基于自注意力生成对抗网络的车牌运动模糊图像处理方法
1.本发明属于计算机视觉技术领域,具体地涉及到车牌运动模糊图片处理。
背景技术:
2.运动模糊图片处理旨在去除存在运动模糊的图片中的运动模糊。随着互联网的发展和个人智能移动设备的大量增加,人们正产生、存储和使用大量的图片;图片中有时存在运动模糊而影响正常的识别操作等,需要对运动模糊图片处理和恢复,在计算机视觉中是基础。由于其广泛的应用场景和研究价值,该技术在学术界和工业界均引起了越来越多的关注。
3.目前大部分运动模糊图片处理方法可以分成两大类别:一类是传统上通过盲或非盲方式对图像运动去模糊处理作为反卷积问题处理,第二类是使用卷积神经网络对模糊核进行估计,近年来使用gan用于图像恢复的成功也实现了运动模糊图片处理。其中包括orest kupyn等人提出的deblurganv2进行图像运动模糊移除。然而由于车牌图像中文字和数字有特定的结构和几何特征的情况,以及网络中需要考虑同个特征图内不同部分细节之间的影响,现有的方法无法全面考虑到图像中的结构几何信息和网络特征图间各部分的影响。
4.针对现有方法存在的技术问题,本发明提出基于自注意力生成对抗网络的车牌运动模糊图像处理方法。
技术实现要素:
5.本发明所要解决的技术问题在于克服上述现有技术的缺点,提供一种方法简单、恢复效果好的基于自注意力生成对抗网络的车牌运动模糊图像处理方法。
6.解决上述技术问题所采用的技术方案是由下述步骤组成:
7.(1)数据集预处理
8.取车牌清晰图片数据集s0共4994张,图片大小为500
×
500像素。
9.1)随机生成角度τ,角度范围是(0,2π),对τ采用马尔可夫随机过程方法生成运动轨迹矢量,对运动轨迹矢量采用亚像素插值法生成模糊内核,模糊内核与清晰图片数据集s0卷积生成车牌模糊图片数据集b0。
10.2)将车牌清晰图片数据集s0与相对应的车牌模糊图片数据集b0构成清晰
‑
模糊图片对数据集;
11.3)清晰
‑
模糊图片对数据集中按3:1的比例划分为训练集p和测试集q,其中训练集p内车牌清晰图片数据集为s,车牌模糊图片数据集为b;训练集q内车牌清晰图片数据集为s1,车牌模糊图片数据集为b1。
12.(2)构建网络模型
13.1)构建生成对抗网络模型的生成器g
14.a构建自注意力机制的基础特征提取网络
15.a模块1
‑
1用基础e1卷积层块卷积操作得特征图c1,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为32。
16.b模块1
‑
2用基础e2卷积层块对模块1
‑
1输出的特征图卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为64,得到特征图c2。
17.c模块1
‑
3用基础e3卷积层块对特征图c2卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为192,得到特征图c3。
18.d模块1
‑
4用基础e4卷积层块对特征图c3卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为1088,得到特征图c4。
19.e模块1
‑
5用基础e5卷积层块对特征图c4卷积操作,得到特征图c5。
20.b构建特征图融合网络
21.a模块1
‑
6是卷积核大小为1
×
1的卷积层,对特征图c5卷积操作,得到特征图d5,用最近邻上采样法对特征图d5进行上采样,得到特征图k5。
22.b模块1
‑
7是卷积核大小为1
×
1的卷积层,对特征图c4卷积操作与特征图k5叠加,连接卷积核大小为3
×
3的卷积层卷积操作,得到特征图d4,用最近邻上采样法对特征图d4进行上采样,得到特征图k4。
23.c模块1
‑
8是卷积核大小为1
×
1的卷积层,对特征图c3卷积操作与特征图k4叠加,连接卷积核大小为3
×
3的卷积层卷积操作得到特征图d3,用最近邻上采样法对特征图d3进行上采样,得到特征图k3。
24.d模块1
‑
9是卷积核大小为1
×
1的卷积层,对特征图c2卷积操作与特征图k3叠加,连接卷积核大小为3
×
3的卷积层卷积操作得到特征图d2。
25.e模块1
‑
10是卷积核大小为1
×
1的卷积层,对特征图c1卷积操作得到特征图d1。
26.f模块1
‑
11是对特征图集合{d2,d3,d4,d5}分别进行扩大因子为1,2,4,8的最近邻上采样法上采样操作,得到的结果拼接融合为特征图r1。
27.g模块1
‑
12是卷积核大小为3
×
3的卷积层,对特征图r1卷积操作,串联自注意力机制卷积层网络i,用最近邻上采样法进行上采样操作,与特征图d1叠加,其后连接3
×
3卷积核的平滑卷积层。
28.2)构建生成对抗网络模型的判别器d
29.判别器d的构建方法如下:
30.a模块2
‑
1是基础h1卷积层依次连接基础h2卷积层、自注意力机制卷积层网络i,自注意力机制卷积层网络i的输入通道数为256。
31.b模块2
‑
2基础h3卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512,得到局部信息判别器的概率值p
l
。
32.c模块2
‑
3基础h4卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512。
33.d模块2
‑
4基础h5卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512,得到全局信息判别器的概率值p
g
。
34.3)自注意力机制卷积层网络i的构建方法
35.上述的自注意力机制卷积层网络i的构建方法如下:
36.a构建注意力影响权重分布层
37.按下式得到自注意力机制的影响权重分布图α
j,i
:
[0038][0039][0040]
s
ij
=f(x
i
)
t
g(x
j
)
[0041]
其中x
i
表示输入的特征图x上位置i的值,x
j
表示输入的特征图x上位置j的值,g(x
j
),f(x
i
)分别表示卷积核大小为1
×
1的卷积层对输入的特征图x上像素i,j卷积操作,i,j∈{1,2,...,n},n是图像上的位置总数,n为有限的正整数,μ的值是10,ω的值是0.5。
[0042]
b构建自注意力特征图层
[0043]
按下式得到自注意力机制特征图o
j
:
[0044][0045]
其中h(x
i
)表示卷积核大小为1
×
1的卷积层对输入的特征图x上像素i卷积操作,α
j,i
是影响权重分布层得到的输出结果。
[0046]
c构建输出层
[0047]
按下式得卷积层输出y
j
:
[0048]
y
j
=γo
j
+x
j
[0049]
其中o
j
是自注意力层的输出结果,γ表示可训练权重,被初始化为0,表示模型将探索局部空间信息。
[0050]
(3)训练生成对抗网络
[0051]
1)确定损失函数
[0052]
损失函数loss由下式确定:
[0053]
l
g
=0.5
×
l
p
+0.006
×
l
x
+0.01
×
l
adv
[0054]
其中l
p
为均方误差损失,l
x
欧氏距离损失,l
adv
对抗损失,l
adv
由下式定义:
[0055]
l
adv
=e
s~p(s)
[(d(s)
‑
e
b~p(b)
d(g(b))
‑
1)2]+e
b~p(b)
[(d(g(b))
‑
e
s~p(s)
d(s)+1)2]
[0056]
其中s~p(s)表示从车牌清晰图片数据集s中取出清晰图片s,p(s)表示车牌清晰图片数据集s中的概率分布;b~p(b)表示从车牌模糊图片数据集b中取出模糊图片b,p(b)表示车牌模糊图片数据集b中的概率分布;d(s)表示判别器对输入的清晰图片s判别为真的概率,g(b)表示输入模糊图片b后生成器g的输出结果图片,d(g(b))表示判断生成器在输入模糊图片b后的输出是否为真的概率,e[
·
]表示对括号内部值取期望。
[0057]
2)训练生成对抗网络的判别器d和生成器g
[0058]
生成对抗网络的生成器g输入为训练集p中车牌模糊图片数据集b的模糊车牌图像,输出的图像作为生成对抗网络判别器d的输入,判别器d判断生成器g输出的图像是否是真实图像的概率,在训练判别器d和生成器g过程中,生成对抗网络的学习率γ为0.0001,优化器为自适应矩估计优化器,每次迭代使用图片的数量为z,z取值范围是[4,16],训练迭代直至生成对抗网络的损失函数loss收敛。
[0059]
(4)保存权重文件
[0060]
每迭代m次保存一次相应的参数及权重文件,其中m取值范围是[100,10000]。
[0061]
(5)测试网络
[0062]
将测试集q中车牌模糊图片数据集b1中的模糊图像输入到基于自注意力机制的生成对抗网络模型,加载保存的参数和权重文件,输出清晰车牌图像。
[0063]
在本发明的训练生成对抗网络的判别器d和生成器g步骤(3)的步骤2)中,z最佳取值为8。
[0064]
在本发明的保存权重文件步骤(4)中,m最佳取值为5000。
[0065]
由于本发明采用了将车牌图片数据集分割成训练集、测试集,在特征金字塔网络的生成器和双重判别器上添加了自注意力机制构成生成对抗网络,训练集在生成对抗网络中进行训练,测试集采用保存训练过程中的权重文件进行测试,充分地利用了图像中结构和几何信息,去除了车牌图像中的运动模糊,解决了车牌运动模糊图像处理方法复杂,处理速度慢的技术问题。与现有技术相比,本发明具有方法简单、处理速度快、处理后车牌的文字清晰等优点,可用于车牌运动模糊图像处理。
附图说明
[0066]
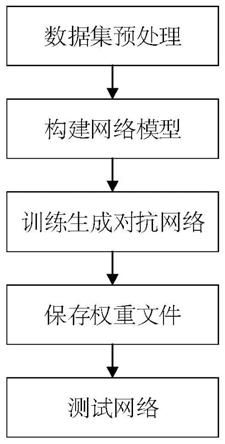
图1本发明实施例1的流程图。
[0067]
图2是图1中构建网络模型的构建生成对抗网络模型的生成器流程图。
[0068]
图3是图1中构建网络模型的构建生成对抗网络模型的判别器流程图。
[0069]
图4是车牌模糊图片数据集b1中1张车牌模糊图片。
[0070]
图5是采用实例1方法对图4的处理结果图。
具体实施方式
[0071]
下面结合附图和实例对本发明进一步详细说明,但本发明不限于下述实施例。
[0072]
实施例1
[0073]
以在图片来自车牌清晰图片数据集中取4994张图片为例,本实施例的基于自注意力生成对抗网络的车牌运动模糊图像处理方法由下述步骤组成(参见图1):
[0074]
(1)数据集预处理
[0075]
取车牌清晰图片数据集s0共4994张,图片大小为500
×
500像素。
[0076]
1)随机生成角度τ,角度范围是(0,2π),本实施例的生成角度τ取值为π,对τ采用马尔可夫随机过程方法生成运动轨迹矢量,对运动轨迹矢量采用亚像素插值法生成模糊内核,模糊内核与清晰图片数据集s0卷积生成车牌模糊图片(如图4所示)数据集b0。
[0077]
2)将车牌清晰图片数据集s0与相对应的车牌模糊图片数据集b0构成清晰
‑
模糊图片对数据集;
[0078]
3)清晰
‑
模糊图片对数据集中按3:1的比例划分为训练集p和测试集q,其中训练集p内车牌清晰图片数据集为s,车牌模糊图片数据集为b;训练集q内车牌清晰图片数据集为s1,车牌模糊图片数据集为b1。
[0079]
(2)构建网络模型
[0080]
在图2、图3中,本实施例的构建网络模型的方法如下:
[0081]
1)构建生成对抗网络模型的生成器g
[0082]
a构建自注意力机制的基础特征提取网络
[0083]
a模块1
‑
1用基础e1卷积层块卷积操作得特征图c1,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为32。
[0084]
b模块1
‑
2用基础e2卷积层块对模块1
‑
1输出的特征图卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为64,得到特征图c2。
[0085]
c模块1
‑
3用基础e3卷积层块对特征图c2卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为192,得到特征图c3。
[0086]
d模块1
‑
4用基础e4卷积层块对特征图c3卷积操作,连接自注意力机制卷积层网络i,自注意力机制卷积层网络i卷积核输入通道数为1088,得到特征图c4。
[0087]
e模块(1
‑
5)用基础e5卷积层块对特征图c4卷积操作,得到特征图c5。
[0088]
b构建特征图融合网络
[0089]
a模块1
‑
6是卷积核大小为1
×
1的卷积层,对特征图c5卷积操作,得到特征图d5,用最近邻上采样法对特征图d5进行上采样,得到特征图k5。
[0090]
b模块1
‑
7是卷积核大小为1
×
1的卷积层,对特征图c4卷积操作与特征图k5叠加,连接卷积核大小为3
×
3的卷积层卷积操作,得到特征图d4,用最近邻上采样法对特征图d4进行上采样,得到特征图k4。
[0091]
c模块1
‑
8是卷积核大小为1
×
1的卷积层,对特征图c3卷积操作与特征图k4叠加,连接卷积核大小为3
×
3的卷积层卷积操作得到特征图d3,用最近邻上采样法对特征图d3进行上采样,得到特征图k3。
[0092]
d模块1
‑
9是卷积核大小为1
×
1的卷积层,对特征图c2卷积操作与特征图k3叠加,连接卷积核大小为3
×
3的卷积层卷积操作得到特征图d2。
[0093]
e模块1
‑
10是卷积核大小为1
×
1的卷积层,对特征图c1卷积操作得到特征图d1。
[0094]
f模块1
‑
11是对特征图集合{d2,d3,d4,d5}分别进行扩大因子为1,2,4,8的最近邻上采样法上采样操作,得到的结果拼接融合为特征图r1。
[0095]
g模块1
‑
12是卷积核大小为3
×
3的卷积层,对特征图r1卷积操作,串联自注意力机制卷积层网络i,用最近邻上采样法进行上采样操作,与特征图d1叠加,其后连接3
×
3卷积核的平滑卷积层。
[0096]
2)构建生成对抗网络模型的判别器d
[0097]
本实施例判别器d的构建方法如下:
[0098]
a模块2
‑
1是基础h1卷积层依次连接基础h2卷积层、自注意力机制卷积层网络i,自注意力机制卷积层网络i的输入通道数为256。
[0099]
b模块2
‑
2基础h3卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512,得到局部信息判别器的概率值p
l
。
[0100]
c模块2
‑
3基础h4卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512。
[0101]
d模块2
‑
4基础h5卷积层连接自注意力机制卷积层网络i,自注意力机制卷积层网络i输入通道数为512,得到全局信息判别器的概率值p
g
。
[0102]
3)自注意力机制卷积层网络i的构建方法
[0103]
上述的自注意力机制卷积层网络i的构建方法如下:
[0104]
a构建注意力影响权重分布层
[0105]
按下式得到自注意力机制的影响权重分布图α
j,i
:
[0106][0107][0108]
s
ij
=f(x
i
)
t
g(x
j
)
[0109]
其中x
i
表示输入的特征图x上位置i的值,x
j
表示输入的特征图x上位置j的值,g(x
j
),f(x
i
)分别表示卷积核大小为1
×
1的卷积层对输入的特征图x上像素i,j卷积操作,i,j∈{1,2,...,n},n是图像上的位置总数,n为有限的正整数,μ的值是10,ω的值是0.5。
[0110]
b构建自注意力特征图层
[0111]
按下式得到自注意力机制特征图o
j
:
[0112][0113]
其中h(x
i
)表示卷积核大小为1
×
1的卷积层对输入的特征图x上像素i卷积操作,α
j,i
是影响权重分布层得到的输出结果。
[0114]
c构建输出层
[0115]
按下式得卷积层输出y
j
:
[0116]
y
j
=γo
j
+x
j
[0117]
其中o
j
是自注意力层的输出结果,γ表示可训练权重,被初始化为0,表示模型将探索局部空间信息。
[0118]
(3)训练生成对抗网络
[0119]
1)确定损失函数
[0120]
损失函数loss由下式确定:
[0121]
l
g
=0.5
×
l
p
+0.006
×
l
x
+0.01
×
l
adv
[0122]
其中l
p
为均方误差损失,l
x
欧氏距离损失,l
adv
对抗损失,l
adv
由下式定义:
[0123]
l
adv
=e
s~p(s)
[(d(s)
‑
e
b~p(b)
d(g(b))
‑
1)2]+e
b~p(b)
[(d(g(b))
‑
e
s~p(s)
d(s)+1)2]
[0124]
其中s~p(s)表示从车牌清晰图片数据集s中取出清晰图片s,p(s)表示车牌清晰图片数据集s中的概率分布;b~p(b)表示从车牌模糊图片数据集b中取出模糊图片b,p(b)表示车牌模糊图片数据集b中的概率分布;d(s)表示判别器对输入的清晰图片s判别为真的概率,g(b)表示输入模糊图片b后生成器g的输出结果图片,d(g(b))表示判断生成器在输入模糊图片b后的输出是否为真的概率,e[
·
]表示对括号内部值取期望。
[0125]
2)训练生成对抗网络的判别器d和生成器g
[0126]
生成对抗网络的生成器g输入为训练集p中车牌模糊图片数据集b的模糊车牌图像,输出的图像作为生成对抗网络判别器d的输入,判别器d判断生成器g输出的图像是否是真实图像的概率,在训练判别器d和生成器g过程中,生成对抗网络的学习率γ为0.0001,优化器为自适应矩估计优化器,每次迭代使用图片的数量为z,z取值范围是[4,16],本实施例的z取值为8,训练迭代直至生成对抗网络的损失函数loss收敛。
[0127]
(4)保存权重文件
[0128]
每迭代m次保存一次相应的参数及权重文件,其中m取值范围是[100,10000],本实施例的m取值为5000。
[0129]
(5)测试网络
[0130]
将测试集q中车牌模糊图片数据集b1中的模糊图像输入到基于自注意力机制的生成对抗网络模型,加载保存的参数和权重文件,输出清晰车牌图像,如图5所示。
[0131]
由于本发明采用了将车牌图片数据集分割成训练集、测试集,在特征金字塔网络的生成器和双重判别器上添加了自注意力机制构成生成对抗网络,训练集在生成对抗网络中进行训练,测试集采用保存训练过程中的权重文件进行测试,充分地利用了图像中结构和几何信息,去除了车牌图像中的运动模糊,解决了车牌运动模糊图像处理方法复杂,处理速度慢的技术问题。与现有技术相比,本发明具有方法简单、处理速度快、处理后车牌的文字清晰等优点,可用于车牌运动模糊图像处理。
[0132]
实施例2
[0133]
以在图片来自车牌清晰图片数据集中取4994张图片为例,本实施例的基于自注意力生成对抗网络的车牌运动模糊图像处理方法由下述步骤组成:
[0134]
(1)数据集预处理
[0135]
取车牌清晰图片数据集s0共4994张,图片大小为500
×
500像素。
[0136]
随机生成角度τ,角度范围是[0,2π],本实施例的生成角度τ取值为对τ采用马尔可夫随机过程方法生成运动轨迹矢量,对运动轨迹矢量采用亚像素插值法生成模糊内核,模糊内核与清晰图片数据集s0卷积生成车牌模糊图片数据集b0。
[0137]
该步骤的其它步骤与实施例1相同。
[0138]
(2)构建网络模型
[0139]
该步骤与实施例1相同
[0140]
(3)训练生成对抗网络
[0141]
1)确定损失函数
[0142]
该步骤与实施例1相同。
[0143]
2)训练生成对抗网络的判别器d和生成器g
[0144]
生成对抗网络的生成器g输入为训练集p中车牌模糊图片数据集b的模糊车牌图像,输出的图像作为生成对抗网络判别器d的输入,判别器d判断生成器g输出的图像是否是真实图像的概率,在训练判别器d和生成器g过程中,生成对抗网络的学习率γ为0.0001,优化器为自适应矩估计优化器,每次迭代使用图片的数量为z,z取值范围是[4,16],本实施例的z取值为4,训练迭代直至生成对抗网络的损失函数loss收敛。
[0145]
(4)保存权重文件
[0146]
每迭代m次保存一次相应的参数及权重文件,其中m取值范围是[100,10000],本实施例的m取值为100。
[0147]
其它步骤与实施例1相同。输出清晰车牌图像。
[0148]
实施例3
[0149]
以在图片来自车牌清晰图片数据集中取4994张图片为例,本实施例的基于自注意
力生成对抗网络的车牌运动模糊图像处理方法由下述步骤组成:
[0150]
(1)数据集预处理
[0151]
取车牌清晰图片数据集s0共4994张,图片大小为500
×
500像素。
[0152]
随机生成角度τ,角度范围是[0,2π],本实施例的生成角度τ取值为对τ采用马尔可夫随机过程方法生成运动轨迹矢量,对运动轨迹矢量采用亚像素插值法生成模糊内核,模糊内核与清晰图片数据集s0卷积生成车牌模糊图片数据集b0。
[0153]
该步骤的其它步骤与实施例1相同。
[0154]
(2)构建网络模型
[0155]
该步骤与实施例1相同
[0156]
(3)训练生成对抗网络
[0157]
1)确定损失函数
[0158]
该步骤与实施例1相同。
[0159]
2)训练生成对抗网络的判别器d和生成器g
[0160]
生成对抗网络的生成器g输入为训练集p中车牌模糊图片数据集b的模糊车牌图像,输出的图像作为生成对抗网络判别器d的输入,判别器d判断生成器g输出的图像是否是真实图像的概率,在训练判别器d和生成器g过程中,生成对抗网络的学习率γ为0.0001,优化器为自适应矩估计优化器,每次迭代使用图片的数量为z,z取值范围是[4,16],本实施例的z取值为16,训练迭代直至生成对抗网络的损失函数loss收敛。
[0161]
(4)保存权重文件
[0162]
每迭代m次保存一次相应的参数及权重文件,其中m取值范围是[100,10000],本实施例的m取值为10000。
[0163]
其它步骤与实施例1相同,输出清晰车牌图像。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1