一种基于判别共享邻域保持的极限学习机人脸降维方法
1.本发明属于生物特征识别系统领域,具体涉及一种基于判别共享邻域保持的极限学习机人脸降维方法。
背景技术:
2.伴随着人工智能、大数据时代的到来,人们需要在日常生活、经济贸易、信息登记和检验等场合验证身份信息。如今,身份认证技术已广泛应用于国家、社会的各领域,近年来,随着电子银行、线上商业、线上教育、智能门禁等模式的推广,人们对于保障身份信息的安全性愈来愈重视。传统的身份认证方法(如密码、身份证等)因其容易盗取、假冒,已无法满足人们对个人信息安全的需求。生物特征识别技术因其稳定高效、单一快速等优势在身份认证领域迅速崛起,已成为人工智能时代学者们研究的热点。用于识别的人类生物特征一般有:人脸、虹膜、掌纹、指纹和步态等,而人脸图像识别因其方便获取,具有丰富的信息和非接触性的优势,已成为了生物特征识别技术研究的焦点之一。然而,人脸数据往往呈现较高维的复杂几何结构,维度过高易造成维数灾难,导致人脸识别效果不理想。因此,对人脸数据进行有效降维具有十分重要的现实意义。
3.现有技术:一般,数据降维可以通过利用线性或者非线性变换将原始数据投影到一个合适的低维空间,同时尽量保持低维数据的几何关系不被改变。经典的线性降维方法有:主成分分析(pca)、线性判别分析(lda)、独立成分分析(ica)、局部保持投影(lpp)、邻域保持嵌入(npe)、稀疏保持投影(spp)等。线性降维方法有显式的映射表达,可解决out-of-sample问题,但对于本质结构为非线性的数据降维效果不好。为解决这一问题,许多非线性降维算法被提出,主要分为核函数降维方法和流形学习方法。代表性的核函数降维算法有:核主成分分析(kpca)、核线性判别分析(klda)、核独立成分分析(kica),hessian局部线性嵌入(hlle)等。核函数降维算法需要先验知识选取核函数类型,不同核函数的降维效果相差较大。局部线性嵌入(lle)和等距映射(isomap)都是经典的流形学习方法,没有显式的映射表达,无法解决out-of-sample问题,当有新样本加入时,需要重新训练算法参数,极大的限制了其实际应用。
4.2014年,huang等提出了一种具有显式表达的非线性降维算法
‑‑
无监督极限学习机(unsupervised extreme learning machine,us-elm)。us-elm计算高效、对新样本泛化性强,可以有效解决out-of-sample问题。2016年,peng等将流形学习思想引入到elm框架中,提出了基于图判别信息正则化的极限学习机算法(gelm)和一种判别流形极限学习机算法(dmelm),dmelm算法相较于gelm算法增加了判别信息,从而使得后者在处理人脸特征等流形非线性数据时具有更加良好的分类性能,也给elm算法的改进方向提供了一个新的分支。
5.上述现有技术的缺点:
6.1、线性降维技术无法挖掘、分析数据潜在的几何结构,对于具有低维流形的非线性高维数据,降维性能会大大降低。
7.2、核化线性降维和流形学习等非线性降维方法没有明确的显式映射表达式,无法解决样本外的问题,即新样本加入时,这些非线性降维模型需重新学习优化。
8.3、us-elm算法挖掘高维非线性数据样本点邻域信息能力差和无法考虑类别信息。
9.为此,我们提出一种基于判别共享邻域保持的极限学习机人脸降维方法,以解决上述背景技术中提到的问题。
技术实现要素:
10.本发明的目的在于提供一种基于判别共享邻域保持的极限学习机人脸降维方法,以解决上述背景技术中提出的问题。
11.为实现上述目的,本发明提供如下技术方案:一种基于判别共享邻域保持的极限学习机人脸降维方法,包括如下步骤:
12.s1、图像预处理:对人脸图像采集模块采集到的人脸图像进行尺度归一化处理;
13.s2、输入层:输入经过尺度归一化处理的人脸特征x;
14.s3、隐含层:选用非线性激励函数(sigmoid函数),将单样本人脸特征x随机非线性映射到n维特征空间,变换得到特征h(x);
15.s4、输出层:固定特征h(x),首先,选用经典的dijkstra算法来计算样本点间的测地距离,在测地距离中加入或减去带有权重的类别距离,得到基于判别信息的新的测地距离,对其进行升序排列;
16.然后,通过rank-order距离计算任意两个样本点间的共享的邻域信息,从而获得拥有判别信息的geodesic rank-order距离;
17.最后,归一化sgrd距离,利用其寻找出样本点的邻域,从而计算出样本点的稀疏邻域重构权值矩阵w
sgrd
;
18.设定输出特征t的维数m小于输入特征x的维数d,利用方程组求解方式得到隐含层和输出层的连接权值β,从而得到sgrd-elm降维输出模型为t=h(x)β;
19.s5、样本数据库:存储经过降维处理的人脸样本数据t。
20.所述步骤s3的实现具体如下:
21.步骤s31、设置隐含层神经元个数为l,l∈n
+
,n
+
代表正整数;
22.步骤s32、随机产生隐含层的输入权值矩阵a=[a1,a2,
…
,ai]
t
和隐含层阈值矩阵b=[b1,b2,
…
,bi]
t
,其中,i=1,2,
…
l,ai表示第i个隐含层节点的输入权值向量,bi表示第i个隐含层节点的阈值;
[0023]
步骤s33计算人脸特征x的第i个样本xi在隐含层的输出向量h(x)=[h1(x),h2(x),
…
,h
l
(x)]∈r1×
l
;
[0024]
其中x∈rd,hi(x)为第i个隐含层节点的输出特征,其表达式为:hi(x)=g(ai,bi,x),ai∈rd,bi∈r,其中,g(ai,bi,x)为隐含层节点的非线性激活函数,采用sigmoid函数,则
[0025][0026]
步骤s34计算人脸数据x在隐含层输出:
[0027][0028]
所述步骤s4的实现具体如下:
[0029]
步骤s41、构建邻接图g:
[0030]
首先,计算数据集x所有样本点间的欧式距离,即计算样本点xi与样本点xj之间的欧氏距离d
ij
=(xi,xj);
[0031]
其次,将计算得到的全局样本点间的欧氏距离d
ij
放到邻接图g,邻接图g中g(i,j)代表了样本点xi到样本点xj的欧式距离;
[0032]
最后,为了合理构建邻接图g,一般基于先验知识设定一个阈值δ;若g(i,j)小于阈值δ,g(i,j)的值保持不变;否则,g(i,j)的值定义为无穷;
[0033]
步骤s42、在邻接图g中,通过dijsktra算法计算数据集x内各样本点间的测地距离,获得所有样本点的测地距离矩阵dg;
[0034]
根据样本点的类别信息,对测地距离矩阵dg中的dg(i,j)作相应的修改;
[0035]
若dg(i,j)对应的两个样本点不属于同类,则dg(i,j)的值修改为:
[0036]dg
(i,j)=dg(i,j)+σmax(d);
[0037]
若dg(i,j)对应的两个样本点属于同类,则dg(i,j)的值修改为:
[0038]dg
(i,j)=dg(i,j)-σmin(d);
[0039]
其中,max(d)表示不同样本点的最大类间距离,min(d)表示同类样本点的最小类间距离,σ为距离权重参数,取值在0-1之间;
[0040]
对修改后的测地距离矩阵dg,作升序排列处理;
[0041]
任意两个样本点xi和xj之间rank-order距离的计算函数描述为:
[0042][0043]
其中,表示样本点xi的第k个近邻样本;代表了样本点xj在样本点xi的邻域列表中的位置,即xj是xi的第几个最近邻点;
[0044]
若任意两个样本点xi和xj之间非对称rank-order距离越小,则说明xi和xj的邻域结构越相似,即意味着它们在空间的真实距离越相近;
[0045]
步骤s43、计算得到对称且归一化的基于判别信息geodesic rank-order距离sgrd(xi,xj):
[0046][0047]
利用sgrd(xi,xj)找到样本点的近邻点,则重构权值矩阵w的计算公式为:
[0048][0049]
[0050]
将计算得到的全局重构权值矩阵w,作n*n维的稀疏变换便可得到稀疏邻域重构权值矩阵w
sgrd
,n为样本个数;
[0051]
步骤s44、基于判别共享邻域保持的极限学习机人脸降维模型:
[0052]
sgrd-elm的目标函数为:
[0053][0054]
s.t.(hβ)
t
hβ=im[0055]
其中,基于判别信息geodesic rank-order的图拉普拉斯矩阵l
sgrd
的计算公式为:
[0056]
l
sgrd
=d-w
sgrd
[0057]
目标函数第二项为基于判别信息和近邻共享信息的正则项,该项的作用是使得隐含层输出的人脸特征更好保持原数据的原始近邻结构,λ为正则项系数,tr(
·
)为矩阵的迹;
[0058]
同时,引入约束项s.t(h(x)β)
t
h(x)β=im解决模型求解出现平凡解的问题,i为单位矩阵;
[0059]
步骤s45、用拉格朗日乘子法对步骤4-4的模型进行求解,可得到最小的m个特征值及对应的特征向量a,从而计算出隐含层和输出层的连接权值β,β=h(x)
t
a;
[0060]
步骤4-6、当m小于d时,便可实现对人脸特征的降维,则该流形保持的显式降维模型为:t=h(x)β。
[0061]
与现有技术相比,本发明的有益效果是:本发明提供的一种基于判别信息和近邻共享的极限学习机人脸降维方法,本发明将磁鼓作为磁环压制胎芯,在磁环成型过程中实现磁环与磁鼓的紧密配合,通过该方案不仅可以避免对磁环内径与磁鼓外径的加工,而且省掉了磁环与磁鼓通过结构胶粘结固定的过程,达到了提高生产效率,降低生产成本的目的。
附图说明
[0062]
图1为elm的网络结构示意图;
[0063]
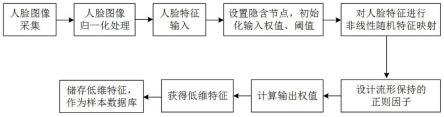
图2为本发明训练阶段的工作流程图;
[0064]
图3为本发明识别阶段的工作流程图。
具体实施方式
[0065]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0066]
实施例1:本发明提供了如图1-3的一种基于判别共享邻域保持的极限学习机人脸降维方法,训练阶段的工作流程如图2所示,步骤实现如下:
[0067]
s1、图像预处理:对人脸图像采集模块采集到的人脸图像进行尺度归一化处理;
[0068]
s2、输入层:输入经过尺度归一化处理的人脸特征x;
[0069]
s3、隐含层:选用非线性激励函数(sigmoid函数),将单样本人脸特征x随机非线性
映射到n维特征空间,变换得到特征h(x);
[0070]
s4、输出层:固定特征h(x),首先,选用经典的dijkstra算法来计算样本点间的测地距离,在测地距离中加入或减去带有权重的类别距离,得到基于判别信息的新的测地距离,对其进行升序排列;
[0071]
然后,通过rank-order距离计算任意两个样本点间的共享的邻域信息,从而获得拥有判别信息的geodesic rank-order距离;
[0072]
最后,归一化sgrd距离,利用其寻找出样本点的邻域,从而计算出样本点的稀疏邻域重构权值矩阵w
sgrd
;
[0073]
设定输出特征t的维数m小于输入特征x的维数d,利用方程组求解方式得到隐含层和输出层的连接权值β,从而得到sgrd-elm降维输出模型为t=h(x)β;
[0074]
s5、样本数据库:存储经过降维处理的人脸样本数据t。
[0075]
所述步骤s3的实现具体如下:
[0076]
步骤s31、设置隐含层神经元个数为l,l∈n
+
,n
+
代表正整数;
[0077]
步骤s32、随机产生隐含层的输入权值矩阵a=[a1,a2,
…
,ai]
t
和隐含层阈值矩阵b=[b1,b2,
…
,bi]
t
,其中,i=1,2,
…
l,ai表示第i个隐含层节点的输入权值向量,bi表示第i个隐含层节点的阈值;
[0078]
步骤s33计算人脸特征x的第i个样本xi在隐含层的输出向量h(x)=[h1(x),h2(x),
…
,h
l
(x)]∈r1×
l
;
[0079]
其中x∈rd,hi(x)为第i个隐含层节点的输出特征,其表达式为:hi(x)=g(ai,bi,x),ai∈rd,bi∈r,其中,g(ai,bi,x)为隐含层节点的非线性激活函数,采用sigmoid函数,则
[0080][0081]
步骤s34计算人脸数据x在隐含层输出:
[0082][0083]
所述步骤s4的实现具体如下:
[0084]
步骤s41、构建邻接图g:
[0085]
首先,计算数据集x所有样本点间的欧式距离,即计算样本点xi与样本点xj之间的欧氏距离d
ij
=(xi,xj);
[0086]
其次,将计算得到的全局样本点间的欧氏距离d
ij
放到邻接图g,邻接图g中g(i,j)代表了样本点xi到样本点xj的欧式距离;
[0087]
最后,为了合理构建邻接图g,一般基于先验知识设定一个阈值δ;若g(i,j)小于阈值δ,g(i,j)的值保持不变;否则,g(i,j)的值定义为无穷;
[0088]
步骤s42、在邻接图g中,通过dijsktra算法计算数据集x内各样本点间的测地距离,获得所有样本点的测地距离矩阵dg;
[0089]
根据样本点的类别信息,对测地距离矩阵dg中的dg(i,j)作相应的修改;
[0090]
若dg(i,j)对应的两个样本点不属于同类,则dg(i,j)的值修改为:
[0091]dg
(i,j)=dg(i,j)+σmax(d);
[0092]
若dg(i,j)对应的两个样本点属于同类,则dg(i,j)的值修改为:
[0093]dg
(i,j)=dg(i,j)-σmin(d);
[0094]
其中,max(d)表示不同样本点的最大类间距离,min(d)表示同类样本点的最小类间距离,σ为距离权重参数,取值在0-1之间;
[0095]
对修改后的测地距离矩阵dg,作升序排列处理;
[0096]
任意两个样本点xi和xj之间rank-order距离的计算函数描述为:
[0097][0098]
其中,表示样本点xi的第k个近邻样本;代表了样本点xj在样本点xi的邻域列表中的位置,即xj是xi的第几个最近邻点;
[0099]
若任意两个样本点xi和xj之间非对称rank-order距离越小,则说明xi和xj的邻域结构越相似,即意味着它们在空间的真实距离越相近;
[0100]
步骤s43、计算得到对称且归一化的基于判别信息geodesic rank-order距离sgrd(xi,xj):
[0101][0102]
利用sgrd(xi,xj)找到样本点的近邻点,则重构权值矩阵w的计算公式为:
[0103][0104][0105]
将计算得到的全局重构权值矩阵w,作n*n维的稀疏变换便可得到稀疏邻域重构权值矩阵w
sgrd
,n为样本个数;
[0106]
步骤s44、基于判别共享邻域保持的极限学习机人脸降维模型:
[0107]
sgrd-elm的目标函数为:
[0108][0109]
s.t.(hβ)
t
hβ=im[0110]
其中,基于判别信息geodesic rank-order的图拉普拉斯矩阵l
sgrd
的计算公式为:
[0111]
l
sgrd
=d-w
sgrd
[0112]
目标函数第二项为基于判别信息和近邻共享信息的正则项,该项的作用是使得隐含层输出的人脸特征更好保持原数据的原始近邻结构,λ为正则项系数,tr(
·
)为矩阵的迹;
[0113]
同时,引入约束项s.t(h(x)β)
t
h(x)β=im解决模型求解出现平凡解的问题,i为单位矩阵;
[0114]
步骤s45、用拉格朗日乘子法对步骤4-4的模型进行求解,可得到最小的m个特征值
及对应的特征向量a,从而计算出隐含层和输出层的连接权值β,β=h(x)
t
a;
[0115]
步骤4-6、当m小于d时,便可实现对人脸特征的降维,则该流形保持的显式降维模型为:t=h(x)β。
[0116]
识别阶段的工作流程如图3所示,步骤实现如下:
[0117]
步骤1图像预处理:对人脸图像采集模块采集到的待识别人脸图像进行尺度归一化处理;
[0118]
步骤2输入层:输入经过尺度归一化处理的待识别人脸特征x
′
;
[0119]
步骤3隐含层:随机初始化隐含层的输入权值矩阵a
′
和隐含层阈值矩阵b
′
,选用非线性激励函数(sigmoid函数),将待识别人脸特征x
′
随机非线性映射到n维特征空间,变换得到特征h(x
′
);
[0120]
步骤4输出层:定位训练阶段得到的隐含层和输出层的连接权值β,根据mp-elm降维输出模型t
′
=h(x
′
)β,得到降维处理的低维人脸特征t
′
;
[0121]
步骤5特征匹配识别:用最近邻分类器方法,将得到的低维特征t
′
与数据库样本t进行匹配识别,得到识别结果。
[0122]
本发明采用supervised geodesic rank-order距离作为样本点间的相似度的度量,对us-elm的高斯流形正则项进行改进,提出一种面向人脸特征识别的具有判别信息的极限学习机(sgrd-elm)降维方法。该方法的实现分两个阶段完成,第一阶段为训练阶段,目的是为保存训练好的输出权值,并为数据库存储经过降维处理的样本;第二阶段为识别阶段,对待识别样本随机初始化输入权值和阈值,用训练阶段训练好的输出权值进行特征降维处理,再与数据库样本进行匹配识别,得到识别结果。
[0123]
1、本发明中引入类内/类间参数对geodesic rank-order距离计算进行修改的方法,应在本发明的保护范围以内。
[0124]
2、本发明采用supervised geodesic rank-order距离作为人脸样本点间的相似度的度量,应在本发明的保护范围以内。
[0125]
3、本发明基于判别信息geodesic rank-order的图拉普拉斯矩阵l
sgrd
的计算方法,应在本发明的保护范围以内。
[0126]
4、本发明能够精准地拟合人脸数据的流形近邻结构,有效地剔除噪声以及流形外数据点的冗余,有提高识别精度、减少样本存储空间的优点,应在本发明的保护范围以内。
[0127]
本发明对人脸样本点间的相似度的计算做了改进,在此基础上,提出了sgrd-elm算法。sgrd-elm既考虑了样本的类别信息,又注重挖掘任意两个样本点的共享近邻信息,使得降维过程中,属于同类样本数据的距离更加紧凑,不同样本数据的距离更远,降维效果明显。
[0128]
本发明对人脸特征进行抗噪的非线性显式降维,该方法能够精准地拟合人脸数据的流形近邻结构,有效地剔除噪声以及流形外数据点的冗余,有提高识别精度、减少样本存储空间的优点。
[0129]
综上所述,与现有技术相比,本发明遵循elm算法经验风险最小化的原理,针对us-elm算法挖掘高维非线性数据样本点邻域信息差和未考虑类别信息的问题,本文采用supervised geodesic rank-order距离作为样本点间的相似度的度量,在此基础上,提出了sgrd-elm算法。sgrd-elm既考虑了样本的类别信息,又注重挖掘任意两个样本点的共享
近邻信息,使得降维过程中,属于同类样本数据的距离更加紧凑,不同样本数据的距离更远,降维效果更优于us-elm,又解决了现有的lle算法因无法求出显式映射函数,在面对人脸新样本时,出现的out-of-sample问题;本发明采用公开人脸图像数据集(orl人脸图像数据集)进行测试,orl人脸数据库是由剑桥大学at&t实验室收集整理的,该人脸库共有40人,每人各拥有10张不同的灰度人脸图像,图像是在不同时间、光照强度、不同拍摄角度的情况下,采用统一人脸采集设备获得,每张人脸图像包含了不同的脸部姿态、人脸形状、面部表情、面部装饰等特征信息。在样本数据降维到64维的情况下,实验结果对比lle方法的人脸识别率平均提高了10%-14%,对比了us-elm方法的人脸识别率平均提高了6%-8%。
[0130]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1