动画化来自头戴式装置相机的虚拟形象的制作方法
动画化来自头戴式装置相机的虚拟形象
1.相关申请的交叉引用
2.本技术要求2019年6月21日提交的美国申请第16/449,117号的优先权,该申请的内容为了所有目的通过引用以其整体并入本文。
技术领域
3.本公开总体上涉及将从安装在ar/vr头戴式装置上的相机捕捉的面部图像映射到用户的图形表示。
4.背景
5.人工现实是一种在呈现给用户之前已经以某种方式进行了调整的现实形式,其可以包括例如虚拟现实(vr)、增强现实(ar)、混合现实(mixed reality,mr)、混杂现实(hybrid reality)或其某种组合和/或衍生物。人工现实内容可以包括完全生成的内容或与捕捉的内容(例如,真实世界的照片)相结合的生成的内容。人工现实内容可以包括视频、音频、触觉反馈、或其某种组合,且其中任何一个都可以在单个通道中或在多个通道中被呈现(例如向观看者产生三维效果的立体视频)。人工现实可以与应用、产品、附件、服务或其某种组合相关联,这些应用、产品、附件、服务或其某种组合例如用于在人工现实中创建内容和/或在人工现实中使用(例如,在人工现实中执行活动)。提供人工现实内容的人工现实系统可以在各种平台上实现,这些平台包括连接到主计算机系统的头戴式显示器(hmd)、独立的hmd、移动设备或计算机系统、或者能够向一个或更多个观看者提供人工现实内容的任何其他硬件平台。
6.概述
7.根据本发明的第一方面,提供了一种系统,包括:一个或更多个包含指令的非暂时性计算机可读存储介质;一个或更多个处理器,该一个或更多个处理器耦合到存储介质,并且能够操作来执行指令以:访问在第一光谱域中捕捉的用户的多个第一捕捉图像;使用第一机器学习模型,基于第一捕捉图像生成多个第一域转移图像,其中第一域转移图像在第二光谱域中;基于第一虚拟形象(avatar),渲染包括第一虚拟形象的视图的多个第一渲染图像,第一虚拟形象是用户的虚拟表示;以及基于第一域转移图像与第一渲染图像之间的比较来更新第一机器学习模型,其中更新后的第一机器学习模型被配置成将第一光谱域中的图像转译(translate)至第二光谱域。
8.处理器还能够操作来执行指令以:使用第二机器学习模型,基于第一捕捉图像生成第一虚拟形象。
9.可以使用参数面部模型基于多个虚拟形象参数来渲染第一虚拟形象。
10.虚拟形象参数在第一域转移图像中的分布可以对应于虚拟形象参数在第一渲染图像中的分布。
11.基于每个第一域转移图像与每个对应的第一渲染图像之间的差异,可以使用损失函数来更新第一机器学习模型。
12.损失函数还可以基于捕捉图像的相机之间的一个或更多个空间关系。
13.处理器还能够操作来执行指令以:访问在第一光谱域中捕捉的多个第二捕捉图像;使用更新后的第一机器学习模型,基于第二捕捉图像生成多个第二域转移图像,其中第二域转移图像在第二光谱域中;使用第二机器学习模型,基于第二捕捉图像生成第二虚拟形象;基于第二虚拟形象,渲染包括第二虚拟形象的视图的多个第二渲染图像;以及基于第二域转移图像与第二渲染图像之间的比较来更新第二机器学习模型,其中第二机器学习模型被配置成基于一个或更多个第一输入图像来生成用于渲染对应于第一输入图像的虚拟形象的一个或更多个虚拟形象参数。
14.更新后的第二机器学习模型还可以被配置成基于一个或更多个第一输入图像,生成表示虚拟形象的空间方位的姿态信息。
15.第一捕捉图像和第二捕捉图像可以由与训练头戴式装置相关联的相机捕捉。
16.处理器还能够操作来执行指令以:访问多个第三捕捉图像,其中第三捕捉图像来自第二捕捉图像的子集;使用更新后的第二机器学习模型生成对应于第三捕捉图像的虚拟形象参数;以及基于第三捕捉图像和对应的虚拟形象参数之间的对应关系,训练第三机器学习模型,以基于一个或更多个第二输入图像生成对应于第二输入图像的一个或更多个虚拟形象参数。
17.第三机器学习模型可以实时生成输出虚拟形象参数。
18.第三捕捉图像可以由与训练头戴式装置相关联的多个训练相机捕捉,第二输入图像可以由与非侵入式头戴式装置相关联的多个非侵入式相机捕捉。
19.非侵入式头戴式装置上的非侵入式相机的位置可以对应于训练头戴式装置上的训练相机的子集的位置。
20.第三机器学习模型可以包括:生成一维向量的多个卷积神经网络分支,其中每个分支对应于一个相机并且将在第一光谱域中由对应相机捕捉的接收图像转换成对应的一个一维向量;以及将向量转换成虚拟形象参数的多层感知器。
21.处理器还能够操作来执行指令以:访问在第一光谱域中捕捉的多个第三图像,其中第三图像由非侵入式相机捕捉,第二图像由侵入式相机捕捉,并且非侵入式相机在数量上少于侵入式相机;使用第三机器学习模型,基于第三图像生成虚拟形象参数;基于虚拟形象参数,渲染包括第三虚拟形象的视图的多个第三渲染图像;以及向用户呈现第三渲染图像。
22.该系统还可以包括第一图形处理单元(gpu)和第二gpu,并且处理器还能够操作来执行指令以:访问在第一光谱域中捕捉的第一用户的多个图像;通过在第一gpu上执行第三机器学习模型,基于第一用户的图像生成第一虚拟形象参数;以及经由通信网络将第一虚拟形象参数发送到第二用户的计算设备。
23.处理器还能够操作来执行指令以:经由通信网络从第二用户的计算设备接收第二虚拟形象参数;使用第二gpu并基于第二虚拟形象参数,渲染包括第二用户的虚拟形象的视图的多个第三渲染图像;以及向第一用户呈现第三渲染图像。
24.第一光谱域可以是红外光,并且第二光谱域可以是可见光。
25.根据本发明的第二方面,提供了一种或更多种包含软件的计算机可读非暂时性存储介质,该软件在被执行时能够操作来:访问在第一光谱域中捕捉的用户的多个第一捕捉图像;使用第一机器学习模型,基于第一捕捉图像生成多个第一域转移图像,其中第一域转
移图像在第二光谱域中;基于第一虚拟形象,渲染包括第一虚拟形象的视图的多个第一渲染图像,第一虚拟形象是用户的虚拟表示;以及基于第一域转移图像与第一渲染图像之间的比较来更新第一机器学习模型,其中更新后的第一机器学习模型被配置成将第一光谱域中的图像转译至第二光谱域。
26.根据本发明的第三方面,提供了一种方法,包括:由计算设备访问在第一光谱域中捕捉的用户的多个第一捕捉图像;由计算设备使用第一机器学习模型基于第一捕捉图像生成多个第一域转移图像,其中第一域转移图像在第二光谱域中;由计算设备基于第一虚拟形象渲染包括第一虚拟形象的视图的多个第一渲染图像,第一虚拟形象是用户的虚拟表示;以及由计算设备基于第一域转移图像与第一渲染图像之间的比较来更新第一机器学习模型,其中更新后的第一机器学习模型被配置成将第一光谱域中的图像转译至第二光谱域。
27.在特定实施例中,系统可以自动将头戴式捕捉设备捕捉的图像映射到用户虚拟形象的状态(例如,面部表情)。头戴式装置可能有ir相机,该ir相机提供面部的局部图像。模仿用户面部的面部表情的虚拟形象可以基于来自安装在头戴式装置中的ir相机的图像而被动画化(animated)。例如,在远程呈现会话期间,虚拟形象可以由用户和其他用户的头戴式装置显示。可以通过确定表示面部的3d形状的一组参数并将这些参数提供给生成3d形状的虚拟形象生成器来动画化该虚拟形象。
28.基于ir相机提供的输入来动画化虚拟形象是困难的,因为ir相机提供来自不同的视点的、面部的特写、倾斜视图的拼接图,而不是面部的完整视图。问题是基于ir相机提供的局部“图像”构建一个模仿面部表情的虚拟形象。在特定实施例中,具有附加的、更具侵入性的ir相机的训练头戴式装置可用于捕捉面部的附加视图,以训练机器学习模型,并且具有较少的、侵入性较低的相机的头戴式装置可与经训练的模型一起使用。然而,训练头戴式装置可能仍然会生成面部的特写、倾斜视图的拼接图。在训练过程中可以使用可见光相机来补充ir相机,但是可见光相机不能提供被头戴式装置遮挡的面部部分的视图。此外,在可能不感测可见光谱的ir相机和可能在可见光谱中生成的虚拟形象之间可能存在模态间隙。此外,在捕捉的ir图像和用户的实际面部表情之间不存在明确的对应关系(因为用户实际面部表情会被ar/vr头戴式装置遮挡),也没有用于虚拟形象生成器的期望参数,该虚拟参数将渲染与用户的实际面部表情相匹配的虚拟形象。在ir光谱和可见光光谱中的捕捉图像之间也可能存在模态间隙。在捕捉的ir图像和捕捉的可见光图像之间没有明确的对应关系,因为ir图像描绘与可见光图像不同的面部部分。
29.本公开教导了一种用于确定捕捉的ir图像与控制虚拟形象的面部表情和头部姿态的虚拟形象参数之间的对应关系的方法。可以通过以下步骤来确定对应关系:训练域转移机器学习模型以将ir图像转移至渲染的虚拟形象图像,然后使用域转移机器学习模型,训练参数提取机器学习模型以基于ir图像识别虚拟形象参数。然后,参数提取模型可以用于基于由非侵入式相机(例如,3个相机)生成的局部ir图像和由参数提取模型识别的对应虚拟形象参数之间的对应关系来训练实时跟踪模型。实时跟踪模型可以由具有非侵入式相机的头戴式装置使用,以基于由非侵入式相机生成的ir图像来识别虚拟形象参数。
30.本发明的实施例可以包括人工现实系统或者结合人工现实系统来实现。人工现实是一种在呈现给用户之前已经以某种方式进行了调整的现实形式,其可以包括例如虚拟现
实(vr)、增强现实(ar)、混合现实(mixed reality,mr)、混杂现实(hybrid reality)或其某种组合和/或衍生物。人工现实内容可以包括完全生成的内容或与捕捉的内容(例如,真实世界的照片)相结合的生成的内容。人工现实内容可以包括视频、音频、触觉反馈、或其某种组合,且其中任何一个都可以在单个通道中或在多个通道中被呈现(例如向观看者产生三维效果的立体视频)。另外,在特定实施例中,人工现实可以与应用、产品、附件、服务或其某种组合相关联,这些应用、产品、附件、服务或其某种组合例如用于在人工现实中创建内容和/或在人工现实中被使用(例如,在人工现实中执行活动)。提供人工现实内容的人工现实系统可以在各种平台上实现,这些平台包括连接到主计算机系统的头戴式显示器(hmd)、独立的hmd、移动设备或计算机系统、或者能够向一个或更多个观看者提供人工现实内容的任何其他硬件平台。
31.本文公开的实施例仅仅是示例,并且本公开的范围不限于它们。特定实施例可以包括上面公开的实施例的部件、元件、特征、功能、操作或步骤中的全部、一些或没有一个被包括。根据本发明的实施例在涉及方法、存储介质、系统和计算机程序产品的所附权利要求中被具体公开,其中,在一个权利要求类别(例如,方法)中提到的任何特征也可以在另一个权利要求类别(例如,系统)中被要求保护。在所附权利要求中的从属性或往回引用仅为了形式原因而被选择。然而,也可以要求保护由对任何前面的权利要求的有意往回引用(特别是多项引用)而产生的任何主题,使得权利要求及其特征的任何组合被公开并且可被要求保护,而不考虑在所附权利要求中选择的从属性。可以被要求保护的主题不仅包括如在所附权利要求中阐述的特征的组合,而且还包括在权利要求中的特征的任何其他组合,其中,在权利要求中提到的每个特征可以与在权利要求中的任何其他特征或其他特征的组合相结合。此外,本文描述或描绘的实施例和特征中的任一个可以在单独的权利要求中和/或以与本文描述或描绘的任何实施例或特征的任何组合或以与所附权利要求的任何特征的任何组合被要求保护。
32.附图简述
33.图1a示出了基于可见光光谱域中的图像来创建虚拟形象的示例方法。
34.图1b示出了用于训练域转移机器学习模型以在不同光谱域之间转移图像的示例方法。
35.图2示出了用于训练虚拟形象参数提取机器学习模型以从红外光谱域中的图像提取虚拟形象参数的示例方法。
36.图3示出了用于训练实时跟踪模型以从红外光谱域中的图像中提取虚拟形象参数的示例方法。
37.图4示出了使用实时跟踪模型基于红外图像动画化虚拟形象的示例方法。
38.图5示出了用于通过训练域转移和参数提取机器学习模型来建立红外图像和虚拟形象参数之间的对应关系的示例流程。
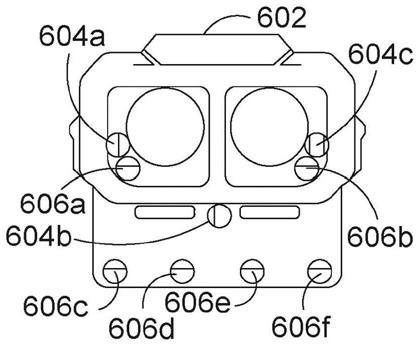
39.图6a示出了具有侵入式和非侵入式红外相机的示例训练头戴式装置。
40.图6b示出了由训练头戴式装置生成的示例图像。
41.图6c示出了具有非侵入式红外相机的示例跟踪头戴式装置。
42.图6d示出了由跟踪头戴式装置生成的示例图像。
43.图6e示出了用于在训练和跟踪头戴式装置中校准相机的示例多平面校准图案。
44.图6f示出了头戴式装置上人体工学相机放置的挑战的示例。
45.图7示出了虚拟形象的纹理图和头戴式相机图像上的示例标记。
46.图8示出了不同光谱域中图像空间结构分布的示例匹配。
47.图9示出了不同光谱域之间的多视图图像域转译中的示例跨视图循环一致性。
48.图10示出了用于训练多视图图像域转译的示例算法。
49.图11示出了示例背景感知的可微分渲染。
50.图12示出了用于在红外图像和虚拟形象参数之间建立对应关系的示例方法。
51.图13示出了示例网络环境。
52.图14示出了示例计算机系统。
53.示例实施例的描述
54.在特定实施例中,系统可以将由头戴式捕捉设备捕捉的图像自动映射到用户虚拟形象的状态(例如,面部表情)。头戴式装置有ir相机,该ir相机提供面部的局部图像。可以基于来自安装在头戴式装置中的ir相机的图像来生成模仿用户面部的面部表情的虚拟形象。例如,在远程呈现会话期间,虚拟形象可以由用户和其他人的头戴式装置显示。可以通过确定表示面部的3d形状的一组参数并将这些参数提供给生成3d形状的虚拟形象生成器来构建虚拟形象。
55.基于ir相机提供的输入来构建虚拟形象是困难的,因为ir相机提供来自不同视点的面部的特写、倾斜视图的拼接图,而不是面部的完整视图。问题在于要基于ir相机提供的局部“图像”构建一个模仿面部表情的虚拟形象。在特定实施例中,具有附加的、更具侵入性的ir相机的训练头戴式装置可用于捕捉面部的附加视图,以训练机器学习模型,并且具有更少的、侵入性更低的相机的跟踪头戴式装置可与经训练的模型一起使用。然而,训练头戴式装置仍然会生成面部的特写、倾斜视图的拼接图。在训练过程中可以使用可见光相机来补充ir相机,但是可见光相机不能提供被头戴式装置遮挡的面部部分的视图。此外,在不感测可见光谱的ir相机和在可见光谱中生成的虚拟形象之间存在模态间隙。此外,在捕捉的ir图像和用户的实际面部表情之间没有明确的对应关系(因为用户实际面部表情会被增ar/vr头戴式装置遮挡),也没有用于虚拟形象生成器的期望参数,该期望参数将渲染与用户的实际面部表情匹配的虚拟形象。ir光谱和可见光光谱中的捕捉图像之间也存在模态间隙。在捕捉的ir图像和捕捉的可见光图像之间没有明确的对应关系,因为ir图像描绘的面部部分不同于可见光图像。
56.本公开教导了一种用于确定捕捉的ir图像和控制虚拟形象面部表情和头部姿态的虚拟形象参数之间的对应关系的方法。可以通过以下步骤来确定对应关系:训练域转移机器学习模型以将ir图像转移至渲染的虚拟形象图像,然后使用域转移机器学习模型,训练参数提取机器学习模型以基于ir图像来识别虚拟形象参数。然后,参数提取模型可以用于基于由非侵入式相机(例如,3个相机)生成的局部ir图像和由参数提取模型识别的对应虚拟形象参数之间的对应关系来训练实时跟踪模型。实时跟踪模型可以由具有非侵入式相机的跟踪头戴式装置使用,以基于由非侵入式相机生成的ir图像来识别虚拟形象参数。
57.图1a示出了基于在可见光光谱域中捕捉的图像来创建虚拟形象的示例方法。一个或更多个可见光(“rgb”)相机108可以基于可见光捕捉用户102的一个或更多个rgb图像110。使用rgb相机108来捕捉rgb图像110在本文被称为“建模捕捉”。rgb相机108可以是多视
图相机设备的部分,其可以包括例如20个、30个、40个或其他合适数量的rgb相机108。面部模型训练过程111可以使用rgb图像110来创建参数面部模型109和面部表情代码113。表情代码113可以是用户面部状态的表示,并且可以编码面部的各个方面,例如眼睛凝视方向、嘴巴姿态、舌头表情等。面部模型109和表情代码113可以用于动画化(例如,渲染)对应于用户102的面部的虚拟形象。
58.图1b示出了用于训练域转移机器学习(ml)模型114以在不同光谱域之间转移图像的示例方法。光谱域可以包括红外光、可见光或其中图像可以被相机捕捉的其他域。用户102佩戴的头戴式装置104可以具有一个或更多个红外(ir)相机,该一个或更多个ir相机可以捕捉一个或更多个ir图像106。每个ir图像106在本文中可以被称为“帧”,并且可以与捕捉时间相关联。头戴式装置104可以是具有特定光谱域的一组相机的训练头戴式装置。例如,该组训练相机可以包括例如5个、9个、11个、12个或其他合适数量的ir相机,如下面参考图6a所述。域转移ml模型训练过程112可以基于ir图像106和渲染图像116来训练域转移ml模型114。渲染图像116可以由渲染器115基于从rgb图像110生成的参数面部模型109和面部表情代码113来渲染。域转移ml模型114可以在从头戴式装置104的ir相机接收的每个帧上进行训练。在被训练之后,域转移ml模型144可以通过基于在ir光谱中接收的ir图像106生成rgb(可见光)光谱中的域转移图像118来执行图像域转移。
59.在特定实施例中,为了在ir光谱域和rgb光谱域之间建立映射,在ir图像106和域转移rgb图像118之间应该存在图像因素的可比较分布,该图像因素包括面部表情和头部姿态。由rgb相机108捕捉的rgb图像110可以是当用户做出一系列表情(例如在朗读句子时)、在交谈期间执行一系列动作等时,用户102面部(没有佩戴训练头戴式装置)的高分辨率图像。例如,用户102可以在由rgb相机108成像时遵循脚本。然后,用户102可以在佩戴训练头戴式装置104的同时遵循类似的脚本,训练头戴式装置104可以使用头戴式装置104上的一组ir相机,例如9个、11个或其他合适数量的相机,来对用户的面部进行成像。rgb图像110可用于确保ir图像106中的面部表情的分布与域转移rgb图像118中的面部表情的分布相当(并且类似地用于两个域中的头部姿态的分布)。
60.在特定实施例中,ir图像106可以在与rgb图像110不同的时间被捕捉。头戴式装置104可以遮挡用户面部的部分,并且头戴式装置104中的ir相机通常不捕捉面部的遮挡部分。在特定实施例中,rgb相机108可以捕捉被头戴式装置104中的ir相机遮挡的面部部分,因为当捕捉rgb图像110时,用户102没有佩戴头戴式装置104。尽管在rgb光谱域和ir光谱域之间存在对应关系,但这种对应关系最初是未知的。由于头戴式装置104遮挡了用户的面部,所以通常不能同时捕捉rgb图像110和ir图像106。因此,识别用于渲染虚拟形象的ir图像106和面部表情代码113之间的对应关系是本文公开的技术所解决的问题。由于该对应关系不能直接用于监督学习,因此学习域转移ml模型114的问题可以被理解为无监督学习问题。换句话说,问题在于训练域转移ml模型114来构建ir图像106和rgb图像110之间的映射,而不需要提供跨两个域的逐帧对应关系的真值信息(ground truth information)。
61.在特定实施例中,可以基于特定用户的面部表情来训练用于为该特定用户102生成虚拟形象的ml模型,例如域转移ml模型114。当基于使用域转移ml模型114从头戴式装置ir图像生成的域转移rgb图像来配置虚拟形象时,从与头戴式装置相机相同的视角来看,虚拟形象的图像应该与由对应于ir图像106的rgb图像110捕捉的空间结构一致。纹理可以不
同,但是虚拟形象上面部特征的位置,例如眼睛、鼻孔、嘴巴等的位置,在rgb图像中应该与在ir图像106中大致相同。如果rgb相机位置改变,则rgb图像110应该相应地改变,并且在空间结构方面看起来与ir图像106相同。下面参考图5进一步详细描述训练过程112。在特定实施例中,一旦已经收集了足够的数据,并且已经为足够数量的人建立了对应关系,就可能不需要针对每个用户执行训练过程112。然后,可以基于用户的社交网络简档图片直接生成虚拟形象生成器和跟踪系统,例如,无需为每个用户训练单独的ml模型。
62.图2示出了用于训练虚拟形象参数提取机器学习(ml)模型206以从红外光谱域中的图像106提取虚拟形象参数的示例方法。虚拟形象参数提取模型训练过程204可以使用ir图像106、参数面部模型109和域转移ml模型114来训练虚拟形象参数提取模型206。域转移ml模型114可用于基于ir图像106生成域转移rgb图像118,并且虚拟形象参数提取模型训练过程204可以学习使参数面部模型109渲染具有类似于域转移rgb图像118的外观的虚拟形象的虚拟形象参数。虚拟形象参数可以包括面部表情代码113和头部姿态(未示出)。可以使用损失函数来测量虚拟形象和rgb图像118之间的相似性,该损失函数可以将基于学习的虚拟形象参数而渲染的虚拟形象的图像(例如,在像素级)与域转移rgb图像118进行比较。下面参考图5进一步详细描述虚拟形象参数提取模型训练过程。
63.图3示出了用于训练实时跟踪机器学习(ml)模型318以基于来自非侵入式相机的输入图像312生成虚拟形象参数的示例方法。可以基于ir图像306和虚拟形象参数308之间的对应关系来训练实时跟踪ml模型318,以将输入ir图像320直接映射到虚拟形象参数322,用于动画化虚拟形象。虚拟形象参数308可以包括面部表情代码和头部姿态。用于训练的(ir图像306和虚拟形象参数308之间的)对应关系可以由虚拟形象参数提取ml模型206识别。用于训练(并随后驱动)实时跟踪ml模型318的输入ir图像可以来自一组非侵入式ir相机,该组非侵入式ir相机可以是用于生成虚拟形象参数提取模型206的训练相机的子集。例如,非侵入式相机可以包括在非侵入式头戴式装置420上的非侵入式位置处的3个相机,并且训练相机可以包括在训练头戴式装置104上的9个相机。该9个相机可以包括在与非侵入式头戴式装置420上的非侵入式相机位置相类似的非侵入式位置处的3个相机,以及6个附加相机,该6个附加相机可以在对佩戴训练头戴式装置104的用户更具侵入性的位置处。下面参考图6c描述示例非侵入式头戴式装置420。
64.在特定实施例中,虚拟形象参数提取模型206可用于找到由9个训练相机捕捉的一组9幅ir图像306与一组对应的虚拟形象参数308之间的对应关系,以用于训练实时跟踪ml模型318。实时跟踪ml模型318可以与非侵入式头戴式装置420一起使用。非侵入式头戴式装置420可以具有比训练头戴式装置104更少的相机,尽管非侵入式头戴式装置420上相机的位置可以对应于训练头戴式装置104上的相应相机的位置。例如,训练头戴式装置104可以具有9个相机,包括处于非侵入位置的3个相机。非侵入式头戴式装置420可以在与训练头戴式装置104上的3个非侵入式相机类似的非侵入位置处具有3个相机。
65.作为示例,由于已知9幅ir图像306对应于该组虚拟形象参数308(根据虚拟形象参数提取模型206),所以该组虚拟形象参数308可以在诸如实时跟踪模型训练过程316的监督学习过程中用作真值。实时跟踪ml模型318可以基于来自训练头戴式装置104的三个非侵入式相机的3幅ir图像312与对应于该ir图像312的相应的一组虚拟形象参数314(选自虚拟形象参数308)的多个组来训练。块310可以选择分别来自训练ir图像306和训练虚拟形象参数
308的3个非侵入式ir图像312和对应的非侵入式虚拟形象参数314的每个组。一旦被训练,实时跟踪ml模型318可以基于从非侵入式头戴式装置的非侵入式相机接收的多组3幅ir图像320直接输出虚拟形象参数322。如下所述,虚拟形象参数可用于动画化虚拟形象。尽管根据特定光谱域中特定数量的图像描述了ml模型及其训练,但是ml模型可以在任何合适光谱域中的任何合适数量的图像上训练和使用。
66.图4示出了使用实时跟踪模型318动画化基于红外图像402的虚拟形象的示例方法。ir图像402可以由非侵入式头戴式装置420捕捉。例如,可以有来自非侵入式头戴式装置420的每个帧中的3幅ir图像402(而不是例如来自训练头戴式装置104的9幅ir图像106)。实时跟踪模型312可以生成虚拟形象参数404,虚拟形象参数404可以与参数面部模型406结合使用来渲染被渲染的虚拟形象408。如下所述,虚拟形象参数404可以包括面部表情和头戴式装置姿态参数。
67.图5示出了用于通过训练域转移和参数提取机器学习模型来建立红外图像和虚拟形象参数之间的对应关系的示例流程。在特定实施例中,流程可以使用预先训练的个性化参数面部模型d 406,该模型可以被理解为是可以基于虚拟形象参数来配置的虚拟形象,该虚拟形象参数例如是估计的面部表情113和估计的姿态510。参数面部模型d 406可以是深度外观模型,例如,深度反卷积神经网络,其基于虚拟形象参数生成虚拟形象的表示,包括几何形状和纹理。估计的面部表情113可以是l维潜在面部表情代码估计姿态510可以是从虚拟形象的参考帧到头戴式装置(由参考相机表示)的6-dof刚性姿态变换估计姿态510可以是视图向量,被表示为从用户头部指向相机的向量(例如,相对于可以从跟踪算法估计的头部方位)。可以基于面部表情代码z 113和姿态v 510使用如下参数面部模型d 406生成几何形状(其可以是网格m 514)和纹理t 516:
68.m,t
←
d(z,v).
ꢀꢀꢀ
(1)
69.在特定实施例中,网格表示包括n个顶点的面部形状,纹理是生成的纹理。通过由渲染器r 115基于网格m 514、纹理t 516和相机的投影函数a 511进行的光栅化,可以从该形状和纹理生成渲染图像r 506:
70.r
←
r(m,t,a(v)).
ꢀꢀꢀ
(2)
71.也就是说,姿态510可以在被发送到渲染器r 115之前由相机的投影功能a 511变换。
72.给定从一组头戴式装置相机c获取的多视图图像特定实施例可以估计在图像500的视图中看到的用户面部表情。图像500可以来自例如侵入式头戴式装置104上的相机的9或11幅相机视图。可以通过估计潜在面部表情代码z 113和头戴式装置姿态v 510来识别解决方案,该潜在面部表情代码z 113和头戴式装置姿态v 510将渲染虚拟形象图像506与所获取的图像500最佳地对齐,以便由损失函数504进行比较。在特定实施例中,代替针对记录中的每个帧单独执行该任务,可以在包括例如数千个多视图帧的数据集上同时估计这些属性。可以为虚拟形象参数提取模型e
θ
206(例如,预测器网络)估计模型参数θ,该虚拟形象参数提取模型e
θ
206通过联合考虑来自多个(例如,大多数或全部)相机的针对该帧(其可以对应于时间瞬间)的数据,对图像500的每个帧提取{z
t
,v
t
}、面部表情代码113和头戴式装置姿态510:
[0073][0074]
注意,相同的虚拟形象参数提取模型e 206可以用于数据集中的所有帧(例如,对于每个帧)。类似于来自运动的非刚性结构,以这种方式使用e 206的好处是面部表情随时间的规律性可以进一步约束优化过程,使得结果更能抵抗终止于较差的局部最小值。
[0075]
在特定实施例中,由于渲染虚拟形象图像r 506和相机获取的图像h500之间的域间隙,它们不可直接比较。为了解决这种不兼容性,还可以学习域转移模型f 114(例如,视图相关神经网络)的模型参数φ:
[0076][0077]
该函数f 114可以针对每个相机(例如,针对每个i∈c)进行评估,并且可以包括针对每个相机i的独立网络。然后可将综合分析重构损失(analysis-by-synthesis reconstruction loss)公式化为:
[0078][0079]
其中是来自公式(2)的渲染的面部模型,使用已知的投影函数a
i 511光栅化,投影函数a
i 511的参数可以从校准的相机i获得。这里,δ是潜在面部表情z 113上的正则项,并且λ加权其相对于域转移图像则项,并且λ加权其相对于域转移图像的l1范数重建的贡献(双竖线(double bars)表示域转移图像和渲染的面部模型之间的差的范数)。
[0080]
在特定实施例中,可能存在解决方案的空间,其中一个网络(例如,f 114)可以补偿由另一个网络(例如,e 206)引起的语义误差,导致低重建误差,但是导致面部表情z 113和头戴式装置姿态v 510的不正确估计。如果没有额外的约束,这种现象在实践中可能经常发生。这种行为被称为协作自我监督。当域间隙主要包括外观差异时,协作自我监督在不保留空间结构的架构中会更加突出。在本文公开的特定实施例中就是这种情况,其中潜在面部表情代码z 113可以是图像的矢量化编码。
[0081]
因此,在特定实施例中,公式(5)可以被解耦成两个阶段。首先,域转移模型f 114可以与e 206分开地学习。此后,f 114可以将头戴式装置图像h
i 500转换成域转移图像而不改变明显的面部表情(例如,语义)。由域转移ml模型训练块112表示的第一训练阶段产生域转移模型f 114。在由参数提取模型训练块204表示的第二训练阶段,f 114可以保持固定,并且公式(5)可以相对于e 206进行优化,以通过将渲染图像206进行优化,以通过将渲染图像与域转移图像进行匹配来产生虚拟形象参数提取模型e 206。
[0082]
在特定实施例中,面部表情保持域转移可以基于不成对的图像转译网络。该架构可以通过强制域之间的循环一致性和两个域中每一个的对抗损失来学习双向域映射(f
φ
和g
ψ
114)。因此,除了头戴式装置到渲染器的域转移网络f之外,还可以训练渲染器到头戴式装置的转移网络g,如图9所示。为了实现表情的保持,应该减少或消除生成器修改图像空间结构的趋势。在全卷积架构中,随机初始化已经导致保留的图像结构,这种趋势可能主要来
自于防止对立鉴别器从它们的空间结构中发现伪图像的压力。换句话说,如果在特定实施例中由头戴式装置姿态v 510和面部表情z 113共同确定的空间结构的分布是平衡的,那么生成器可能没有压力来开始修改它们。
[0083]
在特定实施例中,当在训练之前准备数据集时,可以生成空间结构的平衡分布。更具体地,为了训练图像域转移网络f
φ
和g
ψ
114,可以在应用循环生成性对抗网络(cyclegan)或其他合适的图像到图像转译之前,使用参数面部模型d 406渲染一组图像来准备的数据集副本。要保持不变的图像因素的分布应该是可以跨域比较的。这些因素可以是头戴式装置姿态v 510和面部表情z 113,它们的渲染可以分别由v
t
和z
t
控制。虽然捕捉的头戴式装置数据中的基础面部表情z和头戴式装置姿态v通常是不可控制的,但是可以基于联合分布p(z,v)的估计来生成具有期望统计值的一组渲染图像然而,由于估计头戴式装置数据的z和v是最初的问题,因此可以使用代理来近似
[0084]
在特定实施例中,空间结构的匹配分布在图8的示例中示出。假设z和v之间独立分布或者并且和被单独估计。对于面部表情上的分布,特定实施例可以依赖于数据捕捉过程,其中可以用相同的刺激捕捉用户两次(例如,使用rgb相机108进行“建模”捕捉,而头戴式装置104的ir相机用于进行另一次捕捉)。即使使用两次捕捉可能不会导致捕捉之间的帧到帧映射,面部表情的统计分布也可以被假设为是可比较的。因此,来自建模捕捉的rgb相机108的该组面部表情代码z 113可以用作来自p(z)的近似样本。
[0085]
在特定实施例中,对于头戴式装置姿态上的分布,面部模型d 406的3d几何形状可以通过收集2d标记注释和训练标记检测器来拟合到头戴式装置图像500上检测到的标记。图7中示出了示例标记。尽管仅标记拟合不一定产生对面部表情的精确估计,但是因为它的低维度和有限的变化范围,标记拟合可以给出头戴式装置姿态v的合理估计。将3d网格拟合到2d检测的挑战之一是定义网格顶点和检测到的标记之间的对应关系。注释可用的标记集合不一定与特定网格拓扑中的任何顶点完全匹配。为每个标记手动指定单个顶点可能会导致粗网格拓扑的次优拟合结果。为了解决这个问题,在拟合单个网格的同时,特定实施例可以同时求解在纹理的uv空间中每个标记的网格对应关系(例如,跨所有帧使用),其中m是可用标记的数量。为了将每个标记m投影到每个视图的渲染图像上,特定实施例可以计算当前uj在其封闭三角形中的重心坐标的行向量,该封闭三角形的顶点由索引,然后线性插值封闭三角形的3d顶点的投影其中m是来自公式(1)的网格514(表示面部形状)。因此,可以解决以下优化问题:
[0086][0087]
其中是hmc相机i中标记j的2d检测,p是在中生成2d点的相机投影,且是在[0,1]中的标记检测置信度。注意,对于视图i无法观察到的标记j,为零。
uj可以被初始化为模板网格中的一组预定义顶点,以防止发散。特定实施例还可以避免在虚拟形象不具有网格顶点的区域中使用标记,该区域可以是例如瞳孔和嘴内部。图7示出了uj处于收敛状态的一个示例。
[0088]
求解公式(6)提供了来自每个帧的一组头戴式装置姿态特定实施例可以通过单独地从随机采样头戴式装置姿态次,且还可以从面部建模捕捉的一组编码值中随机采样面部表情代码次,来渲染数据集随机采样的姿态和表情代码,与一起,可以形成用于不成对域转移的训练数据。在特定实施例中,由公式(6)求解的估计z
t
可以被丢弃,因为当仅依赖标记时,z
t
的估计可能较差。
[0089]
在特定实施例中,给定来自两个域和的图像,使用循环一致对抗网络的不成对图像转译的合适方法可以被使用来学习在域之间来回转译图像的视图特定映射f
φ,i
和g
ψ,i 114。由于促进了域之间的平衡分布p(z,v)(如上所述),这种方法产生了合理的结果。然而,由于参数面部虚拟形象模型406的有限渲染保真度,可能会出现失败的情况。这些情况在眼睛图像中可能最明显,其中睫毛和闪光可能几乎完全不存在,因为视图条件渲染方法对近场渲染的泛化能力较差。更具体地,与源图像500相比,域转移图像502可能呈现修改的凝视方向。此外,这种修改在不同的相机视图中可能不一致。此最后效应也可以在面部的其他部分观察到,尽管未达到眼睛的程度。当在公式(5)中跨相机视图联合求解(z,v)时,这些不一致且独立的误差可能会产生平均效应,这可能表现为减弱的面部表情。
[0090]
在特定实施例中,为了克服这个问题,可以利用图像域转译期间相机之间的空间关系。循环一致性可以通过跨视图预测来实现。具体而言,对于表示为0和1的一对视图,“空间预测器”p0和p1可以被训练成将视图0中的图像变换至视图1,反之亦然。可以以这样的方法选择这些对,使得它们观察面部的相似部分,从而它们的内容是相互可预测的(例如,立体眼-相机对和同一侧的下面部相机)。连同cyclegan的各项,损失函数可以是以下形式:
[0091]
l=lc+λglg+λ
p
l
p
+λvlv,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0092]
其中lc=l
ch
+l
cr
是每个域和每个视图的循环一致性损失,
[0093][0094]
lg=l
gh
+l
gr
是每个域和每个视图的gan损失(对于发生器和鉴别器两者),
[0095][0096]
l
p
是视图预测器的损失,
[0097][0098]
并且跨视图循环一致性lv=l
vh
+l
vr
,
[0099][0100]
其中l
cr
、l
gr
、和l
vr
可以对称定义,而dh和dr分别是这两个域中的鉴别器。注意,虽然和没有配对,但是和已配对,和也已配对。这些部件的图示在图9中示出。p0和p1跨域共享,因为视图之间的相对结构差异在两个域中应该是相同的。
[0101]
在特定实施例中,该问题采取极小极大优化问题的形式:
[0102][0103]
如果{p0,p1,f
φ
,g
ψ
}中的参数与{dh,dr}中的参数交替训练,则p和f
φ
(或g
ψ
)之间的共谋(collusion)可以最小化损失函数,而无需跨域保持表情,从而有效地学习真实数据和面部数据上的不同行为,以补偿彼此造成的错误。因此,应该保持不变的语义在域转换过程中可能会丢失。为了解决这个问题,可以使用“不合作训练”技术,通过将优化分成更多的步骤来防止这种“欺骗”行为。在每一步,损失函数可以被重新调整,以便只保留对真实数据进行操作的项,并且只更新以真实数据作为输入的模块。该算法的概要如图10中的算法1所示。通过这种方式,模块可能没有机会学习来补偿先前模块所产生的错误。因此,面部表情可以通过域转移被更好地保持,并且跨视图预测可以提供多视图一致性。
[0104]
在特定实施例中,可微分渲染器r 115可以用于参数面部模型406。给定公式(5)中的估计表情和姿态参数q=(z,v),可微分渲染器r 115可用于生成用于上述域转移的合成样本,并且还用于评估重建精度。渲染函数可以混合面部模型的形状和背景的光栅化,因此对于像素,图像位置p处的颜色c(p)可以由下式确定:
[0105]
c(p)=w(p)c
t
(p)+(1-w(p))cbꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0106]
其中c
t
(p)是来自位置p处纹理的光栅化颜色,且cb是恒定背景。如果w被定义为光栅化的像素覆盖的二进制掩码,其中如果p被分配了一个三角形则w(p)=1,否则w(p)=0,那么因为光栅化的离散性,对于所有p,将为零。在这种情况下,对于前景像素(例如,w(p)=1),c(p)的梯度仍然可以通过由像素在其当前封闭三角形中的重心坐标将纹理(从其中采样像素颜色)中的坐标参数化来从计算。尽管公式化渲染函数及其导数的这种方式在存在多视图约束的情况下可能会在实践中产生良好的结果,但它可能会表现出由w(p)的零梯度导致的失败情况。更具体地,如果像素p被渲染为背景(例如,w(p)=0),但是该像素的目标是前景值,则可能没有梯度传播到表情和姿态参数q=(z,v)。类似地,光栅化边界处的前景像素没有扩展的压力。在实践中,这些条件可能导致终止于具有大量重建误差的较差局部最小值。例如,如图11所示,在目标图像的前景图像倾向于占据图像的较大区域的鼓起脸颊表情中,估计的表情可能不能很好地匹配脸颊的轮廓。
[0107]
在特定实施例中,扩展前景区域的力应该来自前景和背景之间的边界周围的软混合(soft blending)。因此,可以使用类似于抗混叠(anti-aliasing)的软混合,而不是将边界周围的像素二进制分配给从纹理图采样的颜色或背景颜色。为了获得更好的梯度流,混合权重可以由面部模型的投影几何形状来参数化,使得沿着光栅化边界的重建误差可以反
向传播到表情和姿态参数q=(z,v)。为此,可以在远离边界的地方使用衰减混合函数:
[0108][0109]
其中d
p
是从p到光栅化覆盖范围之外的像素的任何投影三角形最近边缘的垂直2d距离,且σ控制衰减速率。公式(13)中用于w(p)的c
t
的值可以被设置为三角形纹理中最靠近边缘的颜色。对于覆盖范围内的像素,d
p
=0。实际上,σ可以被设置为1,并且为了效率,w可以仅针对每个投影三角形的封闭矩形内的像素进行评估。使用这种背景感知渲染,尽管在每次迭代中,一小部分背景像素可能会贡献梯度来扩展或收缩边界,但是这个数量足以防止优化终止于较差的局部最小值。
[0110]
在特定实施例中,对于域变换,(256
×
256)大小的图像可以用于两个域。对于f
φ
、g
ψ
和pi,可以将一个resnet与4倍下采样一起使用,随后跟着3个resnet模块和另外的4倍上采样。对于鉴别器dh和dr,可以应用光谱归一化来获得生成图像的更好质量和更稳定的训练。为了训练e
θ
,在|c|向量被级联且然后使用多层感知器(mlp)将其分别转换成z
t
和v
t
之前,可以构建单独的卷积网络来将单个向量转换成|c|向量。对于公式(5)中的先验δ(z
t
),可以使用l2惩罚因为与d相关联的潜在空间可以用逆正态分布的库贝克-莱布勒(kullback
–
leibler,kl)散度来学习。
[0111]
在特定实施例中,在图5所示的训练之后,可以将收敛的虚拟形象参数提取模型e
θ
206应用于帧以获得每帧对应关系以获得每帧对应关系中的辅助(例如,侵入式)视图可能会被丢弃,同时保留非侵入式头戴式相机(hmc)中可用的视图,其中|c’|=3。保留的视图及它们对应的参数形成训练数据该训练数据可用于训练将在实时动画化期间使用的实时回归器312。
[0112]
在特定实施例中,不是最小化z
t
潜在空间中的l2损失,而是可以以鼓励网络将容量花费在视觉最敏感的部分(例如细微的嘴唇形状和凝视方向)上的方式来测量损失。另外,几何形状和纹理图中的误差,特别是在眼睛和嘴巴区域中的误差,可以被最小化,因为虚拟形象可能具有不充分的几何形状细节,并且因此可能依赖于视图相关的纹理来在这些区域中逼真。
[0113]
可以建立一个回归方程来将转化为目标z
t
:
[0114][0115]
其中,
[0116][0117][0118][0119]
而κ是纹理图上聚焦于眼睛和嘴巴区域的裁剪(如图7所示),且v0是虚拟形象的固
定正面视图。
[0120]
在特定实施例中,期望实时跟踪模型的架构设计提供对目标z
t
的良好拟合,对诸如周围照明和头戴式装置佩戴位置的真实世界变化具有鲁棒性,并实现实时或近实时的推断速度。这些标准不同于虚拟形象参数提取模型e
θ
206,虚拟形象参数提取模型e
θ
206的函数涉及学习(例如,过拟合)使公式(5)最小化的z
t
和v
t
。因此,与e
θ
相比,更小的输入图像(例如,192
×
192等)和更少数量的卷积滤波器和层可以用于架构设计可以类似于:可以构建卷积网络的3个单独分支来将转换成3个一维向量,因为输入图像正在观察面部的不同部分,因此不一定共享空间结构。最后,这些一维向量可以被级联并通过多层感知器转换成z
t
。在训练期间,输入图像可以用随机小角度单应性(homography)来增强,以模拟相机旋转来解决相机安装的制造误差,以及模拟定向图像强度直方图扰动来解决照明变化。
[0121]
假设和d可以被实时评估,则可以构建双向社交虚拟现实(vr)系统,其中两个用户都可以在佩戴例如在非侵入式头戴式装置420上的头戴式相机的同时看到彼此的个性化虚拟形象的高保真动画化。在一侧,计算节点可以在一个gpu上运行第一用户的并经由通信网络将编码后的z
t
发送到另一侧。同时,计算节点可以经由通信网络从另一侧接收第二用户的z
t
,运行第二用户的d,并且在第二gpu上渲染第二用户的虚拟形象的立体图像(针对左眼和右眼)。
[0122]
图6a示出了具有侵入式和非侵入式红外相机的示例训练头戴式装置602。训练头戴式显示器(hmd)602包括增强相机606a-f和标准相机604a-c。hmd 602可用于收集数据,以帮助在hmd图像和虚拟形象参数之间建立更好的对应关系。特定实施例使用相同头戴式装置设计的两个版本:具有最小侵入式相机配置的非侵入式、消费者友好的设计,以及具有增强相机组的训练设计,该增强相机组具有更多适应性视点以支持寻找对应关系。增强训练头戴式装置602可用于收集数据并建立非侵入式头戴式装置相机配置和用户面部表情之间的映射。具体而言,非侵入式相机604可以包括用于嘴巴604b、左眼604c和右眼604a中的每一个的vga分辨率相机。六个增强相机606为每只眼睛增加了附加的视图606a、606b,并增加了嘴巴的四个附加视图606c-f,它们被策略性地放置得更低以捕捉嘴唇接触和垂直嘴部运动,并且在任一侧捕捉嘴唇突出。在该示例中,相机604、606同步并以90hz进行捕捉。相机604、606可以使用定制印刷的3d校准图案640一起进行几何校准,以确保图案的一部分在每个相机的景深内。为了构建训练数据集,可以使用相同的刺激来捕捉每个受试者:一次使用诸如rgb相机106的建模传感器,一次使用增强跟踪传感器604、606。刺激可以包括例如70个表情、50个句子、一系列动作、一系列凝视方向和10分钟的自由对话。这种刺激被设计成覆盖自然表情的范围。使用两个设备收集相同的内容提供了两个域之间大致平衡的面部表情分布,以用作不成对域转移算法的输入。图6b示出了由训练头戴式装置602捕捉的示例图像614、616。捕捉的图像包括可分别由非侵入式相机604a-c捕捉的非侵入式帧614a-c,以及可分别由增强式相机606a-f捕捉的增强式帧616a-f。
[0123]
图6c示出了具有非侵入式红外相机的示例跟踪头戴式装置620。跟踪头戴式显示器620包括标准相机624a-c,其可以在位置上(例如,相对于佩戴者的面部)对应于训练头戴
式显示器602的标准相机604a-c。跟踪头戴式显示器620可以用于具有最小化相机配置的实时或接近实时的面部动画化。图6d示出了由跟踪头戴式装置620生成的示例图像634。捕捉的图像634包括非侵入式帧634a-c,其可以分别由非侵入式相机624a-c捕捉。由非侵入式头戴式装置620捕捉的ir图像634a-c可以至少在相机视点方面对应于由训练头戴式装置捕捉的ir图像614a-c。
[0124]
图6e示出了用于在训练和跟踪头戴式装置中校准相机的示例多平面校准图案640。多平面校准图案640可用于通过训练头戴式装置602中相应的各个相机604a-c来几何校准非侵入式头戴式装置620中的相机624a-c,使得来自由非侵入式头戴式装置620捕捉的ir图像634a-c的视点对应于相应的各个训练头戴式装置ir图像614a-c被捕捉的视点。
[0125]
图6f示出了头戴式装置620上人体工学相机放置的挑战的示例。如图所示,对于安装在用户650佩戴的头戴式装置620上的相机,诸如张嘴的大运动投影至由非侵入式相机624c捕捉的图像中的小变化。相比之下,对用户650来说更具侵入性的相机放置可能更适合训练过程。例如,对于更直接放置在嘴巴前面的相机606f,诸如张嘴的大运动对应于捕捉图像中的大变化,并且捕捉图像中的大变化可以用于更有效地训练本文描述的机器学习模型。
[0126]
图7示出了虚拟形象的纹理图和头戴式相机图像上的示例标记。标记的颜色指示hmc图像701、702、703和纹理图700之间的对应关系。标记可以由通过人类注释训练的检测器从9幅视图(仅示出3幅视图)中检测到。这些标记的uv坐标可以跨多个帧用z
t
和v
t
联合求解。注意,在公式(5)的整体优化中,标记的投影距离不一定被最小化以找到对应关系。图像701上的标记包括左眼标记726a、726b,其对应于纹理图700上的相应标记706a、706b。图像703上的标记包括右眼标记724a、724b,其对应于纹理图700上的相应标记704a、704b。下面部图像702上的标记图像包括左鼻孔标记728、732,其对应于纹理图700上的相应标记708、712。下面部图像705还包括右鼻孔标记730和嘴巴标记734a、734b,它们对应于纹理图700上的相应标记710、714a和714b。
[0127]
图8示出了不同光谱域中图像空间结构分布的示例匹配。在ir域中捕捉的图像的空间结构的统计分布可以与在rgb域中渲染的虚拟形象图像804的空间结构的统计分布相匹配。空间结构的近似分布可以使用捕捉的hmc图像802上的标记检测来获得头部姿态分布并使用由rgb建模相机捕捉的rgb图像来获得面部表情分布进行估计。假设给定受试者共同的刺激,面部表情z的实际分布在统计上可与来自建模相机捕捉的用于构建虚拟形象的分布相比较。然后图像要符合的分布可以被确定为
[0128]
图9示出了不同光谱域之间的多视图图像域转译中的示例跨视图循环一致性。除了每个域内的跨域循环一致性之外,给定每个域中的成对多视图数据,域变换器可以被进一步约束,以鼓励保持面部图像的空间结构。图9中仅示出了一个损失项(4个可能方向中的一个,如在公式(11)中)。这些视图包括对应于第一帧的被标记为“视图0”的第一视图902和对应于第二帧的被标记为“视图1”的第二视图904。第一视图902包括帧910、912。第二视图904包括图像914、916。可以评估视图902、904之间的跨视图一致性。这些域包括对应于hmc
图像106的域h 906和对应于域转移图像502的域r 908。域h 906包括帧910、914,域r包括帧912、916。从域h到r的转译通过f进行,从域r到h的转译通过g进行。此外,从视图0到视图1的转译通过p0进行,从视图1到视图0的转译通过p1进行。可以通过f和g在域h和r之间建立循环,并且可以通过p0和p1在视图0和1之间建立循环。当训练f和g时,域和视图之间的损失可以被计算和最小化。
[0129]
图10示出了用于多视图图像域转译的训练的示例算法。算法1可以接收不成对的hmc图像h 106和渲染图像r 506作为输入,其中图像h之一和图像r之一在第一视图中,而其他图像h和r在第二视图中。该算法可以生成收敛的f
φ
和g
ψ
114作为输出。该算法可以重复以下步骤,直到f
φ
和g
ψ
收敛:采样(t,s)以针对i∈{0,1}获得(4幅图像),使用最小化l
ch
+l
gh
+l
vh
的梯度更新f的φ,使用最小化l
cr
+l
gr
+l
vr
的梯度更新g的ψ,使用最小化l
p
的梯度更新p,以及使用最大化lg的梯度更新dh和dr。
[0130]
图11示出了示例背景感知可微分渲染。在该示例中,对鼓起的脸颊的输入hmc图像1102执行可微分渲染。可以生成域转移(目标)图像1104。还示出了当前渲染的虚拟形象1106。较大的图像示出了叠加图像1104和1106的结果。框1110中的像素在当前被渲染为背景像素,但是其应该被渲染为前景像素。在框1110中示出了对面部轮廓周围的像素的更仔细的观察。对于任何投影三角形(虚线矩形)(例如三角形1114)的边界框1110内的背景像素p,p的颜色由最近边缘p1p2上最近点的颜色c
t
和背景颜色cb混合而来,其中权重与距离d
p
相关。指向下方和右侧的箭头指示从深灰色像素生成的梯度可以反向传播到面部的几何形状。
[0131]
图12示出了用于在红外图像和虚拟形象参数之间建立对应关系的示例方法1200。该方法可以在步骤1210开始,其中该方法可以训练第一机器学习模型以执行从第一光谱域到第二光谱域的图像域转译,其中第一机器学习模型在第一图像和一组对应的渲染图像上训练,并且渲染图像基于对应的建模虚拟形象参数和标记姿态生成。在步骤1220,该方法可以使用第一机器学习模型基于第一图像生成多个域转移图像,其中域转移图像在第二光谱域中。在步骤1230,该方法可以训练第二机器学习模型以识别对应于第一域中的特定图像的一个或更多个识别的虚拟形象参数和识别的姿态,其中在第一图像和对应的域转移图像上训练第二机器学习模型。在步骤1240,该方法可以使用第二机器学习模型为至少一个第一图像生成所识别的虚拟形象参数和姿态。在步骤1250,该方法可以使用基于所识别的参数和姿态的虚拟形象模型来生成表示佩戴者面部的虚拟形象。在步骤1260,该方法可以训练第三机器学习模型以基于输入图像识别虚拟形象参数,其中使用来自非侵入式相机的第一图像和由第二机器学习模型生成的相应虚拟形象参数来训练第三机器学习模型。
[0132]
在适当的情况下,特定实施例可以重复图12的方法的一个或更多个步骤。尽管本公开将图12的方法的特定步骤描述和示出为以特定顺序发生,但是本公开设想图12的方法的任何合适的步骤以任何合适的顺序发生。此外,尽管本公开描述并示出了用于在红外图像和虚拟形象参数之间建立对应关系的示例方法包括图12方法的特定步骤,但是本公开设想了用于在红外图像和虚拟形象参数之间建立对应关系的任何合适的方法,在适当的情况下包括图12方法的全部、一些步骤,或不包括图12方法的步骤。此外,尽管本公开描述和示出了执行图12的方法的特定步骤的特定部件、设备或系统,但是本公开设想了执行图12的方法的任何合适步骤的任何合适的部件、设备或系统的任何合适的组合。
[0133]
图13示出了与社交网络系统相关联的示例网络环境1300。网络环境1300包括通过网络1310彼此连接的用户1301、客户端系统1330、社交网络系统1360和第三方系统1370。尽管图13示出了用户1301、客户端系统1330、社交网络系统1360、第三方系统1370和网络1310的特定布置,但是本公开设想了用户1301、客户端系统1330、社交网络系统1360、第三方系统1370和网络1310的任何合适的布置。作为示例而不是作为限制,客户端系统1330、社交网络系统1360和第三方系统1370中的两个或更多个可以绕过网络1310彼此直接连接。作为另一个示例,客户端系统1330、社交网络系统1360和第三方系统1370中的两个或更多个可以全部或部分地在物理上或逻辑上彼此位于同一位置。此外,尽管图13示出了特定数量的用户1301、客户端系统1330、社交网络系统1360、第三方系统1370和网络1310,但是本公开设想了任何合适数量的用户1301、客户端系统1330、社交网络系统1360、第三方系统1370和网络1310。作为示例而不是作为限制,网络环境1300可以包括多个用户1301、客户端系统1330、社交网络系统1360、第三方系统1370和网络1310。
[0134]
在特定实施例中,用户1301可以是与社交网络系统1360或通过社交网络系统1360互动或通信的个人(人类用户)、实体(例如,企业、公司或第三方应用)或(例如,个人或实体的)团体。在特定实施例中,社交网络系统1360可以是托管在线社交网络的网络可寻址计算机系统。社交网络系统1360可以生成、存储、接收并发送社交网络数据(诸如例如,用户简档数据、概念简档数据、社交图信息或与在线社交网络相关的其他合适的数据)。社交网络系统1360可以由网络环境1300的其他部件直接地或经由网络1310来访问。在特定实施例中,社交网络系统1360可以包括授权服务器(或其他合适的部件),该授权服务器允许用户1301例如通过设置适当的隐私设置来选择加入或选择不将其动作由社交网络系统1360记录或与其他系统(例如,第三方系统1370)共享。用户的隐私设置可以确定可以记录与用户相关联的什么信息、可以如何记录与用户相关联的信息、何时可以记录与用户相关联的信息、谁可以记录与用户相关联的信息、可以与谁共享与用户相关联的信息以及可以记录或共享与用户相关联的信息的目的。授权服务器可用于根据需要通过阻止、数据散列、匿名化或其他合适的技术来实施社交网络系统30的用户的一个或更多个隐私设置。第三方系统1370可以由网络环境1300的其他部件直接或经由网络1310访问。在特定实施例中,一个或更多个用户1301可以使用一个或更多个客户端系统1330来访问社交网络系统1360或第三方系统1370、向社交网络系统1360或第三方系统1370发送数据以及从社交网络系统1360或第三方系统1370接收数据。客户端系统1330可以直接地、经由网络1310或经由第三方系统访问社交网络系统1360或第三方系统1370。作为示例而非限制,客户端系统1330可以经由社交网络系统1360访问第三方系统1370。客户端系统1330可以是任何合适的计算设备,例如个人计算机、膝上型计算机、蜂窝电话、智能手机、平板计算机或增强/虚拟现实设备。
[0135]
本公开设想了任何合适的网络1310。作为示例而不是作为限制,网络1310的一个或更多个部分可以包括自组织网络、内联网、外联网、虚拟专用网络(vpn)、局域网(lan)、无线lan(wlan)、广域网(wan)、无线wan(wwan)、城域网(man)、互联网的一部分、公共交换电话网(pstn)的一部分、蜂窝电话网、或这些中的两个或更多个的组合。网络1310可以包括一个或更多个网络1310。
[0136]
链路1350可以将客户端系统1330、社交网络系统1360和第三方系统1370连接到通信网络1310或连接到彼此。本公开设想了任何合适的链路1350。在特定实施例中,一个或更
多个链路1350包括一个或更多个有线(诸如例如数字用户线路(dsl)或基于电缆的数据服务接口规范(docsis))链路、无线(诸如例如wi-fi或全球互通微波接入(wimax))链路、或光(诸如例如同步光网络(sonet)或同步数字体系(sdh))链路。在特定实施例中,一个或更多个链路1350各自包括自组织网络、内联网、外联网、vpn、lan、wlan、wan、wwan、man、互联网的一部分、pstn的一部分、基于蜂窝技术的网络、基于卫星通信技术的网络、另一链路1350、或两个或更多个这种链路1350的组合。链路1350不需要在整个网络环境1300中一定是相同的。一个或更多个第一链路1350可以在一个或更多个方面上不同于一个或更多个第二链路1350。
[0137]
图14示出了示例计算机系统1400。在特定实施例中,一个或更多个计算机系统1400执行本文描述或示出的一个或更多个方法的一个或更多个步骤。在特定实施例中,一个或更多个计算机系统1400提供本文描述或示出的功能。在特定实施例中,在一个或更多个计算机系统1400上运行的软件执行本文描述或示出的一个或更多个方法的一个或更多个步骤,或者提供本文描述或示出的功能。特定实施例包括一个或更多个计算机系统1400的一个或更多个部分。在本文,在适当的情况下,对计算机系统的引用可以包括计算设备,反之亦然。此外,在适当的情况下,对计算机系统的引用可以包括一个或更多个计算机系统。
[0138]
本公开设想了任何合适数量的计算机系统1400。本公开设想了采取任何合适的物理形式的计算机系统1400。作为示例而不是作为限制,计算机系统1400可以是嵌入式计算机系统、片上系统(soc)、单板计算机系统(sbc)(诸如例如,模块上计算机(com)或模块上系统(som))、台式计算机系统、膝上型或笔记本计算机系统、交互式信息亭、大型机、计算机系统网状网、移动电话、个人数字助理(pda)、服务器、平板计算机系统、增强/虚拟现实设备、或者这些中的两个或更多个的组合。在适当的情况下,计算机系统1400可以包括一个或更多个计算机系统1400;可以是整体式的或分布式的;跨越多个位置;跨越多台机器;跨越多个数据中心;或者驻留在云中,云可以包括在一个或更多个网络中的一个或更多个云部件。在适当的情况下,一个或更多个计算机系统1400可以在没有实质性空间或时间限制的情况下执行本文描述或示出的一个或更多个方法的一个或更多个步骤。作为示例而不是作为限制,一个或更多个计算机系统1400可以实时地或以批处理模式来执行本文描述或示出的一个或更多个方法的一个或更多个步骤。在适当的情况下,一个或更多个计算机系统1400可以在不同的时间或在不同的位置处执行本文描述或示出的一个或更多个方法的一个或更多个步骤。
[0139]
在特定实施例中,计算机系统1400包括处理器1402、存储器1404、存储装置1406、输入/输出(i/o)接口1408、通信接口1410和总线1412。尽管本公开描述并示出了具有在特定布置中的特定数量的特定部件的特定计算机系统,但是本公开设想了具有在任何合适布置中的任何合适数量的任何合适部件的任何合适的计算机系统。
[0140]
在特定实施例中,处理器1402包括用于执行指令(例如构成计算机程序的那些指令)的硬件。作为示例而不是作为限制,为了执行指令,处理器1402可以从内部寄存器、内部高速缓存、存储器1404或存储装置1406中检索(或取回)指令;将这些指令解码并执行它们;以及然后将一个或更多个结果写到内部寄存器、内部高速缓存、存储器1404或存储装置1406。在特定实施例中,处理器1402可以包括用于数据、指令或地址的一个或更多个内部高
速缓存。在适当的情况下,本公开设想了包括任何合适数量的任何合适的内部高速缓存的处理器1402。作为示例而不是作为限制,处理器1402可以包括一个或更多个指令高速缓存、一个或更多个数据高速缓存、以及一个或更多个转译后备缓冲区(tlb)。在指令高速缓存中的指令可以是在存储器1404或存储装置1406中的指令的副本,并且指令高速缓存可以加速处理器1402对那些指令的检索。在数据高速缓存中的数据可以是:在存储器1404或存储装置1406中的数据的副本,用于供在处理器1402处执行的指令来操作;在处理器1402处执行的先前指令的结果,用于由在处理器1402处执行的后续指令访问或者用于写到存储器1404或存储装置1406;或其他合适的数据。数据高速缓存可以加速由处理器1402进行的读或写操作。tlb可以加速关于处理器1402的虚拟地址转译。在特定实施例中,处理器1402可以包括用于数据、指令或地址的一个或更多个内部寄存器。在适当的情况下,本公开设想了包括任何合适数量的任何合适的内部寄存器的处理器1402。在适当的情况下,处理器1402可以包括一个或更多个算术逻辑单元(alu);可以是多核处理器;或者包括一个或更多个处理器1402。尽管本公开描述并示出了特定的处理器,但是本公开设想了任何合适的处理器。
[0141]
在特定实施例中,存储器1404包括主存储器,其用于存储供处理器1402执行的指令或供处理器1402操作的数据。作为示例而不是作为限制,计算机系统1400可以将指令从存储装置1406或另一个源(诸如例如,另一个计算机系统1400)加载到存储器1404。处理器1402然后可以将指令从存储器1404加载到内部寄存器或内部高速缓存。为了执行指令,处理器1402可以从内部寄存器或内部高速缓存中检索指令并将它们解码。在指令的执行期间或之后,处理器1402可以将一个或更多个结果(其可以是中间结果或最终结果)写到内部寄存器或内部高速缓存。处理器1402然后可以将这些结果中的一个或更多个写到存储器1404。在特定实施例中,处理器1402仅执行在一个或更多个内部寄存器或内部高速缓存中或在存储器1404(而不是存储装置1406或其他地方)中的指令,并且仅对在一个或更多个内部寄存器或内部高速缓存中或在存储器1404(而不是存储装置1406或其他地方)中的数据进行操作。一个或更多个存储器总线(其可以各自包括地址总线和数据总线)可以将处理器1402耦合到存储器1404。如下所述,总线1412可以包括一个或更多个存储器总线。在特定实施例中,一个或更多个存储器管理单元(mmu)驻留在处理器1402和存储器1404之间,并且便于由处理器1402请求的对存储器1404的访问。在特定实施例中,存储器1404包括随机存取存储器(ram)。在适当的情况下,ram可以是易失性存储器。在适当的情况下,ram可以是动态ram(dram)或静态ram(sram)。此外,在适当的情况下,ram可以是单端口ram或多端口ram。本公开设想了任何合适的ram。在适当的情况下,存储器1404可以包括一个或更多个存储器1404。尽管本公开描述并示出了特定的存储器,但是本公开设想了任何合适的存储器。
[0142]
在特定实施例中,存储装置1406包括用于数据或指令的大容量存储装置。作为示例而不是作为限制,存储装置1406可以包括硬盘驱动器(hdd)、软盘驱动器、闪存、光盘、磁光盘、磁带或通用串行总线(usb)驱动器、或这些中的两个或更多个的组合。在适当的情况下,存储装置1406可以包括可移动或不可移动(或固定)介质。在适当的情况下,存储装置1406可以在计算机系统1400的内部或外部。在特定实施例中,存储装置1406是非易失性固态存储器。在特定实施例中,存储装置1406包括只读存储器(rom)。在适当的情况下,rom可以是掩模编程rom、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、电可变rom(earom)、或闪存、或这些中的两个或更多个的组合。本公开设想了采用任何合适的物理
形式的大容量存储装置1406。在适当的情况下,存储装置1406可以包括便于在处理器1402和存储装置1406之间的通信的一个或更多个存储装置控制单元。在适当的情况下,存储装置1406可以包括一个或更多个存储装置1406。尽管本公开描述并示出了特定的存储装置,但是本公开设想了任何合适的存储装置。
[0143]
在特定实施例中,i/o接口1408包括为在计算机系统1400和一个或更多个i/o设备之间的通信提供一个或更多个接口的硬件、软件或两者。在适当的情况下,计算机系统1400可以包括这些i/o设备中的一个或更多个。这些i/o设备中的一个或更多个可以实现在人和计算机系统1400之间的通信。作为示例而不是作为限制,i/o设备可以包括键盘、小键盘、麦克风、监视器、鼠标、打印机、扫描仪、扬声器、静态相机、触笔、平板计算机、触摸屏、跟踪球、视频相机、另一个合适的i/o设备、或这些中的两个或更多个的组合。i/o设备可以包括一个或更多个传感器。本公开设想了任何合适的i/o设备以及用于它们的任何合适的i/o接口1408。在适当的情况下,i/o接口1408可以包括使处理器1402能够驱动这些i/o设备中的一个或更多个的一个或更多个设备或软件驱动器。在适当的情况下,i/o接口1408可以包括一个或更多个i/o接口1408。尽管本公开描述并示出了特定的i/o接口,但是本公开设想了任何合适的i/o接口。
[0144]
在特定实施例中,通信接口1410包括提供用于在计算机系统1400和一个或更多个其他计算机系统1400或一个或更多个网络之间的通信(诸如例如,基于包(packet-based)的通信)的一个或更多个接口的硬件、软件或两者。作为示例而不是作为限制,通信接口1410可以包括用于与以太网或其他基于有线的网络进行通信的网络接口控制器(nic)或网络适配器,或者用于与无线网络(例如wi-fi网络)进行通信的无线nic(wnic)或无线适配器。本公开设想了任何合适的网络和用于它的任何合适的通信接口1410。作为示例而不是作为限制,计算机系统1400可以与自组织网络、个域网(pan)、局域网(lan)、广域网(wan)、城域网(man)或互联网的一个或更多个部分、或这些中的两个或更多个的组合进行通信。这些网络中的一个或更多个的一个或更多个部分可以是有线的或无线的。作为示例,计算机系统1400可以与无线pan(wpan)(诸如例如,蓝牙wpan)、wi-fi网络、wi-max网络、蜂窝电话网络(诸如例如,全球移动通信系统(gsm)网络)、或其他合适的无线网络、或这些中的两个或更多个的组合进行通信。在适当的情况下,计算机系统1400可以包括用于这些网络中的任一个的任何合适的通信接口1410。在适当的情况下,通信接口1410可以包括一个或更多个通信接口1410。尽管本公开描述并示出了特定的通信接口,但是本公开设想了任何合适的通信接口。
[0145]
在特定实施例中,总线1412包括将计算机系统1400的部件耦合到彼此的硬件、软件或两者。作为示例而不是作为限制,总线1412可以包括加速图形端口(agp)或其他图形总线、扩展工业标准体系结构(eisa)总线、前端总线(fsb)、hypertransport(ht)互连、工业标准体系结构(isa)总线、infiniband互连、低引脚数(lpc)总线、存储器总线,微通道体系结构(mca)总线、外围部件互连(pci)总线、pci-express(pcie)总线、串行高级技术附件(sata)总线、视频电子标准协会本地(vlb)总线、或任何其他合适的总线、或这些中的两个或更多个的组合。在适当的情况下,总线1412可以包括一个或更多个总线1412。尽管本公开描述并示出了特定总线,但是本公开设想了任何合适的总线或互连。
[0146]
在本文,在适当的情况下,一个或更多个计算机可读非暂时性存储介质可以包括
一个或更多个基于半导体的或其他集成电路(ic)(诸如例如,现场可编程门阵列(fpga)或专用ic(asic))、硬盘驱动器(hdd)、混合硬盘驱动器(hhd)、光盘、光盘驱动器(odd)、磁光盘、磁光盘驱动器、软盘、软盘驱动器(fdd)、磁带、固态驱动器(ssd)、ram驱动器、安全数字(secure digital)卡或驱动器、任何其他合适的计算机可读非暂时性存储介质、或这些中的两个或更多个的任何合适组合。在适当的情况下,计算机可读非暂时性存储介质可以是易失性的、非易失性的或者易失性和非易失性的组合。
[0147]
本文中,除非另有明确指示或通过上下文另有指示,否则“或”是包括性的而非排他性的。因此在本文,除非另有明确指示或通过上下文另有指示,否则“a或b”意指“a、b或两者”。此外,除非另有明确指示或通过上下文另有指示,否则“和”既是联合的又是各自的。因此在本文,除非另有明确指示或通过上下文另有指示,否则“a和b”意指“a和b,联合地或各自地”。
[0148]
本公开的范围包括本领域中的普通技术人员将理解的对本文描述或示出的示例实施例的所有改变、替换、变化、变更和修改。本公开的范围不限于本文描述或示出的示例实施例。此外,尽管本公开将本文的相应实施例描述并示为包括特定的部件、元件、特征、功能、操作或步骤,但是这些实施例中的任何一个可以包括本领域中的普通技术人员将理解的在本文任何地方描述或示出的任何部件、元件、特征、功能、操作或步骤的任何组合或置换。此外,在所附权利要求中对适合于、被布置成、能够、被配置成、实现来、可操作来、或操作来执行特定功能的装置或系统或装置或系统的部件的引用包括无论该装置、系统、部件或其特定功能是否被激活、开启或解锁,只要该装置、系统或部件是这样被调整、被布置、使能够、被配置、被实现、可操作的、或操作的。此外,尽管本公开将特定实施例描述或示为提供特定优点,但是特定实施例可以提供这些优点中的一些、全部或不提供这些优点。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1