基于滑窗相关性计算和Copy机制的工单摘要总结方法与流程
基于滑窗相关性计算和copy机制的工单摘要总结方法
技术领域
1.本发明涉及客服工单总结方法,具体涉及基于滑窗相关性计算和copy机制的工单摘要总结方法。
背景技术:
2.在当前的人工智能领域,自然语言处理的预训练模型已经被广泛使用,比如当前热门的transfromer模型。transfromer模型采用了attention机制,即在处理一个词的时候,能考虑到该词前、后单词的信息,获取上下文的语义,从而建立起文本的长距离依赖关系。
3.在实际业务场景中,尤其是基于人人对话的客服领域,经过语音转写后的文本信息基本上都属于长文本甚至是篇章级别的。而当前的transformer模型在实际业务中主要作为文本特征的抽取器,受限于输入字长的限制和当前计算机的硬件条件,无法一次性处理长度超过512字长的文本信息。而如果仅仅对文本信息做简单地截取,只处理前512字长的信息,可能会造成关键信息的丢失,无法生成语序连贯通顺,且信息完整的摘要总结。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术所存在的上述缺点,本发明提供了基于滑窗相关性计算和copy机制的工单摘要总结方法,能够有效克服现有技术所存在的无法生成语序连贯通顺、信息完整的摘要总结的缺陷。
6.(二)技术方案
7.为实现以上目的,本发明通过以下技术方案予以实现:
8.基于滑窗相关性计算和copy机制的工单摘要总结方法,包括以下步骤:
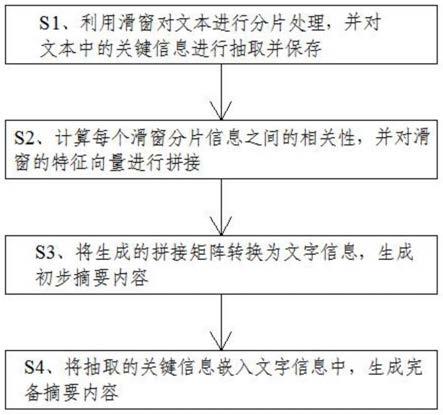
9.s1、利用滑窗对文本进行分片处理,并对文本中的关键信息进行抽取并保存;
10.s2、计算每个滑窗分片信息之间的相关性,并对滑窗的特征向量进行拼接;
11.s3、将生成的拼接矩阵转换为文字信息,生成初步摘要内容;
12.s4、将抽取的关键信息嵌入文字信息中,生成完备摘要内容。
13.优选地,s2中将各滑窗分片信息输入transformer模型中的encoder层,并采用下式计算所述每个滑窗分片信息之间的相关性:
[0014][0015][0016][0017]
[0018]
其中,是模型的三个特征向量,w为权重,是模型的三个特征向量,w为权重,分别表示每个注意力头对特征向量的贡献程度,特征向量的贡献程度,由深度学习反向传播算法确定,表示模型中的多头注意力机制,t表示矩阵的转置,包含每个滑窗分片信息。
[0019]
优选地,所述对滑窗的特征向量进行拼接,包括:
[0020]
将每个注意力头生成的特征向量经过最大池化层后进行矩阵拼接,整个拼接矩阵包含每个滑窗分片信息以及每个滑窗分片信息之间的相关性。
[0021]
优选地,所述拼接矩阵输入transformer模型中的decoder层中转换成文字信息。
[0022]
优选地,s1中所述滑窗设置为512字长。
[0023]
优选地,s1中所述文本中的关键信息根据业务场景确定,文本中的关键信息根据业务场景利用自然语言处理工具进行抽取并保存。
[0024]
优选地,s4中所述生成完备摘要内容之后,利用自然语言处理工具进行语义混淆度评分,并将语义混淆度最低的完备摘要内容作为摘要的最终生成结果。
[0025]
(三)有益效果
[0026]
与现有技术相比,本发明所提供的基于滑窗相关性计算和copy机制的工单摘要总结方法,利用滑动窗口的输入机制,即对长文本信息进行拆分并分批量进行数据输入,能够不再受限于待处理文本的大小,并且通过copy机制针对客服业务中关键信息进行抽取,使得最终生成的摘要不会丢失关键信息,从而能够生成语序连贯通顺、信息完整的摘要总结。
附图说明
[0027]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0028]
图1为本发明生成客服工单摘要的流程示意图;
[0029]
图2为本发明生成客服工单摘要的另一流程示意图。
具体实施方式
[0030]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0031]
基于滑窗相关性计算和copy机制的工单摘要总结方法,如图1和图2所示,利用滑窗对文本进行分片处理,并对文本中的关键信息进行抽取并保存。
[0032]
其中,滑窗设置为512字长,即tranformer模型所能接受的最大字长,实现对整个文本进行拆分并分批量输入数据。
[0033]
文本中的关键信息根据业务场景确定,例如网商购物场景中,商品名和价格为关键信息;快递场景中,发货地、收货地、收获人姓名、联系方式为关键信息。文本中的关键信
息根据业务场景利用自然语言处理工具,例如nltk工具包,进行抽取并保存。
[0034]
计算每个滑窗分片信息之间的相关性,并对滑窗的特征向量进行拼接。
[0035]
将各滑窗分片信息输入transformer模型中的encoder层,并采用下式计算每个滑窗分片信息之间的相关性:
[0036][0037][0038][0039][0040]
其中,是模型的三个特征向量,w为权重,是模型的三个特征向量,w为权重,分别表示每个注意力头对特征向量的贡献程度,特征向量的贡献程度,由深度学习反向传播算法确定,表示模型中的多头注意力机制,t表示矩阵的转置,包含每个滑窗分片信息。
[0041]
对滑窗的特征向量进行拼接,包括:
[0042]
将每个注意力头生成的特征向量经过最大池化层后进行矩阵拼接,整个拼接矩阵包含每个滑窗分片信息以及每个滑窗分片信息之间的相关性,并且保留了特征向量中最能代表语义的特征。
[0043]
将生成的拼接矩阵转换为文字信息,生成初步摘要内容。将拼接矩阵输入transformer模型中的decoder层中转换成文字信息。
[0044]
利用copy机制将抽取的关键信息嵌入文字信息中,生成完备摘要内容。生成完备摘要内容之后,利用自然语言处理工具,例如hannlp和nltk等,进行语义混淆度评分,并将语义混淆度最低的完备摘要内容作为摘要的最终生成结果,使得生成的摘要更加通顺、更符合人类的表达。
[0045]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1