一种基于Word2Vec-BiLSTM-CRF模型的法律领域的实体抽取方法与流程
一种基于word2vec
‑
bilstm
‑
crf模型的法律领域的实体抽取方法
技术领域
1.本发明涉及命名实体识别领域,尤其涉及一种基于word2vec
‑
bilstm
‑
crf模型的法律领域的实体抽取方法。
背景技术:
2.在法律领域,无论是在案件的侦查过程中,或是对于法院的审理诉讼而言,其涉及的命名实体种类众多且复杂。这些实体中最常见的是案情经过的要素,例如人物(犯罪嫌疑人、被害人)、时间、地点、动机、事件等。对于这些不同的案件要素,在不同的刑法罪名语境背景下有着不同的特点和表现形式。
3.法律领域中的实体种类繁多,这些实体的表示形式又各不相同。用一种统一的方法识别这些表示形式不同的命名实体,实现法律领域实体的细粒度刻画,法律领域的数据结构化,进一步挖掘法律领域的不同实体之间的关系具有重要意义。
4.2020年02月18日公开的公开号第cn110807084a号中国专利揭露了一种基于注意力机制的bi
‑
lstm和关键词策略的专利术语关系抽取方法,其包括以下步骤:步骤1):对专利文本进行预处理,识别出术语特征,同时加入位置信息,并通过改进的textrank算法获得类别关键词特征,并将其组成向量矩阵;步骤2):将向量矩阵导入bi
‑
lstm模型中,采用注意力机制获得文本信息的整体特征;步骤3):利用最大池化层选择每个句子的关键特征作为局部特征;步骤4):将整体特征和局部特征融合;步骤5):使用softmax分类器输出分类结果。本发明以专利术语关系抽取为基础,针对传统深度学习方法中存在的长距离依赖问题,通过各种实验对比,本发明的效果优于已有的方法,可以很好地满足实际应用的需要。
5.由于专利相对相对法律领域,其命名实体简单、统一,该方法可以实现对专利术语的抽取,但该抽取方法的效果无法应用于命名实体复杂的法律领域,无有效的识别法挖掘法律领域的实体,抽取效果差。
6.因此,有必要提供一种新的抽取方法解决上述问题。
技术实现要素:
7.为解决上述背景技术中提出的问题,本发明提供了一种基于word2vec
‑
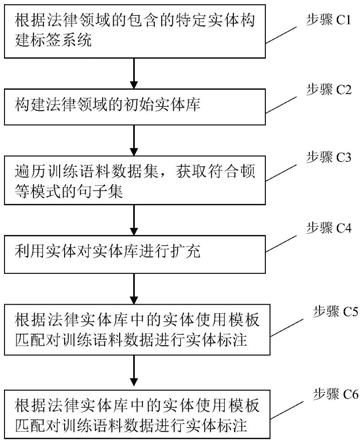
bilstm
‑
crf的法律领域的命名实体识别方法,能够挖掘法律领域的不同实体之间的关系,。
8.为实现上述目的,本发明提供如下技术方案:一种基于word2vec
‑
bilstm
‑
crf的法律领域的命名实体识别方法,具体包括以下步骤:
9.获取法律领域的原始数据并进行数据的预处理,获得的训练语料数据;将步骤a中获得的训练语料数据,输入word2vec算法结合cbow模型,从而得到针对于法律领域的词向量;将步骤a中预处理获取的训练语料数据,结合模板匹配和中文语料的顿等模式进行标注,获取标注语料,具体的:根据法律领域的包含的特定实体构建标签系统,采用bio标注模式,b标签作为实体的开始,i标签表示实体的非开始部分,o表示非实体部分;构建法律领域
的初始实体库;遍历训练语料数据集,获取符合顿等模式的句子集;使用顿等模式匹配初始实体库中实体的同义词、并列词,利用这些实体对实体库进行扩充;根据法律实体库中的实体使用模板匹配对训练语料数据进行实体标注;通过人工筛查的方式对c5获取的标注后的训练预料数据进行核查,纠正、补标实体,并对实体库进行更新,最终获得标注正确的训练语料数据;以bi
‑
lstm作为模型的编码层,将步骤c中获得的标注语料与b步骤中获得词向量相结合作为编码层的输入,输出得到文本语义信息特征;将步骤d中bi
‑
lstm层获取的文本语义信息特征作为crf的输入,最终输出命名实体的识别结果。
10.构建法律领域的特定停用词表,利用jieba、ltp中文分词工具对步骤a中获得的训练语料数据进行分词、去停用词;使用word2vec算法结合cbow模型将词汇包含的语义信息转换为n维词向量,得到法律领域的特定词向量。
11.与现有技术相比,本发明基于word2vec
‑
bilstm
‑
crf的法律领域的实体抽取方法的有益效果是:识别法律文书中种类丰富的实体,实现法律领域实体的细粒度刻画,法律领域的数据结构化,进一步挖掘法律领域的不同实体之间的关系具有重要意义。
附图说明
12.图1为本发明基于word2vec
‑
bilstm
‑
crf的法律领域的实体抽取方法流程示意图。
13.图2为本发明获取标注语料的流程图。
具体实施方式
14.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
15.下面结合附图及实施例对本发明做进一步说明。
16.请参照图1,本发明提供一种基于word2vec
‑
bilstm
‑
crf的法律领域的实体抽取方法,具体包括以下步骤:
17.:获取法律领域的原始数据并进行数据的预处理,获得的训练语料数据,包括如下步骤:
18.步骤a1:通过爬虫技术结合人工筛选,从互联网中获取法律领域的原始数据,包括法律领域的案情陈述、诉讼报告、裁判文书等;
19.步骤a2:对获取的半结构化或非结构化的多源数据进行初步清洗和降噪,获取可用的数据信息。
20.步骤b:训练法律领域的词向量;即将步骤a中获得的训练语料数据,输入word2vec算法结合cbow模型,从而得到针对于法律领域的词向量;其步骤包括:
21.步骤b1:构建法律领域的停用词表,使用jieba、ltp等中文分词工具对训练语料数据进行分词以及去停用词;
22.步骤b2:使用word2vec算法得到针对于法律领域的字向量;
23.步骤b3:word2vec算法使用cbow模型将语义信息转化为n维向量。cbow模型的训练输入是某一个特征词的相关的词对应的字向量,而输出就是这特定的一个词的词向量,能
够很好地保存上下文的语义信息。
24.步骤c:针对步骤a中预处理获取的训练语料数据,构建法律领域的初始实体库,结合模板匹配和中文语料的顿等模式进行标注,顿等模式可以有效地降低人工标注的工作,获取标注语料;其步骤包括:
25.步骤c1:针对法律领域的命名实体构建标签系统,命名实体有法律的种类、组分以及特性组成;采用bio标注模式,b标签作为实体的开始,i标签表示实体的非开始部分,o表示非实体部分;
26.步骤c2:人工构建法律领域的初始实体库;
27.步骤c3:遍历训练语料数据集,获取符合顿等模式的句子集;
28.在中文语料当中,顿号的用法主要是罗列某一类词的同义词,在语料中出现的实体假设前后有顿号出现,那么并列的常常都是该实体的同类词或同义词,可以作为实体对实体库进行补充,这种模式称为“顿等模式”。
29.顿等模式不仅限于顿号连接的前后实体,通常还有如下的一些表现形式:
[0030][0031]
步骤c4:使用顿等模式匹配初始实体库中实体的同义词、并列词等,利用这些实体对实体库进行扩充;
[0032]
步骤c5:根据法律实体库中的实体使用模板匹配对训练语料数据进行实体标注;
[0033]
步骤c6:通过人工筛查的方式对c5获取的标注后的训练预料数据进行核查,纠正、补标实体,并对实体库进行更新,最终获得标注正确的训练语料数据。
[0034]
步骤d:将bi
‑
lstm模型作为编码层,x=(x1,x2,x3,
…
,x
n
)作为编码层的输入,其中x
i
为步骤c中标注完成的训练语料数据中每个字对应的步骤b训练得到的法律领域的字向量;
[0035]
f
t
=σ(w
f
·
[h
t
‑1,x
t
]+b
f
)
[0036]
i
t
=σ(w
i
·
[h
t
‑1,x
t
]+b
i
)
[0037][0038][0039]
o
t
=σ(w
o
·
[h
t
‑1,x
t
]+b
o
)
[0040]
h
t
=o
t
*tanhc
t
[0041]
{h0,h1,...,h
n
}={[h
l0
,h
rn
],[h
l1
,h
r(n
‑
1)
],...,[h
ln
,h
r0
]}
[0042]
bi
‑
lstm能够在指定的时间范围内有效地使用过去的特征(通过前向状态)和未来的特征(通过后向的状态),使用通过时间的反向传播来训练双向lstm网络。
[0043]
步骤e:将bi
‑
lstm层获取的标签向量特征输入crf层,得到每个字标签的得分;
[0044]
crf层能够有效地利用句子级的标签信息,为进一步挖掘法律领域的不同实体之间的关系,设置约束条件确保最终的预测有效,该约束条件能够在训练数据时被crf层自动学习。具体的,
[0045]
将需要识别实体的句子表示为下式,x
i
表示句中的字:
[0046]
x=(x1,x2,...,x
n
);
[0047]
该语句对应的标签为:
[0048]
y=(y1,y2,...,y
n
);
[0049]
确定从识别实体对应语句对应的打分方法函数表达方式:
[0050][0051]
其中a是转移分数矩阵,a
i,j
表示从标签i转移到标签j的分数,其中y0和y
n
分别是句子的开始和结束标签;所以a的纬度为(k+2)*(k+2)(k为标签数);p是bi
‑
lstm网络输出的分数矩阵,纬度为n*k(k为标签数),p
i,j
表示句子中第i个词对应第j个标签的分数。
[0052]
目的是以获得打分函数的最大值。
[0053]
对于给定句子x,得到标签y的概率是:
[0054][0055]
y
x
表示句子x对应的所有可能的标签序列,也就是说句子对应的每个标签序列都有一个分值还有一个概率,目的是让句子对应的真实序列大概率最大。
[0056]
另外,提供一损失函数,获得损失函数中的值最小,变换为下式:
[0057][0058]
以获得出损失函数中的最小值。
[0059]
用似然公式表示:
[0060][0061]
最终输出识别的案件经过中的人物、动机、事件等命名实体。从而识别法律文书中种类丰富的实体,实现法律领域实体的细粒度刻画,法律领域的数据结构化,进一步挖掘法律领域的不同实体之间的关系。
[0062]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1