运动识别方法、运动识别程序以及信息处理装置与流程
1.本发明涉及运动识别方法、运动识别程序以及信息处理装置。
背景技术:
2.在体操、医疗等广泛的领域中,使用选手、患者等人物的骨骼信息来自动识别人物的动作。例如,体操竞技中的当前的评分方法通过多个裁判的目视来进行,但由于器具的进化、训练方法的改善,伴随着动作的复杂化,技巧的高度化不断发展,出现了裁判对于技巧的识别变得困难的情况。其结果是,在评分的公平性、正确性的维持方面产生了担忧,例如根据每个裁判,选手的评分结果不同等。
3.因此,近年来,使用了自动评分技术,该自动评分技术使用选手的3维骨骼坐标(后面有时记载为“骨骼信息”)。例如,通过3d(three-dimensional:三维)激光传感器取得选手的3维点集数据,并且使用3维点集数据计算选手的骨骼信息。然后,根据骨骼信息的时间序列信息来自动识别实施的“技巧”,向裁判提供自动评分结果,由此确保评分的公平性和正确性。
4.若以体操竞技的鞍马为例对这样的技巧的自动识别进行说明,则预先按照每个区域对设置有作为鞍马的器具之一的马环的周围进行分类。例如,将马环1的左侧分类为区域1,将马环1的上方分类为区域2,将马环1与马环2之间分类为区域3,将马环2的上方分类为区域4,将马环2的右侧分类为区域5。
5.然后,根据骨骼信息识别表演者的骨骼,并且根据从骨骼识别结果中得到的左右手腕的位置位于哪个区域来估计手腕的支撑位置。然后,使用根据时间序列的骨骼信息生成的时间序列的骨骼识别结果和所估计出的手腕的支撑位置,按照技巧的规则对技巧的识别、技巧的精度等进行评价,并执行自动评分。
6.现有技术文献
7.专利文献
8.专利文献1:国际公开第2018/070414号
技术实现要素:
9.发明要解决的问题
10.然而,在上述技术中,在3d激光传感器的感测中包含噪声的情况下、或者由于整合多个感测结果时产生的偏差等,使用了感测结果的骨骼识别处理的精度降低,难以保证各关节的位置的估计精度。
11.另一方面,在识别运动方面,有时要求正确地识别现实世界中存在的物体与被摄体的部位的位置关系。例如,根据表演者的手腕是存在于鞍马的区域a还是存在于鞍马的区域b,会出现最终的运动识别结果发生变化的情况等。也就是说,即使动作本身相同,也会出现手在区域a中支撑时被识别为技巧t,手在区域b中支撑时被识别为技巧s的情况等。
12.在上述技术中,直接使用从骨骼识别结果中得到的部位的位置,对该部位是位于
物体上的哪个区域进行了分类。但是,在骨骼识别结果中存在误差的情况下,有时所分配的区域并不正确。例如,在鞍马中,会出现如下情况等:骨骼识别结果所示的手腕被分配到了区域1,但原本手是放在区域2中的。若发生这样的事态,作为结果,会出现运动的识别结果发生错误的情况,例如将技巧s识别为技巧t等。
13.因此,本发明的一个方面的目的在于,提供一种运动识别方法、运动识别程序以及信息处理装置,通过提高针对被摄体的特定部位与现实世界中存在的物体中的多个区域之间的位置关系的估计精度,从而提高使用了该位置关系的运动的识别精度。
14.用于解决问题的手段
15.在第一方案中,在运动识别方法中,计算机执行如下处理:按时间序列取得进行运动的被摄体的基于包括特定关节在内的多个关节各自的位置信息的骨骼信息。在运动识别方法中,计算机执行如下处理:使用所述时间序列的骨骼信息各自所包含的所述多个关节中的第一关节组的位置信息,对分割在所述运动中使用的物体的区域而得到的多个区域中的所述特定关节所在的区域进行估计。在运动识别方法中,计算机执行如下处理:使用所述时间序列的骨骼信息各自所包含的所述多个关节中的第二关节组的位置信息,对所述特定关节所在的区域进行估计,该第二关节组相当于所述第一关节组的一部分,并且该第二关节组包含所述特定关节。在运动识别方法中,计算机执行如下处理:基于估计出的所述特定关节所在的各估计结果,确定所述特定关节所在的区域。在运动识别方法中,计算机执行如下处理:使用所述时间序列的骨骼信息和所确定的所述特定关节所在的区域,识别所述被摄体的运动,并输出识别结果。
16.发明的效果
17.在一个方面中,能够提高使用了被摄体的特定部位与现实世界中存在的物体中的多个区域之间的位置关系的运动的识别精度。
附图说明
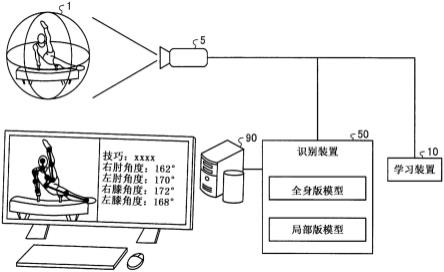
18.图1是示出实施例1的系统的整体结构例的图。
19.图2是示出实施例1的学习装置的功能结构的功能框图。
20.图3是说明距离图像的图。
21.图4是说明骨骼定义的图。
22.图5是说明骨骼数据的图。
23.图6是说明与鞍马相关联的骨骼信息的图。
24.图7是说明类别分类的图。
25.图8是说明基于横向转体时的支撑位置的关节动作的差异的图。
26.图9是说明基于表演俄式转体(russian)时的支撑位置的关节动作的差异的图。
27.图10是说明基于支撑位置的脚踝的z值的变化的图。
28.图11是说明生成全身版模型用的学习数据的图。
29.图12是说明学习数据的整形的图。
30.图13是说明全身版模型的学习的图。
31.图14是说明生成局部版模型用的学习数据的图。
32.图15是说明局部版模型的学习的图。
33.图16是示出实施例1的识别装置的功能结构的功能框图。
34.图17是示出选择信息的例子的图。
35.图18是说明通过全身版模型估计支撑位置的图。
36.图19是示出基于全身版模型的支撑位置的估计结果的一览的图。
37.图20是示出使用了全身版模型的识别结果的一览的图。
38.图21是说明通过局部版模型估计支撑位置的图。
39.图22是示出基于局部版模型的支撑位置的估计结果的一览的图。
40.图23是示出使用了局部版模型的识别结果的一览的图。
41.图24是说明估计结果的选择的图。
42.图25是说明基于全身版模型的支撑位置的估计结果中的、被整合的对象的估计结果的图。
43.图26是说明基于局部版模型的支撑位置的估计结果中的、成为整合对象的估计结果的图。
44.图27是说明支撑位置的整合的图。
45.图28是说明整合后的技巧的再识别结果的图。
46.图29是示出实施例1的评分装置的功能结构的功能框图。
47.图30是示出实施例1的学习处理的流程的流程图。
48.图31是示出实施例1的自动评分处理的流程的流程图。
49.图32是示出类别分类处理的流程的流程图。
50.图33是示出整合处理的流程的流程图。
51.图34是说明实施例2的整合处理的图。
52.图35是说明硬件结构例的图。
具体实施方式
53.以下,基于附图对本发明的运动识别方法、运动识别程序以及信息处理装置的实施例进行详细说明。另外,本发明并不限定于该实施例。另外,各实施例能够在不矛盾的范围内适当组合。
54.实施例1
55.[整体结构]
[0056]
图1是示出实施例1的系统的整体结构例的图。如图1所示,该系统具有3d(three-dimensional)激光传感器5、学习装置10、识别装置50、评分装置90,在该系统中,拍摄作为被摄体的表演者1的3维数据,识别骨骼等并进行正确的技巧的评分。另外,在本实施例中,作为一例,以作为体操竞技的鞍马为例,以识别进行鞍马表演的表演者的骨骼信息为例来进行说明。
[0057]
通常,体操竞技中的当前的评分方法由多个评分者通过目视来进行,但随着技巧的高度化,通过评分者的目视难以评分的情况有所增加。近年来,已知有使用了3d激光传感器5的评分竞技的自动评分系统、评分辅助系统。例如,在这些系统中,通过3d激光传感器5取得作为选手的3维数据的距离图像,并从距离图像中识别骨骼信息,该骨骼信息是选手的各关节的朝向、各关节的角度等。并且,在评分辅助系统中,利用3d模型显示骨骼识别的结
果,由此辅助评分者通过确认表演者的细节的状况等来实施更正确的评分。另外,在自动评分系统中,根据骨骼识别的结果来识别表演的技巧等,并参照评分规则进行评分。
[0058]
在此,在3d激光传感器5的感测中包含噪声等情况下,使用了感测结果的骨骼识别处理的精度降低,有时难以保证关节位置的估计精度。但是,在自动评分系统中,关节位置的估计精度降低会导致系统的可靠性降低,因此减小噪声的影响,抑制估计精度的降低的努力是重要的。
[0059]
因此,通过在表演者1的关节位置的估计中导入ai(artificial intelligence:人工智能)技术,从而减小噪声的影响,并且提高针对表演者1的关节位置与现实世界中存在的鞍马上的各区域的位置关系的估计精度。
[0060]
例如,通过将表演者的骨骼信息的时间序列的变化作为特征进行学习,使用根据表演者1的身体整体的关节位置来估计特定关节的位置的分类模型,从而能够提高表演者1的特定关节的位置估计的估计精度、技巧的识别精度。
[0061]
然而,在使用这样的根据全身的关节位置来估计特定关节位置的分类模型的情况下,如果是用于学习的动作、姿势的骨骼信息,则能够提高估计精度,但关于未知的姿势、动作,估计精度有可能降低。
[0062]
因此,在实施例1中,使用全身版模型和局部版模型这两种来估计表演者1的特定关节位置,从而提高针对各种动作的估计精度,该全身版模型是使用全身的关节位置进行学习而得到的,局部版模型是使用局部的关节位置进行学习而得到的。
[0063]
此外,全身版模型是与全身的关节中的大致相当于全身的第一关节组有关的模型。在以下的实施例中,第一关节组包含18个关节,这18个关节被定义为构成全身的骨骼的关节。
[0064]
另外,局部版模型是与多个关节中的至少包含特定关节的一部分关节组有关的模型。另外,局部版模型还是与第二关节组有关的模型,该第二关节组相当于第一关节组的一部分。在以下的实施例中,第二关节组包含6个关节,这6个关节至少包含两手腕的关节。
[0065]
通过使用这样的2个模型,即使在怀疑在3d激光传感器的感测中混入了噪声的情况下、或者表演了未用于学习的动作或技巧等的情况下,识别装置50也能够正确地估计关节位置,提高表演者1的表演中的技巧的识别精度。其结果是,能够抑制自动评分系统的可靠性的降低。
[0066]
[功能结构]
[0067]
接着,对图1所示的系统具有的各装置的功能结构进行说明。这里,分别对学习装置10、识别装置50和评分装置90进行说明。
[0068]
(学习装置10的结构)
[0069]
图2是示出实施例1的学习装置10的功能结构的功能框图。如图2所示,学习装置10具有通信部11、存储部12、控制部20。
[0070]
通信部11是控制与其他装置之间的通信的处理部,例如通过通信接口等来实现。例如,通信部11接收由3d激光传感器5拍摄到的表演者1的距离图像,从管理者终端等接收各种数据、指示,向识别装置50发送学习完毕的各模型。
[0071]
存储部12对数据、控制部20执行的程序等进行存储。该存储部12存储距离图像13、骨骼定义14、骨骼数据15、全身版模型16、局部版模型17。此外,存储部12例如由存储器、硬
盘等实现。
[0072]
距离图像13是由3d激光传感器5拍摄的表演者1的距离图像。图3是说明距离图像13的图。如图3所示,距离图像13是包含从3d激光传感器5到像素的距离的数据,距3d激光传感器5的距离越近,则以越浓的颜色进行显示。另外,在表演者1的表演过程中随时拍摄距离图像13。
[0073]
骨骼定义14是用于确定骨骼模型上的各关节的定义信息。在此存储的定义信息可以通过由3d激光传感器进行的3d感测来按照每个表演者进行测量,也可以使用一般的体系的骨骼模型来定义。
[0074]
图4是说明骨骼定义14的图。如图4所示,骨骼定义14存储18个(0号到17号)定义信息,这18个定义信息是对由公知的骨骼模型确定的各关节进行了编号而得到的。例如,如图4所示,对右肩关节(shoulder_right)标注7号,对左肘关节(elbow_left)标注5号,对左膝关节(knee_left)标注11号,对右髋关节(hip_right)标注14号。在此,在实施例中,有时将7号右肩关节的x坐标记载为x7,将y坐标记载为y7,将z坐标记载为z7。此外,例如,z轴能够定义为从3d激光传感器5朝向对象的距离方向,y轴能够定义为与z轴垂直的高度方向,x轴能够定义为水平方向。
[0075]
骨骼数据15是包含使用各距离图像生成的与骨骼有关的信息在内的数据。具体而言,骨骼数据15包含使用距离图像取得的、由骨骼定义14定义的各关节的位置。图5是说明骨骼数据15的图。如图5所示,骨骼数据15是将“帧、图像信息、骨骼信息”对应起来的信息。
[0076]
在此,“帧”是用于识别由3d激光传感器5拍摄的各帧的标识符,“图像信息”是关节等的位置为已知的距离图像的数据。“骨骼信息”是骨骼的3维的位置信息,并且“骨骼信息”是与图4所示的18个各关节对应的关节位置(3维坐标)。在图5的例子中,在作为距离图像的“图像数据a1”中,示出了包含头的坐标“x3,y3,z3”等在内的18个关节的位置为已知的情况。此外,例如能够使用学习模型等来提取关节位置,该学习模型是预先进行学习而得到的学习模型,其从距离图像提取各关节位置。
[0077]
在此,在本实施例中作为对象的鞍马的表演中,能够使用18个关节,但也能够仅使用与鞍马的表演特别相关联的关节。图6是说明与鞍马相关联的骨骼信息的图。如图6所示,作为与鞍马的表演较大程度相关联的骨骼信息(关节),可列举出头、右肩、左肩、脊柱、右肘、左肘、右手腕、左手腕、腰、右膝、左膝、右脚踝、左脚踝。
[0078]
头示出抬起或低下头的动作。肩示出躯干与手臂之间的位置关系。脊柱示出身体的弯曲,示出体操中的屈伸、伸身。肘示出手臂的弯曲、力的施加方式。手腕示出抓住物体的位置等。腰示出身体的大致重心。膝盖示出躯干与腿之间的关系,并且膝盖能够确定腿分开与腿并拢的差异。脚踝示出步行状态、跑步状态、鞍马转体运动的轨迹。
[0079]
在鞍马的竞技中,在用手抓住马环的状态下进行的表演和在将手放在马背上的状态下进行的表演混合存在,即使进行了相同的动作,技巧、难易度也会根据手的位置而发生变化。另一方面,由于马环在马背上,因此在一系列的表演过程中,仅通过手的位置难以自动地判定是马环还是马背。因此,在实施例1中,根据图6所示的关节的动作,特别是考虑脚踝的上升幅度等来估计手的位置,由此提高关节位置的估计精度。
[0080]
全身版模型16是基于时间序列的全身的骨骼信息来估计表演者1的手腕的位置的学习模型,并且全身版模型16是使用了由后述的第一学习处理部22学习的神经网络等的模
型。也就是说,全身版模型16将鞍马上的位置分类为多个类别,并将表演者1的全身的骨骼信息的时间序列的变化作为特征量进行学习,从而估计表演者1的手腕的支撑位置。
[0081]
另外,局部版模型17是基于时间序列的一部分骨骼信息来估计表演者1的手腕的位置的学习模型,并且局部版模型17是使用了由后述的第二学习处理部23学习的神经网络等的模型。也就是说,局部版模型17将鞍马上的位置分类为多个类别,将表演者1的一部分骨骼信息的时间序列的变化作为特征量进行学习,从而估计表演者1的手腕的支撑位置。
[0082]
图7是说明类别分类的图。如图7所示,在实施例1中,作为一例,对将区域分割为类别0到类别5这6个类别的例子进行说明。具体而言,类别1(a1)是马端a与马环1之间的马背的区域,类别2(a2)是马环1上方的区域。类别3(a3)是马环1与马环2之间的马背的区域,类别4(a4)是马环2上方的区域。类别5是马环2与马端b之间的马背的区域,类别0(a0)是类别1到类别5以外的区域。
[0083]
控制部20是控制学习装置10整体的处理部,例如能够通过处理器等来实现。控制部20具有取得部21、第一学习处理部22、第二学习处理部23,并且执行各模型的学习。此外,取得部21、第一学习处理部22、第二学习处理部23也能够通过处理器等电子电路、处理器等所具有的进程来实现。
[0084]
取得部21是取得各种数据的处理部。例如,取得部21从3d激光传感器5取得距离图像并存储于存储部12。另外,取得部21从管理者终端等取得骨骼数据并存储于存储部12。
[0085]
第一学习处理部22及第二学习处理部23将时间序列的骨骼信息用作特征量,执行全身版模型16或局部版模型17的学习。
[0086]
在此,作为将时间序列的骨骼信息作为特征量进行学习的理由,对基于支撑位置的关节动作的差异进行说明。图8是说明基于横向转体时的支撑位置的关节动作的差异的图,图9是说明基于表演俄式转体时的支撑位置的关节动作的差异的图。
[0087]
如图8所示,纵向转体是按照正面支撑、背面支撑、正面支撑的顺序进行转体的动作。如技巧编号13所示,在手腕的支撑位置为马背位置的纵向转体中,在背面支撑中,为了避开马环而将脚较高地抬起,在之后的正面支撑中,通过在背面支撑中将脚抬起后的反作用而容易将脚落下。另一方面,如技巧编号14所示,在手腕的支撑位置为马环的纵向转体中,由于在背面支撑中与马环的高度相应地将上身抬高,因此不需要将脚较高地抬起,在之后的正面支撑中,也能够以与背面支撑大致相同的高度来进行转体。即,脚踝的z值的变化量根据手腕的支撑位置而发生变化。
[0088]
另外,如图9所示,俄式转体是通过向下支撑而与转体相应地改变朝向的动作。如技巧编号104至106所示,在手腕的支撑位置为马背位置的俄式转体中,以放置在马背上的手为轴进行转体,因此脚的位置成为比马背低的位置。如技巧编号110至112所示,在手腕的支撑位置为马环的俄式转体中,以放置在马环上的手为轴进行转体,因此与手腕的支撑位置为马背位置的俄式转体相比,脚的位置成为较高的位置。即,脚踝的z值的变化量根据手腕的支撑位置而发生变化。
[0089]
接着,具体说明脚踝的z值的变化。图10是说明基于支撑位置的脚踝的z值的变化的图。在图10中,示出了依次表演马环的纵向转体(技巧编号14)、马环的俄式转体(技巧编号110)、马背的纵向转体(技巧编号13)、马背的俄式转体(技巧编号104)时的脚踝的z值。如图10所示,将马环作为支撑位置时的脚踝的z值的变化(振幅)较小,将马背作为支撑位置时
的脚踝的z值的变化较大。也就是说,可认为,通过学习z值的变化,支撑位置的估计精度得到提高。
[0090]
返回图2,第一学习处理部22是具有第一生成部22a和第一学习部22b且通过机器学习来生成全身版模型16的处理部。
[0091]
第一生成部22a是生成在全身版模型16的学习中使用的学习数据的处理部。具体而言,第一生成部22a生成将时间序列的全身(18个关节)的骨骼信息作为说明变量、将手腕的支撑位置(类别)作为目标变量的学习数据,将该学习数据存储于存储部12,并输出到第一学习部22b。
[0092]
图11是说明生成全身版模型16用的学习数据的图。如图11所示,第一生成部22a参照骨骼数据15的骨骼信息,对各帧的骨骼信息赋予表示右手的支撑位置的坐标的“wr”和表示左手的支撑位置的坐标的“wl”来作为双手的支撑位置信息。
[0093]
例如,第一生成部22a针对时间(time)=0的帧的骨骼信息(j0),从骨骼信息取得右手腕(关节位置=9号)的坐标值(r0)和左手腕(关节位置=6号)的坐标值(l0)。然后,第一生成部22a将右手腕的坐标值(r0)和左手腕的坐标值(l0)与属于预先设定的鞍马的各类别的坐标值进行比较,从而设定右手类别(类别2)和左手类别(类别4)。
[0094]
同样地,第一生成部22a针对时间=1的帧的骨骼信息(j1),从骨骼信息取得右手腕的坐标值(r1)和左手腕的坐标值(l1)。然后,第一生成部22a将右手腕的坐标值(r1)和左手腕的坐标值(l1)与属于各类别的坐标值进行比较,从而设定右手类别(类别2)和左手类别(类别4)。
[0095]
这样,第一生成部22a对按时间序列取得的各帧的骨骼信息赋予作为准确信息的右手类别和左手类别。此外,在图11中,为了简化说明,将骨骼信息记载为j0等,但实际上针对18个关节分别设定了x、y、z值的坐标(合计:18
×
3=54个)。
[0096]
第一学习部22b是使用由第一生成部22a生成的学习数据来执行全身版模型16的学习的处理部。具体而言,第一学习部22b通过使用了学习数据的有教师学习来优化全身版模型16的参数。并且,第一学习部22b将学习完毕的全身版模型16存储于存储部12,并将其发送到识别装置50。此外,结束学习的时机能够任意地设定,例如设定为使用了规定数量以上的学习数据的学习完成的时间点、恢复误差小于阈值的时间点等。
[0097]
这样的第一学习部22b例如将30帧作为1个输入数据输入到全身版模型16,因此通过填充(padding)等来执行学习数据的整形,其中,该30帧是时间序列的18个关节的骨骼信息。图12是说明学习数据的整形的图。如图12所示,在从原始数据中每次错开1个地分别取得规定数量的数据作为学习数据的情况下,为了使各学习数据的数量一致,复制开头帧的数据,并且复制最终帧的数据,从而增加学习数据的数量,其中,在该原始数据中存在有从时间=0的帧0到时间=t的帧t的t个骨骼信息。
[0098]
例如,第一学习部22b将帧0的数据“骨骼信息(j0)、支撑位置信息(wr(r0),wl(l0))”复制到帧0之前的位置,生成帧(-1)或帧(-2)等。同样地,第一学习部22b将帧t的数据“骨骼信息(jt)、支撑位置信息(wr(rt),wl(lt))”复制到帧t之后的位置,生成帧(t+1)或帧(t+2)等。此外,填充数量是用于学习的帧数(length:长度)的一半等。
[0099]
这样,第一学习部22b在执行了学习数据的整形的基础上,执行全身版模型16的学习。图13是说明全身版模型16的学习的图。如图13所示,第一学习部22b取得l个(例如30个)
时间序列的全身(18个关节)的骨骼信息的学习数据作为说明变量,取得位于中间的学习数据的“右手类别、左手类别”作为目标变量。然后,第一学习部22b将l个学习数据输入到全身版模型16,通过基于全身版模型16的输出结果与目标变量“右手类别、左手类别”的误差的误差反向传播法等,来执行全身版模型16的学习,以使输出结果与目标变量一致。
[0100]
例如,第一学习部22b取得以帧n为中间的从帧(n-15)到帧(n-14)这30个帧的骨骼信息作为说明变量,并且取得帧n的“右手类别(类别2)、左手类别(类别4)”作为目标变量。然后,第一学习部22b将所取得的30个帧作为1个输入数据输入到全身版模型16,并取得右手类别与各类别相符的概率(似然度)和左手类别与各类别相符的概率(似然度)。
[0101]
然后,第一学习部22b执行全身版模型16的学习,以使右手类别的概率中的作为目标变量的类别2的概率成为最高且左手类别的概率中的作为目标变量的类别4的概率成为最高。此外,全身版模型16的学习例如是使用误差反向传播法等来更新神经网络的各种参数等。
[0102]
这样,第一学习部22b使用每次将学习数据错开1帧而得到的学习数据来进行学习,由此将18个关节的全骨骼信息的变化作为1个特征量进行学习。例如,第一学习部22b将范围设为
±
10帧,在识别第1280帧的类别分类的情况下,输入从1270到1290帧之间的“20
×
(18个关节
×
3轴(x,y,z)=54)=1080”的骨骼信息,执行全身版模型16的学习。另外,第一学习部22b在识别第1310帧的类别分类的情况下,输入从1300到1320帧之间的“20
×
(18个关节
×
3轴(x,y,z)=54)=1080”的骨骼信息,执行全身版模型16的学习。
[0103]
返回图2,第二学习处理部23是具有第二生成部23a和第二学习部23b且通过机器学习来生成局部版模型17的处理部。
[0104]
第二生成部23a是生成在局部版模型17的学习中使用的学习数据的处理部。具体而言,第二生成部23a生成将时间序列的一部分关节的骨骼信息作为说明变量、将手腕的支撑位置(类别)作为目标变量的学习数据,将该学习数据存储于存储部12,并输出到第二学习部23b。
[0105]
图14是说明生成局部版模型17用的学习数据的图。如图14所示,在局部版模型17的学习中,采用关节编号4(左肩)、关节编号5(左肘)、关节编号6(左手腕)、关节编号7(右肩)、关节编号8(右肘)、关节编号9(右手腕)这6个关节的骨骼信息。具体而言,如图14所示,第二生成部23a从骨骼数据15的骨骼信息中取得上述6个关节的骨骼信息,并对各帧的6个关节的骨骼信息赋予表示右手的支撑位置的坐标的“wr”和表示左手的支撑位置的坐标的“wl”来作为双手的支撑位置信息。
[0106]
例如,第二生成部23a针对时间=0的帧的6个关节的骨骼信息(z0),从骨骼信息取得右手腕(关节位置=9号)的坐标值(r0)和左手腕(关节位置=6号)的坐标值(l0)。然后,第二生成部23a将右手腕的坐标值(r0)和左手腕的坐标值(l0)与属于预先设定的鞍马的各类别的坐标值进行比较,从而设定右手类别(类别2)和左手类别(类别4)。
[0107]
这样,第二生成部23a对按时间序列取得的各帧的上述6个关节的骨骼信息赋予作为准确信息的右手类别和左手类别。此外,在图14中,为了简化说明,将骨骼信息记载为z0等,但实际上对6个关节分别设定了x、y、z值的坐标(合计:6
×
3=18个)。
[0108]
第二学习部23b是使用由第二生成部23a生成的学习数据来执行局部版模型17的学习的处理部。具体而言,第二学习部23b通过使用了学习数据的有教师学习来优化局部版
模型17的参数。并且,第二学习部23b将学习完毕的局部版模型17存储于存储部12,并将其发送到识别装置50。此外,结束学习的时机能够设定为与全身版模型16相同的时机。
[0109]
这样的第二学习部23b例如将30帧作为1个输入数据输入到局部版模型17,因此通过与第一学习部22b相同的方法,从原始数据中生成填充数据,从而增加学习数据的数量,其中,该30帧是时间序列的6个关节的骨骼信息。
[0110]
然后,第二学习部23b在执行了学习数据的整形的基础上,执行局部版模型17的学习。图15是说明局部版模型17的学习的图。如图15所示,第二学习部23b取得与全身版模型16的学习时相同的数量即l个(例如30个)时间序列的6个关节的骨骼信息的学习数据作为说明变量,并取得位于中间的学习数据的“右手类别、左手类别”作为目标变量。然后,第二学习部23b将l个学习数据输入到局部版模型17,通过基于局部版模型17的输出结果与目标变量“右手类别、左手类别”的误差的误差反向传播法等,来执行局部版模型17的学习,以使输出结果与目标变量一致。
[0111]
例如,第二学习部23b取得以帧n为中间的从帧(n-15)到帧(n-14)这30个帧中的6个关节的骨骼信息作为说明变量,并取得帧n的“右手类别(类别4)、左手类别(类别5)”作为目标变量。然后,第二学习部23b将所取得的30个帧(6个关节的骨骼信息)作为1个输入数据输入到局部版模型17,取得右手类别与各类别相符的概率(似然度)和左手类别与各类别相符的概率(似然度)来作为局部版模型17的输出结果。
[0112]
然后,第二学习部23b执行局部版模型17的学习,以使右手类别的概率中的作为目标变量的类别4的概率成为最高且左手类别的概率中的作为目标变量的类别5的概率成为最高。这样,第二学习部23b与全身版模型16同样地,使用每次将学习数据错开1帧而得到的学习数据来进行学习,由此将与6个关节对应的一部分骨骼信息的变化作为1个特征量来进行学习。
[0113]
(识别装置50的结构)
[0114]
图16是示出实施例1的识别装置50的功能结构的功能框图。如图16所示,识别装置50具有通信部51、存储部52、控制部60。
[0115]
通信部51是控制与其他装置之间的通信的处理部,例如通过通信接口等来实现。例如,通信部51接收由3d激光传感器5拍摄到的表演者1的距离图像,从学习装置10接收各学习完毕的模型,将各种识别结果发送到评分装置90。
[0116]
存储部52对数据、控制部60执行的程序等进行存储。该存储部52存储距离图像53、骨骼定义54、骨骼数据55、选择信息56、学习完毕的全身版模型57、学习完毕的局部版模型58。此外,存储部52例如由存储器、硬盘等来实现。
[0117]
距离图像53是由3d激光传感器5拍摄的表演者1的距离图像,距离图像53例如是拍摄有作为评分对象的表演者的表演的距离图像。骨骼定义54是用于确定骨骼模型上的各关节的定义信息。此外,骨骼定义54与图4相同,因此省略详细的说明。
[0118]
骨骼数据55是包含由后述的数据生成部62按每个帧生成的与骨骼有关的信息在内的数据。具体而言,骨骼数据55与图5同样,是将“帧、图像信息、骨骼信息”对应起来的信息。
[0119]
选择信息56是定义了技巧的优先度等的信息。图17是示出选择信息的例子的图。如图17所示,选择信息56是将“选择等级”、“难度(difficulty)”、“要素(element)”对应起
来的信息。在此,“选择等级”表示优先度,“难度”表示技巧的难易度,“要素”是确定技巧的信息。在图17的例子中,示出了如下内容:难易度为“d”的技巧“iii-82”的选择等级为“0”,难易度为“e”的技巧“iii-89”的选择等级为“1”,与技巧“iii-82”相比,优先选择技巧“iii-89”。
[0120]
此外,选择信息56例如可以是记载了未学习的技巧、选择时的优先度的列表,并且也可以设定与学习数据之间的关节坐标的差分值来作为判断是否是未学习的骨骼的阈值。此外,关节坐标的差分例如也可以是以腰为基准的各关节的相对位置的差分。
[0121]
全身版模型57是使用通过学习装置10进行的机器学习而生成的全身的骨骼信息来执行预测的学习模型。该全身版模型57是基于时间序列的全身(18个关节)的骨骼信息来估计表演者1的手腕的位置的学习模型。
[0122]
局部版模型58是使用通过学习装置10进行的机器学习而生成的一部分骨骼信息来执行预测的学习模型。该局部版模型58是基于时间序列的6个关节的骨骼信息来估计表演者1的手腕的位置的学习模型。
[0123]
控制部60是控制识别装置50整体的处理部,例如能够通过处理器等来实现。该控制部60具有取得部61、数据生成部62、第一识别部63、第二识别部64、结果整合部65,并且该控制部60执行手腕的位置的估计、表演者1所表演的技巧的识别。此外,取得部61、数据生成部62、第一识别部63、第二识别部64、结果整合部65也能够通过处理器等电子电路、处理器等所具有的进程来实现。
[0124]
取得部61是取得各种数据、各种指示的处理部。例如,取得部61取得基于3d激光传感器5的测量结果(3维点集数据)的距离图像并将其存储于存储部52。另外,取得部61从学习装置10等取得各学习完毕的模型并将其存储于存储部52。
[0125]
数据生成部62是根据各距离图像生成包含18个关节的位置的骨骼信息的处理部。例如,数据生成部62使用从距离图像识别骨骼信息的学习完毕的模型,生成确定了18个关节位置的骨骼信息。然后,数据生成部62将与距离图像对应的帧的编号、距离图像以及骨骼信息对应起来的骨骼数据55存储于存储部52。另外,学习装置10中的骨骼数据15中的骨骼信息也能够通过同样的方法来生成。
[0126]
第一识别部63是如下处理部:具有第一估计部63a和第一技巧识别部63b,根据全身的骨骼信息来估计作为特定的骨骼信息的手腕的支撑位置,并基于其结果来识别表演者1所表演的技巧。
[0127]
第一估计部63a是如下处理部:使用表演者1的时间序列的全身的骨骼信息和学习完毕的全身版模型57来估计表演者1的手腕的支撑位置。具体而言,第一估计部63a将与学习时相同的帧数作为1个输入数据输入到学习完毕的全身版模型57,基于学习完毕的全身版模型57的输出结果来估计表演者1的手腕的支撑位置。另外,第一估计部63a将估计结果输出到第一技巧识别部63b,并存储于存储部52。
[0128]
图18是说明通过全身版模型57估计支撑位置的图。如图18所示,第一估计部63a将由数据生成部62生成的18个关节的骨骼信息作为原始数据,通过与图12相同的方法进行数据填充,并生成填充数据。然后,第一估计部63a从开头取得30帧,并将30帧各自的18个关节的关节信息输入到学习完毕的全身版模型57。
[0129]
然后,第一估计部63a根据全身版模型57的输出结果,取得右手类别的概率中概率
最高的“类别2”和左手类别的概率中概率最高的“类别3”。然后,第一估计部63a将“右手=类别2,左手=类别3”估计为表演者1的手腕的支撑位置。这样,第一估计部63a通过每次将帧错开1个地进行输入,来估计表演中的各状态的手腕的支撑位置。
[0130]
然后,第一估计部63a将估计结果存储于存储部52。例如,第一估计部63a将如下的估计结果一览存储于存储部52,在该估计结果一览中,将所输入的30帧的开头帧或正中间的帧与作为估计结果的左右手腕的支撑位置对应起来。
[0131]
图19是示出基于全身版模型57的支撑位置的估计结果的一览的图。如图19所示,第一估计部63a生成将“帧编号”、“右手位置”、“左手位置”对应起来的支撑位置的估计结果。在此,“帧编号”表示用于估计的帧,“右手位置”是估计出的右手的手腕所在的类别,“左手位置”是估计出的左手的手腕所在的类别。在图19的例子中,示出了针对帧编号“767”估计出了右手位置为“a5”和左手位置为“a1”。
[0132]
第一技巧识别部63b是如下处理部:使用基于第一估计部63a的手腕的估计位置等,执行表演者1所表演的技巧的临时识别。具体而言,第一技巧识别部63b使用国际公开第2018/070414号所公开的方法,执行表演者1的身躯的位置或技巧与技巧的分隔的姿势的检测、正面支撑或着地位置的确定、分节点的判断、使用了分节点间的信息的基本运动的判定等,自动地临时识别表演者1所表演的各技巧,并将所述各技巧发送到结果整合部65。
[0133]
例如,第一技巧识别部63b使用各帧的骨骼信息,计算表示各关节间的朝向的矢量数据,并计算用于确定身体的朝向或动作的特征量。然后,第一技巧识别部63b将计算出的特征量与预先规定的技巧识别的规则进行比较来识别技巧。例如,第一技巧识别部63b基于各分节间的骨骼信息来计算特征量a、特征量b,并通过特征量a与特征量b的组合识别为技巧a。
[0134]
另外,第一技巧识别部63b使用基于第一估计部63a的手腕的支撑位置的估计结果,将支撑位置发生了变化的场所确定为分节点,并确定技巧的分隔。另外,第一技巧识别部63b也能够使用学习模型等来执行技巧识别,该学习模型将由第一估计部63a估计出的时间序列的手腕的位置信息作为输入而输出技巧名称。此外,第一技巧识别部63b也能够将把识别出的技巧和与用于该技巧的识别的信息相符的帧的信息对应起来后的技巧识别结果保存于存储部52。
[0135]
图20是示出使用了全身版模型57的识别结果的一览的图。如图20所示,第一技巧识别部63b生成将“开头帧”、“最终帧”、“识别结果”对应起来了的的识别结果一览。在此,“开头帧”表示被识别为技巧的帧之间的开头,“最终帧”表示被识别为技巧的帧之间的末尾,“识别结果”表示识别出的技巧的信息。在图20的例子中,表示从“帧687”到“帧714”的动作被识别为技巧“ii-1”。另外,图20中的“罗马数字-数字”对应于技巧,除此以外是技巧与技巧之间的连接动作等。
[0136]
第二识别部64是如下处理部:具有第二估计部64a和第二技巧识别部64b,根据6个关节的骨骼信息,估计作为特定的骨骼信息的手腕的支撑位置,并基于其结果来识别表演者1所表演的技巧。
[0137]
第二估计部64a是如下处理部:使用表演者1的时间序列的6个关节的骨骼信息和学习完毕的局部版模型58来估计表演者1的手腕的支撑位置。具体而言,第二估计部64a将与学习时相同的帧数作为1个输入数据输入到学习完毕的局部版模型58,并基于学习完毕
的局部版模型58的输出结果来估计表演者1的手腕的支撑位置。另外,第二估计部64a将估计结果输出到第二技巧识别部64b,并保存于存储部52。
[0138]
图21是说明通过局部版模型58估计支撑位置的图。如图21所示,第二估计部64a取得由数据生成部62生成的18个关节的骨骼信息中的上述6个关节的骨骼信息作为原始数据,通过与图12相同的方法来进行数据填充,并生成填充数据。然后,第二估计部64a从开头取得30帧,并将30帧各自的6个关节的关节信息输入到学习完毕的局部版模型58。
[0139]
然后,第二估计部64a根据局部版模型58的输出结果,取得右手类别的概率中概率最高的“类别2”和左手类别的概率中概率最高的“类别4”。然后,第二估计部64a将“右手=类别2,左手=类别4”估计为表演者1的手腕的支撑位置。这样,第二估计部64a通过每次将帧错开1个地进行输入,来估计表演中的各状态的手腕的支撑位置。
[0140]
然后,第二估计部64a将估计结果存储于存储部52。例如,第二估计部64a将估计结果一览存储于存储部52,在该估计结果一览中,将所输入的30帧的开头帧或正中间的帧与作为估计结果的左右手腕的支撑位置对应起来。
[0141]
图22是示出基于局部版模型58的支撑位置的估计结果的一览的图。如图22所示,第二估计部64a与图19同样地,生成将“帧编号”、“右手位置”、“左手位置”对应起来了的支撑位置的估计结果。在图22的例子中,示出了针对帧编号“767”估计出了类别“a4”作为右手位置、类别“a5”作为左手位置。
[0142]
第二技巧识别部64b是如下处理部:使用基于第二估计部64a的手腕的估计位置等来执行表演者1所表演的技巧的临时识别。具体而言,第二技巧识别部64b使用与第一技巧识别部63b相同的方法,自动地临时识别表演者1所表演的各技巧,并发送到结果整合部65。
[0143]
另外,第二技巧识别部64b也能够将把识别出的技巧和与用于该技巧的识别的信息相符的帧信息对应起来了的技巧识别结果保存于存储部52。图23是示出使用了局部版模型58的识别结果的一览的图。如图23所示,第二技巧识别部64b与图20同样地,生成将“开头帧”、“最终帧”、“识别结果”对应起来了的识别结果的一览。在图23的例子中,示出了从“帧744”到“帧779”的动作被识别为了技巧“iii-95”。
[0144]
结果整合部65是具有判定部65a、整合部65b、再识别部65c且判定第一识别部63、第二识别部64的识别结果(临时技巧识别)的正当性的处理部。具体而言,结果整合部65从各模型的临时技巧识别的结果中,根据各动作、骨骼的学习状况来选择适当的模型的结果。
[0145]
判定部65a是判定全身版模型57的估计结果或局部版模型58的估计结果中的适当的估计结果的处理部。具体而言,判定部65a将由第一识别部63进行了临时技巧识别而得到的技巧的选择等级与由第二识别部64进行了临时技巧识别而得到的技巧的选择等级进行比较,将选择等级高的一方的模型的估计结果判定为适当的估计结果,并将该估计结果输出到整合部65b等。
[0146]
图24是说明估计结果的选择的图。如图24所示,判定部65a提取被识别为技巧的局部版模型58的对象帧所包含的全身版模型57的帧。此时,判定部65a也可以扩大前后n个帧来提取。另外,n是任意的数。
[0147]
例如,判定部65a参照由第二识别部64得到的局部版模型58的技巧识别结果,确定被识别为技巧的“开头帧(744)、最终帧(779)、识别结果(iii-95)”。接着,判定部65a参照由第一识别部63得到的全身版模型57的技巧识别结果,确定“开头帧(743)、最终帧(761)、识
别结果(iii-82)”和“开头帧(761)、最终帧(768)、识别结果(运动b)”,来作为与被局部版模型58识别为技巧的“开头帧(744)、最终帧(779)”对应的识别结果。
[0148]
然后,判定部65a参照选择信息56,确定与被局部版模型58识别出的技巧(iii-95)对应的选择等级“2”和与被全身版模型57识别出的技巧(iii-82)对应的选择等级“0”。在此,判定部65a判定为优先使用选择等级高的局部版模型58的识别结果,并将该结果输出到整合部65b。另外,判定部65a在全身版模型57的识别结果的选择等级高的情况下,采用第二识别部64的技巧识别结果,并将该结果发送到评分装置90。
[0149]
整合部65b是对基于全身版模型57的支撑位置的估计结果和基于局部版模型58的支撑位置的估计结果进行整合的处理部。具体而言,整合部65b在由判定部65a判定为优先使用第二识别部64的技巧识别结果的情况下,执行支撑位置的整合,其中,第二识别部64使用局部版模型58。即,整合部65b将使用了全身版模型57的支撑位置的估计结果中的、在被优先使用的技巧的识别中使用的帧之间的支撑位置的估计结果置换为局部版模型58的估计结果。
[0150]
首先,整合部65b根据全身版模型57的估计结果来确定成为置换对象(整合目标)的对应部分。图25是说明基于全身版模型57的支撑位置的估计结果中的、要进行整合的对象的估计结果的图。如图25所示,整合部65b在使用全身版模型57估计出的支撑位置的估计结果中,确定与在图24中被确定为优先使用的技巧的识别结果“iii-95”对应的帧744~帧779。
[0151]
接着,整合部65b确定局部版模型58的估计结果中的、要对全身版模型57的估计结果进行更新的对应部分(置换对象)。图26是说明基于局部版模型58的支撑位置的估计结果中的成为整合对象的估计结果的图。如图26所示,整合部65b在由第二估计部64a使用局部版模型58估计出的支撑位置的估计结果中,确定与在图24中被确定为优先使用的技巧的识别结果“iii-95”对应的帧744~帧779。
[0152]
此时,整合部65b将如下范围内的帧选择为对象帧,该范围是从到开头帧为止的手处于其中的连续帧中的最早的帧起到最终帧以后的手处于其中的连续帧中的最晚的帧为止的范围。也就是说,在图25的例子中,关于右手,因为从开头帧744到比开头帧744靠前的帧742为止是相同的估计结果“右手位置=a5”,且最终帧779之后的推定结果与到前面的帧742为止的推定结果不同,因此整合部65b将“帧742~帧779”确定为置换对象。
[0153]
同样地,关于左手,因为从开头帧744到比开头帧744靠前的帧728为止是相同的估计结果“右手位置=a5”,且到比最终帧779靠后的帧798为止是相同的估计结果“右手位置=a5”,因此整合部65b将“帧728~帧789”确定为置换对象。
[0154]
然后,整合部65b将在图25中确定的全身版模型57的估计结果置换为在图26中确定的局部版模型58的估计结果,从而对支撑位置的估计结果进行整合。图27是说明支撑位置的整合的图。如图27所示,整合部65b以局部版模型58的估计结果的右手的支撑位置“帧742~帧779”和左手的支撑位置“帧728~帧789”对全身版模型57的估计结果中的双手的支撑位置“帧744~帧779”进行置换。
[0155]
此时,与要置换的全身版模型57的估计结果的范围相比,作为置换对象的局部版模型58的估计结果的范围更宽,但由于针对该范围判定为了使局部版模型58优先,因此整合部65b扩展全身版模型57的置换对象的范围。
[0156]
也就是说,如图27所示,针对右手的支撑位置,整合部65b将全身版模型57的估计结果的“帧742~帧779”置换为局部版模型58的估计结果的“帧742~帧779”。另外,针对左手的支撑位置,整合部65b将全身版模型57的估计结果的“帧728~帧789”置换为局部版模型58的估计结果的“帧728~帧789”。
[0157]
返回图16,再识别部65c是使用由整合部65b生成的整合结果来执行技巧的再识别的处理部。若以上述例子进行说明,则再识别部65c使用由第一估计部63a利用全身版模型57估计出的支撑位置中的对应帧如图27所示那样被更新后的支撑位置,通过与第一技巧识别部63b相同的方法来执行技巧的识别。
[0158]
也就是说,再识别部65c使用新生成的每个帧的双手的支撑位置的估计结果,再次执行表演整体的技巧识别。图28是说明整合后的技巧的再识别结果的图。如图28所示,若对整合之前和之后的技巧识别结果进行比较,则可知从开头帧“743”到最终帧“761”的识别结果从“iii-82”变更为了“iii-95”。这样,再识别部65c基本上使用全身版模型57的估计结果进行技巧识别,但能够将全身版模型57的估计结果中的可靠性低的帧置换为局部版模型58的估计结果,从而执行与表演者1的一系列的表演有关的技巧识别。
[0159]
(评分装置90的结构)
[0160]
图29是示出实施例1的评分装置90的功能结构的功能框图。如图29所示,评分装置90具有通信部91、存储部92、控制部94。通信部91从识别装置50接收技巧的识别结果、手腕的支撑位置的估计结果、表演者的骨骼信息(3维的骨骼位置信息)等。
[0161]
存储部92对数据、控制部94执行的程序等进行存储。例如,存储部92由存储器、硬盘等来实现。该存储部92存储技巧信息93。技巧信息93是将技巧的名字、难易度、得分、各关节的位置、关节的角度、评分规则等对应起来了的信息。另外,在技巧信息93中包含用于评分的其他各种信息。
[0162]
控制部94是控制评分装置90整体的处理部,例如能够通过处理器等来实现。该控制部94具有评分部95和输出控制部96,并且按照从识别装置50输入的信息来进行表演者的评分等。此外,评分部95和输出控制部96也能够通过处理器等电子电路或处理器等所具有的进程来实现。
[0163]
评分部95是执行表演者的技巧的评分、表演者的表演的评分的处理部。具体而言,评分部95将从识别装置50随时发送的技巧的识别结果、手腕的支撑位置的估计结果、表演者的骨骼信息等与技巧信息93进行比较,从而执行表演者1所表演的技巧、表演的评分。例如,评分部95计算d得分或e得分。然后,评分部95将评分结果输出到输出控制部96。另外,评分部95能够使用广泛应用的评分规则来执行评分。
[0164]
输出控制部96是将评分部95的评分结果等显示于显示器等的处理部。例如,输出控制部96从识别装置50取得由各3d激光传感器拍摄到的距离图像、3维的骨骼信息、表演者1在表演中的各图像数据、评分结果等各种信息,并将这些信息显示于规定的画面。
[0165]
[学习处理的流程]
[0166]
图30是示出实施例1的学习处理的流程的流程图。另外,各模型的学习可以并行执行,也可以依次执行。
[0167]
如图30所示,学习装置10的取得部21取得各骨骼数据15所包含的各骨骼信息(s101),第一学习处理部22或第二学习处理部23执行用于生成两手腕的支撑位置的准确信
息的标注(annotation)(s102)。
[0168]
接着,第一学习处理部22或第二学习处理部23通过分割成一定区间的帧,执行填充,从而执行各模型用的各学习数据的整形(s103)。然后,第一学习处理部22或第二学习处理部23将学习数据分割为用于训练的各模型用的各学习用数据(训练数据)和用于评价的各模型用的评价用数据(s104)。
[0169]
然后,第一学习处理部22或者第二学习处理部23执行各学习数据的扩展(s105),该扩展包括:按鞍马的器具的每个坐标轴旋转或反转、随机噪声的追加、支撑位置的准确值的分布调整等。接着,第一学习处理部22或者第二学习处理部23执行包含归一化、标准化等的尺度调整(s106)。
[0170]
然后,第一学习处理部22或第二学习处理部23决定作为学习对象的各模型的算法、网络、超参数等,并使用各学习数据来执行各模型的学习(s107)。此时,第一学习处理部22或第二学习处理部23针对每1个时期(epoch),使用评价用数据来评价学习中的各模型的学习精度(评价误差)。
[0171]
然后,在满足学习次数超过阈值、或者评价误差为一定值以下等规定条件时,第一学习处理部22或者第二学习处理部23结束学习(s108)。然后,第一学习处理部22或第二学习处理部23选择评价误差成为最小时的各模型(s109)。
[0172]
[自动评分处理]
[0173]
图31是示出实施例1的自动评分处理的流程的流程图。此外,在此,作为一例,对在表演结束后执行自动评分处理的例子进行说明,但也能够在表演过程中执行。
[0174]
如图31所示,当表演开始时(s201:是),识别装置50取得包含3d激光传感器5拍摄到的图像的帧(s202)。
[0175]
接着,当取得帧时(s202:是),识别装置50对帧数进行累加(s203),取得骨骼信息等,并将帧编号对应起来进行管理(s204)。在此,识别装置50反复进行s201后续的步骤,直到表演结束为止(s205:否)。
[0176]
然后,当表演结束时(s205:是),识别装置50执行类别分类处理,使用拍摄到的各帧中的双手的支撑位置的估计及各模型的估计结果来执行临时技巧识别(s206)。进而,识别装置50使用临时技巧识别的结果来执行整合处理(s207)。
[0177]
然后,识别装置50使用整合结果、骨骼数据55内的骨骼信息等,检测表演者的身躯的位置、姿势,执行正面支撑标志或落地标志的设定、分节点的判断、基本运动的判定等,执行表演者1所表演的技巧的再识别(s208)。
[0178]
然后,评分装置90使用再识别出的技巧等来判定难易度(s209),评价表演实施分数并计算出e得分(s210)。然后,评分装置90显示评价结果(s211),执行包括用于评分的各种标志、计数的复位等在内的结束处理(s212)。
[0179]
(类别分类处理)
[0180]
图32是示出类别分类处理的流程的流程图。该处理在图31的s206中执行。
[0181]
如图32所示,第一识别部63和第二识别部64从所取得的骨骼数据35等中提取时间序列的骨骼信息(s301),与学习时同样地,执行填充等数据整形(s302),并执行尺度调整(s303)。此外,第一识别部63提取全身(18个关节)的骨骼信息,第二识别部64提取上述的6个关节的骨骼信息。
[0182]
然后,第一识别部63将提取出的骨骼信息输入到学习完毕的全身版模型57来执行类别分类(s304)。接着,第一识别部63通过类别分类来估计表演者1的双手的支撑位置(s305),并将骨骼信息(帧)和估计出的双手的支撑位置对应起来进行保存(s306)。
[0183]
另一方面,第二识别部64将提取出的骨骼信息输入到学习完毕的局部版模型58来执行类别分类(s307)。接着,第二识别部64通过类别分类来估计表演者1的双手的支撑位置(s308),并将骨骼信息(帧)和估计出的双手的支撑位置对应起来进行保存(s309)。
[0184]
然后,在对所有帧执行了类别分类之前(s310:否),重复s301后续的步骤,当对所有帧执行了类别分类时(s310:是),结束类别分类处理。
[0185]
(整合处理)
[0186]
图33是示出整合处理的流程的流程图。该处理在图31的s207中执行。
[0187]
如图33所示,第一识别部63使用全身版模型57的估计结果等来执行技巧识别(临时技巧识别1)(s401),第二识别部64使用局部版模型58的估计结果等来执行技巧识别(临时技巧识别2)(s402)。
[0188]
接着,结果整合部65确定临时技巧识别1的各技巧的选择等级(s403),并确定临时技巧识别2的各技巧的选择等级(s404)。然后,结果整合部65根据临时技巧识别2的识别结果来确定技巧和与该技巧对应的帧(s405)。接着,结果整合部65根据临时技巧识别1的识别结果,确定与根据临时技巧识别2确定出的帧对应的帧和识别出的技巧(s406)。
[0189]
然后,结果整合部65将根据临时技巧识别2确定出的技巧的选择等级与根据临时技巧识别1确定出的技巧的选择等级进行比较(s407)。在此,在临时技巧识别1的技巧的选择等级为临时技巧识别2的技巧的选择等级以上的情况下(s408:是),结果整合部65选择临时技巧识别1的结果(s409)。
[0190]
另一方面,在临时技巧识别1的技巧的选择等级低于临时技巧识别2的技巧的选择等级的情况下(s408:否),结果整合部65使用局部版模型58的估计结果(支撑位置)来执行估计出的支撑位置的整合(s410)。
[0191]
然后,结果整合部65使用整合后的支撑位置来执行技巧的再识别(s411)。然后,在针对由临时技巧识别2识别出的各技巧的比较结束之前(s412:否),结果整合部65重复s405后续的步骤。另一方面,当针对由临时技巧识别2识别出的全部技巧的比较结束时(s412:是),结果整合部65将结束的技巧识别的结果向评分装置90输出(s413)。
[0192]
[效果]
[0193]
如上所述,识别装置50能够使用类别分类器来确定支撑位置,该类别分类器不仅将如表演鞍马时的手腕那样成为识别对象的关节的位置信息作为输入,还将头、肩、脊柱、肘、腰、膝、脚踝这样的与人的动作有关的关节位置的时间序列信息作为输入。另外,识别装置50通过使用全身版模型57和局部版模型58,不仅能够根据全身的骨骼信息来识别技巧,还能够根据与技巧相关联的一部分骨骼信息来识别技巧,因此即使在产生了学习数据中不包含的未知的姿势或动作的情况下,与使用了一个模型的技巧识别相比,也能够执行高精度的技巧识别。
[0194]
例如,识别装置50使用全身版模型57和局部版模型58,针对学习完毕的技巧,使用全身版模型57的结果来执行技巧识别,针对未学习的技巧,使用局部版模型58的结果来执行技巧识别,其中,全身版模型57使用了全身的关节坐标,局部版模型58使用了支撑部位附
近的关节坐标。其结果是,能够正确地识别未学习的技巧的一部分,而不会使原本正确的技巧的识别恶化。
[0195]
即,自动评分系统通过将使用的关节不同的多个学习结果的模型进行并用,并且根据运动、姿势的学习状况而分开使用并进行整合,能够实现更稳健的支撑位置识别及技巧识别。因此,在自动评分系统中,能够使用表演者1的骨骼信息、正确的支撑位置来识别表演,能够提高识别精度。此外,通过提高识别精度,能够向裁判提供准确的自动评分结果,能够确保评分的公平性和正确性。
[0196]
实施例2
[0197]
[整合处理的其他例]
[0198]
例如,在上述的支撑位置的整合中,如果多个模型的支撑位置的识别结果混合存在,则也考虑会发生如下状况:作为要判断的对象的技巧的前后的技巧(没有意图的技巧)甚至也根据学习状况而发生变化。在这种情况下,存在已经正确识别出的前后的技巧被改写为错误的技巧的风险,因此在这种情况下选择未发生变化的一方。
[0199]
图34是说明实施例2的整合处理的图。如图34所示,假设识别装置50的结果整合部65将使用了基于全身版模型57的支撑位置的估计结果的技巧识别(临时技巧识别)的结果中的、从帧743到帧768的范围判定为整合对象。在该从帧743到帧768的范围中,识别出了技巧“iii-82”,在该帧范围之前识别出了技巧“ii-1”,在该帧范围之后识别出了技巧“ii-13”。
[0200]
然后,如图34的(a)所示,作为使用了整合后的支撑位置的技巧识别的结果,在整合对象帧的前后的技巧识别结果在整合前后未发生变化的情况下,结果整合部65采用使用了整合后的支撑位置的技巧识别的结果。具体而言,由于在包含整合对象帧的从帧744到帧779中识别为技巧“iii-95”,因此技巧识别的结果在整合前后发生了变更。另外,在技巧“iii-95”之前,与整合前同样是技巧“ii-1”,在技巧“iii-95”之后,与整合前同样是技巧“ii-13”。
[0201]
其结果是,结果整合部65判定为已经正确识别出的前后的技巧保持原样且精度低的整合对象部分的技巧被进行了变更,结果整合部65将使用了整合后的支撑位置的技巧识别的结果发送到评分装置90。
[0202]
另一方面,如图34的(b)所示,作为使用了整合后的支撑位置的技巧识别的结果,在整合对象帧的前后的技巧识别结果在整合前后发生了变化的情况下,结果整合部65采用使用了整合前的全身版模型57的支撑位置的技巧识别的结果。具体而言,由于在包含整合对象帧的从帧744到帧779中识别为技巧“iii-95”,因此技巧识别的结果在整合前后发生了变更。另外,在技巧“iii-95”之前,与整合前同样是技巧“ii-1”,但在技巧“iii-95”之后是技巧“ii-1”,其与整合前不同。
[0203]
其结果是,结果整合部65判定为已经正确识别出的前后的技巧甚至也被进行了变更且执行了错误的技巧识别的可能性高,结果整合部65将使用了整合前的全身版模型57的支撑位置的技巧识别的结果发送到评分装置90。
[0204]
这样,识别装置50通过利用所使用的关节不同的多个模型分别擅长的部分来提高识别精度,另一方面,能够在判定因整合导致的可靠性的降低的基础上,执行最终的技巧的识别。
[0205]
实施例3
[0206]
另外,至此对本发明的实施例进行了说明,但本发明除了上述的实施例以外,也可以通过各种不同的方式来实施。
[0207]
[应用例]
[0208]
在上述实施例中,以体操竞技为例进行了说明,但并不限定于此,也能够应用于选手进行一系列的技巧而裁判进行评分的其他竞技。作为其他竞技的一例,有花样滑冰、新体操、竞技啦啦队、游泳的跳入、空手的形式、猫跳空中滑雪(mogul air)等。另外,在上述实施例中,对估计双手的手腕的支撑位置的例子进行了说明,但并不限定于此,上述实施例也能够应用于18个关节中的任意关节的关节位置、关节间的位置等的估计。
[0209]
[3d激光传感器]
[0210]
3d激光传感器5是摄影装置的一例,也可以使用摄像机等。在使用摄像机的情况下,距离图像13和距离图像53成为rgb图像。作为从rgb图像获得骨骼信息的方法,也能够使用openpose等公知的技术。
[0211]
[骨骼信息]
[0212]
另外,在上述实施例中,作为骨骼信息的一例,例示出了各关节的位置而进行了说明,但并不限定于此,能够采用各关节间的朝向(矢量)、各关节的角度、手脚的朝向、脸的朝向等。另外,对在局部版模型17的学习中使用6个关节的骨骼信息的例子进行了说明,但关节的数量、所使用的关节能够任意地设定变更,优选选择对技巧的难易度、完成结果等产生影响的关节。
[0213]
另外,用于全身版模型的学习的关节的数量也不限于18个关节,能够任意地变更。同样地,用于局部版模型的学习的关节的数量也不限于6个关节,能够任意地变更,但优选用于局部版模型的学习的关节数量比用于全身版模型的学习的关节数量少。
[0214]
[数值等]
[0215]
在上述实施例中使用的数值等仅为一例,并不限定实施例,能够任意地进行设定变更。另外,技巧名称、帧的数量、类别的数量等也是一例,能够任意地进行设定变更。另外,模型不限于神经网络,能够使用各种机器学习或深层学习。另外,对处理的流程进行说明的各流程图也能够在不矛盾的范围内变更顺序。
[0216]
[类别分类]
[0217]
在上述实施例中,对使用各模型来估计特定关节的支撑位置的例子进行了说明,但并不限定于此,其中,该各模型应用了神经网络等机器学习。例如,通过对使用了18个关节的规则进行定义并使用该定义,也能够根据18个关节的骨骼信息来估计两手腕的位置而不使用上述模型,其中,在该18个关节的规则中,将作为估计对象的两手腕的位置与剩余的16个关节位置对应起来。同样地,也能够依照使用了一部分关节的定义来估计两手腕的位置,其中,在该使用了一部分关节的定义中,将作为估计对象的两手腕的位置与上述的6个关节位置对应起来。
[0218]
[支撑位置的整合]
[0219]
在上述实施例中,对在使用各模型的支撑位置的估计结果进行技巧识别(临时技巧识别)之后执行整合处理的例子进行了说明,但并不限定于此。例如,也能够比较各模型所估计出的支撑位置来进行整合。作为一例,在参照全身版模型57的支撑位置而估计出了
按照时间序列的顺序不可能存在的支撑位置的情况下,也能够仅将该部分置换为局部版模型58的估计结果。
[0220]
例如,在发生了作为物理连续性不成立的状况的情况下,也能够置换为局部版模型58的估计结果,该状况例如是在右手的支撑位置连续成为类别1(a1)的状态下类别5(a5)突然连续出现规定次数等。此外,不成立的状况也能够预先规则化来定义。
[0221]
[帧数]
[0222]
在上述实施例中,使用30等预先设定的帧数作为时间序列的帧数而执行了各模型的学习、基于各模型的估计,但并不限定于此。例如,能够使用表演、技巧等规定的动作单位的帧数来执行各模型的学习、基于各模型的估计。
[0223]
[选择等级]
[0224]
例如,如果在连续的长时间运动的中途弄错支撑位置的类别,则技巧有时会在错误的前后部分地成立。在这种情况下,一般是难度比连续的长时间运动低的技巧。因此,在使用多个学习结果来识别支撑位置的类别时,在同一区间内识别出了长时间运动和短时间运动的情况下,长时间运动为正确的可能性更高。可以考虑这个情况或技巧的类型(例如,是仅转体数多1次的相同类型的技巧等)来设定选择等级。
[0225]
[系统]
[0226]
关于包括在上述内容中或附图中示出的处理步骤、控制步骤、具体的名称、各种数据或参数在内的信息,除了特别记载的情况以外,能够任意变更。
[0227]
另外,图示的各装置的各结构要素是功能概念性的,不一定需要在物理上如图示那样构成。即,各装置的分散、整合的具体方式不限于图示的方式。也就是说,能够根据各种负荷、使用状况等,以任意的单位在功能性上或物理结构上对其全部或一部分进行分散/整合来构成。另外,各3d激光传感器可以内置于各装置,也可以作为各装置的外部装置通过通信等来连接。
[0228]
例如,技巧识别和组合评价也能够通过不同的装置来实施。另外,学习装置10、识别装置50、评分装置90也能够通过任意组合而成的装置来实现。另外,取得部61是取得部的一例,第一估计部63a是第一估计部的一例,第二估计部64a是第二估计部的一例。判定部65a是确定部的一例,再识别部65c是识别部和输出部的一例。
[0229]
[硬件]
[0230]
接着,对学习装置10、识别装置50、评分装置90等计算机的硬件结构进行说明。此外,各装置具有相同的结构,因此在此,作为计算机100进行说明,具体例示出识别装置50。
[0231]
图35是示出硬件结构例的图。如图35所示,计算机100具有通信装置100a、hdd(hard disk drive:硬盘驱动器)100b、存储器100c和处理器100d。另外,图32所示的各部通过总线等相互连接。此外,hdd也可以使用ssd(solid state drive:固态硬盘)等存储装置。
[0232]
通信装置100a是网络接口卡等,与其他服务器进行通信。hdd100b存储用于使图16等所示的功能工作的程序或db(data base:数据库)。
[0233]
处理器100d从hdd100b等读出用于执行与图16所示的各处理部相同的处理的程序并将该程序在存储器100c中展开,由此使用于执行在图16等中说明的各功能的进程工作。即,该进程执行与识别装置50所具有的各处理部相同的功能。具体而言,以识别装置50为例,处理器100d从hdd100b等读出具有与取得部61、数据生成部62、第一识别部63、第二识别
部64、结果整合部65等相同的功能的程序。并且,处理器100d执行进程,该进程用于执行与取得部61、数据生成部62、第一识别部63、第二识别部64、结果整合部65等相同的处理。
[0234]
这样,计算机100作为通过读出并执行程序来执行识别方法的信息处理装置而进行动作。另外,计算机100通过介质读取装置从记录介质中读出上述程序,并执行读出的上述程序,由此也能够实现与上述实施例相同的功能。另外,在其他实施例中提到的该程序并不限定于由计算机100执行。例如,在其他计算机或服务器执行程序的情况下,或者在这些计算机或服务器协作执行程序的情况下,也能够同样地应用本发明。
[0235]
附图标记说明
[0236]
10 学习装置
[0237]
11 通信部
[0238]
12 存储部
[0239]
13 距离图像
[0240]
14 骨骼定义
[0241]
15 骨骼数据
[0242]
16 全身版模型
[0243]
17 局部版模型
[0244]
20 控制部
[0245]
21 取得部
[0246]
22 第一学习处理部
[0247]
22a 第一生成部
[0248]
22b 第一学习部
[0249]
23 第二学习处理部
[0250]
23a 第二生成部
[0251]
23b 第二学习部
[0252]
50 识别装置
[0253]
51 通信部
[0254]
52 存储部
[0255]
53 距离图像
[0256]
54 骨骼定义
[0257]
55 骨骼数据
[0258]
56 选择信息
[0259]
57 全身版模型
[0260]
58 局部版模型
[0261]
60 控制部
[0262]
61 取得部
[0263]
62 数据生成部
[0264]
63 第一识别部
[0265]
63a 第一估计部
[0266]
63b 第一技巧识别部
[0267]
64 第二识别部
[0268]
64a 第二估计部
[0269]
64b 第二技巧识别部
[0270]
65 结果整合部
[0271]
65a 判定部
[0272]
65b 整合部
[0273]
65c 再识别部
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1