一种基于二次排序的工单检索方法与流程
本发明涉及工单检索方法
技术领域:
,具体为一种基于二次排序的工单检索方法。
背景技术:
:随着互联网不断的高速发展,企业通过在网路上与客户进行交流,并针对客户的问题和请求进行管理、维护和追踪,客户根据关键词搜索来浏览所需要解决问题的文案。在基于关键词的检索中,检索按指定的若干个关键词进行检索,这种基于关键词的检索算法匹配精度较低。基于语义检索的算法,虽然精度较高,但是对大规模的数据而言,检索耗费时间较久,用户体验较差,为此我们提出了一种基于二次排序的工单检索方法。技术实现要素:本发明的目的在于提供一种基于二次排序的工单检索方法,以解决上述
背景技术:
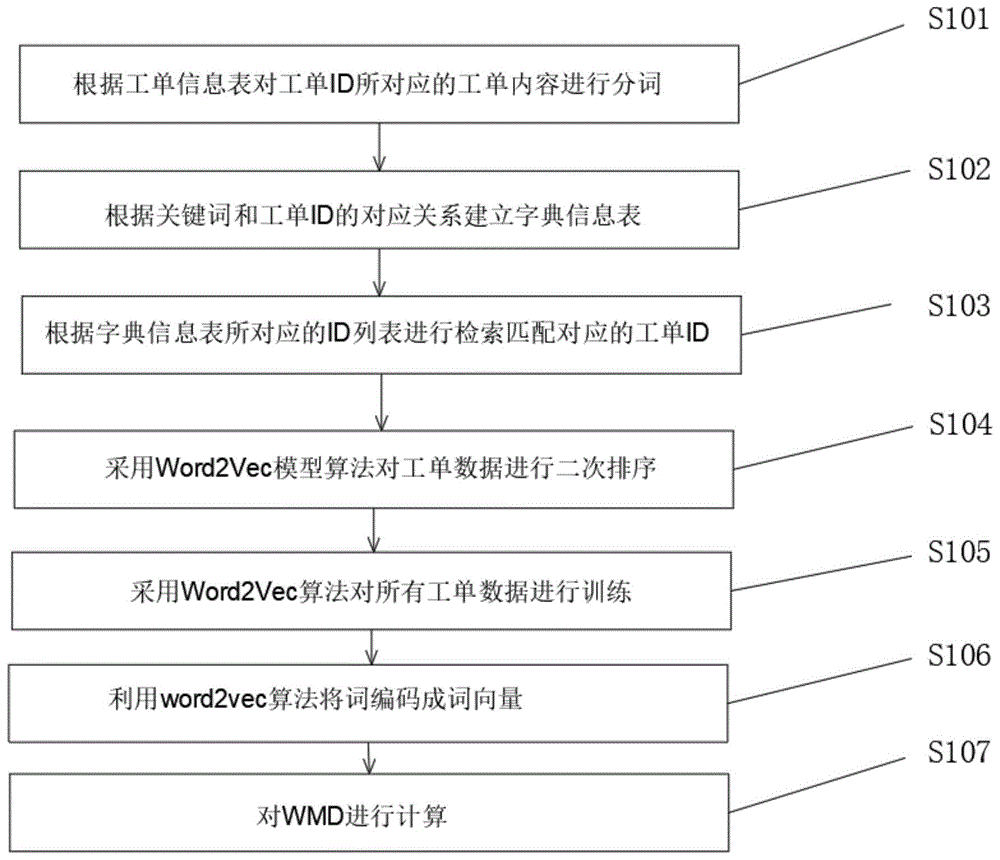
中提出了基于关键词的检索算法匹配精度较低。基于语义检索的算法,虽然精度较高,但是对大规模的数据而言,检索耗费时间较久,用户体验较差的问题。为实现上述目的,本发明提供如下技术方案:一种基于二次排序的工单检索方法,包括:s101:根据工单信息表对工单id所对应的工单内容进行分词;s102:根据关键词和工单id的对应关系建立字典信息表;s103:根据字典信息表所对应的id列表进行检索匹配对应的工单id;s104:采用word2vec模型算法对工单数据进行二次排序;s105:采用word2vec算法对所有工单数据进行训练;s106:利用word2vec算法将词编码成词向量;s107:对wmd进行计算。优选的,所述s101:根据工单信息表对工单id所对应的工单内容进行分词,具体包括:对一个自然语言处理工单进行分词并采用td-idf算法对工单的关键语素信息进行提取,所述工单信息表包括工单id和工单内容。优选的,所述字典信息表用于记录所有出现所述关键词的工单id。优选的,所述s103:根据字典信息表所对应的id列表进行检索匹配对应的工单id,具体包括:对采用td-idf算法提取的所述关键词在字典信息表中查询,对所取出的id列表取交集运算,其id对应的工单为一次检索匹配结果。优选的,所述s106:利用word2vec算法将词编码成词向量,具体包括:对于一个长度为n的词汇表,每一个词都有一个word2vec的embedding表示,构成一个x∈rd·n矩阵,其中每一列xi∈rd代表一个第i个单词的d维embedding向量。优选的,所述s107:对wmd进行计算,具体步骤包括:s1:计算每个关键词的nbow权重;s2:计算pair-wise的单词距离;s3:综合s1和s2计算文档之间的距离;s4:计算出最终两个文本的相似度值。优选的,所述s1:计算每个关键词的nbow权重,具体计算公式为:其中ci表示第i个词在文中出现的次数。d表示的是单个关键词的一个权重分布。优选的,所述s2:计算pair-wise的单词距离,具体计算公式为:c(i,j)=||xi-xj||2。优选的,所述s3:综合s1和s2计算文档之间的距离,具体包括:用d和d'表示两个文档的nbow向量,我们允许d中的任何一个词i转移到d'中的任何一个词j,转移的代价就是c(i,j);定义一个转移矩阵t∈rn×n,其中tij表示单词i有多少的权重要转移到单词j;为了保证将d全部转移到d’,必须满足d中从某单词i流出的权重之和等于该单词在d中的nbow的权重,即同理d’中流入某单词j的权重之和等于该单词在d'中的nbow的权重,即优选的,所述s4:计算出最终两个文本的相似度值,具体包括:需要找到一个单词匹配方式,使得累加带权重求和距离最小,这个最小距离就是最终俩个文本的相似度,具体计算公式如下:其中:最终的相似度值为:与现有技术相比,本发明的有益效果是:该基于二次排序的工单检索方法,采用关键词集合实现一次的工单筛选出n个备选工单,再采用语义相似度计算的方法将一次筛选出的工单进行二次工单排序,得出与待匹配工单语义最接近的工单。在平衡检索时间与检索精度的情况下,精度高,检索速度快,用户体验较为满意。附图说明图1为本发明步骤流程框图;图2为本发明wmd计算流程框图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明提供一种基于二次排序的工单检索方法,请参阅图1-2,包括:s101:根据工单信息表对工单id所对应的工单内容进行分词;s102:根据关键词和工单id的对应关系建立字典信息表;s103:根据字典信息表所对应的id列表进行检索匹配对应的工单id;s104:采用word2vec模型算法对工单数据进行二次排序;s105:采用word2vec算法对所有工单数据进行训练;s106:利用word2vec算法将词编码成词向量;s107:对wmd进行计算。其中,s101:根据工单信息表对工单id所对应的工单内容进行分词,具体包括:对一个自然语言处理工单进行分词并采用td-idf算法对工单的关键语素信息进行提取,工单信息表包括工单id和工单内容。其中,字典信息表用于记录所有出现所述关键词的工单id。其中,s103:根据字典信息表所对应的id列表进行检索匹配对应的工单id,具体包括:对采用td-idf算法提取的所述关键词在字典信息表中查询,对所取出的id列表取交集运算,其id对应的工单为一次检索匹配结果。其中,s106:利用word2vec算法将词编码成词向量,具体包括:对于一个长度为n的词汇表,每一个词都有一个word2vec的embedding表示,构成一个x∈rd·n矩阵,其中每一列xi∈rd代表一个第i个单词的d维embedding向量。其中,s107:对wmd进行计算,具体步骤包括:s1:计算每个关键词的nbow权重;s2:计算pair-wise的单词距离;s3:综合s1和s2计算文档之间的距离;s4:计算出最终两个文本的相似度值。其中:s1:计算每个关键词的nbow权重,具体计算公式为:其中ci表示第i个词在文中出现的次数。d表示的是单个关键词的一个权重分布。其中:s2:计算pair-wise的单词距离,具体计算公式为:c(i,j)=||xi-xj||2。其中:s3:综合s1和s2计算文档之间的距离,具体包括:用d和d'表示两个文档的nbow向量,我们允许d中的任何一个词i转移到d'中的任何一个词j,转移的代价就是c(i,j);定义一个转移矩阵t∈rn×n,其中tij表示单词i有多少的权重要转移到单词j;为了保证将d全部转移到d’,必须满足d中从某单词i流出的权重之和等于该单词在d中的nbow的权重,即同理d’中流入某单词j的权重之和等于该单词在d'中的nbow的权重,即其中:s4:计算出最终两个文本的相似度值,具体包括:需要找到一个单词匹配方式,使得累加带权重求和距离最小,这个最小距离就是最终俩个文本的相似度,具体计算公式如下:其中:最终的相似度值为:实施例该实施例包括如下步骤:1、对一个自然语言处理工单首先进行分词如对工单id为1的工单“公积金政策是什么?”进行分词;工单信息表如下:工单id工单内容1公积金政策是什么?2公积金缴纳标准是什么?2、采用td-idf算法对工单的关键语素信息进行提取,然后将关键词与工单id建立词典中的对应关系用于记录所有出现改关键词的工单id。例如表1中对工单id为1的工单提取关键词为“公积金”和“政策”,在工单id为2的工单提取关键词为“公积金”、“缴纳”和“标准”。则所建立的字典信息表如下:关键词id列表公积金{1,2}政策{1}缴纳{2}标准{3}3、对待排序工单进行分词,如工单“公积金的迁入政策是什么”,采用td-idf算法对工单进行提取关键词“公积金”、“迁入”和“政策”。对提取出来的关键词在字典表中查询得出“公积金”对应的id列表“{1,2}”,“政策”对应的id列表“{1}”,对所取出的id列表取交集运算:{1,2}∩{1}={1},则id为1的工单即为一次检索匹配结果。本实施例采用关键词集合实现一次的工单筛选出多个备选工单,提高了检索的精准度。需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。虽然在上文中已经参考实施例对本发明进行了描述,然而在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,本发明所披露的实施例中的各项特征均可通过任意方式相互结合起来使用,在本说明书中未对这些组合的情况进行穷举性的描述仅仅是出于省略篇幅和节约资源的考虑。因此,本发明并不局限于文中公开的特定实施例,而是包括落入权利要求的范围内的所有技术方案。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1