基于多任务多通道小波变换嵌套长短期记忆模型的多变量空气质量时间序列预测方法
1.本发明涉及环境保护技术领域,更具体的说,涉及一种基于多任务多通道小波变换嵌套长短期记忆模型(mtmc
‑
wnlstm)的多变量空气质量时间序列的预测方法。
背景技术:
2.由于工业化和城市化进程,世界上越来越多的地区受到空气污染的威胁。恶劣的空气环境不仅破坏了自然界的生态平衡,而且影响了我们的生活环境,制约了经济和社会发展。常见的空气污染物包括6个主要成分:细颗粒物(pm2.5),可吸入颗粒物(pm10),二氧化硫(so2),二氧化氮(no2),一氧化碳(co)和臭氧(o3)。pm2.5和pm10主要是来自人类生产和生活垃圾的悬浮微粒,具有非常复杂的物理和化学成分,严重影响吸入后的健康并会引起呼吸系统疾病。空气中过量的二氧化硫(so2)和二氧化氮(no2)气体会引起酸雨。一氧化碳(co)和臭氧(o3)的接触同样将大大损害居民的身心健康。
3.对空气质量指标的研究和预测能够促进更好的预防和控制,从而实现更好的环境保护,提高人们的生活质量。然而,空气污染是一个广泛而复杂的话题。一方面,空气本身的成分很复杂。因此,很难定量测量其相互作用和相关性。另一方面,有许多因素影响空气质量,包括工业生产,能源提取,运输,日常生活,自然气候变化,灾害。这些复杂因素本身以及它们之间的相互作用几乎是无法计算和预测的。
4.因此,考虑到空气质量指标数据水平和历史数据具有一定的继承性,利用其历史记录进行短期时间序列预测是一种更可行的选择。时间序列预测在资源分配,市场研究,环境保护和能源利用等许多领域中发挥着重要作用。在利用大量历史数据进行预测时,基于人工智能技术的机器学习和深度学习方法具有显着优势。
5.用于时间序列预测的最新深度学习方法称为长短期记忆(lstm)。lstm是从原始递归神经网络(rnn)模型升级而来的,并具有独特的内部结构。原始的rnn神经网络无法解决较长的时间依赖性,在处理较长的时间序列时可能会导致梯度爆炸和梯度消失。lstm通过其独特的单元结构解决了这些问题。因此,lstm更能够记住和预测长期信息。
6.尽管具有显着优势,但朴素的机器学习和深度学习方法在空气质量指标预测中显示出困难。首先,空气成分的浓度数据受许多因素影响。因此,数据变化非常频繁且剧烈,具有相当大的不稳定性和不确定性,因此很难通过深度学习方法捕获,学习和预测。其次,空气成分之间存在相互影响。单个变量的变化可能导致多链反应和随后的持续影响。因此,目前的空气质量预测模型还存在预测精度较低、泛化性差、预测滞后等问题。
技术实现要素:
7.针对上述现有技术中存在的问题,本发明提出了一种创新的多任务多通道小波变换和嵌套长短期记忆神经网络模型(简称mtmc
‑
wnlstm模型)来预测每小时的多变量空气指标数据。本发明的模型可以同时预测pm2.5,pm10,so2,no2,co,o3六种空气质量指标变量,即
六种污染物在空气中的浓度。
8.本发明采用以下技术方案实现:
9.一种基于多任务多通道小波变换嵌套长短期记忆模型的多变量空气质量时间序列预测方法模型的空气质量数据时间序列的预测方法,包括以下步骤:
10.1)采集6个空气质量指标数据,每个采集点按时间顺序依次记录各指标的浓度数值,得到单维的时间序列数据并对其进行标准化,即将原数据放缩成平均值为0,标准差为1的数据;所述的6个空气质量指标为pm2.5,pm10,so2,no2,co和o3;
11.2)将标准化后的数据中每个变量的单维时间序列数据通过三次小波变换按照变化频率的高低分解成4个数据子序列,每个子序列长度与原序列相同;
12.3)使用滑动时间窗方法将步骤2)中每个变量的单维时间序列数据分解后得到的4个数据子序列从单维的时间序列数据拓展成多维数据;
13.4)将步骤3)得到的多维数据划分为训练集、验证集和测试集;
14.5)建立多任务多通道nlstm深度学习模型,该模型以最小化预测误差mae、rmse、mape指标和最优化预测拟合效果r2指标为目标进行设计和优化;将训练集输入以进行模型的训练,并采用验证集对模型进行验证;使用训练集和验证集将模型训练至最优状态之后,将测试集输入模型就可得到深度学习模型对测试集中6个空气质量指标的预测结果。
15.上述技术方案中,进一步地,步骤3)中将所述单维的时间序列数据拓展成多维数据,具体如下:使用前三个点的各指标的浓度数值预测第四个点各指标的浓度值,将单维样本数据拓展成为三维样本数据。基于这样的预测方式,将原来的单维时间序列样本数据拓展成为三维样本数据,即每个预测目标值与它对应历史数据的集合。
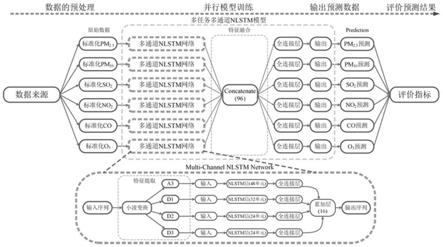
16.进一步地,步骤5)中所述的多任务多通道nlstm深度学习模型包含六个并行任务模块,每个任务模块对应一个空气质量指标变量;所述任务模块由若干通道组成,每个通道对应每个变量分解后的单个子序列的输入,多个通道融合后输出作为该任务模块的输出,以并行学习和预测多个空气质量变量的浓度。
17.更进一步地,所述的通道由一个nlstm神经网络层和一个全连接层组成。
18.在本发明方法中:
19.首先,多变量的空气质量指标时间序列被通过小波变换分解为去噪的低频子信号和去趋势的高频子信号。原始的空气质量指标数据集包含非常频繁且剧烈的波动。如果不进行数据预处理,仅通过深度学习模型无法很好地学习和预测这些波动。小波变换(wt)是一种在时间序列预测中成功实现的数据处理方法,擅长处理非平稳数据。因此,为了使数据的变化特征更易于捕获,本发明使用小波变换处理不稳定的原始数据,从而将不稳定的原始数据变得稳定而更易于预测。
20.其次,将小波变换分解得到的数据子序列输入一个多任务多通道nlstm深度学习模型。该多任务多通道nlstm深度学习模型包含六个并行模块,每个模块对应一个空气质量变量。每个模块有多个通道组成,每个通道对应每个变量分解后的单个子序列。通道由一个嵌套式长短期记忆神经网络(nlstm)层和一个全连接(dense)层组成。每个模块的输出在多任务和多通道网络中进行连接和融合,以并行学习和预测多个空气质量变量的浓度。
21.本发明与现有技术相比,具有以下优点:
22.本发明的基于多任务多通道小波变换嵌套长短期记忆模型的多变量空气质量时
间序列预测方法,使用小波变换处理不稳定的原始数据,从而将不稳定的原始数据变得稳定而更易于预测;将小波变换分解得到的数据子序列输入一个多任务多通道nlstm深度学习模型,可以并行学习和预测多个空气质量变量的浓度。该方法在对空气质量数据的预测研究中不论是预测精度还是泛化性上都要优于单一的学习预测模型,可以有效的应用于环境保护和污染监控中对空气质量数据的预测,并且能够有效解决目前空气质量预测模型中存在的预测精度较低、泛化性差、预测滞后等问题。
附图说明
23.图1为mtmc
‑
wnlstm模型的内部结构和实施流程示意图;
24.图2为三次小波变换的分解过程和分解结果;
25.图3为lstm和nlstm记忆单元内部结构;
26.图4为基于mtmc
‑
wnlstm模型的空气质量数据时间序列的预测方法的仿真结果示意图。
具体实施方式
27.以下结合附图对本发明的优选实施例进行详细描述,但本发明并不仅仅限于这些实施例。本发明涵盖任何在本发明的精神和范围上做的替代、修改、等效方法以及方案。
28.为了使公众对本发明有彻底的了解,在以下本发明优选实施例中详细说明了具体的细节,而对本领域技术人员来说没有这些细节的描述也可以完全理解本发明。
29.在下列段落中参照附图以举例方式更具体地描述本发明,仅用以方便、明晰地辅助说明本发明实施例的目的。
30.嵌套式长短期记忆神经网络(nlstm)是一种最新的lstm模型,nlstm模型能通过在历史数据中存储额外信息来提高预测性能。
31.nlstm存储器单元将一个lstm存储器单元嵌套到另一个lstm单元中。外部存储单元可以自由选择读取和写入内部单元的相关长期信息。这种结构总体上提高了原始lstm神经网络结构的鲁棒性,并能够存储和处理长期历史信息。因此,nlstm在具有此类特征的长期时间序列预测的应用中更具优势。
32.通过外部和内部存储器的结构,nlstm网络中形成了一个存储器层次结构,使它能够记住并处理长期信息。因此,相比于lstm或其他扩展,nlstm网络可用于以更高的精度和更低的误差实现更好的预测。
33.本发明的基于mtmc
‑
wnlstm的多变量空气质量时间序列预测方法,包括以下步骤:
34.1)采集6个空气质量指标数据,每个采集点按时间顺序依次记录,得到单维的时间序列数据并对其进行标准化,即将原数据放缩成平均值为0,标准差为1的数据;所述的6个空气质量指标为pm2.5,pm10,so2,no2,co和o3;
35.2)将标准化后的数据中每个变量的单维时间序列数据通过三次小波变换按照变化频率的高低分解成4个数据子序列,每个子序列长度与原序列相同,过程与结果如图2所示;
36.3)使用滑动时间窗方法将步骤2)中每个变量的单维时间序列数据分解后得到的4个数据子序列从单维的时间序列数据拓展成多维数据;
37.4)将步骤3)得到的数据划分为训练集、验证集和测试集;
38.5)建立多任务多通道nlstm深度学习模型,该模型以最小化预测误差mae、rmse、mape指标和最优化预测拟合效果r2指标为目标进行设计和优化;将训练集输入以进行模型的训练,并采用验证集对模型进行验证;使用训练集和验证集将模型训练至最优状态之后,将测试集输入模型就可得到深度学习模型对测试集中6个空气质量指标的预测结果。
39.采用均方根误差、平均绝对误差或/和平均绝对百分比误差对预测结果进行评价。即选取回归模型通用的3个评价标准对各个方法的性能进行评价,rmse(root mean squared error)均方根误差,mae(mean absolute error)平均绝对误差,mape(mean absolute percent error)平均绝对百分比误差,计算公式如下:
[0040][0041][0042][0043]
另外,引入了决定系数r2整个回归模型的拟合效果,计算公式为:
[0044][0045]
其中f表示实际数据值;是预测值;是实际数据的平均值。在四个指标中,mae,rmse,mape用于评估预测误差的水平,r2用于评估拟合的良好性。
[0046]
上述评价指标可用于量化预测效果,并评估这些预测方法的准确性和能力。
[0047]
表1
‑
6比较了多种现有方法的实验预测结果,以进一步证明本发明在多变量空气质量指标时间序列预测中的优越性。使用相同的评估指标,计算和比较预测每个空气质量指标变量的不同方法的预测误差和拟合效果。不同的空气质量指标成分具有不同的变化模式,因此对预测方法的泛用性提出了挑战。
[0048]
与本发明进行比较的方法包括传统的机器学习模型,包括多层感知机(mlp)和支持向量机回归(svr),用于时间序列预测的先进方法lstm神经网络和扩展的lstm模型,包括堆叠lstm(slstm)。表格中还将所本发明提出的方法与结合lstm和数据处理方法(即经验模态分解(emd)和变分模态分解(vmd))的混合模型进行比较。emd和vmd的实现具有类似小波变换的目的。还将未结合小波变换的多任务nlstm模型与提出的多任务多通道框架进行了比较。结果表明,本发明所提出的方法可以进行准确的预测,既可以更好地拟合原始数据,又可以减少误差,同时所需的时间相对较短。
[0049]
表1本发明和比较方法的预测性能。(pm2.5)
[0050][0051][0052]
表2本发明和比较方法的预测性能。(pm10)
[0053][0054]
表3本发明和比较方法的预测性能。(so2)
[0055][0056][0057]
表4本发明和比较方法的预测性能。(no2)
[0058][0059]
表5本发明和比较方法的预测性能。(co)
[0060][0061][0062]
表6本发明和比较方法的预测性能。(o3)
[0063][0064]
图4示意了基于mtmc
‑
wnlstm模型的空气质量数据时间序列的预测方法的仿真结果,从上至下分别为针对pm2.5,pm10,so2,no2,co,o3的预测结果。图中所示,所述proposed输出作为本技术的预测结果,所述real data输出为理想值或预期值,其余结果为不同的比较方法。图中可见,本技术的预测结果最接近于期望输出,比其他方法更准确,与表1
‑
6中的结果相符。
[0065]
虽然以上将实施例分开说明和阐述,但涉及部分共通之技术,在本领域普通技术人员看来,可以在实施例之间进行替换和整合,涉及其中一个实施例未明确记载的内容,则
可参考有记载的另一个实施例。以上所述的实施方式,并不构成对该技术方案保护范围的限定。任何在上述实施方式的精神和原则之内所作的修改、等同替换和改进等,均应包含在该技术方案的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1