一种网站文章自定义推荐方法与流程
本发明属于网站应用技术领域,具体涉及一种网站文章自定义推荐方法。
背景技术:
随着人们对于碎片化时间的重视,市场上有关文章、博文、新闻的网站和手机应用层出不穷。传统的新闻类网站,文章一般按照时间顺序展示,每个用户看到的是相同的文章列表,导致用户体验度不高,为摆脱传统的编辑推荐模式,通过个性化推荐算法,给用户展示个性化文章成为主流,也能为开发商带来一定的收益。
现在很多文章阅读网站已经使用了个性化推荐,一般通过收集用户的浏览日志,完成个性化推荐;但是由于网站的文章种类繁多,标题党文章横行,导致用户点开的文章可能不是因为他感兴趣,而是被标题吸引。此外,进行推荐的时候,由于系统掉线或者刷新会存在推荐滞后。
技术实现要素:
针对现有技术的上述不足,本发明提供一种网站文章自定义推荐方法,以解决上述技术问题。
本发明提供一种网站文章自定义推荐方法,包括:
对文章的内容进行分词并提取标签词组;
通过词频逆文档频率算法计算文章标签向量;
通过计算余弦相似度进行文章在线推荐;
使用协同过滤算法计算文章兴趣度,并进行离线推荐。
进一步的,所述对文章的内容进行分词并提取标签词组,包括:
对文章的内容进行分词;
将去除无用词条后的剩余词条作为文章的标签词条。
进一步的,所述通过词频逆文档频率算法计算文章标签向量,包括:
计算词频,公式为
计算逆向文件频率,公式为
计算tfidfw=tfw*idfw,得到关键词条;
将标签词条的词条量设为标签向量维度;
将标签词条之外的新的标签向量的值设为0;
输出文章标签向量:vec_a=[0.001,...0.002,..,0],其中a代表文章a。
进一步的,所述通过计算余弦相似度进行文章在线推荐,包括:
通过文章标签向量计算余弦相似度,公式为
根据余弦相似度匹配当前文章的相关文章,并过滤掉标题相似的相关文章,得到在线推荐文章;
在线推荐文章按照所述相似度排序,在用户点击刷新或者重新打开网站时优先展示在线推荐文章。
进一步的,所述使用协同过滤算法计算文章兴趣度,并进行离线推荐,包括:
利用余弦相似度计算用户两两之间的用户相似度;
公式为:
使用协同过滤算法将相近兴趣的用户分在一组;
为任一用户共享推荐组内成员看过的文章。
进一步的,所述方法还包括:
筛选与当前用户的用户相似度匹配较高的若干个用户;
获取所述若干个用户阅读过的离线推荐文章,并过滤掉当前用户阅读过的文章;
将离线推荐文章按照用户相似度加权求和之后排序,并在用户隔天登录时优先展示。
进一步的,所述方法还包括:
文章内容存储到mysql数据库,并设置文章id为索引;
记录用户阅读日志并存储到kafka数据库,所述阅读日志包括:用户id和文章id和阅读时间。
进一步的,所述方法还包括:
网站按照文章大类进行文章展示,设置类别id表示文章类别。
本发明的有益效果在于,
本发明提供的一种网站文章自定义推荐方法,实现了用户浏览文章之后,通过阅读日志的分析,为用户推荐感兴趣的文章。本发明兼具在线实时推荐和离线推荐;所述在线实时推荐,在用户阅读一篇文章之后,立刻计算该文章和数据库中候选文章的相似度;所述离线推荐,通过协同过滤算法,通过对用户历史阅读数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐类别相似的文章。
此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
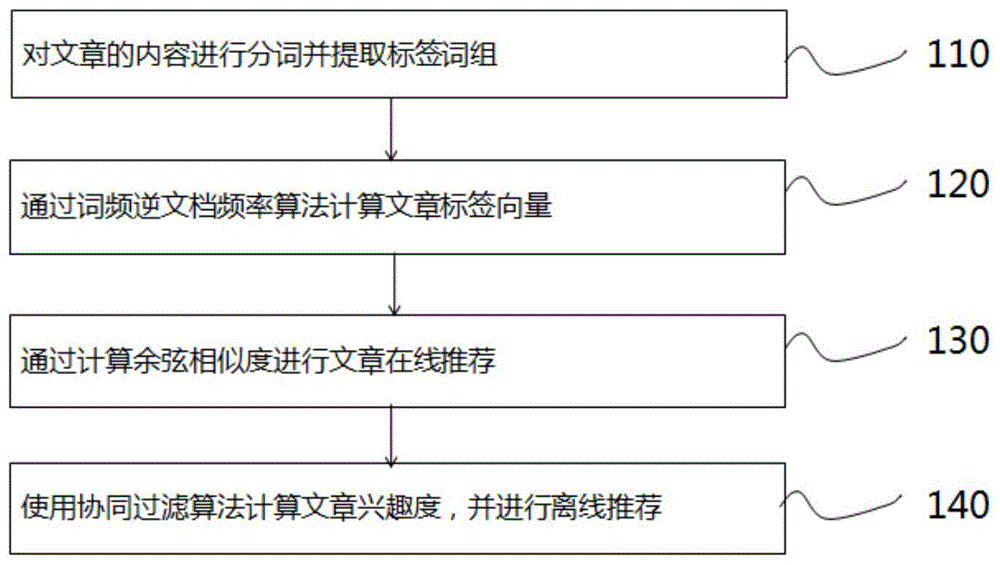
图1是本发明一个实施例的方法的示意性流程图。
图2是本发明一个实施例的网站文章类别id对应关系图。
图3为本发明实施例提供的协同过滤算法示意图。
图4是本发明一个实施例的方法的示意性流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
图1是本发明一个实施例的方法的示意性流程图。如图1所示,该方法包括:
步骤110,对文章的内容进行分词并提取标签词组;
步骤120,通过词频逆文档频率算法计算文章标签向量;
步骤130,通过计算余弦相似度进行文章在线推荐;
步骤140,使用协同过滤算法计算文章兴趣度,并进行离线推荐。
可选地,作为本发明一个实施例,所述对文章的内容进行分词并提取标签词组,包括:
对文章的内容进行分词;
将去除无用词条后的剩余词条作为文章的标签词条。
可选地,作为本发明一个实施例,所述通过词频逆文档频率算法计算文章标签向量,包括:
计算词频,公式为
计算逆向文件频率,公式为
计算tfidfw=tfw*idfw,得到关键词条;
将标签词条的词条量设为标签向量维度;
将标签词条之外的新的标签向量的值设为0;
输出文章标签向量:vec_a=[0.001,...0.002,..,0],其中a代表文章a。
可选地,作为本发明一个实施例,所述通过计算余弦相似度进行文章在线推荐,包括:
通过文章标签向量计算余弦相似度,公式为
根据余弦相似度匹配当前文章的相关文章,并过滤掉标题相似的相关文章,得到在线推荐文章;
在线推荐文章按照所述相似度排序,在用户点击刷新或者重新打开网站时优先展示在线推荐文章。
可选地,作为本发明一个实施例,所述使用协同过滤算法计算文章兴趣度,并进行离线推荐,包括:
利用余弦相似度计算用户两两之间的用户相似度;
公式为:
使用协同过滤算法将相近兴趣的用户分在一组;
为任一用户共享推荐组内成员看过的文章。
可选地,作为本发明一个实施例,所述方法还包括:
筛选与当前用户的用户相似度匹配较高的若干个用户;
获取所述若干个用户阅读过的离线推荐文章,并过滤掉当前用户阅读过的文章;
将离线推荐文章按照用户相似度加权求和之后排序,并在用户隔天登录时优先展示。
可选地,作为本发明一个实施例,所述方法还包括:
文章内容存储到mysql数据库,并设置文章id为索引;
记录用户阅读日志并存储到kafka数据库,所述阅读日志包括:用户id和文章id和阅读时间。
可选地,作为本发明一个实施例,所述方法还包括:
网站按照文章大类进行文章展示,设置类别id表示文章类别。
为了便于对本发明的理解,下面以本发明一种网站文章自定义推荐方法的原理,结合实施例中对标签进行管理的过程,对本发明提供的一种网站文章自定义推荐方法做进一步的描述。
具体的,如图4所示,所述一种网站文章自定义推荐方法包括:
1、文章存储过程中,存到mysql数据库。文章id作为索引,可以快速查找文章;
2、网站按照文章大类进行文章展示,文章类别和类别id的对应关系举例如图2所示;
3、用户阅读网站展示的某篇文章之后,用户id和文章id,阅读时间等信息作为日志存储到kafka数据库;存储格式为:
{用户id:tom,文章id:a1001,文章类别:5,阅读时间:2020-9-1819:20:18};
4、在线推荐模块,从kafka数据库读取数据日志,根据文章id从mysql数据库查询得到文章标题和文字内容;对文章的内容进行分词,去除无用词组后,将剩余词组作为文章标签,组成所述文章的标签词条,得到文章标签向量。文章向量通过tfidf(词频逆文档频率)算法计算得到:
计算词频,公式为
计算逆向文件频率,公式为
计算tfidfw=tfw*idfw,得到关键词条;
tfidf是一种统计方法,用于评估某个词条对于一个文件集或一个语料库中的其中一份文件的重要程度。词条的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。词频(termfrequency,tf)指的是某一个给定的词语在该文件中出现的频率,逆向文件频率(inversedocumentfrequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目。
假设一共有50000个词组,则每篇文章得到的标签向量维度为50000。如果文章中没有出现50000个词组的某个词语,则标签向量对应位置的值为0。文章id为a1001的文章最后形成的标签向量为:
vec_a=[0.001,...0.002,..,0];
5、在得到数据库中所有文章的标签向量之后,可以计算用户阅读的文章a1001和其它文章(比如标签向量为vec_b的这篇文章)的余弦相似度:
余弦相似度代表了两个向量之间的相近程度,对应到文章标签向量余弦相似度,余弦相似度越大的两篇文章,其相似度也越高;我们把余弦相似度作为文章兴趣度进行排序,同时根据标题进行过滤,过滤掉标题相似的文章,取前10个文章id返回给前端页面;
6、在用户点击刷新或者重新打开网站的时候,会优先展示在线推荐模块计算得到的这10篇文章;
7、在离线推荐模块,kafka数据库记录了所有用户当天的阅读日志。我们使用协同过滤算法,计算文章兴趣度,计算流程如图3所示;
7.1、协同过滤原理如图3所示,user3和user2、user1都喜欢product2,user3和user1同时喜欢produce3,我们就认为user3和user1有相同的兴趣偏好,所以可以把user1喜欢的但是user3没有看过的product1和product4推荐给user3。协同过滤算法先对用户群体进行分组,有相近偏好的用户分在一组,然后把该组中其他用户看过的文章推荐给组内成员。
7.2、算法输入数据:用户id,用户阅读的文章id。计算两两用户的相似度。采用余弦相似度。注意,可以采用的评分数据为隐反馈数据(非1即0)。对于两个用户u和v,其用户相似度为:
其中,表示用户u阅读过文章i,其值为1,表示用户v阅读过文章i,其值为1。
7.3、得到所有用户两两之间的相似度之后,可以使用协同过滤算法为其中任一用户进行文章推荐。比如为用户id为tom的用户进行推荐:找出该用户最相似的10个用户,找出这10个用户阅读过的文章,过滤掉tom已经阅读过的文章,将剩下的文章按照用户相似度加权求和之后排序;取前10个文章id保存到数据库;当用户第二天登录的时候,优先展示这10篇文章。
尽管通过参考附图并结合优选实施例的方式对本发明进行了详细描述,但本发明并不限于此。在不脱离本发明的精神和实质的前提下,本领域普通技术人员可以对本发明的实施例进行各种等效的修改或替换,而这些修改或替换都应在本发明的涵盖范围内/任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!