一种智能相册的实现方法及系统、电子装置及存储介质与流程
1.本申请涉及智能相册技术领域,具体涉及一种智能相册的实现方法、系统、电子装置及存储介质。
背景技术:
2.目前的电子设备里均设置有电子相册的功能,以供人们查看电子设备内的图片。
3.现有的一些电子相册具备人脸聚类的功能,可以把相同人脸的图片聚类在一个文件夹内,以方便用户查看关注的人的图片。
4.但是,现有的电子相册只能将相同人脸的图片聚类在一个文件夹内,使得该文件夹内的图片较为杂乱,为用户浏览图片增加了困扰。
技术实现要素:
5.鉴于此,本申请提供一种智能相册的实现方法,以解决现有的电子相册只能将相同人脸的图片聚类在一个文件夹内,使得该文件夹内的图片较为杂乱,为用户浏览图片增加了困扰的问题。
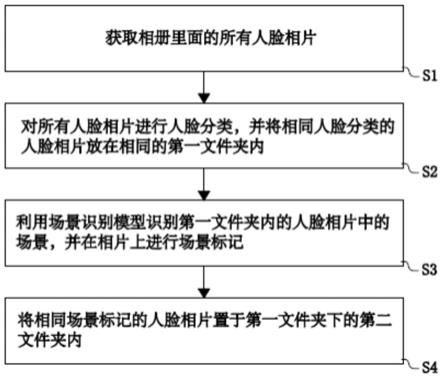
6.本申请第一方面提供一种智能相册的实现方法,包括:获取相册里面的所有人脸相片;对所有人脸相片进行人脸分类,并将相同人脸分类的人脸相片放在相同的第一文件夹内;利用场景识别模型识别所述第一文件夹内的人脸相片中的场景,并在人脸相片上进行场景标记;将相同场景标记的人脸相片置于所述第一文件夹下的第二文件夹内。
7.其中,所述方法还包括:将所述第一文件夹内的人脸相片输入预先训练的表情识别模型,所述表情识别模型用于识别人脸相片中的人脸表情,并在人脸相片上进行表情标记;接收所述表情识别模型输出的每张人脸相片的表情标记;将相同表情标记的人脸相片聚类在所述第一文件夹下的第三文件夹内。
8.其中,所述对所有人脸相片进行人脸分类包括:利用方向梯度直方图特征提取的方法提取人脸相片的浅层特征;利用预先训练的pcanet 网络模型提取人脸相片的深层特征;利用rslda算法对所述浅层特征及所述深层特征进行提炼;对提炼后的浅层特征及深层特征进行融合,得到融合特征;将所述融合特征输入预先训练的支持向量机进行分类,以对人脸相片进行人脸分类。
9.其中,所述场景识别模型的训练方法包括:构建语义分割网络,用于接收人脸相片,输出得分特征图;构建语义特征提取网络,用于接收所述得分特征图,输出语义特征图;构建rgb特征提取网络,用于接收人脸相片,输出rgb特征图;构建注意力特征提取网络,用于接收所述语义特征图及所述rgb特征图,输出注意力特征图;构建分类网络层,用于接收所述注意力特征图,输出人脸相片的场景分类,包括依次构建的平均池化层、随机失活层及全连接层;将具有场景标签的场景样本图像输入训练场景识别模型进行训练。
10.其中,所述表情识别模型的训练方法如下:构建第一核卷积块层及第一最大池化层;构建第二核卷积块层及第二最大池化层;构建第三核卷积块层及第三最大池化层;构建
第四核卷积块层及第四最大池化层;构建第五核卷积块层及第五最大池化层;构建全连接层及输出层;将具有表情标签的表情样本图像输入表情识别模型行训练。
11.其中,所述智能相册的实现方法还包括:获取对所有人脸相片进行人脸分类类别的第一数量,并根据所述第一数量建立相同数量的第一文件夹;获取不同的所述场景标记的第二数量,并根据所述第二数量建立相同数量的第二文件夹;获取不同的所述表情标记的第三数量,并根据所述第三数量建立相同数量的第三文件夹。
12.其中,所述方法还包括:利用人脸分类的类别对所述第一文件夹命名;利用所述场景标记为所述第二文件夹命名;利用所述表情标记为所述第三文件夹命名。
13.本申请上述的智能相册的实现方法,通过使用对人脸分类后进行场景标记,能够在人脸分类后进一步对人脸相片进行分类,从而降低了文件夹内图片的杂乱程度,因此减少了用户浏览图片的困扰。
14.本申请第二方面提供一种智能相册的实现系统,包括:相片获取模块,用于获取相册里面的所有人脸相片;分类模块,用于对所有人脸相片进行人脸分类,并将相同人脸分类的人脸相片放在相同的第一文件夹内;场景标记模块,用于利用场景识别算法识别所述第一文件夹内的人脸人脸相片中的场景,并在人脸相片上进行场景标记;相片放置模块,用于将相同场景标记的人脸相片置于所述第一文件夹下的第二文件夹内。
15.本申请上述的智能相册的实现系统,场景识别模块通过使用场景识别模型,能够在对人脸分类后进行场景标记,从而在分类模块对人脸分类后进一步对人脸相片进行分类,从而降低了文件夹内图片的杂乱程度,因此减少了用户浏览图片的困扰。
16.本申请第三方面提供一种电子装置,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述中的任意一项所述智能相册的实现。
17.本申请第四方面提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述中的任意一项所述智能相册的实现。
附图说明
18.为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
19.图1是本申请实施例智能相册的实现方法的流程示意图;
20.图2是本申请实施例智能相册的实现方法的语义特征网络的结构示意图;
21.图3是本申请实施例智能相册的实现方法的rgb特征提取网络的结构示意图;
22.图4是本申请实施例智能相册的实现方法的人脸表情识别模型结构的结构示意图;
23.图5是本申请实施例智能相册的实现系统的结构示意框图;
24.图6是本申请实施例电子装置的结构示意框图。
具体实施方式
25.下面结合附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而非全部实施例。基于本申请中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。在不冲突的情况下,下述各个实施例及其技术特征可以相互组合。
26.请参阅图1,本申请实施例提供一种智能相册的实现方法,包括: s1、获取相册里面的所有人脸相片;s2、对所有人脸相片进行人脸分类,并将相同人脸分类的人脸相片放在相同的第一文件夹内;s3、利用场景识别模型识别第一文件夹内的人脸相片中的场景,并在相片上进行场景标记;s4、将相同场景标记的人脸相片置于第一文件夹下的第二文件夹内。
27.当相册中有相片时,能够相同人脸分类的相片放在相同的第一文件夹内,并将不同场景的人脸相片放在第一文件夹下的第二文件夹内,用户浏览电子相册时,进入第一文件夹后,会有若干表示不同场景的第二文件夹,例如表示海边、树林、树林、逛街、骑车等场景的文件夹,一个第二文件夹内都是同样场景的人脸相片,因此降低了文件夹内图片的杂乱程度,从而可以使得用户根据自己的喜好浏览关注的人的同一场景的相片,从而减少了用户浏览图片的困扰。
28.在一个实施例中,智能相册的实现方法还包括:将第一文件夹内的人脸相片输入预先训练的表情识别模型,表情识别模型用于识别人脸相片中的人脸表情,并在人脸相片上进行表情标记;接收表情识别模型输出的每张人脸相片的表情标记;将相同表情标记的人脸相片聚类在第一文件夹下的第三文件夹内。
29.通过使用表情识别模型,能够将同一人的形同或相似表情的图像放在一个第三文件夹内,用户浏览电子相册时,进入第一文件夹后,会有若干表示不同表情的第三文件夹,例如表示欢笑、流泪、忧伤、自然表情等表情的文件夹,一个第三文件夹内都是一个人相同或相似的人脸照片,因此降低了文件夹内图片的杂乱程度,从而可以使得用户根据自己的喜好浏览关注的人的相同或相似表情的照片,从而减少了用户浏览量图片的困扰。
30.在一个实施例中,对所有人脸相片进行人脸分类包括:利用方向梯度直方图特征提取的方法提取相片的浅层特征;利用预先训练的 pcanet网络模型提取相片的深层特征;利用rslda算法对浅层特征及深层特征进行提炼;对提炼后的浅层特征及深层特征进行融合,得到融合特征;将融合特征输入预先训练的支持向量机进行分类,以对人脸相片进行人脸分类。
31.方向梯度直方图特征(hog,histogram of oriented gradient),是图像的一种局部特征描述符,利用方向梯度直方图特征提取的方法提取相片的浅层特征包括:
32.将人脸相片划分成多个区域;计算每个区域的梯度直方图,再将每个区域划分成几块,计算每块的梯度直方图并串联,构成该区域特征;将所有区域特征串联起来构成图像的hog特征描述符,即图像的浅层特征。
33.pcanet网络模型在每个阶段选用经典的pca滤波器作卷积核;非线性层选用最简单的二进制量化(哈希编码);特征池化层采用逐块二进制码直方图作为最终的网络输出特征。
34.假设有n个输入训练图像大小为m
×
n,设每个阶段滤波器的大小都为k1×
k2,pcanet模型中只需根据输入图像集学习pca滤波器,pcanet网络模型的每个阶段的工作
过程如下,训练图像为人脸相片样本:
35.第一阶段(pca):对每个像素取大小为k1×
k2的块,第i个图像的所有块构成集合即,x
i,1
,x
i,2
,
…
,其中x
i,j
表示图像i
i
中的第j个向量化模块,其中[z]表示大于或等于 z的最小整数。然后,各模块减去块均值得到其中为减去均值后的块。对所有输入图像进行相同的操作并把结果合并起来得到
[0036]
假设第i层滤波器个数为li,pca最小化造成的正交滤波器的重构误差即:
[0037][0038]
其中,v为特征向量,为大小为l1×
i1的单位矩阵。上述优化问题的解是xx
t
的l1个主要特征向量。因此pca滤波器可表述为其中是将映射成矩阵的函数,q
l
(xx
t
)表示xx
t
的第l个主成分。
[0039]
第二阶段(pca)与第一阶段相似,令第一阶段第l个滤波器的输出为:
[0040][0041]
其中,*表示2d卷积。在卷积操作之前对i
i
的边界进行零填充,这样i
il
与i
i
尺寸一样。与第一阶段一样,令所有的块减去块均值。
[0042]
rslda算法进一步对深浅层特征进行提炼。rslda算法可自适应选取最具判别性的特征,提取的特征不仅能保留大部分能量,且对噪声具有一定的鲁棒性。
[0043]
设有数据集x=[x1,x2,
…
,x
n
]∈r
m
×
n
(m表示样本维数,n表示样本个数),rslda采用l
2,1
范数,优化方程如下:
[0044]
tr(q
t
(s
w
‑
us
b
)q)+λ1||q||
2,1
+λ2||e||1[0045]
x=pq
t
x+e,p
t
p=i
ꢀꢀ
(3)
[0046]
其中,q∈r
m
×
d
(d<m)为判别性投影矩阵;s
b
和s
w
分别为类间和类内散度矩阵;λ1为平衡参数,u为一个小的正常数用于平衡两个散度矩阵。通过采用l
2,1
范数,式(3)可自适应分配特征权重。其中约束条件 x=pq
t
x,p
t
p=i可以看作pca的变体用以保留能量,p∈r
m
×
d
为正交重构矩阵。λ2为平衡参数,e表示误差,是对随机噪声的建模。
[0047]
对任意一张给定的图像i,采用hog算法提取图像的浅层局部特征,记为i
h
,考虑到数据的分布特点,采用rslda进一步对hog特征进行降维,同时在保留数据分布的基础上提取数据的全局特征,此时特征记为i
hr
,因此本文算法的浅层特征中包含了局部
‑
全局特征,且保留数据分布性;同时本算法采用pcanet提取网络的深度特征记为i
p
,同样采用rslda对pcanet特征进行降维,降维后的特征记为i
pr
;在特征融合阶段首先采用串联的形式将深浅特征进行简单融合得到 i
hp
=[i
hp
,i
pr
],因融合后的特征会存在一定的冗余信息,因此进一步采用rslda对i
hp
进行降维,同时也提炼出i
hp
中最具判别力的特征,这也是对深浅特征的进一步融合;最后,使用支持向量机(svm,support vector machine)分类器进行分类。
[0048]
在一个实施例中,场景识别模型的训练方法包括:构建语义分割网络,用于接收人脸相片,输出得分特征图;构建语义特征提取网络,用于接收得分特征图,输出语义特征图;构建rgb特征提取网络,用于接收人脸相片,输出rgb特征图;构建注意力特征提取网络,用于接收语义特征图及rgb特征图,输出注意力特征图;构建分类网络层,用于接收注意力特征图,输出人脸相片的场景分类,包括依次构建的平均池化层、随机失活层及全连接层;将具有场景标签的场景样本图像输入训练场景识别模型进行训练。
[0049]
请参阅图2,在该实施例中,语义特征网络包括依次构建的第一卷积批量归一化层、第一激活函数层、第一最大池化层、第二卷积批量归一化层、第一语义注意力模块、第二激活函数层、第三卷积批量归一化层、第二语义注意力模块、第三激活函数层、第四卷积批量归一化层、第三语义注意力模块、第四激活函数层组成,语义注意力模块包括依次构建的卷积批量归一化层、最大池化层、平均池化层、全连接层、激励函数层、最大池化层、平均池化层、激励函数层、激活函数层,图中
⊙
代表哈达玛积。
[0050]
请参阅图3,rgb特征提取网络包括依次构建的卷积批量归一化层、第一激活函数层、最大池化层、第一提取层、第二激活函数层、第二提取层、第三激活函数层、第三提取层、第四激活函数层、第四提取层、第五激活函数层,图中代表加和。
[0051]
第一提取层、第二提取层、第三提取层、第四提取层结构相同,均由依次的卷积批量归一化层、激活函数层、卷积批量归一化层、激活函数层、卷积批量归一化层、激活函数层。
[0052]
注意力特征提取网络包括依次构建的第一网络及第二网络,第一网络包括依次的第一卷积批量归一化层、第一激活函数层、第二卷积批量归一化层、第二激活函数层、激励函数层,用于提取所述语义特征图的注意力,第二网络包括依次的第一批量归一化层、第三激活函数层、第二批量归一化层、第四激活函数层,用于提取rgb特征图的注意力。
[0053]
分类网络层包括平均池化层、随机失活层及全连接层。
[0054]
在该实施例中,场景识别模型具有rgb特征提取网络构成的rgb 分支,以及语义分割网络及语义特征提取网络构成的语义分支,语义分支基于语义分割网络提取的表示了场景物体及物体关系的得分特征图,从中提取具有辨识力的语义注意力特征图。然后注意力模块使用该特征图对rgb分支从输入彩色图像中提取的特征图进行门控,通过这个过程将网络的注意力重新聚焦到话义分支学习到的有着区分力的特定物体上。提出的网络架构使用经过归一化后的彩色rgb图像i∈r
w
×
h
×3作为语义分割网络和rgb分支的共同输入,语义分割网络输出一个得分特征图m∈r
w
×
h
×
l
,l表示学习的语义标签数。因此该特征图的每一个深度列m
i,j
∈r
w
×
h
×
l
表示第i,j个像素在l个语义标签上的概率分布。整个网络使用通道分离conv(卷积层)+bn(批量归一化层)接relu(激活函数层)的层组合模式,在relu激活层之前应用批标准化,删除任何在标准化中出现的负值(包括之前为非负的值)激活。
[0055]
rgb分支接收输入图像i返回一组基于rgb的特征图其中w
o
,h
o
,c
o
,分别为输出特征图的宽度、高度和通道数。该分支是由原始resnet
‑
50的骨干网络(删去网络尾部的平局池化层和全连接层) 改进而来,在构造块中间实现了4组残差连接组合块,每个组合分别含有3、4、6、3个残差块,f
i
通过最后个组合块得到,然后作为输入进入注意力模块。
[0056]
语义分支的真正输入是语义分割得分特征图m,通过语义分割网络基于给定输入
图像ⅰ预先推理得到。由于m编码了场景中的特定物体和它们对应的空间位置关系,这些物体具有明确的语义并且属于场景中的代表性物体,所以语义分支输出一组基于语义的特征图该组特征图从空间和通道维度建模了语义标签及其语义相互依赖性,作为注意力模块的另一个输入。因为得分特征图m缺少rgb图像中的纹理和材质信息,所以语义分支使用了一个浅层网络,它的输出特征图维度和rgb分支相同。网络中的三个语义注意力模块穿插在通道分离卷积层之间以增强与场景相关语义类的表示。语义注意力模块通过两个阶段 (通道注意力阶段和空间注意力阶段)中的sigmoid激活层(激励函数层)产生的语义注意力特征图(m
c
和m
s
)映射输入特征各通道和空间各部分的重要程度,使输出特征图的一些通道和空间特征被加强,另一些被抑制。在第一个阶段中,由于每个通道表示一个语义类的概率,通道注意力阶段强制网络聚焦到加强的类上。该阶段接收任意大小的输入量特征图f
i,n
∈r
w'
×
h'
×
c'
,分别通过最大池和平均池操作从空间维度对f
i,n
进行压缩,得到两个单独的特征向量和然后经过共享的fc层relu 激活层、fc层得到对应的特征向量f
1c
和见式(4)和式(5),其中φ是relu激活函数分别是两个共享全连接层的权重,r是降维比例因子,在实验中被设置为16。f
1c
和进行加和操作后通过sigmoid 激活层的规范化产生一维的映射到区间(0,1)的通道注意力特征图m
c
见式(6),其中σ是sigmoid激活函数。
[0057][0058][0059][0060]
通道注意力特征图m
c
对输入特征f
in
进行逐通道加权得到第一阶段的输出特征图f
mid
,见式(7),其中
⊙
是哈达玛积。
[0061]
f
mid
=m
c
(f
in
)
⊙
f
in
ꢀꢀ
(7)
[0062]
在第二个阶段,即空间注意力阶段中,f
mid
作为输入特征图经过和第一个阶段类似的处理得到空间注意力特征图m
s
。通过两条并行的最大池化和平均池化操作分别对输入特征图沿着通道维度进行合并(输出特征图通道数被压缩为1)得到两个独立的二维空间特征(向量)和然后将这两个向量在通道维度上进行拼接并通过一个7
×
7大小卷积核 f7×7的卷积操作,再经过sigmoid激活层的归化后得到空间注意力特征图m2,见式(8)。其中a是sigmoid激活函数,“;”表示拼接操作。
[0063][0064]
空间注意力特征图m
s
对中间特征f
mid
同样的在每个通道上逐元素进行空间加权得到语义注意力模块的最终输出特征图f
out
,见式(9),其中
⊙
是哈达玛积。
[0065]
f
out
=m
s
(f
mid
)
⊙
f
mid
ꢀꢀ
(9)
[0066]
注意力模块的作用是基于rgb图像和语义得分特征图的互补特征源在两条分支的最后输出特征图f1、f
m
应用门控机制得到一组应用语义加权的输出特征图输入线性分类器中获得最终的场景概率分布预测。来自语义分支的输出f
m
经过两个通道分离
conv+bn块,再通过一个sigmoid激活层得到语义驱动的特征门控表示f
m,a
,见式 (10),其中σ、φ中分别对应sigmoid和relu激活函数,和分别表示两个通道分离conv层的权重和偏差。
[0067][0068]
类似的,来自rgb分支的输出f通过两个通道分离conv+bn块得到将被门控的rgb特征图f
i,a
,f
i,a
相比f
m,a
少了s1 geoid激活层的映射,其中和分别表示两个通道分离conv层的权重和偏差。
[0069]
注意力模块的输出特征图f
a
然后作为一个由平均池化层、随机失活层和全连接层组成的分类器的输入,该分类器产生一个特征向量f∈r
k
, k为场景的类别数。场景的概率分布y∈r
k
由softmax函数对输入f应用值域映射、归一化后得到通过使用归一化指数函数γ(f)得到给定特征向量f的k维概率分布y,其中y的每一项y
k
由式(11)计算得到,表示对于给定的特征向量f预测类别为k的概率。
[0070][0071]
在一个实施例中,表情识别模型的训练方法如下:构建第一核卷积块层及第一最大池化层;构建第二核卷积块层及第二最大池化层;构建第三核卷积块层及第三最大池化层;构建第四核卷积块层及第四最大池化层;构建第五核卷积块层及第五最大池化层;构建全连接层及输出层;将具有表情标签的表情样本图像输入表情识别模型行训练。
[0072]
在该实施例中,核卷积块包括第一卷积层、第一批标准化层、第一激活层、第二卷积层、第二批标准化层、第二激活层。
[0073]
请参阅图4,该实施例设计人脸表情识别模型结构,由5个采用3
ꢀ×
3卷积的核卷积块(conv
‑
block)、5个最大池化层、1个全连接层和1个输出层组成。第一核卷积块、第二核卷积块、第三核卷积块、第四核卷积块级第五核卷积块的卷积核个数分别为64,128,256,512, 512,步长均为1。模型输入为预处理后的44
×
44像素大小的灰度图片,经过第一核卷积块处理后,输出64张特征图,大小为44
×
44,与原输入大小相同。特征图通过最大池化层进行下采样,输出的特征图大小为 22
×
22
×
64,为原输入的一半。经过第二个核卷积块处理,输出大小为 22
×
22
×
128的特征图,通过最大池化层得到特征图大小为11
×
11
×ꢀ
128。再经过3个同样的“核卷积块+池化”操作后,得到大小为2
×2ꢀ×
512的特征图,送入一个含有512个神经元的全连接层,输出一个512 维的向量。最终通过softmax分类器获得7种表情的分类结果。
[0074]
池化层对输入层的空间维度执行下采样操作,降低特征维度以减小输入特征图的大小。本文采用最大池化操作。完全连接层具有与输入中的每个权重相连的神经元。最终输出结果是一个向量,其维度大小是卷积核的个数。
[0075]
softmax分类器将输入值压缩在0和1之间来输出直观的归一化类概率,如公式(12)所示:
[0076][0077]
其中,n表示总的人脸表情类别数,s(x)表示softmax分类器将输入x分类为j的概率,j表示具体的人脸表情类别。交叉熵损失函数如公式(13)所示:
[0078][0079]
其中,g(x')表示模型输出预测值,y
i
表示真实值,n为样本数,这里1og表示以e为底的自然对数。模型的运算复杂度主要通过参数数量来衡量,参数计算公式如公式(14)所示:
[0080]
k2×
i
×
o
ꢀꢀ
(14)
[0081]
其中,k为卷积核尺寸,i为输入图像通道数,o为输出图像通道数。本实施例表情识别模型参数数量比经典神经网络alexnet和vgg16 少很多,能够有效减少参数数量,在一定程度上降低了人脸表情识别模型训练过程的运算复杂度。
[0082]
在一个实施例中,智能相册的实现方法还包括:获取对所有相片进行人脸分类类别的第一数量,并根据第一数量建立相同数量的第一文件夹;获取不同的场景标记的第二数量,并根据第二数量建立相同数量的第二文件夹;获取不同的表情标记的第三数量,并根据第三数量建立相同数量的第三文件夹。
[0083]
通过建立与第一数量相同的第一文件夹、与第二数量相同的第二文件夹、第三数量相同的第三文件夹,能够使得文件夹的建立,不会多也不会少,从而防止文件夹建立多了导致用户点击空文件夹的情况发生,也不会由于文件夹少而导致不够用的情况发生。
[0084]
在该实施例中,对所有相片进行人脸分类后,根据分类的类别数量建立相同数量的第一文件夹;在相片上进行场景标记后,根据不同场景标记的数量建立相同数量的第二文件夹;在人脸相片上进行表情标记后,根据不同表情标记的数量建立数量相同的第三文件夹。
[0085]
在一个实施例中,智能相册的实现方法还包括:利用聚类模型对所有相片的分类对第一文件夹命名;利用场景标记为第二文件夹命名;利用表情标记为第三文件夹命名。
[0086]
这样的命名方法,能够使得用户一目了然的看到并了解文件夹里的内容,从而使得用户可以第一时间找到自己关注的相片在哪个文件夹内,因此进一步减少了用户浏览图片的困扰。
[0087]
请参阅图5,本申请实施例提供一种智能相册的实现系统,包括:相片获取模块1、分类模块2、场景标记模块3及相片放置模块4;相片获取模块1用于获取相册里面的所有相片;分类模块2用于对所有相片进行人脸分类,并将相同人脸分类的相片放在相同的第一文件夹内;场景标记模块3用于利用场景识别算法识别所述第一文件夹内的人脸相片中的场景,并在相片上进行场景标记;相片放置模块4用于将相同场景标记的人脸相片置于所述第一文件夹下的第二文件夹内。
[0088]
本实施例上述的智能相册的实现系统,场景识别模块通过使用场景识别模型,能够在对人脸分类后进行场景标记,从而在分类模块2对人脸分类后进一步对相片进行分类,
从而降低了文件夹内图片的杂乱程度,因此减少了用户浏览图片的困扰。
[0089]
在一个实施例中,智能相册的实现系统还包括:表情标记模块、表情标记接收模块及调用模块;表情标记模块用于将所述第一文件夹内的人脸相片输入预先训练的表情识别模型,所述表情识别模型用于识别人脸相片中的人脸表情,并在人脸相片上进行表情标记;表情标记接收模块接收所述表情识别模型输出的每张人脸相片的表情标记;调用模块用于调用相片放置模块4将相同表情标记的人脸相片聚类在所述第一文件夹下的第三文件夹内。
[0090]
在一个实施例中,分类模块2包括:浅层特征提取单元、深层特征提取单元、特征提炼单元、特征融合单元及分类单元;浅层特征提取单元用于利用方向梯度直方图特征提取的方法提取相片的浅层特征;深层特征提取单元用于利用预先训练的pcanet网络模型提取相片的深层特征;特征提炼单元用于利用rslda算法对所述浅层特征及所述深层特征进行提炼;特征融合单元用于对提炼后的浅层特征及深层特征进行融合,得到融合特征;分类单元用于将所述融合特征输入预先训练的支持向量机进行分类,以对相片进行分类。
[0091]
在一个实施例中,智能相册的实现系统还包括:数量获取模块及文件夹建立模块,
[0092]
数量获取模块用于获取对所有相片进行人脸分类类别的第一数量,不同的所述场景标记的第二数量,不同的所述表情标记的第三数量;文件夹建立模块用于根据所述第一数量建立相同数量的第一文件夹,根据所述第二数量建立相同数量的第二文件夹;根据所述第三数量建立相同数量的第三文件夹。
[0093]
在一个实施例中,智能相册的实现系统还包括:文件夹命名模块,文件夹命名模块用于利用人脸分类的类别对所述第一文件夹命名,并利用所述场景标记为所述第二文件夹命名,并利用所述表情标记为所述第三文件夹命名。
[0094]
本申请实施例提供一种电子装置,请参阅6,该电子装置包括:存储器601、处理器602及存储在存储器601上并可在处理器602上运行的计算机程序,处理器602执行该计算机程序时,实现前述中描述的智能相册的实现方法。
[0095]
进一步的,该电子装置还包括:至少一个输入设备603以及至少一个输出设备604。
[0096]
上述存储器601、处理器602、输入设备603以及输出设备604,通过总线605连接。
[0097]
其中,输入设备603具体可为摄像头、触控面板、物理按键或者鼠标等等。输出设备604具体可为显示屏。
[0098]
存储器601可以是高速随机存取记忆体(ram,random accessmemory)存储器,也可为非不稳定的存储器(non
‑
volatile memory),例如磁盘存储器。存储器601用于存储一组可执行程序代码,处理器602 与存储器601耦合。
[0099]
进一步的,本申请实施例还提供了一种计算机可读存储介质,该计算机可读存储介质可以是设置于上述各实施例中的电子装置中,该计算机可读存储介质可以是前述中的存储器601。该计算机可读存储介质上存储有计算机程序,该程序被处理器602执行时实现前述实施例中描述的智能相册的实现方法。
[0100]
进一步的,该计算机可存储介质还可以是u盘、移动硬盘、只读存储器601(rom,read
‑
only memory)、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0101]
尽管已经相对于一个或多个实现方式示出并描述了本申请,但是本领域技术人员基于对本说明书和附图的阅读和理解将会想到等价变型和修改。本申请包括所有这样的修
改和变型,并且仅由所附权利要求的范围限制。特别地关于由上述组件执行的各种功能,用于描述这样的组件的术语旨在对应于执行所述组件的指定功能(例如其在功能上是等价的)的任意组件(除非另外指示),即使在结构上与执行本文所示的本说明书的示范性实现方式中的功能的公开结构不等同。
[0102]
即,以上所述仅为本申请的实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,例如各实施例之间技术特征的相互结合,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
[0103]
另外,在本申请的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本申请和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本申请的限制。另外,对于特性相同或相似的结构元件,本申请可采用相同或者不相同的标号进行标识。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个特征。在本申请的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
[0104]
在本申请中,“示例性”一词是用来表示“用作例子、例证或说明”。本申请中被描述为“示例性”的任何一个实施例不一定被解释为比其它实施例更加优选或更加具优势。为了使本领域任何技术人员能够实现和使用本申请,本申请给出了以上描述。在以上描述中,为了解释的目的而列出了各个细节。应当明白的是,本领域普通技术人员可以认识到,在不使用这些特定细节的情况下也可以实现本申请。在其它实施例中,不会对公知的结构和过程进行详细阐述,以避免不必要的细节使本申请的描述变得晦涩。因此,本申请并非旨在限于所示的实施例,而是与符合本申请所公开的原理和特征的最广范围相一致。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1