一种神经网络张量处理器的制作方法
[0001]
本发明涉及人工智能芯片技术领域,尤其涉及一种神经网络张量处理器。
背景技术:
[0002]
处理器技术是人类科技进步的重大体现之一。然而,处理器的抽象模型却十分简单:(1)处理器都由存储器、输入/输出接口、控制单元和计算单元组成;(2)处理器循环执行下列操作:“取指令/数据、执行指令、写数据”;(3)处理器的行为完全由指令和数据决定。无论处理器多复杂,无论是cpu、gpu或dsp,上述模型全部适用。这个处理器抽象模型就是著名的“冯诺依曼结构”,其核心是把用于控制的程序当作数据来存储,这种基于存储程序的计算模型一直沿用至今,无论半导体工艺多先进,处理器结构多复杂,存储程序型计算从未改变。
[0003]
在存储程序计算中,指令和数据是所有操作的核心,直观地按照指令和数据来划分,传统计算体系结构可以分为四类:
[0004]
1)sisd(单指令单数据):最早的计算体系结构,任何时刻,只有一条指令执行,处理一个数据。
[0005]
2)simd(单指令多数据):一种并行计算体系,任何时刻,只有一条指令执行,处理多个数据。大多数现代处理器都拥有这类体系结构扩展(例如arm neon扩展指令和x86mmx/sse扩展指令)。
[0006]
3)misd(多指令单数据):多条指令处理一个数据,目前未被普遍使用。
[0007]
4)mimd(多指令多数据):一种并行计算体系,多个核心(运行不同指令)处理多个数据,大多数mimd体系实际由包含simd的多个核心组成。
[0008]
然而,随着数据密集型任务的出现,数据并行成为计算性能的关键瓶颈。simd架构是用于增加数据并行的直观选择,然而,把多个数据同步打包成一个向量数据并用一条指令执行,这极大地限制了数据并行度的发掘。
[0009]
对此,英伟达提出了simt(单指令多线程)架构。相比于simd,simt的数据由不同线程维护,数据之间是完全异步的关系,各自完全独立,可以实现大量异步数据的完全并行,也即线程级的数据并行。这样的架构极大地增加了数据的并行维度。典型的,1个16核现代先进cpu通常只能同时执行16或32个线程,而一个现代先进gpu同时执行的线程数高达几千个。
[0010]
显而易见的,在存储程序计算中,提高计算性能就是提高指令和数据的执行性能。在过去的近50年发展历程中,以英特尔、英伟达为代表的美国企业引领了处理器技术的重要发展。根据计算任务的特点:指令密集型或数据密集型,处理器架构也按照指令优化和数据优化两大方向发展,并衍生出cpu、gpu两大处理器类型。cpu是最早的处理器,其技术发展主要面向指令执行效率的优化,包括更高的频率、更高效的指令集(risc)、更多的指令级并行(超标量)、更多的任务级并行(超线程、多核)等。gpu是随着数据密集型任务的增多而逐渐发展起来的处理器,其技术发展主要面向数据执行效率的优化,包括更多核心数,更多线
程(simt)、更高效的内存结构,更高效的编程模型等。
[0011]
在通用并行计算这条路上,cpu/gpu架构探索了近50年,拥有一系列复杂的“组合拳”来完成多种粒度的并行计算,从而实现最高能效比的高性能计算,软硬件技术壁垒之高很难打破。
[0012]
从一开始,计算机编程就存在两种模型,一种模拟人类行为结果,一种模拟人类大脑。
[0013]
1)模拟人类行为结果的编程模型(称为传统编程模型),本质是基于人类认知的数学抽象进行编程。在该模型下,计算机的一切行为由人类的抽象思维决定,人类编写的程序代码变成确定的执行序列,并被特定的硬件使用。
[0014]
2)模拟人类大脑的编程模型(称为神经网络编程模型),本质是基于人类大脑的生物抽象进行编程。在该模型下,计算机的一切行为由神经网络结构和知识参数决定,训练获得的知识通过数据的形式存储,并被特定硬件使用。
[0015]
在过去的70年间,由于各种原因,模拟人类行为结果的编程模型得到蓬勃发展,并成为如今主流,目前几乎所有软件编程都属于此类。而模拟人类大脑的编程模型则历经几次浪潮与寒冬,进展缓慢,目前基于神经网络/深度学习技术的编程属于此类。
[0016]
cpu/gpu是基于传统编程模型打造的处理器。cpu/gpu也可以运行神经网络算法,但这是通过把神经网络算法转换成传统编程模型后实现的。大量事实证明,神经网络编程模型十分重要,是下一代智能计算体系的核心关键。如此重要的体系需要一种比cpu、gpu更高效的架构来执行。
[0017]
神经网络编程模型的本质是计算图模型,计算图的输入/输出是张量数据,计算图的类型代表操作类型。因此,直观的,最适合于神经网络编程模型的计算体系结构,是graph/tensor计算体系,其中,处理器的功能由计算图类型决定,而数据则是计算图的输入/输出张量。然而,计算图这一层级的粒度太粗,各类型间并没有太大的相关性,一个典型的神经网络计算由convolution、pooling、bn、scale、relu等组成,它们之间的行为差异巨大,如果处理器按照计算图操作的粒度去设计,这就意味着需要为每一个计算图操作(或某几个)设计专门的计算硬件(正如nvidia dla那样,nvdla为卷积、池化和bn专门设计了不同的计算电路),这样的代价是巨大的,而且也不具备可扩展性。
[0018]
由于人工智能计算任务是数据密集型任务,传统处理器的指令流水线架构会引入过多的指令冗余,不利于计算效率的提高。因此,人工智能计算更适合于数据流水线架构。
技术实现要素:
[0019]
本发明旨在克服上述现有技术的至少一种缺陷(不足),提供一种神经网络张量处理器,用于对神经网络算法进行集中化计算。
[0020]
一种神经网络张量处理器,包括主控制器、重构控制器和数据流计算引擎;所述主控制器用于向外部控制单元提供所述神经网络张量处理器的控制和状态接口,及提供第一配置信息和第一起始信号给重构控制器;所述重构控制器接收来自所述主控制器的所述第一配置信息和所述第一起始信号,并在所述第一起始信号有效后,获取外部存储器的重构指令,并解析重构指令生成第二配置信息和第二起始信号;所述数据流计算引擎接收来自重构控制器的所述第二配置信息和所述第二起始信号,根据所述第二配置信息进行功能配
置,并在所述第二起始信号有效后,获取外部存储器的数据和参数以执行运算,并将计算结果写入外部存储器中。
[0021]
张量处理器采用主控制器、重构控制器和数据流计算引擎组成的三层结构。其中,主控制器的主要作用是为外部控制单元提供传统的软件控制和状态接口,也即在传统编程模型下,通过如c语言等软件程序实现对张量处理器的配置与启动控制等操作;重构控制器的主要作用是在计算图编程模型下对数据流计算引擎进行算子类型定义操作,使数据流计算引擎在每次计算时匹配计算图模型中的某个计算图,从而使神经网络张量处理器具备通用性。
[0022]
张量处理器在实现一次运算前,通过重构控制器对数据流计算引擎进行功能配置,从而在数据流计算引擎的计算过程中无须主控制器等内部或外部控制单元的干预,从而可以大大提高神经网络的计算效率。
[0023]
进一步的,所述主控制器包括寄存器存取单元和寄存器单元;所述寄存器存取单元接收来自外部控制单元的命令;根据外部控制单元的命令中给出的寄存器地址和读写类型,完成所述寄存器单元的写操作或者读操作;所述寄存器单元存储有所述第一配置信息,所述第一配置信息包括算法配置基地址、数据基地址和参数基地址。
[0024]
主控制器仅需要提供少量的第一配置信息即可完成重构控制器的配置和计算指令的发布。
[0025]
进一步的,所述重构控制器包括重构指令获取单元和重构指令解码单元,所述重构控制器接收来自所述主控制器的所述第一配置信息和所述第一起始信号,所述第一起始信号有效后,所述重构指令获取单元根据所述第一配置信息向外部存储器获取重构指令,并由所述重构指令解码单元完成重构指令解码操作,生成所述第二配置信息和所述第二起始信号。
[0026]
进一步的,所述第二配置信息包括所述数据流计算引擎的输入数据的地址、输入参数的地址、输出数据的地址以及算子类型。数据流计算引擎通过功能配置和输入输出的接口配置,从而在数据流计算引擎的计算过程中无须主控制器等内部或外部控制单元干预,从而可以大大提高神经网络的计算效率。
[0027]
进一步的,所述数据流计算引擎包括顺序连接的4d数据存储访问模块、片上存储器、4d计算模块,和顺序连接的1d数据存储访问模块、1d计算模块和直接存储器写模块;所述4d计算模块和所述1d计算模块顺序连接,所述4d计算模块的输出为所述1d计算模块的第二输入;
[0028]
所述4d计算模块用于实现一个张量算子;
[0029]
所述1d计算模块用于实现一个线性算子和/或一个非线性算子;
[0030]
所述数据流计算引擎接收来自重构控制器的所述第二配置信息和所述第二起始信号,所述第二起始信号有效后,所述4d数据存储访问模块从外部存储器获取4d计算模块所需的数据;所述1d数据存储访问模块从外部存储器获取所述1d计算模块所需的数据;
[0031]
所述片上存储器用于缓存所述4d计算模块所需数据;
[0032]
所述直接存储器写模块用于将所述1d计算模块的输出写入外部存储器中。
[0033]
一个神经网络算法通常由多种不同类型的神经网络计算层组成,如卷积、池化、线性激活、非线性激活、全连接等。本发明所述的张量处理器的数据流引擎提供了4d计算模块
controller)、数据流计算引擎(data-flow computing engine)三部分组成。
[0047]
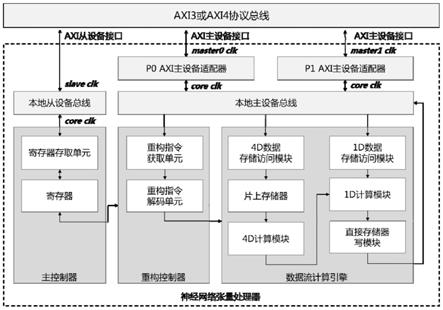
为了提高系统整合的灵活度,张量处理器采用系统内核与axi总线接口异步时钟的方案,系统使用四路完全独立的异步时钟来实现张量处理器内核与外部系统间的隔离。其中,axi从设备接口使用一路axi从设备总线时钟(slave clk),axi主设备接口使用两路axi主设备总线时钟(master0 clk和master1 clk),张量处理器内核使用内核时钟(core clk)。
[0048]
主控制器的主要作用是对外部控制单元提供传统的软件控制和状态接口,也即在传统编程模型下,通过如c语言等软件程序实现对张量处理器的配置与启动控制等操作,使得外部控制单元(如连接到相同axi总线的cpu)可以通过axi协议总线对张量处理器进行控制,如配置算法数据地址、图像数据地址、计算使能等。外部控制单元通过主控制器也可以获得张量处理器的内部状态,如计算结束状态、计算层数等。主控制器通过本地从设备总线与外部系统连接。本地从设备总线的主要作用是实现内核时钟(core clk)与axi从设备总线时钟(slave clk)的时钟同步功能,确保读写数据正确传输。
[0049]
主控制器由寄存器和寄存器存取单元组成。寄存器存取单元接收来自系统外部控制单元的命令(寄存器地址、读写类型等),完成寄存器模块的写或者读操作。对于寄存器所包含的控制和状态内容,一种实现方式如下表所示:
[0050][0051]
重构控制器的主要作用是在计算图编程模型下对数据流计算引擎进行算子类型定义操作,使数据流计算引擎在每次计算时匹配计算图模型中的某个计算图,从而使神经网络张量处理器具备通用性。
[0052]
具体的,重构控制器从外部存储器中获取重构指令、解析重构指令并根据重构指令配置数据流计算引擎。重构指令的内容与数据流计算引擎的实现相对应,其最终目的是配置数据流计算引擎中的关键部位,使数据流计算引擎实现某种功能的计算,如卷积计算。
[0053]
重构控制器的配置内容包括:数据流计算引擎的输入数据的地址、输入参数的地址、输出数据的地址以及算子类型。
[0054]
重构控制器由重构指令获取单元和重构指令解码单元组成。重构控制器接收来自主控制器的配置信息和起始信号。起始信号有效后,重构指令获取单元根据配置信息主动向外部存储器(如连接到相同axi总线的sdram)获取重构指令,并由重构指令解码单元完成指令解码操作,生成配置信息和起始信号。
[0055]
数据流计算引擎由4d数据存储访问模块、片上存储器、4d计算模块、1d数据存储访问模块、1d计算模块、直接存储器写模块组成。数据流计算引擎是一种纯数据通路计算模块,其功能由来自重构控制器的配置信息所决定。
[0056]
数据流计算引擎接收来自重构控制器的配置信息和起始信号。起始信号有效后,4d数据存储访问模块主动向外部存储器(如连接到相同axi总线的sdram)获取4d计算模块所需的数据,1d数据存储访问模主动向外部存储器(如连接到相同axi总线的sdram)获取1d计算模块所需的数据。
[0057]
4d数据存储访问模块获取的数据包括神经网络计算所需的特征数据和参数数据,都统一存储在片上存储器中。片上存储器中所缓存的数据会被4d计算模块重复使用,这些数据使用完毕后会被覆盖以提高片上存储器的利用率。
[0058]
1d数据存储访问模块获取的数据不经过存储器缓存,直接被1d计算模块使用。
[0059]
张量处理器所有的计算功能都由顺序连接的4d计算模块和1d计算模块实现。最好情况下,可以在硬件上实现一个张量算子(如卷积层)、一个线性算子(如bn层(batch normalization))和一个激活算子(如sigmoid激活函数)的融合计算。该融合计算优化由编译器自动实现。
[0060]
计算完成后,数据通过直接存储器写模块主动写入外部存储器。
[0061]
重构控制器与数据流计算引擎均设置有存储器读写访问接口,这些存储器读写访问接口统一通过本地主设备总线和主设备适配器与外部系统连接。本地主设备总线主要实现多对一和一对多的仲裁选择。主设备适配器主要起着时钟同步与数据位宽转换功能,其所连接的两路时钟主设备总线时钟master clk与内核时钟core clk是完全异步的,其所连接外部系统总线的数据位宽可以根据具体设计在64bit、128bit、256bit、512bit间进行选择,概括地说,适于大量数据计算的外部系统总线采用的数据位宽通常为64bit的2
n
倍,其中n为非负整数。
[0062]
一个神经网络算法由多个不同功能的算子组成,完成一个神经网络算法的计算任务就是按一定顺序完成多个不同功能算子的运算任务。
[0063]
进一步的,神经网络张量处理器的一次运算实现1~3个算子功能(最大情况下,在4d计算模块中实现一个张量算子,在1d计算模块中实现一个线性算子和一个激活算子)。
[0064]
一次算子运算分为重构配置和计算两部分。首先,在算子运算的开始阶段,重构控制器完成重构指令的获取以及数据流计算引擎的配置工作,如图2所示。
[0065]
配置完成后,数据流计算引擎将根据具体配置实现1~3个算子功能,并按照数据流的方式执行获取数据、计算、输出数据的操作,如图3所示。
[0066]
所有数据计算完成后,该次运算结束。重构控制器接着获取下一个算子所需的配置信息,从而开启新的算子运行任务。
[0067]
信号列表
[0068]
神经网络张量处理器的i/o信号接口整体框图如下表所示,其中axi从设备接口的信号统一命名为为s00_axi_*,axi主设备p0接口的信号统一命名为mdbb_axi_*,axi主设备p1接口的信号统一命名为mdbs_axi_*。
[0069]
信号列表及描述如下:
[0070]
[0071]
[0072]
[0073]
[0074][0075]
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1