一种产品评论的情感倾向分析系统及方法与流程
1.本发明公开一种系统及方法,涉及自然语言处理中的情感分析领域,具 体地说是一种产品评论的情感倾向分析系统及方法。
背景技术:
2.互联网时代,各种社交媒体、电商网站、社会服务网站等快速兴起和发 展,于是互联网(如微博、淘宝等)上产生了非常大量的关于用户对商品、 服务、新闻等不同事物的评论,这些评论中表达了人们对事物的个人态度和 情感倾向,如喜欢、厌恶、赞同和反对等,无论是公司还是个人都能从中得 到大量有价值的潜在信息,于是,在公司层面,从用户评论中分析、挖掘用 户对公司产品的情感倾向,对于提高公司产品的质量,开拓公司的市场都具 有深远的意义。因此,各个大厂为了提高产品竞争力,都开始关注自己产品 的用户评论信息,以从中挖掘出有价值的信息。然而用户评论中可能存在 大量的重复冗余信息,增加关键词提取难度,同时冗余信息可能增加后续模 型训练的参数,不利于模型更简单轻量,不便使用,从而不能让公司能更 好地规划产品,更好地服务客户,提高客户对公司的满意度。
技术实现要素:
3.本发明针对现有技术的问题,提供一种产品评论的情感倾向分析系统及 方法,利用tfidf算法对其进行关键词提取,以使后续模型训练的参数更少, 模型更简单轻量,以帮助公司能更好地规划产品,更好地服务客户,提高客 户对公司的满意度。
4.本发明提出的具体方案是:
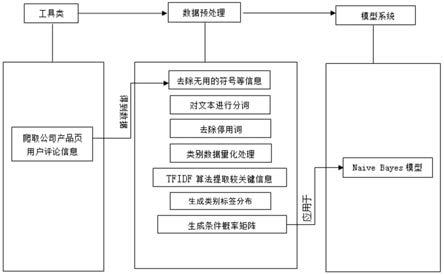
5.一种产品评论的情感倾向分析方法,爬取产品的产品评论及相关信息,
6.对产品评论及相关信息进行预处理,
7.利用tfidf算法预处理后产品评论及相关信息的数据进行关键词提取, 并统一文档所属类别的概率,生成文档类别的标签分布,同时生成条件概率 矩阵,
8.利用naive bayes模型通过标签分布和概率矩阵进行产品评论所属情感 倾向类别的判定。
9.优选地,所述的一种产品评论的情感倾向分析方法中爬取产品评论页的 html页面并抽取产品评论相关信息,获得初始数据集,对初始数据集进行 预处理,获得预处理后的数据集,
10.利用tfidf算法对预处理后的数据集的词向量提取关键词,利用naivebayes算法训练模型,获得naive bayes模型。
11.优选地,所述的一种产品评论的情感倾向分析方法中预处理包括:
12.去除无用的符号信息,
13.对产品评论文本进行分词,去除停用词,
14.对产品评论中类别数据进行量化处理,
15.对产品评论文本数据进行序列化处理。
16.优选地,所述的一种产品评论的情感倾向分析方法中利用tfidf算法将 tfidf矩阵中属于相同类别的文档向量相加,形成m*n的矩阵,m代表类别数, n代表词典数,将每一个词的权重与所在类别的所有词的总权重相比,生成 条件概率矩阵。
17.一种产品评论的情感倾向分析系统,包括爬取模块、预处理模块、分析 模块及判定模块,
18.爬取模块爬取产品的产品评论及相关信息,
19.预处理模块对产品评论及相关信息进行预处理,
20.分析模块利用tfidf算法预处理后产品评论及相关信息的数据进行关 键词提取,并统一文档所属类别的概率,生成文档类别的标签分布,同时生 成条件概率矩阵,
21.判定模块利用naive bayes模型通过标签分布和概率矩阵进行产品评论 所属情感倾向类别的判定。
22.优选地,所述的一种产品评论的情感倾向分析系统中爬取模块爬取产品 评论页的html页面并抽取产品评论相关信息,获得初始数据集,预处理模 块对初始数据集进行预处理,获得预处理后的数据集,
23.分析模块利用tfidf算法对预处理后的数据集的词向量提取关键词,利 用naive bayes算法训练模型,获得naive bayes模型。
24.优选地,所述的一种产品评论的情感倾向分析系统中预处理模块进行预 处理包括:
25.去除无用的符号信息,
26.对产品评论文本进行分词,去除停用词,
27.对产品评论中类别数据进行量化处理,
28.对产品评论文本数据进行序列化处理。
29.优选地,所述的一种产品评论的情感倾向分析系统中分析模块利用 tfidf算法将tfidf矩阵中属于相同类别的文档向量相加,形成m*n的矩阵, m代表类别数,n代表词典数,将每一个词的权重与所在类别的所有词的总 权重相比,生成条件概率矩阵。
30.本发明的有益之处是:
31.本发明提供一种产品评论的情感倾向分析方法,对爬取到的用户评论相 关信息的预处理,利用tfidf算法,对处理好后的用户评论数据进行关键词 提取,利用naive bayes模型用于用户评论的情感倾向分析。本发明利用了 简单高效的tfidf算法提取用户评论中的关键词,去除了文本中的冗余信息, 之后运用简单可解释性强的naive bayes模型,实现了公司产品用户评论的 情感喜恶分析,为公司产品的后续迭代升级提供了一个有价值的参考方向, 避免了单一人员对产品定位的主观性,同时节省了传统调查中大量所需的人 力、物力和金钱成本,对于提高公司产品的用户体验度和满意度、产品的交 易具有重要的意义。
附图说明
32.图1是本发明方法框架流程示意图。
具体实施方式
33.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术 人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的 限定。
34.互联网时代,发表言论的途径日益增加,互联网上产生了大量的关于商 品、服务、热点等的评论信息,这些评论信息表达了对这些事物不同的观点 和态度,从这些信息中,无论个人还是企业,都能从中挖掘出对自己有益的 信息,对于个人,可以大概了解一件商品的性价比等信息以帮助我们决策这 件商品是否值得购买;对于企业,可以从中看出客户对公司产品的满意度和 忠诚度等信息以帮助企业更好地规划产品定位和营销群体等,对更好地服务 客户有一个比较清晰的方向。
35.而本发明提供一种产品评论的情感倾向分析方法,爬取产品的产品评论 及相关信息,
36.对产品评论及相关信息进行预处理,
37.利用tfidf算法预处理后产品评论及相关信息的数据进行关键词提取, 并统一文档所属类别的概率,生成文档类别的标签分布,同时生成条件概率 矩阵,
38.利用naive bayes模型通过标签分布和概率矩阵进行产品评论所属情感 倾向类别的判定。
39.本发明方法结合tfidf和naive bayes算法对公司产品评论作了一个用 户情感倾向分析,以帮助公司能更好地规划产品,更好地服务客户,提高客 户对公司的满意度。
40.具有应用中,在本发明的一些实施例中,具体过程为:
41.s1:爬取公司产品评论页的html页面并抽取出其中的评论相关信息, 得到初始的数据集;
42.s2:对初始数据集进行预处理:包括去除无用的符号等信息,对文本进 行分词,去除停用词,对类别数据进行量化处理,对文本数据进行序列化处 理等步骤,得到预处理后的数据集;
43.s3:对预处理后的数据集的词向量应用tfidf算法提取出用户评论中的 较关键信息,去除一些冗余信息,以减少训练naive bayes模型中的参数个 数,降低训练模型的复杂性;
44.s4统计某一文档属于某一类的概率,生成类别标签分布p(y);
45.s5将tfidf矩阵中属于相同类别的文档向量相加,形成m*n的矩阵,m 代表类别数,n代表词典数,将每一个词的权重除以该类所有词的总权重, 生成条件概率矩阵p(x|y);
46.s6根据naive bayes模型中bayes公式y
i
=max(p(x|y
i
)*p(y
i
))判定评论所 属情感倾向类别。
47.上述实施例利用tfidf算法进行关键词提取,以使训练模型更简单轻量, tfidf算法利用某个词语出现的频率来计算这个词的得分,来提取最终的若 干关键词,结合naive bayes算法进行产品用户评论的情感倾向分析,为公 司产品定位和服务提供了一个有价值的参考。
48.同时本发明还提供一种产品评论的情感倾向分析系统,包括爬取模块、 预处理模块、分析模块及判定模块,
49.爬取模块爬取产品的产品评论及相关信息,
50.预处理模块对产品评论及相关信息进行预处理,
51.分析模块利用tfidf算法预处理后产品评论及相关信息的数据进行关 键词提取,并统一文档所属类别的概率,生成文档类别的标签分布,同时生 成条件概率矩阵,
52.判定模块利用naive bayes模型通过标签分布和概率矩阵进行产品评论 所属情感倾向类别的判定。
53.上述系统内的各模块之间的信息交互、执行过程等内容,由于与本发明 方法实施例基于同一构思,具体内容可参见本发明方法实施例中的叙述,此 处不再赘述。
54.本发明系统同样利用tfidf算法进行关键词提取,以使训练模型更简单 轻量,tfidf算法利用某个词语出现的频率来计算这个词的得分,来提取最 终的若干关键词,结合naive bayes算法进行产品用户评论的情感倾向分析, 为公司产品定位和服务提供了一个有价值的参考。
55.以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明 的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替 代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为 准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1