一种便携式烧伤深度鉴定设备及其设计方法与流程
[0001]
本发明涉及智能硬件及辅助医疗诊断领域,具体地涉及一种基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备及其设计方法。
背景技术:
[0002]
烧伤深度诊断是烧伤伤情判断的重要环节,可靠有效的烧伤创面严重程度评估是临床决策的基础。临床评估是目前常用和普遍的判断方式,然而这种主观判断的影响因素较多,诊断水平参差不齐;基于多种检测工具的客观诊断方法多种多样,但受到成本、操作方式、准确性等因素的制约,目前为止仍未有一种令人满意的诊断工具。有学者将创面图像检测工具与计算机技术结合,提高了深度诊断准确性并在一定程度上实现了自动化智能诊断,该方法为医学智能化诊断开辟了新的思路,但如何便捷、快速、准确、低成本地实现人工智能辅助诊断,业界仍未有完整的解决方案。
[0003]
图像语义分割是图像处理和是机器视觉技术中关于图像理解的重要一环,也是人工智能领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别从而进行目标区域的划分。由于能够实现对单像素分类的特点,图像语义分割在人工智能辅助诊断起到了重要作用。然而,相比传统的卷积神经网络结构,语义分割网络不仅包括基本的下卷积层,还需要同等数量的上卷积层进行图像重构,加大了运算负担。目前,对于运算密集的神经网络推理任务,通常采用专用硬件电路进行硬件加速。常见的硬件加速设备有图像处理器(gpu)、专用集成电路(asic)和现场可编程门阵列(fpga),而fpga由于可重构、低功耗、灵活可配置等优势,适合作为便携式设备的硬件加速单元。
技术实现要素:
[0004]
有鉴于此,本发明提出了一种基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备及其设计方法,通过语义分割网络,根据不同区域的烧伤程度对烧伤图像进行分割和鉴定;通过fpga实现语义分割网络前向推理运算的硬件加速,实现烧伤图像的本地处理。相比部署于gpu或大型深度学习专用服务器上的推理方案,本发明的技术方案具有低延迟、低功耗等优势。
[0005]
本发明的技术方案是:一种基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备,采用通用处理器(cpu)和现场可编程门阵列(fpga)相结合的异构片上系统,搭载专用卷积神经网络加速器,进行本地化烧伤图像的语义分割网络加速,对图像采集模块采集的病人皮肤表面烧伤数据进行实时分割与分类,并将数据通过网络模块上传至服务器。同时,用户可以通过图形化交互子系统对设备进行操作;优选技术方案中,异构片上系统采用通用处理器作为系统调度(ps)端,以此为基础构建专用嵌入式linux操作系统,用于各模块和子系统的整体调度;所述异构片上系统采用fpga作为数据处理(pl)端,以此为基础构建烧伤图像语义分割网络硬件加速器,用于优化
摄像头模块采集的图像数据流和加快神经网络前向推理速度;优选技术方案中,所述的烧伤图像语义分割网络硬件加速器,其特征在于,包括如下单元:图像预处理单元,用于输入烧伤图像预处理;卷积神经网络推理单元,用于卷积神经网络前向推理,输出分割图像;数据流指令解析单元,用于数据流控制指令的解析和计算指令输出;数据加载和控制单元,用于烧伤图像的读取、储存以及内部数据流的控制。
[0006]
优选技术方案中,所述的烧伤图像语义分割网络硬件加速器,其特征在于,所述卷积神经网络推理单元的输入图像为处理后的烧伤图像,整体搭载多个加速核心单元,在一个时钟周期内能够进行多个加速核心单元的并行处理;优选技术方案中,所述的卷积神经网络推理单元,其特征在于,所述加速核心单元搭载多个计算处理单元,各计算处理单元对数据采用booth编码,采用wallace树进行乘法运算。加速核心单元能够在一个时钟周期内进行多个数据的乘累加运算、累加运算、最大选择运算和最小选择运算,共输出多个运算结果;优选技术方案中,所述的烧伤图像语义分割网络硬件加速器,其特征在于,所述数据流指令解析单元采用有限状态机(fsm)方式实现对数据流控制指令的解析,解析得到的指令类型包括:乘累加、累加、最大选择、最小选择、加载数据、读取数据、暂存数据、输出数据。数据流指令解析单元输出的指令用于控制各加速核心单元的运算规则;优选技术方案中,所述的烧伤图像语义分割网络硬件加速器,其特征在于,所述数据加载和控制单元,包括如下部分:直接存储器访问控制器(dma),用于从ddr中读取输入烧伤图像数据和向ddr中写回处理后的分割图像数据;双缓冲队列,用于数据的暂存和输入顺序调整。双缓冲队列采用分块bram实现,能够灵活调整输出数据位宽,降低了bram读取带来的额外功耗;熵编码/解码模块,用于图像数据的游程编码和解码,编码降低了数据的片上储存压力;零检测模块:用于检测图像像素数据是否为0,当像素数据为0时,跳过该像素并进行下一像素的加载,降低了数据的片运算压力;归一化模块,用于网络各层的数据归一化,降低由于数据范围过大带来的漂移误差;优选技术方案中,所述的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备,其特征在于,图形化交互子系统能够实时输出烧伤图像的分类和鉴定结果,根据不同区域的烧伤程度采用不同颜色的掩膜进行标记,并且输出烧伤深度预测结果和整体辅助诊断建议;优选技术方案中,所述的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备,其特征在于,所述网络模块通过无线网络与服务器进行通信,将原始烧伤图像和鉴定后烧伤图像通过无线网络传输至服务器,便于后期比对;本发明还公开了基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的设计方法,其特征在于,包括如下步骤:s01:使用pytorch构建用于烧伤深度鉴定的语义分割网络,训练网络参数并采用量化
和剪枝方法压缩网络模型;s02:根据构建的网络以及fpga资源情况设计fpga硬件加速单元,生成比特流文件并烧写至硬件平台中,用于本地化网络加速;s03:设计和裁剪适用于硬件平台的操作系统,编写图像采集与处理模块、数据储存模块、网络通信模块和用户交互模块的驱动程序;s04:编写用户层程序,实现系统调度以及硬件加速单元的调用。
[0007]
优选技术方案中,所述步骤s01采用感知量化方式对浮点数据进行定点化;采用静态剪枝与动态剪枝相结合的方式对网络模型参数数量进行裁剪,将大部分网络参数裁剪为0值,同时采用熵编码的方式对剪枝后数据进行编码,进一步降低储存空间;优选技术方案中,步骤s02所述fpga硬件加速单元包括如下模块:总线接口和互联矩阵,包括数据总线和控制总线,负责与系统调度端之间控制信号和数据的传输;片上内存,用于网络数据在fpga上的临时储存;dma接口,用于ddr数据读写;前向推理模块,用于卷积神经网络的前向推理,内部包含了前向推理运算所需的各种功能单元,包括:1)向量乘累加单元,用于计算输入向量与权重矩阵的矩阵乘法运算结果;2)累加单元,用于矩阵乘法计算结果的累加;3)激活函数单元,用于计算各层网络的激活值;4)内部暂存单元,用于暂存每次矩阵乘法的计算结果。
[0008]
优选技术方案中,步骤s02所述fpga硬件加速单元对图像进行预处理,包括如下步骤:s01:对输入图像进行滑动均值滤波,除去图像噪声;s02:对输入图像进行分块处理,对各子图像块进行离散余弦变换,获得频域图像数据;s03:对频域图像数据进行低通滤波,保留低频分量,去除高频分量;与现有技术相比,本发明的优点是:本发明能够在本地实现烧伤区域的实时分割和烧伤程度鉴定,基于异构系统搭建的硬件加速单元能够有效提高烧伤图像数据处理速度,辅助烧伤病例的程度量化和诊断。相比部署于gpu或大型深度学习专用服务器上的语义分割推理方案,本发明的技术方案具有低延迟、低功耗、便携、易操作等优势。
附图说明
[0009]
下面结合附图及实施例对本发明作进一步描述:图1是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的整体系统组成框图;图2是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的异构soc系统的组成框图;图3是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的数据通路示意图;图4是本发明实施例所采用的fpga加速核心单元的组成框图;图5是本发明实施例所采用的串矩转换电路的原理示意图;
图6是本发明实施例所采用的卷积流水线的时序示意图;图7是本发明实施例采用的fpga硬件加速器的设计方法流程图;图8是本发明实施例采用的fpga硬件加速器图像预处理模块的设计方法流程图。
[0010]
图9是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备设计方法的整体软件设计流程图。
具体实施方式
[0011]
本实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备,通过语义分割网络和本地语义分割网络加速器,实现烧伤图像的实时鉴定和分割。此外,本实施例还提供了一种适用于上述设备的系统设计方法。
[0012]
以下结合附图对本发明实施例的具体实施方式进行详细说明。应理解,这些实施例是用于说明本发明而不限于限制本发明的范围。实施例中采用的实施条件可以根据具体硬件设备和应用场景做进一步调整,未注明的实施条件通常为常规实验中的条件。
[0013]
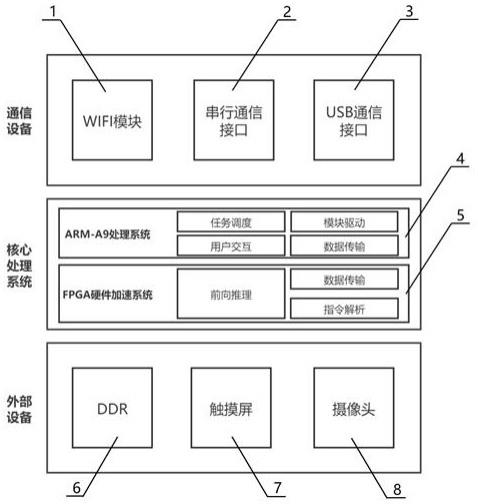
实施例1:一种基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备,其整体系统组成框图如图1所示,包括通信设备、核心处理系统与外部设备。其中,通信设备包括wifi模块1、串行通信接口模块2、usb通信接口模块3;核心处理系统包括arm-a9处理系统模块4、fpga硬件加速系统模块5;外部设备包括ddr模块6、触摸屏模块7、摄像头模块8。
[0014]
wifi模块1通过sdio接口与模块4相连,用于处理后烧伤图像数据的上传;串行通信接口模块2通过uart接口与模块4相连,用于系统调试数据的接收和输出;usb通信接口模块3通过usb接口与模块4相连,用于与其他usb设备间的连接;arm-a9处理系统模块4与fpga硬件加速系统模块5互相配合实现系统功能,两者之间通过axi总线相连,axi总线用于图像数据和控制指令的内部传输;ddr模块6通过axi总线与模块4和模块5相连,用于数据存储;触摸屏模块7通过hdmi接口与模块4相连,用于烧伤图像的实时呈现和用户交互;摄像头模块8通过hdmi接口与模块4相连,用于烧伤图像数据的采集。
[0015]
图2是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的异构soc系统的组成框图。本发明实施例中的异构soc指同时集成系统调度端(processing system end,简称ps)和可编程逻辑端(programmable logic end,,简称pl)芯片的计算系统。其中,本实施例的ps为通用arm处理器,pl为现场可编程门阵列(field progammable gate arrays,简称fpga)。ps与pl之间的通信可通过片内总线系统以及相应的总线桥实现,本实施例和附图中,数据通路采用amba总线系统为例说明,但本发明不限于此。
[0016]
本发明实施例中的异构soc包括ps、片外内存、总线系统和pl。其中ps包括低速外设模块11、arm核模块12;片外内存包括ddr3模块13;总线系统包括apb总线模块14、axi总线模块15;pl包括控制寄存器模块16、pe阵列模块17、dma模块18、输入缓冲模块19、输出缓冲模块20。
[0017]
低速外设模块11通过apb总线接口与apb总线模块14相连,用于系统和外界交互;arm核模块12通过axi总线接口与axi总线模块15相连,用于系统的整体调度和数据流
控制;ddr3模块13通过axi总线接口与axi总线模块15相连,用于数据存储;apb总线模块14与axi总线模块15之间通过axi-apb总线桥相连,两者共同用于系统数据传输;控制寄存器模块16通过axi接口与axi总线相连,用于控制命令的暂存;pe阵列模块17通过内部数据队列接口与输入缓冲模块19相连,用于图像数据的运算和处理;dma模块18通过axi总线接口与axi总线模块15相连,通过内部数据队列接口与输入缓冲模块19、输出缓冲模块20相连,用于图像数据的自动加载和储存;输入缓冲模块19通过内部数据队列接口与dma模块18、pe阵列模块17相连,用于输入数据的缓存;输出缓冲模块20通过内部数据队列接口与dma模块18、pe阵列模块17相连,用于输出数据的缓存;图3是本发明实施例提供的基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的数据通路示意图。数据通过高速总线和低速总线在不同速率的系统模块之间传输。其中arm处理器核、外部存储设备、高速外设和加速器需要较高通信速率,挂载于高速总线下;低速外设需要较低通信速率,挂载于低速总线下。高速总线与低速总线间通过总线桥进行数据转换。
[0018]
本实施例的核心是fpga硬件加速系统模块中的加速核心,图4是本发明实施例所采用的fpga加速核心单元的组成框图。其中,外部输入特征图通过外部数据队列输入至补零电路,通过补零电路调整特征图尺寸,再按照特征图尺寸分成32像素乘32像素的子图像块,输入至以卷积核心为例的计算单元中。在卷积核心中完成运算后,数据通过以累加单元为例的数据处理单元,再输出至输出队列,并在外部读取信号的控制下最终输出为处理后的特征图;图5是本发明实施例所采用的串矩转换电路的原理示意图。串矩转换电路将串行输入的图像数据流转换为二维图像窗口,为卷积、池化等窗口运算提供数据。结合图5对本实施例中的串矩转换电路及其工作原理进行详细描述。
[0019]
串矩转换电路结构通过一个图像串行输入口进行数据输入,每个时钟周期输入一个数据,同时所有内部ram中数据右移,位于行向量尾部的数据则移动至下一行向量的头部。每个行向量的尾部数据输出为一个tap,构成一个窗口列向量。设输入特征图尺寸为,窗口大小为,串矩转换电路结构尺寸为。
[0020]
在串矩转换电路输出第一个卷积的第一个窗口列向量前,需要先填充串矩转换电路的内部ram,此阶段需要的时钟周期为;输出第一个卷积的最后一个窗口列向量,则需要额外个时钟周期;在第个周期,第一个窗口的数据输出,可送入卷积模块进行卷积运算;第个周期,所有窗口数据均输出完毕,该特征图的窗口滑动结束。
[0021]
加速核心单元的计算过程需要对时序进行优化,以提高系统的运行频率。因此,结合图图6对加速核心单元中以卷积运算为例的运算时序作详细描述。本实施例将卷积运算分为乘法、部分和产生与卷积结果产生三个步骤,每个步骤占用一个时钟周期,分别计算窗口数据与卷积核对应数据的乘积结果、列向量元素之和以及最终卷积结果。在第一个时钟
周期,加速核心单元进行窗口一数据的对应元素相乘操作;在第二个时钟周期,加速核心单元进行窗口二数据的对应元素相乘、窗口一数据的部分积产生操作;在第三个时钟周期,加速核心单元进行窗口三数据的对应元素相乘、窗口二数据的部分积产生、窗口一数据的卷积结果产生操作;因此,产生第一个窗口的卷积结果共需要三个时钟周期,而由于对三个步骤做了流水线处理,之后每一个窗口的卷积运算都只需要一个时钟周期。
[0022]
实施例2:一种基于本地语义分割网络和fpga硬件加速的便携式烧伤深度鉴定设备的设计方法,其设计方法流程如图7所示,该方法100包括:s110:使用pytorch构建用于烧伤深度鉴定的语义分割网络,训练网络参数并采用量化和剪枝方法压缩网络模型;s120:根据构建的网络以及fpga资源情况设计fpga硬件加速单元,生成比特流文件并烧写至硬件平台中,用于本地化网络加速;s130:设计和裁剪适用于硬件平台的操作系统,编写图像采集与处理模块、数据储存模块、网络通信模块和用户交互模块的驱动程序;s140:编写用户层程序,实现系统调度以及硬件加速单元的调用。
[0023]
在设计fpga硬件加速器之前,需要先对输入图像作预处理。图8是本发明实施例采用的fpga硬件加速器图像预处理模块的设计方法流程图,该方法200包括:s210:对输入图像进行滑动均值滤波,除去图像噪声;s220:对输入图像进行分块处理,对各子图像块进行离散余弦变换,获得频域图像数据;s230:对频域图像数据进行低通滤波,保留低频分量,去除高频分量;结合图9,对本发明实施例的整体软件设计流程作详细描述。系统上电启动后,首先进行硬件初始化,包括电源管理模块初始化、内存模块初始化、总线系统初始化、外部设备初始化、硬件加速单元初始化。初始化成功后,启动操作系统进行调度,操作系统会启动摄像头数据读取子进程和用户交互子进程。摄像头数据读取子进程会读取摄像头采集的图像并实时显示于屏幕,同时等待用户通过用户交互子进程下达的烧伤分类命令;用户交互子进程会等待用户下达烧伤分类命令,并将命令传递给摄像头数据读取子进程;用户下达烧伤分类命令后,系统调用硬件加速器对当前摄像头采集的烧伤图像数据进行神经网络前向推理,得到分类和分割后的烧伤图像,并显示烧伤图像的分类结果。
[0024]
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人员能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。反根据本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1