一种基于语义相似度的轨迹聚类方法与流程
1.一种基于语义相似度的轨迹聚类方法,用于轨迹聚类,属于聚类方法技术领域。
背景技术:
2.相似性度量是轨迹数据分析中的一个重要研究问题,对于大多数轨迹数据挖掘问题而言,都需要进行轨迹之间的比较,因此,轨迹相似性度量的复杂性会直接影响到相关技术的运行效率和可行性。现有技术中,相似性度量大多采用动态规划实现,需要计算所有轨迹点的成对距离,具体为:动态规划需要计算每条轨迹的每一个点到其他所有轨迹的所有点的距离,时间复杂度很高,为0(n2),n为点的数量,当轨迹数量大量增加时,所需的时间非常可观,甚至难以计算,因此采用动态规划具有二次时间复杂度。而提出的聚类方法,根据同一轨迹簇内的所有轨迹彼此之间都有一定程度的相似,从而设计了一种基于阈值的剪枝方法,对于一条轨迹,不用计算它与其他所有轨迹的相似度,如果它与一个轨迹簇内的一条轨迹相似度非常低,则可以认为它与这个轨迹簇内的所有轨迹相似度都不会很高,相反如果它与一个轨迹簇内的一条轨迹相似度很高,则可以认为它与这个轨迹簇内的所有轨迹都有一定的相似度。通过这个策略,在保证一定的准确度的情况下,减少了大量的轨迹对之间的相似度计算,从而提高了聚类效率。但聚类算法通常从时间或空间角度对相似的轨迹进行聚类,如轨迹都是居住场所
‑
>交通场所
‑
>娱乐场所,其时间和空间上有可能都有不同,单一的只考虑时间或空间因素,轨迹之间的语义关系会被忽略,可能导致不合理的轨迹聚类结果。因此,存在着效率较低、聚类结果不合理的问题。
技术实现要素:
3.针对上述研究的问题,本发明的目的在于提供一种基于语义相似度的轨迹聚类方法,解决现有技术中的相似性度量对数据进行挖掘时,存在着效率较低、聚类结果不合理的问题。
4.为了达到上述目的,本发明采用如下技术方案:
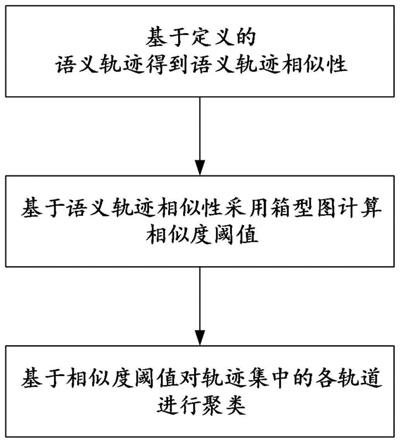
5.一种基于语义相似度的轨迹聚类方法,如下步骤:
6.s1、基于需要挖掘的数据的应用领域定义语义轨迹,再基于定义的语义轨迹得到语义轨迹相似性;
7.s2、给定轨迹训练数据集,抽取数个轨迹,基于语义轨迹相似性采用箱型图计算相似度阈值;
8.s3、基于相似度阈值对轨迹集中的各轨道进行聚类。
9.进一步,步骤s1中需要挖掘的数据的应用领域为包括经纬度、场景标签、时间和天气信息的社交网络领域、交通领域或旅游领域。
10.进一步,步骤s1中得到语义轨迹相似性的步骤如下:
11.s1.1、给定一条语义轨迹序列t
i
={t
i,1
,t
i,2
,
……
,t
i,j
,
……
t
i,n
},其中,n是轨迹的点的个数,t
i,j
是轨迹t
i
的第j个点,t
i,j
由m个属性(p1,p2,
……
,p
m
)组成,m个属性中的各
属性由距离属性和语义属性组成;
12.s1.2、基于语义轨迹中t
i,j
的m个属性得到语义轨迹相似性。
13.进一步,步骤s1.1中距离属性的公式为:
[0014][0015]
语义属性的公式为:
[0016]
sim
semantic
(p
m
)=h
‑1[0017]
其中,是指轨迹t
i
的第x个点的第m个属性,是指轨迹t
k
的第y个点的第m个属性,t
i
和t
k
两条轨迹的点的数量相等或不相等,h是和在层次树中最近公共父节点的层数。
[0018]
进一步,步骤s1.2得到的语义轨迹相似性的公式为:
[0019]
sim=w1·
sim
distance
+w2·
∑sim
semantic
(p
m
)
[0020]
其中,w1为空间相似度所占权重,w2为语义相似度所占权重,w1+w2=1。
[0021]
进一步,步骤s2的具体步骤为:
[0022]
s2.1、给定轨迹训练数据集,并从训练轨迹数据集中随机抽取10%的轨迹,基于语义轨迹相似性计算出两两之间的相似度,得到相似度序列sim
e
={sim1,sim2,
……
,sim
k
};
[0023]
s2.2、根据相似度序列和四分位数的位置公式确定四分位数的位置,四分位数的位置公式如下:
[0024][0025]
其中,i的取值为1、2或3,k为相似度序列sim
e
的长度,l1为下四分位数q1在相似度序列中的位置,l2为中位数q2在相似度序列中的位置,l3为上四分位数q3在相似度序列中的位置;
[0026]
s2.3、根据l1、l2、l3计算相应的下四分位数q1、中位数q2以及上四分位数q3,并取相似度阈值∈1为q1,∈2为q3。
[0027]
进一步,步骤s3的具体步骤为:
[0028]
s3.1、从数据轨迹集d中随机选定一条轨迹t
i
,若随机选定轨迹t
i
为首条轨迹,创建轨迹簇,否则,计算轨迹t
i
与轨迹簇的相似度:
[0029]
(1)选择一轨迹簇作为当前轨迹簇,从当前轨迹簇随机选取的一轨迹作为对比的当前轨迹;
[0030]
(2)计算轨迹t
i
与当前轨迹的相似度;
[0031]
(3)若相似度大于等于阈值∈2,则将轨迹t
i
加入当前轨迹簇;
[0032]
(4)若相似度小于等于阈值∈1,判断轨迹簇是否都已比较,若是,新创建一个轨迹簇,将轨迹t
i
加入新创建的轨迹簇,若否,重新选择一轨迹簇作为当前轨迹簇,再转到步骤(2)执行;
[0033]
(5)若相似度大于∈1小于∈2,判断当前轨迹簇中是否还有未与轨迹t
i
进行比较的轨迹,若是,从未比较的轨迹中重新选择一条轨迹作为当前轨迹,再转到步骤(2)执行,若
否,判断轨迹簇是否都已比较,若是,则将轨迹t
i
加入平均相似度最高的轨迹簇,若否,重新选择一轨迹簇作为当前轨迹簇,再转到步骤(2)执行。
[0034]
s3.2、若数据轨迹集中的轨迹都聚类完,得到n个轨迹簇c1,c2,
……
,cn,d=c1∪c2∪
……
∪cn;否则,重复步骤s3.1,直到聚类完成。
[0035]
本发明同现有技术相比,其有益效果表现在:
[0036]
本发明采用了新的轨迹相似度度量方法,与传统的仅考虑空间坐标信息和时间戳的相似性度量方法相比,考虑了轨迹语义信息,不仅能挖掘在时间和位置上相近的轨迹,还能对具有相似运动模式的轨迹进行更深层次的挖掘,提高了聚类结果的语义准确性。
[0037]
本发明在确定密度阈值时,为了避免人为设定参数的影响,使用了箱型图来进行选取,可以反映原始数据分布的特征,很大程度上减少了人为设定阈值导致的聚类不确定性。在此基础上,提出了一种基于剪枝思想的聚类方法,相比传统聚类方法中需要计算所有轨迹点之间的成对相似度,本发明提出相似性具有传递性的思想,大大减少了相似度计算的次数,从而减少了计算量,极大地提高了轨迹聚类的效率。
[0038]
本发明的聚类结果作为轨迹数据分析的基础,对所有基于轨迹数据的应用都具有应用价值,有助于发现车辆或行人的运动模式、热点区域发现、交通事件检测等,对于智能交通领域和旅游路径推荐等有极大帮助。
附图说明
[0039]
图1为本发明的流程图;
[0040]
图2为本发明中轨迹t
i
与轨迹簇的相似度计算的流程图;
[0041]
图3为本发明中位置层次树的示意图。
具体实施方式
[0042]
下面将结合附图及具体实施方式对本发明作进一步的描述。
[0043]
一种基于语义相似度的轨迹聚类方法,如下步骤:
[0044]
s1、基于需要挖掘的数据的应用领域定义语义轨迹,再基于定义的语义轨迹得到语义轨迹相似性;其中,需要挖掘的数据的应用领域为包括经纬度、场景标签、时间和天气信息的社交网络领域、交通领域或旅游领域,以及其它包含了相关数据信息的领域。
[0045]
语义轨迹相似性的步骤如下:
[0046]
s1.1、给定一条语义轨迹序列t
i
={t
i,1
,t
i,2
,
……
,t
i,j
,
……
t
i,n
},其中,n是轨迹的点的个数,t
i,j
是轨迹t
i
的第j个点,t
i,j
由m个属性(p1,p2,
……
,p
m
)组成,m个属性中的各属性由距离属性和语义属性组成;距离属性的公式为:
[0047][0048]
语义属性的公式为:
[0049]
sim
semantic
(p
m
)=h
‑1[0050]
其中,是指轨迹t
i
的第x个点的第m个属性,是指轨迹t
k
的第y个点
的第m个属性,t
i
和t
k
两条轨迹的点的数量相等或不相等,h是和在层次树中最近公共父节点的层数。
[0051]
层次树包括位置层次树、时间层次次和天气层次树等。
[0052]
位置层次树分为居住、工作学习、消费娱乐、交通、服务和文化娱乐,居住包括家和酒店,工作学习包括学校和公司,消费娱乐包括商超(商店和超市)和饭店,交通包括公交站、地铁站和机场,服务包括银行和医院,文化娱乐包括影剧院、音乐厅和舞厅。
[0053]
时间层次树分为凌晨、上午、下午和晚上,凌晨、上午、下午和晚上4个类别为6个小时,分别为0:00
‑
6:00、6:00
‑
12:00、12:00
‑
18:00、8:00
‑
24:00。
[0054]
天气层次树分为降水、凝结冻结、视程障碍、雷电和其他,降水包括雨、雪和雨夹雪,凝结冻结包括露、霜、雾凇和雨凇,视程障碍包括雾、雪暴、霾、沙尘暴、扬沙和浮尘,雷电包括雷暴和闪电,其他包括风、飑、龙卷、尘卷风、冰针、积雪和结冰。
[0055]
s1.2、基于语义轨迹中t
i,j
的m个属性得到语义轨迹相似性。语义轨迹相似性的公式为:
[0056]
sim=w1·
sim
distance
+w2·
∑sim
semantic
(p
m
)
[0057]
其中,w1为空间相似度所占权重,w2为语义相似度所占权重,w1+w2=1。
[0058]
s2、给定轨迹训练数据集,抽取数个轨迹,基于语义轨迹相似性采用箱型图计算相似度阈值;具体步骤为:
[0059]
s2.1、给定轨迹训练数据集,并从训练轨迹数据集中随机抽取10%的轨迹,基于语义轨迹相似性计算出两两之间的相似度,得到相似度序列sim
e
={sim1,sim2,
……
,sim
k
};例如:三条轨迹t1={t
1,1
,t
1,2
,t
1,3
},t2={t
2,1
,t
2,2
,t
2,3
,t
2,4
},t3={t
3,1
,t
3,2
},计算出t1和t2、t1和t3、t2和t3的相似度sim
1,2
、sim
1,3
、sim
2,3
,升序排列得到相似度序列sim
e
。
[0060]
s2.2、根据相似度序列和四分位数的位置公式确定四分位数的位置,四分位数的位置公式如下:
[0061][0062]
其中,i的取值为1、2或3,k为相似度序列sim
e
的长度,l1为下四分位数q1在相似度序列中的位置,l2为中位数q2在相似度序列中的位置,l3为上四分位数q3在相似度序列中的位置;如,如sim
e
={0.1,0.15,0.2,0.24,0.3,0.38,0.41,0.49,0.51,0.59,0.62,0.66,0.68,0.72},k=14,l1=1*(14+1)/4=3.75,l2=2*(14+1)/4=7.5,l3=3*(14+1)/4=11.25,q1=0.2*0.25+0.24*0.75,q2=0.41*0.5+0.49*0.5,q3=0.62*0.75+0.66*0.25。
[0063]
s2.3、根据l1、l2、l3计算相应的下四分位数q1、中位数q2以及上四分位数q3,并取相似度阈值∈1为q1,∈2为q3。例如:l3=11.25,则根据相似度序列中的第11位数和第12位数进行加权计算q3的值,q3=sim
11
*0.75+sim
12
*0.25。
[0064]
s3、基于相似度阈值对轨迹集中的各轨道进行聚类。
[0065]
进一步,s3.1、从数据轨迹集d中随机选定一条轨迹t
i
,若随机选定轨迹t
i
为首条轨迹,创建轨迹簇,否则,计算轨迹t
i
与轨迹簇的相似度:
[0066]
(1)选择一轨迹簇作为当前轨迹簇,从当前轨迹簇随机选取的一轨迹作为对比的当前轨迹;
[0067]
(2)计算轨迹t
i
与当前轨迹的相似度;
[0068]
(3)若相似度大于等于阈值∈2,则将轨迹t
i
加入当前轨迹簇;
[0069]
(4)若相似度小于等于阈值∈1,判断轨迹簇是否都已比较,若是,新创建一个轨迹簇,将轨迹t
i
加入新创建的轨迹簇,若否,重新选择一轨迹簇作为当前轨迹簇,再转到步骤(2)执行;
[0070]
(5)若相似度大于∈1小于∈2,判断当前轨迹簇中是否还有未与轨迹t
i
进行比较的轨迹,若是,从未比较的轨迹中重新选择一条轨迹作为当前轨迹,再转到步骤(2)执行,若否,判断轨迹簇是否都已比较,若是,则将轨迹t
i
加入平均相似度最高的轨迹簇,若否,重新选择一轨迹簇作为当前轨迹簇,再转到步骤(2)执行。
[0071]
s3.2、若数据轨迹集中的轨迹都聚类完,得到n个轨迹簇c1,c2,
……
,cn,d=c1∪c2∪
……
∪cn;否则,重复步骤s3.1,直到聚类完成。
[0072]
以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1