一种基于深度学习的抗核抗体核型判读方法与设备与流程
本发明涉及抗核抗体核型判读技术领域,具体涉及一种基于深度学习的抗核抗体核型判读方法与设备。
背景技术:
抗核抗体(antinuclearantibody,ana)是指将真核细胞细胞核成分,如:rna,dna,可提取核抗原等作为靶抗原的一类自身抗体的总称,是诊断系统性红斑狼疮(systemiclupuserythematosus,sle)等自身免疫性疾病(autoimmunedisease,aid)的重要指标,而且在对aid的诊疗及预后评估方面也起到重要的作用。目前,有多种方法可以对ana进行检测,如间接免疫荧光法(indirectimmuno-fluorescenceassay,iif)、免疫印迹法(immunoblotingassay)、酶联免疫吸附法(enzyme-linkedimmunosorbentassay,elisa)等。其中基于hep-2细胞的iif敏感性高,并且具有半定量的特点,是ana检测中的参考方法和首选方法。iif的结果以图片的形式呈现,需要有一定经验的医师进行判读,有一定的主观性,而且自动化难度较高。为自动化判读iif的结果,一些公司推出了自动化核型判读仪器,如aesuku的helios,欧蒙的europattern等。但是这些自动化仪器仅能识别一些常见的核型,并且不具备识别混合核型和罕见核型的能力。所以为了结果的准确性,在日常的检验任务中,医师很少使用仪器的这项功能,仍采取人工判读的手段。因此抗核抗体荧光核型的自动化判读有很大的发展空间。
目前,基于深度学习的人工智能技术是解决目标检测问题的主流方法。其中r-cnn系列,ssd系列和yolo系列是目前比较常见的目标检测算法。yolo系列算法的是一步目标检测算法,直接将图片的信息通过卷积神经网络转换成图片中目标的种类和位置,因此相较于两步目标检测算法,该算法在兼顾检测精度的情况下运算速度更快。该系列目前最新的算法是由alexeybochkovskiy等人在yolo-v3的基础上设计的yolo-v4。
存在问题:为了实现抗核抗体荧光图片的自动识别,一些厂商推出了自动化识别仪器,如aesuku的helios,欧蒙的europattern等。但是这些自动化仪器仅能识别一些常见的核型,并且不具备识别混合核型和罕见核型的能力。所以为了结果的准确性,在日常的检验任务中,医师很少使用仪器的这项功能,仍采取人工判读的手段。
技术实现要素:
本发明的目的是针对现有技术存在的不足,提供一种基于深度学习的抗核抗体核型判读方法与设备。
为实现上述目的,在第一方面,本发明提供了一种基于深度学习的抗核抗体核型判读方法,包括:
获取抗核抗体的荧光图片,并基于图片分类模型对抗核抗体的荧光图片进行分类,所述抗核抗体的荧光图片的类别包括阴性、阳性和模糊,如抗核抗体的荧光图片的类别为阴性,则直接输出阴性结果,如抗核抗体的荧光图片的类别为模糊,则输出预警结果;
基于细胞识别模型对类别为阳性的抗核抗体的荧光图片中的细胞进行识别,以获取抗核抗体的荧光图片中的细胞的核型类别,所述核型类别包括常规核型和罕见核型,如细胞的核型类别为罕见核型,则输出预警结果;
以抗核抗体的荧光图片中含有的常规核型的类别为输入,并基于核型判别模型生成荧光核型判读结果。
进一步的,所述图片分类模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张分别符合阴性、阳性、模糊标准的图片,并对其分别进行标注;
从标注后的图片上随机选择部分区域作为类别训练区域图片,并对类别训练区域进行预处理;
将预处理后的类别训练区域图片传入神经网络,在神经网络中首先进行若干次平均池化操作,以将训练区域缩小,然后进行若干次残差卷积,最后接上2层全连接层,输出三个分别与所述荧光图片的类别概率对应的特征值;
以预处理后的类别训练区域图片作为输入,并以其类别作为输出,对神经网络进行训练,以获得图片分类模型。
进一步的,所述细胞识别模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张阳性图片,并按照图片中含有的荧光核型进行标注,如图片中含有多个荧光核型,则给图片标注上多个标签,最终得到图片集a,将图片集a按照标签分为图片集a1至a28,含有图片数量最多的图片集含有的图片数量设定为max_a,遍历图片集a1至a28,如其它图片集含有的图片数量少于max_a,则向该图片集中随机的添加该图片集中原有的图片,直至该图片集中的图片数量达到max_a,这样获得图片数量相等的图片集a1-a28,从图片集a1-a28的每个图片集中随机选取n张图片建立新的图片集b,其中,n为自然数,0<n<max_a,对图片集b中的每张图片随机截取部分区域作为识别训练区域,并将识别训练区域的图片放入新的图片集c,重新对图片集c中所有的图片进行荧光核型标注;
对图片集c中的每张图片进行预处理,然后将图片放入图片集d,重复u次,使图片集d中的图片数量为c的u倍,u为大于零的自然数;
以图片集d作为输入,并以图片集d中相应的标注作为输出训练yolo-v4神经网络,最终得到细胞识别模型m1;
获取多张新的阳性图片,并将新的多张阳性图片纳入图片集e中,然后对图片集e中的每张图片随机截取多张的部分区域作为识别训练区域图片,并将识别训练区域图片放入图片集f,使用细胞识别模型m1对图片集f中的图片进行标注,然后对由细胞识别模型m1标注的图片进行人工修改,最终将这些被修改的图片纳入图片集d,使图片集d不断扩大;
使用扩大后的图片集d对细胞识别模型m1进行训练,以获得完善的细胞识别模型。
进一步的,所述核型判别模型由以下方式生成:
将图片集e和图片集b中的图片纳入图片集f,并对图片集f中的图片进行标注,标注内容为通过细胞识别模型识别出的核型;
将图片集f中的所有图片进行细胞识别,输出的结果根据细胞的分布转化为28维度结构化数据,并将28维度结构化数据作为新神经网络的输入;
遍历输入的所有图片的28维度结构化数据,将除0以外数量最少的细胞数设为min_s,最多的细胞数设为max_s,在min_s和max_s之间设立10个区间,这10个区间作为分桶列分类标准。
以28维10个分桶列分类标准的结构化数据作为输入,并以最终的判读结果作为输出,对神经网络进行训练,以获得核型判别模型。
进一步的,所述预处理包括随机旋转和/或随机镜像翻转。
在第二方面,本发明提供了一种基于深度学习的抗核抗体核型判读设备,包括:
图片分类模块,用于获取抗核抗体的荧光图片,并基于图片分类模型对抗核抗体的荧光图片进行分类,所述抗核抗体的荧光图片的类别包括阴性、阳性和模糊,如抗核抗体的荧光图片的类别为阴性,则直接输出阴性结果,如抗核抗体的荧光图片的类别为模糊,则输出预警结果;
细胞识别模块,用于基于细胞识别模型对类别为阳性的抗核抗体的荧光图片中的细胞进行识别,以获取抗核抗体的荧光图片中的细胞的核型类别,所述核型类别包括常规核型和罕见核型,如细胞的核型类别为罕见核型,则输出预警结果;
核型判读模块,用于以抗核抗体的荧光图片中含有的常规核型的类型为输入,并基于核型判别模型生成荧光核型判读结果。
进一步的,所述图片分类模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张分别符合阴性、阳性、模糊标准的图片,并对其分别进行标注;
从标注后的图片上随机选择部分区域作为类别训练区域图片,并对类别训练区域图片进行预处理;
将预处理后的类别训练区域图片传入神经网络,在神经网络中首先进行若干次平均池化操作,以将训练区域缩小,然后进行若干次残差卷积,最后接上2层全连接层,输出三个分别与所述荧光图片的类别概率对应的特征值;
以预处理后的类别训练区域图片作为输入,并以其类别作为输出,对神经网络进行训练,以获得图片分类模型。
进一步的,所述细胞识别模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张阳性图片,并按照图片中含有的荧光核型进行标注,如图片中含有多个荧光核型,则给图片标注上多个标签,最终得到图片集a,将图片集a按照标签分为图片集a1至a28,含有图片数量最多的图片集含有的图片数量设定为max_a,遍历图片集a1至a28,如其它图片集含有的图片数量少于max_a,则向该图片集中随机的添加该图片集中原有的图片,直至该图片集中的图片数量达到max_a,这样获得图片数量相等的图片集a1-a28,从图片集a1-a28的每个图片集中随机选取n张图片建立新的图片集b,其中,n为自然数,0<n<max_a,对图片集b中的每张图片随机截取部分区域作为识别训练区域,并将识别训练区域的图片放入新的图片集c,重新对图片集c中所有的图片进行荧光核型标注;
对图片集c中的每张图片进行预处理,然后将图片放入图片集d,重复u次,使图片集d中的图片数量为c的u倍,u为大于零的自然数;
以图片集d作为输入,并以图片集d中相应的标注作为输出训练yolo-v4神经网络,最终得到细胞识别模型m1;
获取多张新的阳性图片,并将新的多张阳性图片纳入图片集e中,然后对图片集e中的每张图片随机截取多张的部分区域作为识别训练区域图片,并将识别训练区域图片放入图片集f,使用细胞识别模型m1对图片集f中的图片进行标注,然后对由细胞识别模型m1标注的图片进行人工修改,最终将这些被修改的图片纳入图片集d,使图片集d不断扩大;
使用扩大后的图片集d对细胞识别模型m1进行训练,以获得完善的细胞识别模型。
进一步的,所述核型判别模型由以下方式生成:
将图片集e和图片集b中的图片纳入图片集f,并对图片集f中的图片进行标注,标注内容为通过细胞识别模型识别出的核型;
将图片集f中的所有图片进行细胞识别,输出的结果根据细胞的分布转化为28维度结构化数据;
遍历输入的所有图片的28维度结构化数据,将除0以外数量最少的细胞数设为min_s,最多的细胞数设为max_s,在min_s和max_s之间设立10个区间,这10个区间作为分桶列分类标准;
以28维10个分桶列分类标准的结构化数据作为输入,并以最终的判读结果作为输出,对神经网络进行训练,以获得核型判别模型。
进一步的,所述预处理包括随机旋转和/或随机镜像翻转。
有益效果:本发明能够自动化的进行核型判读,并提供特殊情况预警系统,能够使医师放心的使用这个软件进行核型判读,并人工对预警的图片进行判读,大大提高检验效率。
附图说明
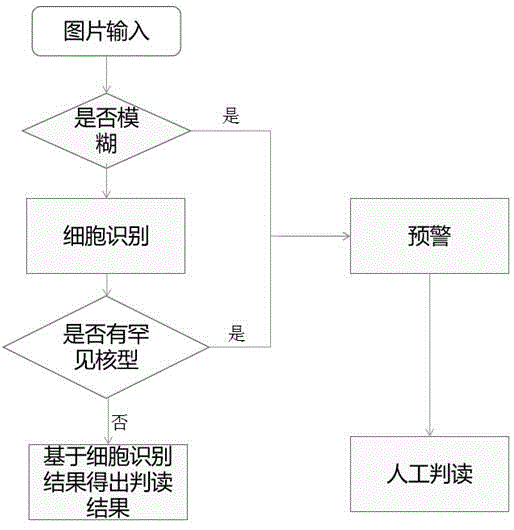
图1是基于深度学习的抗核抗体核型判读方法的流程示意图;
图2是细胞识别模型的神经网络结构示意图;
图3是通过细胞识别模型识别出的细胞核型的效果图;
图4为基于深度学习的抗核抗体核型判读设备的结构框图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,本实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
如图1所示,本发明实施例提供了一种基于深度学习的抗核抗体核型判读方法,包括:
获取抗核抗体的荧光图片,并基于图片分类模型对抗核抗体的荧光图片进行分类,抗核抗体的荧光图片的类别包括阴性、阳性和模糊,如果抗核抗体的荧光图片的类别为阴性,则直接输出阴性结果。如果抗核抗体的荧光图片的类别为模糊,则输出预警结果。对于预警结果的抗核抗体的荧光图片,直接通知医师人工判读。如果抗核抗体的荧光图片的类别为阳性,则进行下一步的细胞识别。需要说明的是,抗核抗体的荧光图片可以从helios设备中进行获取。
基于细胞识别模型对类别为阳性的抗核抗体的荧光图片中的细胞进行识别,以获取抗核抗体的荧光图片中的细胞的核型类别,核型类别包括常规核型和罕见核型,如细胞的核型类别为罕见核型,则输出预警结果。按照行业标准,抗核抗体荧光核型总共分为28种,具体包括基本分类和专家分类,本实施例中的常规核型即为基本分类的核型,罕见核型即为专家分类的核型。同样,对于此处预警结果的抗核抗体的荧光图片,也直接通知医师人工判读。通过细胞识别模型还可以获取抗核抗体的荧光图片中的细胞数量和坐标,可以根据细胞数量和坐标绘制识别图片,以进行展示。
如果细胞的核型类别为常规核型,则进一步以抗核抗体的荧光图片中含有的常规核型的类型为输入,并基于核型判别模型生成荧光核型判读结果。
具体的,本发明实施例的图片分类模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张分别符合阴性、阳性、模糊标准的图片,并对其分别进行标注。抗核抗体荧光图片数据库可以是金域检验的数据库,符合阴性、阳性、模糊标准的图片优选为各1000张。需要说明的是,此处的阳性图片和阴性图片为根据细胞的荧光强度人工分类出的,模糊图片是指人工分类出的helios设备拍摄模糊的图片。
从标注后的图片上随机选择部分区域作为类别训练区域图片,并对类别训练区域图片进行预处理。helios拍摄出来的图片大小为2560*1920,随机截取的类别训练区域图片大小优选为1920*1920。预处理随机旋转和/或随机镜像翻转。
将预处理后的类别训练区域图片传入神经网络,在神经网络中首先进行若干次平均池化操作(averagepooling),以将训练区域缩小,然后进行若干次残差卷积,最后接上2层全连接层,输出三个分别与荧光图片的类别概率对应的特征值。汇集操作优选采用两次,进而将类别训练区域图片的尺寸缩小为480*480,残差卷积优选进行3次。需要说明的是,三个特征值分别对应抗核抗体荧光图片为三个类别(阳性、阴性、模糊)的概率,三个特征值的取值均在0至1之间,并且三个特征值相加为1,如某一抗核抗体荧光图片三个特征值为0.6、0.2、0.2,则对应表示该抗核抗体荧光图片为为阳性类的概率为60%、为阴性类的概率为20%,为模糊类的概率为20%。
以预处理后的类别训练区域图片作为输入,并以其类别作为输出,对神经网络进行训练,以获得图片分类模型。整个训练过程需要不断调节参数完善模型,目的就是根据三个特征值判断出来的类别与抗核抗体荧光图片的实际的类别趋于一致,一般训练完善后的分类准确率在95%以上。另外需要说明的是,通过图片分类模型进行分类时,是通过输出的三个特征值进行判断的,三个特征值中最大者如在0.8以上,则以该最大者作为对应的类别输出分类结果,如三个特征值中的最大者小于0.8,则按模糊进行分类。
如图2所示,本发明实施例的细胞识别模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张阳性图片,并按照图片中含有的荧光核型进行标注,如果图片中含有多个荧光核型,则给图片标注上多个标签。最终得到图片集a,由于荧光核型共为28种,将图片集a按照标签分为图片集a1至a28,含有图片数量最多的图片集含有的图片数量设定为max_a,遍历图片集a1至a28,如其它图片集含有的图片数量少于max_a,则向该图片集中随机的添加该图片集中原有的图片,直至该图片集中的图片数量达到max_a,这样获得图片数量相等的图片集a1-a28,从图片集a1-a28的每个图片集中随机选取n张图片建立新的图片集b,其中,n为自然数,n取值范围为:0<n<max_a,对图片集b中的每张图片随机截取部分区域作为识别训练区域,并将识别训练区域的图片放入新的图片集c,重新对图片集c中所有的图片进行荧光核型标注。前面对筛选多张阳性图片只是少量标注,然后通过这些少量标注训练一个初始的神经网络,然后通过这个初始的神经网络来对新的图片进行标注,然后再人工对这些由神经网络标注的图片进行调整,这样可以减少标注的工作量。并且通过这些被神经网络的标注的图片可以了解这个神经网络对不同种类图片的识别效果,然后针对性的添加识别效果不好的图片作为新的训练材料。
对图片集c中的每张图片进行预处理,然后将图片放入图片集d,重复u次,使图片集d中的图片数量为c的u倍,u为大于零的自然数,优选为10。
以图片集d作为输入,并以图片集d中相应的标注作为输出训练yolo-v4神经网络,最终得到细胞识别模型m1;
获取多张新的阳性图片,并将新的多张阳性图片纳入图片集e中,然后对图片集e中的每张图片随机截取多张部分区域作为识别训练区域图片,并将识别训练区域图片放入图片集f,使用细胞识别模型m1对图片集f中的图片进行标注,然后对由细胞识别模型m1标注的图片进行人工修改,最终将这些被修改的图片纳入图片集d,使图片集d不断扩大。优选从图片集e中的每张图片随机截取10张识别训练区域图片,每张识别训练区域图片的大小优选为416*416。
使用扩大后的图片集d对细胞识别模型m1进行训练,以获得完善的细胞识别模型。
如图3所示,其示意出了通过细胞识别模型识别出的抗核抗体荧光图片中的细胞核型及其概率,概率值在0至1之间,一般当概率在0.6以下时,则忽略核型判断结果。
本发明实施例的核型判别模型由以下方式生成:
将图片集e和图片集b中的图片纳入图片集f,并对图片集f中的图片进行标注,标注内容为通过细胞识别模型识别出的核型。
将图片集f中的所有图片进行细胞识别,输出的结果根据细胞的分布转化为28维度结构化数据,并将28维度结构化数据作为新神经网络的输入。
遍历输入的所有图片的28维度结构化数据,将除0以外数量最少的细胞数设为min_s,最多的细胞数设为max_s,在min_s和max_s之间设立10个区间,这10个区间作为分桶列分类标准;
以28维10个分桶列分类标准的结构化数据作为输入,并以最终的判读结果作为输出,对神经网络进行训练,以获得核型判别模型。需要说明的是,通过细胞识别模型已经能够将阳性图片中的荧光核型识别出来并分类,但是临床上对抗核抗体荧光核型的判读结果并不是将图片中所有的核型识别出来,而是从图片选择几个重要的核型报告结果,而且细胞识别阶段可能会误判一些荧光核型。所以才需要将图片中的荧光核型分布作为输入,图片最终的结果作为输出,训练新的用于判读的神经网络模型。
如图4所示,基于以上实施例,本领域技术人员可以理解,本发明还提供了一种基于深度学习的抗核抗体核型判读设备,包括图片分类模块1、细胞识别模块2和核型判读模块3。
其中,图片分类模块1用于获取抗核抗体的荧光图片,并基于图片分类模型对抗核抗体的荧光图片进行分类,抗核抗体的荧光图片的类别包括阴性、阳性和模糊,如果抗核抗体的荧光图片的类别为阴性,则直接输出阴性结果。如果抗核抗体的荧光图片的类别为模糊,则输出预警结果。对于预警结果的抗核抗体的荧光图片,直接通知医师人工判读。如果抗核抗体的荧光图片的类别为阳性,则进行下一步的细胞识别。需要说明的是,抗核抗体的荧光图片可以从helios设备中进行获取。
细胞识别模块2用于基于细胞识别模型对类别为阳性的抗核抗体的荧光图片中的细胞进行识别,以获取抗核抗体的荧光图片中的细胞的核型类别,核型类别包括常规核型和罕见核型,如细胞的核型类别为罕见核型,则输出预警结果。按照行业标准,抗核抗体荧光核型总共分为28种,具体如图2所示,包括基本分类和专家分类,本实施例中的常规核型即为基本分类的核型,罕见核型即为专家分类的核型。同样,对于此处预警结果的抗核抗体的荧光图片,也直接通知医师人工判读。通过细胞识别模型还可以获取抗核抗体的荧光图片中的细胞数量和坐标,可以根据细胞数量和坐标绘制识别图片,以进行展示。
核型判读模块3用于以抗核抗体的荧光图片中含有的常规核型的类型为输入,并基于核型判别模型生成荧光核型判读结果。
具体的,本发明实施例的图片分类模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张分别符合阴性、阳性、模糊标准的图片,并对其分别进行标注。抗核抗体荧光图片数据库可以是金域检验的数据库,符合阴性、阳性、模糊标准的图片优选为各1000张。需要说明的是,此处的阳性图片和阴性图片为根据细胞的荧光强度人工分类出的,模糊图片是指人工分类出的helios设备拍摄模糊的图片。
从标注后的图片上随机选择部分区域作为类别训练区域图片,并对类别训练区域图片进行预处理。helios拍摄出来的图片大小为2560*1920,随机截取的类别训练区域图片大小优选为1920*1920。预处理随机旋转和/或随机镜像翻转。
将预处理后的类别训练区域图片传入神经网络,在神经网络中首先进行若干次平均池化操作(averagepooling),以将训练区域缩小,然后进行若干次残差卷积,最后接上2层全连接层,输出三个分别与荧光图片的类别概率对应的特征值。汇集操作优选采用两次,进而将类别训练区域图片的尺寸缩小为480*480,残差卷积优选进行3次。需要说明的是,三个特征值分别对应抗核抗体荧光图片为三个类别(阳性、阴性、模糊)的概率,三个特征值的取值均在0至1之间,并且三个特征值相加为1,如某一抗核抗体荧光图片三个特征值为0.6、0.2、0.2,则对应表示该抗核抗体荧光图片为为阳性类的概率为60%、为阴性类的概率为20%,为模糊类的概率为20%。
以预处理后的类别训练区域图片作为输入,并以其类别作为输出,对神经网络进行训练,以获得图片分类模型。整个训练过程需要不断调节参数完善模型,目的就是根据三个特征值判断出来的类别与抗核抗体荧光图片的实际的类别趋于一致,一般训练完善后的分类准确率在95%以上。另外需要说明的是,通过图片分类模型进行分类时,是通过输出的三个特征值进行判断的,三个特征值中最大者如在0.8以上,则以该最大者作为对应的类别输出分类结果,如三个特征值中的最大者小于0.8,则按模糊进行分类。
本发明实施例的细胞识别模型由以下方式生成:
从抗核抗体荧光图片数据库筛选多张阳性图片,并按照图片中含有的荧光核型进行标注,如果图片中含有多个荧光核型,则给图片标注上多个标签。最终得到图片集a,由于荧光核型共为28种,将图片集a按照标签分为图片集a1至a28,含有图片数量最多的图片集含有的图片数量设定为max_a,遍历图片集a1至a28,如其它图片集含有的图片数量少于max_a,则向该图片集中随机的添加该图片集中原有的图片,直至该图片集中的图片数量达到max_a,这样获得图片数量相等的图片集a1-a28,从图片集a1-a28的每个图片集中随机选取n张图片建立新的图片集b,其中,n为自然数,n取值范围为:0<n<max_a,对图片集b中的每张图片随机截取部分区域作为识别训练区域,并将识别训练区域的图片放入新的图片集c,重新对图片集c中所有的图片进行荧光核型标注。前面对筛选多张阳性图片只是少量标注,然后通过这些少量标注训练一个初始的神经网络,然后通过这个初始的神经网络来对新的图片进行标注,然后再人工对这些由神经网络标注的图片进行调整,这样可以减少标注的工作量。并且通过这些被神经网络的标注的图片可以了解这个神经网络对不同种类图片的识别效果,然后针对性的添加识别效果不好的图片作为新的训练材料。
对图片集c中的每张图片进行预处理,然后将图片放入图片集d,重复u次,使图片集d中的图片数量为c的u倍,u为大于零的自然数,优选为10。
以图片集d作为输入,并以图片集d中相应的标注作为输出训练yolo-v4神经网络,最终得到细胞识别模型m1;
获取多张新的阳性图片,并将新的多张阳性图片纳入图片集e中,然后对图片集e中的每张图片随机截取多张部分区域作为识别训练区域图片,并将识别训练区域图片放入图片集f,使用细胞识别模型m1对图片集f中的图片进行标注,然后对由细胞识别模型m1标注的图片进行人工修改,最终将这些被修改的图片纳入图片集d,使图片集d不断扩大。优选从图片集e中的每张图片随机截取10张识别训练区域图片,每张识别训练区域图片的大小优选为416*416。
使用扩大后的图片集d对细胞识别模型m1进行训练,以获得完善的细胞识别模型。
如图3所示,其示意出了通过细胞识别模型识别出的抗核抗体荧光图片中的细胞核型及其概率,概率值在0至1之间,一般当概率在0.6以下时,则忽略核型判断结果。
本发明实施例的核型判别模型由以下方式生成:
将图片集e和图片集b中的图片纳入图片集f,并对图片集f中的图片进行标注,标注内容为通过细胞识别模型识别出的核型。
将图片集f中的所有图片进行细胞识别,输出的结果根据细胞的分布转化为28维度结构化数据,并将28维度结构化数据作为新神经网络的输入。
遍历输入的所有图片的28维度结构化数据,将除0以外数量最少的细胞数设为min_s,最多的细胞数设为max_s,在min_s和max_s之间设立10个区间,这10个区间作为分桶列分类标准;
以28维10个分桶列分类标准的结构化数据作为输入,并以最终的判读结果作为输出,对神经网络进行训练,以获得核型判别模型。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!