使用深度学习进行显微图像的数字染色的方法和系统
使用深度学习进行显微图像的数字染色的方法和系统
1.相关申请
2.本技术要求于2020年7月29日提交的美国临时专利申请第63/058,329号和于2019年12月23日提交的美国临时专利申请第62/952,964号的优先权,这些申请的全部内容通过引用结合于此。根据35u.s.c.
§
119和任何其他可适用的法规要求优先权。
技术领域
3.本技术领域总体上涉及用于对未染色的(即,无标记的)组织进行成像的方法和系统。具体地,本技术领域涉及利用深度神经网络学习对未染色或未标记组织的图像进行数字或虚拟染色的显微法和系统。神经网络中的深度学习是一类机器学习算法,用于将无标记组织切片的图像数字染色成等同于被染色或标记的同一样本的显微图像的图像。
背景技术:
4.组织样本的显微成像是用于诊断各种疾病的基础工具并且形成病理学和生物科学的主力。组织切片的临床建立的黄金标准图像是耗时费力过程的结果,该过程包括组织标本被福尔马林固定石蜡包埋(ffpe),切成薄片(通常约2μm至10μm),标记/染色并且安装在载玻片上,然后接着是使用例如明视野显微镜对其进行显微成像。所有这些步骤使用多种试剂并且给组织带来不可逆的影响。近来已经努力使用不同的成像模态来改变该工作流程。已经尝试使用基于例如双光子荧光、二次谐波生成、三次谐波生成以及拉曼散射的非线性显微法使对新鲜的非石蜡包埋的组织样本进行成像。其他尝试已使用可控的超连续光源来获取多模图像用于新鲜的组织样本的化学分析。这些方法需要使用超快激光器或超连续光源,这在大多数设置中可能不容易获得,并且由于较弱的光信号而需要相对长的扫描时间。除了这些之外,也已经出现了通过对染色的样本使用uv激发或通过利用生物组织在短波长下的荧光发射使非切片的组织样本成像的其他显微法。
5.事实上,荧光信号通过使用从内源性荧光团发射的荧光为使组织样本成像创造了一些难得的机会。已经证明,此类内源性荧光特征携带有用的信息,该信息可以被映射到生物标本的功能和结构特性,并且因此已经被广泛地用于诊断和研究目的。这些努力的一个主要焦点领域是在不同条件下对不同生物分子与其结构特性之间的关系的光谱研究。这些良好表征的生物成分中的一些包括维生素(例如,维生素a、核黄素、硫胺素)、胶原蛋白、辅酶、脂肪酸等。
6.虽然以上讨论的一些技术具有使用各种对比机制区别例如组织样本中的细胞类型和亚细胞组分的独特能力,但病理学家以及肿瘤分类软件通常被训练用于检查“黄金标准”染色的组织样本以做出诊断决定。由此部分启示,已经增强上述技术中的一些以产生伪苏木精和伊红(h&e)图像,这些图像是基于线性近似,该线性近似使用表示包埋在组织中的各种染料的平均光谱响应的在经验上确定的常数将图像的荧光强度与每组织体积的染料浓度相关。这些方法还使用外源染色来增强荧光信号对比度,以便产生组织样本的虚拟h&e图像。
技术实现要素:
7.在一个实施方式中,一种生成样本的虚拟染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用多个匹配的免疫组织化学(ihc)染色的显微图像或图像块及其在免疫组织化学(ihc)染色之前获得的同一样本的对应的荧光寿命(flim)显微图像或图像块来训练该训练的深度神经网络。使用荧光显微镜和至少一个激发光源获得样本的荧光寿命(flim)图像,并将样本的荧光寿命(flim)图像输入至训练的深度神经网络。该训练的深度神经网络输出样本的虚拟染色的显微图像,该虚拟染色的显微图像基本上等同于已经免疫组织化学(ihc)染色的同一样本的对应图像。
8.在另一实施方式中,一种对利用非相干显微镜获得的样本的显微图像进行虚拟自动聚焦的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用用作深度神经网络的输入图像的多对离焦和/或对焦显微图像或图像块以及利用非相干显微镜获得的用作用于训练深度神经网络的真值图像的同一样本的对应或匹配对焦显微图像或图像块来训练该训练的深度神经网络。使用非相干显微镜获得样本的离焦或对焦图像。然后,将从非相干显微镜获得的样本的离焦或对焦图像输入至训练的深度神经网络。训练的深度神经网络输出具有改善的聚焦的输出图像,该输出图像基本上匹配由非相干显微镜获取的同一样本的对焦图像(真值)。
9.在另一实施方式中,一种利用非相干显微镜生成样本的虚拟染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用多对离焦和/或对焦显微图像或图像块训练该训练的深度神经网络,多对离焦和/或对焦显微图像或图像块用作深度神经网络的输入图像,并且均与在化学染色过程后利用非相干显微镜获得的生成用于训练深度神经网络的真值图像的同一样本的对应的对焦显微图像或图像块匹配。使用非相干显微镜获得样本的离焦或对焦图像,并且将从非相干显微镜获得的样本的离焦或对焦图像输入至训练的深度神经网络。训练的深度神经网络输出样本的输出图像,该输出图像具有改善的聚焦并且被虚拟染色为基本上类似于且匹配在化学染色过程之后通过非相干显微镜获得的同一样本的化学染色的对焦图像。
10.在另一实施方式中,一种生成样本的虚拟染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用多对染色的显微图像或图像块训练该训练的深度神经网络,多对染色的显微图像或图像块被至少一种算法虚拟染色或被化学染色成具有第一染色剂类型,并且均与被至少一种算法虚拟染色或被化学染色成具有另一不同的染色剂类型的同一样本的对应的染色的显微图像或图像块匹配,该多对染色的显微图像或图像块构成用于训练深度神经网络的真值图像以将利用第一染色剂类型组织化学或虚拟染色的输入图像转换成利用第二染色剂类型虚拟染色的输出图像。获得利用第一染色剂类型染色的样本的组织化学或虚拟染色的输入图像。样本的组织化学或虚拟染色的输入图像被输入至训练的深度神经网络,该训练的深度神经网络将利用第一染色剂类型染色的输入图像转换成利用第二染色剂类型虚拟染色的输出图像。训练的深度神经网络输出样本的输出图像,该输出图像被虚拟染色为基本上类似于并匹配在化学染色过程之后由非相干显微镜获得的利用第二染色剂类型染色的同一样本的化学染色图像。
11.在另一实施方式中,一种使用单个训练的深度神经网络生成具有多种不同的染色剂的样本的虚拟染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用用作用于训练深度神经网络的真值图像的使用多个化学染色剂的多个匹配的化学染色显微图像或图像块及其在化学染色之前获得的用作用于训练深度神经网络的输入图像的同一样本的对应和匹配的荧光显微图像或图像块来训练该训练的深度神经网络。使用荧光显微镜和至少一个激发光源获得样本的荧光图像。应用一个或多个类条件矩阵调节训练的深度神经网络。样本的荧光图像与一个或多个类条件矩阵一起被输入至训练的深度神经网络。训练和调节的深度神经网络输出具有一种或多种不同的染色剂的样本的虚拟染色的显微图像,并且其中,输出图像或其子区域基本上等同于利用对应的一种或多种不同的染色剂进行组织化学染色的同一样本的对应显微图像或图像子区域。
12.在另一实施方式中,一种使用单个训练的深度神经网络生成具有多种不同的染色剂的样本的虚拟染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的训练的深度神经网络,其中,利用使用多种化学染色剂的多个匹配的化学染色的显微图像或图像块及其在化学染色之前获得的同一样本的对应的显微图像或图像块来训练该训练的深度神经网络。使用显微镜获得样本的输入图像。应用一个或多个类条件矩阵调节训练的深度神经网络。样本的输入图像连同一个或多个类条件矩阵一起被输入至训练的深度神经网络。训练和调节的深度神经网络输出具有一种或多种不同的染色剂的样本的虚拟染色的显微图像,并且其中,输出图像或其子区域基本上等同于利用对应的一种或多种不同的染色剂进行组织化学染色的同一样本的对应显微图像或图像子区域。
13.在另一实施方式中,一种生成样本的虚拟去染色的显微图像的方法包括:提供由图像处理软件使用计算装置的一个或多个处理器执行的第一训练的深度神经网络,其中,利用用作深度神经网络的训练输入的多个匹配的化学染色的显微图像或图像块及其在化学染色之前获得的一个或多个同一样本的对应非染色显微图像或图像块来训练第一训练的深度神经网络,该多个匹配的化学染色的显微图像或图像块构成在深度神经网络的训练期间的真值。使用显微镜获得化学染色样本的显微图像。化学染色样本的图像被输入至第一个训练的深度神经网络。第一训练的深度神经网络输出样本的虚拟去染色的显微图像,该虚拟去染色的显微图像基本上等同于在任何化学染色之前或没有任何化学染色时获得的同一样本的对应图像。
附图说明
14.图1示意性地示出了根据一个实施方式的用于从样本的未染色显微镜图像生成样本的数字/虚拟染色的输出图像的系统。
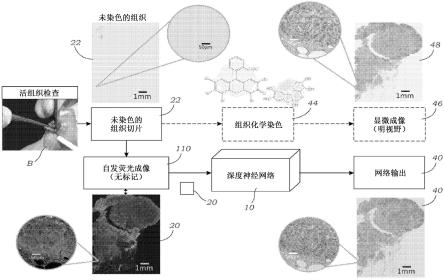
15.图2示出了使用未染色组织的荧光图像的基于深度学习的数字/虚拟组织学染色操作的示意性表示。
16.图3a至图3h示出了与化学染色的h&e样本匹配的数字/虚拟染色结果。前两(2)列(图3a和图3e)示出了未染色的唾液腺组织切片的自发荧光图像(用作深度神经网络的输入),并且第三列(图3c和图3g)示出了数字/虚拟染色结果。最后一列(图3d和图3h)示出了在组织化学染色过程之后同一组织切片的明视野图像。图3c和图3d的评估都证明了皮下纤
维-脂肪组织内的小岛浸润肿瘤细胞。注意,在两个面板中都清楚地理解了包括核仁(图3c和图3d中的箭头)和染色质纹理的区别的核细节。类似地,在图3g和图3h中,h&e染色剂表明浸润性鳞状细胞癌。在两种染色剂/面板中都可清晰识别在相邻基质中具有水肿粘液质变化(图3g和图3h中的星号)的促结缔组织增生反应。
17.图4a至图4h示出了与化学染色的琼斯(jones)jones样本匹配的数字/虚拟染色结果。前两(2)列(图4a和图4e)示出了未染色的肾组织切片的自发荧光图像(用作深度神经网络的输入),并且第三列(图4c和图4g)示出了数字/虚拟染色结果。最后一列(图4d和图4h)示出了在组织化学染色过程之后同一组织切片的明视野图像。
18.图5a至图5p示出了与肝脏和肺组织切片的马松(masson)三色染色剂匹配的数字/虚拟染色结果。前两(2)列示出了用作深度神经网络的输入的未染色的肝脏组织切片(第一行和第二行
–
图5a、图5b、图5e、图5f)和未染色的肺组织切片(第三行和第四行
–
图5i、图5j、图5m、图5n)的自发荧光图像。第三列(图5c、图5g、图5k、图5o)示出了这些组织样本的数字/虚拟染色结果。最后一列(图5d、图5h、图5l、图5p)示出了在组织化学染色过程之后同一组织切片的明视野图像。
19.图6a示出了用于随机初始化和迁移学习初始化的组合损失函数对迭代次数的曲线图。图6a示出了如何使用迁移学习实现优越的收敛。使用从唾液腺组织切片学习的权重和偏差初始化新的深度神经网络,以实现利用h&e对甲状腺组织的虚拟染色。与随机初始化相比,迁移学习实现更快的收敛,还实现较低的局部最小值。
20.图6b示出了用于随机初始化和迁移学习两者的学习过程的不同阶段的网络输出图像,以更好地示出迁移学习将所呈现的方法转换成新组织/染色剂组合的影响。
21.图6c示出了对应的h&e化学染色的明视野图像。
22.图7a示出了仅使用dapi通道的皮肤组织的虚拟染色(h&e染色)。
23.图7b示出了使用dapi和cy5通道的皮肤组织的虚拟染色(h&e染色)。cy5是指用于标记生物分子的远红色荧光标记花菁染料。
24.图7c示出了对应的组织学染色(即,用h&e化学染色)的组织。
25.图8示出了化学染色过程之后未染色组织样本的自发荧光图像相对于同一样本的明视野图像的视野匹配和配准过程。
26.图9示意性地示出了使用gan的虚拟染色网络的训练过程。
27.图10示出了根据一个实施方式的用于生成器和鉴别器的生成对抗网络(gan)架构。
28.图11a示出了使用未染色组织的自发荧光和荧光寿命图像的基于机器学习的虚拟ihc染色。在其使用深度神经网络模型的训练之后,训练的深度神经网络快速输出虚拟染色的组织图像,响应于未染色的组织切片的自发荧光寿命图像,绕过在组织学中使用的标准ihc染色程序。
29.图11b示出了根据一个实施方式的用于在荧光寿命成像(flim)中使用的生成器(g)和鉴别器(d)的生成对抗网络(gan)架构。
30.图12示出了与her2染色剂匹配的数字/虚拟染色结果。最左边的两列示出了未染色的人乳腺组织切片(用作深度神经网络10的输入)对于两个激发波长的自发荧光强度(第一列)和寿命图像(第二列),并且中间列示出了虚拟染色结果(虚拟染色)。最后一列示出了
在ihc染色过程(ihc染色)之后同一组织切片的明视野图像。
31.图13示出了标准(现有技术)自动聚焦方法和本文公开的虚拟聚焦方法的比较。右上部分:标准自动聚焦方法需要获取多个图像,以与自动聚焦算法一起使用,该自动聚焦算法根据预定义的标准选择最对焦的图像。相对照地,所公开的方法仅需要单个像差图像以使用训练的深度神经网络将其虚拟地重新聚焦。
32.图14示出了用于样本的各个成像平面的后成像计算自动聚焦方法的重新聚焦能力的演示,其中,z的值表示与聚焦平面相距的焦距,聚焦平面位于z=0(作为参考平面)内。可以使用在每个面板的左上角出现的并且将该图像与参考对焦图像(在z=0处)进行比较的结构相似性指数定性和定量地评估网络的重新聚焦能力。
33.图15示出了基于机器学习的方法的示意图,该方法使用类条件将多种染色剂应用于显微镜图像以产生虚拟染色图像。
34.图16示出了根据一个实施方式的示出用于显示来自训练的深度神经网络的输出图像的图形用户界面(gui)的显示器。图像的不同区域或子区域被突出显示,这些区域或子区域可以被不同的染色剂虚拟染色。这可以手动地、借助于图像处理软件自动地或这两者的一些组合(例如,混合方法)来完成。
35.图17示出了染色剂微结构的示例。诊断专家可以手动地标记未染色组织的切片。这些标记被网络用来利用所期望的染色剂对组织的不同区域进行染色。示出了组织化学染色的h&e组织的共配准图像以用于比较。
36.图18a至图18g示出了染色剂混合的示例。图18a示出了用作机器学习算法的输入的自发荧光图像。图18b示出了用于比较的组织化学染色的h&e组织的共配准图像。图18c示出了利用h&e(无jones)进行虚拟染色的肾组织。图18d示出了利用jones染色剂(无h&e)进行虚拟染色的肾组织。图18e示出了利用输入类条件比率为3:1的h&e:jones染色剂进行虚拟染色的肾组织。图18f示出了利用输入类条件比率为1:1的h&e:jones染色剂进行虚拟染色的肾组织。图18g示出了利用输入类条件比率为1:3的h&e:jones染色剂进行虚拟染色的肾组织。
37.图19a和图19b示出了对从显微镜获得的图像进行虚拟去染色(例如,染色图像到去染色图像)的另一实施方式。还示出了可选的基于机器学习的操作以利用与显微镜所获得的化学染色剂不同的化学染色剂对图像进行重新染色。这示出了虚拟去染色和重新染色。
38.图20a示出了可以生成h&e和特殊染色剂图像两者的虚拟染色网络。
39.图20b示出了用于将样式迁移到虚拟和/或组织化学染色的图像的样式迁移网络(例如,cyclegan网络)的一个实施方式。
40.图20c示出了用于训练染色剂变换网络(10
staintn
)的方案。染色剂变换被随机地给予虚拟染色的h&e组织,或给予在穿过k=8染色剂变换网络(10
styletn
)中的一个之后同一视野的图像。使用所期望的特殊染色剂(在这种情况下是pas)的完全匹配的虚拟染色的组织被用作训练该神经网络的真值。
41.图21示意性地示出了在样式变换(例如,cyclegan)的训练阶段期间由各个网络执行的变换。
42.图22a示出了用于样式变换的第一生成器网络g(x)的结构。
43.图22b示出了用于样式变换的第二生成器网络f(y)的结构。
具体实施方式
44.图1示意性地示出了用于从样本22的输入显微镜图像20输出数字染色的图像40的系统2的一个实施方式。如本文所解释的,输入图像20是未用荧光染色剂或标记染色或标记的样本22(在一个实施方式中,诸如组织)的荧光图像20。即,输入图像20是样本22的自发荧光图像20,其中,由样本22发射的荧光是包含在其中的频移光的一个或多个内源性荧光团或其他内源性发射体的结果。频移光是以不同于入射频率(或波长)的不同频率(或波长)发射的光。频移光的内源性荧光团或内源性发射体可包括分子、化合物、复合物、分子种类、生物分子、色素、组织等。在一些实施方式中,输入图像20(例如,原始荧光图像)经受选自对比度增强、对比度反转、图像滤光的一个或多个线性或非线性预处理操作。该系统包括其中包含一个或多个处理器102的计算装置100以及并入训练的深度神经网络10的图像处理软件104(例如,如在本文中一个或多个实施方式中解释的卷积神经网络)。如本文所解释的,计算装置100可包括个人计算机、膝上型计算机、移动计算装置、远程服务器等,但可以使用其他计算装置(例如,并入一个或多个图形处理单元(gpu)的装置或其他专用集成电路(asic))。gpu或asic可以用于加速训练以及最终图像输出。计算装置100可以与用于显示数字染色的图像40的监视器或显示器106相关联或连接至该监视器或显示器。显示器106可用于显示图形用户界面(gui),用户使用该gui显示和查看数字染色的图像40。在一个实施方式中,用户能够使用例如gui在用于特定样本22的多个不同的数字/虚拟染色剂之间手动触发或切换。可替换地,不同染色剂之间的触发或切换可由计算装置100自动完成。在一个优选实施方式中,训练的深度神经网络10是卷积神经网络(cnn)。
45.例如,在本文所描述的一个优选实施方式中,使用gan模型来训练该训练的深度神经网络10。在gan训练的深度神经网络10中,使用两个模型来训练。使用捕获数据分布的生成模型,而第二模型估计样本来自训练数据而不是来自生成模型的概率。关于gan的细节可以在goodfell等人的generative advancesarial nets.,advances in neural information processing systems,27,pp.2672
–
2680(2014)中找到,该申请通过引用结合于本文中。相同或不同的计算装置100可以执行深度神经网络10(例如,gan)的网络训练。例如,在一个实施方式中,可以使用个人计算机来训练gan,但是这种训练可能花费相当长的时间。为了加速该训练过程,一个或多个专用gpu可用于训练。如在本文中所解释的,在从市场上可买到的图形卡获得的gpu上执行这种训练和测试。一旦已经训练了深度神经网络10,就可以在不同计算装置110上使用或执行深度神经网络10,该不同计算装置可包括具有用于训练过程的更少计算资源的计算装置(但是gpu也可以集成到训练的深度神经网络10的执行中)。
46.图像处理软件104可使用python和tensorflow来实施,但是可使用其他软件包和平台。训练的深度神经网络10不限于特定软件平台或编程语言,并且可以使用任何数量的市场上可买到的软件语言或平台执行训练的深度神经网络10。集成有训练的深度神经网络10或者与训练的深度神经网络10协调运行的图像处理软件104可以在本地环境或移除云型环境中运行。在一些实施方式中,图像处理软件104的一些功能可以用一种特定语言或平台(例如,图像归一化)来运行,而训练的深度神经网络10可以用另一种特定语言或平台来运
行。尽管如此,这两个操作都由图像处理软件104执行。
47.如图1所示,在一个实施方式中,训练的深度神经网络10接收未标记样本22的单个荧光图像20。在其他实施方式中,例如,在使用多个激发通道(参见本文的黑色素讨论)的情况下,可以存在输入至训练的深度神经网络10的未标记样本22的多个荧光图像20(例如,每个通道一个图像)。荧光图像20可包括未标记的组织样本22的宽视野荧光图像20。宽视野旨在指示宽视野(fov)是通过扫描更小的fov获得的,其中,宽的fov在10至2,000mm2的大小范围内。例如,更小的fov可以通过扫描荧光显微镜110获得,该扫描荧光显微镜使用图像处理软件104来将更小的fov数字化地拼接在一起以创建更宽的fov。例如,宽的fov可用于获得样本22的全视野数字切片(whole slide images,wsi)。使用成像装置110获得荧光图像。对于本文所述的荧光实施方式,可包括荧光显微镜110。荧光显微镜110包括照射样本22的至少一个激发光源以及用于捕获由样本22中包含的频移光的荧光团或其他内源性发射体发射的荧光的一个或多个图像传感器(例如,cmos图像传感器)。在一些实施方式中,荧光显微镜110可包括利用处于多个不同波长或波长范围/带的激发光照射样本22的能力。这可以使用多个不同的光源和/或不同的滤光器组(例如,标准uv或近uv激发/发射滤光器组)来实现。此外,在一些实施方式中,荧光显微镜110可包括可以过滤不同发射带的多个滤光器组。例如,在一些实施方式中,可以捕获多个荧光图像20,使用不同的滤光器组在不同的发射带捕获每个荧光图像。
48.在一些实施方式中,样本22可包括布置在衬底23上或衬底中的一部分组织。在一些实施方式中,衬底23可包括光学透明衬底(例如,玻璃或塑料载玻片等)。样本22可包括使用切片机装置等切成薄切片的组织切片。组织22的薄切片可以被认为是弱散射相位对象,在明视野照明下具有有限的振幅对比度调制。可在有或没有盖玻片/盖片的情况下使样本22成像。样本可涉及冷冻切片或石蜡(蜡)切片。组织样本22可以是固定的(例如,使用福尔马林)或未固定的。组织样本22可以包括哺乳动物(例如,人或动物)组织或植物组织。样本22还可包括其他生物样本、环境样本等。示例包括颗粒、细胞、细胞器、病原体、寄生虫、真菌或其他受关注的微型对象(具有微米级尺寸或更小尺寸)。样本22可包括生物流体或组织的涂片。例如,这些涂片包括血涂片、巴氏或pap涂片。如本文所解释的,对于基于荧光的实施方式,样本22包括一个或多个天然存在的或内源性荧光团,该荧光团发出荧光并被荧光显微镜装置110捕获。当用紫外线或近紫外光激发时,大多数植物和动物组织示出一些自发荧光。内源性荧光团可包括作为示例说明的蛋白质,诸如胶原蛋白、弹性蛋白、脂肪酸、维生素、核黄素、卟啉、脂褐质、辅酶(例如,nad(p)h)。在一些可选的实施方式中,还可以添加以外源方式添加的荧光标记或者其他外源性光发射体(用于训练深度神经网络10或用于测试新样本12或用于这两者)。如本文所解释的,样本22还可包含频移光的其他内源发射体。
49.响应于输入图像20,训练的深度神经网络10输出或生成数字染色的或标记的输出图像40。数字染色的输出图像40被“染色”成已使用训练的深度神经网络10数字集成到染色的输出图像40中。在一些实施方式中,诸如那些涉及组织切片的实施方式中,训练的深度神经网络10看似熟练的观察者(例如,训练的组织病理学家)基本上等同于已经化学染色的同一组织切片样本22的对应的明视野图像。实际上,如本文所解释的,使用训练的深度神经网络10获得的实验结果显示经训练的病理学家能够用两种染色技术(化学染色对比数字/虚拟染色)并且在这些技术之间具有高度一致性地识别组织病理学特征,而无需明确的优选
染色技术(虚拟对组织学)。组织切片样本22的数字或虚拟染色看起来就像组织切片样本22已经历组织化学染色一样,虽然没有进行这样的染色操作。
50.图2示意性地示出了在典型的基于荧光的实施方式中涉及的操作。如图2所示,获得诸如未染色的组织切片的样本22。这可以通过活组织检查b等从活组织获得。然后,使用荧光显微镜110对未染色的组织切片样本22进行荧光成像,并且生成荧光图像20。然后将该荧光图像20输入至训练的深度神经网络10,然后迅速输出组织切片样本22的数字染色的图像40。该数字染色的图像40非常类似于实际组织切片样本22经受组织化学染色的同一组织切片样本22的明视野图像的外观。图2(使用虚线箭头)示出了常规过程,借此对组织切片样本22进行组织化学或免疫组织化学(ihc)染色44,随后进行常规明视野显微成像46以生成染色的组织切片样本22的常规明视野图像48。如图2所示,数字染色的图像40非常类似于实际化学染色的图像48。使用本文所述的数字染色平台获得类似的分辨率和色彩轮廓。如图1所示,该数字染色的图像40可在计算机监视器106上示出或显示,但应当理解,数字染色的图像40可在任何合适的显示器(例如,计算机监视器、平板计算机、移动计算装置、移动电话等)上显示。gui可以显示在计算机监视器106上,使得用户可以观看数字染色的图像40并且可选地与数字染色的图像40交互(例如,缩放、剪切、高亮、标记、调整曝光等)。
51.在一个实施方式中,荧光显微镜110获得未染色的组织样本22的荧光寿命图像并输出在ihc染色之后与同一视野的明视野图像48良好匹配的图像40。荧光寿命成像(flim)基于与荧光样本的激发态衰减率的差异产生图像。由此,flim是一种对比度基于独立荧光团的寿命或衰减的荧光成像技术。荧光寿命通常被定义为分子或荧光团在通过发射光子返回至基态之前保持处于激发态的平均时间。在未标记的组织样本的所有固有特性中,内源性荧光团的荧光寿命是测量荧光团在返回到基态之前保持处于激发态的时间的最有信息性的通道之一。
52.众所周知,例如黄素腺嘌呤二核苷酸(fad)和烟酰胺腺嘌呤二核苷酸(nad+或nadh)的内源性荧光发射体的寿命取决于诸如充足氧气的浸入化学环境,因此,指示在明视野或荧光显微镜技术中不明显的组织内的生理生物变化。尽管现有文献已经确认良性组织与癌组织之间的寿命变化之间密切相关,但是缺乏跨模态图像变换方法,使得病理学家或计算机软件能够基于它们所训练的颜色对比度对未标记的组织进行疾病诊断。在本发明的该实施方式中,机器学习算法(即,训练的深度神经网络10)使得能够基于荧光寿命成像对未染色的组织样本22进行虚拟ihc染色。使用该方法,可以用虚拟染色代替费力且耗时的ihc染色程序,这明显更快并且提供将允许组织保存用于进一步分析。
53.在一个实施方式中,使用未染色样本22的寿命(例如,衰减时间)荧光图像20,用作为ihc染色后同一视野的明视野图像的配对的真值图像48来训练该训练的神经网络10。在另一实施方式中,也可以使用寿命荧光图像20和荧光强度图像20的组合来训练该训练的神经网络10。一旦神经网络10已经收敛(即,被训练),其可以用于从未染色的组织样本22盲目推断新的寿命图像20,并且将它们转换或输出至染色之后的明视野图像40的等同物,而无需任何参数调整,如图11a和图11b所示。
54.为了训练人工神经网络10,使用生成对抗网络(gan)框架来执行虚拟染色。训练数据集由单个或多个激发和发射波长的多个组织切片22的自发荧光(内源性荧光团)寿命图像20组成。通过具有光子计数能力的标准荧光显微镜110扫描样本22,该标准荧光显微镜输
出每个视野的荧光强度图像20i和寿命图像20l。组织样本22还被发送到病理学实验室用于ihc染色并且由用于生成真值训练图像48的明视野显微镜扫描。同一视野的荧光寿命图像20l和明视野图像48是成对的。训练数据集由数千个这种对20l、48组成,这些对分别被用作用于训练网络10的输入和输出。通常,人工神经网络模型10在约30小时之后在两个nvidia 1080ti gpu上收敛。一旦神经网络10收敛,该方法能够实时对未标记的组织切片22进行虚拟ihc染色,如图12所示。注意,可以用荧光寿命图像20l和荧光强度图像20i来训练深度神经网络10。这在图11b中示出。
55.在另一实施方式中,提供训练的深度神经网络10a,其拍摄像差和/或离焦输入图像20,然后输出基本匹配同一视野的聚焦图像的校正图像20a。对于例如组织样本22的高质量和快速显微成像的关键步骤是自动聚焦。常规地,使用光学和算法方法的组合来执行自动聚焦。这些方法是耗时的,因为它们以多个聚焦深度使样本22成像。对更高通量显微术的不断增长的需求需要对试样的轮廓做出更多假设。换言之,人们牺牲了通常通过多焦点深度采集获得的准确度,假设在相邻的视野中试样的轮廓是均匀的。这种类型的假设经常导致图像聚焦误差。这些误差可能需要使试样重新成像,这在例如生命科学实验中不总是可行的。例如,在数字病理学中,这种聚焦误差可能延长患者疾病的诊断。
56.在该特定实施方式中,对于非相干成像模态,使用训练的深度神经网络10a来执行成像后计算自动聚焦。因此,可以与通过荧光显微术(例如,荧光显微镜)获得的图像以及其他成像模态结合使用。示例包括荧光显微镜、宽视野显微镜、超分辨率显微镜、共焦显微镜、具有单光子或多光子激发荧光的共焦显微镜、二次谐波或高谐波生成荧光显微镜、光片显微镜、flim显微镜、明视野显微镜、暗视野显微镜、结构光照明显微镜、全内反射显微镜、计算显微镜、偏光显微镜、基于合成孔径的显微镜或相衬显微镜。在一些实施方式中,训练的深度神经网络10a的输出生成聚焦于或比原始输入图像20更聚焦的修改的输入图像20a。然后,将具有改善的聚焦的该修改的输入图像20a输入到本文中描述的从第一图像模态转换成第二图像模态(例如,荧光显微术至明视野显微术)的分开训练的深度神经网络10。对此,训练的深度神经网络10a、10以“菊花链”配置耦接在一起,训练的自动聚焦神经网络10a的输出是用于数字/虚拟染色的训练的深度神经网络10的输入。在另一实施方式中,用于训练的深度神经网络10的机器学习算法将自动聚焦功能与在本文中描述的将图像从一个显微镜模态变换成另一显微镜模态的功能相结合。在后一实施方式中,不需要两个分开训练的深度神经网络。相反,提供执行虚拟自动聚焦以及数字/虚拟染色的单个训练的深度神经网络10a。网络10、10a两者的功能被组合到单个网络10a中。该深度神经网络10a遵循如本文所描述的架构。
57.无论该方法是在单个训练的深度神经网络10a还是多个训练的深度神经网络10、10a中实现,甚至可以用离焦输入图像20生成虚拟染色的图像40并且增加成像样本22的扫描速度。使用在不同焦点深度处获得的图像来训练深度神经网络10a,而输出(根据实现方式,其为输入图像20或虚拟染色的图像40)是同一视野的聚焦图像。使用标准光学显微镜获取用于训练的图像。对于深度神经网络10a的训练,“黄金标准”或“真值”图像与各种离焦或像差图像配对。用于训练的黄金标准/真值图像可包括样本22的聚焦图像,例如,可以通过任何数量的聚焦标准(例如,锐边或其他特征)来识别该聚焦图像。“黄金标准”图像还可包括景深扩展图像(edof),该景深扩展图像是提供更大景深的聚焦视图的基于多个图像的合
成聚焦图像。对于深度神经网络10a的训练,一些训练图像本身可以是对焦图像。离焦图像和对焦图像的组合可用于训练深度神经网络10a。
58.在训练阶段结束之后,深度神经网络10a可用于使来自单个散焦图像的像差图像重新聚焦,如图13所示,与需要通过多个深度平面获取多个图像的标准自动聚焦技术相反。如图13所示,从显微镜110获得的单个散焦图像20d被输入至训练的深度神经网络10a,并且生成聚焦图像20f。在本文解释的一个实施方式中,该聚焦图像20f随后可被输入至训练的深度神经网络10。可替换地,深度神经网络10的功能(虚拟染色)可以与自动聚焦功能结合到单个深度神经网络10a中。
59.为了训练深度神经网络10a,可以使用生成对抗网络(gan)来执行虚拟聚焦。训练数据集由用于多个激发和发射波长的多个组织切片的自发荧光(内源性荧光团)图像组成。在另一实施方式中,训练图像可以是其他显微镜模态(例如,明视野显微镜、超分辨率显微镜、共焦显微镜、光片显微镜、flim显微镜、宽视野显微镜、暗视野显微镜、结构光照明显微镜、计算显微镜、偏光显微镜、基于合成孔径的显微镜或全内反射显微镜以及相衬显微镜)。
60.通过奥林巴斯显微镜扫描样本,并且在每个视野处获取轴向间距为0.5μm的21层图像堆叠(在其他实施方式中,可以在不同的轴向间距下获得不同数量的图像)。同一视野的散焦像差图像和聚焦图像是成对的。训练数据集由数千个这种对组成,这些对分别被用作用于网络训练的输入和输出。用于约30,000个图像对的训练在nvidia 2080 ti gpu上花费约30小时。在深度神经网络10a的训练之后,该方法能够将针对多个散焦距离的试样22的图像20d重新聚焦成聚焦图像20f,如图14所示。
61.自动聚焦方法也可应用于厚试样或样本22,其中,网络10a可被训练为在试样的特定深度特征(例如,厚组织切片的表面)上重新聚焦,从而消除显著降低图像质量的离焦散射。用户可定义各种用户定义的深度或平面。这可以包括样本22的上表面、样本22的中平面或样本22的底表面。然后,该训练的深度神经网络10a的输出可以用作对如本文所解释的第二且独立训练的虚拟染色神经网络10的输入,以对无标记组织样本22进行虚拟染色。然后第一训练的深度神经网络10a的输出图像20f被输入至虚拟染色训练的神经网络10。在可替换实施方式中,人们可以使用如上概述的类似过程来训练可以直接拍摄非相干显微镜110(诸如荧光、明视野、暗视野或相位显微镜)的离焦图像20d的单个神经网络10,以直接输出无标记样本22的虚拟染色的图像40,其中,原始图像20d(在同一神经网络的输入处)是离焦的。与获得离焦图像20d的非相干显微镜110的图像模态相比,虚拟染色的图像40类似于另一图像模态。例如,可利用荧光显微镜获得离焦图像20d,而对焦且数字染色的输出图像40基本上类似于明视野显微镜图像。
62.在另一实施方式中,利用基于机器学习的框架,其中,训练的深度神经网络10使得能够用多种染色剂对样本22进行数字/虚拟染色。可使用单个训练的深度神经网络10将多个组织化学虚拟染色剂应用于图像。此外,该方法能够使用户定义的受关注区域执行特定虚拟染色以及多种虚拟染色剂的混合(例如,以生成其他独特的染色剂或染色组合)。例如,可以提供图形用户界面(gui)以允许用户利用一种或多种虚拟染色剂喷涂或突出显示未标记的组织学组织的图像的特定区域。该方法使用类条件卷积神经网络10来变换由一个或多个输入图像20组成的输入图像,在一个具体实施方式中,一个或多个输入图像包括未标记的组织样本22的自发荧光图像20。
63.作为示例,为了证明其实用性,使用单个训练的深度神经网络10利用以下染色剂对组织样本20的未标记切片的图像进行虚拟染色:苏木精和伊红(h&e)染色剂、苏木精、伊红、jones银染色剂、masson三色染色剂、过碘酸雪夫(pas)染色剂、刚果红染色剂、阿尔新蓝染色剂、蓝铁、硝酸银、三色染色剂、齐-内(ziehl neelsen)、grocott六胺银(gms)染色剂、革兰氏染色剂、酸性染色剂、碱性染色剂、银染色剂、尼氏(nissl)、weigert氏染色剂、高尔基染色剂、卢卡斯快蓝染色剂、甲苯胺蓝(toluidine blue)、genta、mallory三色染色剂、高莫里氏(gomori)三色染色剂、范吉森(van gieson)、吉姆萨(giemsa)、苏丹黑、perls普鲁士蓝(perls'prussian)、贝斯特氏卡红(best's carmine)、吖啶橙、免疫荧光染色剂、免疫组织化学染色剂、kinyoun冷染色剂、阿氏(albert)染色、鞭毛染色、芽孢染色、黑色素和印度墨汁。
64.该方法还可以用于生成新的染色剂,这些染色剂是多种虚拟染色剂以及利用这些训练的染色剂对特定组织微结构的染色的组成。在又一可替换的实施方式中,图像处理软件可用于自动识别或分割未标记组织样本22的图像内的受关注区域。这些识别出的或分割的受关注区域可以呈现给用户以用于虚拟染色或已经被图像处理软件染色。作为一个示例,可自动分割细胞核并用特定虚拟染色剂对细胞核进行“数字”染色,而不必由病理学家或其他操作员识别。
65.在该实施方式中,未标记组织22的一个或多个自发荧光图像20被用作训练的深度神经网络10的输入。使用类条件生成对抗网络(c-gan)将该输入转换成同一视野的染色的组织切片的等效图像40(参见图15)。在网络训练期间,输入到深度神经网络10中的类被指定为该图像的对应的真值图像的类。在一个实施方式中,类条件可以实现为具有与网络输入图像相同的垂直和水平维度的一组“独热”编码矩阵(图15)。在训练期间,该类可改变为任何数量。可替换地,通过将类编码矩阵m修改为使用多个类的混合,而不是简单的独热编码矩阵,可以混合多个染色剂,从而创建具有独特染色剂的输出图像40,该输出图像具有从由深度神经网络10学习的各种染色剂产生的特征(图18a至图18g)。
66.由于深度神经网络10旨在学习从未标记组织试样22的自发荧光图像20到染色试样的自发荧光图像(即,黄金标准)的转换,因此关键在于精确地对准fov。此外,当多于一个的自发荧光通道被用作网络10的输入时,必须对准各个滤光器通道。为了使用四种不同的染色剂(h&e、masson三色染色剂、pas和jones染色剂),分别针对来自这四种不同的染色数据集的每个输入图像和目标图像对(训练对)实施图像预处理和对准。图像预处理和对准遵循本文所述的和图8所示的全局和局部配准过程。然而,一个主要区别在于,当使用多个自发荧光通道作为网络输入时(即,如在此所示的dapi和txred),它们必须对准。即使使用相同显微镜捕获来自两个通道的图像,但确定来自两个通道的对应fov不是精确对准的,特别是在fov的边缘上。因此,使用如本文所述的弹性配准算法来精确对准多个自发荧光通道。弹性配准算法通过分层地将图像分成越来越小的块同时匹配对应的块来匹配图像的两个通道(例如,dapi和txred)的局部特征。然后计算出变换图被应用于txred图像以确保它们与来自dapi通道的对应图像对准。最后,来自两个通道的对准的图像与含有两个dapi和txred通道的全视野数字切片对准。
67.在共配准过程结束时,来自未标记组织切片的单个或多个自发荧光通道的图像20与组织化学染色的组织切片22的对应明视野图像48良好地对准。在将这些对准的对馈送到
深度神经网络10用于训练之前,分别对dapi和txred的全视野数字切片实施归一化。通过减去整个组织样本的平均值并且将其除以像素值之间的标准偏差来执行该全载玻片归一化。在训练程序之后,使用类条件,可利用同一输入图像20上的单个算法将多个虚拟染色剂应用于图像20。换言之,每个单独的染色剂不需要额外网络。单个训练的神经网络可以用于将一种或多种数字/虚拟染色剂应用于输入图像20。
68.图16示出了显示根据一个实施方式的用于显示来自训练的深度神经网络10的输出图像40的图形用户界面(gui)的显示器。在该实施方式中,向用户提供可用于识别和选择输出图像40的某些区域用于虚拟染色的工具列表(例如,指针、记号笔、橡皮擦、圆圈、荧光笔等)。例如,用户可以使用一个或多个工具来选择输出图像40中的组织的某些区域或区以用于虚拟染色。在该具体示例中,通过已由用户手动选择的散列线(区域a、b、c)来识别三个区域。可向用户提供染色剂的调色板,以从中选择染色剂对这些区域进行染色。例如,可以向用户提供染色剂选项(例如,masson三色染色剂、jones染色剂、h&e)以对组织进行染色。然后用户能够选择不同的区域来用一种或多种这些染色剂染色。这导致诸如图17所示的微结构输出。在分开的实施方式中,图像处理软件104可用于自动识别或分割输出图像40的某些区域。例如,图像分割和计算机生成的映射可用于识别成像样本22中的某些组织学特征。例如,可以由图像处理软件104自动识别细胞核、某些细胞或组织类型。可以利用一种或多种染色剂/染色剂组合对输出图像40中的这些自动识别的受关注区域进行手动和/或自动染色。
69.在又一实施方式中,可在输出图像40中生成多种染色剂的混合。例如,多种染色剂可以不同的比率或百分比混合在一起以产生独特的染色剂或染色剂组合。在本文中(图18e至图18g)公开了使用具有不同输入类条件的染色剂比率(例如,图18e中的h&e:jones染色剂的虚拟3:1)的染色剂混合物生成虚拟染色的网络输出图像40的示例。图18f示出了h&e:jones的比率为1:1的虚拟混合的染色剂。图18f示出了h&e:jones的比率为1:3的虚拟混合的染色剂。
70.尽管数字/虚拟染色方法可用于无标记样本22获得的荧光图像,但应当理解,多染色剂数字/虚拟染色方法也可用于其他显微镜成像模态。例如,这些包括染色或未染色样本22的明视野显微图像。在其他示例中,显微镜可包括:单光子荧光显微镜、多光子显微镜、二次谐波生成显微镜、高谐波生成显微镜、光学相干断层扫描(oct)显微镜、共焦反射显微镜、荧光寿命显微镜、拉曼光谱显微镜、明视野显微镜、暗视野显微镜、相衬显微镜、定量相位显微镜、结构光照明显微镜、超分辨率显微镜、光片显微镜、计算显微镜、偏光显微镜、基于合成孔径的显微镜和全内反射显微镜。
71.数字/虚拟染色方法可以与任意数量的染色剂一起使用,这些染色剂包括例如苏木精和伊红(h&e)染色剂、苏木精、伊红、jones银染色剂、masson三色染色剂、过碘酸雪夫(pas)染色剂、刚果红染色剂、阿尔新蓝染色剂、蓝铁、硝酸银、三色染色剂、齐-内、grocott六胺银(gms)染色剂、革兰氏染色剂、酸性染色剂、碱性染色剂、银染色剂、尼氏、weigert氏染色剂、高尔基染色剂、卢卡斯快蓝染色剂、甲苯胺蓝、genta、mallory三色染色剂、高莫里氏三色染色剂、范吉森、吉姆萨、苏丹黑、perls普鲁士蓝、贝斯特氏卡红、吖啶橙、免疫荧光染色剂、免疫组织化学染色剂、kinyoun冷染色剂、阿氏染色剂、鞭毛染色剂、芽孢染色剂、黑色素和印度墨汁染色剂。成像的样本22可包括组织切片或细胞/细胞结构。
72.在另一实施方式中,训练的深度神经网络10'、10”可操作为虚拟去染色(并且可选地用不同染色剂对样本进行虚拟重新染色)。在该实施方式中,提供了由图像处理软件104使用计算装置100(参见图1)的一个或多个处理器102执行的第一训练的深度神经网络10',其中,利用多个匹配的化学染色显微图像或图像块80
train
及其化学染色之前获得的同一样本的对应的未染色的真值显微图像或图像块82
gt
来训练第一训练的深度神经网络10'(图19a)。因此,在该实施方式中,用于训练深度神经网络10'的真值图像是未染色的(或未标记的)图像,而训练图像是化学染色的(例如,ihc染色的)图像。在该实施方式中,使用本文描述的任何类型的显微镜110获得化学染色的样本12(即,待测试或成像的样本12)的显微镜图像84
test
。然后,化学染色的样本的图像84
test
被输入到训练的深度神经网络10'。训练的深度神经网络10'然后输出样本12的虚拟去染色的显微图像86,该图像基本上等同于未化学染色(即,未染色或未标记的)获得的同一样本的对应图像。
73.可选地,如图19b所示,提供了由图像处理软件104使用计算装置100(参见图1)的一个或多个处理器102执行的第二训练的深度神经网络10”,其中,利用多个匹配的未染色或未标记的显微图像或图像块88
train
及其在化学染色之前获得的同一样本的对应的染色的真值显微图像或图像块90
gt
来训练第二训练的深度神经网络10”(图19a)。在该实施方式中,染色的真值对应于在80
train
图像中使用的不同染色剂。接下来,样本12(即,待测试或成像的样本12)的虚拟去染色的显微图像86被输入至第二训练的深度神经网络10”。第二训练的深度神经网络10”然后输出样本12的染色的或标记的显微图像92,该图像基本上等同于利用不同的化学染色剂获得的同一样本12的对应图像。
74.例如,该染色剂从以下各项中的一个转换或转换成以下各项中的一个:苏木精和伊红(h&e)染色剂、苏木精、伊红、jones银染色剂、masson三色染色剂、过碘酸雪夫(pas)染色剂、刚果红染色剂、阿尔新蓝染色剂、蓝铁、硝酸银、三色染色剂、齐-内、grocott六胺银(gms)染色剂、革兰氏染色剂、酸性染色剂、碱性染色剂、银染色剂、尼氏、weigert氏染色剂、高尔基染色剂、卢卡斯快蓝染色剂、甲苯胺蓝、genta、mallory三色染色剂、高莫里氏三色染色剂、范吉森、吉姆萨、苏丹黑、perls普鲁士蓝、贝斯特氏卡红、吖啶橙、免疫荧光染色剂、免疫组织化学染色剂、kinyoun冷染色剂、阿氏染色、鞭毛染色、芽孢染色、黑色素和印度墨汁。
75.应当理解,该实施方式可以与离焦和对焦图像的基于机器学习的训练相结合。因此,可以训练该网络(例如,深度神经网络10')以除了去染色/重新染色之外还聚焦或消除光学像差。此外,对于本文所描述的所有实施方式,在一些情况下,输入图像20可以具有与真值(gt)图像所具有的数值孔径和分辨率相同或基本上相似的数值孔径和分辨率。可替换地,与真值(gt)图像相比,输入图像20可具有较低的数值孔径和较差的分辨率。
76.实验-使用自动荧光对无标记组织进行数字染色
77.组织样本的虚拟染色
78.使用组织切片样本22和染色剂的不同组合来测试和证明本文所述的系统2和方法。在基于cnn的深度神经网络10的训练之后,通过向其馈送与在训练或验证集中使用的图像不重叠的无标记组织切片22的自发荧光图像20来盲目地测试其推断。图4a至图4h示出了被数字/虚拟染色成与同一样本22的h&e染色的明视野图像48(即,真值图像)匹配的唾液腺组织切片的结果。这些结果证明了系统2将无标记组织切片22的荧光图像20转换成明视野等效图像40的能力,示出了从h&e染色的组织预期的正确颜色方案,该组织含有各种组分,
诸如上皮样细胞、细胞核、核仁、基质和胶原蛋白。图3c和图3d两者的评估示出了h&e染色剂表明了皮下纤维-脂肪组织内的小岛浸润性肿瘤细胞。注意,在两个面板中都清楚地理解了包括核仁(箭头)和染色质纹理的区别的核细节。类似地,在图3g和图3h中,h&e染色剂表明了浸润性鳞状细胞癌。在两种染色剂中可清晰识别在相邻基质中具有水肿性粘液质变化(星号)的促结缔组织增生反应。
79.接下来,深度网络10被训练成利用两种不同的染剂(即,jones六胺银染色剂(肾)和masson三色染剂(肝脏和肺))对其他组织类型进行数字/虚拟染色。图4a至图4h和图5a至图5p总结了这些组织切片22的基于深度学习的数字/虚拟染色的结果,其与在组织化学染色过程之后捕获的同一样本22的明视野图像48非常匹配。这些结果示出了训练的深度神经网络10能够从无标记试样(即,没有任何组织化学染色剂)的单个荧光图像20推断用于不同组织类型的不同类型的组织学染色剂的染色模式。利用与图3a至图3h中相同的总体结论,病理学家还确认图4c和图5g的神经网络输出图像正确地揭示对应于肝细胞、窦状小管、胶原蛋白和脂肪滴(图5g)的组织学特征,与它们出现在化学染色(图5d和图5h)之后捕获的同一组织样本22的明视野图像48中的方式一致。类似地,同一专家还确认图5k和图5o(肺)中报告的深度神经网络输出图像40揭示出与血管、胶原蛋白和肺泡腔对应的一致染色的组织学特征,因为他们出现在化学染色(图6l和图6p)之后成像的同一组织样本22的明视野图像48中。
80.将来自训练的深度神经网络10的数字/虚拟染色的输出图像40与标准组织化学染色图像48进行比较,用于诊断多种类型组织上的多种类型的状况,这些组织是福尔马林固定石蜡包埋的(ffpe)或冷冻切片。在以下表1中总结了结果。由四个认证的病理学家(他们不了解虚拟染色技术)对十五(15)个组织切片的分析表明有100%的非主要不一致,定义为在专业观察者之间在诊断中没有临床上显著的差异。“诊断时间”在观察者之间显著变化,从观察者2的平均10秒/图像到观察者3的平均276秒/图像。然而,对于除了观察者2之外的所有观察者,观察者内部的变化性是非常小的并且倾向于更短的时间诊断虚拟染色的载玻片图像40,对于虚拟载玻片图像40和组织学染色的载玻片图像48两者是相等的,即,约10秒/图像。这些指示两种图像模态之间的非常类似的诊断效用。
81.表1
82.83.[0084][0085]
对全视野数字切片(wsi)的染色效果的盲评估
[0086]
在评估组织切片和染色剂中的差异之后,在专门的染色组织学工作流程中测试虚拟染色系统2的能力。具体地,用20
×
/0.75na物镜使肝脏组织切片的15个无标记样本和肾的13个无标记组织切片的自发荧光分布成像。所有肝脏和肾组织切片从不同的患者获得,并且包括小的活组织检查和较大的切除两者。所有组织切片从ffpe获得,但不盖上盖玻片。在自发荧光扫描之后,用masson三色染色剂(4μm肝脏组织切片)和jones染色剂(2μm肾组织切片)对组织切片进行组织学染色。然后将wsi分成训练集和测试集。对于肝脏载玻片群组,7个wsi用于训练虚拟染色算法,并且8个wsi用于盲测试;对于肾载玻片群组,6个wsi用于训练算法,并且7个wsi用于测试。研究病理学家对每个wsi的染色技术不知情,并要求对不同染色剂的质量应用1-4数字等级:4=完美,3=非常好,2=可接受,1=不可接受。其次,研究病理学家仅针对肝脏的特定特征:核细节(nd)、细胞质细节(cd)以及细胞外纤维化(ef)应用相同的计分量表(1-4)。在以下表2(肝脏)和表3(肾)中总结了(优胜者被加粗)这些结果。数据指出病理学家能够利用染色技术以及在技术之间具有高度一致性来识别组织病理学特征,而无需明确的优选染色技术(虚拟对组织学)。
[0087]
表2
[0088][0089][0090]
表3
[0091][0092]
网络输出图像质量的量化
[0093]
接下来,除了图3a至图3h、图4a至图4h、图5a至图5p中提供的视觉比较之外,通过首先计算化学染色样本22的明视野图像48与数字/虚拟染色图像40之间的像素级差异来定量训练的深度神经网络10的结果,该数字/虚拟染色图像使用深度神经网络10合成而不使用任何标记/染色剂。以下表4使用ycbcr颜色空间总结组织类型和染色剂的不同组合的该比较,其中,色度分量cb和cr完全限定颜色,并且y限定图像的亮度分量。该比较的结果揭示,对于色度(cb,cr)和亮度(y)通道,这两组图像之间的平均差分别为<~5%和<~16%。接下来,使用第二度量进一步量化该比较,即,结构相似性指数(ssim),其通常用于预测观察者相较于参考图像将给予图像的分数(本文中的等式8)。ssim的范围在0和1之间,其中,1定义相同图像的分数。在表4中也总结了这种ssim量化的结果,其很好地说明了化学染色样本的网络输出图像40与明视野图像48之间的强结构相似性。
[0094]
表4
[0095][0096]
应当注意,化学染色的组织样本22的明视野图像48事实上不提供网络输出图像40的该特定ssim和ycbcr分析的真实黄金标准,因为在组织化学染色过程以及相关的脱水和清除步骤期间存在组织经历的不受控制的变化和结构改变。对于一些图像注意到的另一变化是自动显微镜扫描软件为两种成像模态选择不同的自动聚焦平面。所有这些变化为两组图像的绝对定量比较产生一些挑战(即,无标记组织的网络输出40对组织学染色过程之后同一组织的明视野图像48)。
[0097]
染色标准化
[0098]
数字/虚拟染色系统2的有趣的副产品可以是染色标准化。换言之,训练的深度神经网络10收敛到“普通染色”着色方案,由此组织学染色的组织图像48中的变化高于虚拟染色的组织图像40中的变化。虚拟染色剂的着色仅是其训练的结果(即,在训练阶段期间使用的黄金标准组织学染色),并且还可以通过重新训练具有新染色剂着色的网络基于病理学家的喜好进行调整。可以从头开始创建或通过迁移学习加速这种“改进的”训练。这种使用深度学习的潜在染色标准可弥补在样本制备的不同阶段的人与人变化的负面影响,在不同临床实验室之间产生共同基础,增强临床医生的诊断工作流程,以及帮助开发新算法,诸如不同类型的癌症的自动组织转移检测或分级等。
[0099]
其他组织-染色剂组合的迁移学习
[0100]
使用迁移学习的概念,用于新组织和/或染色剂类型的训练程序可以更快地收敛,同时还实现改善的性能,即,训练成本/损失函数中更好的局部最小值。这意味着,从不同的组织-染色剂组合中预先学习的cnn模型深度神经网络10可以用于初始化深度神经网络10以统计地学习新组合的虚拟染色。图6a至图6c示出了这种方法的有利属性:训练新的深度神经网络10以对未染色的甲状腺组织切片的自发荧光图像20进行虚拟染色,并且使用先前针对唾液腺的h&e虚拟染色训练的另一深度神经网络10的权重和偏差对其进行初始化。根据在训练阶段使用的迭代次数的损失度量的进展清楚地表明,与从头开始训练的相同网络架构相比,新甲状腺深度网络10使用如图6a所示的随机初始化快速收敛至较低的最小值。
图6b比较了该甲状腺网络10在其学习过程的不同阶段的输出图像40,其还示出了迁移学习快速适应对新组织/染色剂组合提出的方法的影响。在例如≥6,000次迭代的训练阶段之后,网络输出图像40揭示细胞核显示不规则外形、核沟和染色质苍白,提示甲状腺乳头状癌;细胞还显示轻度至中度量的嗜酸性粒细胞质,并且网络输出图像处的纤维血管核心显示增加的炎性细胞,包括淋巴细胞和浆细胞。图6c示出了对应的h&e化学染色的明视野图像48。
[0101]
在不同分辨率下使用多个荧光通道
[0102]
使用训练的深度神经网络10的方法可以与其他激发波长和/或成像模态组合以便增强其对不同组织成分的推断性能。例如,尝试使用虚拟h&e染色检测在皮肤组织切片样本上的黑色素。然而,在网络的输出中没有清楚地识别黑色素,因为它在本文所描述的实验系统中测量的dapi激发/发射波长下呈现弱的自发荧光信号。增加黑色素的自发荧光的一种潜在方法是当样本处于氧化溶液中时使它们成像。然而,在采用源自例如cy5滤光器(激发628nm/发射692nm)的另外的自发荧光通道的情况下使用更实际的替代方案,使得可以在训练的深度神经网络10中增强并准确地推断黑色素信号。通过使用dapi和cy5自发荧光通道两者训练网络10,训练的深度神经网络10能够成功地确定在样本中哪里出现黑色素,如图7a至图7c所示。相对照地,当仅使用dapi通道时(图7a),网络10不能确定含有黑色素的区域(该区域看起来是白色的)。换句话说,网络10使用来自cy5通道的另外的自发荧光信息来区分黑色素与背景组织。对于在图7a至图7c中示出的结果,使用用于cy5通道的低分辨率物镜(10
×
/0.45na)获取图像20,以补充高分辨率dapi扫描(20
×
/0.75na),因为假设在高分辨率dapi扫描中发现最必要的信息并且可以利用低分辨率扫描对另外的信息(例如,黑色素存在)进行编码。以此方式,使用两个不同的通道,其中一个通道以较低分辨率使用以识别黑色素。这可能需要用荧光显微镜110多次扫描通过样本22。在又一多通道实施方式中,可将多个图像20馈送至训练的深度神经网络10。例如,这可包括原始荧光图像与已经历线性或非线性图像预处理(诸如对比度增强、对比度反转和图像滤波)的一个或多个图像结合。
[0103]
在本文中描述的系统2和方法示出了使用监督深度学习技术对无标记组织切片22进行数字/虚拟染色的能力,该监督深度学习技术使用由标准荧光显微镜110和滤光器组捕获的样本的单个荧光图像20作为输入(在其他实施方式中,当使用多个荧光通道时,输入多个荧光图像20)。这种基于统计学习的方法具有在组织病理学中重构临床工作流程的潜力,并且可以受益于多种成像模态,诸如荧光显微术、非线性显微术、全息显微术、受激拉曼散射显微术和光学相干断层扫描术等,以潜在地提供组织样本22的组织化学染色的标准实践的数字替代方案。在此,使用固定的未染色的组织样本22证明该方法以提供与化学染色的组织样本的有意义的比较,这对于训练深度神经网络10以及针对临床批准的方法盲测试网络输出的性能是必要的。然而,所提出的基于深度学习的方法广泛地适用于样本22的不同类型和状态,包括未切片的新鲜的组织样本(例如,在活组织检查程序之后),而不使用任何标记或染色剂。在其训练之后,深度神经网络10可以用于对使用例如uv或深度uv激发或甚至非线性显微镜模态获取的无标记的新鲜的组织样本22的图像进行数字/虚拟染色。例如,拉曼显微术可以提供非常丰富的无标记的生物化学特征,这些特征可以进一步增强神经网络学习的虚拟染色的有效性。
[0104]
训练过程的重要部分涉及将无标记的组织样本22的荧光图像20与其在组织化学
染色过程之后对应的明视野图像48(即,化学染色的图像)匹配。应当注意,在染色过程和相关步骤期间,一些组织构成可能以在训练阶段中误导损失/成本函数的方式被损失或变形。然而,这仅是训练和验证相关的挑战,并且不对良好训练的深度神经网络10针对无标记组织样本22的虚拟染色的实践造成任何限制。为了确保训练和验证阶段的质量并且使该挑战对网络性能的影响最小化,为两个图像集之间(即,在组织化学染色过程之前和之后)的可接受的相关值建立阈值并且从训练/验证集中消除不匹配的图像对,以确保深度神经网络10学习实际信号,而不是由于化学染色过程对组织形态的扰动。事实上,清除训练/验证图像数据的这个过程可以迭代地完成:可以从明显改变的样本的粗略消除开始并且因此收敛至被训练的神经网络10上。在该初始训练阶段之后,可用图像集中的每个样本的输出图像40可针对其对应的明视野图像48进行筛选,以设置更精细的阈值,以拒绝一些另外的图像并进一步清除训练/验证图像集。通过该过程的几次迭代,不仅能够进一步细化图像集,而且能够改善最终训练的深度神经网络10的性能。
[0105]
以上描述的方法将减轻由于组织学染色过程之后的一些组织特征的随机损失引起的一些训练挑战。事实上,这突出了跳过组织化学染色涉及的费力且昂贵的程序的另一动机,因为在无标记方法中保存局部组织的组织学将更容易,而不需要专家处理染色过程的一些精细程序,这有时也要求在显微镜下观察组织。
[0106]
使用pc桌面,深度神经网络10的训练阶段花费相当多的时间(例如,唾液腺网络约13小时)。然而,通过使用基于gpu的专用计算机硬件可以显著加速整个过程。此外,如已经在图6a至图6c中强调的,迁移学习为新组织/染色剂组合的训练阶段提供“热启动”,使得整个过程显著更快。一旦已经训练了深度神经网络10,则样本图像40的数字/虚拟染色以单一非迭代的方式进行,这不需要试错法或任何参数调谐来实现最佳结果。基于其前馈和非迭代架构,深度神经网络10在小于一秒(例如,0.59秒,对应于约0.33mm
×
0.33mm的样本视野)内快速输出虚拟染色的图像。随着基于gpu的进一步加速,其具有在输出数字/虚拟染色的图像40中实现实时或接近实时性能的潜力,尤其在手术室中或对于体内成像应用可能有用。应当理解,该方法也可用于本文所描述的体外成像应用中。
[0107]
所实现的数字/虚拟染色过程基于对每个组织/染色剂组合的单独的cnn深度神经网络10进行训练。如果向基于cnn的深度神经网络10馈送具有不同组织/染色剂组合的自发荧光图像20,它将不如所期望的那样进行。然而,这不是限制,因为对于组织学应用,组织类型和染色剂类型是针对每个受关注的样本22预先确定的,并且因此,用于从未标记的样本22的自发荧光图像20创建数字/虚拟染色的图像40的特定cnn选择不需要另外的信息或资源。当然,可以通过例如增加模型中的训练参数的数量,以可能增加训练和推断时间的代价来学习针对多个组织/染色剂组合的更一般的cnn模型。另一种途径是系统2和方法对同一未标记的组织类型进行多种虚拟染色的潜力。
[0108]
系统2的显著优点在于非常灵活。如果通过临床比较检测到诊断故障,通过相应地惩罚捕捉到的此类故障,可以适应反馈以统计地修正其性能。这种迭代训练和迁移学习周期,基于网络输出性能的临床评估,将有助于优化所提出的方法的稳健性和临床影响。最后,该方法和系统2可通过基于虚拟染色局部鉴定受关注区域,并且使用该信息来指导用于例如微免疫组织化学或测序的组织的随后分析用于对未染色组织水平的微指导分子分析。对未标记组织样本的这种类型的虚拟微指导可以促进亚型疾病的高通量鉴定,还帮助开发
针对患者的定制疗法。
[0109]
样本制备
[0110]
将福尔马林固定的石蜡包埋的2μm厚的组织切片使用二甲苯去石蜡并且使用cytoseal
tm
(美国马萨诸塞州沃尔瑟姆赛默飞世尔科技公司(thermo-fisher scientific,waltham,ma usa))安装在标准载玻片上,随后放置盖玻片(美国宾夕法尼亚州匹兹堡飞世尔科技公司fishrefinest
tm
,24
×
50-1(fisherfinest
tm
,24x50-1,fisher scientific,pittsburgh,pa usa))。在未标记的组织样本的初始自发荧光成像过程(使用dapi激发和发射滤光器组)之后,然后将载玻片放入二甲苯中持续约48小时或直到可以去除盖玻片而不损伤组织。一旦去除盖玻片,将载玻片浸入(大约浸入30下)无水酒精、95%酒精中,然后在d.i.水中洗涤约1分钟。这个步骤之后是用于h&e、masson三色染色剂或jones染色剂的对应的染色程序。该组织处理路径仅用于训练和验证该方法,并在网络训练后不需要该组织处理路径。为了测试该系统和方法,使用不同的组织和染色剂组合:唾液腺和甲状腺组织切片用h&e染色,肾组织切片用jones染色剂染色,而肝脏和肺组织切片用masson三色染色剂染色。
[0111]
在wsi研究中,ffpe 2-4μm厚的组织切片在自发荧光成像阶段期间未盖上盖玻片。在自发荧光成像之后,组织样本如上所述进行组织学染色(masson三色染色剂用于肝脏组织切片,jones染色剂用于肾组织切片)。通过将组织切片包埋在0.c.t.(tissue tek,sakura finetek usa inc)中并用干冰浸渍于2-甲基丁烷中来制备未染色的冷冻样本。然后将冷冻切片切成4μm切片并且放入冰箱中直到它成像。在成像过程之后,组织切片用70%酒精洗涤、h&e染色并盖上盖玻片。从转化病理学核心实验室(tpcl)获得样本,并由ucla处的组织学实验室制备。在irb 18-001029(ucla)下获得糖尿病患者和非糖尿病患者的肾组织切片。在去识别患者相关信息之后获得所有样本,并且从现有试样制备所有样本。因此,这项工作不干扰护理或样本收集程序的标准实践。
[0112]
数据获取
[0113]
使用配备有载物台(motorized stage)的常规荧光显微镜110(日本东京奥林巴斯公司ix83(ix83,olympus corporation,tokyo,japan))捕获无标记的组织自发荧光图像20,其中,通过显微镜自动化软件(molecular devices,llc)控制图像采集过程。用近uv光激发未染色的组织样本并且使用dapi滤光块(osfi3-dapi-5060c,激发波长377nm/50nm带宽,发射波长447nm/60nm带宽)利用40
×
/0.95na物镜(olympus uplsapo 40x2/0.95na,wd0.18)或20
×
/0.75na物镜(olympus uplsapo 20x/0.75na,wd0.65)成像。对于黑色素推断,使用cy5滤光块(cy5-4040c-ofx,激发波长628nm/40nm带宽,发射波长692nm/40nm带宽)利用10
×
/0.4na物镜(olympus uplsapo 10x2)另外获取样本的自发荧光图像。利用科学cmos传感器(orca-flash4.0 v2,hamamatsu photonics k.k.,shizuoka prefecture,japan)以约500ms的曝光时间捕获每个自发荧光图像。使用配备有2
×
放大适配器的20
×
/0.75na物镜(plan apo),使用载玻片扫描仪显微镜(aperio at,leica biosystems)获取明视野图像48(用于训练和验证)。
[0114]
图像预处理和对准
[0115]
由于深度神经网络10旨在学习化学上未染色的组织样本22的自发荧光图像20与组织化学染色之后的同一组织样本22的明视野图像48之间的统计变换,所以准确地匹配输
入和目标图像(即,未染色的自发荧光图像20和染色的明视野图像48)的fov是重要的。在matlab(the mathworks inc.,natick,ma,usa)中实施的图8中描述了描述全局和局部图像配准过程的总体方案。该过程的第一步骤是找到用于匹配未染色的自发荧光图像和化学染色的明视野图像的候选特征。为此,对每个自发荧光图像20(2048
×
2048像素)进行下采样以匹配明视野显微镜图像的有效像素大小。这产生1351
×
1351像素未染色的自发荧光组织图像,通过使所有像素值的底部1%和顶部1%饱和来增强该图像的对比度,并且反转对比度(图8中的图像20a)以更好地表示灰度转换的全视野数字切片的颜色图。然后,执行相关补丁处理60,其中,通过将1351
×
1351像素补丁中的每一个与从全载玻片灰度图像48a提取的相同大小的对应补丁相关来计算归一化相关得分矩阵。该矩阵中具有最高得分的条目表示两种成像模态之间最可能匹配的fov。使用该信息(其定义一对坐标),从原始全载玻片明视野图像48的匹配fov裁切48c以产生目标图像48d。在该fov匹配程序60之后,自发荧光图像20和明视野显微镜图像48粗糙地匹配。然而,由于在两个不同显微成像实验(自发荧光,随后是明视野)处样本放置的轻微失配,它们仍然不能在单个像素级精确配准,这在同一样本的输入图像与目标图像之间随机引起轻微旋转角度(例如,约1-2度)。
[0116]
输入-目标匹配过程的第二部分涉及全局配准步骤64,其校正自发荧光图像与明视野图像之间的该轻微旋转角度。这通过从图像对中提取特征向量(描述符)及其对应位置并且通过使用所提取的描述符来匹配特征来完成。然后,使用m-估计样本一致性(msac)算法(其是随机样本一致性(ransac)算法的变体)找到对应于匹配对的变换矩阵。最后,通过将该变换矩阵应用于原始明视野显微镜图像块48d来获得角度校正图像48e。在施加该旋转之后,由于旋转角度校正,图像20b、48e被进一步裁切100个像素(每侧50个像素)以适应图像边缘处的未定义像素值。
[0117]
最后,对于局部特征配准操作68,通过从大到小分级地匹配对应块,匹配两个图像集的局部特征(自发荧光20b对明视野48e)的弹性图像配准。神经网络71用于学习粗略匹配图像之间的变换。该网络71使用与图10中的网络10相同的结构。使用低数量的迭代,使得网络71仅学习准确的颜色映射,而不学习在输入图像与标记图像之间的任何空间变换。从该步骤计算的变换图最终应用于每个明视野图像块48e。在这些配准步骤60、64、68结束时,自发荧光图像块20b及其对应的明视野组织图像块48f彼此精确地匹配,并且可用作用于训练深度神经网络10的输入和标记对,从而允许网络仅关注并学习虚拟组织学染色的问题。
[0118]
对于20
×
物镜图像(用于生成表2和表3数据),使用相似的过程。代替对自发荧光图像20进行下采样,明视野显微镜图像48被下采样至它们的原始尺寸的75.85%,使得它们与较低放大率图像匹配。此外,为了使用这些20
×
图像产生全视野数字切片,应用另外的阴影校正和归一化技术。在被馈送到网络71之前,通过减去整个载玻片上的平均值并且将其除以像素值之间的标准偏差来归一化每个视野。这使每个载玻片内以及载玻片之间的网络输入归一化。最后,将阴影校正应用于每个图像以说明在每个视野的边缘处测量的较低的相对强度。
[0119]
深度神经网络架构和训练
[0120]
在此,gan架构用于学习从无标记的未染色自发荧光输入图像20到化学染色的样本的对应明视野图像48的变换。基于标准卷积神经网络的训练学习使网络的输出与目标标记之间的损失/成本函数最小化。因此,该损失函数69(图9和图10)的选择是深度网络设计
的关键成分。例如,简单地将l
2-norm惩罚选择为成本函数将倾向于生成模糊结果,因为网络将所有似乎合理的结果的权值概率平均;因此,通常需要另外的正则项来引导网络在网络的输出处保存期望的尖锐样本特征。gan通过学习旨在准确地对深度网络的输出图像真假(即,在其虚拟染色中是正确的还是错误的)进行划分的标准来避免这个问题。这使得不能容忍与期望标记不一致的输出图像,这使得损失函数适应眼前的数据和期望任务。为了实现该目标,gan训练程序涉及训练两种不同的网络,如图9和图10所示:(i)生成器网络70,在这种情况下,该生成器网络旨在学习未染色的自发荧光输入图像20与组织学染色过程之后同一样本12的对应的明视野图像48之间的统计变换;以及(ii)鉴别器网络74,学习如何鉴别染色的组织切片的真实明视野图像与生成器网络的输出图像。最终,该训练过程的期望结果是训练的深度神经网络10,其将未染色的自发荧光输入图像20变换为数字染色的图像40,该数字染色的图像将与同一样本22的染色的明视野图像48无法区分。对于该任务,生成器70和鉴别器74的损失函数69如此定义:
[0121][0122]
其中,d是指鉴别器网络输出,z
label
表示化学染色的组织的明视野图像,z
output
表示生成器网络的输出。生成器损失函数使用正则参数(λ,α)来平衡生成器网络输出图像相对于其标记、输出图像的全变分(tv)算子和输出图像的鉴别器网络预测的像素均方误差(mse),该正则参数从经验上设置为不同的值,分别适应像素mse损失和组合的生成器损失(l
generator
)的约2%和约20%。图像z的tv算子被定义为:
[0123][0124]
其中,p、q是像素索引。基于等式(1),鉴别器试图将输出损失最小化,同时将正确分类实际标记(即,化学染色的组织的明视野图像)的概率最大化。理想地,鉴别器网络将旨在实现d(z
label
)=1和d(z
output
)=0,但如果由gan成功地训练生成器,则d(z
output
)将理想地收敛至0.5。
[0125]
在图10中详细描述了生成器深度神经网络架构70。输入图像20由网络70以多尺度方式使用下采样和上采样路径处理,帮助网络学习各种不同尺度的虚拟染色任务。下采样路径由四个单独的步骤(四个块#1、#2、#3、#4)组成,其中,每个步骤包含一个残差块,每个残差块将特征图xk映射为特征图x
k+1
:
[0126]
x
k+1
=xk+lrelu[conv
k3
{lrelu[conv
k2
{lrelu[conv
k1
{xk}]}]}](3)
[0127]
其中,conv{.}是卷积算子(其包括偏差项),k1、k2和k3表示卷积层的序列号,并且lrelu[.]是在整个网络中使用的非线性激活函数(即,渗漏整流线性单元),定义为:
[0128][0129]
下采样路径中的每一级的输入通道的数量被设置为:1、64、128、256,而下采样路径中的输出通道的数量被设置为:64、128、256、512。为了避免每个块的尺寸失配,特征图xk被零填充为与x
k+1
中通道的数量匹配。每个下采样水平之间的连接是具有2个像素跨度的2
×
2平均池化层,其对特征图以4倍(每个方向2倍)进行下采样。在第四下采样块的输出之后,另一卷积层(cl)在将其连接到上采样路径之前将特征图的数量保持为512。上采样路径由四个对称的上采样步骤(#1、#2、#3、#4)组成,每个步骤包含一个卷积块。将特征图yk映射至特征图y
k+1
的卷积块操作由下式给出:
[0130]yk+1
=lrelu[conv
k6
{lrelu[conv
k5
{lrelu[conv
k4
{concat(x
k+1
,us{yk})}]}]}](5)
[0131]
其中,concat(.)是合并通道数量的两个特征图之间的串联,us{.}是上采样算子,并且k4、k5和k6表示卷积层的序列号。针对上采样路径中的每个水平的输入通道的数量分别被设置为1024,512,256,128,并且针对上采样路径中的每一级的输出通道的数量分别被设置为256、128、64、32。最后一层是将32个通道映射到3个通道的卷积层(cl),由ycbcr颜色图来表示。生成器网络和鉴别器网络两者都用256
×
256个像素的块大小来训练。
[0132]
图10中概括的鉴别器网络接收对应于输入图像40ycbcr、48ycbcr的ycbcr颜色空间的三个(3)输入通道。然后使用卷积层将该输入变换成64通道表示,其后跟随有以下算子的5个块:
[0133]zk+1
=lrelu[conv
k2
{lrelu[conv
k1
{zk}]}](6)
[0134]
其中,k1、k2表示卷积层的序列号。每个层的通道数量是3、64、64、128、128、256、256、512、512、1024、1024、2048。下一层是具有等于块大小(256
×
256)的滤光器大小的平均池化层,其产生具有2048个条目的向量。该平均池化层的输出然后被馈送到具有以下结构的两个全连接层(fc):
[0135]zk+1
=fc[lrelu[fc{zk}]](7)
[0136]
其中,fc表示全连接层,具有可学习的权重和偏差。第一全连接层输出具有2048个条目的向量,而第二全连接层输出标量值。该标量值用作sigmoid激活函数d(z)=1/(1+exp(-z))的输入,该函数计算鉴别器网络输入为真/真实或假的概率(在0与1之间),即,理想地,d(z
label
)=1,如图10中的输出67所示。
[0137]
整个gan的卷积核被设置为3
×
3。通过使用标准偏差为0.05和平均值为0的截断正态分布使这些核随机初始化;将所有网络偏差初始化为0。通过深度神经网络10的训练阶段使用自适应矩估计(adam)优化器通过反向传播(图10的虚线箭头所示)更新可学习参数,其中,生成器网络70的学习速率为1
×
10-4
,鉴别器网络74的学习速率为1
×
10-5
。而且,对于鉴别器74的每次迭代,存在生成器网络70的4次迭代,以避免跟随鉴别器网络与标记的潜在过度拟合的训练停滞。在训练中使用块大小10。
[0138]
一旦所有视野都通过网络10,使用fiji网格/集合拼接插件将全视野数字切片拼接在一起(例如,参见schindelin,j.等人的:fiji:anopen-sourceplatformforbiological-imageanalysis.nat.methods9,676-682(2012),其通过引用结合于此)。该插件计算每个贴图之间的精确重叠并且将其线性混合到单个大图像中。总体上,推断和拼接每cm2分别花费约5分钟和30秒,并且可以使用硬件和软件进展来显著改进。在向病理学家示出之前,裁切出在自发荧光图像或明视野图像中离焦或具有重大像差(例如,由于灰尘颗粒)的切片。最后,图像被导出到zoomify格式(被设计成能够使用标准网络浏览器查看较大图像;http://zoomify.com/)并且被上传到gigamacro网站(https://viewer.gigamacro.com/)以使病理学家容易访问和查看。
[0139]
实现方式细节
[0140]
在以下表5中示出了其他实现方式细节,包括训练块的数量、阶段的数量和训练时间。使用python版本3.5.0实现数字/虚拟染色深度神经网络10。使用tensorflow框架版本1.4.0实现gan。所使用的其他python库是os、time、tqdm、python图像处理库(pil)、scipy、glob、ops、sys和numpy。该软件在具有核i7-7700k cpu@4.2ghz(英特尔)和ram为64gb,运行windows 10操作系统(微软)的台式计算机上实现。使用双gtx 1080ti gpu(nvidia)进行网络训练和测试。
[0141]
表5
[0142][0143][0144]
实验-使用荧光寿命成像flim对样本进行虚拟染色
[0145]
在该实施方式中,使用能够基于荧光寿命成像对未染色的组织样本22进行虚拟ihc染色的训练的神经网络10。该算法采用未染色的组织样本22的荧光寿命图像20l,并输出与ihc染色之后同一视野的明视野图像48良好匹配的图像40。使用该方法,可以用虚拟染色代替费力且耗时的ihc染色程序,这明显更快并且提供将允许组织保存用于进一步分析。
[0146]
数据获取
[0147]
参考图11a,将未染色的福尔马林固定石蜡包埋的(ffpe)的乳腺组织(例如,通过活组织检查b获得)切成薄的4μm切片并固定在标准显微镜载玻片上。在irb 18-001029下获得这些组织切片22。组织在成像之前用二甲苯去石蜡并且使用cytoseal(赛默飞世尔科技公司)安装在标准载玻片上。使用标准荧光寿命显微镜110(sp8-dive,leica microsystems),其配备有20
×
/0.75na物镜(leica hc pl apo 20
×
/0.75imm)以及分别在435-485nm和535-595nm波长范围接收荧光信号的两个单独的混合光电检测器。显微镜110使用以约0.3w激发的700nm波长激光,这些未标记的组织切片22自发荧光寿命被成像生成图像20l。对于像素大小为300nm的1024
×
1024像素,扫描速度为200hz。一旦获得自发荧光
寿命图像20l,使用标准her2、er或pr染色程序对载玻片进行ihc染色。由ucla转化病理学核心实验室(tpcl)进行染色。然后使用配备有20
×
/0.75na物镜(aperio at,leica biosystems)的商用载玻片扫描显微镜使这些ihc染色的载玻片成像以创建用于训练、验证和测试神经网络10的目标图像48。
[0148]
图像预处理和配准
[0149]
因为深度神经网络10旨在从未标记试样22的自发荧光寿命图像20l学习变换,因此重要的是精确地对准它们与目标的对应明视野图像48之间的fov。图像预处理和对准遵循本文所述的和图8所示的全局和局部配准过程。在配准过程结束时,来自未标记组织切片22的单个/多个自发荧光和/或寿命通道的图像与ihc染色的组织切片的对应的明视野图像48良好对准。在将这些对准的图像对20l、48馈送到神经网络10之前,通过减去整个载玻片上的平均值并且将其除以像素值之间的标准偏差来在荧光强度图像上实现载玻片归一化。
[0150]
深度神经网络架构、训练和验证
[0151]
对于训练的深度神经网络10,条件gan架构用于学习从无标记的未染色的自发荧光寿命输入图像20l到三种不同染色剂(her2、pr和er)中的对应明视野图像48的转换。在自发荧光寿命图像20l配准至明视野图像48之后,这些精确对准的fov被随机分割成256
×
256个像素的重叠块,其然后被用于训练基于gan的深度神经网络10。
[0152]
基于gan的神经网络10由两个深度神经网络组成:生成器网络(g)和鉴别器网络(d)。对于该任务,生成器和鉴别器的损失函数定义如下:
[0153][0154][0155]
其中,各向异性全变分(tv)算子和l1范数被定义为:
[0156][0157]
其中,d(
·
)和g(
·
)是指鉴别器和生成器网络输出,z
label
表示组织学染色的组织的明视野图像,并且z
output
表示生成器网络的输出。
[0158]
结构相似性指数(ssim)定义为:
[0159][0160]
其中,μ
x
,μy是图像的平均值,是x,y的方差;σ
x,y
是x和y的协方差;以及c1,c2是用于稳定具有小分母的除法的变量。ssim值1.0是指相同的图像。生成器损失函数使生成器网络输出图像的逐像素ssim和l1范数与其标记、输出图像的总变分(tv)算子与输出图像的鉴别器网络预测平衡。正则参数(μ,α,v,λ)被设置为(0.3,0.7,0.05,0.002)。
[0161]
生成器g的深度神经网络架构遵循图11b所示的(并且在本文中描述的)深度神经
网络10的结构。然而,在该实现方式中,网络10开始于卷积层将输入寿命和/或自发荧光图像数据映射200到十六(16)个通道中,接着是下采样路径由五个单独的下采样操作202组成。下采样路径中的每一级的输入通道的数量被设置为:16、32、64、128、256,而下采样路径中的输出通道的数量被设置为:32、64、128、256、512。在中心块卷积层203之后,上采样路径由五个对称的上采样操作204组成。上采样路径中的每一级的输入通道的数量分别被设置为1024、512、256、128、64,并且上采样路径中的每一级的输出通道的数量分别被设置为256、128、64、32、16。最后一层206是利用由rgb颜色图表示的tanh()激活函数208将16个通道映射到3个通道的卷积层。生成器(g)和鉴别器(d)网络两者都用256
×
256个像素的图像块大小来训练。
[0162]
鉴别器网络(d)接收与输入图像的rgb颜色空间对应的三个(3)(即,红、绿和蓝)输入通道。然后,使用卷积层210将该三通道输入变换成16通道表示,该卷积层之后是以下算子的5个块212:
[0163]zk+1
=pool(lrelu[conv
k2
{lrelu[conv
k1
{zk}]}])(11)
[0164]
其中,conv{.}是卷积算子(其包括偏差项),k1和k2表示卷积层的序列号,并且lrelu[.]是在整个网络中使用的非线性激活函数(即,渗漏整流线性单元),并且pool(.)是2
×
2平均池化运算,被定义为:
[0165][0166]
每级的输入通道和输出通道的数量正好遵循生成器下采样路径,然后是中心块卷积层213。最后一级214表示为:
[0167]zk+1
=
[0168]
sigmoid(fc[dropout[lrelu[fc[lrelu[conv
k2
{lrelu[conv
k1
{zk}]}]]]](13)
[0169]
其中,fc[.]表示全连接层,具有可学习的权重和偏差。sigmoid(.)表示sigmoid激活函数,并且dropout[.]随机地从全连接层删去50%的连接。
[0170]
将整个基于gan的深度神经网络10中的卷积滤光器大小设置为3
×
3。使用自适应矩估计(adam)优化器通过训练更新可学习参数,其中生成器网络(g)的学习速率为1
×
10-4
,并且鉴别器网络(n)的学习速率为1
×
10-5
。将训练的块大小设置为48。
[0171]
实现方式细节
[0172]
使用python版本3.7.1利用pyptorch框架版本1.3来实现虚拟染色网络10。该软件在具有3.30ghz的英特尔i9-7900xcpu和ram为64gb,运行microsoftwindows10操作系统的台式计算机上实现。使用两个nvidiageforcegtx1080tigpu进行网络训练和测试。
[0173]
实验-后成像计算自动聚焦
[0174]
该实施方式涉及用于诸如明视野显微术和荧光显微术的非相干成像模态的后成像计算自动聚焦。该方法仅需要单个像差图像以使用训练的深度神经网络虚拟重新聚焦该单个像差图像。该数据驱动的机器学习算法采用像差的和/或离焦的图像,并输出与同一视野的聚焦图像良好匹配的图像。使用该方法,可以增加使例如组织的样本成像的显微镜的扫描速度。
[0175]
荧光图像获取
[0176]
参考图13,通过由micro-manager显微镜自动化软件控制的倒置olympus显微镜(ix83,olympus)110获得组织自发荧光图像20。在紫外线范围附近激发未染色的组织22并且使用dapi滤光块(osf13-dapi-5060c,激发波长377nm/50nm带宽,发射波长447nm/60nm带宽)成像。使用20
×
/0.75na物镜(olympusuplsapo20
×
/0.75na,wd0.65)获取图像20。在每个阶段位置,自动化软件基于图像对比度执行自动聚焦,并且以0.5μm的轴向间隔从-10μm至10μm获取协议栈。每个图像20用科学cmos传感器(orca-flash4.0v.2,hamamatsuphotonics)以约100ms的暴光时间捕获。
[0177]
图像预处理
[0178]
为了校正来自显微镜载物台的刚性位移和旋转,首先使自发荧光图像栈(2048
×
2048
×
41)与imagej插件
‘
stackreg’对准。然后,使用imagej插件
‘
extendeddepthoffield’为每个栈生成景深扩展图像。在横向上将栈和对应的景深扩展(edof)图像裁切成非重叠的512
×
512个更小的块,并且将最聚焦的平面(目标图像)设置为与edof图像具有最高结构相似性指数(ssim)的平面。然后,聚焦平面上方和下方的10个平面(对应于+/-5μm散焦)被设置为在栈的范围内,并且从21个平面中的每一个生成用于训练网络10a的输入图像。
[0179]
为了生成训练和验证数据集,同一视野的散焦像差和聚焦图像被配对并且分别用作网络10a训练的输入和输出。原始数据集由约30,000个这样的对组成,随机划分为训练数据集和确认数据集,其占数据的85%和15%。训练数据集在训练期间通过随机翻转和旋转被增强8次,而验证数据集未被增强。从训练数据集和验证数据集中没有出现的单独的fov裁切出测试数据集。图像在被馈送到网络10a之前在fov处通过其平均值和标准偏差进行归一化。
[0180]
深度神经网络架构、训练和验证
[0181]
生成对抗网络(gan)10a在此用于执行快照自动聚焦。gan网络10a由生成器网络(g)和鉴别器网络(d)组成。生成器网络(g)是具有残余连接的u网,并且鉴别器网络(d)是卷积神经网络。在训练期间,网络10a迭代地使生成器和鉴别器的损失函数最小化,定义为:
[0182]
lg=
[0183]
mae{z
label
,z
output
}+λ
×
msssim{z
label
,z
output
}+β
×
mse{z
label
,z
output
}+α
×
(1-d(z
output
))2(14)
[0184]
ld=d(z
output
)2+(1-d(z
label
))2(15)
[0185]
其中,z
label
表示聚焦的荧光图像,z
output
表示生成器输出,d是鉴别器输出。生成器损失函数是由正则参数λ,β,α平衡的平均绝对误差(mae)、多尺度结构相似性(ms-ssim)指数以及均方误差(mse)的组合。在训练中,参数在经验上被设置为λ=50,β=1,α=1。多尺度结构相似性指数(ms-ssim)被定义为:
[0186][0187]
其中,yj和yj是下采样2
j-1
次的失真和参考图像;μ
x
,μy是x、y的平均值;是x的方差;σ
xy
是x、y的协方差;以及c1、c2、c3是用于稳定具有小分母的除法的小常数。
[0188]
自适应矩估计(adam)优化器用于更新可学习参数,其中,生成器(g)和鉴别器(d)
的学习速率分别为1
×
10-4
和1
×
10-6
。此外,在每次迭代中六次更新生成器损失和三次更新鉴别器损失。在训练中使用块大小为五(5)。每50次迭代测试验证集,并且选择最佳模型作为验证集上具有最小损失的模型。
[0189]
实现方式细节
[0190]
网络使用tensorflow在pc上实现,该pc具有2.3ghz的intel xeon core w-2195cpu和256gb ram,使用nvidia geforce 2080ti gpu。对于大小为512
×
512的大约30,000个图像对的训练花费约30小时。512
×
512个像素图像块的测试时间为约0.2s。
[0191]
实验-利用单个网络用多种染色剂进行虚拟染色
[0192]
在该实施方式中,类条件卷积神经网络10用于变换由未标记的组织样本22的一个或多个自发荧光图像20组成的输入图像。作为示例,为了证明其实用性,使用单个网络10用苏木精和伊红(h&e)、jones银染色剂、masson三色染色剂和过碘酸雪夫(pas)染色剂对未标记的切片的图像进行虚拟染色。训练的神经网络10能够生成新的染色剂以及用这些训练的染色剂对特定组织微结构进行染色。
[0193]
数据获取
[0194]
将未染色的福尔马林固定石蜡包埋的(ffpe)肾组织切片成2μm薄片并且固定在标准显微镜载玻片上。在irb 18-001029下获得这些组织切片22。配备有20
×
/0.75na物镜(olympus uplsapo 20x/0.75\na,wd0.65)以及两个单独的滤光块dapi(osfi3-dapi-5060c,ex 377/50\nm em 447/60\nm,semrock)和txred(osfi3-txred-4040c,ex 562/40nm em 624/40nm,semrock)的常规宽视野荧光显微镜110(ix83,olympus)与所成像的未标记的组织切片22的自发荧光一起使用。dapi通道的曝光时间是约50ms并且对于txred通道是约300ms。一旦组织切片22的自发荧光被成像,使用标准h&e、jones、masson三色染色剂或pas染色程序对载玻片进行组织学染色。由ucla转化病理学核心实验室(tpcl)进行染色。然后使用fda批准的载玻片扫描显微镜110(aperio at,leica biosystems,使用20x/0.75na物镜扫描)使这些组织学染色的载玻片成像,以产生用于训练、验证和测试神经网络10的目标图像48。
[0195]
深度神经网络架构、训练和验证
[0196]
条件gan架构用于训练的深度神经网络10学习使用四种不同的染色剂(h&e、masson三色染色剂、pas和jones)从无标记的未染色的自发荧光输入图像20到对应的明视野图像48的变换。当然,可以在深度神经网络10中训练其他或附加染色剂。在自发荧光图像20与明视野图像48共同配准之后,这些精确对准的fov被随机分割成256
×
256个像素的重叠块,然后用于训练gan网络10。在条件gan网络10的实现方式中,使用独热编码矩阵m(图15),在每个矩阵m对应于不同的染色剂的训练过程中,该独热编码矩阵m串联至网络的256
×
256个输入图像/图像栈块。表示这种调节的一种方式是通过以下给出的:
[0197][0198]
其中,[
·
]是指串联,并且ci表示第i种染色剂类型(在该示例中:h&e、masson三色染色剂、pas和jones)的标记的256
×
256矩阵。对于来自第i个染色数据集的输入图像和目标图像对,ci被设置为全1矩阵,因而所有其他剩余矩阵被分配零值(参见图15)。条件gan网络10由两个深度神经网络组成,如本文解释的生成器(g)和鉴别器(d)。对于该任务,生成器和鉴别器的损失函数被定义为:
[0199][0200][0201]
其中,各向异性tv算子和l1范数被定义为:
[0202][0203]
其中,d(
·
)和g(
·
)分别是指鉴别器和生成器网络输出,z
label
表示组织学染色的组织的明视野图像,并且z
output
表示生成器网络的输出。p和q表示图像块的垂直和水平像素的数量,且p和q表示求和索引。正则参数(λ,α)被设置为0.02和2000,该正则参数适应总变分损失项为大约l1损失的2%并且鉴别器损失项为总生成器损失的98%。
[0204]
生成器(g)的深度神经网络架构遵循在图10中示出的(并且在本文中描述的)深度神经网络10的结构。然而,在一个实现方式中,向下取样路径中的每一级的输入通道的数量设置为:1、96、192、384。鉴别器网络(d)接收七个输入通道。三个输入通道(ycbcr颜色图)来自生成器输出或目标,并且四个输入通道来自独热编码类条件矩阵m。使用卷积层将这个输入变换成64通道特征图。将整个gan的卷积滤光器大小设置为3
×
3。使用自适应矩估计(adam)优化器通过训练更新可学习参数,其中,生成器网络(g)的学习速率为1
×
10-4
,并且鉴别器网络(d)的学习速率为2
×
10-6
。对于每个鉴别器步骤,存在对生成器网络进行十次迭代。将训练的块大小设置为9。
[0205]
单个虚拟组织染色
[0206]
一旦深度神经网络10被训练,独热编码标记被用于调节网络10以生成期望的染色图像40。换句话说,对于第i染色(对于单个染色剂实施方式),ci矩阵被设置为全1矩阵并且其他剩余矩阵被设置为全0。因此,一个或多个条件矩阵可应用于深度神经网络10以在成像样本的所有或子区域上生成相应的染色剂。条件矩阵m限定每个染色剂通道的子区域或边界。
[0207]
染色剂混合和微结构化
[0208]
在训练过程之后,可以以网络10未被训练的方式使用条件矩阵,以便创建新的或新颖类型的染色剂。可以在以下等式中概括应该满足的编码规则:
[0209][0210]
换言之,对于给定的索引集i、j,训练网络10的跨染色剂的数量(在我们的示例中,n
stains
=4)的总和应等于1。在一个可行的实现方式中,通过修改类编码矩阵以使用多个类的混合,如在以下等式中所描述的:
[0211][0212]
可以混合各种染色剂,从而产生具有从由人工神经网络学习的各种染色剂发出的
特征的独特染色剂。这在图17中示出。
[0213]
另一选项是将组织的视野分成不同的受关注区域(roi),其中,可以利用特定染色剂或这些染色剂的混合对每个受关注区域进行虚拟染色:
[0214][0215]
其中,roi是视野中的定义的受关注区域。可以跨视野定义多个非重叠的roi。在一个实现方式中,不同的染色剂可以用于不同的受关注区域或微结构。这些可以是用户定义的并且如在本文中所解释的手动标记的,或以算法方式生成的。作为示例,用户可以经由gui手动限定各种组织区域并且利用不同的染色剂对它们进行染色(图16和图17)。这导致不同组织成分被不同地染色,如图16和图17所示。使用python分割数据包labelme来实现roi的选择性染色(微结构化)。使用该数据包,生成roi逻辑掩码,然后被处理成用于微结构的标记在另一实现方式中,可以基于例如由分割软件获得的计算机生成的映射对组织的结构进行染色。例如,这可以利用一种(或多种)染色剂对所有细胞核进行虚拟染色,而利用另一种染色剂或染色剂组合对组织22的其余部分进行染色。其他手动、软件或混合方法可以用于实现组织结构的选择多样性。
[0216]
图16示出了显示器106的gui的示例,该显示器包括工具条120,该工具条可以用于选择网络输出图像40中的某些受关注区域以利用特定染色剂进行染色。gui还可以包括不同染色剂选项或染色剂调色板122,其可以用于为网络输出图像40或网络输出图像40内的选定受关注区域选择期望的染色剂。在该具体示例中,通过已由用户手动选择的散列线(区域a、b、c)来识别三个区域。在其他实施方式中,也可以通过图像处理软件104自动识别这些区域。图16示出了包括其中包含一个或多个处理器102的计算装置100和结合训练的深度神经网络10的图像处理软件104的系统。
[0217]
实现方式细节
[0218]
使用具有tensorflow框架版本1.11.0的python版本3.6.0实现虚拟染色网络。该软件可以在任何计算装置100上实现。对于本文所描述的实验,计算装置100是具有2.30ghz的intel xeon w-2195cpu和256gb ram,运行microsoft windows 10操作系统的台式计算机。使用四个nvidia geforce rtx 2080ti gpu进行网络训练和测试。
[0219]
利用多种样式增强训练
[0220]
图20a至图20c示出了利用另外样式增强作为染色剂变换网络10
staintn
(图20c)的深度神经网络的训练的另一实施方式。使用虚拟染色网络10生成的并且旨在用作用于训练染色剂迁移网络10
staintn
的输入的图像被归一化(或标准化)。然而,在某些情况下需要用另外的样式进行增强,因为使用标准组织学染色和扫描生成的全视野数字切片表明由于不同实验室之间的不同染色程序和试剂以及特定的数字全载玻片扫描仪特性而不可避免的可变性。该实施方式因此产生染色剂迁移网络10
staintn
,其可通过在训练过程中结合多种样式来适应宽范围的输入图像。
[0221]
因此,为了将网络10
staintn
的性能推广到该染色可变性,利用另外的染色样式增强网络训练。样式是指可能出现在化学染色的组织样本中的图像的不同可变性。在该实现方式中,决定通过使用cyclegan方法训练的k=8唯一样式迁移(染色归一化)网络来促进该增强,但可以使用其他样式迁移网络。cyclegan是使用两个生成器(g)和两个鉴别器(d)的gan
方法。一对用于将图像从第一域转换到第二域。另一对用于将图像从第二域转换到第一域。例如,这在图21中可见。例如,关于cyclegan方法的细节可见于zhu等人的unpaired image-to-image translation using cycle-consistent adversial networks,arxiv:1703.10593v1-v7(2017-2020),其通过引用结合于本文。这些样式增强确保了宽的样本空间被随后的染色剂变换网络10
staintn
覆盖,并且因此当应用于化学h&e染色的组织样本时,无论技术人员间、实验室间或设备间变化如何,染色剂迁移都将是有效的。
[0222]
样式变换网络10
styletn
可以用于增强虚拟染色剂生成器/变换网络10
staintn
以用于虚拟到虚拟染色剂变换或化学到虚拟染色剂变换。鉴于在化学染色剂(例如,h&e染色剂)中所见的可变性,后者更有可能与染色剂变换网络一起使用。例如,在工业中需要将一种类型的化学染色剂变换为另一种类型的化学染色剂。示例包括化学h&e染色剂以及产生诸如pas、mt或jms的专用染色剂的需要。例如,非肿瘤性肾病依赖于这些“特殊染色剂”来提供护理病理评估的标准。在许多临床实践中,h&e染色剂在特殊染色剂之前是可用的,并且病理学家可以提供“初步诊断”以使得患者的肾病学家能够开始治疗。这在诸如新月体性肾小球肾炎或移植排斥反应的一些疾病的设置中是尤其有用的,其中,快速诊断,随后快速开始或治疗可以导致临床结果的显著改进。在当最初仅h&e载玻片可用的设置中,初步诊断之后是通常在第二工作日提供的最终诊断。如本文所解释的,开发改进的深度神经网络10
staintn
以通过使用h&e染色的载玻片生成三种另外的特殊染色剂:pas、mt和jones六胺银(jms)来改进初步诊断,该h&e染色的载玻片可以同时利用组织化学染色的h&e染色剂由病理学家检查。
[0223]
提出了一组受监督的基于深度学习的工作流程,其使得用户能够使用染色剂变换网络10
staintn
执行两个染色剂之间的变换。这通过首先生成配准的几对虚拟染色的h&e图像和无标记组织切片的同一自发荧光图像的特殊染色剂来实现(图20a)。这些生成的图像可以用于将化学染色的图像变换成专用染色剂。这促进创建完美空间配准的(配对的)数据集,并且允许染色剂变换网络10
staintn
被训练,而不仅仅依赖于分布匹配损失和未配对的数据。此外,未对准不会产生像差,因此提高了变换的准确度。这通过评估具有不同非肿瘤性疾病的肾组织来验证。
[0224]
使用深度神经网络10
staintn
来进行h&e染色的组织与特殊染色剂之间的变换。为了训练该神经网络,一组另外的深度神经网络10相互结合使用。该工作流程依赖于虚拟染色使用单个未标记的组织切片生成多种不同染色剂的图像的能力(图20a)。通过使用单个神经网络10生成h&e图像和一种特殊染色剂(pas、mt或jms)两者,可以创建完全匹配(即,配对)的数据集。由于使用虚拟染色网络10生成的图像的归一化(标准化),旨在在训练染色剂变换网络10
staintn
时用作输入的虚拟染色的图像40利用附加的染色样式来增强以确保一般化(图20b)。这通过图20b中的虚拟染色的图像40通过样式迁移网络10
styletn
运行以创建增强的或样式迁移的输出图像40'来示出。换句话说,染色剂变换网络10
staintn
被设计为能够处理不可避免的h&e染色可变性,其是不同实验室之间的染色程序和试剂以及特定的数字全载玻片扫描仪特性的结果。这种增强由使用cyclegan训练的k=8唯一样式迁移(染色归一化)网络10
styletn
执行(图20b)。这些增强确保宽的h&e样本空间被随后的染色剂变换网络10
staintn
覆盖,并且因此当应用于h&e染色的组织样本时,不论技术人员间、实验室间或设备间变化如何,它将是有效的。注意,即使深度神经网络10
staintn
用于将化学染色剂变换为一
种或多种虚拟染色剂,但对于染色剂样式变换使用不同的虚拟染色输入来完成神经网络10
staintn
的增强训练。
[0225]
使用该数据集,可以使用图20c所示的方案训练染色剂变换网络10
staintn
。网络10
staintn
是随机馈送的图像块,该图像块来自虚拟染色的组织40(上路径),或者来自通过k=8样式迁移网络10
styletn
中的一个(左路径)的虚拟染色的图像,并且生成组织化学染色剂迁移的输出图像40”。无论cyclegan样式迁移如何,对应的特殊染色剂(来自同一未标记视野的虚拟特殊染色剂)用作真值48。然后,在从ucla储存库取得的各种数字h&e载玻片上盲测试网络10
staintn
(对于未训练网络的患者/病例),其表示疾病和染色变化的群组。
[0226]
用于数据增强的染色剂样式迁移的方法
[0227]
为了确保神经网络10
staintn
能够应用于多种h&e染色的组织切片,cyclegan模型用于通过使用样式变换网络10
styletn
进行样式变换来增强训练数据集(图20b)。该神经网络10
styletn
学习在给定训练样本x和y的两个域x和y之间映射,其中,x是原始虚拟染色的h&e的域(图21中的图像40
x
),并且y是在不同的实验室或医院中的h&e生成的图像48y的域。该模型执行两个映射g:x
→
y和f:y
→
x。此外,引入两个对抗鉴别器d
x
和dy。图21中示出了示出这些不同网络之间的关系的示图。如图21所示,虚拟h&e图像40
x
(样式x)被输入到生成器g(x)以创建具有样式y的生成的h&e图像40y。然后使用第二生成器f(g(x))映射回x域以生成图像40
x
。参考图21,组织化学染色的h&e图像40y(样式y)被输入至生成器f(y)以创建具有样式x的生成的h&e图像48
x
。然后使用第二生成器g(f(y))映射回到y域以生成图像48y。图22a和图22b示出了两个生成器网络g(x)(图22a)和f(y)(图22b)的构造。
[0228]
生成器l
generator
的损失函数包含两种项:对抗损失l
adv
,用于将生成图像的染色样式与目标域中的组织化学染色的图像的样式匹配;以及循环一致性损失l
cycle
,以防止所学习的映射g和f彼此冲突。因此,由以下等式描述总损失:
[0229][0230]
其中,λ和是用于对损失函数进行加权的常数。对于所有网络,λ被设置为10,并且被设置为等于1。图21中的每个生成器与鉴别器(d
x
或dy)相关联,确保了生成图像与真值的分布匹配。每个生成器网络的损失可以写为:
[0231]
l
advx
→y=(1-dy(g(x)))2(23)
[0232]
l
advy
→
x
=(1-d
x
(f(y)))2(24)
[0233]
并且循环一致性损失可以被描述为:
[0234]
l
cycle
=l1{y,g(f(y))}+l1{x,f(g(x))}(25)
[0235]
其中,l1损失或平均绝对误差损失由下式给出:
[0236][0237]
在该等式中,p和q是像素索引,并且p和q是横向尺寸上的像素的总数。
[0238]
用于训练d
x
和dy的对抗损失项被定义为:
[0239]
[0240][0241]
对于这些cyclegan模型,g和f使用u网架构。该架构由三个“下块”220以及随后的三个“上块”222组成。下块220和上块222中的每一个包含三个具有3
×
3内核大小的卷积层,在由leakyrelu激活函数激活时,激活该卷积层。下块220各自将通道的数量增加两倍,并且以具有步长和内核大小为2的平均池化层结束。上块222在应用卷积层之前以双三次上采样开始。在某个层的每个块之间,跳跃连接被用于通过网络传递数据而不需要经过所有的块。
[0242]
鉴别器d
x
和dy由4个块构成。这些块包括两个卷积层和leakyrelu对,它们一起将通道数量增加两倍。这些之后是步长为2的平均池化层。在五个块之后,两个全连接层将输出维数减少到单个值。
[0243]
在训练期间,自适应矩估计(adam)优化器用于更新可学习参数,其中,生成器(g)和鉴别器(d)网络两者的学习速率为2
×
10-5
。对于鉴别器训练的每个步骤,针对生成器网络执行训练的一次迭代,并且用于训练的块大小被设置为6。
[0244]
在一些实施方式中,样式变换网络10
styletn
可以包括染色向量的归一化。也可以在同一染色的载玻片的两个不同变化之间以监督的方式训练该训练的网络10
staintn
,其中,该变化是样本用不同显微镜成像或组织化学染色随后对同一载玻片进行第二次重新染色的结果。可由一组配对的虚拟染色的图像训练该训练的网络10
staintn
,每个图像用不同的虚拟染色剂进行染色,由单个虚拟染色神经网络10生成。
[0245]
尽管已经示出和描述了本发明的实施方式,但是在不脱离本发明的范围的情况下,可以进行各种修改。例如,尽管不同的实施方式已经被描述为生成无标记或未染色样本的数字/虚拟染色的显微图像,但是还可以使用利用一种或多种外源性荧光标记或其他外源性光发射体标记该样本的方法。因此,这些样本被标记但不用常规免疫化学(ihc)染色剂标记。因此,本发明不应限于所附权利要求及其等同物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1