一种基于大数据的简历推送方法与流程
本发明涉及信息技术相关领域,尤其涉及一种基于大数据技术的简历推荐方法。
背景技术:
随着企业间人才竞争的不断加剧,如何在合理预算范围内更快更准地找到人才,已成为企业愈发关注的议题,也是企业人力资源部门(hr)面临的主要挑战。传统的招聘方式是企业的hr通过招聘会现场、报刊广告、人才猎取、员工推荐、校园招聘或从各大招聘网站筛选简历。
这些方式并不能满足企业以及招聘者的需求,首先由于招聘信息的不对称,简历筛选消耗hr大量时间;在招聘过程中,hr大量的时间都是花在简历筛选上,人工筛选简历,简历平均通过率在20%左右,而一些求职者为了省事,因此简历“海投”,这样使得hr每天不得不疲于奔命地不断大量筛选简历,而不能投入足够的精力在相对精准的人才识别上;最后由于信息筛选时间成本高,给企业带来高昂的招聘成本;为此,我们提出一种基于大数据的简历推送方法。
技术实现要素:
针对现有技术存在的不足,本发明目的是提供一种基于大数据的简历推送方法。本发明通过控制中心对简历信息进行审核过滤,排除由于求职人员简历“海投”而造成的明显不符合任职要求的简历信息,提高简历信息质量,减少hr的工作量,缩短信息筛选时间;本发明通过智能排序模块根据推送值对简历信息进行排序,减少hr筛选简历的时间,提高简历通过率,使hr能够投入足够的精力在相对精准的人才识别上,缩短信息筛选的时间成本,给企业带来更好的招聘成果。
本发明的目的可以通过以下技术方案实现:
一种基于大数据的简历推送方法,包括如下步骤:
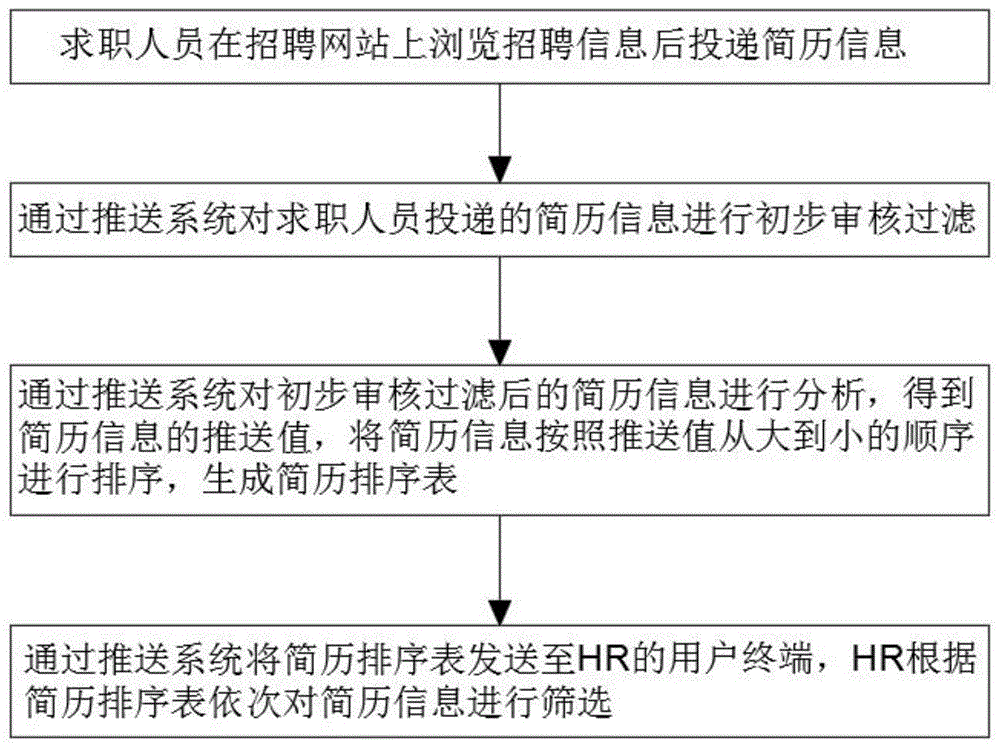
qq1:求职人员在招聘网站上浏览招聘信息后投递简历信息;
qq2:通过推送系统对求职人员投递的简历信息进行初步审核过滤;
qq3:通过推送系统对初步审核过滤后的简历信息进行分析,得到简历信息的推送值,将简历信息按照推送值从大到小的顺序进行排序,生成简历排序表;
qq4:通过推送系统将简历排序表发送至hr的用户终端,hr根据简历排序表依次对简历信息进行筛选;
所述推送系统包括数据库、招聘模块、简历上传模块、控制中心、智能排序模块、筛选模块、监测模块、调查模块、存储模块和兴趣评估模块;
所述数据库用于存储有各个招聘岗位的招聘信息;
所述招聘模块用于展示招聘岗位的招聘信息并供求职人员浏览招聘信息后投递简历或直接投递简历;
所述招聘模块与简历上传模块通信连接,简历上传模块用于求职人员对简历信息进行编辑上传,简历上传模块编辑上传的简历信息经控制中心审核过滤后,将对应的简历信息传输至智能排序模块;
所述智能排序模块用于接收简历信息并对简历信息进行分析,得到简历信息的推送值,智能排序模块将简历信息按照推送值从大到小的顺序进行排序,生成简历排序表,并将简历排序表发送至控制中心,所述控制中心用于将简历排序表发送至筛选模块;
所述筛选模块用于hr根据简历排序表依次对简历信息进行筛选。
进一步地,所述控制中心对简历信息进行审核过滤的方法为:
v1:简历上传模块上传简历信息至控制中心;控制中心对各求职人员上传的简历信息进行简历特征提取,提取出简历特征信息,将简历特征信息存储于数据库,并与相应的简历信息关联;所述简历特征信息包括意向职位、意向工作地、年龄、性别、学历和专业;
v2:获取该简历信息对应的招聘岗位的招聘信息,获取招聘信息对应的任职要求,所述任职要求包括年龄、学历、专业和工作地点;
v3:获取简历特征信息中的意向职位,判断该意向职位与对应的招聘岗位是否一致;若一致,则保留该简历信息,执行下一步,若不一致,则删除该简历信息;
v4:获取简历特征信息中的意向工作地,判断该意向工作地与对应的招聘岗位的工作地点是否一致;若一致,则保留该简历信息,执行下一步,若不一致,则删除该简历信息;
v5:获取简历特征信息中的年龄、学历和专业,将该特征信息与任职要求中年龄、学历和专业一一对比,若对比结果均符合,则保留该简历信息,否则删除该简历信息;
控制中心用于将审核过滤后的简历信息传输至智能排序模块。
进一步地,所述智能排序模块用于接收简历信息并对简历信息进行分析,具体分析步骤为:
步骤一:获取简历信息的投递时间,将投递时间与系统当前时间进行时间差计算获取得到投递时长,将投递时长标记为t1;
步骤二:设定简历信息的丰富度值为dr;
获取简历特征信息中的年龄和学历;将年龄信息分为20岁以下,20-25岁,25-30岁、30-40岁和40岁以上五个档次;
设定每个年龄档次均有一个对应的预设值,将该年龄与所有的年龄档次进行匹配得到对应的年龄预设值并标记为y1;
将学历信息分为高中以下、高中、专科、本科、硕士和博士六个档次;
设定每个学历档次均有一个对应的预设值,将该学历与所有的学历档次进行匹配得到对应的学历预设值并标记为y2;
步骤三:获取求职人员对该招聘岗位的兴趣值g1;
步骤四:获取求职人员的信誉分并标记为x1;
步骤五:将投递时长、丰富度值、年龄预设值、学历预设值、关注值和信誉分进行归一化处理并取其数值;
利用公式ts=t1×a1+dr×a2+y1×a3+y2×a4+g1×a5+x1×a6获取得到简历信息的推送值ts;其中a1、a2、a3、a4、a5和a6均为预设系数。
进一步地,所述监测模块用于采集招聘岗位招聘开始后求职人员的浏览信息并对浏览信息进行分析,得到求职人员对该招聘岗位的第一关注值,具体分析步骤为:
dd1:获取求职人员的浏览信息,浏览信息为求职人员对该招聘岗位的招聘信息的浏览次数和浏览时间;
dd2:将求职人员对该招聘岗位的浏览次数标记为hs;将求职人员对该招聘岗位的浏览时间标记为ts;
dd3:利用公式gs=hs×d1+ts×d2获取得到求职人员对该招聘岗位的第一关注值gs;其中d1、d2为预设系数;
监测模块用于将第一关注值gs传输至控制中心,控制中心用于将第一关注值gs传输至兴趣评估模块,并将第一关注值gs存储到存储模块。
进一步地,所述数据库还存储有各个招聘岗位的关键词;所述调查模块用于当求职人员针对某一招聘岗位投递简历信息后,向第三方网站采集该求职人员的检索信息,并对检索信息进行分析,具体步骤为:
k1:获取该求职人员的检索信息,将检索信息与该招聘岗位的关键词进行匹配,若匹配一致,则将此次检索标记为有效检索;
k2:将有效检索的次数进行累加形成检索频次,并标记为j1;将有效检索的检索时长进行累加形成检索总时长,并标记为j2;
k3:利用公式j3=j1×d3+j2×d4获取得到求职人员对该招聘岗位的第二关注值j3;
调查模块用于将第二关注值j3传输至控制中心,控制中心用于将第二关注值j3传输至兴趣评估模块,并将第二关注值j3存储到存储模块。
进一步地,所述兴趣评估模块用于接收第一关注值、第二关注值并根据第一关注值、第二关注值来评估求职人员对招聘岗位的兴趣值g1,即g1=gs×d5+j3×d6,其中d5、d6均为预设系数。
进一步地,步骤二中简历信息的丰富度值的计算方法为:
s1:获取简历信息中的文字描述,将文字描述的文本大小标记为ws;
s2:获取简历信息中的工作经历信息,将工作经历的次数标记为r1;将工作年限标记为n1;
s3:获取简历信息中的培训经历信息,将培训经历的次数标记为r2;将培训时长标记为n2;
s4:获取简历信息中的荣誉与证书信息,将取得的荣誉数量标记为r3,将取得的证书数量标记为r4;
s5:利用公式dr=ws×a1+r1×a2+n1×a3+r2×a4+n2×a5+r3×a6+r4×a7获取得到简历信息的丰富度值dr,其中a1、a2、a3、a4、a5、a6和a7均为预设系数。
进一步地,步骤四中求职人员的信誉分的计算方法为:
将求职人员的分数设置为预设分xc,当有扣分项时会扣除相应分数,扣分项的具体判定过程如下:
ss1:获取求职人员的征信信息,所述征信信息包括负债、逾期还款记录;
当求职人员有负债时,每一千元负债扣除预设分数e1,将求职人员的负债标记为f1;
当求职人员有逾期还款记录时,扣除预设分数e2,将求职人员的逾期还款次数标记为f2;
ss2:当求职人员有拒绝面试记录时,扣除预设分数e3,将求职人员拒绝面试的次数标记为f3;
当求职人员有拒绝就职记录时,扣除预设分数e4,将求职人员拒绝就职的次数标记为f4;
ss3:利用公式x1=xc-f1/1000×e1-f2×e2-f3×e3-f4×e4获取得到求职人员的信誉分x1。
本发明的有益效果是:
1、本发明通过控制中心对简历信息进行审核过滤;控制中心对各求职人员上传的简历信息进行简历特征提取,提取出简历特征信息,将简历特征信息与对应的招聘岗位的招聘信息进行一一比对,若对比结果均符合,则保留该简历信息,否则删除该简历信息;本发明通过控制中心对简历信息进行审核过滤,排除由于求职人员简历“海投”而造成的明显不符合任职要求的简历信息,提高简历信息质量,减少hr的工作量,缩短信息筛选时间;
2、本发明通过智能排序模块用于接收简历信息并对简历信息进行分析;获取简历信息中的文字描述,将文字描述的文本大小标记为ws;获取简历信息中的工作经历信息,将工作经历的次数标记为r1;将工作年限标记为n1;获取简历信息中的培训经历信息,将培训经历的次数标记为r2;将培训时长标记为n2;获取简历信息中的荣誉与证书信息,将取得的荣誉数量标记为r3,将取得的证书数量标记为r4;利用公式dr=ws×a1+r1×a2+n1×a3+r2×a4+n2×a5+r3×a6+r4×a7获取得到简历信息的丰富度值dr;采集招聘岗位招聘开始后求职人员的浏览信息并对浏览信息进行分析,得到求职人员对该招聘岗位的第一关注值;当求职人员针对某一招聘岗位投递简历信息后,向第三方网站采集该求职人员的检索信息并对检索信息进行分析,得到求职人员对该招聘岗位的第二关注值,根据第一关注值、第二关注值来评估求职人员对招聘岗位的兴趣值g1;再结合简历信息的投递时长、对应的年龄预设值和学历预设值以及求职人员的信誉分,获取得到简历信息的推送值;本发明通过智能排序模块根据推送值对简历信息进行排序,减少hr筛选简历的时间,提高简历通过率,使hr能够投入足够的精力在相对精准的人才识别上,缩短信息筛选的时间成本,给企业带来更好的招聘成果。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明的流程示意图。
图2为本发明中推送系统的系统框图
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1-2所示,一种基于大数据的简历推送方法,包括如下步骤:
qq1:求职人员在招聘网站上浏览招聘信息后投递简历信息;
qq2:通过推送系统对求职人员投递的简历信息进行初步审核过滤;
qq3:通过推送系统对初步审核过滤后的简历信息进行分析,得到简历信息的推送值,将简历信息按照推送值从大到小的顺序进行排序,生成简历排序表;
qq4:通过推送系统将简历排序表发送至hr的用户终端,hr根据简历排序表依次对简历信息进行筛选。
所述推送系统包括数据库、招聘模块、简历上传模块、控制中心、智能排序模块、筛选模块、监测模块、调查模块、存储模块和兴趣评估模块;
所述数据库用于存储有各个招聘岗位的招聘信息;
所述招聘模块用于展示招聘岗位的招聘信息并供求职人员浏览招聘信息后投递简历或直接投递简历;
所述招聘模块与简历上传模块通信连接,简历上传模块用于求职人员对简历信息进行编辑上传,简历上传模块编辑上传的简历信息经控制中心审核过滤后,将对应的简历信息传输至智能排序模块;
所述智能排序模块用于接收简历信息并对简历信息进行分析,得到简历信息的推送值,智能排序模块将简历信息按照推送值从大到小的顺序进行排序,生成简历排序表,并将简历排序表发送至控制中心,所述控制中心用于将简历排序表发送至筛选模块;
所述筛选模块用于hr根据简历排序表依次对简历信息进行筛选;
所述控制中心对简历信息进行审核过滤的方法为:
v1:简历上传模块上传简历信息至控制中心;控制中心对各求职人员上传的简历信息进行简历特征提取,提取出简历特征信息,将简历特征信息存储于数据库,并与相应的简历信息关联;所述简历特征信息包括意向职位、意向工作地、年龄、性别、学历和专业;
v2:获取该简历信息对应的招聘岗位的招聘信息,获取招聘信息对应的任职要求,所述任职要求包括年龄、学历、专业和工作地点;
v3:获取简历特征信息中的意向职位,判断该意向职位与对应的招聘岗位是否一致;若一致,则保留该简历信息,执行下一步,若不一致,则删除该简历信息;
v4:获取简历特征信息中的意向工作地,判断该意向工作地与对应的招聘岗位的工作地点是否一致;若一致,则保留该简历信息,执行下一步,若不一致,则删除该简历信息;
v5:获取简历特征信息中的年龄、学历和专业,将该特征信息与任职要求中年龄、学历和专业一一对比,若对比结果均符合,则保留该简历信息,否则删除该简历信息;
控制中心用于将审核过滤后的简历信息传输至智能排序模块;
本发明通过控制中心对简历信息进行审核过滤,排除由于求职人员简历“海投”而造成的明显不符合任职要求的简历信息,提高简历信息质量,减少hr的工作量,缩短信息筛选时间;
所述智能排序模块用于接收简历信息并对简历信息进行分析,具体分析步骤为:
步骤一:获取简历信息的投递时间,将投递时间与系统当前时间进行时间差计算获取得到投递时长,将投递时长标记为t1;
步骤二:设定简历信息的丰富度值为dr;
获取简历特征信息中的年龄和学历;将年龄信息分为20岁以下,20-25岁,25-30岁、30-40岁和40岁以上五个档次;
设定每个年龄档次均有一个对应的预设值,将该年龄与所有的年龄档次进行匹配得到对应的年龄预设值并标记为y1;
将学历信息分为高中以下、高中、专科、本科、硕士和博士六个档次;
设定每个学历档次均有一个对应的预设值,将该学历与所有的学历档次进行匹配得到对应的学历预设值并标记为y2;
步骤三:获取求职人员对该招聘岗位的兴趣值g1;
步骤四:获取求职人员的信誉分并标记为x1;
步骤五:将投递时长、丰富度值、年龄预设值、学历预设值、关注值和信誉分进行归一化处理并取其数值;
利用公式ts=t1×a1+dr×a2+y1×a3+y2×a4+g1×a5+x1×a6获取得到简历信息的推送值ts;其中a1、a2、a3、a4、a5和a6均为预设系数,例如a1取值0.23,a2取值0.17,a3取值0.28,a4取值0.59,a5取值0.67,a6取值0.48;
监测模块用于采集招聘岗位招聘开始后求职人员的浏览信息并对浏览信息进行分析,得到求职人员对该招聘岗位的第一关注值,具体分析步骤为:
dd1:获取求职人员的浏览信息,浏览信息为求职人员对该招聘岗位的招聘信息的浏览次数和浏览时间;
dd2:将求职人员对该招聘岗位的浏览次数标记为hs;将求职人员对该招聘岗位的浏览时间标记为ts;
dd3:利用公式gs=hs×d1+ts×d2获取得到求职人员对该招聘岗位的第一关注值gs;其中d1、d2为预设系数;例如d1取值0.4,d2取值0.6;
监测模块用于将第一关注值gs传输至控制中心,控制中心用于将第一关注值gs传输至兴趣评估模块,并将第一关注值gs存储到存储模块;
所述数据库还存储有各个招聘岗位的关键词,例如,a招聘岗位的关键词为“cad绘图”、“设计”、“营销”等;
所述调查模块用于当求职人员针对某一招聘岗位投递简历信息后,向第三方网站采集该求职人员的检索信息,例如第三方网站为百度网站和图书馆书籍借阅网;并对检索信息进行分析,具体步骤为:
k1:获取该求职人员的检索信息,将检索信息与该招聘岗位的关键词进行匹配,若匹配一致,则将此次检索标记为有效检索;例如,对于a招聘岗位而言,若求职人员的检索信息带有“cad绘图”、“设计”、“营销”这三个关键词中的一个或多个时,则匹配一致,此次检索为有效检索;或者求职人员在图书馆借阅过带有“cad绘图”、“设计”、“营销”这三个关键词中的一个或多个的书籍时,则匹配一致,此次借阅为有效借阅;
k2:将有效检索的次数进行累加形成检索频次,并标记为j1;将有效检索的检索时长进行累加形成检索总时长,并标记为j2;
k3:利用公式j3=j1×d3+j2×d4获取得到求职人员对该招聘岗位的第二关注值j3;其中d3、d4均为预设系数;例如d3取值0.43,d4取值0.37;
调查模块用于将第二关注值j3传输至控制中心,控制中心用于将第二关注值j3传输至兴趣评估模块,并将第二关注值j3存储到存储模块;
所述兴趣评估模块用于接收第一关注值、第二关注值并根据第一关注值、第二关注值来评估求职人员对招聘岗位的兴趣值g1,即g1=gs×d5+j3×d6,其中d5、d6均为预设系数;例如d5取值0.46,d6取值0.59;
所述简历信息的丰富度值的计算方法为:
s1:获取简历信息中的文字描述,将文字描述的文本大小标记为ws;
s2:获取简历信息中的工作经历信息,将工作经历的次数标记为r1;将工作年限标记为n1;
s3:获取简历信息中的培训经历信息,将培训经历的次数标记为r2;将培训时长标记为n2;
s4:获取简历信息中的荣誉与证书信息,将取得的荣誉数量标记为r3,将取得的证书数量标记为r4;
s5:利用公式dr=ws×a1+r1×a2+n1×a3+r2×a4+n2×a5+r3×a6+r4×a7获取得到简历信息的丰富度值dr,其中a1、a2、a3、a4、a5、a6和a7均为预设系数,例如a1取值0.23,a2取值0.29,a3取值0.31,a4取值0.17,a5取值0.46,a6取值0.48,a7取值0.61;
所述求职人员的信誉分的计算方法为:
将求职人员的分数设置为预设分xc,当有扣分项时会扣除相应分数,扣分项的具体判定过程如下:
ss1:获取求职人员的征信信息,所述征信信息包括负债、逾期还款记录;
当求职人员有负债时,每一千元负债扣除预设分数e1,将求职人员的负债标记为f1;
当求职人员有逾期还款记录时,扣除预设分数e2,将求职人员的逾期还款次数标记为f2;
ss2:当求职人员有拒绝面试记录时,扣除预设分数e3,将求职人员拒绝面试的次数标记为f3;
当求职人员有拒绝就职记录时,扣除预设分数e4,将求职人员拒绝就职的次数标记为f4;
ss3:利用公式x1=xc-f1/1000×e1-f2×e2-f3×e3-f4×e4获取得到求职人员的信誉分x1。
本发明的工作原理是:
一种基于大数据的简历推送方法,在工作时,招聘模块用于展示招聘岗位的招聘信息并供求职人员浏览招聘信息后投递简历或直接投递简历;控制中心对简历信息进行审核过滤;控制中心对各求职人员上传的简历信息进行简历特征提取,提取出简历特征信息,将简历特征信息与对应的招聘岗位的招聘信息进行一一比对,若对比结果均符合,则保留该简历信息,否则删除该简历信息;本发明通过控制中心对简历信息进行审核过滤,排除由于求职人员简历“海投”而造成的明显不符合任职要求的简历信息,提高简历信息质量,减少hr的工作量,缩短信息筛选时间;
智能排序模块用于接收简历信息并对简历信息进行分析;获取简历信息中的文字描述,将文字描述的文本大小标记为ws;获取简历信息中的工作经历信息,将工作经历的次数标记为r1;将工作年限标记为n1;获取简历信息中的培训经历信息,将培训经历的次数标记为r2;将培训时长标记为n2;获取简历信息中的荣誉与证书信息,将取得的荣誉数量标记为r3,将取得的证书数量标记为r4;利用公式dr=ws×a1+r1×a2+n1×a3+r2×a4+n2×a5+r3×a6+r4×a7获取得到简历信息的丰富度值dr;采集招聘岗位招聘开始后求职人员的浏览信息并对浏览信息进行分析,得到求职人员对该招聘岗位的第一关注值;当求职人员针对某一招聘岗位投递简历信息后,向第三方网站采集该求职人员的检索信息并对检索信息进行分析,得到求职人员对该招聘岗位的第二关注值,根据第一关注值、第二关注值来评估求职人员对招聘岗位的兴趣值g1;再结合简历信息的投递时长、对应的年龄预设值和学历预设值以及求职人员的信誉分,获取得到简历信息的推送值,智能排序模块将简历信息按照推送值从大到小的顺序进行排序,生成简历排序表,并将简历排序表发送至控制中心,所述控制中心用于将简历排序表发送至筛选模块;所述筛选模块用于hr根据简历排序表依次对简历信息进行筛选,本发明通过智能排序模块根据推送值对简历信息进行排序,减少hr筛选简历的时间,提高简历通过率,使hr能够投入足够的精力在相对精准的人才识别上,缩短信息筛选的时间成本,给企业带来更好的招聘成果。
上述公式均是由采集大量数据进行软件模拟及相应专家进行参数设置处理,得到与真实结果符合的公式。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!