基于轨迹数据挖掘的城市语义图谱构建方法
本发明属于轨迹计算技术领域,具体涉及一种构建成城市语义图谱的方法。
背景技术:
对城市区域的功能描述与对应的人流行为阐释,一直是一项极具有应用前景和商业价值的技术。该类技术将人流源数据与语义源数据进行融合分析与数据挖掘,构建并输出一个针对城市各区域功能描述的数据结构,这种数据结构可以称为城市语义图谱。在本发明中,城市语义图谱被定义为是针对城市各细粒度区域进行功能描述的数据结构。它可以实现对城市不同地点的人类行为识别,比如购物、教育和医疗等等,这种对城市区域的描述称为语义信息。人流源数据主要指gps轨迹数据集或社交网络的地理位置签到数据等,语义源数据主要包括语义兴趣点(poi)数据集,街区位置数据集,社区网格位置数据集。该技术通过融合分析这两类数据源,得到城市语义信息,这种对人流行为分析和区域功能描述的语义信息对市政规划、交通建设和商业推广有巨大价值。比如通过城市语义信息得到目前人群高频次消费零售的主要区域,针对这些区域政府可以规划更多的沿街店铺区、商住两用楼和其他商业配套设置;又比如通过城市语义信息得到通勤人群的高频居住区域和工作区域之间的联动关系,针对性地配套更多的公交线路,地铁站和消费场所等。
目前来看,城市语义分析技术主要分为两种形式:
(1)针对街区或网格的固定构型语义信息构建技术:固定构型语义信息构建技术主要针对城市街区或者空间网格这种地理形状有预先定义并固定不变的语义源数据进行分析,将人流源数据匹配到对应地理位置的街区或者网格,然后进行聚合汇总,得到粗粒度的整体区域功能描述。该种技术较为传统经典,用于可视化宏观分析场景较多。
(2)针对细粒度语义兴趣点(poi)的不定构型语义信息构建技术:不定构型语义信息构建技术往往将海量的语义兴趣点poi先进行基于空间位置的组合,得到不定形状的poi散点集合。然后结合对人流源数据的匹配分析,最终得到细粒度的非预先定义地理形状的区域行为分析结果。该种技术较为新颖灵活,属于目前少有的非人工预定义的数据驱动策略。
比较两类技术,可以看出固定构型语义构建适合大尺度宏观层面的城市语义信息分析,由于其描述的空间区域是比如街区和网格这些预先定义固定形状的数据,语义分析的结果受到地理形状的局限较大,得到的信息量较小,缺乏灵活性与普适性。且其语义分析结果往往与预先发布的城市规划方案重合性较大,获得到的新信息不足。而不定构型语义构建技术利用散点聚类方法克服了上述诸多不利因素,其得到的最终结果具有细粒度的微观尺度,具有更大的信息量和更高的普适性,对市政规划、交通建设和商业推广的决策支持也更有价值。
本发明提供一种城市语义图谱构建方法,属于不定构型语义信息构建技术。其针对poi散点的多重聚集和迭代拆解过程可以完美匹配人流数据的迁移和聚集形态,高度融合并反映了人流移动聚集规律。在实际应用中具有空间粒度细且语义数量多的先进优势。
技术实现要素:
本发明克服了固定构型语义信息构建技术的局限性,提供一种基于轨迹数据挖掘的针对语义兴趣点(poi)组合构建城市语义图谱的方法,以克服现有技术的不足。
本发明提出的基于轨迹数据挖掘的城市语义图谱构建方法,是通过轨迹数据挖掘将语义兴趣点(pointofinterest,简称poi)数据进行转化,具体步骤分为如下四个阶段:
(一)预处理阶段:对轨迹数据进行位置与时间判定,寻找驻留点;随后对轨迹数据进行精简,只保留驻留点;
具体地,对轨迹数据进行位置与时间判定,寻找在连续的30分钟时间以上的,位置变动在50m距离内的gps点,这些点的几何中心位置定义为驻留点(staypoint),认定为出行者在此地活动,到访了附近的poi点;
(二)聚类阶段:根据预处理阶段处理好的驻留点对临近poi点进行到访频次计数,利用频次计数、邻域密度和语义类别对poi点进行基于密度的带额外判定条件的dbscan聚类;
具体步骤为:
步骤(1),利用驻留点位置,对附近每个poi点做到访频次计数;对于每个poi点pi,其到访频次定义为:
即根据gps的分布误差符合二维高斯分布的特点,定义三倍标准差距离r3σ,利用所有距离pi点r3σ以内的驻留点sp累计频次,d(sp,pi)指两点之间的距离;频次采用高斯分布系数进行描述,符合越近到访概率越大的客观规律;
步骤(2),利用poi点的频次计数、邻域密度和语义类别对poi点进行密度聚类。采用数据挖掘领域经典的dbscan聚类算法为基础稍作改进,对所有poi点进行聚类。在dbscan聚类算法的扩充聚类阶段加入若干判定条件,当判定条件为真时,才允许执行加入新点到当前聚类集合。该条件定义如下:对于当前聚类集合的代表元pi,其临近的点
其中,
(三)纯化阶段,根据聚类阶段得到的大量聚类进行内部语义纯净度校验;对于纯净度不足的,进行迭代的二分裂操作,直到得到多个纯净的小聚类为止。具体地,对于每个聚类而言,执行以下步骤:
步骤(1)、校验;对于该聚类c0,对内部每个poi点进行语义类别校验和空间分布校验,只要通过任意一项,即可认为是纯净聚类,直接结束无需执行后续步骤。其中:
语义类别校验指
空间分布校验指
步骤(2)、描述;对于无法通过校验步骤的聚类,对内部每个点的语义类别分布概率进行描述,该概率分布代表每个聚类内部每个poi点局部位置的语义类别组成占比。对于任意点
即每一种语义类别占比被定义为该类别其余点到该点的到访频次计数在所有类别的计数总和中的占比。
步骤(3)、分裂;选择聚类内部最邻近几何中心的poi点作为代表点,比较其他点和代表点语义类别分布概率之间的差值距离,差值距离从小到大排序,以中位数作为划分线而分裂原聚类,形成两个较小的聚类。其中差值距离较小的点组成的新聚类比原先的旧聚类更为语义纯净。对于任意的
步骤(4)、迭代;对于分裂步骤产生的两个新聚类分别重复前3个步骤,进行循环迭代。
(四)重组阶段,对于纯化阶段产生的大量新聚类通过外部语义比较进行聚类合并。具体步骤为:
步骤(1),计算每个聚类的整体外部语义类别概率分布。对于任意聚类ui而言,其整体外部语义类别概率分布定义为:
即每类别点的驻留点到访频次在总频次中的占比。
步骤(2),将所有外部语义类别概率分布的余弦相似度大于阈值β且彼此几何中心距离在r3σ内的聚类对进行两两合并重组,不断逐次比较,直到将所有合并重组都执行完成。
其中,余弦相似度定义为:
prod(ui,uj)为任意聚类ui,uj的点乘:
上述四个阶段全部执行完成后,所形成的聚类集合称之为城市语义图谱。图谱内包含大量的结构紧凑且语义信息纯净的聚类。每个聚类的语义信息可以视为对该区域内城市功能的描述和对人流数据的行为分析结果。可以结合新采集的轨迹数据集,提取其中的驻留点,对每个驻留点进行城市语义图谱的空间覆盖查询或者最近邻查询,即可获取该点的语义信息,并最终将轨迹点序列转化成语义标签序列。
本发明高度融合并反映了人流移动聚集规律,作为一种不定构型语义信息构建技术展现了人群聚集活动在城市范围内的行为复杂性与空间规律性。与其他方法相比可以得到更加细粒度且数量更多的城市区域的语义类别信息,具有空间粒度细且语义数量多的先进优势。作为一种非人工干预的数据驱动方法具有广泛的应用前景。
附图说明
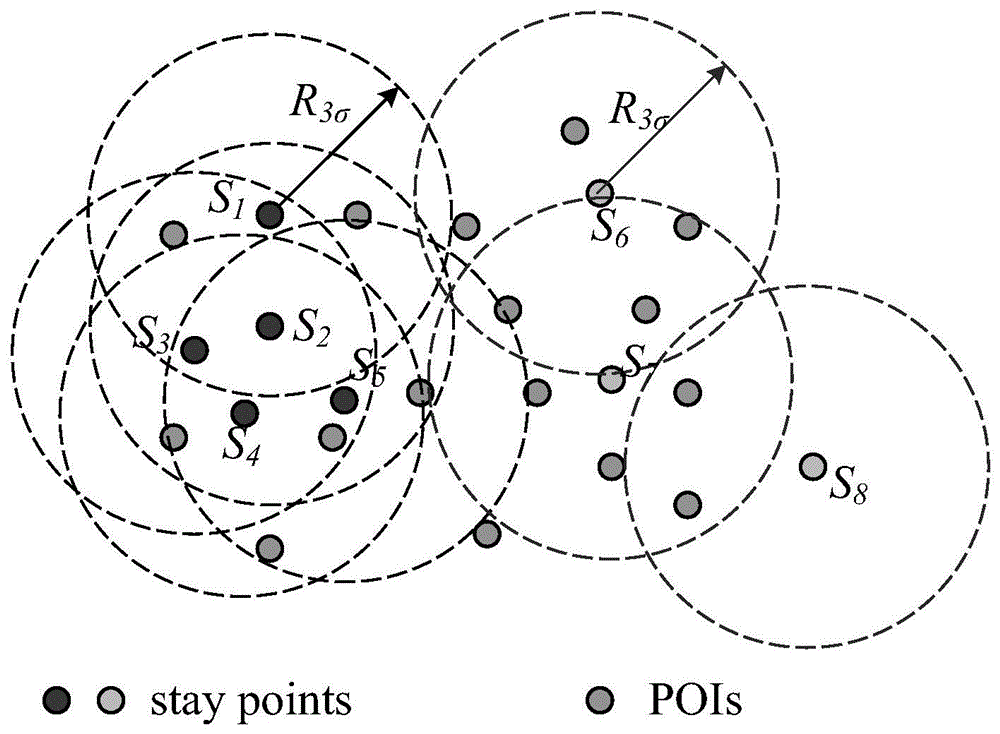
图1为预处理阶段图示。其中,s1到s8这8个点是从预处理阶段中采集到的驻留点(staypoints),其余的点都是poi点。所有驻留点以r3σ为搜索半径将覆盖范围内的poi点进行到访频次加权计数。
图2为聚类阶段图示。其中,p1到p16这16个点是图1中除8个驻留点以外的所有poi点,这些点的语义类别分为三类:shop,restaurant,office,可由图3得知其对应种类归属。经过聚类阶段以后分成三个聚类,其中两个大聚类用虚线圈出,剩余p16由于过于较为远离驻留点和其他poi点单独成一类。
图3为纯化阶段图示。其中,所有标有shop,restaurant和office标签的点都是图2中对应的poi点,表示各自语义类别。经过纯化阶段又细分为四类,其中箭头指向的restaurantunit和officeunit由图2中右侧虚线圈出的大聚类分裂而来,其余保持不变。
图4为重组阶段图示。其中,三个虚线圈出的聚类是由图3中四个细分聚类经过重组阶段合并得到,其中officeunit吞并了临近的单独成类且语义类别相同的p16。
具体实施方式
下面结合具体实例和附图进一步说明本发明:
一预处理阶段:
通过位置与时间判定,发现轨迹数据集中有8组点是在连续30分钟以上,位置变动距离在50m距离内的gps点,它们的几何中心定义为驻留点(staypoint),既为图1中s1到s8的这8个点。
二聚类阶段:
步骤(1)通过对s1到s8这些驻留点的r3σ半径范围查询,对周围的poi点进行到访频次计数,所涉及到的范围如图1中圆形虚线所示。
步骤(2)利用到访频次计数、领域密度和语义类别对poi点进行有额外判定条件的dbscan聚类。如图2所示,p1到p16这16个poi点中p1,p2,p3,p4,p5,p6这6个临近点均位于左侧s1,s2,s3,s4,s5这5个驻留点附近,具有相似的到访频度计数,且语义类别一致都为shop,因此聚集成一类,以左侧的虚线圈出。p7,p8,p9,p10,p11,p12,p13,p14,p15这9个临近点环绕在s6,s7,s8这3个驻留点周围,也具有相似的到访频度计数和一致的类别,也聚集成一类以右侧的虚线圈出。剩余p16由于过于较为远离驻留点和其他poi点单独成一类。
三纯化阶段:
步骤(1)校验步骤发现图2中右侧虚线圈出聚类内部有两种语义类别,因此开始顺序执行步骤(2);
步骤(2)描述步骤。描述步骤对于p7,p8,p9,p10,p11,p12,p13,p14,p15这9个poi点进行内部语义类别分布概率计算。
步骤(3)分裂步骤对于这9个点先寻找距离几何中心最近的点p11作为代表点,然后比较其与剩余8个点的概率分布,得到8个kl散度值,它们分别为kl(p11,p7)=0.473,kl(p11,p8)=0.394,kl(p11,p9)=0.212,kl(p11,p10)=0.051,kl(p11,p12)=0.569,kl(p11,p13)=0.895,kl(p11,p14)=1.134,kl(p11,p15)=1.873。对8组kl散度进行升序排序可得序列{p10,p9,p8,p7,p12,p13,p14,p15},再利用中位数分割为两个小聚类,并把代表点放入kl散度值较小的聚类中,就可以得到如图3所示的两个分裂完的聚类restaurantunit和officeunit。
步骤(4)迭代步骤跳转回步骤(1)校验步骤,发现两个新聚类都是纯净的,则结束迭代。
四重组阶段:
步骤(1)对图3中的4个聚类shopunit,restaurantunit,officeunit和p16进行外部语义类别概率分布计算。
步骤(2)发现officeunit和p16的外部语义类别概率分布的余弦相似度大于阈值且彼此几何中心距离在r3σ内,则进行一次重组合并。合并结果如图4所示,有3个用虚线圈出的分布紧凑且语义类别相同的poi聚类组成了最终的城市语义图谱。
下面通过真实数据集上的实验来算法的准确性。我们使用2015年上海共2200万条出租车轨迹数据集,和高德地图2015年上海市路网数据和120万个poi数据进行数据实验。在上海各个城区针对传统固定构型语义信息构建技术的代表街区网格算法和本发明提出的不定构型语义信息构建技术进行比较,表1展示了各个城区的城市语义图谱中的聚类区域数量对比,比较指标分为区域总数量与平均覆盖面积。区域总数量越多说明城市语义图谱的信息量越丰富,内容越全面;区域平均覆盖面积约小说明城市语义图谱的语义识别与区域功能划分越详细精准。可以看出本发明具有空间粒度细且语义数量多的先进优势。
表1
- 还没有人留言评论。精彩留言会获得点赞!