基于骨架和视频特征融合的行为分类方法与流程
1.本发明属于计算机图像处理技术领域,具体涉及一种利用骨架特征和视频特征融合的行为分类方法。
背景技术:
2.在计算机视觉任务中,行为识别是十分具有挑战性的领域。行为识别主要有两类研究方法,一类是基于 rgb 图像的行为识别,另外一类是基于骨架的行为识别。基于 rgb 的方法,其优点是拥有所有视觉层面上的信息,特征完备,但其缺点是场景过于丰富,而人体姿态在不同的相机角度下变化太大,模型无法完全理解人体姿态语义信息,可能学习到更多的背景特征。基于骨架的方法,其优点人体姿态结构清晰,天然的图模型,对相机视角变化和背景不敏感,特征聚焦在人体。但其缺点也很明显,没有其他物体和背景相关特征,导致当人体与物体进行交互时,往往很难识别其行为类别。因此可以通过将视频特征与骨架特征相融合,以解决单一特征不鲁棒的缺点。
技术实现要素:
3.本发明的目的在于提供一种鲁棒性好的将视频与骨架特征融合的行为分类方法。
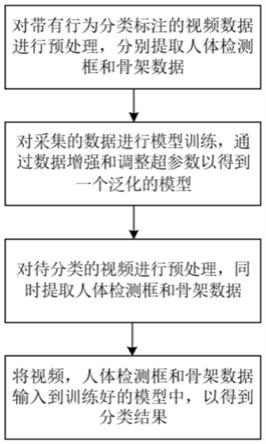
4.本发明提供的将视频与骨架特征融合的行为分类方法,是基于深度学习的;基本步骤为:对已有的人类行为视频数据进行预处理,通过人体检测模型和openpose
1.分别获取对应的人体检测框和人体骨架数据,作为深度学习模型的训练数据;其中视频数据和人体检测框数据作为前景与背景特征融合网络的输入,骨架特征作为个体与群体特征融合网络的输入;两个网络的输出结果进行平均为最终分类结果;接着对训练集进行监督式学习,得到泛化的深度学习模型;然后,对识别的视频进行和模型训练时一样的预处理,然后作为输入,放进预先训练好深度学习模型里,就能得到行为分类的结果。
5.本发明提出的基于骨架和视频特征融合的行为分类方法,具体步骤如下:(1)获取深度学习的训练数据;(2)训练深度学习模型;(3)用训练好的模型对视频进行行为分。
6.步骤(1)中所述获取深度学习训练数据的具体流程为:(11)首先处理视频数据;所有的视频数据都按30fps处理,所有视频缩放至256
×
256,并同时从视频中随机抽取一段视频帧,长度为
푇
,采样率为2(即每隔一帧采样一次);(12)用resnet
‑
101
‑
fpn为骨干的faster
‑
rcnn
2.模型对流程(11)中处理好的视频数据进行人体检测,得到人体检测框;该resnet
‑
101
‑
fpn为骨干的faster
‑
rcnn模型是在imagenet和coco人体关键点数据集上预训练得到的;(13)对流程(12)中获取的人体检测框数据,在每个人体框内使用openpose的2d姿态估计来获取骨架数据,其数据结构为18个关节的2d空间坐标。
7.步骤(2)中所述训练深度学习模型,具体包括:
对于视频数据使用前景与背景特征融合网络进行训练;所述前景与背景特征融合网络是由3dcnn网络提取的背景特征与人体检测框内的前景特征进行融合的网络,其中3dcnn网络使用slowfast
3.网络;对于骨架数据使用个体与群体特征融合网络进行训练;所述个体与群体特征融合网络主要由st
‑
gcn
4.网络构成,通过注意力机制自适应调整个体行为在群体行为中的权重;将前景与背景特征融合网络和个体与群体特征融合网络的输出结果进行平均,得到最后的分类结果。
8.本发明中,对于数据集较小的情形,对数据进行数据增强处理;对视频数据和骨架数据同时做随机缩放、随机旋转
ꢀ−
20 度至 20 度、随机裁剪以及随机水平翻转操作;对视频数据做随机颜色抖动操作。针对每个骨架节点的空间位置做轻微随机抖动;训练深度学习模型的具体流程为:(21)设置模型超参数;模型中主要超参数有:gpu个数,批次大小,动量参数,权重衰减项,学习率,丢弃率,迭代次数;本发明中,模型超参数可设置如下:gpu个数:设置为8;批次大小:设置为64;动量参数:这个值影响着梯度下降到最优值的速度,设置为0.9;权重衰减项:权重衰减正则项值越大对过拟合的抑制能力越大,设置为0.0001;学习率调整策略:使用带有线性warmup策略的sgdr,计算方式为
휂
⋅
[cos(1+
푖
/
푖푚푎푥
⋅
휋
)];其中
휂
为初始学习率,设置为0.1,imax为总迭代次数,i为第i次迭代;丢弃率:设置为0.5;迭代次数:训练的总次数,10万次以上。
[0009]
(22)超参数设置好后,开始训练,注意训练时的训练损失和验证损失值,两者同时减小说明网络预测能力正逐步增加,当两者不再减小时,说明网络已经收敛,结束训练;(23)多次调整超参数,得到泛化性能最好的模型;步骤(3)中所述用训练好的模型对带分类视频进行行为分类,具体包括:对视频数据的处理,与步骤(1)相同;视频数据和人体检测框输入到前景与背景特征融合网络,骨架数据输入到个体与群体特征融合网络;最后对两者的输出结果进行平均,得到最后的分类结果。其中:(3.1)前景与背景特征融合网络的实现,具体流程为:设视频片段rgb数据经过时空卷积神经网络的前向传播后得到的特征图为
푋
푆푇
∈
ℝ
퐵
×
퐶
×
푇
×
퐻
×
푊
,其中b为批大小,c为通道数,t、h和w分别为特征图的时长、高以及宽。首先对
푋
푆푇
进行时序全局池化消去时序维度,得到
푋 ∈
ꢀℝ
퐵
×
퐶
×
푇
×
퐻
×
푊
,接着用提前训练好的人体检测器检测出该视频段内关键帧的人体边界框,设为
푛
ꢀ×ꢀ
[
푥1, 푦1, 푥2, 푦2, 푠푐표푟푒
],其中
푛
为检测框的数量,
푠푐표푟푒
为检测框的置信度。前景特征图
푋
푓
为经过
푅푂퐼퐴
l
푖푔푛
操作后的特征。
푋
푏
为下采样后的
푋
,也是全局特征,
푋
푏
∈
ꢀℝ
퐵
×
퐶
×
퐻
′×
푊
′
。前景特征与背景特征的融合操作在第二个维度上。
[0010]
(3,2)个体与群体特征融合网络的实现,具体流程为:这里使用st
‑
gcn作为骨架特征抽取的基本模块,对于群体骨架序列,其输入的数据为
푋
푔
∈
ꢀℝ
퐵
×
푁
×
푇
×
푉
,其中b代表批次大小,n代表固定的群体人数,t为时间序列长度,v为骨架节点个数。当视频帧中人数大于n时,取其中n个置信度最大的骨架序列。当视频中人数
小于n时,对于缺少的人数的骨架序列都设为{b,n
′
,t,v} =1
푒
‑8,其中n
′
为缺少的人数。而对于个体骨架序列,每个骨架序列
푋
푖
,1≤
푗
≤
푁
的维度都为{b,1,t,v}。对于群体骨架序列,我们使用st
‑
gcn
푔
进行时空图卷积,获取群体骨架特征
퐹
푔
。对于每个个体骨架序列,我们使用st
‑
gcn
푖
,1≤
푖
≤
푁
进行时空图卷积,获取个体骨架特征
퐹
푖
。然后对不同个体的骨架特征进行融合,这里直接进行特征拼接。为了对时序维度t’和骨架节点维度v调整时空权重,先站着通道维度进行最大池化。接着将个体特征通过sigmoid运算,把所有值转化到0到1之间,得到注意力特征,然后通过注意力特征与群体特征的点乘,使群体特征图进行一次权重重新分配,增加重要个体行为在群体行为中的权重同时弱化非相关个体行为在群体行为中的重要性。
[0011]
(3.3)图像与骨架特征融合网络的实现,具体流程为:对视频数据的处理与步骤(1)相同,其中视频数据和人体检测框输入到前景与背景特征融合网络,骨架数据输入到个体与群体特征融合网络;最后对两者的输出结果进行平均,得到最后的分类结果。
附图说明
[0012]
图1为本发明的总流程框图。
[0013]
图2为数据提取的结果展示。其中,(a)为原图,(b)中绿色框为人体检测框,红色代表提取的人体骨架结构。
[0014]
图3为本发明中的前景与背景特征融合网络的模型架构图。
[0015]
图4为本发明中的个体与群体特征融合网络的模型架构图。
[0016]
图5为本发明的骨架与视频特征融合网络的模型架构图。
[0017]
图6为本发明的模型架构的实验结果图。
[0018]
图7为本发明的模型架构的部分实验数据展示图。其中,(a)和(c)分别为run和carry object动作发生处的图片,(b)和(d)分别为其对应的骨架。
具体实施方式
[0019]
模型中主要超参数有:gpu个数,批次大小,动量参数,权重衰减项,学习率,丢弃率,迭代次数;本发明中,模型超参数可设置如下:gpu个数:设置为8;批次大小:设置为64;动量参数:这个值影响着梯度下降到最优值的速度,设置为0.9;权重衰减项:权重衰减正则项值越大对过拟合的抑制能力越大,设置为0.0001;学习率调整策略:使用带有线性warmup策略的sgdr,计算方式为
휂
⋅
[cos(1+
푖
/
푖푚푎푥
⋅
휋
)];其中
휂
为初始学习率,设置为0.1,imax为总迭代次数,i为第i次迭代;丢弃率:设置为0.5;迭代次数:训练的总次数,10万次以上。
[0020]
最后,用训练好的模型对带分类视频进行行为分类,其中:(3.1)前景与背景特征融合网络实现,具体流程为:设视频片段rgb数据经过时空卷积神经网络的前向传播后得到的特征图为
푋
푆푇
∈
ℝ
퐵
×
퐶
×
푇
×
퐻
×
푊
,其中b为批大小,c为通道数,t、h和w分别为特征图的时长、高以及宽。首先对
푋
푆푇
进行时序全局池化消去时序维度,得到
푋 ∈
ꢀℝ
퐵
×
퐶
×
푇
×
퐻
×
푊
,接着用提前训练好的人体检测器检测出该视频段内关键帧的人体边界框,设为
푛
ꢀ×ꢀ
[
푥1, 푦1, 푥2, 푦2, 푠푐표푟
푒
],其中
푛
为检测框的数量,
푠푐표푟푒
为检测框的置信度。前景特征图
푋
푓
为经过
푅푂퐼퐴
l
푖푔푛
操作后的特征。
푋
푏
为下采样后的
푋
,也是全局特征,
푋
푏
∈
ꢀℝ
퐵
×
퐶
×
퐻
′×
푊
′
。前景特征与背景特征的融合操作在第二个维度上。
[0021]
(3,2)个体与群体特征融合网络实现,具体流程为:这里使用st
‑
gcn作为骨架特征抽取的基本模块,对于群体骨架序列,其输入的数据为
푋
푔
∈
ꢀℝ
퐵
×
푁
×
푇
×
푉
,其中b代表批次大小,n代表固定的群体人数,t为时间序列长度,v为骨架节点个数。当视频帧中人数大于n时,取其中n个置信度最大的骨架序列。当视频中人数小于n时,对于缺少的人数的骨架序列都设为{b,n
′
,t,v} =1
푒
‑8,其中n
′
为缺少的人数。而对于个体骨架序列,每个骨架序列
푋
푖
,1≤
푗
≤
푁
的维度都为{b,1,t,v}。对于群体骨架序列,我们使用st
‑
gcn
푔
进行时空图卷积,获取群体骨架特征
퐹
푔
。对于每个个体骨架序列,我们使用st
‑
gcn
푖
,1≤
푖
≤
푁
进行时空图卷积,获取个体骨架特征
퐹
푖
。然后对不同个体的骨架特征进行融合,这里直接进行特征拼接。为了对时序维度t’和骨架节点维度v调整时空权重,先站着通道维度进行最大池化。接着将个体特征通过sigmoid运算,把所有值转化到0到1之间,得到注意力特征,然后通过注意力特征与群体特征的点乘,使群体特征图进行一次权重重新分配,增加重要个体行为在群体行为中的权重同时弱化非相关个体行为在群体行为中的重要性。
[0022]
(3.3)图像与骨架特征融合网络实现,具体流程为:对视频数据的处理与步骤(1)相同,其中视频数据和人体检测框输入到前景与背景特征融合网络,骨架数据输入到个体与群体特征融合网络;最后对两者的输出结果进行平均,得到最后的分类结果。
[0023]
从图6中可以看到,骨架网络在run一类上具有较高的精度,而在carry object一类上的精度很低。而rgb网络却与骨架网络得到的结果相反。基于图像和骨架特征融合的网络在两类上都达到了最高精度。从图7可以看出当人没有与其他物体发生交互时,我们可以通过骨架推断出动作,但是对于人与物体交互的动作(拿手机),无法通过骨架行识别。这说明了图像与骨架特征融合的有效性,也说明了本发明的有效性和优越性。
[0024]
参考文献(1)cao z , hidalgo g , simon t , et al. openpose: realtime multi
‑
person 2d pose estimation using part affinity fields[j]. ieee transactions on pattern analysis and machine intelligence, 2018.(2)ren s , he k , girshick r , et al. faster r
‑
cnn: towards real
‑
time object detection with region proposal networks[j]. ieee transactions on pattern analysis & machine intelligence, 2017, 39(6):1137
‑
1149.(3)feichtenhofer c , fan h , malik j , et al. slowfast networks for video recognition[c]// 2019 ieee/cvf international conference on computer vision (iccv). ieee, 2019.(4)yan s , xiong y , lin d . spatial temporal graph convolutional networks for skeleton
‑
based action recognition[j]. 2018。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1