具备抽取句中情感的持有者、表达对象、事件的能力;
情感实体抽取模型训练测试流程如图3所示,基于抽取出的情感句,抽取句中情感的持有者、表达对象、情感句相关的事件。基于深度学习算法采用序列到序列的模型识别情感句中的重要实体。
进一步的实施例中,所述情感实体抽取模型由三个部分组成:字向量层、编码器、解码器;
具体地,所述字向量层同样采用bert预训练模型。输入情感句抽取模型抽取出的情感句,输出情感句的字向量表示。
具体地,所述编码器采用双向的长短时记忆神经网络(lstm),用于提取输入文本的语义特征。lstm也是一种循环神经网络(rnn)的特殊类型,可以学习长久依赖信息,所有rnn都具有一种重复神经网络模块的链式形式。在标准的rnn中,该重复模块只有一个非常简单的结构,例如一个tanh层,而lstm的“记忆细胞”通过刻意设计避免了长期依赖问题。lstm通过一种精心设计称为门的结构控制细胞状态,直接在整个并向中删减或增加信息。采用bi-lstm能够通过两个不同方向的特征提取器获取整个文本的全局特征信息从而提高enconder对全文的特征提取能力。lstm模型计算方式如下:
it=σ(wxixt+whiht-1+wcict-1+bi)
ft=σ(wxfxt+whfht-1+wcfct-1+bf)
ct=ftct-1+ittanh(wxcxt+whcht-1+bc)
ot=σ(wxoxt+whoht-1+wcoct-1+bo)
ht=ottanh(ct)
式中,i、f、c、o分别为输入门、遗忘门、细胞状态和输出门;w和b分别为对应的权重系数矩阵和偏置项;σ和tanh分别为sigmoid函数和双曲正切激活函数。
lstm模型训练过程大致可以分为四个步骤:①按照上述五式(前向计算方法)计算lstm细胞的输出值;②反向计算每个lstm细胞的误差项,包括按时间和模型层级2个反向传播方向;③根据相应的误差项,计算每个权重的梯度;④应用基于梯度的优化算法更新权重。lstm结构图如图4所示。
具体地,所述解码器采用条件随机场(crf)。编码器将数据进行特征提取与编码,解码器将特征解码成对应的标签,根据预测的标签值,获取对应的实体位置与实体类别。crf里的条件指的是在给定随机变量x的条件下,随机变量y的马尔科夫随机场。通常情况,只使用线性链条件随机场,将其用于标注问题,条件概率为p(y|x)。其中x是给定的观测序列,y是需要标注的标注序列(状态序列)。对于任意节点v成立,则称条件概率分布p(y|x)为条件随机场,其一般形式如下。
p(yv|x,yw,w≠v)=p(yv|x,yw,w~v)
通过解码器可以获取每个词的对应标签,根据标签类别判别实体的类型和位置从而实现情感句中情感持有者、表达对象、事件的识别与抽取,经过测试该模型可以达到65%的准确率。crf结构图如图5所示。
步骤6:采用步骤1、步骤2的方法爬取新闻语料并切分成句,将切分成句的新闻语料输入训练好的情感句抽取模型抽取情感句,并将抽取的情感句输入训练好的情感实体抽取模型,获得情感实体。
经过上述的步骤1至步骤5,训练了情感句抽取模型与情感实体抽取模型,在实际应用中,通过步骤1的方式爬取新的新闻语料,通过步骤2对语料进行预处理,将处理好的长文本切分成句输入情感句抽取模型,模型判断输入句子是否为情感句。将情感句抽取模型判断为是情感句的句子存储成情感句库。读取情感句库中的情感句作为情感实体抽取模型的输入,经过情感句抽取模型,可以获取输入情感句中各类别情感实体的位置。根据位置可以抽取出情感句中包含的情感持有者,情感表达对象,相关事件。
本发明基于远程监督学习训练深度学习模型抽取新闻中的情感实体,包括情感持有者、情感表达对象、事件;针对新闻领域实体抽取的挑战,设计了基于bert字向量的深度学习模型,同时结合专家知识库,自动标注的方式极大程度的缓解了人工标注的成本,具有重大意义。
- 还没有人留言评论。精彩留言会获得点赞!