一种基于BERT-base网络的带噪半监督文本分类方法与流程
本发明应用于自然语言处理(nlp)领域,具体涉及一种基于bert-base网络的带噪半监督文本分类方法。
背景技术:
随着通信、互联网技术的发展,数据已经成为了一种工业原材料,如何挖掘并利用隐藏在数据中的信息已经形成多个产业并且创造了巨大的经济效益。文本数据因为由人的直接表达生成,故产生成本最低,数量最大,包含信息也最为丰富。
在文本数据的众多应用中,分类是一个基础性工作。传统文本分类一般基于带标签数据做监督学习,但在实际的特定工业场景中,数据大多为无标签的原始数据,数据的标注可能需要耗费大量的人力资源,且人工标注的标签质量如何也值得怀疑,实际情况下甚至可能出现“训练数据越多,训练效果越差”的情况。故仅利用少量带标签数据和大量无标签数据的半监督学习方法就成为更加实际且低成本的选择。
目前的半监督学习大多应用于图像分类,近几年的主流方法都利用了一致性正则和最小化熵的思想。一方面,若对数据输入添加噪声,一个鲁棒的模型的输出应该是相似的;另一方面,模型在无标签数据上的熵应该尽可能最小化。无标签数据通过一次或数次增强后输入模型,用模型的较低熵输出作为其预测标签。与此同时,将该无标签数据用另一种方式扰动之后输入模型,此时模型的输出应该和刚刚得到的人工标签存在相似性。衡量“较低熵”的方法一般是看模型输出的概率分布中的最大概率是否超过某个阈值。如何衡量“相似性”则取决于选择何种损失函数,一般的选择有kl散度、交叉熵、l2正则等。但在文本半监督分类中有两方面的问题。一方面,如何将图像半监督分类中的一致性正则和最小化熵的思想应用于文本处理之中。对图像进行旋转、镜像、转换灰度等简单操作就可以在样本标签不变的条件下实现数据增强。然而在nlp中,文本数据具有一定离散特性,很难通过简单的转换来生成大量语义不变的扩充样本。尤其是短文本中,对部分词语的改动很可能直接改变整体语义,故直接在词向量上添加扰动并非最佳选择。另一方面,通过设定概率阈值来判断模型的输出的置信度,这种方法较为简单而直接,但在实际操作中的问题在于:由于阈值的存在,无标签数据可能会在模型训练中期甚至后期才会加入,而此时那些早已参与训练的少量带标签数据可能已经过拟合,用过拟合的模型去预测数据的标签,这种预测势必包含错误判断,且这种错误并非均匀分散的随机噪声,而是模型“死读书”之后产出的系统性噪声。故如何处理带标签和无标签数据的协同训练,如何处理模型预测中的噪声也是个问题。
技术实现要素:
本发明提供一种基于bert-base(bert是一种基于transformer架构的双向编码器)的带噪半监督文本分类方法,它对无标签样本通过回译方法产生新样本,然后通过模型预测将置信度较高的预测结果作为该新样本的预测标签;训练过程中,采用插值方法将带标签样本和无标签样本协同训练,并用梯度上升方法对无标签样本在模型中第3隐层的输出向量添加扰动,最后用改进的损失函数提高模型对于其预测标签中噪声的鲁棒性。
为实现上述目的,本发明采用的技术方案步骤如下:
s1、数据初始化阶段。将无标签样本做回译操作并产生新样本,然后将新样本输入模型,最后将其中高置信度的输出向量转化为对应one-hot标签。具体步骤如下:
s11、将无标签样本
s12、将样本
s13、若样本
s2、数据增强阶段。采用fgm(fastgradientmethod)方法添加扰动并作插值处理,具体步骤如下:
s21、bert-base网络主要由1个词向量编码层和12个transformer架构的隐藏层构成,这里针对无标签样本
s22、在bert-base网络中第7、9、12隐藏层中随机选择一层进行无标签样本和有标签样本隐藏层输出的插值操作。设
s221、利用beta分布产生一个0~1之间的随机数λ。
s222、取λ1=max{λ,1-λ},λ2=min{λ,1-λ},即λ1>λ2且λ1+λ2=1。
s223、计算
s224、将
s3、损失函数的构造阶段。损失函数loss=ls+lsce,第一项为带标签样本的模型输出
s31、lsce=μ1lce+μ2lrce。对称交叉熵包括两部分,lce为交叉熵,lrce反交叉熵。μ1和μ2是二者的超参数权重。具体公式为:
交叉熵:
反交叉熵:
其中i∈{1,2,…,nl},j∈{1,2,…,nu},因为
s32、ls为针对带标签样本的交叉熵。
s33、计算最终损失函数loss:loss=ls+lsce=ls+μ1lce+μ2lrce。
s4、模型参数更新阶段。
s41更新模型参数θ,即θ←θ-η▽θloss,η为学习率。
s42、在下一批次样本中重复步骤s1-步骤s4,每经过一批次样本的训练后验证模型预测正确率,若更新了当前最高正确率则保存该模型参数。若模型经过10批次训练后预测正确率仍未提高,则结束训练过程。
s5、用训练好的模型做文本的分类应用。
与现有方法相比,本发明有以下优点:
本发明基于如今较为流行的bert-base模型实现了一种针对文本分类的半监督的带噪学习方法。(1)相比传统半监督学习方法,本发明更为细致地考虑到模型预测标签中的噪声问题,并引入图像带噪学习领域的对称交叉熵,降低了模型误判的影响。(2)再将其和插值方法融合,形成了全新的two-hot模式下的对称交叉熵,提升了模型泛化性能的同时将带标签和无标签样本协同训练,尽量减少了训练过程中在部分数据的过拟合现象。(3)在插值操作中,相比传统做法中将所有样本随机打乱后插值的粗犷做法,本发明较为细致地始终保持无标签样本和带标签样本间的交叉,且在权值的选择上尽量保持损失函数梯度下降时对真实标签的偏向性,这进一步减轻了模型误判带来的影响。(4)相比传统做法中直接在词向量上添加扰动,本发明选择bert-base隐层输出向量作为扰动对象,从而尽量减少扰动操作对样本语义上的过度修改。
附图说明
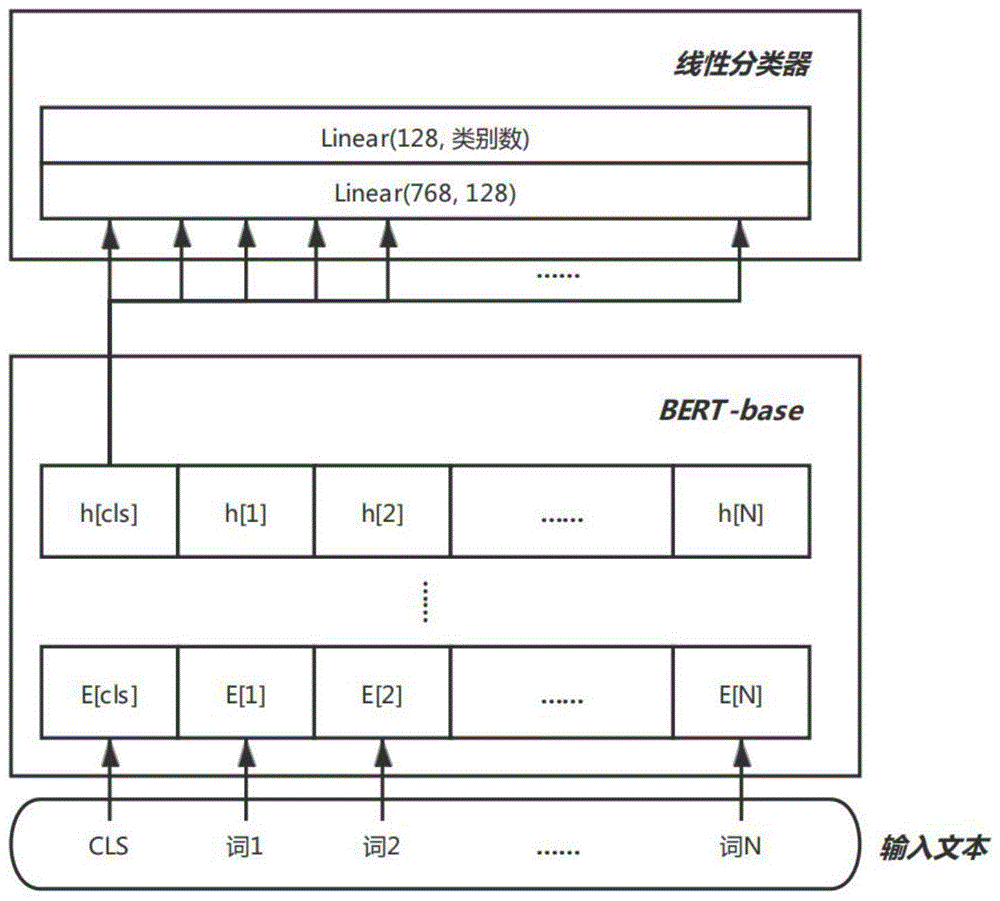
图1为模型主要结构图;
图2为本发明中基于bert-base的半监督带噪学习方法的单轮训练流程图;
图3为本发明中扰动和插值操作示意图;
具体实施方式
下面将结合附图对本发明的具体实施细节做进一步阐述。
一种基于bert-base的半监督带噪文本分类方法,模型结构如图1所示,它由词向量编码器和12层transformer架构的隐层构成。bert-base通过多层运算后,取语句开始标志(cls)的最终隐层输出向量作为整句话的语义表达向量,然后针对该语义向量用一个两层线性分类器做最终分类。
本方法主要分四个阶段:s1数据初始化阶段、s2数据增强阶段、s3损失函数的构造阶段、s4模型参数更新阶段、s5模型应用阶段。结合图2,本发明的步骤如下:
s1、数据初始化阶段。对无标签样本做回译操作并产生新样本。将新样本输入模型,将其中高置信度的输出向量转化为对应one-hot标签。具体包括:
s11、将无标签样本
s12、将样本
s13、若样本
s2、数据增强阶段。结合图3所示,采用fgm(fastgradientmethod)方法添加扰动并作插值处理。由于文本中语义的表达并不连续,对部分关键词的改变可能导致整体语义的过度反差,而研究表明,bert一些特定隐层输出在句法语义等信息的提取中效果较好,故在bert中特定transformer隐层而非词向量编码层做扰动和插值处理。步骤s2具体为:
s21、bert-base网络主要由1个词向量编码层和12个transformer架构的隐藏层构成,这里针对无标签样本
s22、在bert-base网络中第7、9、12隐藏层中随机选择一层进行无标签样本和有标签样本隐藏层输出的插值操作。设
s221、利用beta分布产生一个一个0-1之间的随机数λ。
s222、取λ1=max{λ,1-λ},λ2=min{λ,1-λ},即λ1>λ2且λ1+λ2=1
s223、计算
s224、将
s3、损失函数的构造阶段。损失函数loss=ls+lsce,第一项为对带标签样本的模型输出
s31、lsce=μ1lce+μ2lrce。对称交叉熵包括两部分,lce为传统交叉熵,lrce反交叉熵。μ1和μ2是二者的超参数权重。具体公式为:
交叉熵:
反交叉熵:
i∈{1,2,…,nl},j∈{1,2,…,nu},因为
以下为本发明中构造的two-hot模式反交叉熵的有效性的解释,以单个带标签样本和单个无标签样本为例:
lrce=-pilogλ1-pjlogλ2-(1-pi-pj)a
其中,zi和zj分别表示正确标签和预测标签所属类别处模型softmax前的输出,zc表示错误类别处模型softmax前的输出。pi和pj分别表示正确标签和预测标签所属类别处模型的最终输出,pc表示错误类别处模型的最终输出。
因为0<λ1,λ2<1,a<0,two-hot模式下pi和pj基本在0~0.5范围内,故:
即lrce的下降会使得正确类别处的输出zi和zj上升,错误类别处的输出zc下降,符合损失函数基本目的,lrce可加速loss的梯度下降。
研究表明,误判情况的偶发性导致模型对于错误标签的预测置信度不会很高,所以若pj对应的预测标签属于误判,则较小的一次项可对
s32、ls为针对带标签样本的交叉熵。
s33、计算最终损失函数:loss=ls+lsce=ls+μ1lce+μ2lrce。
s4、模型参数更新阶段。
s41、更新模型参数θ,即θ←θ-η▽θloss,η为学习率。
s42、在下一批次样本中重复步骤s1-步骤s4,每经过一批次样本的训练后验证模型预测正确率,若更新了当前最高正确率则保存该模型参数。若模型经过10批次数据训练后预测正确率仍未提高,则结束训练过程。
s5、模型应用阶段。使用s42步骤中训练好的模型,将测试文本输入模型,模型输出向量中最大概率处对应的类别即为预测所属的分类。
综上所述,本发明将图像半监督分类的思想方法引入自然语言处理领域,提出了基于bert-base模型的半监督带噪文本分类方法。
通过更为细致地在bert-base隐层中做扰动和插值处理,本发明减少了由于对词向量直接改动而导致语义过度变化的情况,并使得模型在提升鲁棒性和泛化性能的同时将带标签和无标签样本协同训练,尽量减少了训练过程中在部分数据的过拟合现象。
考虑到预测标签中的噪声处理问题,本发明引入图像带噪学习领域的对称交叉熵,并将其和插值处理融合,形成了two-hot模式下的对称交叉熵。插值处理时更细致的权重选择使得训练过程总是略微偏向真实标签,这进一步减轻了预测标签中的噪声对训练过程的影响,提升了模型训练过程的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!