基于案情事实的法条智能推荐方法及系统及装置及介质与流程
本发明涉及自然语言处理领域,具体地,涉及基于案情事实的法条智能推荐方法及系统及装置及介质。
背景技术:
目前司法领域基于案情事实的法条推荐技术主要存在着两个问题:第一是案情事实和法条的交互不充分,目前已有的系统是单独编码案情事实和法条,在编码的基础上在利用注意力机制做交互;第二是系统面临着过拟合的问题,已有的方法在训练模型时使用softmax,导致案情事实和法条之间的相似度很容易掉入过拟合陷阱,从法律判案的角度讲,案情事实与法条的确是需要精确一对一的映射,但是从自然语言的角度讲,案情事实和法条的匹配度并不是说要么完全匹配要么完全不匹配,而是具有一定的匹配度,导致目前的案情事实的法条推荐不准确。
技术实现要素:
本发明目的是使基于案情事实的法条推荐的结果更加精准,更加高效地辅助法官判案。
为实现上述目的,本发明提供了基于案情事实的法条智能推荐方法,所述方法包括:
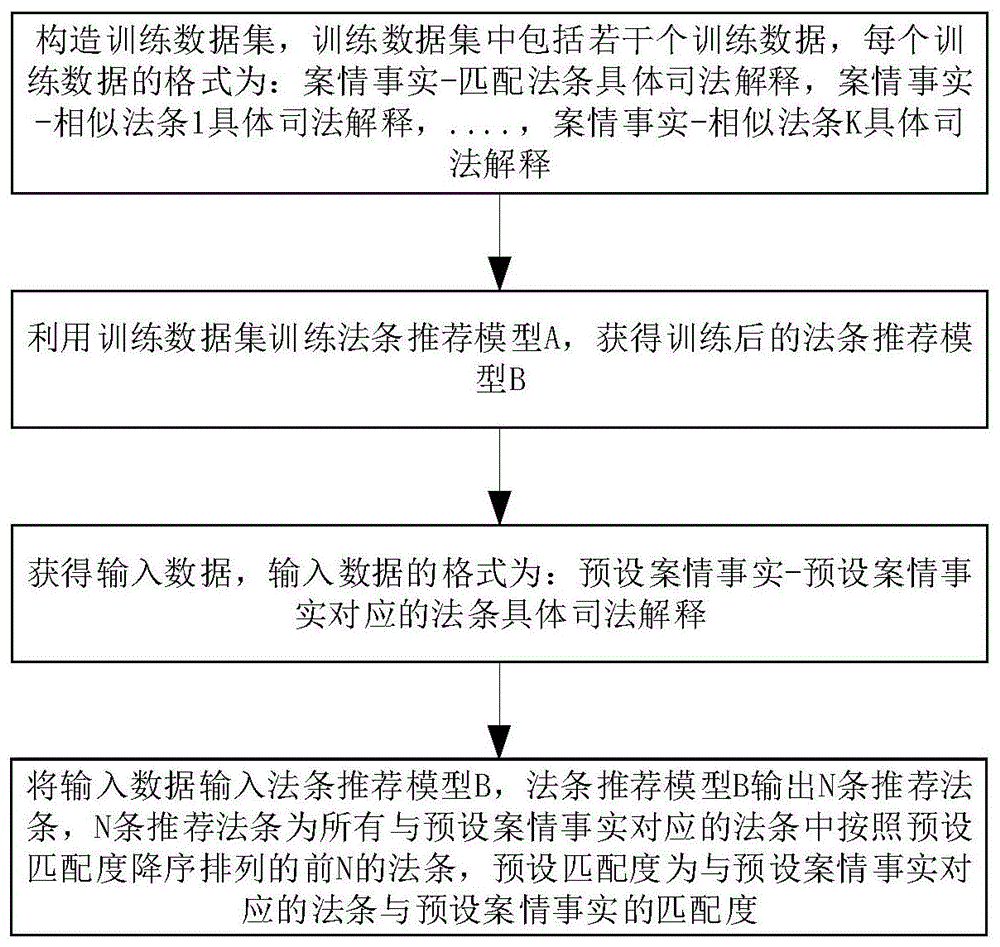
构造训练数据集,训练数据集中包括若干个训练数据,每个训练数据的格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,....,案情事实-相似法条k具体司法解释,k为大于1的整数;
利用训练数据集训练法条推荐模型a,获得训练后的法条推荐模型b;
获得输入数据,输入数据的格式为:预设案情事实-预设案情事实对应的法条具体司法解释;
将输入数据输入法条推荐模型b,法条推荐模型b输出n条推荐法条,n条推荐法条为所有与预设案情事实对应的法条中按照预设匹配度降序排列的前n的法条,预设匹配度为与预设案情事实对应的法条与预设案情事实的匹配度,n为大于或等于1的整数。
其中,本发明的原理为:首先从法官判案的司法角度出发,案情事实与法条的确有着匹配的关系;其次我们的发明使用的基于bert的siamese网络模型、定义的损失函数以及构造的训练数据集,可以让模型学习到案情事实和法条之间的相互语义关系(匹配度),充分使用了bert的self-attention机制来使得案情事实和法条之间做语义上的充分交互,tripletloss可以有效地降低训练时的过拟合,从而使得最终模型的推荐更加的精确。
优选的,本方法中构造训练数据集具体包括:
从裁判文书中抽取案情事实a和与案情事实a对应的法条b;
从法规库中抽取法条b对应的司法解释d;
基于司法解释d,生成与法条b相似度降序排列的前topk个相似法条;
构造数据e,数据e格式为:案情事实a,匹配法条具体司法解释,相似法条1具体司法解释,相似法条2具体司法解释,…相似法条k具体司法解释;
将数据e转化为训练数据f,训练数据f格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释;其中,案情事实-匹配法条具体司法解释为匹配数据,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释为非匹配数据。
优选的,本方法中法条推荐模型包括:
输入层、bert层、fc层和输出层;其中,输入层包括第一输入子层和第二输入子层,bert层包括第一bert模块和第二bert模块,fc层包括:第一fc子层和第二fc子层;
其中,法条推荐模型训练时,第一输入子层的输入数据为训练数据中的匹配数据,第二输入子层的输入数据为训练数据中的非匹配数据;
第一输入子层的输入数据输入至第一bert模块,第一bert模块输出至第一fc子层,第一fc子层输出至输出层,第一fc子层输出匹配法条与案情事实的匹配度;
第二输入子层的输入数据输入至第二bert模块,第二bert模块输出至第二fc子层,第二fc子层输出至输出层,第二fc子层输出非匹配法条与案情事实的匹配度。
优选的,本方法中法条推荐模型的第一bert模块和第二bert模块共享权重参数,第一fc子层和第二fc子层共享权重参数。
优选的,本方法中法条推荐模型的输出层中设有tripletloss函数,tripletloss=max(0,margin+p_neg-p_pos),margin作为超参数调优,p_neg为非匹配法条与案情事实的匹配度,p_pos为匹配法条与案情事实的匹配度。
本发明还提供了基于案情事实的法条智能推荐系统,所述系统还包括:
构造单元,用于构造训练数据集,训练数据集中包括若干个训练数据,每个训练数据的格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,....,案情事实-相似法条k具体司法解释,k为大于1的整数;
训练单元,用于利用训练数据集训练法条推荐模型a,获得训练后的法条推荐模型b;
输入数据获得单元,用于获得输入数据,输入数据的格式为:预设案情事实-预设案情事实对应的法条具体司法解释;
法条推荐模型b,用于处理输入法条推荐模型b的输入数据输出n条推荐法条,n条推荐法条为所有与预设案情事实对应的法条中按照预设匹配度降序排列的前n的法条,预设匹配度为与预设案情事实对应的法条与预设案情事实的匹配度,n为大于或等于1的整数。
优选的,本系统中构造单元具体包括:
第一抽取子单元,用于从裁判文书中抽取案情事实a和与案情事实a对应的法条b;
第二抽取子单元,用于从法规库中抽取法条b对应的司法解释d;
生成子单元,用于基于司法解释d,生成与法条b相似度降序排列的前topk个相似法条;
构造子单元,用于构造数据e,数据e格式为:案情事实a,匹配法条具体司法解释,相似法条1具体司法解释,相似法条2具体司法解释,…相似法条k具体司法解释;
转化子单元,用于将数据e转化为训练数据f,训练数据f格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释;其中,案情事实-匹配法条具体司法解释为匹配数据,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释为非匹配数据。
优选的,本系统中法条推荐模型包括:
输入层、bert层、fc层和输出层;其中,输入层包括第一输入子层和第二输入子层,bert层包括第一bert模块和第二bert模块,fc层包括:第一fc子层和第二fc子层;
其中,法条推荐模型训练时,第一输入子层的输入数据为训练数据中的匹配数据,第二输入子层的输入数据为训练数据中的非匹配数据;
第一输入子层的输入数据输入至第一bert模块,第一bert模块输出至第一fc子层,第一fc子层输出至输出层,第一fc子层输出匹配法条与案情事实的匹配度;
第二输入子层的输入数据输入至第二bert模块,第二bert模块输出至第二fc子层,第二fc子层输出至输出层,第二fc子层输出非匹配法条与案情事实的匹配度。
优选的,本系统中法条推荐模型的第一bert模块和第二bert模块共享权重参数,第一fc子层和第二fc子层共享权重参数。
优选的,本系统中法条推荐模型的输出层中设有tripletloss函数,tripletloss=max(0,margin+p_neg-p_pos),margin作为超参数调优,p_neg为非匹配法条与案情事实的匹配度,p_pos为匹配法条与案情事实的匹配度。
本发明还提供了一种基于案情事实的法条智能推荐装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述基于案情事实的法条智能推荐方法的步骤。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述基于案情事实的法条智能推荐方法的步骤。
本发明提供的一个或多个技术方案,至少具有如下技术效果或优点:
本发明实现了基于案情事实的法条的智能推荐,使用模型为基于bert的siamesenetwork,主要目的是充分使用bert的自注意力机制去保证案情事实和法条的充分attend(注意),同时使用tripletloss来对抗过拟合陷阱,tripletloss函数只需要我们的模型取得正样本的匹配度比负样本的匹配度大于某个margin阈值即可,因此留有了一定的匹配灰度,防止过拟合。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本发明的一部分,并不构成对本发明实施例的限定;
图1为基于案情事实的法条智能推荐方法的流程示意图;
图2是本发明中训练模型的结构示意图;
图3是本发明中预测模型的结构示意图;
图4是本发明中基于案情事实的法条智能推荐系统的组成示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
可以理解的是,术语“一”应理解为“至少一”或“一个或多个”,即在一个实施例中,一个元件的数量可以为一个,而在另外的实施例中,该元件的数量可以为多个,术语“一”不能理解为对数量的限制。
实施例一
附图1为基于案情事实的法条智能推荐方法的流程示意图,本发明实施例一提供了基于案情事实的法条智能推荐方法,所述方法包括:
构造训练数据集,训练数据集中包括若干个训练数据,每个训练数据的格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,....,案情事实-相似法条k具体司法解释,k为大于1的整数,本发明中相似法条k的数目可以根据实际需要进行调整,本发明不进行具体的限定;
利用训练数据集训练法条推荐模型a,获得训练后的法条推荐模型b;
获得输入数据,输入数据的格式为:预设案情事实-预设案情事实对应的法条具体司法解释;
将输入数据输入法条推荐模型b,法条推荐模型b输出n条推荐法条,n条推荐法条为所有与预设案情事实对应的法条中按照预设匹配度降序排列的前n的法条,预设匹配度为与预设案情事实对应的法条与预设案情事实的匹配度,n为大于或等于1的整数。
本方法将使用bert-basedsiamesenetwork作为模型架构,使用tripletloss做为损失函数来训练,然后使用该网络做法条的预测推荐。
下面将从数据集的构造、训练和预测对本发明做详细的阐述。
构造训练数据集。针对某一个案由,从公开的裁判文书中,基于规则抽取所有的案情事实和对应的法条(本发明中的规则可以是预设的也可以是根据实际需要灵活调整的,本发明不进行具体的限定,可以是自动抽取也可以是手动抽取,本发明不进行具体的限定,如专业法律人士手工标注训练数据);从法规库中(其中规库就是一个法条的名字和相应司法解释的对应关系;比如:《中华人名共和国物权法》第十六条:【不动产登记簿效力及其管理机构】不动产登记簿是物权归属和内容的根据。不动产登记簿由登记机构管理),抽取上述法条对应的司法解释;基于法条对应的具体司法解释,使用关键字和语义相似性技术生成每个法条最相似的topk其它法条对应关系(相似的法条为指根据司法解释中出现的关键字的重叠情况、司法解释的编辑距离、以及sent2vec语义编码等技术来提取相似的司法解释作为非匹配的法条)。从而,可以构造出(案情事实,匹配法条具体司法解释,相似法条1具体司法解释,相似法条2具体司法解释,…相似法条k具体司法解释)的数据。对上述的数据进一步的转化成(案情事实,匹配法条具体司法解释),(案情事实,相似法条1具体司法解释),…,(案情事实,相似法条k具体司法解释);前一条数据称为匹配数据,后面k条数据称为非匹配数据,这一组数据都是针对同一个案情事实描述。
训练模型。其模型架构图如图2所示,法条推荐模型包括:输入层、bert层、fc层和输出层;其中,输入层包括第一输入子层和第二输入子层,bert层包括第一bert模块和第二bert模块,fc层包括:第一fc子层和第二fc子层。
法条推荐模型采用bert-basedsiamesenetwork,使用tripletloss作为训练的损失函数。上述针对的同一个案情事实将构造出若干个训练数据,每个训练数据的格式为((案情事实,匹配法条具体司法解释),....,(案情事实,相似法条k具体司法解释))。该输入主要目的是充分利用bert的自注意力机制,使得案情事实和法条句子充分地相互注意(attend);bert层共享权重参数,取bert的cls输出并接入fc(全连接层),fc层同样共享权重参数。fc层输出是一个0到1的数字,表示案情事实和法条解释的匹配程度。法条推荐模型最终的输出p_pos和p_neg分别表示针对同一个案情事实,匹配法条和非匹配法条的匹配度,最后接入tripletloss函数max(0,margin+p_neg-p_pos),margin作为超参数调优。
模型预测。使用如图3所示的方式做模型预测也即法条推荐。预测模型的bert层和fc层的参数都是上述训练模型得到的参数,对于前述的法条集中的每一个法条,构造预测模型的输入(案情事实,法条具体司法解释),对预测模型的最终输出的匹配度取topn最大值作为相应的推荐法条。
实施例二
如图4所示,本发明实施例二提供了基于案情事实的法条智能推荐系统,所述系统还包括:
构造单元,用于构造训练数据集,训练数据集中包括若干个训练数据,每个训练数据的格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,....,案情事实-相似法条k具体司法解释,k为大于1的整数;
训练单元,用于利用训练数据集训练法条推荐模型a,获得训练后的法条推荐模型b;
输入数据获得单元,用于获得输入数据,输入数据的格式为:预设案情事实-预设案情事实对应的法条具体司法解释;
法条推荐模型b,用于处理输入法条推荐模型b的输入数据输出n条推荐法条,n条推荐法条为所有与预设案情事实对应的法条中按照预设匹配度降序排列的前n的法条,预设匹配度为与预设案情事实对应的法条与预设案情事实的匹配度,n为大于或等于1的整数。
其中,在本发明实施例二中,本系统中构造单元具体包括:
第一抽取子单元,用于从裁判文书中抽取案情事实a和与案情事实a对应的法条b;
第二抽取子单元,用于从法规库中抽取法条b对应的司法解释d;
生成子单元,用于基于司法解释d,生成与法条b相似度降序排列的前topk个相似法条;
构造子单元,用于构造数据e,数据e格式为:案情事实a,匹配法条具体司法解释,相似法条1具体司法解释,相似法条2具体司法解释,…相似法条k具体司法解释;
转化子单元,用于将数据e转化为训练数据f,训练数据f格式为:案情事实-匹配法条具体司法解释,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释;其中,案情事实-匹配法条具体司法解释为匹配数据,案情事实-相似法条1具体司法解释,…,案情事实-相似法条k具体司法解释为非匹配数据。
其中,在本发明实施例二中,本系统中法条推荐模型包括:
输入层、bert层、fc层和输出层;其中,输入层包括第一输入子层和第二输入子层,bert层包括第一bert模块和第二bert模块,fc层包括:第一fc子层和第二fc子层;
其中,法条推荐模型训练时,第一输入子层的输入数据为训练数据中的匹配数据,第二输入子层的输入数据为训练数据中的非匹配数据;
第一输入子层的输入数据输入至第一bert模块,第一bert模块输出至第一fc子层,第一fc子层输出至输出层,第一fc子层输出匹配法条与案情事实的匹配度;
第二输入子层的输入数据输入至第二bert模块,第二bert模块输出至第二fc子层,第二fc子层输出至输出层,第二fc子层输出非匹配法条与案情事实的匹配度。
优选的,本系统中法条推荐模型的第一bert模块和第二bert模块共享权重参数,第一fc子层和第二fc子层共享权重参数。
其中,在本发明实施例二中,本系统中法条推荐模型的输出层中设有tripletloss函数,tripletloss=max(0,margin+p_neg-p_pos),margin作为超参数调优,p_neg为非匹配法条与案情事实的匹配度,p_pos为匹配法条与案情事实的匹配度。
实施例三
本发明还提供了一种基于案情事实的法条智能推荐装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述基于案情事实的法条智能推荐方法的步骤。
其中,所述处理器可以是中央处理器(cpu,centralprocessingunit),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor)、专用集成电路(applicationspecificintegratedcircuit)、现成可编程门阵列(fieldprogrammablegatearray)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的数据,实现发明中基于案情事实的法条智能推荐装置的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等。此外,存储器可以包括高速随机存取存储器、还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡,安全数字卡,闪存卡、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
实施例四
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述基于案情事实的法条智能推荐方法的步骤。
所述基于案情事实的法条智能推荐装置如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序可存储于一计算机可读存介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码、对象代码形式、可执行文件或某些中间形式等。所述计算机可读取介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器、随机存储器、点载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!