一种多源异构数据库语义集成方法与流程
1.本发明涉及一种多源异构数据库语义集成方法。
背景技术:
2.随着信息化社会的发展,多源异构数据库的碎片化问题越来越突出。在大数据时代,当前的信息资源利用方式正在从依靠同源结构化数据进行信息管理,向多源异构资源共享进行信息集成管理转变。然而,目前基于异构数据的集成效果已经不能适应日益复杂的应用需求。如何有效地利用这些结构化、非结构化数据,把这些独立、分布各异的数据库联合起来,对实现信息共享开放、提升数据利用价值具有重要意义。如何实现非结构化文本数据库与结构化知识图谱的语义融合,是多源异构数据库语义集成的突出问题。
技术实现要素:
3.为解决上述技术问题,本发明提供了一种多源异构数据库语义集成方法,该多源异构数据库语义集成方法将深度强化学习技术与多源异构数据库语义集成相结合,能够有效建立不同形态下知识之间的语义映射关系。
4.本发明通过以下技术方案得以实现。
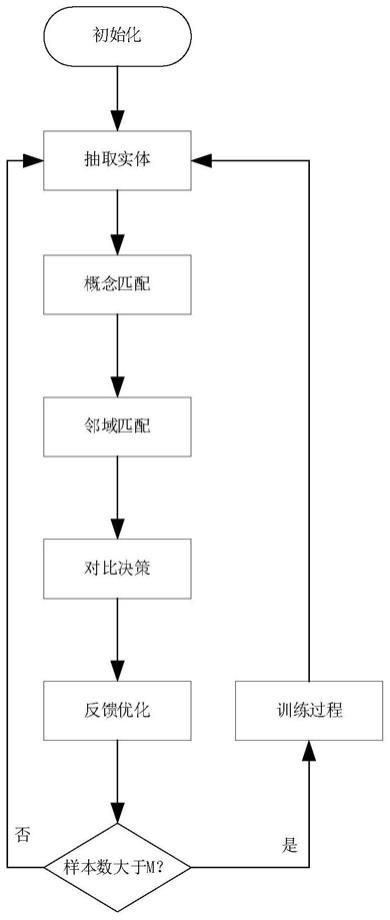
5.本发明提供的一种多源异构数据库语义集成方法,包括如下步骤:
6.①
抽取实体:基于实体抽取模型从非结构化文本中抽取领域相关实体并识别对应类别;
7.②
概念匹配:根据对应类别与知识图谱中本体概念进行匹配,得到同类别的候选实体集合;
8.③
邻域匹配:根据相关实体的上下文信息得到对齐实体图表示,根据候选实体集合在知识图谱中的领域关系,得到候选实体图表示;
9.④
对比决策:通过对对齐实体图表示和候选实体图表示进行对比决策,得到最匹配候选实体排列作为匹配结果。
10.还包括如下步骤:
11.⑤
反馈优化:利用对匹配结果的评价反馈,优化实体抽取模型的参数。
12.所述步骤
①
包括如下步骤:
13.s11:根据标签体系对非结构文本进行标注,构建针对抽取实体任务的数据集;
14.s12:基于序列标注模型,抽取非结构化文本的相关实体,并识别出相关实体对应的类别。
15.所述序列标注模型为,利用预训练语言模型bert结合条件随机场crf构建。
16.所述步骤
③
邻域匹配,包含如下步骤:
17.s31:根据对相关实体所在非结构化文本的上下文进行句法依存分析,得到待对齐的对齐实体图表示;
18.s32:根据所述候选实体集合,通过候选实体集合中的每个候选实体在知识图谱中
的位置及其邻域结构特征,得到每个候选实体的候选实体图表示。
19.所述步骤
④
对比决策,包含如下步骤:
20.s41:以对齐实体图表示和候选实体图表示作为输入,用策略网络输出待对齐实体与候选实体匹配的匹配结果;
21.s42:返回匹配结果中匹配度最高的n个候选实体及匹配度排序列表。
22.所述策略网络为孪生图神经网络模型。
23.所述步骤
⑤
反馈优化,包括如下步骤:
24.s51:收集对每个待对齐实体匹配结果的评价反馈;
25.s52:根据策略网络对每个待对齐实体预测的匹配度排序列表,结合评价反馈,构造针对策略网络的奖励函数;
26.s53:记录策略网络的历史输入、输出及对应的奖励值,作为样本训练集;
27.s54:当样本训练集中样本数大于m则启动对策略网络的训练过程。
28.本发明的有益效果在于:将深度强化学习技术与多源异构数据库语义集成相结合,建立不同形态下知识之间的语义映射关系,能更好支撑基于语义集成的语义检索、智能问答等相关应用。
附图说明
29.图1是本发明的流程示意图。
具体实施方式
30.下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
31.如图1所示的一种多源异构数据库语义集成方法,包括如下步骤:
32.①
抽取实体:基于实体抽取模型从非结构化文本中抽取领域相关实体并识别对应类别;
33.②
概念匹配:根据对应类别与知识图谱中本体概念进行匹配,得到同类别的候选实体集合;
34.③
邻域匹配:根据相关实体的上下文信息得到对齐实体图表示,根据候选实体集合在知识图谱中的领域关系,得到候选实体图表示;
35.④
对比决策:通过对对齐实体图表示和候选实体图表示进行对比决策,得到最匹配候选实体排列作为匹配结果。
36.还包括如下步骤:
37.⑤
反馈优化:利用对匹配结果的评价反馈,优化实体抽取模型的参数。
38.步骤
①
包括如下步骤:
39.s11:根据标签体系对非结构文本进行标注,构建针对抽取实体任务的数据集;
40.s12:基于序列标注模型,抽取非结构化文本的相关实体,并识别出相关实体对应的类别。
41.序列标注模型为,利用预训练语言模型bert结合条件随机场crf构建。
42.步骤
③
邻域匹配,包含如下步骤:
43.s31:根据对相关实体所在非结构化文本的上下文进行句法依存分析,得到待对齐
的对齐实体图表示;
44.s32:根据候选实体集合,通过候选实体集合中的每个候选实体在知识图谱中的位置及其邻域结构特征,得到每个候选实体的候选实体图表示。
45.步骤
④
对比决策,包含如下步骤:
46.s41:以对齐实体图表示和候选实体图表示作为输入,用策略网络输出待对齐实体与候选实体匹配的匹配结果;
47.s42:返回匹配结果中匹配度最高的n个候选实体及匹配度排序列表。
48.策略网络为孪生图神经网络模型。
49.步骤
⑤
反馈优化,包括如下步骤:
50.s51:收集对每个待对齐实体匹配结果的评价反馈;
51.s52:根据策略网络对每个待对齐实体预测的匹配度排序列表,结合评价反馈,构造针对策略网络的奖励函数;
52.s53:记录策略网络的历史输入、输出及对应的奖励值,作为样本训练集;
53.s54:当样本训练集中样本数大于m则启动对策略网络的训练过程。
54.实施例1
55.采用上述方案,具体包括以下步骤:
56.s1:通过基于深度学习算法的实体抽取模型,从非结构化文本中抽取领域相关实体,得到实体的起止位置,并识别出该实体对应的类别;
57.s2:将识别出的待对齐实体的类别与知识图谱中本体概念进行匹配,得到与待对齐实体具有相同类别的候选集合;
58.s3:根据非结构化文本的实体上下文信息得到待对齐实体的图表示,根据知识图谱中节点的邻域关系,得到候选实体的图表示;
59.s4:通过深度强化学习模型对候选集合中候选实体的图表示与待对齐实体的图表示逐一对比决策,从而得到与待对齐实体最匹配的候选实体排列;
60.s5:通过利用用户对最后匹配结果的评价反馈,优化深度强化学习模型的参数,学习到匹配策略。
61.实施例2
62.采用上述方案,具体包括以下步骤:
63.s11:建立标签体系,根据该标签体系对非结构文本进行标注,构建针对实体抽取任务的数据集;
64.s12:利用预训练语言模型bert,构建bert结合条件随机场crf的序列标注模型。基于该模型,完成剩余非结构化文本的实体抽取,得到实体的起止位置,并识别出该实体对应的类别;
65.其中:针对具体的领域应用,预训练语言模型bert可以先在大规模的无标注的领域相关文本语料中作领域适配;针对具体的应用任务,可以在任务相关文本语料中作任务适配。以提升语言模型bert在实体抽取任务中的性能。
66.s21:根据非结构化文本的实体抽取结果,将识别出的待对齐实体的类别与知识图谱中本体概念进行匹配。将知识图谱中已匹配概念下的实体集合,作为待对齐实体的候选集合。
67.其中:本体匹配是为多源异构数据库语义集成任务建立分区索引,提高实体链接的效率。
68.s31:根据待对齐实体所在非结构化文本的上下文,通过上下文的句法依存分析得到待对齐实体的图表示;
69.s32:根据s2中待对齐实体的候选集合,对于候选集合中的每个候选实体,通过该候选实体在知识图谱中的位置及其邻域结构特征,得到该候选实体的图表示。
70.待对齐实体的图表示体现了实体所在上下文中词与词之间的句法结构,并作为孪生图神经网络模型的输入之一;候选实体的图表示体现了候选实体在知识图谱中与其领域实体之间的语义关系,并作为孪生图神经网络模型的输入之一。
71.s41:构建孪生图神经网络模型,作为深度强化学习的策略网络。该策略网络以得到的待对齐实体图表示,以及候选实体图表示共同作为输入,输出待对齐实体与候选实体是否匹配;
72.s42:针对待对齐实体的候选集合,通过策略网络逐一对候选集合中每个候选实体与待对齐实体的图表示作出判决,并得到对应的匹配度。返回匹配度最高的10个候选实体,及对应匹配度排序列表。
73.其中:应用多层带注意力机制的孪生图神经网络模型,有利于发现并利用待对齐实体的图表示,以及候选实体的图表示中丰富的图结构信息,有助于策略网络预测待对齐实体与候选实体的匹配度。
74.s51:收集用户对每个待对齐实体匹配结果的评价反馈;
75.s52:根据s4中策略网络对每个待对齐实体预测的匹配度排序列表,结合用户评价反馈,构造针对深度强化学习模型的奖励函数;
76.s53:记录基于策略网络的输入、决策输出、及获得的奖励值,作为样本构建深度强化学习模型的训练集;
77.s54:当所收集的训练样本大于一定数量,启动对策略网络的训练程序,优化深度强化学习模型的参数,使模型学习到与任务适配的匹配策略。
78.其中:用户对每个待对齐实体匹配结果的评价反馈,可以操作为:从匹配度排序列表选择与待对齐实体语义等价的候选实体,或者认为匹配度排序列表中不存在与待对齐实体语义等价的候选实体。奖励函数可设计为:如果匹配度排序列表中存在与待对齐实体语义等价的候选实体,语义等价候选实体在匹配度排序列表中位置的倒数设置为奖励值;如果匹配度排序列表中不存在与待对齐实体语义等价的候选实体,奖励值设置为一个负值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1