一种基于多尺度视觉特征提取的轻量级语义分割方法
本发明属于图像分割技术领域,涉及一种基于多尺度视觉特征提取的轻量级语义分割方法。
背景技术:
在无人机,无人驾驶等高机动性的自主决策终端系统中,如何实现准确的环境感知是系统运行的重要基础,可通过对设备采集图片进行知识推断,完成设备的场景理解。图像语义分割是ai领域的一个重要分支,是机器视觉技术中关于图像理解的重要一环。语义分割(semanticsegmentation)是从粗推理到精推理的过程,即通过查找图像像素所属类别,识别图中存在的内容以及位置,最终完成图像中各物体对象的整体标注,形成图像掩膜或输出每个像素所属类别。近年来随着深度学习的普及,许多语义分割问题正在采用深层次的结构来解决,最常见的是卷积神经网络(cnn),在精度及效率上超过其他方法。然而,此类方法使用了复杂的网络结构,计算资源和运算时间要求较高,在资源受限的嵌入式环境中受到极大的应用限制。
目前各应用语义分割任务的领域多属于移动端系统或高机动性系统,语义分割网络模型大且推理速度慢,现有方法进行语义分割时为实现轻量化一般的做法有两种:减小图片大小和降低模型复杂度。减小图片大小可以最直接地减少运算量,但是图像会丢失掉大量的空间细节从而影响精度,不易完成小尺度物体的分割。降低模型复杂度则会导致模型的特征提取能力减弱,严重影响分割精度。因此需要一种高精度且能够快速标注多尺度物体的语义分割方法。
技术实现要素:
本发明的目的是提供一种基于多尺度视觉特征提取的轻量级语义分割方法,解决了现有各应用语义分割任务的领域中存在的语义分割网络模型大且推理速度慢的问题。
本发明所采用的技术方案是,设计一种基于多尺度视觉特征提取的轻量级网络模型litnet的语义分割方法,具体按以下步骤实施:
步骤1,构建基于多尺度特征提取的轻量级卷积神经网络litnet;
步骤2,将经步骤1建立的神经网络进行训练;
步骤3,将经步骤2训练好的网络进行测试。
本发明的特点还在于:
其中步骤1的具体实施过程包括:所述多尺度特征提取的轻量级卷积神经网络结构包括特征提取模块、多尺度融合模块和上采样模块三部分,具体按以下步骤实施:
步骤1.1,图像输入网络后,首先通过特征提取模块进行下采样提取特征;
步骤1.2,再经过多尺度融合模块融合上下文信息,提取图像多尺度特征;
步骤1.3,最后通过上采样模块恢复图像尺寸,提高图像分辨率,输出分割结果;
其中特征提取模块具体按以下步骤实施:
步骤1.1.1,输入图像,设置设置widthmultiplerα为1;
步骤1.1.2,对输入图像进行一次普通卷积操作,压缩1次h*w,将通道数调整为32*α通道,并进行batchnormalization与relu激活;
步骤1.1.3,将步骤1.1.2中所得特征图传入反残差卷积块进1次反残差卷积,得到通道数为16的特征图;
步骤1.1.4,对步骤1.1.3所得特征图进行16次反残差卷积操作,输出320通道的特征图;
其中反残差卷积构造步骤为:
首先通过1*1卷积进行通道扩张,并进行batchnormalization与relu激活;然后通过3*3可分离卷积,并引入空洞卷积进行处理;进而通过1*1卷积调整通道,并进行batchnormalization与relu激活;最后引入残差网络结构,将输入与最终卷积输出进行融合;
其中多尺度融合模块具体按以下步骤实施:
步骤1.2.1,将特征提取模块所得特征图传入多尺度融合模块,构造平均全局池化层、膨胀率分别为1,6,12,18的空洞卷积模块;
步骤1.2.2,获取整体特征然后进行1x1卷积调整通道数,并恢复分辨率;,
步骤1.2.3,通过1*1卷积获取整体特征,改变通道数;
步骤1.2.4,分别使用膨胀率为6,12,18的空洞卷积提取到不同尺度下的特征;
步骤1.2.5,将步骤1.2.2~1.2.4中获取的特征进行合并,此时特征图的通道数为1280;
步骤1.2.6,通过构造1x1卷积调整通道数,得到融合后的256维特征图;
其中上采样模块具体按以下步骤实施:
步骤1.3.1,多尺度融合模块中得到256维特征图,构造上采样模块;
步骤1.3.2,对特征图进行三次双线性插值,得到上采样后的特征图;
步骤1.3.3,利用1*1卷积将通道数调整为分割类别数;
步骤1.3.4,构造reshape用于将特征图恢复为原始输入图片大小;
其中步骤2中网络训练为使用camvid数据集对网络进行训练,具体按以下步骤实施:
步骤2.1,获取预训练权重;
步骤2.2,将数据集数据打乱,将90%的图像用于训练,10%的图像用于估计;
步骤2.3,采用交叉熵损失函数,每个epoch之后输出训练损失与训练准确率以及验证损失与验证准确率;
步骤2.4,初始学习率定为1e-3,训练采用学习率自动下降的方式;
步骤2.5,val_loss2次不下降就将学习率降为之前的1/2继续训练;
步骤2.6,val_loss6次不下降时即认为训练完成,停止训练并保存模型;其中步骤2.2的具体操作过程包括:
首先将训练集按照预先设定的batch输入进网络,然后随机random数据集为每张图片在[0.7,1.3]范围内任意选择一种尺寸比例进行缩放,再然后按照0.5的概率大小对全部图片做左右变换的翻转处理,再将图片调整色彩,最后将训练图片的大小统一裁剪为设定大小;
其中步骤3中网络测试的具体过程为将测试图像输入网络,得到语义分割结果,并计算miou与fps,对网络性能进行评估:
步骤3.1,获取数据集中分割类别的rgb颜色;
步骤3.2,设定分类数及输入图像大小;
步骤3.3,加载模型并读取数据集;
步骤3.4,将数据集图像每一帧传入分割模型,对像素点进行分类;
步骤3.5,通过像素点分类标签,对分割图像上色,并调整为原图像大小。
本发明的有益效果是
本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法,针对于计算资源受限设备,采用轻量化设计,模型大小仅有10m,完全可以满足各种移动设备或其他嵌入式设备的语义分割要求,还采用了多尺度特征提取设计,使得图像中各种尺度的物体均可进行分割,以满足各种情况下的作业要求。
附图说明
图1是本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法中语义分割网络结构示意图;
图2是本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法中改进mobilenetv2网络结构图;
图3是本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法中多尺度融合模块结构图;
图4是本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法中后阶段网络训练loss曲线;
图5是本发明的一种基于多尺度视觉特征提取的轻量级语义分割方法中网络分割结果。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
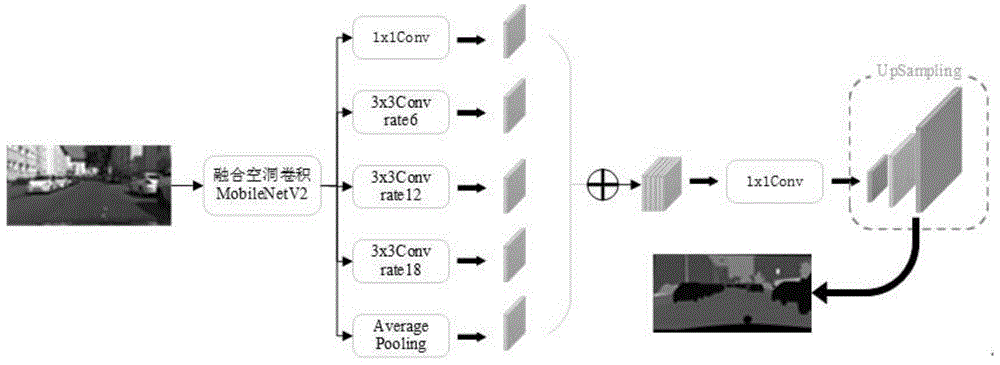
本发明提供了一种基于多尺度视觉特征提取的轻量级语义分割方法,如图1所示,具体按以下步骤实施:
步骤1,构建基于多尺度特征提取的轻量级卷积神经网络litnet,通过特征提取器提取图像特征,将特征传入融合空洞卷积的空间金字塔模块提取图像多尺度特征,最后通过简单上采样模块完成特征整合,恢复图像分辨率;
其网络结构共分为3个模块:1)特征提取模块;2)多尺度融合模块;3)上采样模块;
图像输入网络后,首先通过特征提取模块进行下采样提取特征,再经过多尺度融合模块融合上下文信息,提取图像多尺度特征,最后通过上采样模块恢复图像尺寸,提高图像分辨率,输出分割结果;
步骤2,网络训练:本发明使用tensorflow框架搭建网络结构,使用交叉熵函数作为损失函数,使用adam算法优化训练参数,并在训练过程中采用早停策略防止网络训练过拟合,以达到最优训练效果,;
步骤3,网络测试:将测试图像输入网络,得到语义分割结果,并计算miou与fps,对网络性能进行评估。
1)特征提取模块;对于语义分割任务来说,最为重要的是特征提取模块,此模块用于提取图像从低维的线性特征到高维抽象特征,分割网络的大部分参数以及计算量来自于这个模块,如图2所示,本发明为保证精度的同时寻求更快的分割速度,通过引进并改进了一种适用于移动设备的轻量化网络mobilenetv2,用于模型轻量化,该网络可以大大减小计算量从而使运行速度显著提升;
mobilenetv2在深度卷积前增添了点卷积,之所以这么做,由于dw卷积的输出通道数只由输入通道数决定,自身无法更改通道数,这就面临的一个问题是假若上层输出的输入道数过少,则深度卷积仅仅可以对空间中维度较低的特征进行提取并且激活函数不可以有效地发挥在高维空间进行非线性变换提取多样特征,输出效果必然不会令人满意,所以为了处理这个现象,mobilenetv2先构建一个升维系数是6的pw特意用来期望提升通道维度在高维提取特征,后面再结合一个dw卷积,经历了这样的阶段,无论输入通道数多大,深度卷积都可以通过逐点卷积在更高的维度工作来提取特征;由于mobilenetv2从高维向低维转换使网络丢失空间信息,本发明引入空洞卷积增大感受野,增加图像空间信息,对于卷积神经网络,浅层网络用于提取低级特征(点,线),深层网络用于提取高级特征(物体),高级特征往往与上下文信息有关,因此我们将网络6-16层融合不同膨胀率的空洞卷积;
由于使用轻量级网络作为特征提取器,分割精度不可避免地会下降,因此考虑到防止精度下降过于严重,为使模型的综合性能达到最佳,更好地平衡模型的分割精度和速度,在mobilenetv2中又引入了一种新的非线性激活函数swish,swish的定义如下:
swish(x)=xgσ(βx)(1)
其中,
非线性激活函数对于深层神经网络的训练能否成功起着关键的作用,由于网络层数越来越深,会使输入特征图的分辨率逐渐减小,考虑到要减弱应用非线性激活函数的成本,因此在mobilenetv2网络的深层部分将relu激活函数用swish替换,swish在网络深层部分表现比较明显,虽然会带来一点延迟,但可以弥补只用relu激活函数的mobilenetv2产生的潜在精度损失;
本发明的特征提取模块具体按以下步骤实施:
步骤1.1.1,输入图像,设置设置widthmultiplerα为1;
步骤1.1.2,对输入图像进行一次普通卷积操作,压缩1次h*w,将通道数调整为32*α通道,并进行batchnormalization与relu激活;
步骤1.1.3,将步骤1.1.2中所得特征图传入反残差卷积块进1次反残差卷积,得到通道数为16的特征图;反残差卷积构造步骤为:
首先通过1*1卷积进行通道扩张,并进行batchnormalization与relu激活;然后通过3*3可分离卷积,并引入空洞卷积进行处理;进而通过1*1卷积调整通道,并进行batchnormalization与relu激活;最后引入残差网络结构,将输入与最终卷积输出进行融合;
步骤1.1.4,对步骤1.1.3所得特征图进行16次反残差卷积操作,输出320通道的特征图。
2)多尺度融合模块
如图3所示,多尺度融合模块是一种带空洞卷积的空间金字塔,是一种能够获取多尺度上下文的架构,特征提取模块中的下采样过程是为了扩大感受野,使得每个卷积输出都包含较大范围的信息,对于提取抽象化信息有很大帮助,但在这个过程中,图像的分辨率不断下降,包含的信息越来越抽象,而图像的局部信息与细节信息会逐渐丢失,虽然现在也有通过线性插值上采样来恢复分辨率的手段存在,但在这个过程,还是不可避免的会造成信息的损失,而引入空洞卷积可以在不进行下采样情况下扩大感受野;
输出于顶端的featuremap,将其平行输出到五个模块中,第一个模块经过了平均池化,1x1的卷积层进行通道数变换,最后通过双线性插值恢复分辨率,第二到第五个模块都是空洞卷积,只是dilationrate不同,分别取了1,6,12,18;之后将这五个模块的输出concat到一起,通过一个1x1的卷积层,降低通道数到需要的数值,然后输出;
本发明的多尺度融合模块具体按以下步骤实施:
步骤1.2.1,将特征提取模块所得特征图传入多尺度融合模块,构造平均全局池化层、膨胀率分别为1,6,12,18的空洞卷积模块;
步骤1.2.2,获取整体特征然后进行1x1卷积调整通道数,并恢复分辨率;,
步骤1.2.3,通过1*1卷积获取整体特征,改变通道数;
步骤1.2.4,分别使用膨胀率为6,12,18的空洞卷积提取到不同尺度下的特征;
步骤1.2.5,将步骤1.2.2~1.2.4中获取的特征进行合并,此时特征图的通道数为1280;
步骤1.2.6,通过构造1x1卷积调整通道数,得到融合后的256维特征图。
3)上采样模块
在下采样的过程中,将图片的特征提取出来,实际上是把图片的关键部分提取出来的,降低了图片的分辨率,图片尺寸缩小;通过上采样模块,要恢复图片的大小,提高图片的分辨率。综合图像的分割精度以及速度,本发明采用3次上采样,每次上采样恢复特征图的1/2,最后得到与输入同等大小的图像;
本发明的上采样模块具体按以下步骤实施:
步骤1.3.1,多尺度融合模块中得到256维特征图,构造上采样模块;
步骤1.3.2,对特征图进行三次双线性插值,得到上采样后的特征图;
步骤1.3.3,利用1*1卷积将通道数调整为分割类别数;
步骤1.3.4,构造reshape用于将特征图恢复为原始输入图片大小。
本发明步骤2中网络训练为使用camvid数据集对网络进行训练,本发明的模型训练主要基于tensorflow框架,进行训练时可将训练集按照预先设定的batch输入进网络,输入图像大小也可根据硬件不同进行调整,具体按以下步骤实施:
步骤2.1,获取预训练权重;
步骤2.2,将数据集数据打乱,将90%的图像用于训练,10%的图像用于估计;首先将训练集按照预先设定的batch输入进网络,然后随机random数据集为每张图片在[0.7,1.3]范围内任意选择一种尺寸比例进行缩放,再然后按照0.5的概率大小对全部图片做左右变换的翻转处理,再将图片调整色彩,最后将训练图片的大小统一裁剪为设定大小;这样使得训练样本的图像尺寸和形状更丰富,更加具有随机性,从而避免过拟合;
步骤2.3,采用交叉熵损失函数,每个epoch之后输出训练损失与训练准确率以及验证损失与验证准确率;
步骤2.4,初始学习率定为1e-3,训练采用学习率自动下降的方式;
步骤2.5,val_loss2次不下降就将学习率降为之前的1/2继续训练;
步骤2.6,val_loss6次不下降时即认为训练完成,停止训练并保存模型;
一般地,当val_loss一直不下降时意味着模型基本训练完毕,本发明采用加入早停函数的方式,当val_loss6次不下降时即认为训练完成,停止训练并保存模型,可以有效防止过拟合;本发明经过在camvid数据集进行1200次迭代训练,最终得到收敛的模型,图4为采用预训练方式,最后40epoch的训练loss曲线。
本发明步骤3中网络测试的具体过程为将测试图像输入网络,得到语义分割结果,并计算miou与fps,对网络性能进行评估:
步骤3.1,获取数据集中分割类别的rgb颜色;
步骤3.2,设定分类数及输入图像大小;
步骤3.3,加载模型并读取数据集;
步骤3.4,将数据集图像每一帧传入分割模型,对像素点进行分类;
步骤3.5,通过像素点分类标签,对分割图像上色,并调整为原图像大小;
具体的利用训练得到的模型做性能测试来说明本发明的效果:
在camvid数据集上,模型参数量为257w,模型大小为10m,在尺寸为480x360的输入上,单帧预测时间为29ms,可达到34fps的帧率,可以满足实时性要求。在预测精度上,本发明的miou(meanintersectionoverunion)达到了70.24%;本发明兼顾精度与速度,可以达到高精度实时分割,与其他经典语义分割网络对比如表1。
表1网络性能对比
本发明提出的一种基于多尺度视觉特征提取的轻量级语义分割方法,在保证图像分割精度的同时实现快速推理,满足实时性要求,首先在底层特征提取模块采用mobilenetv2融合空洞卷积,在保证分割速度的同时利用空洞卷积增大感受野保留图像空间信息;利用融合空洞卷积空间金字塔结构获取多尺度上下文,对上层提取的特征图利用多尺度提取获得确定大小的特征向量;为保留图像细节与边缘信息,分割网络加入3次融合上采样过程,更精确的恢复图像的多尺度特征,经过实验分析,如图5所示,本发明litnet与经典分割网络deeplab、pspnet、icnet进行比较,计算参数量大幅下降,在camvid数据集上分割精度与分割速度得到明显提升。
- 还没有人留言评论。精彩留言会获得点赞!