一种实体关系的抽取方法和设备与流程
[0001]
本发明涉及数据处理技术领域,具体涉及一种实体关系的抽取方法和设备。
背景技术:
[0002]
在很多领域,例如医学领域,涉及到大量的实体,为此,需要了解实体之间的关系,以此利于后续的应用,但是目前实体关系的获取一般是先通过使用多种cnn(convolutional neural networks,卷积神经网络)和lstm(long short-term memory,长短期记忆人工神经网络)深度学习网络从不同维度的特征来进行抽取,然后将这些多种cnn和lstm深度学习网络联合在一起,选择出样本最右的实体关系。
[0003]
但是目前的这种方式没有考虑到不同实体之间上下位语义信息以及实体的类型信息,导致识别不准确。
[0004]
为此,目前需要一种更好的方案来解决现有技术中的问题。
技术实现要素:
[0005]
本发明提供一种实体关系的抽取方法和设备,能够解决现有技术中识别不准确的技术问题。
[0006]
本发明解决上述技术问题的技术方案如下:
[0007]
本发明实施例提供了一种实体关系的抽取方法,包括:
[0008]
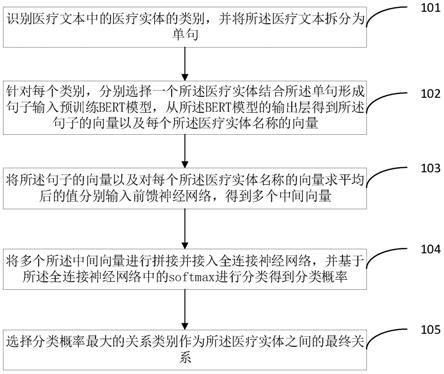
识别医疗文本中的医疗实体的类别,并将所述医疗文本拆分为单句;
[0009]
针对每个类别,分别选择一个所述医疗实体结合所述单句形成句子输入预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;
[0010]
将所述句子的向量以及对每个所述医疗实体名称的向量求平均后的值分别输入前馈神经网络,得到多个中间向量;
[0011]
将多个所述中间向量进行拼接并接入全连接神经网络,并基于所述全连接神经网络中的softmax进行分类得到分类概率;
[0012]
选择分类概率最大的关系类别作为所述医疗实体之间的最终关系。
[0013]
在一个具体的实施例中,在识别医疗文本中的医疗实体的类别之前,还包括:获取医疗文本。
[0014]
在一个具体的实施例中,所述医疗文本包括以下一个或多个的任意组合:医学教材、临床指南、病历。
[0015]
在一个具体的实施例中,所述“识别所述医疗文本中的医疗实体的类别”,包括:
[0016]
采用bert和crf的组合对所述医疗文本中医疗实体的类别进行识别。
[0017]
在一个具体的实施例中,所述类别包括:疾病、检查、症状、治疗、药物。
[0018]
在一个具体的实施例中,在所述句子中,每个所述医疗实体前均设置有所述医疗实体对应类别的标识;所述句子前设置句子的标识。
[0019]
在一个具体的实施例中,所述句子的向量是通过以下公式确定的:
[0020]
h'
cls
=w
cls
(tanh(h
cls
))+b
cls
;
[0021]
其中,h'
cls
为所述句子的向量;w
cls
为所述句子的权重参数;h
cls
为所述句子;b
cls
为所述句子的偏置参数。
[0022]
在一个具体的实施例中,当所述医疗实体的数量为2个时;所述医疗实体名称的向量是通过以下公式确定的:
[0023][0024][0025]
其中,i
e1
,j
e1
,i
e2
,j
e2
分别为实体e1的首末字符位置和实体e2的首末字符位置;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量;w
e1
为实体e1的权重参数;w
e2
为实体e2的权重参数;b
e1
为实体e1的偏置参数;b
e2
为实体e2的偏置参数。
[0026]
在一个具体的实施例中,当所述医疗实体的数量为2个时;所述分类概率是通过以下公式确定的:
[0027]
p=softmax(w[concat(h'
cls
,h
e
'1,h
e
'2)]+b);
[0028]
p为分类概率;w为隐藏层的权重参数;b为隐藏层的偏置参数;h'
cls
为所述句子的向量;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量。
[0029]
本发明实施例还提出了一种实体关系的抽取设备,包括:
[0030]
识别模块,用于识别医疗文本中的医疗实体的类别,并将所述医疗文本拆分为单句;
[0031]
获取模块,用于针对每个类别,分别选择一个所述医疗实体结合所述单句形成句子输入预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;
[0032]
中间模块,用于将所述句子的向量以及对每个所述医疗实体名称的向量求平均后的值分别输入前馈神经网络,得到多个中间向量;
[0033]
输入模块,用于将多个所述中间向量进行拼接并接入全连接神经网络,并基于所述全连接神经网络中的softmax进行分类得到分类概率;
[0034]
确定模块,用于选择分类概率最大的关系类别作为所述医疗实体之间的最终关系。
[0035]
本发明的有益效果是:
[0036]
本方案采用预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;再给予前馈神经网络,得到多个中间向量接入全连接神经网络,得到分类概率;并基于分类概率确定医疗实体之间的最终关系,以此使用预训练的bert模型抽取实体的上下位语义特征,并将实体的类型加入对关系的预测,提高了识别的准确性。
附图说明
[0037]
图1为本发明实施例提供的一种实体关系的抽取方法的流程示意图;
[0038]
图2为本发明实施例提供的一种实体关系的抽取方法的流程示意图;
[0039]
图3为本发明实施例提供的一种实体关系的抽取设备的结构示意图;
[0040]
图4为本发明实施例提供的一种实体关系的抽取设备的结构示意图。
具体实施方式
[0041]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0042]
本发明实施例提供的一种实体关系的抽取方法,如图1或2所示,包括以下步骤:
[0043]
步骤101、识别医疗文本中的医疗实体的类别,并将所述医疗文本拆分为单句;
[0044]
具体的,所述医疗文本包括以下一个或多个的任意组合:医学教材、临床指南、病历。
[0045]
由此,步骤101中的所述“识别所述医疗文本中的医疗实体的类别”,包括:
[0046]
采用bert(bidirectional encoder representations from transformers,也即即双向transformer的encoder)和crf(conditional random field,条件随机场)的组合对所述医疗文本中医疗实体的类别进行识别。
[0047]
所述类别包括:疾病、检查、症状、治疗、药物。
[0048]
具体的,根据需要还可以设置有其他类别,并不限于以上这几种具体的类别。
[0049]
步骤102、针对每个类别,分别选择一个所述医疗实体结合所述单句形成句子输入预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;
[0050]
在所述句子中,每个所述医疗实体前均设置有所述医疗实体对应类别的标识;所述句子前设置句子的标识。
[0051]
例如疾病类别的标识为“&疾病”、检查类别的标识为“#检查”,整个句子的标识为“[cls]”。
[0052]
具体的,句子的标识与类别的标识不同,且不同类别的标识也不同。
[0053]
步骤103、将所述句子的向量以及对每个所述医疗实体名称的向量求平均后的值分别输入前馈神经网络,得到多个中间向量;
[0054]
具体的,所述句子的向量是通过以下公式确定的:
[0055]
h'
cls
=w
cls
(tanh(h
cls
))+b
cls
;
[0056]
其中,h'
cls
为所述句子的向量;w
cls
为所述句子的权重参数;h
cls
为所述句子;b
cls
为所述句子的偏置参数。
[0057]
以两个医疗实体,且分属不同类别的例子来进行说明,当所述医疗实体的数量为2个时;所述医疗实体名称的向量是通过以下公式确定的:
[0058]
[0059][0060]
其中,i
e1
,j
e1
,i
e2
,j
e2
分别为实体e1的首末字符位置和实体e2的首末字符位置;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量;w
e1
为实体e1的权重参数;w
e2
为实体e2的权重参数;b
e1
为实体e1的偏置参数;b
e2
为实体e2的偏置参数。
[0061]
步骤104、将多个所述中间向量进行拼接并接入全连接神经网络,并基于所述全连接神经网络中的softmax进行分类得到分类概率;
[0062]
仍以上述为例来进行说明,当所述医疗实体的数量为2个时;所述分类概率是通过以下公式确定的:
[0063]
p=softmax(w[concat(h'
cls
,h
e
'1,h
e
'2)]+b);
[0064]
p为分类概率;w为隐藏层的权重参数;b为隐藏层的偏置参数;h'
cls
为所述句子的向量;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量。
[0065]
步骤105、选择分类概率最大的关系类别作为所述医疗实体之间的最终关系。
[0066]
本方案将医疗文本中的医疗实体输入预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;再给予前馈神经网络,得到多个中间向量接入全连接神经网络,得到分类概率;并基于分类概率确定医疗实体之间的最终关系,以此使用预训练的bert模型抽取实体的上下位语义特征,并将实体的类型加入对关系的预测,提高了识别的准确性。
[0067]
在一个具体的实施例中,在识别医疗文本中的医疗实体的类别之前,还包括:获取医疗文本。
[0068]
在一个具体的例子中,如图2所示,本方案还包括如下步骤:
[0069]
1.搜集医疗文献,如医学教材、临床指南、病历等
[0070]
2.采用预训练模型bert+crf对步骤1中的医学文本进行医疗实体识别,并将文本拆分成单句,从单句中选择两类实体进行关系的识别,如疾病和检查
[0071]
3.对步骤2中两类实体每个类别分别任意选择一个实体进行两两组合,获得多个实体对e1和e2,每个实体对作为一次输入。对输入的句子使用一种特殊符号(如“&”和“#”)区分出两个实体,并且实体前加入实体类型。处理方式举例如下:
[0072]
[cls]&疾病&慢性阻塞性肺疾病&的急性加重常因微生物感染诱发,当合并细菌感染时,#检查#血白细胞计数#增高,中性粒细胞核左移
[0073]
4.将步骤3中处理的单句加入预训练bert模型,从bert的输出层抽取[cls]向量和两个实体名称的向量,并分别加入前馈神经网络,最后将更新后的三个变量拼接后接入全连接神经网络,通过softmax进行分类,方法如下:
[0074]
(1)[cls]接入前馈神经网络
[0075]
h'
cls
=w
cls
(tanh(h
cls
))+b
cls
[0076]
(2)分别对两个实体名称的向量求平均,并接入前馈神经网络
[0077]
[0078][0079]
其中;对实体名称的向量求平均是对该实体名称的每个字的向量求平均;i
e1
,j
e1
,i
e2
,j
e2
分别为实体e1的首末字符位置和实体e2的首末字符位置
[0080]
(3)将(1)和(2)获得的三个向量进行拼接并接入全连接神经网络,通过softmax获得分类概率,公式如下:
[0081]
p=softmax(w[concat(h'
cls
,h
e
'1,h
e
'2)]+b)
[0082]
5.基于步骤4的概率p,选择概率最大的关系类别作为实体e1和e2的最终关系。
[0083]
本方案中,使用预训练的bert模型抽取实体的上下位语义特征,并将实体的类型加入对关系的预测,有效提升了识别的准确性。
[0084]
实施例2
[0085]
本发明实施例2还公开了一种实体关系的抽取设备,如图3所示,包括:
[0086]
识别模块201,用于识别医疗文本中的医疗实体的类别,并将所述医疗文本拆分为单句;
[0087]
获取模块202,用于针对每个类别,分别选择一个所述医疗实体结合所述单句形成句子输入预训练bert模型,从所述bert模型的输出层得到所述句子的向量以及每个所述医疗实体名称的向量;
[0088]
中间模块203,用于将所述句子的向量以及对每个所述医疗实体名称的向量求平均后的值分别输入前馈神经网络,得到多个中间向量;
[0089]
输入模块204,用于将多个所述中间向量进行拼接并接入全连接神经网络,并基于所述全连接神经网络中的softmax进行分类得到分类概率;
[0090]
确定模块205,用于选择分类概率最大的关系类别作为所述医疗实体之间的最终关系。
[0091]
在一个具体的实施例中,如图4所示,还包括:
[0092]
文本模块206,用于在识别医疗文本中的医疗实体的类别之前,获取医疗文本。
[0093]
在一个具体的实施例中,所述医疗文本包括以下一个或多个的任意组合:医学教材、临床指南、病历。
[0094]
在一个具体的实施例中,所述识别模块201,用于:
[0095]
采用bert和crf的组合对所述医疗文本中医疗实体的类别进行识别。
[0096]
识别模块201,所述类别包括:疾病、检查、症状、治疗、药物。
[0097]
识别模块201,在所述句子中,每个所述医疗实体前均设置有所述医疗实体对应类别的标识;所述句子前设置句子的标识。
[0098]
识别模块201,所述句子的向量是通过以下公式确定的:
[0099]
h'
cls
=w
cls
(tanh(h
cls
))+b
cls
;
[0100]
其中,h'
cls
为所述句子的向量;w
cls
为所述句子的权重参数;h
cls
为所述句子;b
cls
为所述句子的偏置参数。
[0101]
识别模块201,当所述医疗实体的数量为2个时;所述医疗实体名称的向量是通过以下公式确定的:
[0102][0103][0104]
其中,i
e1
,j
e1
,i
e2
,j
e2
分别为实体e1的首末字符位置和实体e2的首末字符位置;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量;w
e1
为实体e1的权重参数;w
e2
为实体e2的权重参数;b
e1
为实体e1的偏置参数;b
e2
为实体e2的偏置参数。
[0105]
识别模块201,当所述医疗实体的数量为2个时;所述分类概率是通过以下公式确定的:
[0106]
p=softmax(w[concat(h'
cls
,h
e
'1,h
e
'2)]+b);
[0107]
p为分类概率;w为隐藏层的权重参数;b为隐藏层的偏置参数;h'
cls
为所述句子的向量;h
e
'1为实体e1的向量;h
e
'2为实体e2的向量。
[0108]
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1