组织学图像分析
1.本发明涉及组织学图像的分析。它尤其涉及使用机器学习算法来执行这种分析,并且还涉及训练所述机器学习算法来执行所述分析。
背景技术:
2.生物标志物越来越多地用于将抗癌疗法与特定的肿瘤基因型、蛋白质和rna表达谱相匹配,通常在晚期疾病患者中进行(la thangue和kerr,《自然评论临床肿瘤学(nat rev clin oncol)》,2011;8:587-96;van allen等人,《自然医学(nat med)》,2014;20:682-8;moscow等人,《自然评论临床肿瘤学》,2018;15:183-92)。
3.这方面的一个实例是选择kras-野生型结肠直肠癌(crc)用于用表皮生长因子受体抑制剂进行治疗(karapetis等人,《新英格兰医学期刊(n engl j med)》,2008;359:1757-65)。然而,在crc的辅助设置中,主要问题是二元的,是否提供治疗,以及随后的药物选择、剂量和时间表主要取决于分期而不是伴随诊断的存在。如果有可能进一步完善预后模型,这将允许通过定义一个亚组来制定更有针对性的方法,在所述亚组中,相对于单独的手术,辅助化疗的绝对益处是最小的,而在光谱的另一端,定义可能受益于长期联合化疗的患者(kerr和shi,《自然评论临床肿瘤学》,2013;10:429-30;hutchins等人,《临床肿瘤学杂志(j clin oncol)》,2011;29:1261-70;salazar等人,《临床肿瘤学杂志》,2011;29:17-24;gray等人,《临床肿瘤学杂志》,2011;29:4611-9)。
4.超过二十年的在早期crc患者中使用氟嘧啶与奥沙利铂等细胞毒性药物联合进行的辅助试验已使ii期或iiia期crc患者的总生存期(os)提高了约3-5%,所述患者中大多数(约80%)仅通过手术治愈。尽管进行了辅助化疗,仍有约20%的患者会复发,化疗相关死亡率可能为0.5-1%,并且20%的患者会出现明显的副作用。风险收益比相当微不足道,但如果可以定义一个具有较高复发风险和癌症特异性死亡风险的亚组,则风险收益比可能会低得多(qc小组,《柳叶刀(lancet)》,2000;355:1588-96;quasar collaborative g,gray r,barnwell j等人,《柳叶刀》,2007;370:2020-9;andre等人,《临床肿瘤学杂志》,2009;27:3109-16;andre等人,《临床肿瘤学杂志》,2015;33:4176-87)。
5.尽管临床验证的预后生物标志物将有助于辅助治疗决策,但很少有已被充分可靠地验证用于常规临床应用。可以对错配修复(mmr)状态进行常规评估(sinicrope,《自然评论临床肿瘤学》,2010;7:174-7;mouradov等人,《美国胃肠病学杂志(am j gastroenterol)》,2013;108:1785-93),因为那些患有mmr缺陷型肿瘤的患者往往预后良好。我们最近报道了肿瘤细胞dna含量(倍性)的测量与基质部分相结合可以将ii期患者分层为非常好的、中等和差的预后组(danielsen等人,《肿瘤学年鉴(ann oncol)》,2018;29:616-23)。有趣的是,驱动突变和rna特征的分析表明它们是单独的弱预后标志物并且不能指导临床决策(grey等人,2011,同上;mouradov等人,2013,同上)。
6.因此,需要提供改进的评估生物材料中的生物标志物的方法,并进一步发展提供有用和有效的方法来分类生物材料的能力,如用于预后和诊断方法。
7.深度学习已被证明适用于某些肿瘤类型的检测和描绘(ehteshami bejnordi等人,《美国医学会杂志(jama)》,2017;318:2199-210),并且已经报道了各种癌症分类(coudray等人,《自然医学》,2018;24:1559-67)。然而,我们还没有看到用于根据组织学图像直接预测患者的结果的经过验证的系统。
8.本研究的目的是推进深度学习和数字分析的使用,以开发用于组织学图像分析的全自动系统。这已在使用常规的完整载玻片图像(wsi)预测原发性crc患者的预后中得到测试和验证。
9.如本文所使用的,“组织学图像”是指显示生物材料的微观结构的图像。“所关注的组织学特征”是指这种微观结构的特征。例如,该特征可能是预后、诊断或治疗目的或科学研究所关注的。
10.组织学样本通常用于检查结构以确定诊断或尝试确定预后。
11.在组织学图像涉及病理学的情况下,可以使用术语“组织病理学图像”。
12.在微观尺度上,细胞的许多有趣特征并不是自然可见的,因为它们是透明无色的。为了揭示这些特征,在显微镜下成像之前,通常会用一种或多种标志物对样本进行染色。所述标志物包含一种或多种着色剂(染料或颜料),这些着色剂被设计成与细胞结构的特定组分特异性结合,从而揭示所关注的组织学特征。
13.一种常用的染色系统被称为h&e(苏木精和伊红)。h&e含有苏木精和伊红两种染料。伊红是一种酸性染料
–
它带负电荷。它将碱性(或嗜酸性)结构染成红色或粉红色。苏木精可以被认为是一种碱性染料。它用于将酸性(或嗜碱性)结构染成紫蓝色。
14.细胞核中的dna(异染色质和核仁)、核糖体和粗面内质网中的rna都是酸性的,因此苏木精与它们结合并将它们染成紫色。一些细胞外物质(即软骨中的碳水化合物)也是嗜碱性的。细胞质中的大多数蛋白质都是碱性的,因此伊红与这些蛋白质结合并将它们染成粉红色。这包含肌肉细胞中的细胞质细丝、细胞内膜和细胞外纤维。
15.本领域技术人员将了解可以使用的许多替代染色剂,其实例在本技术中进一步讨论。
16.这种组织学图像尤其可以用于评估可能患病的组织,例如可能是癌变的组织。因此,图像可以是组织病理学图像。可能有用的是,能够对组织学(例如组织病理学)图像进行分类以确定预期结果,例如出于从其获得组织学图像的受试者的诊断、预后和/或分层的目的,为受试者做出治疗决定和/或评估受试者正在和/或已经接受的治疗的效果。
17.传统上,组织病理学家
–
接受过这些图像解释培训的专业医学专家在组织学图像中鉴定所关注的组织学特征。
18.然而,已经进行了实验,并且在预后价值有限的许多情况下,无论是在比较不同组织病理学家的鉴定时,甚至是在不同场合向同一组织病理学家展示相同图像时,组织病理学家进行的分类已被证明是不一致的。这种不一致以及观察者之间和内部的可变性可能会产生严重影响。
19.因此需要改进的自动化组织病理学图像分析方法和设备。
技术实现要素:
20.本发明由权利要求书限定。
21.公开了一种用于确定用于一个或多个源组织学图像的总体分类器的计算机实施系统,所述系统包括:
22.第一图块(tile)生成器,所述第一图块生成器被配置成从所述一个或多个源组织学图像生成多个第一图块,其中所述多个第一图块中的每一个图块包括多个像素,所述多个像素表示具有第一面积和第一分辨率的所述一个或多个源组织学图像的区域;
23.第二图块生成器,所述第二图块生成器被配置成从所述一个或多个源组织学图像生成多个第二图块,其中所述多个第二图块中的每一个图块包括多个像素,所述多个像素表示具有第二面积和第二分辨率的所述一个或多个源组织学图像的区域,其中:
24.所述第一图块的所述第一面积大于所述第二图块的所述第二面积;并且
25.所述第二图块的所述第二分辨率高于所述第一图块的所述第一分辨率;
26.机器学习网络,所述机器学习网络被配置成处理所述多个第一图块以确定用于所述一个或多个源组织学图像的第一分类器;
27.机器学习网络,所述机器学习网络被配置成处理所述多个第二图块以确定用于所述一个或多个源组织学图像的第二分类器;以及
28.分类器组合器,所述分类器组合器被配置成组合所述第一分类器和所述第二分类器以确定用于所述一个或多个源组织学图像的总体分类器。
29.所述分类器组合器可以被配置成:
30.将阈值函数应用到所述第一分类器以确定带阈值的第一分类器;
31.将阈值函数应用到所述第二分类器以确定带阈值的第二分类器;以及
32.组合所述带阈值的第一分类器和所述带阈值的第二分类器以确定所述总体分类器。
33.所述机器学习网络可以被配置成处理所述多个第一图块以确定用于所述一个或多个源组织学图像的多个第一分类器。所述机器学习网络可以被配置成处理所述多个第二图块以确定用于所述一个或多个源组织学图像的多个第二分类器。
34.所述分类器组合器可以被配置成:
35.将统计函数应用到所述多个第一分类器以确定组合的第一分类器;
36.将统计函数应用到所述多个第二分类器以确定组合的第一分类器;
37.组合所述组合的第一分类器和所述组合的第二分类器以确定所述总体分类器。
38.所述分类器组合器可以被配置成执行所述第一分类器和所述第二分类器的逻辑组合以确定用于所述一个或多个源组织学图像的总体分类器。
39.还公开了一种处理组织学图像的计算机实施方法,所述方法包括:
40.接收一个或多个源组织学图像;
41.从所述一个或多个源组织学图像生成多个第一图块,其中所述多个第一图块中的每一个图块包括多个像素,所述多个像素表示具有第一面积和第一分辨率的所述一个或多个源组织学图像的区域;
42.从所述源组织学图像生成多个第二图块,其中所述多个第二图块中的每一个图块包括多个像素,所述多个像素表示具有第二面积和第二分辨率的所述一个或多个源组织学图像的区域,其中:
43.所述第一图块的所述第一面积大于所述第二图块的所述第二面积;并且
44.所述第二图块的所述第二分辨率高于所述第一图块的所述第一分辨率;
45.将机器学习网络应用到所述多个第一图块以确定用于所述一个或多个源组织学图像的第一分类器;
46.将机器学习网络应用到所述多个第二图块以确定用于所述一个或多个源组织学图像的第二分类器;以及
47.组合所述第一分类器和所述第二分类器以确定用于所述一个或多个源组织学图像的总体分类器。
48.还公开了一种用于确定一个或多个源组织学图像的分类器的计算机实施系统,所述系统包括:
49.图块生成器,所述图块生成器被配置成从所述一个或多个源组织学图像生成多个图块,其中所述多个图块中的每一个图块包括多个像素,所述多个像素表示所述一个或多个源组织学图像的区域;
50.第一神经网络,所述第一神经网络被配置成处理所述多个图块以确定所述多个图块中的每一个图块的图块特征;
51.池化函数,所述池化函数被配置成组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征(bag-feature);以及
52.第二神经网络,所述第二神经网络被配置成处理所述包特征以确定用于所述一个或多个源组织学图像的分类器。所述第二神经网络可以是分类网络。
53.所述系统可以进一步包括:
54.损失函数,所述损失函数被配置成:
55.将由所述第二神经网络确定的所述分类器与由真值数据表示的地面真值(ground-truth)进行比较,以及
56.基于所述比较的结果为所述第一神经网络、所述池化函数和所述第二神经网络设置可训练参数。
57.所述系统可以进一步包括:
58.分割块,所述分割块被配置成将图像分割方法应用到完整载玻片图像组织学图像以提供源组织学图像。
59.还公开了一种处理组织学图像的计算机实施方法,所述方法包括:
60.接收一个或多个源组织学图像;
61.从所述一个或多个源组织学图像生成多个图块,其中所述多个图块中的每一个图块包括多个像素,所述多个像素表示所述源组织学图像的区域;
62.将第一神经网络应用到所述多个图块以确定所述多个图块中的每一个图块的图块特征;
63.组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征;以及
64.将第二神经网络应用到所述包特征以确定用于所述一个或多个源组织学图像的分类器。所述第二神经网络可以是分类网络。
65.还公开了一种用于确定一个或多个源组织学图像的总体分类器的计算机实施系统,所述系统包括:
66.第一图块生成器,所述第一图块生成器被配置成从所述一个或多个源组织学图像
生成多个第一图块,其中所述多个第一图块中的每一个图块包括多个像素,所述多个像素表示具有第一面积和第一分辨率的所述一个或多个源组织学图像的区域;
67.第二图块生成器,所述第二图块生成器被配置成从所述一个或多个源组织学图像生成多个第二图块,其中所述多个第二图块中的每一个图块包括多个像素,所述多个像素表示具有第二面积和第二分辨率的所述一个或多个源组织学图像的区域,其中:
68.所述第一图块的所述第一面积大于所述第二图块的所述第二面积;并且
69.所述第二图块的所述第二分辨率高于所述第一图块的所述第一分辨率;
70.机器学习网络,所述机器学习网络被配置成处理所述多个第一图块以确定用于所述一个或多个源组织学图像的第一分类器,其中所述机器学习网络包括:
71.第一神经网络,所述第一神经网络被配置成处理所述多个第一图块以确定所述多个第一图块中的每一个图块的图块特征;
72.池化函数,所述池化函数被配置成组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征;以及
73.第二神经网络,所述第二神经网络被配置成处理所述包特征以确定用于所述一个或多个源组织学图像的第一分类器,其中所述第二神经网络是分类网络;
74.机器学习网络,所述机器学习网络被配置成处理所述多个第二图块以确定用于所述一个或多个源组织学图像的第二分类器,其中所述机器学习网络包括:
75.第一神经网络,所述第一神经网络被配置成处理所述多个第二图块以确定所述多个第二图块中的每一个图块的图块特征;
76.池化函数,所述池化函数被配置成组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征;以及
77.第二神经网络,所述第二神经网络被配置成处理所述包特征以确定用于所述一个或多个源组织学图像的第二分类器,其中所述第二神经网络是分类网络;以及
78.分类器组合器,所述分类器组合器被配置成组合所述第一分类器和所述第二分类器以确定用于所述一个或多个源组织学图像的总体分类器。
79.还公开了一种确定用于一个或多个源组织学图像的总体分类器的计算机实施方法,所述方法包括:
80.从所述一个或多个源组织学图像生成多个第一图块,其中所述多个第一图块中的每一个图块包括多个像素,所述多个像素表示具有第一面积和第一分辨率的所述一个或多个源组织学图像的区域;
81.从所述一个或多个源组织学图像生成多个第二图块,其中所述多个第二图块中的每一个图块包括多个像素,所述多个像素表示具有第二面积和第二分辨率的所述一个或多个源组织学图像的区域,其中:
82.所述第一图块的所述第一面积大于所述第二图块的所述第二面积;并且
83.所述第二图块的所述第二分辨率高于所述第一图块的所述第一分辨率;
84.将机器学习网络应用到所述多个第一图块以确定用于所述一个或多个源组织学图像的第一分类器,其中应用所述机器学习网络包括:
85.将第一神经网络应用到所述多个第一图块以确定所述多个第一图块中的每一个图块的图块特征;
86.组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征;以及
87.将第二神经网络应用到所述包特征以确定用于所述一个或多个源组织学图像的第一分类器(所述第二神经网络可以是分类网络);
88.将机器学习网络应用到所述多个第二图块以确定用于所述一个或多个源组织学图像的第二分类器,其中应用所述机器学习网络包括:
89.将第一神经网络应用到所述多个第二图块以确定所述多个第二图块中的每一个图块的图块特征;
90.组合所述图块特征的子集以生成所述每个子集中的每一个子集的包特征;以及
91.将第二神经网络应用到所述包特征以确定用于所述一个或多个源组织学图像的第二分类器(所述第二神经网络可以是分类网络);以及
92.组合所述第一分类器和所述第二分类器以确定用于所述一个或多个源组织学图像的总体分类器。
93.本文公开的任何第一图块生成器和第二图块生成器可以被配置成彼此独立地生成它们各自的图块。
94.本文公开的任何系统可以进一步包括:
95.分割块,所述分割块被配置成将图像分割方法应用到完整载玻片图像组织学图像以提供多个源组织学图像。
96.本文公开的任何第一神经网络都可能已经使用训练组织学图像和相关的地面真值进行了训练。本文公开的任何第二神经网络都可能已经使用训练组织学图像和相关的地面真值进行了训练。
97.本文公开的任何机器学习网络都可能已经使用训练组织学图像和相关的地面真值进行了训练。
98.本文公开的任何方法可以是针对受试者产生诊断和/或预后确定的方法,
99.其中所述方法包括接收一个或多个源组织学图像,所述一个或多个源组织学图像获自从所述受试者获得的一个或多个组织学样品,并且其中所述方法包括:
100.根据本文公开的任何适当方法确定用于所述一个或多个源组织学图像(102)的分类器;和/或根据本文公开的任何公开的适当方法确定用于所述一个或多个源组织学图像的所述总体分类器,以及
101.将诊断和/或预后评估归因于所述分类器和/或总体分类器。
102.所述受试者可以是人。
103.所述受试者可能患有病理学病状、已经被诊断为患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、之前已经针对病理学病状接受过治疗和/或之前可能曾患有病理学病状。
104.从所述受试者获得的所述或每个组织学样品可以获自所述受试者身体的一部分,所述部分患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、已经针对病理学病状接受过治疗和/或之前曾患有病理学病状。
105.所述病理学病状可以是癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症。
106.所述癌症可以是结肠直肠癌。
107.所述方法可以包括评估从获自所述受试者的多个组织学样品获得的多个源组织学图像,以确定多个分类器和/或总体分类器,以及:
108.任选地将所述诊断和/或预后评估归因于所述多个分类器和/或总体分类器;和/或
109.任选地其中所述受试者患有病理学病状、已经被诊断为患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、之前已经针对病理学病状接受过治疗和/或之前曾患有病理学病状,如癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症,并且任选地其中所述癌症是结肠直肠癌。
110.所述方法可以包括评估病理学病状的一种或多种另外的诊断和/或预后标志物,并且
111.其中将诊断和/或预后评估归因于分类器和/或总体分类器的步骤可以包含评估所述或每个另外的诊断和/或预后标志物的所述或每个评估结果。
112.所述方法可以进一步包括基于所述诊断和/或预后评估为所述受试者做出治疗决定,
113.任选地其中所述治疗决定是关于诊断或预后的病理学病状,如癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症,并且任选地其中所述癌症是结肠直肠癌。
114.还公开了一种治疗有需要的受试者的方法,其中诊断和/或预后评估已通过本文公开的任何适当方法归因于所述受试者,所述方法包括通过手术和/或非手术疗法的方法治疗所述受试者;
115.任选地其中对所述诊断或预后的病理学病状的治疗是用于治疗癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症,并且任选地其中所述癌症是结肠直肠癌。
116.所述受试者可以是人。在一些实例中,所述受试者:
117.(a)患有病理学病状、已经被诊断为患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、之前已经针对病理学病状接受过治疗和/或之前曾患有病理学病状;和/或
118.(b)其中病理学病状的诊断和/或预后评估已通过本文公开的任何适当方法归因于所述受试者。
119.所述病理学病状可以是癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症,并且任选地其中所述癌症是结肠直肠癌。
120.所述方法可以包括考虑到已通过本文公开的任何适当方法归因于所述受试者的所述诊断和/或预后评估来调整所述手术和/或非手术疗法的一个或多个参数,并且任选地
121.其中所述手术和/或非手术疗法的所述一个或多个参数选自由以下组成的组:所述手术和/或非手术疗法的性质、所述手术和/或非手术疗法的时机、所述手术和/或非手术疗法的时段、疗法的剂量、所述非手术疗法的施用途径以及所述手术和/或非手术疗法所靶向的身体部位。
122.所述受试者的所述诊断和/或预后评估可以包含评估通过手术和/或非手术疗法进行的早期或正在进行的治疗对所述受试者的影响,
123.例如,为了监测这种治疗的进展和/或效果,并且进一步任选地
124.其中所述方法包含做出另外的治疗决定的步骤,如停止、继续、重复或修改早期或正在进行的治疗和/或实施不同的治疗模态,并且任选地,
125.对所述受试者实施所述另外的治疗决定;任选地其中:
126.所述诊断和/或预后评估、所述治疗和/或所述治疗决定是关于病理学病状,如癌症,例如选自由以下组成的组的癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症,并且任选地其中所述癌症是结肠直肠癌。
127.本文可以提供一种计算机程序,当所述计算机程序在计算机上运行时使计算机配置任何设备,包含本文公开的系统、块或模块,或者执行本文公开的任何方法。作为非限制性实例,计算机程序可以是软件实施方案,并且计算机可以被视为任何适当的硬件,包含数字信号处理器、微控制器以及只读存储器(rom)、可擦除可编程只读存储器(eprom)或电可擦除可编程只读存储器(eeprom)中的实施方案。所述软件可以是汇编程序。
128.所述计算机程序可以设置在计算机可读介质上,所述计算机可读介质可以是如盘或存储器装置等物理计算机可读介质,或者可以体现为瞬态信号。此类瞬态信号可以是网络下载,包含互联网下载。
附图说明
129.现将参照附图借助于实例来描述本发明,在附图中:
130.图1示出了用于确定源组织学图像(如源组织病理学图像)的分类器的计算机实施系统;
131.图2示出了用于确定用于源组织学图像(如源组织病理学图像)的总体分类器的计算机实施系统;
132.图3示出了用于确定用于源组织学图像(如源组织病理学图像)的总体分类器的系统的具体实施方案;
133.图4示出了示例分段网络架构的图示;
134.图5示出了分割方法在调整集(tuning set)上的性能;
135.图6示出了图3的机器学习网络架构的这种实施方案的图示;
136.图7示出了对于训练队列中预后不明显的患者,图3的机器学习网络的21个候选10x模型的c指数;
137.图8示出了对于训练队列中预后不明显的患者,图3的机器学习网络的21个候选40x模型的c指数;
138.图9示出了对于训练队列中预后不明显的患者,inception v3网络的21个候选10x模型的c指数;
139.图10示出了对于训练队列中预后不明显的患者,inception v3网络的21个候选40x模型的c指数;
140.图11示出了对于训练队列中预后不明显的患者,集成模型预测的不良预后概率的c指数,其阈值设置为0.01、0.02等,直至并包含0.99;
141.图12示出了一个图表,说明了来自ahus队列的患者、载玻片和载玻片图像的包含和排除;
142.图13示出了一个图表,说明了来自aker队列的患者、载玻片和载玻片图像的包含和排除;
143.图14示出了一个图表,说明了来自gloucester队列的患者、载玻片和载玻片图像的包含和排除;
144.图15示出了一个图表,说明了来自victor队列的患者、载玻片和载玻片图像的包含和排除;
145.图16示出了对验证队列中domore-v1-crc标志物的初步分析和分期特异性分析,其中:(a)示出了使用aperio at2图像评估的所有患者的结果;(b)示出了使用nanozoomer xr图像评估的所有患者的结果;(c)示出了使用aperio at2图像评估的ii期的结果;(d)示出了使用aperio at2图像评估的iii期的结果;(e)示出了使用aperio at2图像评估的pn2的结果;并且(f)示出了使用aperio at2图像评估的pt4的结果;
146.图17示出了在测试队列中的aperio at2载玻片图像上评估的domore-v1-crc标志物的结果。普通的domore-v1-crc标志物在a、c和d中进行了评估;其中a)涉及通过domore-v1-crc评估的所有患者;c)与通过domore-v1-crc评估的ii期相关,并且d)与通过domore-v1-crc评估的iii期相关。在b中评估的二元domore-v1-crc标志物是通过对domore v1网络的两个集成模型(一个为10x,一个为40x)的预测概率进行平均,并将平均值设为0.58来制作的;使用与用于从两个集成模型创建两个集成标志物的方法相同的方法计算阈值(参见实例1的分类部分);
147.图18示出了一个图表,说明了来自quasar 2队列的患者、载玻片和载玻片图像的包含和排除;并且
148.图19示出了被预测为预后良好、预后不确定和预后不良的患者组的kaplan-meier曲线和风险比。a)来自aperio at2的扫描结果;b)来自nanozoomer xr的扫描结果。注意:尽管标签中有(%),但癌症特异性生存期不是以百分比计。
具体实施方式
149.1.本公开的计算机系统
150.1.1第一示例计算机系统
151.图1示出了用于确定一个或多个源组织学图像102(如源组织病理学图像)的分类器118的计算机实施系统100。
152.如下文将讨论的,系统100包含应用机器学习算法的网络架构111,所述机器学习算法包含两个神经网络108、116。当系统100被训练时,接收到的源组织学图像102包括训练组织学图像,如训练组织病理学图像,并且系统100还处理接收到的真值数据120,所述真值数据表示与所述训练组织学图像相关联的已知结果(“地面真值”)。出于训练目的,应用系统100的目的是适当配置各种可训练参数(包含与两个神经网络108、116相关联的参数),这些参数将用于对随后接收到的源组织学图像102(如源组织病理学图像)进行准确分类。
153.还如下文所讨论的,系统100可用于处理一个或多个源组织学图像102,如源组织病理学图像,其结果(“地面真值”)是未知的。在这种情况下,系统可以应用使用训练组织学图像(如训练组织病理学图像)配置的神经网络108、116,使得系统100的输出是用于接收到的源组织学图像102的分类器118。
154.本文档第1.1节和第1.2节(以及其它章节)中的具体描述描述了一种应用程序,其中单个源组织学图像被划分为多个图块,使得每个图块是单个源组织学图像的像素的子集。在其它实例中,可以处理多个源组织学图像,使得图块可以是整个源组织学图像或源组织学图像的像素的子集。任选地,对多个源组织学图像进行处理,使得每个源组织学图像被划分为多个图块,并且每个图块是每个单个源组织学图像的像素的子集。
155.例如但不限于,多个源组织学图像可以来自相同的组织学样本,和/或来自从相同生物来源获得的不同组织学样本。例如,多个源组织学图像可以来自从同一生物体获得的不同组织学样本;在这种情况下,例如,这些不同的组织学样本可能来自同一组织或来自同一生物体内的不同组织,来自同一器官或来自同一生物体内的不同器官,或者来自同一结构或来自同一生物体内的不同结构。
156.通过处理多个源组织学图像,系统可以考虑存在于单个生物来源中不同位置的特征。任选地,此类位置可以代表存在于单个生物来源中的不同平面(例如,平行或基本平行的平面,或相交的平面)。因此,这种方法可用于生成有关单个生物来源内的不同位置的信息。一个此类实例是使用来自多个平行或基本平行平面的图像来生成与该生物来源相关的3维信息。此类信息可以被认为是“三维源组织学图像”,并且在本发明的实践中也可以被考虑作为源组织学图像的一种任选形式。
157.任选地,三维源组织学图像可以由从生物来源获得的生物材料的多个物理分离(通常,连续平行或基本平行)的切片构建,如本技术的第2.4节所述。获得三维源组织学图像的另一种方法是使用选择性聚焦技术从“厚”组织学切片中获得多个组织学图像,例如如本技术的第2.4节中进一步讨论的那样。
158.另一个此类实例是生成关于单个生物来源内多个离散位置的信息,例如为了确定肿瘤异质性。下面提供了这种处理的进一步细节。
159.1.1.1训练机器学习算法:
160.本章节涉及训练图1的系统100的机器学习算法。
161.系统100包含图块生成器104,其接收一个或多个源组织学图像102,如一个或多个源组织病理学图像。当系统正在被训练时,源组织学图像102可以被称为训练组织学图像。当正在使用一个或多个源组织病理学图像102对系统进行训练时,每个图像可以被称为训练组织病理学图像。本文描述了源组织学图像的各种实例,并且应当理解,系统100可以处理任何类型的组织学图像,包含但不限于任何类型的组织病理学图像。在一些实例中,一个或多个源组织学图像102中的所述或每个图像在被提供给图块生成器104之前可能已经被分割。例如,如将在下面参考图3详细描述的,任选的分割块122可以处理wsi组织学图像124,如wsi组织病理学图像,以提供源组织学图像102。(wsi代表完整载玻片图像。)在一些实例中,分割块122本身可以是神经网络。
162.图块生成器104从一个或多个源组织学图像102(如一个或多个源组织病理学图像)生成多个图块106。多个图块106中的每一个图块包括表示源组织学图像102的区域的多个像素。在一些实例中,多个图块可以是矩形的并且可以对应于一个或多个源组织学图像102的相邻区域。在一些实例中,所述或每个源组织学图像102的像素仅包含在单个图块中。任选地,图块可以彼此间隔开、彼此邻接或者可以彼此重叠。在一些应用中,来自所述或每个源组织学图像102的像素中的一些像素可能不包含在任何图块中
–
例如,如果没有足够的
像素被定位以在源组织学图像102的外围形成完整的图块。
163.图块生成器104(或系统100的另一组件)然后将多个图块106的子集分配给在多实例学习中已知的“包”。图块可以随机分配到包中。在一个实例中,可以随机均匀地绘制图块而无需替换。如果包可以容纳图像中的所有图块,则将按顺序对所有图块进行采样。如果不是,则可以应用一种采样方案,其根据某些标准(在训练期间可能会改变),给某些图块赋予比其它图块更大的权重。
164.每个包表示多个图块106的子集。图像中所有图块的集合表示为i。来自同一图像的图块集合被称为包,并且包的集合被称为批量(或小批量)。没有一个单独的图块被分配地面真值(标签),相反,图块包继承了它所起源的图像的地面真值。我们将包表示为图块的集合,
165.第一神经网络108、池化函数112和第二神经网络116可以一起被认为是用于应用使用多实例学习的机器学习算法的网络架构111。下面总结了训练的一个更新步骤,然后在随后的描述中更详细地讨论:
166.1.一批包被输入到网络架构111;
167.2.第一神经网络(表示网络)将每个图块106映射到图块的表示(图块特征110);
168.3.图块特征100由池化函数112聚合;
169.4.第二神经网络(分类网络)将池化的图块特征(包特征114)作为输入并产生预测(分类器18);
170.5.该预测(分类器118)使用一些损失函数与参考分类(真值数据120)进行比较;
171.6.损失函数关于网络参数的导数用于更新网络架构111的各个参数。第一神经网络108(表示网络)、池化函数112和第二神经网络116(分类网络),都可以具有基于损失函数的导数更新的可训练参数。可以端到端地训练整个网络111。
172.在其余的描述中,我们将忽略批量维度(并隐含地假设批量大小为1)。在具有神经网络的常规深度学习设置中,扩展到大于1的批量大小可以像预期的那样工作。
173.第一神经网络108处理多个图块106中的至少一些图块以确定那些图块106的图块特征110。图块特征110是相关联的输入图块106的表示。第一神经网络108也可以被称为表示网络,并且可以包含应用到多个图块106中的每一个图块的相对轻量级的神经网络。在一个应用中,使用已知的mobilenetv2网络来实现第一神经网络108,如本文进一步描述的(例如,在本技术的第1.3.4节中)。应当理解,可以从图块106提取特征的任何神经网络都可以用作第一神经网络108。例如,可以使用任何卷积网络,尽管网络的选择可能有助于总体分类表现。可以用作第一神经网络108的网络的众所周知的实例包含vgg族、inception族和resnet。
174.下面将描述用于训练第一神经网络108的机制,例如通过调整第一神经网络108中的权重值(或其它可训练参数)。在此实例中,第一神经网络108的输出不直接与真值数据120进行比较,所述真值数据表示与源组织学图像102相关联的地面真值(即已知的真实结果)。
175.第一神经网络(也可以被称为表示网络)是函数其将形状为m
×n×
c的图块x映射到大小为s的图块fr(x;θr)的一些特征表示。例如,该函数可以是常规卷积神经网络。与表示网络相关的可训练参数表示为θr。
176.在此实例中,第一神经网络108应用到包b中的所有图块,从而产生一包表示r={fr(x;θr):x∈b}。请注意,在同一次更新中,包中的所有图块和批量中的所有包使用完全相同的第一神经网络108,其具有相同的θr值。在下一步之前,可以计算和存储批量内的所有表示。
177.由第一神经网络108输出的用于多个图块106中的每一个图块的图块特征110被提供给池化函数112。池化函数112可以组合与一包图块中的图块相关联的图块特征110,以提供每个包的包特征114。
178.池化函数112可以将图片特征集r110减少为一个包b的单个表示,并且通常是函数可以将图片特征集r110减少为一个包b的单个表示,并且通常是函数其中b是包中的图块数。由于此函数可能依赖于包中所有图块的最终表示,因此在计算所有这些表示之前可能不会计算它。该函数还可以具有可训练参数,其集合表示为θ
p
。
179.这些包特征114适用于通过下游多实例学习(mil)算法进行处理。在一个应用中,池化函数112可以应用已知的noisy-and池化函数来生成包特征114。在其它实例中,池化函数112可以将任何归约函数(如总和、平均值、中值等)应用到图块特征110(其可以被认为是输入图块表示)。可以使用的其它更复杂的实例包含noisy-or、isr、广义均值、lse。
180.第二神经网络116处理包特征114中的每一个,以确定用于一个或多个源组织学图像102(如一个或多个源组织病理学图像)的分类器118。第二神经网络116可以被称为分类网络。在一些实例中,第二神经网络116可以被提供为全连接神经网络
181.第二神经网络116(分类网络)的函数可以表示为其中k是类的数量。此函数可以用它自己的可训练参数集θc进行参数化,并且输出范围通常是[0,1],使得对于所有拟合输入所有k类的总和为有了这个,此函数的输出可以被解释为可能的输出类的预测概率,以输入为条件。请注意,包中的所有图块对每个包的单个预测都有贡献,因此网络111不提供每个图块的预测,而是提供图1中所示的分类器118的每个包的预测。
[0182]
在训练阶段,系统100还接收真值数据120。真值数据120表示与所述或每个源组织学图像102(如源组织病理学图像)相关联的地面真值(即已知的真实结果)。例如,但不限于,在训练阶段涉及使用来自同一组织学样本和/或来自从同一生物来源获得的不同组织学样本的多个源组织学图像的情况下,则真值数据120可以表示与从其获得所述或每个组织学样本的相同生物来源相关联的相同地面真值(即相同的已知的真实结果)。
[0183]
全网络111的函数可以表示为其产生分类器118,所述分类器表示每个图块包b的预测f(b;θr,θp,θc)。损失函数l126将分类器118与真值数据进行比较。在下面的描述中,我们假设损失函数足够可微,从而可以使用基于梯度的优化方法进行优化。这在图1中由处理损失函数126的输出并更新第一神经网络108、池化函数112和第二神经网络116中的每一个的可训练参数θr、θ
p
、θc的处理块113以图形方式表示。所述可训练参数中的一个或多个可训练参数也可以被称为加权值。
[0184]
理想情况下,希望包中的图块跨越整个图像,但这可能会受到某些应用程序中的硬件限制,这通常需要二次采样。原则上,可以通过多种不同方式从图像中采样图块,但假设没有先验知识,无需替换的均匀随机采样就足够了。对于图块的随机子采样,图像不太可
能每次都由相同的图块配置表示。这可能对训练产生正则化效果,并有助于泛化。
[0185]
如上所述,包被赋予其原始图像的标签,并且如果包中的图块没有跨越整个图像,则这种分配可能不完全合理。然而,已经发现将图像标签分配给一包图块所导致的误差小于将图像标签分配给单个图块。在这个假设中隐含的是,近似误差随着包中图块所表示的面积的增加而减小,范围从具有单个图块的包到含有图像中所有图块的包。
[0186]
在网络111的训练期间,可能令人期望的是,使用尽可能多的图块来表示图像,并且对于大图像,每个包的图块数量可能受到运行该方法的硬件的内存的限制。第一神经网络108(表示网络)可能是该框架中最大的内存消耗者。在前向传播中,包中的所有图块都可以由第一神经网络处理,但只有图块的表示(即图块特征110)在前向传播中被进一步使用。与存储和处理相关联的图块图像106相比,存储和处理图块特征110需要的内存要少得多。
[0187]
基于梯度的优化方法可以利用网络111“内”的每个图块的中间表示来更新网络的参数。这意味着这些中间表示(包含图块特征110)被存储,直到基于损失函数126的输出计算相关梯度。通过减少反向传播中使用的图块的数量,内存占用可以显著减少。因此,在一个应用中,网络111可以在第二神经网络116的前向传播中使用整个包b,但在反向传播中仅使用包的子集请注意,在此类应用中,可能只有第二神经网络采用这种梯度贡献截断。来自包的所有图块特征110可以被池化函数112使用,并因此被第二神经网络116使用,并且与池化函数112和第一神经网络108相关联的参数(θ
p
,θc)的更新不受第一神经网络中的截断的影响。
[0188]
网络111中的所有可训练参数都可以通过这种反馈机制进行迭代更新。
[0189]
如将在下面详细描述的,系统可以围绕训练循环应用多次迭代,以便选择将用作机器学习算法108的一部分的最终加权值或其它可训练参数。如上所述,因此,应用网络111进行训练的目的是适当地配置网络111,以便它可以用于准确地分类随后接收到的源组织学图像102,如源组织病理学图像,其结果(“地面真值”)是未知的。
[0190]
在一些实例中,训练阶段可以涉及处理来自一个或多个训练队列的数据。应当理解,使用更大的训练队列可以产生更好的系统100,用于随后确定用于结果未知的源组织学图像102的分类器118。例如,训练队列可以包括来自多个不同生物来源中的每一个生物来源的一个或多个源组织学图像,这些生物来源可以选自至少100个、200个、300个、400个、500个、600个、700个、800个、900个、1000个、1500个、200个、2500个、3000个、4000个、5000个、6000个、7000个、8000个、9000个、10000个或更多个不同的生物来源,其中训练队列中的每个生物来源的地面真值是已知的。
[0191]
在处理训练队列之后,系统可以使用来自训练队列的数据应用调整过程和/或使用来自验证队列的数据应用验证过程。调整队列和/或验证队列可以例如包括来自多个不同生物来源中的每一个生物来源的一个或多个源组织学图像,其中不同生物来源的数量可以例如与训练队列中不同生物来源的数量在数量上大致相同(例如,
±
50%、40%、30%、20%、10%、5%或更少)、至少在数量上一样多或在数量上更多(例如,至少50%、60%、70%、80%、90%、100%或更多)。下面提供了示例性细节,但这些不是限制性的,并且技术人员可以使用他们的公知常识来选择合适的训练、调整和/或验证队列以用于该过程。
[0192]
1.1.2使用经过训练的机器学习算法:
[0193]
本节涉及将图1的网络111应用到一个或多个未分类的源组织学图像102,如一个
或多个未分类的源组织病理学图像,其结果(“地面真值”)是未知的。这也被称为推断。例如,网络111可以应用到存在于三维源组织学图像中的多个源组织学图像,如上文进一步讨论的。
[0194]
也就是说,系统100可以应用使用训练组织学图像(如训练组织病理学图像)配置的网络111,以确定用于所述或每个接收到的源组织学图像102的分类器118。以与训练阶段相同的方式起作用的处理块在此不再详细描述。
[0195]
在此实例以及本文描述的其它实例中,用于处理未分类图像的系统100已经使用训练组织学图像和相关联的地面真值进行了训练。更具体地说,第一神经网络、池化函数和第二神经网络中的一个或多个已经使用训练组织学图像和相关联的地面真值进行了训练。如本领域已知的,可以执行训练直到已经执行了围绕循环的最大迭代次数,或者直到损失函数达到可接受的低值,作为非限制性实例。至此,可以认为训练完成。(这并不是说训练不能在以后恢复,如果合适的话。)例如,可以针对一组固定的时期执行优化(通过数据集的完全遍历)。因此,如果训练集中有100个图像,并且算法以5的批量大小训练10个时期,则在终止之前将执行200个优化步骤。更一般地,在数值优化中,可以基于损失函数值终止优化。实例可以是(1)当值低于某个阈值时,(2)当最后k步骤中的值的绝对变化低于某个阈值时,以及(3)当最后k步骤中的值相对于当前值的变化低于某个阈值时。
[0196]
以与上述相同的方式,图块生成器104接收一个或多个源组织学图像102并从所述或每个源组织学图像102生成多个图块106。
[0197]
第一神经网络108处理多个图块106,以确定多个图块106的图块特征110。第一神经网络108可以利用应用在训练阶段期间确定的加权值的神经网络。第一神经网络108可以应用到图像中的所有图块。这可以一次在一个图块上完成,并且可以存储每个图块特征110,直到所有图块都被第一神经网络108处理。每个图块表示110可能只需要非常少量的内存,因此对于所有实践目的,推断中每个图像的图块数量在内存需求方面几乎是无限的。
[0198]
池化函数112聚合图块特征110以提供包特征114。任选地,尤其是在处理未分类的源组织学图像102时,池化函数112可以生成包特征114的包,所述包特征在它们之间包含所有图块特征110。也就是说,没有一个图块特征110可以从包特征114中排除。
[0199]
第二神经网络116处理包特征114,以确定用于所述或每个源组织学图像102的分类器118。
[0200]
即使包的大小在训练和推断中可能不同(当应用到未分类的图像数据时),已发现经过成功训练的网络仍能产生合理的结果。对于其中网络111使用图像中的所有图块进行推断的应用,图像通常在推断中比在训练中更好地被表示。可能有利的是,具有相对较大的包大小用于训练,因为这可以使网络111能够学习可以在整个图像上泛化的特征。在一些实例中,包含来自整个图像的多于5%、8%、10%、15%或20%的图块的包可被视为大包。在某些应用中,也可以在推断过程中使用相对较大的图块包。例如,该算法可以在推断过程中对图块进行二次采样以生成大包,从而加快分类速度。
[0201]
应当理解,在处理未分类的源组织学图像102时不应用损失函数126,因为不存在关联的真值数据120。
[0202]
任选地,如将参考图3详细描述的,可以多次应用图1的系统100的一个或多个部分以确定用于图像或图像集合的多个分类器118,所述图像或图像集合可以被组合以确定总
体分类器。
[0203]
有利的是,图1的系统可以准确和有效地对组织学图像进行分类,特别是用于对如结肠直肠癌等的预后进行分类。
[0204]
1.2第二示例计算机系统
[0205]
图2示出了用于确定用于一个或多个源组织学图像202(如一个或多个源组织病理学图像)的总体分类器232的计算机实施系统200。这可以任选地包含确定用于源组织学图像202的集合的总体分类器232,如存在于三维源组织学图像中的多个源组织学图像,如上文进一步讨论的。
[0206]
如将在下面讨论的,系统200可用于处理一个或多个源组织学图像202,如一个或多个源组织病理学图像,其结果是未知的。该系统可以在训练阶段中应用已经使用训练组织学图像(如训练组织病理学图像)适当配置的机器学习网络211、215。机器学习网络211、215可以以本领域已知的任何方式进行训练。在一些实例中,机器学习网络211、215中的每一个可以包含参考图1描述的网络111,并且可以按照与参考图1描述的方式相同方式进行训练。也就是说,机器学习网络211、215中的每一个可以包含第一神经网络、池化函数和第二神经网络。下面的图3是以这种方式组合图1和2的系统的实例。
[0207]
在一个实施例中,系统200包含第一图块生成器204和第二图块生成器205,它们都接收相同的一个或多个源组织学图像202。与图1一样,图2的系统200可以处理任何类型组织学图像,如任何类型的组织病理学图像。此外,一个或多个源组织学图像202可以由处理一个或多个wsi组织学图像224的任选的分割块222提供。
[0208]
在此实施例中,第一图块生成器204从所述或每个源组织学图像202生成多个第一图块206,并且第二图块生成器205从所述或每个源组织学图像202生成多个第二图块207。
[0209]
在替代实施例中,系统200包含第一图块生成器204和第二图块生成器205,它们接收不同的源组织学图像202(分别为第一和第二源组织学图像),这些源组织学图像是通过从相同的源组织学样品获得不同放大倍率的组织学图像而生成的。第一源组织学图像202和第二源组织学图像202可以至少(通常仅)在图像生成时已应用到同一组织学样品的成像的放大倍率方面有所不同。
[0210]
在此替代实施例中,第一图块生成器204从第一源组织学图像202生成多个第一图块206,并且第二图块生成器205从第二源组织学图像202生成多个第二图块207。
[0211]
在任一个实施例中,多个第一图块206中的每一个图块包括多个像素,所述多个像素表示具有第一面积和第一分辨率的源组织学图像206的区域;并且多个第二图块207中的每一个图块包括多个像素,所述多个像素表示具有第二面积和第二分辨率的源组织学图像的区域。第一图块206的第一面积大于第二图块207的第二面积。以这种方式,与第二图块207相比,第一图块206表示源组织学图像202的更大面积,因此也表示在源组织学图像202中示出的组织学样本的更大面积。
[0212]
第一图块206的第一分辨率低于第二图块207的第二分辨率。以这种方式,与第一图块206相比,第二图块207以更大的粒度显示源组织学图像202的更多细节。因此,第二图块207展示了源组织学图像202中所示的组织学样本的更多细节。
[0213]
以这种方式,第一图块206可以表示组织学样本的足够大的面积,使得其包含样本的结构信息,例如样本内组织的一般结构和/或取向、样本内单个细胞的大小和/或形状和/
或单个细胞和/或细胞组相对于其它单个细胞和/或细胞组的位置。在更一般的术语中,第一图块206的尺寸可以被确定为包含实心多细胞结构的架构,如器官、组织或其它实心结构。因此,该实施例特别适用于评估其中存在这种超细胞结构的固体生物样品(例如但不限于固体肿瘤样品)。因此,此类信息可以包含与样本的分类(如诊断或预后)相关的信息,如组织结构和/或分化模式。
[0214]
这些结构信息中的一些或全部信息可能不一定在第二图块207中可见,因为它们表示比第一图块206更小的面积。此外,第二图块207可以包含组织学样本的足够细节,使得它可以包含个体细胞水平的信息,并且具体地说,可以显示亚细胞结构,如亚细胞结构的存在、大小、位置、形状、密度和/或其它特性中的一种或多种。这种亚细胞结构可以包含但不限于细胞中的细胞核;例如,在第二图块207中可观察到的细胞中的细胞核的大小和/或密度可能是特别关注的,例如,在如癌症(具体地说,实体癌)等病理学的诊断和/或预后中。第二图块207中的附加和/或替代的所关注的亚细胞结构可以包含一种或多种细胞器,和/或一种或多种其它细胞组分,如单个蛋白质、dna分子、rna分子、脂质和/或膜。
[0215]
示例性细胞器和其它大分子包含但不限于内质网(粗糙和/或光滑)、高尔基体、线粒体、液泡、叶绿体、顶体、自噬体、中心粒、纤毛、刺胞、眼点装置、糖体、乙醛糖体、氢化酶体、溶酶体、黑素体、线粒体、肌原纤维、核仁、眼状体、括号体、过氧化物酶体、蛋白酶体、核糖体(80s)、应力颗粒、tiger结构域和/或囊泡。这些亚细胞结构中的一些或全部结构在第一图块206中可能不可见,因为它们通常不具有期望的分辨率。
[0216]
在一个实施例中,第一图块206含有与通过组织学图像的典型低倍光学显微术分析获得的信息等效的信息。在本实例中,低倍光学显微术分析中使用的放大倍率为10x放大倍率,但也可以使用其它低倍放大倍率。例如,在低倍光学显微术分析中使用的放大倍率水平可以是至少4x且小于40x放大倍率,或者可以是约4x、5x、6x、7x、8x、9x、10x、11x、12x、13x、14x、15x、16x、17x、18x、19x、20x、25x、30x或35x放大倍率。在此上下文中,术语“约”是指为所述放大倍率的
±
1x、2x、3x、4x或5x的值,前提是它是提供上述类型样本的部分或全部结构信息的合适的放大倍率水平。原则上,与用于第二图块207的放大倍率相比,低倍放大倍率仅需要在相对意义上是“低倍”的。
[0217]
另外或可替代地,在此实施例中,第二图块207含有与通过组织学图像的典型高倍光学显微术分析获得的信息等效的信息。在本实例中,高倍光学显微术分析中使用的放大倍率为40x放大倍率,但也可以使用其它高倍放大倍率。例如,在高倍光学显微术分析中使用的放大倍率水平可以在约20x和约100x放大倍率之间,如约20x、30x、40x、50x、60x、70x、80x、90或100x放大倍率。在此上下文中,术语“约”是指为所述放大倍率的
±
1x、2x、3x、4x或5x的值,前提是它是在单个细胞水平上提供信息的足够放大倍率,并且具体地说,可以显示上述类型的亚细胞结构中的部分或全部。原则上,与用于第一图块206的放大倍率相比,高倍放大倍率仅需要在相对意义上是“高倍”的。
[0218]
应当理解,在组织学图像中可观察到的信息不仅取决于生成图像时使用的放大倍率水平和/或生成的图像的分辨率,还取决于所使用的染色和/或成像技术。例如,所使用的染色技术将影响在图像中被标记和可见的物理结构,如下面在本技术的第2.4.1节中进一步讨论的。
[0219]
重要的是,第一图块206和第二图块207都可以由足够少量的计算机数据来表示,
使得它们可以被系统200的下游处理块充分处理,而不需要太多的处理能力或处理得太慢。如果以不同方式生成图块,其具有第二图块207的更高分辨率和第一图块206的更大面积,则下游处理块可能需要不可接受的高处理资源来充分执行。
[0220]
在一些应用中,第一图块生成器204和第二图块生成器205可以彼此独立地生成它们各自的图块。例如,第一图块206不一定需要以源组织学图像202的同一点为中心。实际上,第一图块生成器204和第二图块生成器205不需要具有关于产生其图块的另一个图块生成器的任何信息。在一些实例中,第一图块206和第二图块207各自随机地被引导到源组织学图像202的不同面积。因此,可以随机选择第一图块206中的每一个图块居中的源组织学图像202的区域,也可以随机选择第二图块207中的每一个图块居中的源组织学图像202的区域,使得第一图块206和第二图块207的随机选择彼此独立。
[0221]
为了生成准确的分类器218、219,两个机器学习网络211、215的后续应用不需要这两组图块是如何生成的或者它们是如何相互关联的任何协调。因此,有利的是,图2的系统200可以避免对协调两个图块生成器204、205和两个机器学习网络211、215的任何处理的需要。系统200包含机器学习网络211,其处理多个第一图块206以确定用于所述或每个源组织学图像202的第一分类器218。系统200还包含机器学习网络215,其处理多个第二图块207以确定用于所述或每个源组织学图像202的第二分类器219。以这种方式,第二分类器219可以基于在第二图块207中示出的信息,并且第一分类器218可以基于在第一图块206中示出的信息。这些机器学习网络211、215可以各自包含单个神经网络,或多个神经网络,如图1所示。
[0222]
该系统还包含分类器组合器230,其组合第一分类器218和第二分类器219以确定用于所述或每个源组织学图像202的总体分类器232。这可以任选地包含确定用于源组织学图像202的集合的总体分类器232,如存在于三维源组织学图像中的多个源组织学图像,如上文进一步讨论的。
[0223]
可以以多种方式执行组合,包含数学组合、逻辑组合或数学和逻辑组合的组合。例如,第一分类器218和第二分类器219可以具有数值,并且总体分类器232可以是第一分类器218和第二分类器219的平均值。可替代地,第一分类器218和第二分类器219可以逻辑值,并且总体分类器232可以是第一分类器218和第二分类器219的逻辑组合。此类逻辑函数可以是and函数,仅当具有相同的逻辑值时,所述and函数才将总体分类器232设置为与第一分类器218和第二分类器219相同的逻辑值。参考图3描述了分类器组合器230的具体实施方案的另外的细节。
[0224]
有利的是,图2的系统200可以以改进的方式对一个或多个源组织学图像202进行分类,因为它可以基于仅在图块集之一中充分表示的不同特性(第一图块206的大面积或第二图块207的高清晰度)。此外,就所需的处理资源的量而言,分类可以被认为是有效的,因为可以从所述或每个源组织学图像202中提取相关信息和特征,而不需要具有大面积和高清晰度的图块。
[0225]
1.3第三示例计算机系统
[0226]
图3示出了用于确定用于一个或多个源组织学图像302的总体分类器332的系统300的具体实施方案,如一个或多个源组织病理学图像,例如存在于三维源组织学图像中的多个源组织学图像,如上文进一步讨论的。如下文将讨论的,以与图2的系统类似的方式,图
3的系统300生成具有相对较大面积的第一图块306(与第二图块307相比),生成具有相对较高清晰度的第二图块307(与第一图块306相比),并且还具有分类器组合器330。此外,系统300包含机器学习网络311,其包含表示网络308(也可以被称为第一神经网络)和分类网络316(也可以被称为第二神经网络),它们类似于图1的对应组件。
[0227]
以下讨论涉及使用图3的系统300对深度学习模型进行外部评估,以预测来自结肠直肠癌组织切片的癌症特异性生存期,如通过wsi组织病理学图像324所表示的。
[0228]
1.3.1训练队列:
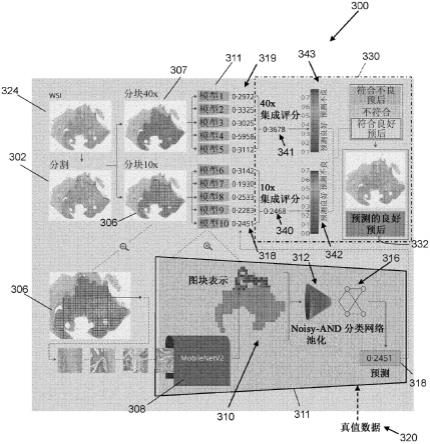
[0229]
本研究使用了四个训练队列。这些是ahus队列、aker队列、gloucester队列和victor队列,它们将在以下小节中进一步描述。根据手术年龄和随访数据,训练队列中的患者被标记为明显或不明显的预后。预后明显的患者包括被定义为预后良好的患者和被定义为预后不良的患者。如果患者在手术时年龄小于85岁,术后随访时间超过6年,没有癌症特异性死亡记录,也没有复发记录,则被定义为预后良好。复发数据的可用性因队列而异,并且尤其受限于gloucester队列。对于ahus队列,要求预后良好的患者没有转移记录(没有局部复发的记录),而aker、gloucester和victor患者不需要有局部或转移性复发的记录。如果患者在手术时年龄小于85岁并且在手术后100天(含端值)和2.5年(不含端值)之间发生癌症特异性死亡,则被定义为预后不良。不满足预后良好或不良标准的患者被定义为预后不明显。
[0230]
1.3.1.1ahus队列
[0231]
图12示出了一个图表,说明了来自ahus队列的患者、载玻片和载玻片图像的包含和排除,以及所包含患者的预后。css,癌症特异性存活;csd,癌症特异性死亡。
[0232]
在从1988年至2000年期间在挪威阿克斯胡斯(akershus)大学医院接受治疗的219名结肠腺癌患者的连续系列中1,172名患者患有i期、ii期或iii期疾病,并且可使用福尔马林固定石蜡包埋的(ffpe)组织块。每个ffpe肿瘤组织块的3μm切片用苏木精和伊红(h&e)染色,并由挪威奥斯陆大学医院癌症遗传学和信息学研究所(icgi)的实验室人员制备为组织载玻片。病理学家确定每个组织切片中是否有肿瘤;排除无肿瘤载玻片的12名患者(如图12所示)。使用两台扫描仪扫描肿瘤组织载玻片,一台aperio at2(leica biosystems,德国)和一台nanozoomer xr(hamamatsu photonics,日本)。使用openslide 3.4.1的python接口(版本1.1.1)读取扫描,可获自https://openslide.org/。应用自动分割方法(下文讨论)来鉴定320个载玻片图像中的肿瘤,并使用被称为40x和10x的两种分辨率将每个载玻片图像划分成多个被称为图块的非重叠区域(请参阅下面的分块章节)。160名肿瘤分割内有图块的所包含患者被定义为ahus队列;图12详细说明了这些患者的预后(参见上文明显和不明显预后的定义2)。
[0233]
1.3.1.2aker队列
[0234]
图13示出了一个图表,说明了来自aker队列的患者、载玻片和载玻片图像的包含和排除,以及所包含患者的预后。css,癌症特异性存活;csd,癌症特异性死亡。
[0235]
1993年至2003年间在挪威aker大学医院接受原发性结肠直肠癌治疗的578名i期、ii期或iii期患者中的每人一个载玻片,并由danielsen及其同事以与ahus队列相同的方式进行分析。三个载玻片的盖玻片被损坏,因此无法被nanozoomer xr扫描仪扫描,并且自动分割方法鉴定出三张aperio at2载玻片图像和两张nanozoomer xr载玻片图像没有肿瘤;
其它患者包括aker队列(图13)。
[0236]
1.3.1.3gloucester队列
[0237]
图14示出了一个图表,说明了来自gloucester队列的患者、载玻片和载玻片图像的包含和排除,以及所包含患者的预后。css,癌症特异性存活;csd,癌症特异性死亡。
[0238]
gloucester结肠直肠癌研究在1988年至1996年间招募了1,036名患者,其中19名因同时性癌症而被排除在外(图14)。其余1,017名患者以与ahus队列相同的方式进行处理,从而导致969名患者具有aperio at2分割,并且967名患者具有nanozoomer xr分割(图14)。这些患者构成了gloucester队列,但其中一名患者被排除在aperio at2 10x图块集之外,因为肿瘤分割内没有图块(图14)。
[0239]
1.3.1.3victor队列
[0240]
图15示出了一个图表,说明了来自victor队列的患者、载玻片和载玻片图像的包含和排除,以及所包含患者的预后。css,癌症特异性存活;csd,癌症特异性死亡。
[0241]
victor试验将ii期和iii期结肠直肠癌患者随机分组,在初步治疗后接受罗非昔布或安慰剂,以检查心血管不良事件。针对2002年至2004年间招募的患者中的795名患者,检索到来自ffpe组织块的h&e染色的3μm切片,其中一些在icgi切片,并且一些在其它地方切片。这些切片的处理方式与ahus队列的处理方式相同。victor队列由767名具有aperio at2 40x图块的患者、764名具有aperio at2 10x图块的患者、761名具有nanozoomer xr 40x图块的患者和756名具有nanozoomer xr 10x图块的患者组成(图15)。
[0242]
1.3.2分割:
[0243]
如图3中示意性所示,通过应用图像分割方法从wsi组织学图像324(如wsi组织病理学图像)生成源组织学图像302。
[0244]
此实例中的分割方法包含从输入图像生成概率图的过程,以及根据输入图像和相应的概率图创建被划分为前景和背景区域的图像的不同过程。
[0245]
图4示出了示例分段网络架构的图示。每层由名称、输出高度、输出宽度和输出通道的数量表示。从顶部的输入图像向下进展到底部的预测输出。概率图可以由图4的分割网络生成,所述分割网络基于deeplab网络(chen等人,《ieee模式分析和机器智能汇刊(ieee trans pattern anal mach intell)》,2018,40:834-848)。最终的分割可以使用密集的条件随机场来实现(和koltun,《神经信息处理系统的进展(adv neural inf process syst)》,2011;24:109-117)。
[0246]
所述方法最初在1077个图像上进行训练,所述图像带有来自aker队列(670个图像)和victor队列(407个图像)的相应注释。这些图像是从使用nanozoomer(hamamatsu photonics,日本)扫描仪扫描的载玻片中获得的,并且注释是由病理学家手绘的。然后将这种经过训练的方法应用到来自aker队列、ahus队列和gloucester队列的图像。由此产生的分割由病理学家验证,其纠正了不令人满意的分割。这组具有相应(可能已校正的)掩码的图像构成了图像分割方法的开发数据集。
[0247]
从1717名患者的开发数据集中,随机抽取25%(429名患者)形成调整集,并且其余1288名患者构成训练集。在训练集中,有358名患者发生了癌症特异性事件,并且有930个患者图像没有发生癌症特异性事件。在调整集中,有128个具有癌症特异性事件的患者图像,并且301名患者没有癌症特异性事件。使用aperio at2扫描仪和nanozoomer xr扫描仪扫描
来自分割开发集中的患者的载玻片。因此,分割任务中的开发集包括3430次扫描(来自nanozoomer xr扫描仪的4次扫描丢失),训练集中有2573次,调整集中有857次。
[0248]
每次扫描都以数字方式调整到对应于2.5x分辨率的大小(参见下面的分块章节),并存储为png图像。然后使用catmull-rum三次过滤器调整每个图像的大小以适应1600x1600像素的帧。这是通过调整图像大小同时保持纵横比直到其最大尺寸(高度或宽度)为1600像素来完成的。然后通过沿着每边的最短尺寸填充大小调整后的图像直到其也是1600像素来形成新图像。大小调整后的图像的中心与填充后的图像的中心对齐,并且进一步使用填充后的图像。
[0249]
分割网络使用100,000个更新步骤(训练迭代)进行训练,每个更新步骤使用分布在4个gpu上的16个图像(这个集合被称为迷你批量)。开发数据集中的每个图像在使用两次之前被使用一次,这意味着在训练期间每个图像被处理大约622次(通过数据集的一次进展被称为一个时期)。在每个时期,相同的图像被使用一次,但每次都有细微的变化。首先,在图像中的随机位置裁剪641x641像素的一部分。然后,按以下顺序应用一组取向失真
[0250]
1.以50%的概率水平翻转图像(沿其水平轴镜像)。
[0251]
2.以50%的概率竖直翻转图像(沿其竖直轴镜像)。
[0252]
3.以50%的概率将图像按以下度数之一旋转一次:0、90、180、270。
[0253]
最后,图像以其平均值和标准差为中心(参见https://www.tensorflow.org/versions/r1.10/api_docs/python/tf/image/per_image_standardization)。将生成的图像作为rgb图像输入分割网络。
[0254]
将可训练参数使用xavier权重初始化方案进行初始化,并使用标准随机梯度下降优化方法进行更新(glorot和bengio,“了解训练深度前馈神经网络的难度(understanding the difficulty of training deep feedforward neural networks.)”,《第13届国际人工智能与统计学会议学报(proc 13th int conf artif intell stat)》,第9卷,249-256(2010))。将优化中的步长初始化为0.05,并在迭代96488(约600个训练时期)时减少0.1倍。
[0255]
将经过训练的网络应用到图像会产生与图像具有相同空间形状的概率图。此概率图是单通道灰度图像,其强度值为0、1、
…
、255。所述方法将高值分配给其发现的可能描绘癌组织的区域。
[0256]
对于每个图像,在将经过训练的网络应用到所有不同版本之前,通过旋转和翻转原始图像来创建图像的附加版本。共有8个版本,并且它们通过以下操作从原始图像中获得:
[0257]
1.什么都不做(这是原始图像)
[0258]
2.围绕其水平轴翻转图像
[0259]
3.围绕其竖直轴翻转图像
[0260]
4.将图像顺时针旋转90度
[0261]
5.将图像顺时针旋转180度
[0262]
6.将图像顺时针旋转270度
[0263]
7.将图像顺时针旋转90度并围绕其水平轴翻转结果
[0264]
8.将图像顺时针旋转270度并围绕其水平轴翻转结果
[0265]
然后将生成的概率图恢复到其原始取向,并计算所有不同版本的平均图像并在此
过程中进一步使用。
[0266]
在推断时,将经过训练的网络一次应用到一个图像(即批量大小为1),并且与训练阶段相反,既不应用裁剪也不应用取向失真。然而,重要的是,每个图像都以其平均值和标准差为中心,就像在训练中所做的那样。使用tensorflow 1.10(https://www.tensorflow.org)在python3.5(https://www.python.org)中实施和运行该网络。
[0267]
使用python库pydensecrf v1.0rc3(https://github.com/lucasb-eyer/pydensecrf)对概率图进行分割。该模型使用一元势(概率图)、高斯成对势(addpairwisegaussian(sxy=1,compat=1))和双边成对势(addpairwisebilateral(sxy=30,srgb=3,compat=100))。将浮点值在(0,1)中的所生成图像的阈值设置为0.5以生成二进制掩码,其中值小于0.5的像素被标记为背景,并且其余像素被标记为前景。
[0268]
在移除与具有少于20,000个像素的八邻域相连的前景区域之前,使用5x5均值滤波器对生成的分割进行平滑处理。完全包含在前景区域内的背景区域被标记为前景。
[0269]
该方法每4,000次迭代应用到调整集,并根据参考分割评估预测的分割。然后选择获得最高平均bookmakers知情度评分的模型作为实验其余部分使用的模型。
[0270]
图5示出了分割方法在调整集上的性能。如上所述,该方法在跨每4,000次迭代的训练过程均匀分布的多次训练迭代中进行评估。图5显示,该模型在迭代88,000次(图5中的附图标记534)时获得了0.902的最高评分。
[0271]
回到图3,分割方法的输出是源组织病理学图像302。
[0272]
1.3.3分块:
[0273]
通过分割方法被鉴定为肿瘤的区域是源组织病理学图像302,在此实例中,由于常用硬件中有限的gpu内存,所述源组织病理学图像不直接适合用作卷积神经网络(cnn)的输入。因此,该过程从源组织学图像302(即,在每个载玻片图像中被分割为肿瘤的区域)内生成多个固定大小的非重叠区域,被称为图块。应当理解,可以采用等效的方法从源组织学图像302内的任何所关注区域生成图块(例如,在源组织学图像中,所述源组织学图像取自或不取自任何其它类型的癌症和/或任何其它病理学病状的组织学样品)。
[0274]
在图3中,示出了多个第一图块306和多个第二图块307。与图2的方式相同,第一图块306具有较大的面积和相对较低的分辨率,而第二图块307具有相对较小的面积和相对较高的分辨率。
[0275]
由于像素表示的物理面积可能取决于用于获得图像的扫描仪以及其它因素,因此表示相同物理面积的图块是通过在来自aperio at2和nanozoomer xr载玻片图像的图块中包含略微不同数量的像素来创建的。在最大分辨率(被称为40x)下,aperio at2载玻片图像中的像素在竖直和水平方向上的物理大小均为0.253μm/像素,而nanozoomer xr载玻片图像中的像素在竖直和水平方向上的物理大小均为0.227μm/像素。为了制作40x图块(分辨率更高的第二图块307),从aperio at2载玻片图像的肿瘤分割内提取具有486x486像素的图块,而nanozoomer xr载玻片图像使用542x542像素。类似地,aperio at2载玻片图像使用1942x1942像素的图块大小,nanozoomer xr载玻片图像使用2166x2166像素的图块大小,以制作10x图块(它们是第一图块306,分辨率较低)。然后将这些原始图块中的每一个图块重新采样为512x512像素,从而使两个扫描仪的每个像素的物理面积类似;0.240x0.240μm用于40x图块,并且0.960x0.960μm用于10x图块。
intell stat)》,第15卷,315-323(2011))。在每个倒置瓶颈模块内,第一个卷积层使用步幅为1的1x1卷积核和relu6激活函数(krizhevsky,a.“cifar-10上的卷积深度信念网络(convolutional deep belief networks on cifar-10.)”可获自:https://www.cs.toronto.edu/~kriz/conv-cifar10-aug2010.pdf.(2010))。深度可分离卷积层使用3x3卷积核。每当空间大小在高度和宽度上减半时,步幅为2,否则步幅为1。激活函数是relu6函数。最后一个卷积层使用步幅为1的1x1卷积核,以及恒等激活函数。当倒置瓶颈模块的输入通道的数量等于同一模块中的输出通道的数量时,模块内第一个卷积层的输入与模块内最后一个卷积层的结果相加。倒置瓶颈模块之后的卷积层使用步幅为1的1x1卷积以及relu激活函数。上述所有卷积和可分离卷积层在应用激活函数之前对卷积结果进行批量归一化(ioffe,s.和szegedy,c.“批量归一化:通过减少内部协变量偏移来加速深度网络训练(batch normalization:accelerating deep network training by reducing internal covariate shift.)”,《第32届国际计算机视觉会议学报(proc 32nd int conf mach learn)》,第37卷,448-456(2015))。将所有的核权重都使用xavier初始化,并且不使用偏置参数。最后的卷积层使用步幅为1的1x1卷积核。该层没有使用批量归一化,并且激活是恒等函数。网络的其余部分由noisy-and池化函数组成,然后是softmax分类,遵循kraus及其同事的设计(kraus,o.z.,ba,j.l.和frey,b.j.“使用深度多实例学习对显微术图像进行分类和分割(classifying and segmenting microscopy images with deep multiple instance learning.)”《生物信息学(bioinformatics)》32,i52-i59(2016))。存在一个与池化函数的输出相关联的交叉熵损失函数,以及一个与分类输出相关联的交叉熵损失函数。
[0284]
机器学习网络311网络以32个包的批量大小进行训练,所述包跨8个gpu分别,每个gpu上有4个包。每个包由64个图块组成,大小为512x512x3像素,并且值为0、1、
…
、255。有助于梯度计算的图块数量为8。为了更新网络参数,0.001的初始步长大小与adam优化方法一起使用(kingma,d.p.和ba,j.“adam:一种随机优化方法(adam:a method for stochastic optimization.)”可获自:https://arxiv.org/abs/1412.6980.(2015))。当在10x图块(第一图块306)上进行训练时,学习率最初设置为0.001,然后在迭代6,000次和迭代12,000次时连续降低0.1倍,然后在迭代15,000次后停止训练。使用两倍的迭代次数在40x图块(第二图块307)上进行训练,即学习率从0.001开始,并在迭代12,000次和迭代24,000次时连续降低0.1倍,然后在迭代30,000次后停止训练。
[0285]
在每个步骤,在进入机器学习网络311之前,每个图块都被失真和归一化。首先,它被随机裁剪为448x448的大小,然后图块的取向被失真。将图块从左到右随机翻转(围绕其中心竖直轴),然后从上到下随机翻转(围绕其中心水平轴),最后随机旋转0
°
、90
°
、180
°
或270
°
。然后,通过将其转换为32位浮点数,然后将整个图块除以255.0,将其值缩放为(0,1)。然后,在使用均匀分布在1/1.1和1.1之间的值缩放每个通道之前,将图块从rgb颜色空间转换为hsv颜色空间。然后将图块转换回rgb。最后,将图块归一化为具有零均值和单位范数(有关更多信息,请参见rgb_to_hsv,hsv_to_rgb,per_image_standardization,https://www.tensorflow.org/versions/r1.10/api_docs/python/tf/image)。
[0286]
在推断时,不应用裁剪,因此机器学习网络311评估大小为512x512x3像素的整个图块。此外,不应用取向或颜色失真。在进入机器学习网络311之前,每个图块被归一化为具
有零均值和单位范数,如在训练中一样。使用tensorflow 1.10(https://www.tensorflow.org)在python 3.5(https://www.python.org)中实施和运行该网络。为了解决训练集中的类不平衡问题,对队列-扫描仪组合中的少数类进行过采样,使得在每个队列-扫描仪组合中被标记为具有良好预后和不良预后的图像的数量相等。在每个队列-扫描仪组合中,图像被随机均匀地采样,没有替换。
[0287]
1.3.5另一个用于比较的网络-inceptionv3网络
[0288]
另一个网络,inception v3网络(szegedy,c.,vanhoucke,v.,ioffe,s.,shlens,j.和wojna,z.“重新思考计算机视觉的inception架构(rethinking the inception architecture for computer vision.)”,《2016年ieee国际计算机视觉与模式识别会议学报(proc 2016 ieee conf comput vis pattern recognit)》2818-2826(2016))用于获得分类结果,以用于与图3的机器学习网络311的结果进行比较。
[0289]
inception v3网络使用keras(2.1.6)使用tensorflow docker image(tensorflow/tensorflow:1.9.0-gpu-py3)进行训练。输入图像大小为512x512,并且输出为两类,第一类是预后良好的概率,第二类是预后不良的概率。使用了二元交叉熵损失函数,并使用keras.optimizers.adam使用默认参数对其进行了优化,但初始学习率设置为0.0001。为了解决预后良好和预后不良的图块之间的类不平衡,在训练之前对每个队列的来自少数类的图块进行过采样,并将文件路径保存为列表。因此,每个队列含有相同数量的包含良好预后和不良预后的图块,代价是可能会两次包含一些图块。图块列表在训练之前加载,并在使用keras.preprocessing.image.imagedatagenerator的修改版本使用16个工作线程加载批量图像之前随机打乱。imagedatagenerator被修改为通过以下方式执行颜色失真:
[0290]
1.将图块转换为hsv颜色空间,
[0291]
2.通过添加
±
0.05之间的随机均匀采样值来增强色调,
[0292]
3.将饱和度按1/1.1和1.1之间的随机均匀采样值缩放,
[0293]
4.将饱和度按
±
0.1之间的随机均匀采样值偏移,
[0294]
5.将值按1/1.1和1.1之间的随机均匀采样值缩放,
[0295]
6.将值按
±
0.1之间的随机均匀采样值偏移,以及
[0296]
7.将图块转换回rgb颜色空间。
[0297]
然后通过减去平均颜色值并除以用于训练的所有图块(即训练队列中具有明显预后的患者的所有图块)的标准差来将图块归一化。对于每次训练迭代,由于gpu内存限制,使用16个图块的批量大小。当在10x图块上进行训练时,学习率最初设置为0.0001,然后在每25,000次迭代中连续减半(从第25,000次迭代开始),然后在迭代150,000次后停止训练。使用两倍的迭代次数在40x图块(第二图块)上进行训练,即学习率从0.0001开始,并在每50,000次迭代中连续减半(从第50,000次迭代开始),然后在迭代300,000次后停止训练。网络输出是图块预后不良的预测概率。通过对患者的所有图块的预测概率进行平均来计算所述患者预后不良的预测概率。
[0298]
1.3.6单个模型
[0299]
针对两个分辨率中的每一个分辨率,对两个网络((i)图3的机器学习网络311,和(ii)inception v3网络)中的每一个网络进行五次训练,结果是20次训练运行。对于这20次
训练中的每一次,对训练队列中所有预后不明显的患者的21个模型进行了评估。针对每次训练运行评估的21个模型从迭代的1/3到训练停止(包含两端)均匀分布。机器学习网络311的每个10x模型在迭代5,000次、5,500次等直至迭代15,000次时进行评估。机器学习网络311的每个40x模型在迭代10,000次、11,000次等直至迭代30,000次时进行评估。inception v3网络的每个10x模型在迭代50,000次、55,000次等直至迭代150,000次时进行评估。inception v3网络的每个40x模型在迭代100,000次、110,000次等直至迭代300,000次时进行评估。
[0300]
为了减少40x模型的评估时间,我们为具有超过2,000个40x图块的每个载玻片选择了2,000个40x图块的随机样品。对所有模型都评估相同的图块。为了进一步减少机器学习网络311的40x模型的评估时间,一次使用50个图块评估具有超过50个图块的患者,从而导致在这些评估中忽略了在50的最后一个倍数之后排序的图块,即每个患者最多忽略49个图块。请注意,这些加速仅在模型选择期间应用;对于所选模型的所有应用,包含本文档中描述的外部评估,所有图块都将被评估。
[0301]
针对每次训练运行,选择使harrell一致性指数最大化的模型(harrell,f.e.,jr,califf,r.m.,pryor,d.b.,lee,k.l.和rosati,r.a.“评估医学测试的产量(evaluating the yield of medical tests.)”《美国医学会杂志(j am med assoc)》247,2543-2546(1982))(c指数)。c指数将观察到的癌症特异性死亡或审查时间与模型预测的训练队列中预后不明显的患者预后不良的概率进行比较。因此,当对训练队列中的非明显预后患者进行评估时,具有最大c指数的模型似乎在其预测的概率中提供了最多的预后信息。
[0302]
图7-10示出了所有候选模型的c指数,并指示了用于21次训练运行中每一次的选定模型。
[0303]
图7示出了对于训练队列中预后不明显的患者,机器学习网络311的21个候选10x模型的c指数。子图a到e示出了训练运行1到5。参考为736a-e的点表示所选模型。包含参考738a-e的点(当然,736a-e除外)和之后的点表示未选择的模型。示出了来自每次训练运行的前三分之一的九个模型(参考738a-e的模型之前的模型)的c指数,以进行比较。
[0304]
图8示出了对于训练队列中预后不明显的患者,机器学习网络311的21个候选40x模型的c指数。子图a到e示出了训练运行1到5。参考为836a-e的点表示所选模型。包含参考838a-e的点(当然,836a-e除外)和之后的点表示未选择的模型。示出了来自每次训练运行的前三分之一的九个模型(参考838a-e的模型之前的模型)的c指数,以进行比较。
[0305]
图9示出了对于训练队列中预后不明显的患者,inception v3网络的21个候选10x模型的c指数。子图a到e示出了训练运行1到5。参考为936a-e的点表示所选模型。包含参考938a-e的点(当然,936a-e除外)和之后的点表示未选择的模型。示出了来自每次训练运行的前三分之一的九个模型(参考938a-e的模型之前的模型)的c指数,以进行比较。
[0306]
图10示出了对于训练队列中预后不明显的患者,inception v3网络的21个候选40x模型的c指数。子图a到e示出了训练运行1到5。参考为1036a-e的点表示所选模型。包含参考1038a-e的点(当然,1036a-e除外)和之后的点表示未选择的模型。示出了来自每次训练运行的前三分之一的九个模型(参考1038a-e的模型之前的模型)的c指数,以进行比较。
[0307]
1.3.6集成模型
[0308]
通过对五个选定模型预测的患者预后不良概率进行平均,为每个网络和分辨率创
建集成模型,从而产生四个集成模型;机器学习网络311的10x和40x集成模型,并且对于inception v3网络也类似。
[0309]
参考图3,机器学习网络311的五个实例被示出为模型6-10。这些实例中的每一个实例都包含第一神经网络308和第二神经网络316。此外,这些实例中的每一个实例被应用到多个第一图块306,以确定用于源组织学图像302的第一分类器318的五个实例。在图3中,第一分类器318的五个实例具有各自的值0.3142、0.1930、0.2533和0.2451。分类器组合器330计算第一分类器318的这五个实例的统计表示,在此实例中为平均值,以确定平均的第一分类器340。在图3的实例中,平均的第一分类器340具有值0.2468,并且被称为10x集成预测。
[0310]
类似地,机器学习网络311的五个实例被示出为模型1-5。这些实例中的每一个实例都包含第一神经网络308和第二神经网络316。此外,这些实例中的每一个实例被应用到多个第二图块307,以确定用于源组织学图像302的第二分类器319的五个实例。在图3中,第二分类器319的五个实例具有各自的值02972、0.3325、0.3025、0.5958和0.3112。系统300计算第二分类器319的这五个实例的统计表示,在此实例中为平均值,以确定平均的第二分类器341。在图3的实例中,平均的第二分类器341具有值0.3678,并且被称为40x集成预测。
[0311]
以这种方式,分类器组合器330可以将统计函数(如平均函数)应用到多个分类器以确定组合的分类器(如平均的分类器340、341)。
[0312]
在此实例中,分类器组合器330将第一阈值函数342应用到平均的第一分类器340以确定带阈值的第一分类器。在此实例中,第一阈值函数342将单个阈值应用到平均的第一分类器340,使得带阈值的第一分类器具有二进制值。下面描述了如何设置单个阈值的实例。在图3中,带阈值的第一分类器的值可以是“预测良好”或“预测较坏”。因此,这种处理可以被认为是对集成模型预测的不良预后概率进行二分法。在其它实例中,第一阈值函数342可以将多个阈值应用到平均的第一分类器340,使得带阈值的第一分类器可以采用三个或更多个离散值中的一个。
[0313]
类似地,分类器组合器330将第二阈值函数343应用到平均的第二分类器341以确定带阈值的第二分类器。在此实例中,如上所述,第二阈值函数343将单个阈值应用到平均的第二分类器341,使得带阈值的第二分类器具有二进制值。下面描述了如何设置单个阈值的实例。同样,带阈值的第二分类器的值可以是“预测良好”或“预测较差”。尽管在其它实例中,第二阈值函数343可以将多个阈值应用到平均的第二分类器341,使得带阈值的第二分类器可以采用三个或更多个离散值中的一个。
[0314]
以这种方式,分类器组合器330可以将阈值函数(包含一个或多个阈值)应用到分类器(任选地应用到平均的分类器)以确定带阈值的分类器。
[0315]
在此实例中,确定的带阈值的分类器是从中获取样品的患者的预后指示,所评估的组织学图像来自所述样品。应当理解,可以采用等效方法来创建集成模型,所述集成模型确定关于任何其它结果的分类器(任选地,平均的分类器),结果取决于与在训练阶段期间使用的源组织学图像相关联的地面真值。
[0316]
在一种实施方案中,为了确定用于对每个集成模型预测的不良预后概率进行二分法的合适阈值,对于训练队列中预后不明显的患者,二分集成模型预测的c指数预测阈值为0.01、0.02等,直至并包含0.99。可以为每个集成模型选择获得最大c指数的阈值。
[0317]
图11示出了对于训练队列中预后不明显的患者,集成模型预测的不良预后概率的c指数,其阈值设置为0.01、0.02等,直至并包含0.99。
[0318]
·
绘图a示出了图3的机器学习网络311的10x集成模型。如果集成模型预测的不良预后概率大于0.51,则预测结果为不良预后。否则,预测概率小于或等于0.51,预测结果为良好预后。该阈值(可被称为二分标志物)可以被称为机器学习网络311的10x集成标志物。
[0319]
·
绘图b示出了机器学习网络311的40x集成模型。由图b鉴定的阈值,可被称为机器学习网络311的40x集成标志物,在此实例中被定义为阈值0.56。
[0320]
·
绘图c示出了inception v3网络的10x集成模型。inception v3网络的10x集成标志物被定义为阈值0.54。
[0321]
·
绘图d示出了inception v3网络的40x集成模型。inception v3网络的40x集成标志物也被定义为阈值0.54。
[0322]
返回到图3,分类器组合器330然后组合带阈值的第一分类器和带阈值的第二分类器以确定用于源组织学图像202的总体分类器332。在此实例中,分类器组合器330执行带阈值的第一分类器和带阈值的第二分类器的逻辑组合。如果带阈值的第一分类器和带阈值的第二分类器都表示相同的结果,则分类器组合器将总体分类器332设置为与带阈值的第一分类器和带阈值的第二分类器相同的值。如果带阈值的第一分类器和带阈值的第二分类器表示不同的结果,则分类器组合器将总体分类器332设置为不同于带阈值的第一分类器和带阈值的第二分类器二者的值。如图3所示:
[0323]
·
如果带阈值的第一分类器和带阈值的第二分类器表示预测良好,则分类器组合器330将总体分类器332设置为“符合良好预后”。
[0324]
·
如果带阈值的第一分类器和带阈值的第二分类器表示预测不良,则分类器组合器330将总体分类器332设置为“符合不良预后”。
[0325]
·
如果带阈值的第一分类器和带阈值的第二分类器中的一个表示预测良好,而另一个表示预测不良,则分类器组合器330将总体分类器332设置为“不符合”。
[0326]
以这种方式,可以为机器学习网络311(以及inception v3网络)创建组合的10x和40x集成模型,方法是定义其中10x和40x集成标志物预测的结果与预测的良好预后(如果两个集成标志物都预测良好预后)或预测的不良预后(如果两个集成标志物都预测不良预后)相同的患者,以及其中10x和40x集成标志物预测的结果与预测的不确定预后不同的患者。任选地,如果不能为患者分析集成标志物之一,例如由于没有10x图块,则10x和40x集成标志物也未定义。因此,此类患者被排除在组合模型的分析之外。
[0327]
这导致了两个组合的10x和40x集成标志物,一个用于机器学习网络311,一个用于inception v3网络。这些3组变量可以被称为domore v1标志物和inception v3标志物。
[0328]
本文公开的计算机系统可以包括计算机可读存储介质、存储器、处理器和一个或多个接口,它们都通过一个或多个通信总线链接在一起。示例性计算机系统可以采用传统计算机系统的形式,如例如台式计算机、个人计算机、膝上型计算机、平板电脑、智能手机、智能手表、虚拟现实耳机、服务器、大型计算机等。在一些实施例中,它可以嵌入显微术设备中,如能够进行完整载玻片成像的虚拟载玻片显微镜。
[0329]
计算机可读存储介质和/或存储器可以存储一个或多个计算机程序(或软件或代码)和/或数据。存储在计算机可读存储介质中的计算机程序可以包含供处理器执行以使计
算机系统运行的操作系统。存储在计算机可读存储介质和/或存储器中的计算机程序可以包含根据本发明实施例的计算机程序或当由处理器执行时使处理器执行根据本发明实施例的方法的计算机程序
[0330]
处理器可以是适合于执行一个或多个计算机可读程序指令的任何数据处理单元,如属于存储在计算机可读存储介质和/或存储器中的计算机程序的数据处理单元。作为一个或多个计算机可读程序指令的执行的一部分,处理器可以将数据存储到计算机可读存储介质和/或存储器和/或从计算机可读存储介质和/或存储器读取数据。处理器可以包括单个数据处理单元或并行或与彼此协作操作的多个数据处理单元。在特别优选的实施例中,处理器可以包括一个或多个图形处理单元(gpu)。gpu非常适合于训练和使用机器学习算法(如本文所公开的那些算法)中所涉及的计算类型。作为一个或多个计算机可读程序指令的执行的一部分,处理器可以将数据存储到计算机可读存储介质和/或存储器和/或从计算机可读存储介质和/或存储器读取数据。
[0331]
一个或多个接口可以包括使计算机系统能够通过网络与其它计算机系统通信的网络接口。网络可以是适合于从一个计算机系统向另一个计算机系统传输或通信数据的任何类型的网络。例如,网络可以包括局域网、广域网、城域网、互联网、无线通信网络等中的一个或多个。计算机系统可以通过任何合适的通信机制/协议通过网络与其它计算机系统通信。处理器可以通过一个或多个通信总线与网络接口通信,以使网络接口通过网络向另一计算机系统发送数据和/或命令。类似地,一个或多个通信总线使处理器能够对计算机系统通过网络接口从网络上的其它计算机系统接收到的数据和/或命令进行操作。
[0332]
接口可以可替代地或另外包括用户输入接口和/或用户输出接口。用户输入接口可以被布置成接收来自系统的用户或操作员的输入。用户可以通过一个或多个用户输入装置(未示出)提供该输入,如鼠标(或其它定点装置、轨迹球或键盘)。用户输出接口可以被布置成在显示器(或监视器或屏幕)(未示出)上将图形/视觉输出提供到系统的用户或操作员。处理器可以指示用户输出接口形成图像/视频信号,所述信号使显示器显示期望的图形输出。显示器可以是触摸感应的,从而使用户能够通过触摸或按压显示器来提供输入。
[0333]
根据本发明的实施例,接口可以可替代地或另外包括到数字显微镜或其它显微术系统的接口。例如,接口可以包括到能够进行完整载玻片成像(wsi)的虚拟显微术设备的接口。在wsi中,虚拟载玻片是通过载玻片扫描仪对载玻片进行高分辨率扫描而生成的。扫描通常是分段完成的,然后将生成的图像拼接在一起以形成一个非常大的图像,该图像具有扫描仪能够达到的最高放大倍率。这些图像的尺寸可能约为100,000x 200,000像素
–
换句话说,它们可能包含数十亿像素。根据一些实施例,计算机系统可以通过接口控制显微术设备以扫描含有样本的载玻片。计算机系统因此可以从显微术设备获得组织学样本的显微图像,通过接口接收。
[0334]
应当理解,上述计算机系统的架构仅为示例性的,并且可以使用具有使用替代组件或使用更多(或更少)组件的不同架构的系统来代替。
[0335]
2.组织学图像及其来源
[0336]
如本文所使用的,术语“组织学图像”是指组织学样本的图像,其示出生物材料的微观结构。“源组织学图像”是已经从定义的生物材料来源获得的组织学样本的组织学图像。例如,定义的生物材料来源可以是生物材料的离体样品。可以根据本发明使用组织学图
像,例如,用于训练目的或用于推断目的,如本技术中进一步描述的。
[0337]
例如,组织学图像可以通过组织学样本的光学显微术获得,例如,在相当于低倍或高倍放大倍率的放大倍率下,如本技术的第1.2节中更详细讨论的那样。然而,本领域技术人员将理解,对组织学样本进行成像的其它方式,包含其它形式的显微术,可以用于生成组织学图像。
[0338]
还可以方便地生成组织学图像,例如,通过使用如本领域常规技术等技术生成完整载玻片图像(wsi),例如,如以下文献所讨论的:farahani等人,《国际病理学和检验医学(pathology and laboratory medicine international)》,2015,7:23
–
33,其内容通过引用并入本文。wsi,通常也被称为“虚拟显微术”,通常旨在以计算机生成的方式模拟常规的光学显微术。实际上,wsi通常包含两个过程。第一个过程通常使用专用硬件(扫描仪)将组织学样本的图像(通常在载玻片上提供)数字化,从而生成大的代表性数字图像(所谓的“数字载玻片”)。第二个过程通常使用专用软件(例如所谓的虚拟载玻片查看器)来查看和/或分析所生成的巨大数字文件。正如farahani等人(2015,同上)所讨论的那样,在过去十年中,已经开发了广泛的商用wsi仪器。常见wsi系统及其各自供应商的列表包含但不限于3dhistech(panoramic scan ii,250flash);digipath(pathscope);hamamatsu(nanozoomer rs、ht和xr);huron(tissuescope 4000、4000xt、hs);leica,前身为aperio并以aperio的名义运营(scanscope at、at2、cs、fl、scn400);mikroscan(d2);olympus(v s120-sl);omnyx(vl4,vl120);perkinelmer(lamina);philips(超快速扫描仪(ultra-fast scanner));sakura finetek(visiontek);unic(precice 500、precice 600x);ventana,前身为bioimagene并以bioimagene的名义运营(iscan coreo、iscan ht);以及zeiss(axio scan.z1)。这些装置旨在满足不同用户群的需求。farahani等人(2015,同上)的表2提供了所选wsi系统之间的差异的列表。优选的装置包含在本实例中使用的装置,其包含nanozoomer xr扫描仪和/或apiero at2扫描仪。
[0339]
因此,在优选的实施例中,所述或每个源组织学图像可以是wsi。
[0340]
在优选的实施例中,本发明的方法(具体地说,训练方法)包含使用至少两个不同的图像扫描设备获得已经用标志物染色的组织学样本的多个源组织学图像,如wsi。通过避免使用单台图像扫描设备,经过训练的机器学习算法不会被训练为仅使用来自所述单台图像扫描设备的图像,因此经过训练的机器学习算法应该更能够处理来自不同图像扫描设备的图像。在训练中引入更多的扫描仪可以有利地提高后续推断的泛化。
[0341]
在使用不同的图像扫描设备的情况下,本发明的方法可以进一步包含对齐图像的步骤。这可以通过例如通常被称为sift变换的尺度不变特征变换来完成。
[0342]
每个显微图像优选地是由一个、两个或三个颜色通道组成的灰度或彩色图像。最优选地,其是由三个颜色通道组成的彩色图像。因此,其为每个像素提供三个样品。样品是三维颜色空间中的坐标。合适的3-d颜色空间包含但不限于rgb、hsv、ycbcr和yuv。
[0343]
组织学图像中的“所关注的组织学特征”是指如wsi等组织学图像中存在的微观结构的特征。非限制性地,该特征可能是例如诊断或治疗目的或科学研究所关注的。
[0344]
组织学样本通常用于检查结构以确定诊断或确定关于从中获取组织学样本的受试者的预后。
[0345]
组织学样本可以从任何生物来源获得。例如,它们可以来自任何有机体,来自有机
体内的任何组织、器官或其它结构,以及来自健康和/或病理学样品。下面将进一步讨论特别所关注的来源。
[0346]
如在本技术的第1节中更详细地讨论并且由本权利要求书进一步定义的,本技术描述了用于确定用于源组织学图像(102;202;302)的分类器(118;318)或总体分类器(232;332)的计算机实施系统(100;200;300),所述源组织学图像可以是源组织病理学图像。
[0347]
在训练阶段,所使用的源组织学图像(例如wsi)是从已知地面真值的来源获得的组织学样本的图像。然后将每个源组织学图像与相关联的真值数据配对,这些真值数据表示从中获得每个组织学样本的每个来源的地面真值。在本文所述的实例中,组织学样本获自癌症患者,以及与将每个患者分类为预后组相关的地面真值,如本文进一步描述的。
[0348]
在使用已经被训练过的计算机实施系统(100;200;300)的情况下,通过训练阶段,源组织学图像(例如wsi)可以是从地面真值未知的来源获得的组织学样本的图像。未知的地面真值可以例如但不限于是与从中获得组织学样本的来源(如受试者)相关的诊断或预后信息。然后可以使用计算机实施系统(100;200;300)来确定用于与未知地面真值相关的源组织学图像(102;202;302)的分类器(118;318)或总体分类器(232;332),例如通过对从中获得源组织学图像的来源进行诊断或预后评估。
[0349]
2.1有机体:
[0350]
从中获得源组织学图像(102;202;302)的组织学样本的生物来源可以例如来自任何生物体,优选地,细胞生物体,更优选地,多细胞生物体。生物来源可以是例如动物,例如人类或非人类动物,如灵长类动物、非人类灵长类动物、实验室动物、农场动物、家畜或家养宠物。
[0351]
可能最优选的是,生物来源是人类受试者。
[0352]
示例性的非人类动物可以任选地包含家禽(如鸡、火鸡、鹅、鹌鹑或鸭)、家畜(如牛、绵羊、山羊或猪、羊驼、斑腾牛、野牛、骆驼、猫、鹿、狗、驴、大额牛、豚鼠、马、骆驼、骡子、兔子、驯鹿、水牛、牦牛)和其它动物,包含动物园动物、圈养动物、野味动物、鱼类(包含淡水和咸水鱼、养殖鱼和观赏鱼)、其它海洋和水生动物(包含贝类,如但不限于牡蛎、贻贝、蛤蜊、虾、对虾、龙虾、小龙虾、螃蟹、墨鱼、章鱼和鱿鱼)、家养动物(如猫和狗)、啮齿动物(如老鼠、大鼠、豚鼠、仓鼠)和马,以及任何其它家养、野生和养殖动物,包含哺乳动物、海洋动物、两栖动物、鸟类、爬行动物、昆虫和其它无脊椎动物。
[0353]
在替代实施例中,用于生物来源的生物体可以包括从非动物来源获得的生物材料,如从植物、真菌或单胞菌属(例如细菌或古细菌)获得的生物材料。
[0354]
2.2组织、器官和其它结构
[0355]
生物来源可以来自所选生物体的任何组织类型、器官或其它所关注的结构,如来自人类受试者或任何其它多细胞生物体,如上文在本技术的第2.1节中所讨论的。
[0356]
例如,生物来源可以来自存在于人类或非人类动物体内的组织;包含例如所选生物体的上皮、结缔组织、肌肉和/或神经系统中的一种或多种。可能特别优选的是,生物来源可以来自存在于人类受试者内的组织。
[0357]
因此,生物来源可以来自或包含存在于所选生物体的上皮内的组织,如来自人类受试者。
[0358]
上皮是连续的细胞片(一层或多层厚),其覆盖身体的外表面,排列与外部环境(消
化道、呼吸道和泌尿生殖道)相通的内部封闭腔和体管,构成腺体及其导管的分泌部分,并且存在于某些感觉器官(例如耳朵和鼻子)的感觉接受区域。上皮覆盖和排列表面(例如皮肤),参与吸收(例如肠)、分泌(例如腺体),可以是感觉的(例如神经上皮)或收缩的(例如肌上皮细胞)。上皮细胞通常是覆盖身体表面的连续细胞片。上皮有两种主要类型:覆盖上皮和腺上皮。
[0359]
覆盖上皮可以包含鳞状上皮(例如血管的内皮衬里和体腔的间皮衬里)、立方上皮(例如排列小导管和/或小管的组织,如在唾液腺或肾脏中)、柱状上皮(如排列在胃、子宫颈和/或肠内的细胞)、假复层上皮、复层上皮(如角化(即皮肤)或非角化(即食道)形式的复层上皮)。
[0360]
腺上皮存在于腺体中,腺体是分泌性上皮细胞的有组织集合。大多数腺体是在发育过程中通过上皮细胞的增殖形成的,因此它们会突出到下面的结缔组织中。一些腺体通过导管保持与表面的连续性,并且被称为外分泌腺。当其它腺体的导管在发育过程中退化时,它们就会失去与表面的直接连续性。这些腺体被称为内分泌腺。
[0361]
因此,用于本发明的源组织学图像的生物来源可以由任何一种或多种上述类型的上皮或任何其它类型的所关注的上皮组成、基本上由这些上皮组成或包括这些上皮。
[0362]
另外和/或可替代地,源组织学图像的生物来源可以来自或包含存在于所选生物体的结缔组织内的组织,如来自人类受试者。结缔组织由细胞和细胞外基质构成。细胞外基质由蛋白质和多糖基质中的纤维构成,由细胞外基质中的细胞分泌和组织。细胞外基质的组成的变化决定了结缔组织的性质。例如,如果基质被钙化,则它可以形成骨骼或牙齿。特殊形式的细胞外基质也构成了肌腱、软骨和眼角膜。一般结缔组织要么松散,要么致密,这取决于纤维的排列。细胞位于由成纤维细胞分泌的糖蛋白、纤维蛋白和糖胺聚糖构成的基质中,并且基质的主要组分实际上是水。
[0363]
例如,结缔组织可以是一种适当的结缔组织形式(例如松散的不规则结缔组织和/或致密的不规则结缔组织),或一种特殊的结缔组织形式。特殊的结缔组织的实例包含:存在于肌腱和韧带中的致密规则结缔组织;软骨;脂肪组织;造血组织(如骨髓、淋巴组织);血液;和骨头。
[0364]
因此,用于本发明的源组织学图像的生物来源可以由任何一种或多种上述类型的结缔组织或任何其它类型的所关注的结缔组织组成、基本上由这些结缔组织组成或包括这些结缔组织。
[0365]
另外和/或可替代地,源组织学图像的生物来源可以来自或包含存在于所选生物体的肌肉内的组织,如来自人类受试者。肌肉组织可以是横纹的或平滑的。肌肉组织可以是一种骨骼肌或心肌形式(两者都是横纹肌的类型),或者可以是一种平滑肌(如在大多数血管和管状器官(如肠)的壁中发现的肌肉组织)。
[0366]
因此,用于本发明的源组织学图像的生物来源可以由任何一种或多种上述类型的肌肉组织或任何其它类型的所关注的肌肉组织组成、基本上由这些肌肉组织组成或包括这些肌肉组织。
[0367]
另外和/或可替代地,源组织学图像的生物来源可以来自或包含存在于所选生物体的神经系统内的组织,如来自人类受试者。神经系统包含由大脑和脊髓组成的中枢神经系统(cns);和周围神经系统(pns),所述周围神经系统由cns以外的所有神经组织组成,包
含来自大脑的颅神经、来自脊髓的脊神经和被称为神经节的结节,所述结节含有神经元细胞体。
[0368]
因此,用于本发明的源组织学图像的生物来源可以由任何一种或多种上述类型的神经系统或所述神经系统内的任何其它类型的所关注的组织组成、基本上由这些神经系统和组织组成或包括这些神经系统和组织。
[0369]
任选地,用于本发明的源组织学图像的生物来源可以由从所选生物体的以下任何一种或多种器官中的获得(如来自人类受试者)的生物材料组成、基本上由这些生物材料组成或包括这些生物材料:
[0370]-肌肉系统,如来自骨骼、关节、韧带、肌肉系统和/或肌腱。
[0371]-消化系统,如来自口腔(例如牙齿和/或舌头)、唾液腺(例如腮腺、颌下腺和/或舌下腺)、咽、食道、胃、小肠(例如十二指肠、空肠和/或回肠)、大肠、肝脏、胆囊、肠系膜、胰腺、肛管和/或肛门。
[0372]-呼吸系统,如来自鼻腔、咽、喉、气管、支气管、肺和/或隔膜。
[0373]-泌尿系统,如来自肾脏、输尿管、膀胱和/或尿道。
[0374]-生殖器官,如女性或男性生殖器官。女性生殖系统包含内生殖器官(如卵巢、输卵管、子宫和阴道)、外生殖器官(如外阴和阴蒂)和胎盘。男性生殖系统包含内生殖器官(如睾丸、附睾、输精管、精囊、前列腺、尿道球腺)和外生殖器官(如阴茎和阴囊)。
[0375]-内分泌系统,如垂体、松果体、甲状腺、甲状旁腺、肾上腺和胰腺。
[0376]-循环系统,如心脏、卵圆孔未闭、动脉、静脉和毛细管。
[0377]-淋巴系统,如淋巴管、淋巴结、骨髓、胸腺、脾脏、肠道相关淋巴组织,包含扁桃体。
[0378]-神经系统,如大脑(包含大脑(例如大脑半球)和间脑)、脑干(包含中脑、脑桥和延髓)、小脑、脊髓和心室系统,包含脉络丛。周围神经系统,如神经(例如颅神经、脊神经、神经节和肠神经系统)。
[0379]-感觉器官,如眼睛及其组分(例如角膜、虹膜、睫状体、晶状体和/或视网膜)、耳朵或其组分(例如外耳,如耳垂;鼓膜;中耳,如听小骨;内耳,如耳蜗、耳前庭和/或半规管)、嗅觉上皮和舌头(包含味蕾)。
[0380]-外皮系统,如乳腺、皮肤和/或皮下组织。
[0381]
2.3健康或病理学样品
[0382]
组织学样本可以从健康或病理学样品中获得。
[0383]
用于本发明的源组织学图像的生物来源可以由从健康或病理学样品获得的生物材料组成、基本上由所述生物材料组成或包括所述生物材料。
[0384]
如果生物材料是从病理学样品获得的,则从其获得的组织学样本可以被称为“组织病理学”样品,并且从定义来源的组织病理学样品获得的图像可以被称为“源组织病理学图像”。如本文所使用的,术语“病理学”是指不健康的状态,包含任何医学病状、病症或疾病。
[0385]
这种组织病理学样品可能含有或疑似含有包括病理学病状的生物材料。例如,组织病理学样品的生物来源可以是患有病理学病状、已经被诊断为患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、之前已经针对病理学病状接受过治疗和/或之前曾患有病理学病状的受试者,如人类受试者。
[0386]
例如,在病理学病状是癌症,并且生物来源是患有癌症、已经被诊断为患有癌症、疑似患有癌症、正在针对癌症接受治疗、已经针对癌症接受过治疗和/或之前曾患有癌症的受试者(如人类受试者)的情况下,组织病理学样品可能含有或疑似含有包括癌细胞的生物材料。
[0387]
从组织病理学样品获得的源组织病理学图像可以被证实含有包括生物材料的图像,所述生物材料:(a)包括具有病理学病状的生物材料、基本上由具有病理学病状的生物材料组成或由具有病理学病状的生物材料组成和/或(b)包括已被病理学病状改变的生物材料、基本上由已被病理学病状改变的生物材料组成或由已被病理学病状改变的生物材料组成。
[0388]
该确认步骤可以以多种方式执行。本领域技术人员了解用于确认在生物材料中、在从生物材料获得的组织学样品中和/或在从其获得的组织学图像中存在病理学病状的许多不同方法。例如,但不限于,确认步骤可以通过人类评估(例如,由受过训练的病理学家)进行。如本文所例示但不限于,在从患有癌症的人类受试者获得的源组织病理学图像的上下文中,病理学家用于确定每个组织切片中是否存在肿瘤,但是应当理解,也可以使用等效的计算机实施的评估来确定组织样品中是否存在肿瘤材料。
[0389]
因此,可能优选的是,组织学样本包括从患有或疑似患有医学病状的受试者获得的生物材料。
[0390]
例如,医学病状可以是疾病。更具体地,所述疾病可以是选自由以下组成的组的疾病:传染病、缺陷病、遗传病(包含基因病和非基因遗传病)和生理病。
[0391]
所述疾病可以是传染病。可替代地,所述疾病可以是非传染性疾病。
[0392]
如本技术的第2.2节中所述,所述疾病可以任选地存在于一个或多个组织和/或器官或其它身体部分中。
[0393]
示例性疾病包含但不限于:基因起源的疾病、由化学和/或物理损伤引起的疾病、免疫起源的疾病(包含免疫缺陷和没有感染时的免疫反应)、生物起源的疾病(包含,例如,病毒性疾病、立克次体病、细菌性疾病以及由真菌和其它寄生虫引起的疾病)、与细胞异常生长相关的疾病(包含但不限于增生、良性肿瘤和恶性肿瘤),具体地说,癌症、代谢-内分泌疾病、营养疾病(例如包含营养过剩疾病和/或营养缺乏疾病、神经精神疾病(包含例如神经系统疾病,如阿尔茨海默病(alzheimer's disease)、亨廷顿舞蹈病(huntington's chorea)和帕金森病(parkinson's disease)),以及衰老疾病。
[0394]
所述疾病可以任选地是急性的、慢性的、恶性的或良性的。急性疾病过程通常突然开始并很快结束。慢性疾病通常开始非常缓慢,然后持续很长时间。术语良性和恶性,最常用于描述肿瘤,可以在更一般的意义上使用。良性疾病通常没有并发症,并且通常预后良好(结果)。恶性肿瘤意味着一个过程,如果任其发展,就会导致致命的疾病。癌症是所有恶性肿瘤的总称。
[0395]
2.3.1癌症:
[0396]
在本发明特别关注的一个实施例中,用于本发明的源组织学图像的生物来源可以由从患有癌症、已经被诊断为患有癌症、疑似患有癌症、正在针对癌症接受治疗、已经针对癌症接受过治疗和/或之前曾患有癌症的受试者(如人类受试者)获得的生物材料组成、基本上由所述生物材料组成或包括所述生物材料。
[0397]
生物材料可以从受试者体内的原发性、继发性或任何其它肿瘤部位获得,或从任何此类已知肿瘤部位的局部、区域或远端部位获得。
[0398]
组织病理学样品可能含有或疑似含有包括一种或多种癌细胞的生物材料。
[0399]
从组织病理学样品获得的源组织病理学图像在其用于本发明之前可以被证实含有包括一个或多个癌细胞的生物材料的图像。
[0400]
可以用本发明评估任何类型的癌症。
[0401]
肿瘤通常被分配一个等级和一个分期。实体瘤的分期是指它的大小或范围,以及它是否已经扩散到其它器官和组织。肿瘤的等级
–
癌症等级
–
表明它可能生长和扩散的速度。
[0402]
例如,癌症可以是0期、i期、ii期、iii期或iv期,或其任何一个或多个的细分。这些不同分期的特性及其细分在本领域中是众所周知的。然而,一般而言:0期表明癌症在起始点(原位)并且尚未扩散。i期表明癌症很小并且没有扩散到其它任何地方。ii期表明癌症已经生长,但尚未扩散。iii期表明癌症较大并且可能已经扩散到周围组织和/或淋巴结(淋巴系统的一部分)。iv期表明癌症已经从它开始的地方扩散到至少一个其它身体器官;也被称为“继发性”或“转移性”癌症。
[0403]
在一个实施例中,癌症可以是由tnm分期系统分类的癌症分期。这是由ajcc和国际癌症控制联盟(uicc)开发和维护的系统。它是世界各地医疗专业人员最常用的分期系统。tnm分类系统是作为医生根据某些标准化标准对不同类型癌症进行分期的工具而开发的。tnm分期系统基于肿瘤的范围(t)、扩散到淋巴结的范围(n)和是否存在转移(m)。
[0404]-t类别描述原始(原发性)肿瘤。tx是指无法评估的原发性肿瘤。t0是指没有原发性肿瘤的证据。tis是指原位癌(尚未扩散到邻近组织的早期癌症)。t1、t2、t3和t4与原发性肿瘤的大小和/或范围有关。
[0405]-n类别描述癌症是否已到达附近的淋巴结。nx表示无法评估区域性淋巴结。n0表示没有区域性淋巴结的参与(淋巴结中未发现癌症)。n1、n2和n3表示区域性淋巴结的参与(数量和/或扩散范围)。
[0406]-m类别表明是否存在远处转移(癌症扩散到身体的其它部位)。m0表示没有远处转移(癌症没有扩散到身体的其它部位)。m1表示远处转移(癌症已扩散到身体的远端部分)。
[0407]
因为每种癌症类型都有自己的分类系统,所以字母和数字对于每种癌症并不总是意味着相同的东西。一旦确定了t、n和m,就将它们组合起来,并且可以分配0、i、ii、iii、iv的总体分期。有时也使用如iiia和iiib等字母将这些分期细分。进一步的指导可以在以下网址中找到:www.https://cancerstaging.org.
[0408]
在一些癌症类型中,可以考虑非解剖因素来分配解剖分期/预后组。这些在ajcc癌症分期手册的每一章中都有明确定义(例如前列腺中的gleason评分)。这些因素与t、n和m分开收集,它们仍然是纯粹的解剖学并用于分配分期组。在分组中使用非解剖学因素的情况下,针对非解剖因素不可用(x)或希望分配一个忽略非解剖因素的组的情况提供了分组的定义。
[0409]
i期癌症进展最慢,并且通常预后较好。较高分期的癌症通常更晚期,但在许多情况下仍然可以成功治疗。
[0410]
在另外和/或可替代的选项中,癌症可以是特定等级的。分级通常基于细胞的分化
(与正常细胞的相似程度)。例如,癌症的指定等级可以是i级、ii级、iii级或iv级癌症,或者两个或三个类别的组合。这些不同等级的特性在本领域中是众所周知的。然而,一般而言:i级癌症是其中细胞与正常细胞相似且生长不迅速的一类癌症;ii级癌症是其中癌细胞看起来不像正常细胞并且比正常细胞生长得更快的一类癌症;并且iii级和iv级是其中癌细胞看起来异常并且可能更积极地生长或扩散的一类癌症。例如,可以基于划分细胞的频率在一些癌症中评估生长特性。
[0411]
例如,癌症可以是选自由以下组成的组的一类癌症:癌、肉瘤、骨髓瘤、白血病、淋巴瘤和混合型癌症。
[0412]
癌是指上皮起源的恶性肿瘤或身体内部或外部衬里的癌症。癌是上皮组织的恶性肿瘤,占所有癌症病例的80%到90%。上皮组织遍布全身。如上文进一步讨论的,它存在于皮肤中,以及器官和内部通道(如胃肠道)的覆盖物和衬里中。
[0413]
癌可以分为两种主要亚型:腺癌,发生于腺体器官;和鳞状细胞癌,起源于鳞状上皮。
[0414]
腺癌通常发生在黏膜中,并且最初表现为增厚的斑块状白色黏膜。它们通常很容易通过它们所发生的软组织传播。鳞状细胞癌发生在身体的许多区域。
[0415]
大多数癌会影响能够分泌的器官或腺体,如产生乳汁的乳房,或分泌粘液的肺,或结肠或前列腺或膀胱。
[0416]
在一个实施例中,癌可以是源自上皮细胞的癌症,其选自乳腺癌、基底细胞癌、腺癌、胃肠癌、唇癌、口腔癌、食道癌、小肠癌和胃癌、结肠癌、肝癌、膀胱癌、胰腺癌、卵巢癌、宫颈癌、肺癌和皮肤癌(如鳞状细胞癌和基底细胞癌)、前列腺癌、肾细胞癌和其它影响全身上皮细胞的已知癌症。
[0417]
肉瘤是指起源于支持性和结缔组织(如骨骼、肌腱、软骨、肌肉和脂肪)的癌症。通常发生在年轻人中,最常见的肉瘤通常发展为骨骼上的疼痛肿块。肉瘤通常类似于它们所生长的组织。
[0418]
肉瘤的实例是:骨肉瘤或成骨肉瘤(骨)、软骨肉瘤(软骨)、平滑肌肉瘤(平滑肌)、横纹肌肉瘤(骨骼肌)、间皮肉瘤或间皮瘤(体腔膜层)、纤维肉瘤(纤维组织)、血管肉瘤或血管内皮瘤(血管)、脂肪肉瘤(脂肪组织)、神经胶质瘤或星形细胞瘤(大脑中发现的神经源性结缔组织)、粘液肉瘤(原始胚胎结缔组织)、间充质或混合中胚层肿瘤(混合结缔组织类型)。
[0419]
骨髓瘤是起源于骨髓浆细胞的癌症。浆细胞产生一些在血液中发现的蛋白质。
[0420]
癌症可以是实体癌或液体癌。
[0421]
例如,白血病(“液体癌”或“血癌”)是骨髓癌(血细胞生成部位)。这种疾病通常与未成熟白细胞的过度产生有关。这些未成熟的白细胞表现不佳,因此患者通常容易感染。白血病还会影响红细胞,并可能导致血液凝固不良和贫血导致的疲劳。白血病的实例包含:
[0422]-髓性或粒细胞性白血病(髓性和粒细胞性白细胞系列的恶性肿瘤)
[0423]-淋巴、淋巴细胞或淋巴细胞白血病(淋巴和淋巴细胞血细胞系列的恶性肿瘤)
[0424]-真性红细胞增多症或红细胞增多症(各种血细胞产物的恶性肿瘤,但以红细胞为主)
[0425]
淋巴瘤在淋巴系统的腺体或淋巴结中发展,所述淋巴系统是一个由血管、淋巴结
和器官(特别是脾脏、扁桃体和胸腺)组成的网络,可净化体液并产生抗感染的白细胞或淋巴细胞。与有时被称为“液体癌”的白血病不同,淋巴瘤是“实体癌”。淋巴瘤也可能发生在特定器官,如胃、乳房或大脑中。这些淋巴瘤被称为结外淋巴瘤。淋巴瘤分为两类:霍奇金淋巴瘤(hodgkin lymphoma)和非霍奇金淋巴瘤(non-hodgkin lymphoma)。霍奇金淋巴瘤中reed-sternberg细胞的存在在诊断上将霍奇金淋巴瘤与非霍奇金淋巴瘤区分开来。
[0426]
混合类型的癌症可以包含其中类型组分在一个类别内或来自不同癌症类别的癌症。一些实例是:腺鳞癌;混合中胚层肿瘤;癌肉瘤;和畸胎癌。
[0427]
任选地,癌症可以是原发性癌症或转移性癌症。原发性癌症是指原发性肿瘤中的癌细胞,其是出现在受试者体内第一部位的肿瘤,并且可以与出现在受试者体内远离原发性肿瘤的部位的转移性肿瘤区分开来。转移性癌症是由转移引起的,转移是指癌症从起源器官扩散到患者中另外的远端部位的情况。
[0428]
在一个优选的实施例中,用于本发明的组织学样本包括从患有或疑似患有选自以下列表中任何一项或多项的一类癌症的受试者获得的生物材料:
[0429]
·
急性淋巴细胞白血病(all)、
[0430]
·
急性髓细胞性白血病(aml)、
[0431]
·
青少年癌症(例如12-18岁的青少年)、
[0432]
·
肾上腺皮质癌,还包含例如:
[0433]
о儿童肾上腺皮质癌
[0434]
·
与aids相关的癌症,还包含例如:
[0435]
о卡波西肉瘤(kaposi sarcoma)(软组织肉瘤)
[0436]
о与aids相关的淋巴瘤(淋巴瘤)
[0437]
о原发性cns淋巴瘤(淋巴瘤)
[0438]
·
肛门癌
[0439]
·
阑尾癌
[0440]
·
儿童星形细胞瘤(脑癌)
[0441]
·
非典型畸胎瘤/横纹肌瘤,儿童,中枢神经系统(脑癌)
[0442]
·
皮肤基底细胞癌
[0443]
·
胆道癌
[0444]
·
膀胱癌,还包含例如:
[0445]
о儿童膀胱癌
[0446]
·
骨癌(例如,尤文肉瘤(ewing sarcoma)、骨肉瘤或恶性纤维组织细胞瘤)
[0447]
·
脑肿瘤
[0448]
·
乳腺癌,还包含例如:
[0449]
о儿童乳腺癌
[0450]
·
儿童支气管肿瘤
[0451]
·
伯基特淋巴瘤(burkitt lymphoma)
[0452]
·
类癌瘤(胃肠道),还包含例如:
[0453]
о儿童类癌瘤
[0454]
·
原发性不明的癌,还包含例如:
[0455]
о儿童原发性不明的癌
[0456]
·
儿童心脏(心脏)肿瘤
[0457]
·
中枢神经系统,还包含例如:
[0458]
о儿童非典型畸胎瘤/横纹肌瘤,(脑癌)
[0459]
о儿童胚胎肿瘤,(脑癌)
[0460]
о儿童生殖细胞肿瘤,(脑癌)
[0461]
о原发性cns淋巴瘤
[0462]
·
宫颈癌,还包含例如:
[0463]
о儿童宫颈癌
[0464]
·
儿童癌症(例如,18岁以下的儿童,优选地,16岁、14岁或12岁以下,如1-12岁范围内的儿童)、
[0465]
·
罕见的儿童癌症、
[0466]
·
胆管癌
[0467]
·
儿童脊索瘤、
[0468]
·
慢性淋巴细胞白血病(cll)
[0469]
·
慢性粒细胞性白血病(cml)
[0470]
·
慢性骨髓增生性肿瘤
[0471]
·
结肠直肠癌,还包含例如:
[0472]
о儿童结肠直肠癌
[0473]
·
儿童颅咽管瘤(脑癌)
[0474]
·
皮肤t细胞淋巴瘤
[0475]
·
导管原位癌(dcis)
[0476]
·
胚胎肿瘤,中枢神经系统,儿童(脑癌)
[0477]
·
子宫内膜癌(子宫癌)
[0478]
·
儿童室管膜瘤(脑癌)
[0479]
·
食道癌,还包含例如:
[0480]
о儿童食道癌
[0481]
·
感觉神经母细胞瘤(头颈癌)
[0482]
·
尤文肉瘤(骨癌)
[0483]
·
儿童颅外生殖细胞肿瘤、
[0484]
·
性腺外生殖细胞肿瘤
[0485]
·
眼癌,还包含例如:
[0486]
о儿童眼内黑色素瘤
[0487]
о眼内黑色素瘤
[0488]
о视网膜母细胞瘤
[0489]
·
输卵管癌
[0490]
·
骨纤维组织细胞瘤,恶性,和骨肉瘤
[0491]
·
胆囊癌
[0492]
·
胃癌(胃癌),还包含例如:
[0493]
о儿童胃癌(胃癌)
[0494]
·
胃肠道类癌
[0495]
·
胃肠道间质瘤(gist)(软组织肉瘤),还包含例如:
[0496]
о儿童胃肠道间质瘤
[0497]
·
生殖细胞肿瘤,还包含例如:
[0498]
о儿童中枢神经系统生殖细胞肿瘤(脑癌)
[0499]
о儿童颅外生殖细胞肿瘤
[0500]
о性腺外生殖细胞肿瘤
[0501]
о卵巢生殖细胞肿瘤
[0502]
о睾丸癌
[0503]
·
妊娠滋养细胞疾病
[0504]
·
毛细胞白血病
[0505]
·
头颈癌
[0506]
·
儿童心脏肿瘤
[0507]
·
肝细胞(肝)癌
[0508]
·
朗格汉斯细胞组织细胞增生症(histiocytosis,langerhans cell)
[0509]
·
霍奇金淋巴瘤
[0510]
·
下咽癌(头颈癌)
[0511]
·
眼内黑色素瘤,还包含例如:
[0512]
о儿童眼内黑色素瘤
[0513]
·
胰岛细胞肿瘤、胰腺神经内分泌肿瘤
[0514]
·
卡波西肉瘤(软组织肉瘤)
[0515]
·
肾(肾细胞)癌
[0516]
·
朗格汉斯细胞组织细胞增生症
[0517]
·
喉癌(头颈癌)
[0518]
·
白血病
[0519]
·
唇癌和口腔癌(头颈癌)
[0520]
·
肝癌
[0521]
·
肺癌(非小细胞和小细胞),还包含例如:
[0522]
о儿童肺癌
[0523]
·
淋巴瘤
[0524]
·
男性乳腺癌
[0525]
·
恶性骨纤维组织细胞瘤和骨肉瘤
[0526]
·
黑色素瘤,还包含例如:
[0527]
о儿童黑色素瘤
[0528]
·
眼内(眼)黑色素瘤,还包含例如:
[0529]
о儿童眼内黑色素瘤
[0530]
·
默克尔细胞癌(merkel cell carcinoma)(皮肤癌)
[0531]
·
恶性间皮瘤,还包含例如:
[0532]
о儿童间皮瘤
[0533]
·
转移性癌症
[0534]
·
隐匿性原发性转移性鳞状颈癌(头颈癌)
[0535]
·
nut基因改变的中线道癌(midline tract carcinoma)
[0536]
·
口腔癌(头颈癌)
[0537]
·
多发性内分泌腺瘤综合征
[0538]
·
多发性骨髓瘤/浆细胞肿瘤
[0539]
·
蕈样肉芽肿(淋巴瘤)
[0540]
·
骨髓增生异常综合征、骨髓增生异常/骨髓增生性肿瘤
[0541]
·
慢性粒细胞性白血病(cml)
[0542]
·
急性髓细胞性白血病(aml)
[0543]
·
慢性骨髓增生性肿瘤
[0544]
·
鼻腔和鼻窦癌(头颈癌)
[0545]
·
鼻咽癌(头颈癌)
[0546]
·
神经母细胞瘤
[0547]
·
非霍奇金淋巴瘤
[0548]
·
非小细胞肺癌
[0549]
·
口腔癌、唇癌和口腔癌以及口咽癌(头颈癌)
[0550]
·
骨肉瘤和恶性骨纤维组织细胞瘤
[0551]
·
卵巢癌,还包含例如:
[0552]
о儿童卵巢癌
[0553]
·
胰腺癌,还包含例如:
[0554]
о儿童胰腺癌
[0555]
·
胰腺神经内分泌肿瘤(胰岛细胞肿瘤)
[0556]
·
乳头状瘤(儿童喉部)
[0557]
·
副神经节瘤,还包含例如:
[0558]
о儿童副神经节瘤
[0559]
·
鼻窦和鼻腔癌(头颈癌)
[0560]
·
甲状旁腺癌
[0561]
·
阴茎癌
[0562]
·
咽癌(头颈癌)
[0563]
·
嗜铬细胞瘤,还包含例如:
[0564]
о儿童嗜铬细胞瘤
[0565]
·
垂体瘤
[0566]
·
浆细胞赘瘤/多发性骨髓瘤
[0567]
·
胸膜肺母细胞瘤
[0568]
·
妊娠和乳腺癌(即怀孕女性的乳腺癌)
[0569]
·
原发性中枢神经系统(cns)淋巴瘤
[0570]
·
原发性腹膜癌
[0571]
·
前列腺癌
[0572]
·
直肠癌
[0573]
·
复发性癌症
[0574]
·
肾细胞(肾)癌
[0575]
·
视网膜母细胞瘤
[0576]
·
儿童横纹肌肉瘤(软组织肉瘤)
[0577]
·
唾液腺癌(头颈癌)
[0578]
·
肉瘤,还包含例如:
[0579]
о儿童横纹肌肉瘤(软组织肉瘤)
[0580]
о儿童血管肿瘤(软组织肉瘤)
[0581]
о尤文肉瘤(骨癌)
[0582]
о卡波西肉瘤(软组织肉瘤)
[0583]
о骨肉瘤(骨癌)
[0584]
о软组织肉瘤
[0585]
о子宫肉瘤
[0586]
·
塞扎里综合征(s
é
zary syndrome)(淋巴瘤)
[0587]
·
皮肤癌,还包含例如:
[0588]
о儿童皮肤癌
[0589]
·
小细胞肺癌
[0590]
·
小肠癌
[0591]
·
软组织肉瘤
[0592]
·
皮肤鳞状细胞癌
[0593]
·
隐匿性原发性转移性鳞状颈癌(头颈癌)
[0594]
·
胃癌(胃癌),还包含例如:
[0595]
о儿童胃癌(胃癌)
[0596]
·
皮肤t细胞淋巴瘤
[0597]
·
睾丸癌,还包含例如:
[0598]
о儿童睾丸癌
[0599]
·
咽喉癌(头颈癌),还包含例如:
[0600]
о鼻咽癌
[0601]
о口咽癌
[0602]
о下咽癌
[0603]
·
胸腺瘤和胸腺癌
[0604]
·
甲状腺癌
[0605]
·
肾盂和输尿管的移行细胞癌(肾(肾细胞)癌)
[0606]
·
原发性不明的癌,还包含例如:
[0607]
о儿童原发性不明的癌症
[0608]
·
罕见的儿童癌症
[0609]
·
输尿管和肾盂移行细胞癌(肾(肾细胞)癌)
[0610]
·
尿道癌
[0611]
·
子宫内膜癌
[0612]
·
子宫肉瘤
[0613]
·
阴道癌,还包含例如:
[0614]
о儿童阴道癌
[0615]
·
血管肿瘤(软组织肉瘤)
[0616]
·
外阴癌
[0617]
·
wilms肿瘤和其它儿童肾肿瘤
[0618]
·
年轻人的癌症(例如,16-30岁的年轻人,如18-30岁;任选地小于28岁、26岁、24岁、22岁或20岁)
[0619]
更具体地说,在优选的实施例中,用于本发明的源组织学图像的生物来源可以由从患有一类癌症、已经被诊断为患有一类癌症、疑似患有一类癌症、正在针对一类癌症接受治疗、已经针对一类癌症接受过治疗和/或之前曾患有一类癌症的受试者(如人类受试者)获得的生物材料组成、基本上由所述生物材料组成或包括所述生物材料,所述癌症选自以下列表中的任何一项或多项:
[0620]
皮肤癌:皮肤癌主要分为三种类型:基底细胞癌、鳞状细胞癌和黑色素瘤。这些癌症源自具有相同名称的表皮层。黑色素瘤源自表皮最深处的黑色素细胞或色素细胞。基底细胞癌和鳞状细胞癌通常发生在暴露在阳光下的身体部位,如面部、耳朵和四肢。
[0621]
肺癌:肺癌很难在早期发现,因为症状通常要等到疾病进展后才会出现。症状包含持续咳嗽、痰中带血、胸痛和反复发作的肺炎或支气管炎。
[0622]
女性或男性乳腺癌:据估计,在美国,大约八分之一的女性最终会在其一生中患上乳腺癌。大多数乳腺癌是导管癌。最有可能患上这种疾病的女性是50岁以上的女性;已经患过一侧乳房癌症的女性;母亲或姐妹患有乳腺癌的女性;从未有过孩子的女性;以及在30岁以后生第一个孩子的女性。其它风险因素包含肥胖、高脂肪饮食、初潮早(月经开始)和绝经晚(月经停止)。
[0623]
前列腺癌:前列腺癌主要见于老年男性。随着男性年龄的增长,前列腺可能会扩大并阻塞尿道或膀胱。这可能会导致排尿困难或干扰性功能。这种情况被称为良性前列腺肥大(bph)。虽然bph不是癌性的,但可能需要手术来纠正它。bph或其它前列腺问题的症状可能与前列腺癌的症状类似。
[0624]
结肠和/或直肠癌:结肠直肠癌(crc)是一种通常起源于胃肠道结肠或直肠上皮细胞的疾病。在影响大肠的癌症中,约70%发生在结肠,约30%发生在直肠。这些癌症总体上是第三大最常见的癌症。症状包含便血,其可以通过简单的粪便潜血测试来检测,或排便习惯的改变,如严重的便秘或腹泻。
[0625]
子宫(子宫体)癌症:子宫是女性骨盆中的囊,其允许婴儿从受精卵发育并保护婴儿直到出生。子宫癌是最常见的妇科恶性肿瘤。这种癌症在40岁以下的女性中很少发生。它最常发生在60岁以后。主要症状通常是异常子宫出血。通常进行子宫内膜活检或d&c以确认诊断。
[0626]
除了以上讨论的以原发部位命名的癌症类型外,还有许多其它实例,如脑癌、睾丸癌、膀胱癌等。
[0627]
2.3.2处理:
[0628]
如上所述,从中生成源组织病理学图像的组织病理学样品的生物来源可以是正在针对病理学病状(如癌症)接受治疗和/或之前已经接受过治疗的受试者(如人类受试者)。
[0629]
另外和/或可替代地,受试者可以例如是患有所关注的病理学病状(包含但不限于癌症)并且例如希望获得有关病理学病状的进一步信息,以帮助就该病理学病状的未来治疗的需求、性质和/或潜在益处做出决定的受试者。
[0630]
例如,受试者可以是已被诊断为患有所关注的病理学病状(包含但不限于癌症)并且已经接受了针对该病理学病状的一种或多种治疗的受试者,所述受试者希望了解他们是否仍然患有病理学病状和/或获得有关在受试者体内先前治疗过病理学病状的部位或受试者体内任何其它部位的生物材料的进一步信息,以帮助就该病理学病状的未来治疗的需求、性质和/或潜在益处做出决定。
[0631]
包含了针对病理学病状(包含癌症)的任何此类治疗形式,并且技术人员熟知本领域的此类治疗,包含但不限于手术和/或非手术治疗方法(例如,施用一种或多种组合物,所述或每种组合物包括一种或多种活性剂,所述活性剂提供关于病理学病状的治疗效果和/或预防效果),以及如何使治疗形式与病理学病状的类型相匹配。
[0632]
更具体地但不限于,癌症治疗包含手术、放射疗法、化学疗法、双膦酸盐、基因疗法、免疫疗法、靶向疗法、激素疗法、干细胞和/或骨髓移植,和/或精准医学。另外的癌症治疗包含但不限于射频消融、激光治疗、高强度聚焦超声(hifu)、光动力疗法、冷冻疗法、紫外线治疗和/或电化学疗法。在一个实施例中,癌症治疗(例如,在就该病理学病状的未来治疗的需求、性质和/或潜在益处做出决定的上下文中)可以是一种辅助疗法形式。辅助疗法是在初步(初始)治疗之外给予的一种治疗形式。癌症的辅助疗法包含在初步(例如手术)治疗之后的一种疗法,并且可以是旨在治疗初步治疗后残留在受试者体内的任何癌细胞和/或帮助降低癌症复发的风险的一种癌症疗法(例如,化学疗法或放射疗法,或任何其它形式的癌症疗法)。
[0633]
2.3.3受试者特性:
[0634]
如上所述,充当根据本发明使用的组织学样本中存在的生物材料的来源的受试者(如人类受试者)可以是健康受试者,或更典型地是病理学受试者。
[0635]
受试者可以任选地是男性,如男性人类。
[0636]
受试者可以任选地是女性,如女性人类。
[0637]
例如,受试者可以是成人、青少年、少年、儿童、婴儿、新生儿、胎儿或胚胎;如人类成人、人类青少年、人类少年、人类儿童、人类婴儿、人类新生儿、人类胎儿或人类胚胎。
[0638]
例如,受试者可以是小于1个月、2个月、3个月、4个月、5个月、6个月、7个月、8个月、9个月、10个月、11个月或12个月大的人类婴儿。
[0639]
受试者可以是例如年龄为至少或大于1岁的人(例如男性和/或女性),例如,至少或大于2岁、3岁、4岁、5岁、6岁、7岁、8岁、9岁、10岁、11岁、12岁、13岁、14岁、15岁、16岁、17岁、18岁、19岁或20岁;并且任选地小于100岁、90岁、85岁、80岁、75岁、65岁、60岁、55岁、50岁、45岁或40岁。
[0640]
受试者可以是例如年龄为至少或大于20岁的人(例如男性和/或女性),例如,至少或大于25岁、30岁、35岁、40岁、45岁、50岁、55岁、60岁、65岁、70岁、75岁或80岁;并且任选地
小于100岁、90岁或85岁。
[0641]
病理学受试者可以是患有病理学病状、已经被诊断为患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、之前已经针对病理学病状接受过治疗和/或之前曾患有病理学病状的受试者(如人类受试者)。
[0642]
在包括来自病理学受试者的生物材料的组织学样本的情况下,组织学样本可以含有或疑似含有包括受试者中存在的病理学病状的生物材料。此类病理学包含但不限于本技术的第2.3节中讨论的那些病理学,并且在优选的实施例中,病理学病状可以是癌症的一种形式,例如本技术的第2.3.1节中讨论的癌症类型。
[0643]
例如,受试者可以是之前没有被诊断出患有所关注的病理学病状(包含但不限于癌症)但是例如希望知道他们是否患有该病理学病状和/或是否处于患有或进展为该病理学病状的风险中的受试者。
[0644]
受试者可以例如是患有所关注的病理学病状(包含但不限于癌症)并且例如希望获得有关病理学病状的进一步信息,以例如确定他们的预后和/或帮助就该病理学病状的未来治疗的需求、性质和/或潜在益处做出决定的受试者。
[0645]
例如,受试者可以是已被诊断为患有所关注的病理学病状(包含但不限于癌症)并且已经接受了针对该病理学病状的一种或多种治疗(例如,如上文本技术的第2.3.2节中所讨论的)的受试者,所述受试者希望了解他们是否仍然患有病理学病状和/或获得有关在受试者体内先前治疗过病理学病状的部位或受试者体内任何其它部位的生物材料的进一步信息,以例如确定他们的预后和/或帮助就该病理学病状的未来治疗的需求、性质和/或潜在益处做出决定。
[0646]
例如,在病理学病状是癌症的情况下,样本可以取自:
[0647]
·
之前没有被诊断出患有癌症但例如希望知道他们是否患有癌症的受试者;
[0648]
·
已被诊断为患有癌症并且例如希望获得有关癌症的进一步信息,以例如确定他们的预后和/或帮助就该癌症的未来治疗的需求、性质和/或潜在益处做出决定的受试者;和/或
[0649]
·
已被诊断为患有癌症并且已经接受了针对该癌症的一种或多种治疗的受试者,所述受试者希望了解他们是否仍然患有癌症和/或获得有关在受试者体内先前治疗过癌症的部位或受试者体内任何其它部位的生物材料的进一步信息,以例如确定他们的预后和/或帮助就该癌症的未来治疗的需求、性质和/或潜在益处做出决定。
[0650]
充当根据本发明使用的组织学样本中存在的生物材料的来源的受试者(如人类受试者)可以是具有和/或已经确定具有患病理学病状(包含但不限于癌症)的风险(例如高于平均风险)的受试者。
[0651]
癌症上下文中的已知风险因素包含但不限于年龄、饮酒、接触致癌物质、慢性炎症、饮食、激素、免疫抑制、传染原、肥胖、辐射、阳光和烟草。充当根据本发明使用的组织学样本中存在的生物材料的来源的受试者(如人类受试者)可以是具有和/或已经确定具有基于上述一种或多种风险因素的患癌风险的受试者。
[0652]
高龄是总体癌症和许多个体癌症类型最重要的风险因素之一。根据nci监测、流行病学和最终结果项目的最新统计数据,癌症诊断的中位年龄为66岁。这意味着一半的癌症病例发生在这个年龄以下的人身上,一半发生在这个年龄以上的人身上。四分之一的新癌
症病例是在65到74岁的人群中诊断出来的。在许多常见的癌症类型中也可以看到类似的模式。例如,诊断时的中位年龄是乳腺癌61岁,结肠直肠癌68岁,肺癌70岁,前列腺癌66岁。因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是年龄为至少或超过50岁、55岁、60岁、65岁、70岁、75岁或80岁的人(例如男性和/或女性);并且任选地小于100岁、90岁或85岁;例如,年龄为50到85岁、60到85岁、65到85岁或65到75岁。
[0653]
但癌症可能发生在任何年龄。例如,骨癌最常在20岁以下的人群中被诊断出来,超过四分之一的病例发生在这个年龄段。10%的白血病是在20岁以下的儿童和青少年中被诊断出来的,而总体上只有1%的癌症是在该年龄组中被诊断出来的。一些类型的癌症,如神经母细胞瘤,在儿童或青少年中比在成人中更常见。
[0654]
烟草使用是癌症和癌症死亡的主要原因。使用烟草产品或经常接触环境烟草烟雾(也被称为二手烟)的人患癌症的风险增加,因为烟草产品和二手烟含有许多会破坏dna的化学物质。烟草使用会导致多种癌症,包含肺癌、喉癌(声匣)、口腔癌、食道癌、咽喉癌、膀胱癌、肾癌、肝癌、胃癌、胰腺癌、结肠癌和直肠癌以及子宫颈癌,以及急性髓细胞性白血病。使用无烟烟草(鼻烟或咀嚼烟草)的人患口腔癌、食道癌和胰腺癌的风险增加。因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是具有烟草使用史(包含接触烟草,如二手烟)的人(例如男性和/或女性)。
[0655]
饮酒会增加患癌症的风险,例如口腔癌、咽喉癌、食道癌、喉癌(声匣)、肝癌和/或乳腺癌。受试者喝的酒越多,他们的风险就越高。饮酒和吸烟的人患癌症的风险要高得多。因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是具有饮酒史(通常高于平均饮酒量)和/或烟草使用的人(例如男性和/或女性)。
[0656]
激素水平会影响患癌症的风险。例如,雌激素,一组女性性激素,是已知的人类致癌物。尽管这些激素在女性和男性中都具有重要的生理作用,但它们也与某些癌症的风险增加有关。例如,服用更年期激素联合疗法(雌激素加孕激素,它是女性激素黄体酮的合成版本)会增加女性患乳腺癌的风险。单独使用雌激素进行更年期激素疗法会增加患子宫内膜癌的风险,并且仅用于接受过子宫切除术的女性。研究还表明,女性患乳腺癌的风险与卵巢产生的雌激素和孕激素(被称为内源性雌激素和孕激素)有关。长时间接触和/或接触高水平的这些激素与乳腺癌风险增加有关。接触增加的原因可能是月经提前开始、绝经晚、第一次怀孕时年龄较大以及从未生育过。相反,生育可能是乳腺癌的保护因素。
[0657]
己烯雌酚(des)是一种雌激素,其在1940年至1971年间在美国被给予一些孕妇,以预防流产、早产和相关的妊娠问题。在怀孕期间服用des的女性患乳腺癌的风险增加。他们的女儿患阴道癌或子宫颈癌的风险增加。正在研究对怀孕期间服用了des的女性的子孙可能产生的影响。
[0658]
因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是具有相关激素风险因素的人(例如男性和/或女性)。
[0659]
接受免疫抑制的受试者患癌症的风险也可能增加。例如,器官移植受者通常接受免疫抑制药物。免疫抑制药物使免疫系统无法检测和破坏癌细胞或抵抗导致癌症的感染。感染hiv和其它免疫抑制病原体也会削弱免疫系统并增加患某些癌症的风险。
[0660]
移植受者中最常见的四种癌症是非霍奇金淋巴瘤(nhl)以及肺癌、肾癌和肝癌,这些癌症在这些个体中比在普通人群中更常见。nhl可由爱泼斯坦-巴尔病毒(ebv)感染引起,
并且肝癌可由乙型肝炎(hbv)和丙型肝炎(hcv)病毒慢性感染引起。通常认为肺癌和肾癌与感染无关。
[0661]
感染hiv/aids的人患由传染原引起的癌症的风险也会增加,所述传染原包含ebv;人疱疹病毒8或卡波西肉瘤相关病毒;hbv和hcv,其导致肝癌;和人乳头瘤病毒,其导致宫颈癌、肛门癌、口咽癌和其它癌症。hiv感染还与如肺癌等癌症的风险增加有关,这些癌症被认为不是由传染原引起的。
[0662]
因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是免疫抑制的人(例如男性和/或女性)。
[0663]
接触某些传染原,包含病毒、细菌和寄生虫,会导致癌症或增加癌症形成的风险。一些病毒会破坏通常控制细胞生长和增殖的信号传导。此外,一些感染会削弱免疫系统,使身体抵抗其它致癌感染的能力降低。而一些病毒、细菌和寄生虫也会引起慢性炎症,从而可能导致癌症。大多数与癌症风险增加有关的病毒都可以通过血液和/或其它体液从一个人传染给另一个人。可导致癌症或增加癌症风险的示例性传染原包含:爱泼斯坦-巴尔病毒(ebv)、乙型肝炎病毒和丙型肝炎病毒(hbv和hcv)、人免疫缺陷病毒(hiv)、人乳头瘤病毒(hpv)、人t细胞白血病/淋巴瘤病毒1型(htlv-1)、卡波西肉瘤相关疱疹病毒(kshv)、默克尔细胞多瘤病毒(mcpyv)、幽门螺杆菌(h.pylori)、泰国肝吸虫(opisthorchis viverrini)和血吸虫(schistosoma hematobium)。
[0664]
因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是患有可能导致癌症或增加癌症形成风险的传染原感染(无论是否实际诊断)、疑似患有所述传染原感染、正在针对所述传染原感染接受治疗、已经针对所述传染原感染接受过治疗和/或之前曾患有所述传染原感染的人(例如男性和/或女性)。
[0665]
肥胖的人患多种癌症的风险可能增加,包含乳腺癌(绝经期妇女)、结肠癌、直肠癌、子宫内膜癌(子宫内膜)、食道癌、肾癌、胰腺癌和胆囊癌。因此,在本公开的一个实施例中,病理学病状是癌症并且受试者是肥胖的人(例如男性和/或女性)。
[0666]
在本公开的另一个实施例中,病理学病状是癌症并且受试者是具有并且任选地已经确定具有癌症遗传风险因素的人(例如男性和/或女性)。例如,遗传风险因素可以通过遗传性的遗传特征或获得性的遗传特征。许多类型的遗传风险因素在本领域是众所周知的,例如但不限于林奇综合征(lynch syndrome)、brca基因、视网膜母细胞瘤基因等。
[0667]
2.4组织学样本的制备
[0668]
本领域技术人员熟知本领域公知的用于从获自生物来源的生物材料制备组织学样本的多种技术。用于制备组织学样本的任何合适的方法都可以用于本发明的上下文中。
[0669]
例如但不限于,对于待检查的样本(例如通过光学显微术和/或wsi成像),通常使用三种技术:石蜡技术、冷冻切片和半薄切片。
[0670]
石蜡技术是最常用的。在这种技术中,组织被固定并嵌入蜡中。这使组织变硬,并且更容易从中切割切片。然后对切片进行染色,以帮助区分组织的组分。
[0671]
固定涉及生物样品的化学固定。添加的化学物质与一些蛋白质结合并交联,并通过脱水使其它蛋白质变性。这会使组织变硬,并使原本可能降解组织的酶失活。固定还可以杀灭细菌等,并且还可以增强组织染色。常见的固定剂是4%的甲醛水溶液,ph为中性。另一种常见的选项是福尔马林固定石蜡包埋的(ffpe)组织样本,几十年来一直是研究和治疗应
用的主要内容。
[0672]
固定后,样品通常经过脱水和清除、包埋、切片、染色和固定等步骤。
[0673]
脱水和清除:为了切割切片,可能需要将固定的生物样品包埋在石蜡中,但蜡不溶于水或酒精。但是,它可溶于溶剂,如二甲苯。因此,组织中的水可以用溶剂代替。为此,首先将组织脱水,例如,通过逐渐用酒精代替样品中的水。例如,这可以通过使组织通过增加浓度的乙醇(从0到100%)来实现。最后,一旦水被100%酒精取代,酒精就会被与酒精混溶的溶剂(例如二甲苯)取代。最后一步被称为“清除”。
[0674]
在脱水和清除步骤之后,通常用嵌入步骤处理样品。例如,可以将组织置于温热的石蜡中,让熔化的石蜡填充曾经有水的空间。冷却后组织变硬,并且可用于切割切片(切片)。
[0675]
对于切片步骤,组织被修剪,并安装在切割装置(例如切片机或超切片机)上。切成薄切片,可以将薄片染色并安装在显微镜载玻片上。在此上下文中,“薄”切片可以包含大约一个细胞的深度或更小的切片。通常,取自动物或人类生物来源的样品中的细胞的直径可以为例如10-15μm,并且薄切片的厚度可以相同或更小,如厚度为5-10μ。
[0676]
在一个选项中,可能需要切割生物材料的多个物理分离的(通常是连续平行或基本平行的)薄片,以便获得源组织学图像的集合,这些图像一起可以形成三维源组织学图像。
[0677]
在另一个选项中,可能需要切割厚切片,可以将其染色并安装在显微镜载玻片上,并且可以通过厚切片内的多个平面中的选择性聚焦技术从所述厚切片获得多个图像(例如,连续平行或基本平行的图像)。选择性聚焦技术在本领域中是已知的,例如mir等人,2014:“数字摄影聚焦测量的广泛经验评估(an extensive empirical evaluation of focus measures for digital photography)”,spie会议记录-国际光学工程学会9023(可在线获取:https://cs.uwaterloo.ca/~vanbeek/publications/spie2014.pdf)和hosseini等人,于2018年提交给ieee以供发表:“数字病理学中高通量完整载玻片成像的焦点质量评估(focus quality assessment of high-throughput whole slide imaging in digital pathology)”(可在线获取:https://arxiv.org/pdf/1811.06038.pdf),两者的内容均通过引用并入本文。
[0678]
在此上下文中,“厚”切片可以包含厚度大于一个单元的深度的切片,例如至多2个、3个、4个、5个、6个、7个、8个、9个、10个、20个、30个、40个、50个、60个、70个、80个、90个、100个或更多个细胞的深度。如上所述,取自动物或人类生物来源的样品中的细胞通常直径为例如10-15μm。因此,在此上下文中,厚切片的厚度可能大于10μm、15μm、20μm、25μm、30μm、40μm、50μm、60μm、70μm、80μm、90μm、100μm、150μm、200μm、250μm、300μm、400μm、500μm或更多。例如,在通过厚切片内的多个平面中的选择性聚焦技术获得多个连续平行或基本平行图像的情况下,这是可以提供源组织学图像的集合的另一种方式,这些图像一起可以形成三维源组织学图像。
[0679]
染色和安装:不幸的是,大多数染色溶液都是水性的,因此为了对切片进行染色,蜡可能需要溶解并用水代替(再水化)。这基本上是相反的脱水和清除步骤。使切片通过蜡溶剂(例如二甲苯),然后降低酒精浓度(100%到0%),最后是水。一旦染色,可以将切片再次脱水,并置于溶剂(例如二甲苯)中。然后可以将其安装在溶解在溶剂中的封固剂中的显
微镜载玻片上。可以将盖玻片放在顶部,以保护样品。可能允许在盖玻片的边缘周围蒸发溶剂(例如二甲苯),这会干燥封固剂并将盖玻片牢固地粘合到载玻片上。
[0680]
用于制备组织学样本的替代方法包含但不限于制备冷冻切片和半薄切片。
[0681]
对于冷冻切片的生产,将组织快速冷冻(例如在液氮中),然后在冷的情况下切割(例如在冷的冷藏柜(低温恒温器)中用冷刀切割),然后进行染色以准备观察。这个过程更快,并且可以保留一些可能被石蜡技术丢失的组织细节。冷冻切片的厚度通常为5-10μm,但可以为所需的目标选择任何合适的厚度,包含上述任何厚度。
[0682]
半薄切片在很难看到厚切片细节的情况下可能很有用。为了解决这个问题,可以将切片嵌入环氧树脂或丙烯酸树脂中,这样可以切割更薄的切片(例如小于2μm)。
[0683]
2.4.1染色组织学样本
[0684]
组织学图像或组织病理学图像可以通过对组织学或组织病理学样本进行适当染色来制备,如上所述。在微观尺度上,细胞的许多有趣特征并不是自然可见的,因为它们是透明无色的。为了揭示这些特征,在显微镜下成像之前,通常会用标志物对样本进行染色。所述标志物包含一种或多种着色剂(染料或颜料),这些着色剂被设计成与细胞结构的特定组分特异性结合,从而揭示所关注的组织学特征。本领域技术人员熟知本领域众所周知的多种染色技术。用于染色组织学样本的任何合适的方法都可以用于本发明的上下文中。非限制性地,可适用于本发明的此类染色技术在下文中进一步讨论。
[0685]
所使用的技术可以是非特异性的,以几乎相同的方式对大多数细胞进行染色,也可以是特异性的,选择性地对细胞或组织内的特定化学组或分子进行染色。通常通过使用一种染料将一些细胞组分染成第一种颜色,同时使用一种或多种复染剂将细胞的其余部分染成一种或多种不同的颜色来进行染色。
[0686]
例如,染色技术可以使用嗜碱性和嗜酸性染色。
[0687]
酸性染料(例如伊红)与细胞中的阳离子或碱性组分发生反应。大多数蛋白质和细胞质中的许多其它组分都是碱性的,并且将与酸性染料结合。这包含例如肌肉细胞中的细胞质细丝、细胞内膜和细胞外纤维。
[0688]
碱性染料(例如苏木精)与细胞中的阴离子或酸性组分发生反应。核酸是酸性的,并且因此与碱性染料结合。例如,细胞核中的dna(异染色质和核仁)、核糖体和粗面内质网中的rna都是酸性的,因此与碱性染料结合。一些细胞外物质(例如软骨中的碳水化合物)也会与碱性染料结合。
[0689]
为了本发明的目的,在一个优选实施例中,所使用的染色剂是一种被称为h&e(苏木精和伊红)的染色系统。h&e含有苏木精和伊红两种染料。伊红是一种酸性染料:它带负电荷,可将碱性(即嗜酸性)结构染成红色或粉红色。这有时也被称为“嗜酸性粒细胞”。苏木精可以被认为是一种碱性染料,并且其用于将酸性(即嗜碱性)结构染成紫蓝色。因此,当用h&e系统对组织学样品进行染色时,细胞核和含有rna的部分细胞质通常会被染成一种颜色(紫色),而细胞质的其余部分通常会被染成不同的颜色(粉红色)。
[0690]
然而,应当理解,本发明不限于任何特定染色技术的使用。例如,许多其它酸性和碱性染料在本领域中是已知的。实例如下表所示:
[0691]
h&e以外的示例性组织学染色可以包含:
[0692][0693][0694]
对于碱性染料,细胞的阴离子基团(这些包含核酸的磷酸基团、糖胺聚糖的硫酸基团和蛋白质的羧基)的反应可能取决于它们被使用时的ph。
[0695]
对于酸性染料,所讨论的染料通常可以另外对特定的嗜酸性组分具有选择性。例如,著名的马洛里染色技术(mallory staining technique)使用三种酸性染料:苯胺蓝、酸性品红和橙黄g,它们分别选择性地染色胶原蛋白、细胞质和红细胞。
[0696]
如本文所考虑的,用于本发明的另外的染色技术包含:
[0697]
高碘酸-席夫反应(pas),其中席夫试剂是与醛基反应的漂白碱性品红。该反应导致切片呈深红色。它是pas染色的基础。pas将碳水化合物和富含碳水化合物的大分子染成深红色(洋红色)。因此pas会染色:糖原,其是碳水化合物在细胞内的细胞内储存形式;细胞和组织中的粘液;基底膜、肾小管和小肠和大肠的刷状缘结缔组织和软骨中的网状纤维(即胶原蛋白)。
[0698]
马森三色(masson's trichrome),其通常用于结缔组织染色。术语“三色”意味着该技术产生三种颜色。细胞核和其它嗜碱性结构被染成蓝色,细胞质、肌肉、红细胞和角蛋白被染成鲜红色。胶原蛋白可能被染成绿色或蓝色,这取决于所使用的技术的变型。
[0699]
阿尔新蓝是一种粘蛋白染色剂,其染色某些类型的粘蛋白蓝。软骨也被染成蓝色。它可以与其它染色系统(如h&e)和van gieson染色剂一起使用。
[0700]
van gieson技术将胶原蛋白染成红色,将细胞核染成蓝色,并且将红细胞和细胞质染成黄色。它也可以与将弹性蛋白染成蓝色/黑色的弹性蛋白染色剂结合使用。它常用于血管和皮肤。
[0701]
网状蛋白染色技术将网状蛋白纤维染成蓝色/黑色。它可以与其它染色技术一起使用,例如h&e
[0702]
偶氮卡红染色导致细胞核被染成鲜红色,胶原蛋白、基底膜和粘蛋白被染成蓝色,并且肌肉和红细胞被染成橙色至红色。这种技术特别适用于结缔组织和上皮的染色。
[0703]
吉姆萨(giemsa)染色技术通常用于染色血液和骨髓涂片。细胞核被染成深蓝色至紫色,细胞质被染成淡蓝色,红细胞被染成淡粉色。
[0704]
甲苯胺蓝是一种碱性染料,其将酸性组分染成各种深浅的蓝色。它通常用于薄的丙烯酸或环氧树脂切片。
[0705]
银和金方法可用于展示精细结构,如神经元中的细胞过程。这种技术会产生黑色、
棕色或金色的污渍。
[0706]
铬明矾/苏木精是一种不太常用的技术,其将细胞核染成蓝色,并将细胞质染成红色。它可能对来自胰腺的样品特别有用,其中胰高血糖素分泌细胞被染成粉红色,并且胰岛素分泌细胞被染成蓝色。
[0707]
艾沙明蓝/伊红是一种类似于h&e的染色技术,但蓝色更强烈。
[0708]
尼氏和亚甲蓝是一种染色技术,例如,可用作碱性染料来染色神经元中的粗面er。
[0709]
苏丹黑和锇是染色含脂质结构(如髓磷脂)的一种棕黑色染料。
[0710]
也可以使用免疫组织化学(ihc)技术(单独或与任何一种或多种前述技术组合)。免疫组织化学技术在本领域中是众所周知的。通常,使用对蛋白质(或其它特异性靶标)进行特异性标记的一抗,然后可以使用标记的二抗(例如荧光标记的)与一抗结合,以显示第一抗体(一抗)已结合的位置。可以通过任何合适的方式检测标记。例如,在使用荧光标记抗体的方法的情况下,可以使用配备有荧光的光学显微镜(或等效成像设备)来将染色可视化。荧光抗体在一种波长的光下被激发,然后它们发出不同波长的光。使用正确的滤光片组合,可以观察到由发射的荧光产生的染色图案。
[0711]
在对含有或疑似含有癌症的样品进行成像的上下文中,ihc技术可能会越来越有用。在此类技术中,一抗可以例如靶向肿瘤标志物。肿瘤标志物是分子,其水平被认为是肿瘤细胞的信号、符号或表示,并且在癌症条件下可能会增加。肿瘤标志物可以包含但不限于蛋白质、基因表达模式和dna变化。通过ihc可视化的肿瘤标志物可以包含酶、癌基因、肿瘤特异性抗原、肿瘤抑制基因和肿瘤增殖标志物等。
[0712]
3.地面真值
[0713]
如在本技术的第1节中更详细地讨论并且由本权利要求书进一步定义的,本技术描述了用于确定用于源组织学图像(102;202;302)的分类器(118;318)或总体分类器(232;332)的计算机实施系统(100;200;300),所述源组织学图像可以是源组织病理学图像。
[0714]
还如在本技术的第2节中更详细讨论的,在训练阶段,其中系统(100;200;300)可用于训练系统(100;200;300)内的机器学习算法,用于训练的源组织学图像是从已知地面真值的来源获得的组织学样本的图像。然后将每个源组织学图像用相关联的真值数据标记,这些真值数据表示从中获得每个组织学样本的每个来源的地面真值。
[0715]
在此上下文中,“地面真值”可以是与所述或每个源组织学图像相关联的任何所关注的信息。可以与每个图像相关联的任何有用的度量都可以用作“地面真值”。应当理解,地面真值的选择是确定随后训练的机器学习算法的功能和效用的重要特征。
[0716]
例如,使用组织病理学样本的源组织病理学图像进行训练的算法,其中与每个图像相关的地面真值是对特定病理学病状的已知诊断(例如,存在或不存在),以及随后经过训练的算法将适用于从未知诊断的受试者(“测试受试者”)获取的组织学样本的显微图像中诊断该病理学病状(和/或患该病理学病状的风险),因此也将适用于在测试受试者的病理学病状的诊断中使用。
[0717]
在另一个实例中,使用组织病理学样本的源组织病理学图像进行训练的算法,其中与每个图像相关的地面真值可能是对特定病理学病状的已知预后,以及随后经过训练的算法将适用于从未知预后的受试者(“测试受试者”)获取的组织学样本的显微图像中预知该病理学病状,因此也将适用于在测试受试者的预后中使用。
[0718]
在本文所述的实例中,组织学样本获自癌症患者,以及与将每个患者分类为预后组相关的地面真值。
[0719]
在本文所述的一个实施例中,组织学样本可获自患有一种或多种癌症的患者,以及与每个患者内存在的癌症的分期和/或等级的分类相关的地面真值,具体地说,其中所述分期和/或等级与定义的预后相关。
[0720]
例如,随后经过训练的算法可随后适用于自动鉴定取自一个或多个癌症分期和/或等级未确定和/或预后未知的受试者(“测试受试者”)的组织学样本的显微图像中存在的癌症的分期和/或等级,因此也可以任选地用于测试受试者中癌症的预后。
[0721]
在另外或可替代的选项中,随后经过训练的算法可以适用于自动和直接预测测试受试者中的癌症特异性预后(例如生存期),并且任选地用于通过鉴定可能具有良好预后并因此可能不会从进一步治疗中受益的低风险受试者和/或鉴定更有可能从进一步疗法中受益的高风险受试者而做出一个或多个进一步治疗决定(如决定进行进一步治疗和/或选择治疗类型),如更强化的治疗方案。
[0722]
任选地,一个或多个组织学样本可以来自一个或多个已经接受癌症手术治疗(例如肿瘤切除术)的测试受试者,并且所述经过训练的算法可以用于自动和直接预测测试受试者中的癌症特异性预后(例如生存期),并且任选地用于做出一个或多个进一步的辅助治疗决定。
[0723]
本文所述的任何癌症都可以适当地评估,但特别关注的癌症是如本文所例示的结肠直肠癌。
[0724]
更一般地,举例来说,训练阶段可以涉及使用包括从健康受试者和/或从病理学受试者(其可以包含但不限于本技术的第2.3节中讨论的那些病理学,并且在特别关注的实施例中,可以是如本技术的第2.3.1节中讨论的癌症的一种形式)获得的生物材料的组织学样本的源组织学图像,其中与每个源组织学图像相关联的地面真值是已知的并且可以在训练阶段期间提供给系统(100;200;300),所述系统用于训练系统(100;200;300)内的机器学习算法。
[0725]
与每个源组织学图像相关联的地面真值完全由用户自行决定,并且不受本发明的限制。
[0726]
然而,例如,在涉及源自病理学受试者的源组织病理学图像的训练阶段的上下文中,则地面真值可以任选地选自以下一项或多项:
[0727]
(a)受试者是否存在病理学病状;
[0728]
(b)受试者的病理学病状的类型、等级和/或分期(例如区分癌症的不同分期和/或等级);
[0729]
(c)定义的事件后一段时间内受试者病理学病状的进展(或无进展);
[0730]
(d)受试者在定义的事件后的生存期(通常不包括与特定病理学病状无关的任何死亡);和/或
[0731]
(e)受试者的病理学病状在针对该病理学病状的任何早期治疗(例如手术或非手术治疗)后复发(或不复发);
[0732]
其中“定义的事件”可以是例如从创建源组织学图像的受试者获取生物材料的时间,或针对该病理学病状的一些先前治疗(例如手术或非手术治疗,如本技术的第2.3.2节
中讨论的治疗)的时间。
[0733]
任选地,病理学病状可以是本技术的第2.3节中所述的病状,例如本技术的第2.2节中所述的组织、器官或其它身体部位中的病状。在一个特别关注的实施例中,病理学病状可以是癌症,如本技术的第2.3.1节中所述的癌症,例如实体癌(例如癌),其代表性实例是如实例中所示的crc。任选地,当病理学病状是癌症时,“定义的事件”可以是一些先前的癌症治疗的时间,如本技术的第2.3.2节中定义的治疗,例如手术(如肿瘤的手术切除)。
[0734]
定义的事件之后的时间段可以是任何所关注的时间段。在一个实施例中,其可以在0到24小时之间,如约1小时、2小时、3小时、4小时、5小时、6小时、7小时、8小时、9小时、10小时、11小时、12小时、13小时、14小时、15小时、16小时、17小时、18小时、19小时、20小时、21小时、22小时、23小时或24小时。在另一个实施例中,其可以在0到28天之间,如约1天、2天、3天、4天、5天、6天、7天、8天、9天、10天、11天、12天、13天、14天、15天、16天、17天、18天、19天、20天、21天、22天、23天、24天、25天、26天、27天或28天。在另一个实施例中,其可以在0到12个月之间,如约1个月、2个月、3个月、4个月、5个月、6个月、7个月、8个月、9个月、10个月、11个月或12个月。在另一个实施例中,其可以是1年或更多年,和/或0到20年之间,如0到10年、0到9年、0到8年、0到7年、0到6年、0到5年、0到4年、0到3年或0到2年,例如约1年、2年、3年、4年、5年、6年、7年、8年、9年、10年、11年、12年、13年、14年、15年、16年、17年、18年、19年或20年。
[0735]
因此,在一个实施例中,在涉及源自病理学受试者的源组织病理学图像的训练阶段的上下文中,则地面真值是在定义的事件之后的一段时间内,受试者的病理学病状(如癌症)的进展(或无进展),所述定义的事件选自从创建源组织学图像的受试者获取生物材料的时间,或针对该病理学病状的一些先前治疗的时间,并且其中时间段是如上所述的时间段。
[0736]
在另一个实施例中,在涉及源自病理学受试者(如患有癌症的受试者)的源组织病理学图像的训练阶段的上下文中,则地面真值是受试者在定义的事件之后的生存期,其中所述定义的事件被选择为从创建源组织学图像的受试者获取生物材料的时间,或针对该病理学病状(如癌症)的一些先前治疗的时间,并且其中时间段是如上所述的时间段。
[0737]
在使用组织病理学样本的源组织病理学图像训练算法的情况下,其中与每个图像相关联的地面真值是特定病理学病状(如癌症)的已知预后,则可能需要考虑到地面真值预后,例如:
[0738]
(i)在定义的时间段内任何病理学病状特异性(例如癌症特异性)的死亡;和/或
[0739]
(ii)在规定的时间段内受试者的病理学病状(例如癌症)的复发。
[0740]
(i)和(ii)的定义的时间段可以相同或不同。
[0741]
它可能适合于与地面真值相关的真值数据来代表地面真值的“类别”。例如:
[0742]-任何通过第一预定义阈值的地面真值预后信息(例如,病理学病状特异性生存期长于第一预定时段和/或病理学病状在第二预定时段内不复发)都可以被认为与作为该样品的真值数据的“良好预后”相关联;
[0743]-任何未能通过第二预定义阈值的地面真值预后信息(例如,病理学病状特异性生存期少于第三预定时段和/或病理学病状在第四预定时段内复发)都可以被认为与作为该样品的真值数据的“不良预后”相关联;
[0744]-并且进一步地,第一和第二预定义阈值可以相同或不同,并且当它们不同时,第三类真值数据是可能的,其中地面真值预后信息通过第二预定义阈值但未通过第一预定义阈值,并且这可以被认为与作为该样品的真值数据的“非明显预后”相关联。
[0745]
在本文所述的训练实例中,组织学样本获自癌症患者,以及与将每个患者分类为预后组相关的地面真值。明显预后组患者包括预后良好、不良或不明显的患者。如果患者在手术时年龄小于85岁,术后随访时间超过6年,没有癌症特异性死亡记录,并且在这6年内也没有复发记录,则被定义为具有良好预后。如果患者在手术时年龄小于85岁并且如果他们在手术后100天(含端值)和2.5年(不含端值)之间发生癌症特异性死亡,则被定义为具有不良预后。不满足这些标准中的任何一个的患者被归类为非明显预后组。
[0746]
4.本发明系统的应用
[0747]
还如上所述,本发明的计算机实施系统(100;200;300)可用于处理一个或多个源组织学图像(102;202;302),如一个或多个源组织病理学图像,其结果(“地面真值”)未知。
[0748]
在这种情况下,系统可以应用使用训练组织学图像(如训练组织病理学图像)配置的机器学习算法,使得系统的输出是用于接收到的源组织学图像102的分类器(118;318),和/或总体分类器(232;332)。
[0749]
应当理解,分类器和/或总体分类器的性质将取决于在训练期间使用的地面真值的性质,如在本技术的第3节中进一步讨论的。
[0750]
例如,分类器和/或总体分类器可以针对从中获得组织学图像的受试者给出诊断或预后确定。
[0751]
因此,本发明还提供了一种通过如上文进一步描述的本发明的方法处理一个或多个组织学图像的计算机实施方法,其中所述方法是针对受试者产生诊断和/或预后确定的方法,其中所述方法包括接收从一个或多个获自所述受试者的组织学样品获得的一个或多个源组织学图像(202;302),并且其中所述方法包括:
[0752]
如上文进一步描述的确定用于根据本发明的一个或多个源组织学图像(102;302)的分类器(118;318);和/或如上文进一步描述的确定用于根据本发明的一个或多个源组织学图像(202;302)的总体分类器(232;332),以及
[0753]
任选地,将诊断和/或预后评估归因于所述分类器和/或总体分类器。
[0754]
受试者可以是任何生物来源,如本技术的第2.1节中描述的生物来源,并且在一个优选的实施例中是人。
[0755]
一个或多个组织学样品可以从患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、已经针对病理学病状接受过治疗和/或曾患有病理学病状的受试者获得,例如,如本技术的第2.3节所述的病理学病状。在一个特别关注的实施例中,病理学病状是癌症,如在本技术的第2.3.1节中进一步描述的癌症。
[0756]
一个或多个组织学样品可以从任何组织类型、器官或其它所关注的结构获得,例如,从受试者中的任何组织类型、器官或其它所关注的结构获得,如本技术的第2.2节中所述。
[0757]
任选地,从受试者获得的所述或每个组织学样品获自所述受试者身体的一部分,所述部分患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、已经针对病理学病状接受过治疗和/或之前曾患有病理学病状,例如,如本技术的第2.3节中描述的
病理学病状,并且更具体地说,癌症,如本技术的第2.3.1节中进一步描述的癌症。
[0758]
在一个优选的选项中,所述方法包括评估从获自受试者的多个组织学样品获得的多个源组织学图像(202;302)。任选地,受试者患有如癌症等病理学病状、疑似患有如癌症等病理学病状、正在针对如癌症等病理学病状接受治疗、已经针对如癌症等病理学病状接受过治疗和/或之前曾患有如癌症等病理学病状,并且进一步任选地,多个组织学样品是从受试者体内的多个位置获得的样品,这些位置具有、疑似具有和/或之前曾具有包含病理学病状的生物材料和/或这些位置正在针对如癌症等病理学病状接受治疗和/或已经针对如癌症等病理学病状接受过治疗。例如,其中病理学病状是癌症,多个组织学样品可以包括取自受试者中的同一肿瘤的多个样品或由取自受试者中的同一肿瘤的多个样品组成,在这种情况下,所述方法可以任选地允许评估肿瘤异质性。
[0759]
在一个实施例中,所述方法包括将所确定的分类器(118;318)和/或总体分类器(232;332)与一种或多种用于所关注的病理学病状的另外的诊断和/或预后标志物组合。
[0760]
例如,病理学病状可以是癌症,并且所述方法可以包括将所确定的分类器(118;318)和/或总体分类器(232;332)与一种或多种用于癌症的另外的诊断和/或预后标志物组合。例如,在癌症是crc的情况下,则可以使用在本技术的实例中讨论的一种或多种另外的标志物。
[0761]
在评估此类一种或多种另外的诊断和/或预后标志物的情况下,则将诊断和/或预后评估归因于分类器(118;318)和/或总体分类器(232;332)的步骤可以包含评估所述或每个另外的诊断和/或预后标志物的所述或每个评估结果。
[0762]
例如,在监测正在进行的治疗和/或先前的治疗(如手术和/或疗法)的进展或效果的方法中,和/或在治疗已经被评估的受试者的方法中,这些方法可以用于帮助做出诊断、做出预后、对患者组进行分层、基于分层患者组的诊断和/或预后评估为受试者做出治疗决定。
[0763]
5.治疗方法
[0764]
本发明进一步提供了一种治疗有需要的受试者的方法,其中诊断和/或预后评估已通过根据本发明的方法归因于所述受试者,所述方法包括通过手术和/或疗法的方法治疗所述受试者。
[0765]
换言之,本发明提供了一种外科手术和/或治疗性处理(如包括一种或多种治疗剂的药学上可接受的组合物),用于治疗有需要的受试者的方法,其中诊断和/或预后评估已通过根据本发明的方法归因于所述受试者。
[0766]
此类治疗方法可以包含例如治疗和/或预防方法。这种类型的治疗可以包含,例如,一种或多种治疗形式,如上文本技术的第2.3.2节所讨论的。
[0767]
优选地,已经归因于受试者的诊断和/或预后评估是关于病理学病状,例如本技术的第2.3节中描述的病理学病状。在一个特别关注的实施例中,病理学病状是癌症,如在本技术的第2.3.1节中进一步描述的癌症。
[0768]
受试者可以是任何生物体,如本技术的第2.1节中描述的生物体,并且在一个优选的实施例中是人。
[0769]
所述受试者可以是患有病理学病状、疑似患有病理学病状、正在针对病理学病状接受治疗、已经针对病理学病状接受过治疗和/或曾患有病理学病状的受试者,例如,如本
申请的第2.3节所述的病理学病状。在一个特别关注的实施例中,病理学病状是癌症,如在本技术的第2.3.1节中进一步描述的癌症。
[0770]
因此,治疗方法可以是治疗本技术的第2.3节所述的病理学病状的方法。在一个特别关注的实施例中,病理学病状是癌症,如在本技术的第2.3.1节中进一步描述的癌症。
[0771]
在一个特别关注的实施例中,病理学病状是癌症,并且待治疗的受试者是在通过根据本发明的方法归因于受试者的诊断和/或预后评估之前已经针对癌症进行过治疗(例如通过手术和/或非手术疗法)的受试者。以这种方式,例如,可以对受试者进行分层,并且可以在对所述受试者采用治疗模态之前确定进一步治疗(例如辅助治疗和/或进一步的手术和/或非手术治疗)的可能益处。
[0772]
鉴于诊断和/或预后评估已经被归因于所述受试者,所述治疗方法可以任选地包括调整所述手术和/或非手术疗法的一个或多个参数。任选地,所述手术和/或非手术疗法的所述一个或多个参数选自由以下组成的组:所述手术和/或非手术疗法的性质、所述手术和/或非手术疗法的时机、所述手术和/或非手术疗法的时段、疗法的剂量、所述非手术疗法的施用途径以及所述手术和/或非手术疗法所靶向的身体部位。
[0773]
在一个选项中,受试者的诊断和/或预后评估包含评估早期或正在进行的疗法和/或手术治疗对受试者的影响,例如,以便监测这种治疗的进展和/或效果,并且进一步任选地,其中所述方法包含做出进一步治疗决定的步骤,如停止、继续、重复或修改早期的或正在进行的治疗和/或实施不同的治疗模态,并且进一步任选地包含针对患者实施所述治疗决定的步骤。
[0774]
**************************************************************************
[0775]
本发明由以下实例进一步说明,所述实例不应当解释为限制本发明的范围。
[0776]
实例1
[0777]
方法
[0778]
训练和调整队列
[0779]
本研究使用了四个训练队列,由以下组成:(i)1988年至2000年间在挪威阿克斯胡斯大学医院接受治疗的160名i期、ii期或iii期结肠癌患者,如以下文献所述:bondi等人,《临床病理学杂志(j clin pathol)》,2005;58:509-14;(ii)1993年至2003年间在挪威aker大学医院接受治疗的576名i期、ii期或iii期crc患者,如以下文献所述:danielsen等人,《肿瘤学年鉴》,2018;29:616-23;(iii)1988年至1996年间在英国gloucester结肠直肠癌研究中治疗的970名i期、ii期或iii期crc患者,如以下文献所述:petersen等人,《gut》,2002;51:65-9和mitchard等人,《组织病理学(histopathology)》,2010;57:671-9;以及(iv)2002年至2004年期间在英国victor试验中治疗的767名ii期和iii期crc患者,如以下文献所述:kerr等人,《新英格兰医学期刊》,2007;357:360-9和midgley等人,《临床肿瘤学杂志》,2010;28:4575-80。这些队列是在本技术的第1节中进一步描述。
[0780]
根据手术年龄和随访数据,将患者分为明显或不明显预后组。明显预后组患者包括预后良好或不良的患者。如果患者在手术时年龄小于85岁,术后随访时间超过6年,没有癌症特异性死亡记录,也没有复发记录,则被定义为具有良好预后。如果患者在手术时年龄小于85岁并且在手术后100天(含端值)和2.5年(不含端值)之间发生癌症特异性死亡,则被定义为具有不良预后。不满足这些标准中的任何一个的患者被归类为非明显预后组。
[0781]
训练队列由来自四个队列中828名预后明显的患者的1652个wsi组成,而调整队列由来自1645名预后不明显的患者的3280个wsi组成。wsi由挪威癌症遗传学和信息学研究所(icgi)的实验室人员制备。训练和调整患者的人口统计数据总结在下表1中。
[0782]
测试队列
[0783]
测试队列由在英国切尔滕纳姆(cheltenham,uk)制备的1824个wsi组成,其来自gloucester结肠直肠癌研究中的920名患者。wsi是从不同的福尔马林固定石蜡包埋的(ffpe)肿瘤组织块中获得的,而不是获自在训练和调整队列中使用的那些。测试患者的人口统计数据总结在下表1中。
[0784]
验证队列
[0785]
验证队列由在icgi制备的2234个wsi组成,其来自招募到quasar 2试验的1,122名患者(kerr等人,《柳叶刀》,2016;17:1543-57)。
[0786]
开放标签、随机、对照quasar 2试验(isrctn注册号isrctn45133151)在2005年4月至2010年10月期间从七个国家(澳大利亚、奥地利、捷克共和国、新西兰、塞尔维亚、斯洛文尼亚和英国)170家医院招募了1952名经组织学证实的iii期或高危ii期结肠直肠癌患者,其中1,941人拥有可评估的数据(kerr等人,2016,同上)。
[0787]
该试验旨在调查贝伐单抗是否提高了原发性肿瘤潜在治愈性手术后的无病生存期。所有患者均接受了卡培他滨形式的辅助化疗,但均未接受新辅助治疗。治疗组之间没有观察到显著差异,并且调查人员得出结论,在这种辅助设置中不应使用贝伐单抗添加到卡培他滨(kerr等人,2016,同上)。
[0788]
通过鼓励但不要求初步切除的血液样品和肿瘤样品,从quasar 2试验的1,251名ii期或iii期结肠直肠癌患者中收集ffpe组织块。这些患者在临床和病理学特性方面代表了整个试验人群(kerr等人,2016,同上)。参与试验的医院的病理学家进行了病理学评估。所有患者都提供了治疗和使用组织样品的书面知情同意书。西米德兰兹研究伦理委员会(编号04/mre/11/18)和挪威医学与健康研究伦理区域委员会(rek)(编号2015/1607)批准了该研究。
[0789]
来自1,140名患者的组织块被icgi的实验室人员接收、切片并制备为3μm h&e染色的组织载玻片(图18)。一位对临床结果不知情的当地病理学家确定了每个组织切片中是否存在肿瘤。使用与训练队列相同的两台扫描仪(即aperio at2和nanozoomer xr)获取1,132个肿瘤切片的数字图像。先前开发的分割模型被盲目地应用到自动鉴定肿瘤区域,对1,113名患者进行aperio at2分割并对1,121名患者进行nanozoomer xr分割(图18)。像训练队列一样分块但没有10x图块的载玻片图像可以适合3个aperio at2分割和2个nanozoomer xr分割的自动肿瘤分割(图18)。quasar 2队列被定义为来自aperio at2载玻片图像的40x图块(适用于1,113名患者)、来自aperio at2载玻片图像的10x图块(适用于1,110名患者)、来自nanozoomer xr载玻片图像的40x图块(适用于1,121名患者)和来自nanozoomer xr载玻片图像的10x图块(适用于1,119名患者)。
[0790]
quasar 2队列代表了符合quasar 2试验条件的患者。符合条件的患者必须满足以下所有纳入标准(最初由kerr等人描述,2016,同上):
[0791]-年龄为18岁或以上。
[0792]-结肠直肠腺癌。
[0793]-经组织学证实的r0 m0 iii期或高危ii期结肠直肠癌,其中高危定义为存在以下一种或多种不良预后特征:t4期、淋巴浸润、血管浸润、腹膜受累、分化差原发肿瘤的术前梗阻或穿孔
[0794]-随机分组前4至10周进行初步切除。
[0795]-世界卫生组织(who)表现状态0或1。
[0796]-考虑到合并症,但不包含癌症风险,预期寿命为至少5年。
[0797]
此外,符合条件的患者不能满足以下任何排除标准(最初由kerr等人描述,2016,同上):
[0798]-除了治疗过的宫颈原位癌、基底细胞癌或鳞状细胞癌以外的癌症病史,或者如果在先前的癌症之后的无病间隔超过10年。
[0799]-在过去2年内需要治疗的炎症性肠病和/或活动性消化性溃疡。
[0800]-上消化道缺乏身体完整性、吸收不良综合征或无法口服药物。
[0801]-中度或重度肾功能损害(肌酐清除率《30毫升/分钟)。
[0802]-任何以下血液异常:
[0803]
о中性粒细胞绝对计数《1.5x109/l。
[0804]
о血小板计数《100x109/l。
[0805]
о总胆红素浓度》正常上限(uln)的1.5倍。
[0806]
о丙氨酸氨基转移酶、天冬氨酸氨基转移酶或碱性磷酸酶浓度》正常上限(uln)的2.5倍。
[0807]-蛋白尿》500mg/24小时。
[0808]-既往化疗、免疫治疗或膈下放疗(包含对直肠的新辅助疗法)或预计在未来12个月内需要对这些部位进行放疗的患者。
[0809]-在随机分组的4周内使用任何研究药物或药剂/程序。
[0810]-长期使用全剂量抗凝剂、大剂量阿司匹林(》325mg/天)、抗血小板药物或已知的出血倾向(允许使用低剂量阿司匹林)。
[0811]-与索立夫定(sorivudine)或其化学相关类似物的伴随治疗。
[0812]-有不受控制的癫痫发作、中枢神经系统疾病或精神病史,导致知情同意或干扰口服药物摄入的依从性。
[0813]-临床上显著的心血管疾病,即活动性或自(例如)脑血管意外、心肌梗塞、不稳定型心绞痛、纽约心脏协会(nyha)ii级或更大的充血性心力衰竭、需要药物治疗的严重心律失常或不受控制的高血压以来《12个月。
[0814]-已知的凝血病。
[0815]-已知对中国仓鼠卵巢细胞蛋白或其它重组人或人源化抗体过敏,或对贝伐单抗调配物的任何赋形剂过敏。
[0816]-怀孕或哺乳期妇女,或未采取避孕措施的绝经前妇女。
[0817]
验证患者的人口统计数据总结在下表1中。
[0818]
表1.
[0819][0820][0821]
样品制备
[0822]
用苏木精和伊红(h&e)对3μm ffpe组织块切片进行染色,并且病理学家(m.p.)确定它含有肿瘤。
[0823]
wsi是在两台扫描仪aperio at2(leica biosystems,德国)和nanozoomer xr(hamamatsu photonics,日本)上以可用的最高分辨率(被称为40x)获得的。
[0824]
通过自动分割方法鉴定具有高肿瘤含量的区域(如本技术的第1节所述)。40x分辨率的wsi通常含有100,000x100,000像素的订单,比目前可通过深度学习方法进行分类的图像大多个数量级。为了保留高分辨率的预后信息,wsi被划分为多个非重叠图像区域,被称为10x和40x分辨率的图块,其中40x的每个像素表示约0.24x0.24μm2的物理大小。
[0825]
分类
[0826]
五个卷积神经网络在训练队列中的634,564个10x图块上进行训练,并且五个卷积神经网络在11,591,555个40x图块上进行训练,其中患者的明显预后作为地面真值。所有网
络都是domore v1网络,这是一个用于分类超大异构图像的专用网络,包括mobilenetv2(sandler等人,2018,同上)表示网络、noisy-and池化函数(krauss等人,2016,同上)和全连接的分类网络(图3)。
[0827]
传统的分类网络是在图像上训练的,其中每个图像都有一个相关的标签。一种方法是让每个图块继承其wsi的标签,但由于空间异质性,图块不一定含有反映wsi的预后信息。使用来自多实例学习的想法,我们改为对来自wsi的图块集合进行训练,其中每个集合都标有wsi的标签。使用一种新颖的梯度近似方法,我们能够在训练期间通过增加表示每个wsi的图块的数量来端到端地训练网络。
[0828]
网络经过收敛训练,并在训练进程中的21个等距位置处进行评估,从而导致每次训练运行21个模型。调整队列上模型的性能用于从每次训练运行中选择单个模型,从而针对每个分辨率生成五个模型。
[0829]
为了评估wsi,五个选定模型中的每一个模型都提供了对预后不良概率的预测,并且平均预测概率被定义为集成模型的预测概率。通过评估调整队列确定了两个集成模型(一个用于10x,一个用于40x)中的每一个模型的预测概率的合适阈值,从而导致预测预后良好或不良的两个集成标志物。
[0830]
在测试队列上评估了两个集成标志物和一些其它候选标志物的性能,这导致选择两个集成标志物的组合用于验证队列上的初步分析。如果两个集成标志物预测良好预后,则所述组合(被称为domore-v1-crc标志物)预测良好预后;如果集成标志物的预测不同,则预后不确定;并且如果两个集成标志物预测不良预后,则预后不良;如果由于没有图块而无法分析集成标志物,则预测未定义。
[0831]
初步分析
[0832]
我们针对验证队列中的两个扫描仪预定义了domore-v1-crc标志物(在图2和3中体现为总体分类器(232、332))的初步分析。用于测量模型性能的选定指标是预测为不确定预后的患者和预测为不良预后的患者相对于预测为良好预后的患者的95%置信区间(ci)的风险比(hr),其中这两个hr及其相应的ci是通过分析cox比例风险模型计算得出的,所述模型以domore-v1-crc标志物作为唯一变量(domore-v1-crc标志物作为分类变量被包含在内,即模型由预后不确定和预后不良的两个指标变量组成)并以癌症特异性生存期(css)作为端点(efron的方法用于关联事件)。
[0833]
用于评估domore-v1-crc标志物是否预测css的选定测试是使用显著性水平0.05的双尾mantel-cox对数秩检验。到css的时间是从随机化日期到癌症特异性死亡或失访日期计算的。初步分析是对domore-v1-crc标志物在接受辅助化疗(特别是卡培他滨)并满足quasar2试验的资格标准(如上所述)的目标人群中预测css的能力的无偏评估。
[0834]
统计学分析
[0835]
在对验证队列进行评估之前计划了初步和辅助分析,并在方案中进行了描述。如果在分析时可用并且在css的单变量分析中显著,则将标志物包含在多变量模型中。所有报告的ci的置信水平为95%。双侧p《0.05被认为是统计学上显著的。生存期分析在stata/se 15.1(statacorp,tx)中进行。
[0836]
结果
[0837]
在aperio at2扫描仪(预后预测不确定的患者的hr,1.89;ci,1.14-3.15;预后预
测不良的患者的hr,3.84;ci,2.72-5.43;p《0.0001;图16a)和nanozoomer xr扫描仪(预后预测不确定患者的hr,2.42;ci,1.45-4.03;预后预测不良的患者的hr,3.39;ci,2.36-4.87;p《0.0001;图16b)的验证队列的初步分析中,domore-v1-crc是css的统计学上显著的标志物。下面显示了来自aperio at2扫描仪的结果。基于nanozoomer xr扫描仪的相应分析以及基于10x和40x分辨率水平的两个扫描仪的结果也很重要(数据未显示)。
[0838]
在多变量分析中调整协变量pn分期、pt分期、淋巴浸润和静脉血管浸润后,domore-v1-crc显著预测css(不良与良好预后预测的hr,3.04;ci,2.07-4.47;表2)。domore-v1-crc与许多已确定的预后因素相关,如年龄、pn分期、pt分期、组织学等级、位置、侧向性、braf突变和微卫星不稳定性,但与性别、淋巴浸润、静脉血管浸润或kras突变无关(表3)。
[0839]
表2.使用domore-v1-crc标志物在aperio at2载玻片图像上评估的验证队列中的癌症特异性生存期分析。
[0840][0841]
表3.在aperio at2载玻片图像上评估的domore-v1-crc标志物与验证队列中不同患者特性之间的关联。*
[0842]
[0843][0844]
*由于四舍五入,百分比总和可能不是100。iqr表示四分位距。
[0845]
domore-v1-crc是ii期(不良与良好预后预测的hr,2.71;ci,1.25-5.86;图16c)和iii期(不良与良好预后预测的hr,4.09;ci,2.77-6.03;图16d)css的重要预测因子。
[0846]
它还显著鉴定了在iiia期、iiib期和iiic期(数据未显示)以及按pn分期(图16e和未显示的附加数据)或pt分期(pt1-3对比pt4;图16f和未显示的附加数据)分层时癌症死亡风险增加的患者。二元domore-v1-crc标志物提供的hr与普通domore-v1-crc标志物的不良与良好预后预测的hr接近相同(数据未显示)。
[0847]
inception v3是最先进的卷积神经网络,并且使用与domore-v1-crc相同的研究设置进行训练、调整和评估(参见本技术的第1节中的讨论),并提供了具有统计学意义的css标志物,其性能仅比domore-v1-crc稍差(数据未显示)。
[0848]
在来自另一家医院制备的新肿瘤块的切片的测试队列中,domore-v1-crc显著鉴定癌症死亡风险增加的患者(不良与良好预后预测的hr,4.83;ci,3.27-7.12;图17a)。
[0849]
当在ii期和iii期分析domore-v1-crc时,实验室制备的稳健性也很明显(图17c-d)。二分法domore-v1-crc还提供了css的重要预测因子(图17b)。
[0850]
重要的是要记住,quasar 2验证队列中的所有患者都接受了卡培他滨的辅助化疗(添加贝伐单抗不影响无病生存期或总体生存期),这解释了生存曲线通常更好的观察结
果,因为只有少数患者在测试队列中接受了化疗。
[0851]
讨论
[0852]
基于机器学习的最新发展(lecun等人,《自然(nature)》,2015;521:436-44),我们使用标准实验室h&e染色的组织学切片开发了一个全自动系统,用于预测患者(如患有crc的癌症患者)的结果。所述方法首先勾勒出图像中的病理学(例如癌变)组织,然后将患者分层为预后类别;在验证中,这些疾病特异性死亡率的hr相差3-4倍。
[0853]
深度学习已被证明适用于某些肿瘤类型的检测和描绘(ehteshami bejnordi等人,《美国医学会杂志》,2017;318:2199-210),并且已经报道了各种癌症分类(coudray等人,《自然医学》,2018;24:1559-67)。然而,我们还没有看到用于根据组织学图像直接预测患者的结果的经过验证的系统。
[0854]
自动预测程序减少了人为干预,这可以提高预后的客观性和可重复性。此外,伴随着湿实验室程序的自动化程度增加,更高的分析通量将允许基于来自肿瘤的多个样品做出决策。这可能会减少肿瘤异质性的挑战,这可能是提高预后准确性的关键。
[0855]
大多数现有的预后标志物,如mmr状态(sinicrope,《自然评论临床肿瘤学》,2010;7:174-7;mouradov等人,《美国胃肠病学杂志》,2013;108:1785-93)、基质估计(danielsen等人,《肿瘤学年鉴》,2018;29:616-23)、淋巴浸润(akagi等人,《抗癌研究(anticancer res)》,2013;33:2965-70)、rna谱(salazar等人,《临床肿瘤学杂志》,2011;29:17-24;gray等人,《临床肿瘤学杂志》,2011;29:4611-9)和突变负担(mouradov等人,《美国胃肠病学杂志》,2013;108:1785-93)在生物学上可能是合理的,但功能不如domore-v1-crc,其在hr方面优于这些标志物并在风险组中提供了临床上更有用的患者分层和分布。
[0856]
domore-v1-crc在技术上应用简单,并且可以在世界各地的标准病理学实验室交付。请注意,虽然训练网络需要资源,但在新患者的载玻片图像上应用domore-v1-crc标志物的计算任务要小得多,并且可以使用消费类硬件在十分钟内在临床环境中执行。该标志物的临床效用在于它可以指导与患者讨论不同治疗选项(化疗剂量/时间表)的利弊。尽管目前辅助治疗中使用的药物数量仅限于氟嘧啶类
±
奥沙利铂,但最近的数据表明,对于大多数iii期患者而言,3个月的治疗达到了与6个月的治疗大致相同的生存期结果,而高危患者(pt4和pn2)可能受益于长期疗法(grothey等人,《新英格兰医学期刊》,2018;378:1177-88;iveson等人,《柳叶刀》,2018;19:562-7)。
[0857]
在大多数精心设计的临床试验中,辅助治疗后crc复发和死亡的hr的成比例降低非常一致,为20%。然而,针对低风险和高风险亚组,这转化为完全不同的绝对生存期改善。不存在针对这些风险分层组的前瞻性辅助试验,但这不应阻止临床医生解释现有试验数据并将其应用到被证明具有低或高复发风险的个体。
[0858]
以图16c为例,人们可以将这些数据解释为表明预后不良组中患有ii期疾病的那些个体(约20%)将受益于单药氟嘧啶,例如卡培他滨,而预后较好的组仅通过手术治愈的可能性很高。iii期、pn2期和pt4期患者有更多不同的生存曲线(图16d-f),并且可以得出结论,对于不适合联合化疗的患者来说,在良好且可能不确定的情况下,生存组使用单药卡培他滨的生存期非常合理,而预后较差的组可能从3或6个月的联合化疗中获益更多(绝对生存获益约为8-10%)。显然,这些生存曲线具有指示性,并且临床医生和患者将使用这些曲线来就辅助化疗选择做出联合和更明智的决定。
[0859]
总之,使用与常规h&e染色的ffpe肿瘤组织切片的数字扫描相关的深度学习技术,可以开发出临床上有用的预后标志物。该检测已在大型独立患者人群中进行了广泛评估,与现有的分子和形态学预后标志物相关并优于现有的分子和形态学预后标志物,在肿瘤和淋巴结分期中提供一致的结果,并且临床医生可以使用它来支持辅助治疗选择的决策。
[0860]
我们还表明,如本文所述的深度学习方法可用于完全自动并直接从扫描的组织病理学图像(如使用苏木精和伊红染色、福尔马林固定、石蜡包埋的肿瘤组织切片例示)预测癌症特异性生存期。分类器的独立验证表明,示例性系统将ii期和iii期结肠直肠癌患者分层为明显预后组,从而补充已建立的预后标志物,并在风险比方面优于大多数现有标志物。通过使用该系统鉴定可能仅通过手术治愈的风险非常低的患者以及更有可能从更密集的方案中受益的高风险患者,可以改进癌组织(如结肠直肠癌)切除后辅助治疗的选择。
[0861]
因此,本技术描述了一种方法,所述方法能够提供全自动深度学习系统,用于根据常规组织病理学图像预测患者结果、对这些个体进行分层,并能够做出增强的治疗决策。
[0862]
实例2:
[0863]
该实例提供了额外的支持数据,这些数据示出了将本发明的方法应用到肺癌评估的初步结果。
[0864]
使用从奥斯陆大学医院收集的肺癌患者的肺组织的完整载玻片图像进行了与第1.3节和实例1中描述的实验类似的实验。以结肠直肠癌为例,我们针对每个患者使用单个组织块,然后在两台扫描仪(aperio at2和nanozoomer xr)上扫描单个切片,从而为每个患者生成两个完整的载玻片图像。
[0865]
方法和实验与第1.3节和实例1中描述的完全相同,但以下情况除外:
[0866]-所有患者均来自同一队列
[0867]-测试队列仅由具有明显良好或明显不良结果的患者组成
[0868]-用于定义分块面积的手动肿瘤分割
[0869]
表4:实验中使用的患者数量
[0870][0871]
图19中提供了测试队列结果的生存期分析,实验中包含的两个扫描仪中的每一个扫描仪都有一个kaplan-meier图。这与图16中针对结肠直肠癌实验的分析格式相同。该图说明了癌症特异性生存期,即在没有肺癌死亡的情况下,三个预测结果组的生存期。估计的生存概率可以从y轴读取,而x轴表示手术后的时间。从图中可以看出,当将预测的预后良好组与预后不良组进行比较时,癌症特异性生存期的差异很大。不确定组的癌症特异性生存期在预后良好组和预后不良组之间。
[0872]
需要注意的是,测试患者的数量少于实例1的实验(参见表4)。还应注意,与实例1不同,测试患者与训练患者来自同一队列,因此可归因于这些结果的权重可能会在未来的评估中通过选择测试患者和训练来自不同队列的患者而得到进一步证实。另一方面,与实例1相比,训练中使用的患者更少,并且都来自同一队列,而使用更大、更多样化的训练队列
可以额外改善结果。
[0873]
因此,尽管最好采取进一步措施对独立队列进行验证,以便严格评估所述方法对肺癌样品的性能,但本实施例中提供的初步结果清楚地表明所述方法可以另外用于预测患有除crc以外的癌症形式(包含肺癌)的患者的结果。
[0874]
*****************************************************************
[0875]
在实践所要求保护的发明时,本领域的技术人员可以通过研究附图、公开内容以及所附权利要求书来理解和实现所公开实施例的其它变型。在权利要求书中,词语“包括”不排除其它要素或步骤,并且不定冠词“一个/一种(a或an)”不排除复数。在相互不同的从属权利要求中叙述某些措施的这一事实并不表明这些措施的组合不能被有利地使用。权利要求书中的任何参考符号都不应被解释为限制范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1