一种基于FPGA卷积神经网络结构的光学像差畸变校正系统的制作方法
本发明涉及光学技术领域,具体是一种基于fpga卷积神经网络结构的光学像差畸变校正系统。
背景技术:
大气中的湍流效应会导致光在大气中传输时出现光强起伏、光斑漂移等。这些效应会导致激光远场传输时激光传输能量集中度下降,导致光学成像系统分辨力下降。提高激光系统的光束质量、改善光学成像系统的分辨能力需要对大气湍流导致的像差畸变进行校正。
卷积神经网络可以通过对包含有湍流像差信息的目标成像与湍流像差畸变信息进行学习,实现通过对目标成像信息获取而得到湍流像差畸变信息,从而实现对湍流像差畸变的校正。但卷积神经网络计算量较大,难以满足大气湍流造成的高频相位畸变的要求。
技术实现要素:
本发明的目的在于克服现有技术卷积神经网络计算量较大,难以满足大气湍流造成的高频相位畸变的要求的不足,提供了一种基于fpga卷积神经网络结构的光学像差畸变校正系统,利用光学成像系统对经过大气湍流后的目标直接成像,通过fpga卷积神经网络对目标成像进行特征分析,计算并提取大气湍流造成的畸变相位信息,用于对大气湍流造成的光学波前像差畸变校正,本发明的fpga卷积神经网络结构具有功耗低、运行速度快、效率高等优点。
本发明的目的主要通过以下技术方案实现:
一种基于fpga卷积神经网络结构的光学像差畸变校正系统,包括探测相机、校正组件和fpga卷积神经网络模型,所述探测相机为cdd相机,所述校正组件包括变形镜、凸透镜和半透半反镜;所述fpga卷积神经网络模型包括卷积模块、非线性函数sigmoid模块、池化模块、中间量存储模块、全连接层模块,数据通过卷积模块和池化模块进行卷积运算和池化运算,各层之间通过非线性函数sigmoid模块实现激活连接。
本技术方案不依赖光学信标和波前传感器,通过建立面向大气湍流这一真实物理过程的深度神经网络,通过光学系统对目标直接成像,实现波前传感与校正,最终实现波前像差的探测与重构。本技术方案采用fpga卷积神经网络模型,利用卷积模块进行卷积运算,;非线性函数sigmoid模块用于实现卷积神经网络中的sigmoid函数;池化模块用于将卷积层的输出进一步池化,实现特征输出的维度降低;中间量存储模块用于存储卷积神经网络计算中的中间变量;全连接层模块用于实现卷积神经网络感知机的计算功能,实现输出。
需要说明的是本技术方案的光学像差畸变校正系统中探测相机实现对目标物体的探测成像;校正组件主要实现对大气湍流的像差畸变进行补偿,fpga为载体实现了卷积神经网络模型,通过计算探测相机采集的图片,采用深度神经网络模型计算出变形镜的控制电压;探测相机为2048×2048像素,帧频90fps,变形镜为压电可变形反射镜,包含40个促动器,最高刷新率为4khz,包含10mm光瞳直径的反射镜,有保护层的银膜,最高刷新率为4khz。
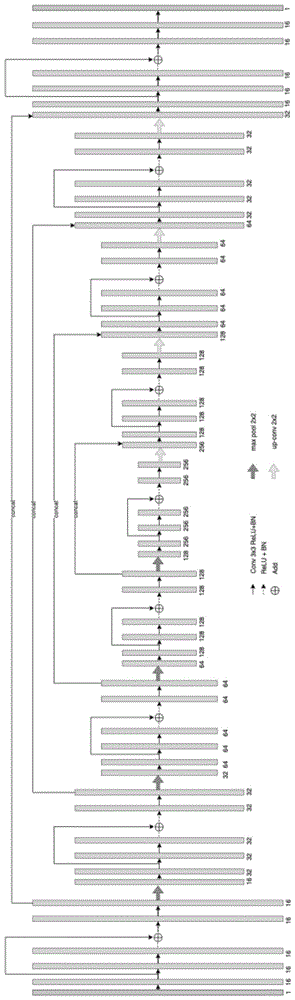
进一步的,fpga卷积神经网络模型的网络结构分为9层,每层都包含依序连接的3个卷积模块、1个位加模块和1个卷积模块,每层的不同的模块之间通过池化或插值的方式进行连接。
本技术方案设计的fpga卷积神经网络模型包含9个不同的处理层,不同的层之间通过池化或插值的方式进行连接,通过对每层的计算性能分析后发现,当本技术方案系统工作频率为200mhz,则该系统的处理帧频为:200m/636315=314fps,当工作频率300mhz,则为:471fps。工作频率320mhz以上时,可达到:502fps,其计算速度明显加快。需要说明的是,本技术方案的每层的内部各操作层可以实现完全并行。优选的,本技术方案中第1层和第9层的卷积模块包含16个通道,第2层和第8层的卷积模块包含32个通道,第3层的卷积模块包含64个通道,第4层和第6层的卷积模块包含128个通道,第5层和第7层的卷积模块包含256个通道。
进一步的,所述fpga卷积神经网络模型的第1~4层为下采样层,第5层为桥接层,第6~9层为上采样层,上采样通过转置卷积实现,中间层经过一次上采样操作,尺寸扩大为前一层的一倍,同时控制其通道数减少一半;第1~5层通过最大池化连接,第6~9层通过上卷积连接,第1~4层和第6~9层通过残差一一对应连接,并将下采样过程中的部分中间层复制到上采样层中,参与上采样过程,第6~9层的输出经过一次卷积操作后,得到最终的输出图像。
进一步的,在最大池化和下采用过程中,每次从4个像素中确定一个最大的作为结果;在上采用过程中采用行缓冲的结构,通过相邻像素的计算得到所需的结果。
本技术方案对于最大池化或下采样的操作,通过4输入比较器的方式,每次从4个像素中确定一个最大的作为结果;对于上采样,采用类似卷积行缓冲的结构,通过相邻像素的计算得到所需的结果。优选的,通过设置比较器进行relu操作,bn可以通过查找表的方式加以解决。
进一步的,所述卷积模块由3个长度为28的行寄存器、3个长度为12的行寄存器和3×3的乘加阵列组成。
本技术方案卷积模块的行寄存器首尾相连,且尾部都是通过数据选择器连接到乘加阵列的一行。乘加阵列的每个结构单元均含有2个寄存器、1个乘法器,2个寄存器分别存储的是卷积核的一个元素和输入图像的一个像素。该结构可以完成当输入分别为大小28×28和12×12的图像时,卷积核大小为3×3的卷积运算。
进一步的,非线性函数sigmoid模块将自变量对应的sigmoid函数值预先存储在rom或ram中,其中自变量作为地址输入,函数值作为这个模块的输出,以实现sigmoid函数。
进一步的,所述池化模块由2个长度为24的行寄存器、2个长度为8的行寄存器和2×2的乘加阵列组成。
本技术方案池化模块的行寄存器首尾相连,且尾部都是通过数据选择器连接到乘加阵列的一行。乘加阵列的每个结构单元均含有2个寄存器、1个乘法器,2个寄存器分别存储的是卷积核的一个元素和输入图像的一个像素。该模块可以将24×24的输出特征图池化为12×12的特征图,也可以将8×8的输出特征图池化为4×4的特征图。
进一步的,中间量存储模块用来存储每个池化模块产生的结果,并在卷积模块连接状态变化之后,将暂存的中间结果重新读出,输入给变化后的卷积模块。
本技术方案中间量存储模块是用来存储卷积神经网络计算过程产生的中间变量的,包括ram以及ram_control,ram用于数据存储,ram_control用于控制模块的存储。该模块存储是每个池化层之后产生的结果,并且在状态变化,即卷积模块连接变化之后,将暂存的中间结果,重新读出,输入给变化后的卷积模块。
进一步的,全连接层模块包括10个乘累加器,将数据与权重参数对应的输入全连接层模块,使用10个乘累加器,经过192个时钟周期后即可得到全连接层模块的输出结果。
本技术方案全连接层用于实现卷积神经网络中的单层感知机的计算功能,完成192个输入和10个输出之间的全连接。将数据与权重参数对应的输入,使用10个乘累加器,经过192个时钟周期后即可得到全连接层的输出结果。因为10个乘累加的结果都需要经过sigmoid函数,为了节约资源,只是用一个sigmoid模块。因此需要将10个乘累加结果暂存,串行的输入给sigmoid模块,最后全连接层也是串行的输出10个结果。
进一步的,所述系统中输入图像的卷积计算采用3x3循环的并行计算结构,所述并行计算结构包含3个行缓冲,每个行缓冲后分别设有3个寄存器,当输入图像经1个行缓冲输入后,3个行缓冲预取3行的待处理数据,每个行缓冲后的3个寄存器对该行缓冲输出数据的前3个像素进行同时访问,将9个寄存器的输出结果合并;在数据处理过程中,3个行缓冲连续预取待处理数据,通过像素移位及合并9个寄存器的所有输出结果,通过,即得到输入图像的卷积计算结果。
由于fpga资源的限制,不可能对上述的网络架构实现全流水的硬件。发明人通过研究后发现,相比在网络结构上实现全流水的硬件,在fpga内实现一层,甚至一层中的部分计算所需的硬件架构,更多的计算通过硬件复用的方式进行是更行之有效的方法。本技术方案的fpga卷积神经网络模型中大量采用了卷积计算,而且所有的卷积核都是3x3的,如果按照通用cpu上的串行计算方式,每个像素点的卷积都需要一个3x3的循环才能完成,计算时间长。为此本技术方案的fpga卷积神经网络模型在卷积计算过程中采用并行计算结构,使每个卷积所涉及的9个乘法同时进行,而且根据资源的情况,多个通道的卷积也可以同时进行。例如,1个输入图像与16个通道的卷积核进行卷积运算并生成16个结果,如果串行操作,需要128*128*3*3*16=2359296次计算的时间,而采用本技术方案的并行计算结构,16个通道并行,则大约需要128*128+128*2=16640次计算的时间,在相同工作频率下通过本技术方案的并行计算将时间缩短了141倍左右。此外,本技术方案还通过流水结构的设计确保在计算完一个像素所对应的卷积之后,能够连续输出后续像素所对应的卷积值。即在流水线充满时每个节拍可以输出一个卷积计算结果;通过设计3个行缓冲可以将3行的待处理数据预取到位,再结合9个寄存器对每行的前3个像素进行同时访问,可以使得在每次进行一个像素的移位后都能拿到9个所需的像素值供下一个卷积操作,通过这样的结构,在经过一个流水线充满的延迟后,就可以连续地输出卷积结果。此外,在不同的层,以及每层的不同子层之间都可以设计适合的结构使其可以充分流水,从而提升整体的处理性能。在所述系统在并行计算结构后,还包括数据重排,所述系统还包括片外存储器,输入图像的卷积计算结果存储在片外存储器中,并在片外存储器中进行数据重排;由于fpga片内资源的限制,计算的中间结果必须要写回到片外存储器,下一级计算再从片外存储器读取;由于上述并行结构的设计,所需读进的数据可能不是需要一个完整的图片/数据接着一个完整的图片/数据,而是同时需要多个图片/数据的同一部分;因此通过数据的重排,可以使要同时处理的数据在存储空间上排放在一起,便于一次性的读取。
综上所述,本发明与现有技术相比具有以下有益效果:
1、本发明不依赖光学信标和波前传感器,通过建立面向大气湍流这一真实物理过程的深度神经网络,通过光学系统对目标直接成像,实现波前传感与校正,最终实现波前像差的探测与重构;本发明采用fpga卷积神经网络模型,利用卷积模块进行卷积运算,;非线性函数sigmoid模块用于实现卷积神经网络中的sigmoid函数;池化模块用于将卷积层的输出进一步池化,实现特征输出的维度降低;中间量存储模块用于存储卷积神经网络计算中的中间变量;全连接层模块用于实现卷积神经网络感知机的计算功能,实现输出。
2、本发明的fpga卷积神经网络模型在卷积计算过程中采用并行计算结构,使每个卷积所涉及的9个乘法同时进行,而且根据资源的情况,多个通道的卷积也可以同时进行;通过流水结构的设计确保在计算完一个像素所对应的卷积之后,能够连续输出后续像素所对应的卷积值。在不同的层,以及每层的不同子层之间都可以设计适合的结构使其可以充分流水,从而提升整体的处理性能。。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为本发明的fpga卷积神经网络模型;
图2为本发明的卷积计算的并行计算结构。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例1:
如图1和图2所示,本实施例包括探测相机、校正组件和fpga卷积神经网络模型,所述探测相机为cdd相机,所述校正组件包括变形镜、凸透镜和半透半反镜;所述fpga卷积神经网络模型包括卷积模块、非线性函数sigmoid模块、池化模块、中间量存储模块、全连接层模块,数据通过卷积模块和池化模块进行卷积运算和池化运算,各层之间通过非线性函数sigmoid模块实现激活连接。
优选的,fpga卷积神经网络模型的网络结构分为9层,每层都包含依序连接的3个卷积模块、1个位加模块和1个卷积模块,每层的不同的模块之间通过池化或插值的方式进行连接。
优选的,所述fpga卷积神经网络模型的第1~4层为下采样层,第5层为桥接层,第6~9层为上采样层,上采样通过转置卷积实现,中间层经过一次上采样操作,尺寸扩大为前一层的一倍,同时控制其通道数减少一半;第1~5层通过最大池化连接,第6~9层通过上卷积连接,第1~4层和第6~9层通过残差一一对应连接,并将下采样过程中的部分中间层复制到上采样层中,参与上采样过程,第6~9层的输出经过一次卷积操作后,得到最终的输出图像。
优选的,在最大池化和下采用过程中,每次从4个像素中确定一个最大的作为结果;在上采用过程中采用行缓冲的结构,通过相邻像素的计算得到所需的结果。
优选的,所述卷积模块由3个长度为28的行寄存器、3个长度为12的行寄存器和3×3的乘加阵列组成。
优选的,非线性函数sigmoid模块将自变量对应的sigmoid函数值预先存储在rom或ram中,其中自变量作为地址输入,函数值作为这个模块的输出,以实现sigmoid函数。
优选的,所述池化模块由2个长度为24的行寄存器、2个长度为8的行寄存器和2×2的乘加阵列组成。
优选的,中间量存储模块用来存储每个池化模块产生的结果,并在卷积模块连接状态变化之后,将暂存的中间结果重新读出,输入给变化后的卷积模块。
优选的,全连接层模块包括10个乘累加器,将数据与权重参数对应的输入全连接层模块,使用10个乘累加器,经过192个时钟周期后即可得到全连接层模块的输出结果。
优选的,所述系统中输入图像的卷积计算采用3x3循环的并行计算结构,所述并行计算结构包含3个行缓冲,每个行缓冲后分别设有3个寄存器,当输入图像经1个行缓冲输入后,3个行缓冲预取3行的待处理数据,每个行缓冲后的3个寄存器对该行缓冲输出数据的前3个像素进行同时访问,将9个寄存器的输出结果合并;在数据处理过程中,3个行缓冲连续预取待处理数据,通过像素移位及合并9个寄存器的所有输出结果,通过,即得到输入图像的卷积计算结果。
本实施例图1中conv3x3relu+bn为3x3卷积模块及激活函数,relu+bn为激活函数,add为加法,maxpool2x2为2x2的最大池化,up-conv2x2为2x2的上卷积;图2中reg为寄存器,buffer为缓存,mul表示乘,h11、h12、h13、h21、h22、h23、h31、h32和h33分别为9个寄存器内存储的数据,k11、k12、k13、k21、k22、k23、k31、k32和k33分别为与9个寄存器内数据分别相乘的数据,add为加法。非线性函数sigmoid模块的激活函数为relu+bn。
本实施例提供的基于fpga卷积神经网络结构的光学像差畸变校正系统,其工作过程如下:
s1,建立基于深度学习训练目标图像和像差畸变的fpga卷积神经网络模型;
s2、fpga卷积神经网络模型构建完成后,将原始目标成像图和经过湍流畸变后的目标成像图作为fpga卷积神经网络模型输入,将大气湍流相位畸变作为fpga卷积神经网络模型输出;
s3、波前校正器将驱动信号加载到波前校准器的各个驱动上,使波前校正器产生与待校正波前共轭的变形量以校正大气湍流畸变所导致的波前的像差,完成待校正波前的校正;
s4、fpga卷积神经网络的训练集采用主控计算机利用液晶相位屏加载低价zernike系数生成的用于描述kolmogorov湍流谱的相位畸变作为网络输出,并将相位畸变加载到目标成像光路中,得到目标的模拟湍流畸变成像图和原始的目标成像图作为输入;
s5、fpga卷积神经网络在训练时采用随机梯度下降算法,通过降低损失函数的函数值来学习建立后的所述卷积神经网络的参数;损失函数为:
式中,nx和ny分别表示x和y方向的像素数,yij表示实际加载的相位屏在坐标(i,j)处的像素值,
对输入图像的卷积计算结果进行数据重排方法为:
s1、获取所有待重排的卷积计算结果,按照预设的行数m和列数n,建立mxn的基础数据合集;
s2、取基础数据合集中的任一卷积计算结果作为目标对象,将目标对象与基础数据合集中的所有数据一一进行相似度计算;
s3、将基础数据合集中相似度计算结果大于预设值的卷积计算结果的合集建立为目标对象的相似数据合集;
s4、提取所有卷积计算结果的相似数据合集的特征信息,建立特征信息合集;
s5、得到基础数据合集和特征信息合集的映射关系;
s6、将特征信息合集生成多个二维数据重排路径,从多个二维数据重排路径中筛选出具有最短重排元素距离的最优数据重排路径,根据最优数据重排路径对特征信息合集进行重排;
s7、依据基础数据合集和特征信息合集的映射关系,及特征信息合集重排结果对基础数据合集进行数据重排。
上述数据重排方法,通过建立础数据合集,并进行相似度计算,去除了无关信息的干扰,通过提取特征信息,减少了参与匹配计算的图像数据量,在保证有效信息完整获取的情况下减少图像处理过程中的冗余数据,实现保证准确率条件下检测速度的提高。
为了验证本实施例提供的光学像差畸变校正系统对光学像差畸变的处理效果,发明人对系统的fpga卷积神经网络模型计算性能进行了分析,由于网络结构中不同的层之间通过池化或插值的方式进行连接,所以可以首先分析每层的计算性能,假定每层的内部各操作层可以实现完全并行,每层的分析如下:
第一层:输入数据大小128x128,若完全并行后,所需的乘法器(multiplier)、加法器(adder)和缓存(buffer)数量如下:
1-1:1conv16:multiplier:9x16=144、buffer:128x3=384b、adder:8x16=128
cyclestoprocess(处理周期):由于16个通道的卷积可以同时进行,而且卷积时9个乘法可以同时进行,因此在经过一定的延迟,第一批16个结果出来后,就可以每个cycle(周期)出16个结果了,可以计算出、这层操作的时间为:(128x2+15)+128x128=16655cycles
1-2:16conv16:multiplier:9x16x16=2304、buffer:128x3x16=6144、adder:8x16x16=2048
cyclestoprocess(处理周期):由于16个数据的16个通道的卷积可以同时进行,而且卷积时9个乘法可以同时进行,因此在经过一定的延迟,第一批16个结果出来后,就可以每个cycle出16个结果了,可以计算出、这层操作的时间约为:(128x2+19)+128x128=16659cycles
1-3:16conv16:multiplier:9x16x16=2304、buffer:128x3x16=6144、adder:8x16x16=2048
cyclestoprocess(处理周期):(128x2+19)+128x128=16659cycles
1-4:adder:16
cyclestoprocess(处理周期):此次做的操作时2个数据的点对点加法操作,通过设计,可以将这层操作与1-3组合起来,仅增加1-2个cycles即可完成。
1-5:16conv16:multiplier:9x16x16=2304、buffer:128x3x16=6144、adder:128x16=2048
cyclestoprocess(处理周期):(128x2+19)+128x128=16659cycles
若fpga具有的各类资源如下:slc:600;memory:32mb;dsp:2520个;i/o:328个,其中每个dsp可以实现一个25bitx18bit的乘法器,因此需要对网络参数进行量化操作。由于dsp数量的限制,layer1无法完全实现流水方式。因此按照每个乘法器可以完成1个卷积所需的乘法计算,如果各内部层之间不考虑进一步的流水化,则第一层所需的操作时间约为:16655+16659+16659+16659=66632cycles。
第二层:是在第一层基础上经过池化得到,输入数据大小64x64,即为layer1的1/4大小。
2-1:16conv32:multiplier:9x16x32=4608、buffer:64x3x16=3072、adder:8x16x32=4096
cyclestoprocess(处理周期):这层如果要全并行,需要4608个乘法器,超出了fpga的资源,因此需要复用,通过2轮使用完成操作,而这2轮是可以流水的,因此处理时间:
(64x2+15)+(64x64)+(64x64)=8335cycles
2-2:32conv32:multiplier:9x32x32=9216、buffer:64x3x32=6144、adder:8x32x32=8192
cyclestoprocess(处理周期):这层如果要全并行,需要9216个乘法器,超出了fpga的资源,因此需要复用,通过4轮使用完成操作,而这4轮是可以流水的,因此处理时间:
(64x2+15)+(64x64)x4=16527cycles
2-3:32conv32:multiplier:9x32x32=9216、buffer:64x3x32=6144、adder:8x32x32=8192、cycles:16527cycles
2-4:adder:32
cyclestoprocess(处理周期):此次做的操作是2个数据的点对点加法操作,通过设计,可以将这层操作与2-3组合起来,仅增加1-2个cycles即可完成。
2-5:32conv32:multiplier:9x32x32=9216、buffer:64x3x32=6144、adder:8x32x32=8192、cycles:16527cycles
由于dsp数量的限制,第二层无法完全实现流水方式。因此按照每个乘法器可以完成1个卷积所需的乘法计算,如果各内部层之间不考虑进一步的流水化,则第二层所需的操作时间约为:8335+16527+16527+16527=57916cycles。
同理:可计算出:第三层:57660cycles;第四层:57532cycles;第五层:不超过57532cycles;第六层:32956+49293=82249;第七层:24813+49389=74202;第八层:33340+49581=82921;第九层:16655x2+16659x3=83287;整体时间估算:第1~9层:636315cycles
如果设计完成的系统工作频率为200mhz,那么该系统的处理帧频为:200m/636315=314fps;如果工作频率300mhz,则为:471fps。工作频率320mhz以上时,可达到:502fps。
通过以上分析,说明采用本实施例的系统具有优异的性能;以上的分析仅考虑了对浮点数的定点化操作,但没有改变网络模型。如果对各层之间再进行流水设计,以及进一步提升工作频率,有望达到500fps的要求。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!