使用层间存储器布局变换的高吞吐量神经网络操作的制作方法
使用层间存储器布局变换的高吞吐量神经网络操作
1.相关申请的交叉引用
2.本技术要求2019年5月16日提交的美国申请第16/414,534号的优先权,该申请的内容通过引用以其整体并入本文以用于全部目的。
3.发明背景
4.神经网络通常在大型数据集上运行,可以消耗大量的计算和存储器资源来解决复杂的人工智能问题。定制微处理器的创建部分地通过优化对输入数据执行的矩阵运算来提高神经网络的计算效率。这些定制的微处理器通常被设计为优化单一类型的卷积。然而,不同类型的神经网络可能需要不同类型的矩阵运算,包括不同类型的卷积运算。此外,随着神经网络变得更加复杂和/或专门化,神经网络的不同层可能需要不同类型的矩阵运算。因此,需要一种微处理器系统,其支持多种类型的卷积运算,同时在执行神经网络运算时保持高计算吞吐量。
5.附图简述
6.在以下详细描述和附图中公开了本发明的各种实施例。
7.图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。
8.图2是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。
9.图3是说明使用神经网络解决人工智能问题的过程的实施例的流程图。
10.图4是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。
11.图5是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。
12.图6是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。
13.图7是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。
14.详细描述
15.本发明可以以多种方式实现,包括作为过程;装置;系统;物质的组成;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,例如被配置为执行存储在耦合到处理器的存储器上和/或由该存储器提供的指令的处理器。在本说明书中,这些实现或者本发明可以采取的任何其他形式可以被称为技术。通常,在本发明的范围内,可以改变所公开的过程的步骤顺序。除非另有说明,否则被描述为被配置成执行任务的诸如处理器或存储器的组件可以被实现为在给定时间被临时配置为执行任务的通用组件或者被制造为执行任务的特定组件。如本文所使用的,术语“处理器”指的是被配置成处理数据(例如计算机程序指令)的一个或更多个设备、电路和/或处理核心。
16.下面提供了本发明的一个或更多个实施例的详细描述以及说明本发明原理的附图。结合这些实施例描述了本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求限定,并且本发明包括许多替代、修改和等同物。为了提供对本发明的全面理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,并且本发明可以根据权利要求来实施,而不需要这些具体细节中的一些或全部。为了清楚起见,没有详细描述与本发明相关的技术领域中已知的技术材料,以免不必要地模糊本发明。
17.公开了一种支持高吞吐量神经网络操作的微处理器系统和相关技术。在各种实施
例中,微处理器系统利用层间存储器布局变换来支持持续的峰值吞吐量神经网络操作,例如,当应用多层神经网络来解决复杂的人工智能问题时。所公开的技术允许具有在不同类型的矩阵运算之间交替的多层的神经网络有效地操作。例如,执行二维或三维卷积的层的输出可以馈入执行逐深度(depthwise)卷积的层,而对计算效率的影响最小。类似地,执行逐深度卷积的层的输出可以馈入执行二维或三维卷积的层,而对计算效率的影响最小。在各种实施例中,神经网络的不同层可以在不同类型的矩阵运算之间交替,以支持各种神经网络配置。所公开的微处理器系统包含硬件单元,该硬件单元包括能够访问共享存储器的处理元件。在各种实施例中,处理元件包括用于执行矩阵运算的矩阵处理器单元、用于执行矩阵转置运算的转置硬件单元、分散硬件单元和收集硬件单元。分散和收集硬件单元允许根据数据布局格式从共享存储器中写入和读取数据。分散硬件单元可以将数据放置在共享存储器中非连续位置,而收集硬件单元可以从共享存储器中非连续位置获取数据。硬件单元可以在重叠配置中被利用来并行操作,例如在流水线架构中操作。在各种实施例中,使用有效的数据布局格式从共享存储器写入和读取数据允许矩阵处理器单元以最小的停顿(stalling)在峰值吞吐量下操作。在一些实施例中,微处理器系统的各种硬件单元和可配置的存储器布局格式允许微处理器系统在解决人工智能问题时显著增加计算吞吐量。在一些实施例中,所公开的技术用于有效地解决神经网络层之间失配的布局格式。例如,需要高度x权重x通道(hwc)格式数据的神经网络层可以在需要通道x高度x权重(chw)格式数据的层之前,反之亦然。
18.在一些实施例中,微处理器包括处理元件和与处理元件通信的共享存储器。例如,每个具有至少一个处理元件的一个或更多个微处理器能够从共享的片上存储器组件读取和/或写入。在一些实施例中,处理元件包括矩阵处理器单元、转置硬件单元、分散硬件单元和收集硬件单元。在各种实施例中,每个单元可以是单独的硬件单元。矩阵处理器单元被配置为执行矩阵运算。例如,矩阵处理器单元可以执行矩阵运算,包括点积运算。转置硬件单元被配置为执行矩阵转置运算。例如,可以使用转置硬件单元来转置输入矩阵。分散硬件单元被配置为将数据放置到共享存储器中的为输出数据布局转换选择的位置。例如,分散硬件单元可以分散矩阵数据的通道,使得根据特定的输出数据布局格式,属于一个通道的所有数据将是连续的。在各种实施例中,分散硬件单元可以根据布局格式将数据分散到共享存储器的非连续位置。收集硬件单元被配置为从共享存储器中的非连续位置获得输入数据,用于输入数据布局转换。例如,收集硬件单元可以通过使用跨步读取(stride read)读取对应于每个通道的数据来从共享存储器收集数据,使得处理元件在不同的连续行中具有不同的通道。
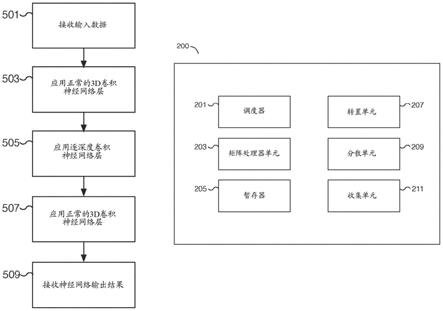
19.图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。在所示的示例中,系统100包括存储器101和处理元件111、121、131和151。在一些实施例中,存储器101是可由一个或更多个处理元件(例如处理元件111、121、131和151)访问的共享片上存储器组件。例如,处理元件111可以向片上存储器读写对应于对大数据矩阵的子集执行的计算的数据。处理元件121可以向片上存储器读写对应于在相同大数据矩阵的不同子集上执行的计算的数据。以这种方式,复杂人工智能问题的不同部分可以通过将计算负载分散到不同的处理元件上来解决。处理元件111、121、131和151可以各自并行操作,以解决更大的人工智能问题的一部分。在各种实施例中,图1的系统100可以包括更少或更多的处理元件。例
如,根据预期的计算要求,处理元件的数量可以按比例增加或减少。在一些实施例中,存储器101是末级高速缓存(llc)和/或可以使用静态随机存取存储器(sram)来实现。
20.在一些实施例中,处理元件用于求解神经网络的层。例如,处理元件,例如处理元件111、121、131和/或151之一,可以用于执行矩阵运算,例如卷积运算,用于将神经网络应用于从存储器101检索的输入数据集。一个或更多个不同的滤波器、核、卷积矩阵等可以应用于输入数据。卷积运算可以在不同类型的卷积之间交替进行。例如,卷积运算可以包括逐深度、逐组、正常、规则、逐点和/或三维卷积等。一层的结果输出可以被馈送到另一层,并且可以被存储在存储器101中。在各种实施例中,当完成对每一层的处理时,使用允许有效处理下一层的数据布局格式来存储结果。例如,得到的数据可以被转换并分散到存储器101的非连续位置,并且随后使用收集操作从存储器101读取,以从存储器101的非连续位置检索数据。在各种实施例中,神经网络的最终输出可以被写入存储器101。
21.图2是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。在所示的示例中,处理元件200包括调度器201、矩阵处理器单元203、暂存器(scratchpad)205、转置单元207、分散单元209和收集单元211。在各种实施例中,处理元件200是图1的处理元件111、121、131和/或151,并且通信连接到诸如图1的存储器101的存储器组件。
22.在一些实施例中,调度器201是用于调度诸如矩阵处理器单元203、转置单元207、分散单元209和/或收集单元211的不同硬件单元的硬件单元。调度器201可用于调度由硬件单元并行执行的操作。例如,矩阵处理器单元203可以执行点积运算,而转置单元207执行矩阵变换操作,分散单元209执行对存储器的写操作,和/或收集单元211执行对存储器的读操作。在一些实施例中,对于每个硬件单元存在单独的原语(primitives),并且调度器201调度由不同硬件原语调用的操作。例如,转置运算、分散操作和收集操作是调用相应硬件单元的原语。在各种实施例中,调度器201可以调度由不同硬件单元同时和/或并行执行的操作。通过跨不同硬件单元的重叠计算,处理元件200的峰值吞吐量增加。例如,矩阵处理器单元203不需要停顿等待输入数据被格式化为正确的布局格式。各种潜在的瓶颈(例如将数据转换为不同的布局格式或从不同的布局格式转换数据)被最小化。在一些实施例中,调度器201用于实现流水线架构,其中一个或更多个不同的硬件单元可以在神经网络操作的不同阶段上操作。
23.在一些实施例中,矩阵处理器单元203是硬件矩阵处理器单元,用于执行矩阵运算,包括与卷积运算相关的运算。例如,矩阵处理器单元203可以是用于执行点积运算的点积引擎。在一些实施例中,支持的卷积运算包括逐深度、逐组(groupwise)、正常(normal)、规则(regular)、逐点和/或三维卷积等。例如,矩阵处理器单元203可以接收第一输入矩阵,例如表示为三维矩阵的大图像的子集。第一输入矩阵可以具有以下维度:高度x宽度x通道(hwc)、通道x高度x宽度(chw)或另一适当的布局格式。矩阵处理器单元203还可以接收第二输入矩阵,例如滤波器、核或权重等,以应用于第一输入矩阵。矩阵处理器单元203可用于使用两个输入矩阵执行卷积运算,以确定结果输出矩阵。在一些实施例中,矩阵处理器单元203可以包括输入和/或输出缓冲器,用于加载输入数据矩阵并写出结果数据矩阵。
24.在一些实施例中,暂存器205是用于存储诸如与神经网络操作相关的数据的存储器暂存器。暂存器205可以用于由不同的硬件单元临时存储数据。在一些实施例中,暂存器205由用于快速读写访问的寄存器组成。在各种实施例中,处理元件200的一个或更多个硬
件单元可以访问暂存器205。
25.在一些实施例中,转置单元207是用于执行一个或更多个矩阵转置运算的硬件转置单元。例如,转置单元207可以是转置引擎,用于对输入矩阵进行操作,以将矩阵转置成与当前或下一个神经网络层兼容的格式。在一些实施例中,转置单元207可以在执行矩阵运算之后用于准备矩阵结果数据以写入存储器,和/或在矩阵运算之前用于准备矩阵运算的矩阵输入数据。在各种实施例中,转置单元207可以在矩阵处理器单元203的峰值吞吐量下操作。
26.在一些实施例中,分散单元209是硬件分散单元,用于将数据写入存储器,例如可由一个或更多个不同处理元件访问的共享存储器。分散单元209可用于将数据放置在被选择用于执行输出数据布局转换的位置,包括不连续的位置。例如,分散单元209可用于将数据写入共享存储器,其中通道维度是外部矩阵维度。一个或更多个不同的处理元件可以各自执行分散操作,以根据和/或保留特定的数据布局格式将每个处理元件各自的数据写入更大的矩阵。在各种实施例中,分散单元209可以沿着高速缓存线或高速缓存线块执行写入。在一些实施例中,分散单元209可以在矩阵处理器单元203的峰值吞吐量下操作。
27.在一些实施例中,收集单元211是硬件收集单元,用于从诸如共享存储器的存储器加载数据,以准备执行矩阵运算。收集单元211可用于从共享存储器的连续或非连续位置获得数据,用于输入数据布局转换。例如,收集单元211可用于从共享存储器读取数据,其中通道维度是外部矩阵维度。一个或更多个不同的处理元件可以各自执行收集操作,以读取分配给每个处理元件的给定通道的数据。在各种实施例中,收集单元211可以沿着高速缓存线或高速缓存线块执行读取。在一些实施例中,收集单元211可以在矩阵处理器单元203的峰值吞吐量下操作。
28.图3是说明使用神经网络解决人工智能问题的过程的实施例的流程图。例如,将多层神经网络应用于输入数据,以解决复杂的人工智能问题,例如图像识别和推荐。在一些实施例中,使用图1的系统100和/或图2的一个或更多个处理元件200来应用神经网络。
29.在301,接收输入数据。例如,接收矩阵形式的输入数据。在一些实施例中,矩阵是三维矩阵,其维度对应于高度、宽度和通道。例如,可以使用不同的数据布局格式来格式化输入数据,这取决于执行配置的矩阵运算的效率。在各种实施例中,数据布局格式利用高度
×
宽度
×
通道(hwc)布局、通道
×
高度
×
宽度(chw)布局或另一种适当的数据布局格式。输入数据可以位于共享存储器或另一存储器存储介质中。
30.在303,神经网络被应用于输入数据。例如,通过在一个或更多个不同的处理元件上分配和分布神经网络操作,将输入数据应用于神经网络。在一些实施例中,每个处理元件被分配了神经网络操作的一部分,并且可以处理神经网络的一层或更多层的结果。在一些实施例中,每个神经网络可以访问在301从共享存储器接收的输入数据。例如,从共享存储器中检索输入数据的子集,并将其用作每个处理元件的矩阵处理器单元的输入。在各种实施例中,每个处理元件的结果被写入共享存储器。每个处理元件可以只对输入数据的子集进行操作,并且每个处理元件的结果可以使用输出数据布局格式分散到共享存储器,以保持输出结果的格式。
31.在各种实施例中,在303应用的神经网络的不同层可以利用不同类型的卷积运算。例如,卷积运算可以在正常或三维卷积和逐组或逐深度卷积之间交替。在一些实施例中,根
据配置的卷积运算,卷积运算可以具有防止数据重用的低算术强度。例如,由于缺少跨通道的缩减(reduction),矩阵处理器单元可以使用通道x高度x宽度(chw)数据布局更有效地执行逐组卷积,而由于跨通道的缩减,通过使用高度x宽度x通道(hwc)布局可以更有效地执行正常的3d卷积。通过允许层之间不同的卷积类型,层之间的输入和输出数据布局格式可能失配。例如,一层的数据布局格式的内部维度可以对应于后续层的数据布局格式的外部维度之一。在各种实施例中,使用本文公开的技术来解决失配。
32.在305,接收神经网络输出结果。例如,每个处理元件将其处理结果写入共享存储器。完成后,输出结果是将神经网络应用于输入数据的输出结果。在各种实施例中,输出结果被接收并用于解决人工智能问题。
33.图4是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。在所示的示例中,将具有三层的神经网络应用于输入数据,以解决复杂的人工智能问题,例如图像识别和推荐。在一些实施例中,图4中应用的神经网络的不同层利用不同类型的卷积运算。例如,卷积运算可以在正常或三维卷积和逐组或逐深度卷积之间交替。层间的输入和输出数据布局格式可能失配。在各种实施例中,使用本文公开的技术来解决失配。在一些实施例中,使用图1的系统100和/或图2的一个或更多个处理元件200来应用神经网络。在一些实施例中,步骤401在图3的301执行,步骤403、405和/或407在图3的303执行,和/或步骤409在图3的305执行。尽管图4中的示例的神经网络包括三层,但是可以适当地利用附加的(或更少的)层。替代神经网络的附加中间(或隐藏)层的功能类似于在步骤405应用的图4的神经网络的第二层。
34.在401,接收输入数据。例如,接收矩阵形式的输入数据。在一些实施例中,矩阵是三维矩阵,其维度对应于高度、宽度和通道。例如,可以使用不同的数据布局格式来格式化输入数据,这取决于执行配置的矩阵运算的效率。在各种实施例中,数据布局格式利用高度
×
宽度
×
通道(hwc)布局、通道
×
高度
×
宽度(chw)布局或另一种适当的数据布局格式。输入数据可以位于共享存储器或另一存储器存储介质中。
35.在403,应用神经网络的第一层。例如,使用在401接收的输入数据作为输入值来处理神经网络的第一层。在一些实施例中,通过在一个或更多个不同的处理元件上分配和分布对应于第一层的神经网络操作来处理第一层。每个处理元件可以被分配针对第一层的神经网络操作的一部分。在一些实施例中,使用处理元件的一个或更多个硬件单元来处理输入数据,以使用与第一层的卷积运算兼容的输入数据布局格式来转换输入数据。第一层的卷积运算由每个分配的处理元件执行,一旦完成,结果可以在被馈送到神经网络的第二层之前被写回到共享存储器。在各种实施例中,一个或更多个硬件单元可以用于使用输出数据布局格式转换结果,为神经网络的第二层做准备。例如,在某些场景中,使用与下一层兼容的输出数据布局格式将结果分散到共享存储器中。
36.在405,应用神经网络的第二层。例如,在403执行并存储在共享存储器中的第一层的结果被用作神经网络的第二层的输入。在一些实施例中,类似于第一层,通过在一个或更多个不同的处理元件上分配和分布对应于第二层的神经网络操作来处理第二层。每个处理元件可以被分配针对第二层的神经网络操作的一部分。在一些实施例中,使用一个或更多个硬件单元来处理第二层的输入数据,以使用与第二层的卷积运算兼容的输入数据布局来转换输入数据。第二层的卷积运算由每个分配的处理元件执行,一旦完成,结果可以在被馈
送到神经网络的第三层之前被写回到共享存储器。在各种实施例中,一个或更多个硬件单元可以用于使用输出数据布局格式转换结果,为神经网络的第三层做准备。
37.在407,应用神经网络的第三层也是最后一层。例如,在405执行并存储在共享存储器中的第二层的结果被用作神经网络的第三层也是最后一层的输入。在一些实施例中,类似于第一和第二层,通过在一个或更多个不同的处理元件上分配和分布对应于第三层的神经网络操作来处理第三层。每个处理元件可以被分配第三层的神经网络操作的一部分。在一些实施例中,使用一个或更多个硬件单元来处理第三层的输入数据,以使用与第三层的卷积运算兼容的输入数据布局来转换输入数据。第三层的卷积运算由每个分配的处理元件执行,一旦完成,结果可以写回到共享存储器。在各种实施例中,一个或更多个硬件单元可以用于使用神经网络的预期结果的输出数据布局格式来转换结果。
38.在409,接收神经网络输出结果。例如,在407完成时,每个处理元件可以将其处理结果写入共享存储器。部分结果被组合以形成完整的神经网络输出结果。在一些实施例中,可以在确定最终神经网络输出结果之前处理部分输出结果。完成后,输出结果是将神经网络应用于在401接收的输入数据的输出结果。在各种实施例中,接收的输出结果用于解决人工智能问题。
39.图5是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。在所示的示例中,将具有三层的神经网络应用于输入数据,以解决复杂的人工智能问题,例如图像识别和推荐。每层使用的卷积运算不同于前一层,导致不同层的卷积运算之间输入和输出数据布局格式失配。第一层利用三维卷积,第二层利用逐深度卷积,第三层和最后一层利用三维卷积。在各种实施例中,其他卷积类型和组合可能是合适的。在一些实施例中,在图5的过程中应用的神经网络是图4的三层神经网络。在一些实施例中,步骤501在图4的401处执行,步骤503在图4的403处执行,步骤505在图4的405处执行,步骤507在图4的407处执行,和/或步骤509在图4的409处执行。尽管图5中的示例的神经网络包括具有特定卷积运算的三层,但是可以适当地利用附加的(或更少的)层和卷积组合/类型。
40.在各种实施例中,神经网络层的输入数据可能不是该层的卷积运算所期望的数据布局格式。类似地,卷积运算的结果可能不会使用当前层或后续层的数据布局格式来保存。相反,输入和/或输出数据布局转换可以由处理元件来执行。每个处理元件的硬件单元,例如转置硬件单元、分散硬件单元和/或收集硬件单元,可以用于根据矩阵处理器单元期望的数据布局格式来转换输入数据,以执行每个层的卷积运算。类似地,每个处理元件的硬件单元可以用于根据与下一个神经网络层兼容的输出数据布局格式来转换由矩阵处理器单元确定的卷积结果,并为下一个神经网络层做准备。在一些实施例中,所使用的数据格式是用于高效处理的中间数据布局格式。
41.在501,接收输入数据。例如,从共享存储器接收输入数据,以供一个或更多个处理元件处理。输入数据可以是三维矩阵,例如具有多个通道的图像数据。在一些实施例中,如参照图4的步骤401所述,接收输入数据。
42.在503,应用正常的三维卷积神经网络层。神经网络的第一层利用三维卷积运算。例如,使用三维卷积将核应用于在501接收的输入。第一层的部分结果可以由不同的处理元件确定,每个分配的处理元件使用矩阵处理器单元对输入数据的分配部分应用三维卷积。结果可以合并到共享存储器中,并馈送到神经网络的第二层。在一些实施例中,诸如转置硬
件单元、分散硬件单元和/或收集硬件单元的硬件单元可以用于根据输入和输出数据布局格式准备输入和输出数据。在各种实施例中,馈送到矩阵处理器单元的数据被转换成高度
×
权重
×
通道(hwc)格式,以利用跨通道的缩减。
43.在505,应用逐深度卷积神经网络层。神经网络的第二层利用逐深度卷积运算。例如,使用逐深度卷积将核应用于步骤503的输出。第二层的部分结果可以由不同的处理元件确定,每个分配的处理元件使用矩阵处理器单元对输入数据的分配部分应用逐深度卷积。结果可以合并到共享存储器中,并馈送到神经网络的第三层。由于第一层和第二层之间以及第二层和第三层之间的格式失配,可以利用诸如转置硬件单元、分散硬件单元和/或收集硬件单元的硬件单元来根据输入和输出数据布局格式准备输入和输出数据。在各种实施例中,数据具有低算术强度,跨通道的数据重用机会很少。矩阵处理器单元的输入数据不是采用高度x权重x通道(hwc)格式,而是转换成通道x高度x权重(chw)格式,以便更有效地处理。
44.在507,应用正常的三维卷积神经网络层。神经网络的第三层也是最后一层利用三维卷积运算。例如,使用三维卷积将核应用于步骤505的输出。第三层也是最后一层的部分结果可以由不同的处理元件确定,每个分配的处理元件使用矩阵处理器单元对输入数据的分配部分应用三维卷积。结果可以合并到共享存储器中,以确定神经网络的输出结果。由于第二层和第三层之间的格式失配,诸如转置硬件单元、分散硬件单元和/或收集硬件单元的硬件单元可以用于根据输入和输出数据布局格式准备输入和输出数据。在各种实施例中,馈送到矩阵处理器单元的数据被转换成高度
×
权重
×
通道(hwc)格式,以利用跨通道的缩减。
45.在509,接收神经网络输出结果。接收最终的神经网络输出结果,并可用于解决复杂的人工智能问题。在一些实施例中,如参照图4的步骤409所述,接收神经网络输出结果。
46.图6是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。在所示示例中,数据布局格式在两个不同的神经网络层之间变换,第二层应用逐深度卷积。在一些实施例中,第一神经网络层利用不同于第二层的卷积运算。在一些实施例中,步骤601、603和605在图4的403和/或图5的503处执行,并且对应于图4和图5的神经网络的第一层的部分。在一些实施例中,步骤607、609和611在图4的405和/或图5的505处执行,并且对应于图4和图5的神经网络的第二层。在一些实施例中,使用图1的系统100和/或图2的一个或更多个处理元件200来执行图6的过程。
47.在601,接收高度
×
权重
×
通道(hwc)格式的数据。例如,数据可以是使用用于神经网络层的hwc格式的输入数据执行矩阵运算(例如三维卷积运算)的结果。在一些实施例中,hwc数据是点积引擎结果。使用hwc格式的数据布局,数据的内部维度是通道数据。
48.在603,高度x权重x通道(hwc)格式的数据被转置为通道x高度x权重(chw)格式。例如,转置运算将数据从将通道数据作为内部维度转换为将通道数据作为外部维度。在一些实施例中,转置硬件单元或转置引擎,例如图2的转置单元207,执行每个处理元件本地的矩阵转置。在各种实施例中,允许对存储器的块级访问以执行转置运算。
49.在605,通道x高度x权重(chw)格式的数据分散到共享存储器中。例如,每个处理元件通过分散通道数据将其各自的结果保存到共享存储器中,使得属于通道的所有数据都是连续的。在一些实施例中,跨越不同处理元件实现的分散操作的地址由分散操作原语的参数控制。在603转置的数据以chw格式存储在共享存储器中,并且可以被一个或更多个不同
的处理元件访问,以应用神经网络的下一层。在各种实施例中,分散操作由每个处理元件使用分散硬件单元(例如图2的分散单元209)到共享存储器(例如图1的存储器101)来执行。
50.在607,从共享存储器收集通道x高度x权重(chw)格式化数据的指定部分。在一些实施例中,步骤607是逐深度卷积层的开始,其开始于从共享存储器获得分配的数据工作负荷。每个处理元件通过利用诸如图2的收集单元211的收集硬件单元来收集数据。分配通道的数据被收集到每个相应的处理元件中。在一些实施例中,每个处理元件被分配单一通道。
51.在609,执行逐深度卷积。例如,使用在607收集到处理元件中的数据和卷积滤波器来执行卷积运算。在一些实施例中,卷积运算由每个处理元件使用诸如图2的矩阵处理器单元203的矩阵处理器单元来执行。每个处理元件的结果对应于指定通道的结果。
52.在611,逐深度卷积的结果被保存到共享存储器。例如,每个处理元件的卷积结果被保存到共享存储器,例如图1的存储器101。在各种实施例中,每个处理元件的结果对应于单个通道,并且通道数据可以由每个处理元件作为连续写入来写入。产生的数据作为通道x高度x权重(chw)格式的数据存储在共享存储器中,属于一个通道的所有数据被连续存储。在一些实施例中,用于将数据保存到共享存储器的地址由写操作原语的参数控制。在一些实施例中,写操作利用分散操作。
53.图7是说明使用多层神经网络解决人工智能问题的过程的实施例的流程图。在所示的示例中,数据布局格式在两个不同的神经网络层之间变换,第一层应用逐深度卷积,第二层应用正常的三维卷积。不同的神经网络层需要改变输入的数据布局。在一些实施例中,步骤701、703和705在图4的405和/或图5的505处执行,并且对应于图4和图5的神经网络的第二层。在一些实施例中,步骤701、703和705分别是图6的步骤607、609和611。在一些实施例中,步骤707、709和711在图4的407和/或图5的507处执行,并且对应于图4和图5的神经网络的第三层的部分。在一些实施例中,使用图1的系统100和/或图2的一个或更多个处理元件200来执行图7的过程。
54.在701,从共享存储器收集通道x高度x权重(chw)格式化数据的指定部分。在一些实施例中,步骤701是逐深度卷积层的开始,其开始于从共享存储器获得分配的数据工作负荷。每个处理元件通过利用诸如图2的收集单元211的收集硬件单元来收集数据。分配通道的数据被收集到每个相应的处理元件中。在一些实施例中,每个处理元件被分配单一通道。
55.在703,执行逐深度卷积。例如,使用在701收集到处理元件中的数据和卷积滤波器来执行卷积运算。在一些实施例中,卷积运算由每个处理元件使用诸如图2的矩阵处理器单元203的矩阵处理器单元来执行。每个处理元件的结果对应于指定通道的结果。
56.在705,逐深度卷积的结果被保存到共享存储器。例如,每个处理元件的卷积结果被保存到共享存储器,例如图1的存储器101。在各种实施例中,每个处理元件的结果对应于单个通道,并且通道数据可以由每个处理元件作为连续写入来写入。产生的数据作为通道x高度x权重(chw)格式的数据存储在共享存储器中,属于一个通道的所有数据被连续存储。在一些实施例中,用于将数据保存到共享存储器的地址由写操作原语的参数控制。在一些实施例中,写操作利用分散操作。
57.在707,从共享存储器收集通道x高度x权重(chw)格式化数据的指定部分。在一些实施例中,步骤707是二维卷积层的开始,其开始于从共享存储器获得分配的数据工作负荷。每个处理元件通过利用诸如图2的收集单元211的收集硬件单元来收集数据。与步骤701
的收集操作相反,在707,收集操作从每个通道读取数据。在一些实施例中,读取操作是跨步读取,并且每个处理元件从不同的通道获得数据。在一些实施例中,从中收集数据的存储器位置由收集操作原语的参数指定。
58.在709,通道x高度x权重(chw)格式的数据被转置为高度x权重x通道(hwc)格式。例如,转置运算将数据从将通道数据作为外部维度转换为将通道数据作为内部维度。在一些实施例中,转置硬件单元或转置引擎,例如图2的转置单元207,执行每个处理元件本地的矩阵转置。
59.在711,执行正常的三维卷积。例如,使用收集到处理元件和卷积滤波器中的转置数据来执行卷积运算。在一些实施例中,卷积运算由每个处理元件使用诸如图2的矩阵处理器单元203的矩阵处理器单元来执行。每个处理元件的结果对应于分配的工作负荷的结果。在一些实施例中,结果被保存到共享存储器、转置和/或分散到共享存储器。
60.尽管为了清楚理解的目的已经详细描述了前述实施例,但是本发明不限于所提供的细节。有许多实现本发明的替代方式。所公开的实施例是说明性的,而不是限制性的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1