基于CORDIC算法的正余弦、反正切函数运算的装置及方法
本发明涉及正余弦、反正切函数运算的技术领域,具体涉及一种基于cordic算法的正余弦、反正切函数运算装置及方法。
背景技术:
正余弦和反正切函数计算是科学计算中相当常见的几种超越函数计算,目前主要的硬件设计方案主要包括查表法、多项式逼近方法和cordic(coordinaterotationdigitalcomputer,坐标旋转数字计算机)方法;随着精度要求的提高,查表法和多项式逼近法硬件资源消耗成指数增加;传统cordic算法可以通过移位和相加计算三角函数,但是在高精度要求下需会产生极大的计算延迟。目前正余弦和反正切函数计算精度主要包括定点、单精度浮点和双精度浮点,针对128位浮点的计算硬件实现研究还较少。
技术实现要素:
本发明旨在提供了一种基于并行cordic算法的正余弦、反正切函数运算装置及方法,利用四步并行分支cordic算法,将四次单步迭代合并为一次四步迭代,每次迭代进行四位有效精度的逼近,降低了cordic算法由逐位迭代所带来的巨大延时代价。
本发明技术方案的第一方面,提供一种基于cordic算法的正余弦、反正切函数运算的装置,所述装置包括:
异常处理模块:检测输入弧度值是否存在异常,如果输入弧度值合法,输出到预处理模块;
预处理模块:将异常处理模块输入的弧度值转换到cordic算法可计算的范围,并输入到四步并行迭代模块;
四步并行迭代模块:基于cordic算法实现四步并行迭代运算,具体为:对预处理模块得到的数据进行x通道、y通道和z通道迭代运算,以及对符号因子预测;
标准化浮点归一化模块:对四步并行迭代模块得到的数据进行前导零检测,然后归一化组合成标准的浮点形式输出。
进一步的,所述四步并行迭代模块中的四步并行迭代运算是将cordic算法中的四次单步迭代合并为一次四步并行迭代,在每一次的四步并行迭代中,同时预测4个符号因子δi,δi+1,δi+2,δi+3,所述四步并行迭代公式为:
其中,i表示四步并行迭代次数,δi,δi+1,δi+2,δi+3表示四个符号因子,θi,θi+1,θi+2,θ3表示四个旋转角度,xi,yi,zi表示第i次四步并行迭代x通道、y通道、z通道的初始值,xi+4,yi+4,zi+4表示第i次四步并行迭代x通道、y通道、z通道的结果。
进一步的,当所述装置在进行正余弦函数运算时,所述符号因子δi,δi+1,δi+2,δi+3的取值范围均为{-1,1}。
进一步的,当所述装置在进行反正切函数运算时,所述符号因子δi,δi+1,δi+2,δi+3的取值范围均为{0,-1}。
进一步的,当所述装置在进行正余弦函数运算时,所述基于cordic算法实现四步并行迭代运算具体为:x通道、y通道和z通道以迭代方式分别进行16组迭代计算,然后从z通道中选出16组结果z值中最接近于0的两个作为分支,经过二选一比较器,选出z值最接近于0的一个分支以及该分支对应的符号因子si=[δi,δi+1,δi+2,δi+3],与符号因子si=[δi,δi+1,δi+2,δi+3]对应的x通路迭代结果x值和y通路迭代结果y值直接作为本次四步并行迭代的结果。
进一步的,当所述装置在进行反正切函数运算时,所述基于cordic算法实现四步并行迭代运算具体为:x通道、y通道和z通道以迭代方式分别进行16组迭代计算,然后从y通道选出16组结果y值中最接近于0且不越过坐标系x轴的那条分支,以及该分支对应的符号因子si=[σi,σi+1,σi+2,σi+3],与符号因子si=[δi,δi+1,δi+2,δi+3]对应的x通路迭代结果x值和z通路迭代结果z值直接作为本次四步并行迭代的结果。
进一步的,当所述装置在进行正余弦函数运算时,所述四步并行迭代模块中还包括利用常数乘法器对相同乘法项进行一次计算,所述常数乘法器采用csd重编码方式。
本发明技术方案的第二方面,提供一种基于cordic算法的正余弦、反正切函数运算方法,步骤为:
s1、检测输入弧度值是否存在异常,如果输入弧度值合法,输出到s2;
s2、将s1输入的弧度值转换到cordic算法可计算的范围,并输入到s3;
s3、接收s2输入的数据,然后基于cordic算法实现四步并行迭代运算,具体为:对s2输入的数据进行x通道、y通道和z通道迭代运算,以及对符号因子预测;
s4、对s3得到的数据进行前导零检测,然后归一化组合成标准的浮点形式输出。
进一步的,所述四步并行迭代运算是将cordic算法中的四次单步迭代合并为一次四步并行迭代,在每一次的四步并行迭代中,同时预测4个符号因子δi,δi+1,δi+2,δi+3,所述四步并行迭代公式为:
其中,i表示四步并行迭代次数,δi,δi+1,δi+2,δi+3表示四个符号因子,θi,θi+1,θi+2,θ3表示四个旋转角度,xi,yi,zi表示第i次四步并行迭代x通道、y通道、z通道的初始值,xi+4,yi+4,zi+4表示第i次四步并行迭代x通道、y通道、z通道的结果。
本发明提供的一种基于cordic算法的正余弦、反正切函数运算装置及方法,其有益效果是:
1、基于128位标准浮点,提高了正余弦和反正切函数计算结果的可表示精度,在合适的输入范围内,最高精度可达113bit。扩大了正余弦函数的可计算范围,由[-π/2,π/2]扩大至[-213,213]。
2、采用改进的四步并行分支cordic算法,极大的减少了计算所需的迭代次数,完成一次对数函数运算只需要37个时钟周期。
附图说明
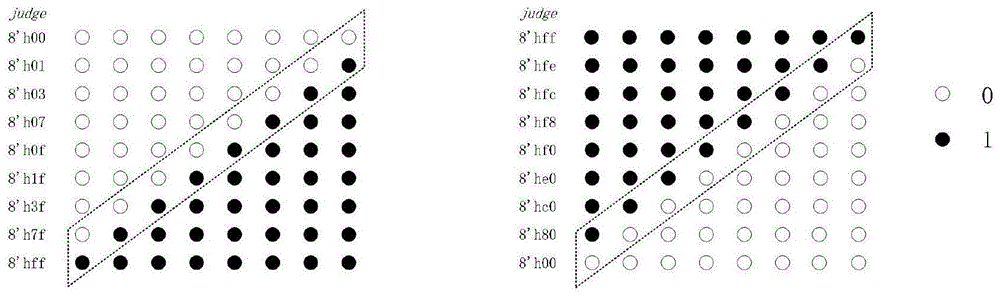
图1是本发明实施例中正余弦函数运算的judge示意图;
图2是本发明实施例中反正切函数运算judge示意图;
图3是本发明实施例中正余弦函数运算整体结构示意图;
图4是本发明实施例中正余弦函数运算异常处理模块的流程示意图;
图5是本发明实施例中正余弦函数运算预处理模块结构示意图;
图6是本发明实施例中正余弦函数四步并行迭代模块结构示意图;
图7是本发明实施例中x通道四步并行迭代模块结构图;
图8是本发明实施例中正余弦函数标准浮点归一化模块的结构示意图;
图9是本发明实施例中反正切函数运算整体结构示意图;
图10是本发明实施例中反正切函数四步并行迭代模块结构示意图。
具体实施方式
为进一步对本发明的技术方案作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的步骤。
本发明针对正余弦和反正切函数提出了新型四步并行分支迭代cordic算法,解决了传统cordic算法计算延迟的问题,四步并行分支迭代cordic算法的基本思想是将四次单步迭代合并为一次四步迭代,在每一次的四步迭代中,同时预测4个符号因子。
以x通道为例,根据cordic算法可得:
对(1)、(2)推导可得第i次四步迭代公式公式:
其中,i表示四步并行迭代次数,δi,δi+1,δi+2,δi+3表示四个符号因子,其符号表示下一次迭代是顺时针还是逆时针,θi,θi+1,θi+2,θ3表示四个旋转角度,xi,yi,zi表示第i次四步并行迭代x通道、y通道、z通道的初始值,xi+4,yi+4,zi+4表示第i次四步并行迭代x通道、y通道、z通道的结果。
对于旋转模式,δi的符号预测是由上一步迭代zi的符号位决定。每一步迭代都有一个固定的伸缩比例因子,正由于该伸缩比例因子的存在,导致每一步都必须旋转一定的角度,以至于必须经过规定的迭代次数才能停止迭代,否则每一步迭代都需要伸缩因子补偿逻辑进行修正。本发明中的四步并行分支迭代cordic算法中,对于正余弦函数的计算,δi,δi+1,δi+2,δi+3的取值范围为{-1,1},这是为了保证伸缩比例因子为定值。在每一次四步迭代中xi+4,yi+4,zi+4都有16个可能的分支情况。其中,δi已知,可由上一步的zi得到,所比较剩下的8个zi+4,选出最接近于0的那条分支,以及该zi+4对应的δi,δi+1,δi+2,δi+3。然后根据δi,δi+1,δi+2,δi+3得到xi+4,yi+4。下面具体看xi+4,yi+4的迭代表达式,以xi+4为例,表1为xi+4的16个分支情况。
表1xi+4对应的迭代表达式
从表1可知,xi+4的前后8个分支存在一定的对称性,其中存在大量的数值相同,符号相反的系数。统计可得,该算法xi+4,yi+4的16个分支在每一次迭代中各自需要40次加法和减法,20次乘法,25次移位运算。
在符号因子δi预测方面,四步并行分支迭代算法在每一次迭代中需要同时预测下一步迭代的δi,δi+1,δi+2,δi+3值,δi的取值使得zi+4顺时针也可逆时针旋转,最终目标都是向0靠近。根据zi的最高符号位可知,上一步旋转后是否跨越了x轴。在本次迭代中,其中δi可由上一步迭代后的zi的最高符号位得到,那么需要比较的zi+4的分支减少至8个。judge表示剩下的8个zi+4的最高符号位,当zi大于0时,judge为从后往前依次取前8个zi+4的最高符号位,当zi小于0时,judge为从前往后依次取后8个zi+4的最高符号位,如图1所示,judge将会以连续0或者连续1的形式排列。根据judge中0和1的分界点,就可以得到两个最接近于0的zi+4的取值,如图1中的虚线框所示,然后将这两个zi+4的值通过2选1比较器,选出最接近于0的zi+4以及该zi+4对应的xi+4,yi+4。
反正切函数计算使用cordic算法圆周模型的向量模式,δi的符号预测是由上一步迭代后的yi符号位决定。对于反正切函数计算,不需要考虑伸缩比例因子。本次算法将δi,δi+1,δi+2,δi+3的取值由{-1,1}改成了{0,-1},δ的取值可以使得zi+4一直保持在第一象限顺时针旋转,保证矢量不会越过x轴。其中-1代表本次迭代后依然没有越过x轴,则本次迭代继续顺时针旋转,0代表本次迭代后将会越过x轴,则本次迭代不旋转。
表2yi+4的迭代表达式
yi+4的迭代表达式如表2所示。当δ取{0,-1}时,该算法xi+4,yi+4的16个分支在每一次迭代中各自需要32次加法和减法,16次乘法,21次移位运算,总体计算量略有下降。
在符号因子预测方面,δ取{0,-1}使得预测更加快速简单。和前面所述一样,每一次迭代后都可以预测下一步迭代的δi,δi+1,δi+2,δi+3值,δi的取值使得(xi,yi)顺时针旋转也可不旋转,最终目标都是向x轴靠近,yi+4值会逐渐向0靠近。根据每步迭代中yi+4的最高符号位,就可知道旋转后的(xi,yi)是否跨越了x轴。如图2所示,图中的judge依次代表yi+4的16个分支取值的最高符号位,从左到右依次是[δi,δi+1,δi+2,δi+3]=[0,0,0,0]到[δi,δi+1,δi+2,δi+3]=[-1,-1,-1,-1]对应的yi+4。由于16个旋转角度值zi+4是从小到大的顺序排列的,所以judge值将会以连续0或者连续1的形式出现,在本发明中,使yi+4值向0靠近,同时保证不越过x轴,根据judge中0和1的分界点,就可找出最接近于x轴的(xi+4,yi+4)以及相对应的δi,δi+1,δi+2,δi+3的值,如图2中虚线框所示。然后根据δi,δi+1,δi+2,δi+3选出对应的xi+4,zi+4。
本发明基于ieee-754128位浮点标准,根据四步并行分支迭代cordic算法,对浮点正余弦函数运算部件进行了整体框架设计。
浮点正余弦函数运算装置主要包括三个部分:异常处理模块、预处理模块、四步并行迭代模块以及标准化浮点归一化模块,所述标准化浮点归一化模块还包括象限映射单元和mux选择器,浮点正余弦函数运算装置整体结构示意图如图3所示。
异常处理模块和和预处理模块中,算法的输入收敛范围是(-99.8°,99.8°),对于一个任意的输入数据,预处理模块先检测输入弧度值是否存在异常,如果输入弧度值合法,那么接下来将该输入弧度值转换到cordic算法可计算的范围。
异常处理模块的流程如图4所示,其中input为128位的浮点输入弧度值,ep_sin和ep_cos为对浮点输入异常的处理结果。
异常处理模块首先将浮点输入值拆分为符号位s、指数部分e和尾数部分m,然后对浮点输入进行异常检测,若存在异常,则输出异常标志位ep,以及对应的异常处理结果ep_sin,ep_cos。如果输合法,则进入到预处理模块。,当浮点输入弧度值合法时,ep置为0,将得到的input_s,input_e,input_m输入到下一个模块。
预处理模块主要负责将输入浮点数弧度转换为cordic可计算的弧度范围,此模块将输入弧度制都映射到第一象限。输出值为s和q,s仍为输入浮点数的符号,而q值将决定输入弧度映射到哪个象限。point为转换后的cordic算法可计算的弧度。
预处理模块结构如图5所示,input_m是113位的尾数部分,在input_m后扩展16位用作移位,扩展后为129位。偏差计算逻辑用于处理输入的指数部分,将输入拆分,传递给后续逻辑进行计算。input_m与input_e和选择信号sel的对应关系如表3所示,根据输入值可分为三种情况。当input_e小于15’h3fff时,将input_m右移n位,即(16383-input_e)位,得到m1;当input_e等于15’h3fff,且input_m小于或等于π/2时,得到的m3即为input_m的值。
当input_e大于15’h3fff,或者input_e等于15’3fff且input_m大于π/2时,此时已超出cordic角度旋转覆盖范围,将输入值按式(4)的方式进行变换。
其中q为
表3input_m,input_e和sel的对应关系
为得到q和r,首先将input_m乘以1/π,这两个数相乘后结果一定为小数,在电路存储中,input_m为129位,后128位是小数部分,所以在二进制存储中,实际上是扩大了2128倍。1/π的位宽设为128位,同理,实际上是将1/π扩大了2119倍。big_m表示两数相乘后的值,为257位。将big_m向左移n+1位后,即为整数部分q1,由整数部分可知该输入值落入的具体象限,在后面象限映射中只需取最后两位即可。将big_m向右移(257-n-1)位,即为小数部分r。接下来将r舍入到129位,根据就近舍入模式的定义对r进行舍入,得到129位的m_point。接下来将m_point乘以π/2,其中π/2的位宽设为129位,同样将乘积结果舍入到129位,得到m2。最后根据选择信号sel选择相应的m和q值。
四步并行迭代模块是本次设计的核心模块,主要负责x通道、y通道和z通道的迭代过程,以及符号因子的预测。其中ep_lock为异常使能信号,s’和q’为决定落入的象限,添加了ep_lock、s’和q’可以使得对于同一个输入数据,能够保持前后的一致性。xn和yn代表迭代结束后的x通道和y通道的输出值,正余弦函数运算四步并行迭代模块结构示意图如图6所示。
正余弦函数的计算中,δ的取值为{-1,1},x通道、y通道和z通道以迭代方式分别进行16组迭代计算,然后从z通道中选出16组结果z值中最接近于0的两个作为分支,经过二选一比较器,选出z值最接近于0的一个分支以及该分支对应的符号因子si=[δi,δi+1,δi+2,δi+3],与符号因子si=[δi,δi+1,δi+2,δi+3]对应的x通路迭代结果x值和y通路迭代结果y值直接作为本次四步并行迭代的结果。
根据加4计数器,z通道每次从查找表中取得4个弧度值,这里查找表位数为129位,其中最θi+1,θi+2,θi+3为确定的值,且θi>θi+1>θi+2>θi+3,s结合δ的取值,可知δiθi+δi+1θi+1+δi+2θi+2+δi+3θi+3的16个取值可以是从大到小的顺序,如式(5)所示。
其中ite_z0到ite_z7为正值,ite_z8到ite_z15为负值,并且存在一定的对称关系,前后8个一一对应的绝对值相等,所以只要计算ite_z0到ite_z7的值即可,ite_z8到ite_z15可取前八个相反数。
经过z通道四步迭代模块,将会得到两个最接近于0的zi+4值,接着经过二选一比较器选出最接近于0的zi+4值。如果zi+4的16个分支用z0到z15表示,对应的δiθi+δi+1θi+1+δi+2θi+2+δi+3θi+3为ite_z0到ite_z15,那么符号因子si=[δi,δi+1,δi+2,δi+3]相应取值为[1,1,1,1]到[0,0,0,0],其中1代表δi为1,0代表δi为-1。
四步并行迭代模块的瓶颈在于x通道和y通道中的大量计算,其中存在大量相同常数系数的乘法项,利用常数乘法器模块,对相同乘法项进行一次计算,可以减少乘法带来的计算负担。常数乘法器模块采用csd重编码方式,相比于基本二进制分解,该编码方式节约了近三分之一的代价。
xi+4的16个分支包含64次加减法,还可进一步优化。前后8个分支存在一定的对称性,可将其中重复的加法项和减法项只进行一次计算。图7为x通道四步并行迭代模块结构图。
首先xi和yi进入多常数乘法器模块,再根据加4计数器进行移位操作,这样使得xi和yi先左移后右移,减少了损失位数,可以有效提高精度。对称分支的前三项和后两项的运算为重复运算,为进一步减少关键路径延时,分支的前三项和后两项并行运算,经过最后一步加减运算就可得到两条分支的计算结果,另外14个分支的运算原理与此类似。通过z通道的选择信号si即可得到相应的xi+4。同理可得y通道的yi+4。
乘法器最大的常数系数为35,应在xi和yi的高位预留6位,本实施例采用有符号数的加减,应考虑一个符号位,再加上一个加法进位,所以xi和yi在输入四步并行迭代模块前,应在高位补充8位以防止溢出。此外在xi和yi的尾部增加了15位的补偿位宽,最终xi和yi的位宽设置为136位。查找表的位宽设为有符号的129位,加上zi的计算中存在的1个进位,1个符号位,最终zi位宽设置为131位。
浮点归一化模块还包括象限映射单元,浮点归一化模块负责将定点形式的xn和yn转化为标准浮点输出的x_out和y_out。象限映射单元根据输入的s’和q’值,将x_out和y_out映射到相应的象限,最后根据ep_lock使能信号,输出值sin和cosine就是最后我们需要求得的正余弦函数值。图8为标准浮点归一化模块的结构图。
象限映射单元根据符号位s’,象限标识q’,将x_out和y_out映射到相应的象限取值。当s’为0时,相应的输出关系如表4所示。当s’为1时,相应的输出关系如表4、表5所示。
表4s’=0对应的输出关系表
根据表4和5的对应关系得到输出x_out和y_out。其中x_out对应余弦函数计算结果,y_out对应正弦函数计算结果。最后还需经过一个多路选择器,根据异常使能信号ep_lock进行结果选择,该结果就是浮点正余弦函数运算单元的最终输出。
表5s’=1对应的输出关系表
cordic算法中反正切函数的计算不需要考虑伸缩比例因子,因此可进一步对四步并行分支迭代cordic算法进行改进。两个函数的硬件设计可用同一个查找表,其他模块都独立于正余弦函数。
和浮点正余弦函数运算部件的模块结构相同,浮点反正切函数运算主要分为四个部分:异常处理模块、预处理模块、四步并行迭代模块和标准化浮点归一化模块,浮点反正切函数运算整体结构示意图如图9所示。
预处理模块中首先将输入数据拆分,对其进行异常检测,如果存在异常,异常标志信号ep置1,以及给出异常处理结果ep_arc;如果输入数据合法,输入预处理模块对数据的指数部分和尾数部分进一步处理,保证
异常处理模块和预处理模块首先对异常输入和特殊输入进行检测和处理,如果输入合法,接着对两个输入值进行预处理,使其落入cordic算法可计算区域。
异常处理模块负责对异常输入和特殊输入进行处理。首先将输入的浮点数input_x拆分成符号位x_s,指数部分x_e和添加了隐藏位1的尾数部分x_m,将input_y拆分成y_s,y_e和y_m。然后对输入数据进行异常检测,当出现异常输入和特殊输入时,ep置1,异常输入主要包括以下几种:
(1)当input_x或input_y为nan,ep_arc设置为nan。
(2)当input_x和input_y都为无穷大或者都为无穷小时,ep_arc设置为nan。
特殊输入指的是该浮点反正切函数运算部件无法计算的输入域,主要包括以下几种:
(1)当input_y为0时,ep_arc设置为0。
(2)当input_x为0时,ep_arc设置为π/2。
(3)当x_e-y_e>128,在下一个模块对其进一步处理时,对y_m移位将超出128位,移位后的y_m为0,该运算部件的迭代过程将不会进行,ep_arc设置为0。
(4)当y_e-x_e>128时,由于位宽限制,对x_m移位将超出最高可移位数128位,此时arctan(input_y/input_x)的数值将接近于π/2,ep_arc设置为π/2。
异常检测完成后,如果输入合法,则进入输入预处理模块。将x_m和y_m后都扩展15位,提高小数值计算精度。对于反正切函数的计算,实施例将输入向量都转换到第一象限,将x_s和y_s作为象限标识符。根据y_e和x_e大小进行以下处理:
(1)当y_e>x_e时,将x_m右移(y_e-x_e)位得到x_m1,y_m赋值给y_m1。
(2)当y_e<x_e时,将y_m右移(x_e-y_e)位得到y_m1,x_m赋值给x_m1。
这样处理的原因在于,首先保证输入向量的模大于1,如果
四步并行迭代模块结构示意图如图10所示,采用单级循环结构,用的是向量模式,将δ取值改为{0,-1},使得向量保持在第一象限旋转。
y通道将会选出最接近于0且不越过x轴的那条分支,以及该分支对应的符号因子si=[δi,δi+1,δi+2,δi+3]。根据si选择相应的x通道和z通道分支结果。通道中每次迭代过程需要16次乘法,32次加法,其中乘法运算仍使用上节所介绍的多常数乘法器。y通道的16条分支中,最长路径延时是si=[δi,δi+1,δi+2,δi+3]为[-1,-1,-1,-1]对应的分支,将该分支的前三个运算和后两个运算并行计算,然后合并,减少关键路径延时。δi取值为0的好处在于,当向量预测会在下一步旋转越过x轴时,可以保持不旋转,那么符号因子的预测将变得很简单。将yi+4的16个分支取值从大到小排列,即si=[δi,δi+1,δi+2,δi+3]取值从0000到[-1,-1,-1,-1],每个分支的最高符号位组成16位的judge选择信号,judge与si对应关系如表3-6所示,其中si中的1代表δi取值为-1,0代表δi取值为0。根据judge选择相应的si。
将si=[δi,δi+1,δi+2,δi+3]取值从0000到[-1,-1,-1,-1]对应的zi+4的16条分支设置为z0到z15,由于θi>θi+1>θi+2>θi+3,z0到z15是从小到大的顺序,但有一个特殊情况,在第一次迭代中θi+1+θi+2+θi+3>θi,将导致z7>z8,所以在第一次迭代中,应将judge中这两个对应的yi+4最高符号位交换,才能保证judge值为连续0和连续1的形式。
表6judge与si对应表
该四步并行迭代模块的xi,yi位宽设置同样为136位。由于zi中只存在加法器,查找表可设为128位,加上一个进位,最终zi设置为129位。x、y、z通道迭代初始值分别为x0,y0,0,同正余弦迭代控制逻辑一样,需要32个周期即可完成反正切函数arctan(y0/x0)的计算。
标准化浮点归一化模块首先根据x_s和y_s对z_out做以下处理:
(1)当x_s=0时,z_out1仍为z_out。
(2)当x_s=1时,z_out1为π减去z_out。
其中π,z_out1设置为130位。同样采用树形编码的前导零检测,z_out1为无符号的130位,直接对z_out1进行前导零检测,然后进行归一化,得到e和m,s与y_s相同。将s、e和m组合成标准的浮点形式。最后根据异常使能信号ep_lock选择最终输出得到arctan。
在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的步骤、方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种步骤、方法所固有的要素。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!