单遍次渲染和上缩放的制作方法
1.本发明涉及利用抗锯齿(anti-aliasing)进行图像的渲染和上缩放,例如用于在基于图块(tile)的移动图形处理单元(graphics processing unit,gpu)上的游戏渲染。
背景技术:
2.随着消费电子产品分辨率的提高,对移动gpu的需求也在不断增加。移动gpu需要渲染在4k或8k图像分辨率下的大屏幕产品。4k屏幕正变得越来越受欢迎,8k屏幕现在正走向市场。这些分辨率的要求如图1所示。
3.出于几个原因,使用移动gpu来支持在4k和8k下的渲染是非常具有挑战性的。首先,在1080p分辨率下的手机屏幕上,像素着色阶段已经是大多数3d游戏的瓶颈。其次,大屏幕意味着需要对更多的像素进行着色:4k是1080p分辨率的4倍,8k是1080p分辨率的16倍。即使是现代的高端桌面显卡也可能难以处理这种额外的着色工作负载。因此,可能无法在8k分辨率下自然地执行像素着色。因此,在低分辨率图像被以低成本渲染后可能必须执行上缩放。
4.因为由于像素着色器中涉及的大量着色工作负载,移动gpu通常不可能在8k原生分辨率下直接执行像素着色,所以需要在低分辨率(low resolution,lr)下进行渲染,然后上缩放到目标高分辨率(high resolution,hr)。图2示意性地示出了通过在降低的分辨率下进行渲染然后上缩放到所需的目标分辨率来解决像素着色工作负载的过程。上缩放本质上意味着拉伸lr图像以获得hr图像。需要在lr图像上进行“放大”,以便可以填充更大的hr屏幕进行显示。
5.然而,该过程的缺点是,当游戏在降低的分辨率下执行渲染时,会在低分辨率下发生光栅化。上缩放还意味着在更大的空间域对原始成像信号进行欠采样。因此,这会给渲染结果带来锯齿。这最终会在图像中造成高度尖突状的对象边缘,并且在最坏的情况下,会损害较小对象的整体可见性,导致闪耀和闪烁效果。例如,可能会引入空间噪声和时间闪烁。
6.根据奈奎斯特-香农定理,采样率必须等于或高于信号最高频率的两倍,否则会出现锯齿。
7.移动设备需要实时的渲染性能,对于游戏需要高帧率和低延迟的用户交互。同时,它们需要低功耗以延长电池寿命,并且在用户长时间手持时需要低散热以保持舒适。对于以高屏幕分辨率渲染高质量和复杂的像素着色,同时确保将功耗和散热保持在非常低的水平,这可能是一个两难的选择。
8.一种已知的上缩放方法是最近重建,如在https://en.wikipedia.org/wiki/image_scaling所描述的。在最简单的缩放形式中,原始像素被复制以适合所需的更高的分辨率。这是一种简单快速的上缩放方法。然而,图像质量通常非常差,并且产生的图像可能看起来呈尖突状和块状。
9.如在https://www.techspot.com/article/1873-radeon-image-sharpening-vs-nvidia-dlss/所描述的,dlss利用深度神经网络来提取渲染场景的多维特征,以构建在高
分辨率下的高质量的最终图像。dlss强制游戏在较低的分辨率(通常为1440p)下进行渲染,然后使用人工智能(artificial intelligence,ai)算法来推断如果在更高的分辨率(通常为4k)下进行渲染会是什么样子。这可以减少锯齿。该方法利用nvidia gpu上的专用张量核进行ai算法。需要更少的像素着色,因此渲染速度更快。然而,这种方法是入侵式的,需要在发布前对于每个游戏进行逐个案例的ai训练,涉及到大的训练集和对于每次游戏更新的重新训练。它也不适合没有专用张量核的其他gpu,并且dlss也导致了一些测试场景的模糊图像质量。
10.如在https://www.amd.com/en/technologies/radeon-software-image-sharpening所描述的,镭龙图像锐化是智能锐化技术,可以在不显著降低性能的情况下提升游戏的视觉质量。该效果查看游戏中任何给定场景的高对比度部分,并且人工绘制更多细节。纹理被整体锐化,这可能使1080p图像在上缩放后看起来接近1440p并显示在hr监视器上。与必须在逐个游戏的基础上实现的dlss不同,镭龙图像锐化是在涉及一些空间域图像滤波的上缩放之后的图像后处理。它可以针对任何游戏被打开或关闭,不需要在每个游戏基础上实现,并且是非侵入式的。在大多数情况下,具有专用视频存储器和良好图像质量的独立gpu成本较低。然而,该方法不知道哪些元素应该被锐化,哪些不应该被锐化,并且现有的伪影可能被锐化并且变得更加可见。
11.如在https://software.intel.com/en-us/articles/checkerboard-rendering-for-real-time-upscali ng-on-intel-integrated-graphics所描述的,棋盘渲染是一种产生全分辨率像素的技术,显著减少了着色,对视觉质量的影响最小。它开发了一个解决方案来解决渲染为更高目标分辨率而设计的内容的问题。它可能会将目标分辨率为1080p的内容改为在540p(960x 540)下进行渲染,然后使用棋盘(checkerboard,cbr)技术通过临时组合两个帧的结果来向上缩放到1080p,每个帧都使用2x多重采样抗锯齿(multisample anti-aliasing,msaa)进行渲染。它允许以2x msaa的低成本进行具有良好图像质量的4x上缩放,并且像素着色速率降低(仅为目标hr的四分之一)。但是,第一列像素没有重建,所以会出现锯齿。渲染当前帧时,先前帧必须保持2x msaa。因此,该方法具有带宽成本。如果对象在两个帧之间移动得太快,可能会导致时间伪影,诸如模糊和重影。它也是入侵式的,因为用户必须使用特定的扩展。
12.如在https://microsoft.github.io/directx-specs/d3d/variablerateshading.html所描述的,可变速率着色或粗糙像素着色是一种能够在针对一帧的渲染图像上以不同的速率分配渲染性能和功率的机制。从视觉上看,在有些情况下,可以降低着色速率,但很少或没有降低可感知的输出质量,从而导致“随心所欲”的性能。该模型通过添加粗糙着色的新概念,将具有msaa的超级采样扩展到相反的“粗糙像素”方向。这是可以以比像素更粗糙的频率执行着色的地方。也就是说,可以将一组像素作为单个单元进行着色,然后将结果传播给该组中的所有样点。粗糙着色api允许应用程序指定属于着色组的像素数量。在分配渲染目标后,可以改变粗糙像素大小。因此,屏幕的不同部分或不同的绘制通道可以具有不同的子采样率。可变速率着色是一种将着色速率与可见性解耦的复杂解决方案。它允许以精细的粒度灵活地改变着色速率。屏幕的不同部分或不同的绘制通道可以具有不同的子采样率。然而,vrs具有更复杂的gpu线程调度逻辑,这取决于在屏幕的不同部分访问的密度图像。由于相邻像素之间的不同着色速率的不规则性,对于如此多的
并发gpu线程来说,存在额外的调度成本。为每个帧构建和访问密度图以指定和检索针对每个粗糙像素的着色速率图是有成本的。
13.如在mavridis,p.和papaioannou,g.在2015年的“用于高像素密度显示器上的高能效渲染的基于msaa的粗糙着色”,高性能图形2015(“msaa-based coarse shading for power-efficient rendering on high pixel-density displays”,high performance graphics 2015)中所述,基于msaa的粗糙着色采用了通过使用msaa样点来减少像素着色器调用的类似想法,但它专注于针对现有gpu的软件实现,并且涉及两个渲染遍次:第一遍次以较低的像素计数渲染到中间渲染缓存,但具有适当数量的msaa样点,而第二遍次读取中间渲染缓存并且执行子像素msaa样点到像素的映射。这种两遍次方法的问题在于,存储第一遍次输出的中间渲染缓存(由于针对每个像素的多个msaa样点而具有非常大的存储器大小)必须由第二遍次从ddr存储器读入gpu芯片,由于会在两遍次期间输出和输入相同的中间渲染缓存,因而非常消耗带宽。
14.总之,渲染和上缩放的关键技术问题是,由于移动gpu有限的计算能力、存储器带宽、电池和散热能力,该算法对于移动gpu来说可能过于复杂,并且由于lr渲染以及随后上缩放到hr之后最终图像上有锯齿,图像质量可能较差。
15.需要开发一种克服这些问题的渲染和上缩放方法。
技术实现要素:
16.根据第一方面,提供了一种图形处理系统,其被配置为处理包括多个渲染像素的图像,该系统被配置为将图像分成多个图块,每个图块包括图像的渲染像素的子集并且对应于多个显示像素,该系统包括:片上图块存储器;以及处理器,其中该处理器被配置为针对图像中的至少一个渲染像素执行处理遍次,包括:通过以下方式渲染该渲染像素:确定样点集,每个样点在该渲染像素中具有各自的位置,并且这些位置在该渲染像素中共同具有采样密度;在第一分辨率下对该渲染像素进行着色,以给出该渲染像素的着色结果;以及基于该着色结果将该样点中的每一个的着色值写入片上图块存储器;以及通过根据该样点集的着色值确定在大于第一分辨率的目标分辨率下与渲染像素重叠的多个显示像素中的每一个的显示像素着色值,在片上图块存储器中存储经渲染的渲染像素的上缩放表示。
17.渲染(包括像素着色)和上缩放两者都可以在沿着gpu流水线的仅一个单渲染遍次中完成。这可以产生在高分辨率下的高质量最终图像。在一些实现方式中,可能没有尖突状的对象边缘,具有移动gpu上低着色分辨率下非常低的渲染成本和低存储器带宽消耗。
18.每渲染像素可以执行一次着色。在低分辨率下使用每像素着色可以以低渲染成本产生高分辨率下的高质量最终图像。
19.目标分辨率可以比第一分辨率大等于渲染像素的采样密度的因子。这可以允许在移动gpu的片上图块存储器中的上缩放期间,从片上存储器中读取每个像素的样点,并逐个解析为相应的显示像素(每显示像素一个样点)。
20.采样密度可以对应于多重采样抗锯齿级别。多重采样抗锯齿(msaa)级别可以是4x或16x。可以使用其他msaa级别。这可以允许像素在被上缩放到目标分辨率之前在低分辨率下被渲染。
21.该系统可以由移动图形处理单元来实现。这可以允许该系统在诸如智能手机和平
板电脑等消费产品中实现。
22.渲染像素的渲染可以进一步包括:针对样点位置中的每一个,确定相应的样点位置是否被图像中的图元覆盖。具有被确定为被图元覆盖的位置的每个样点的着色值可以等于渲染像素的着色结果。这可以导致较低的渲染成本。
23.渲染像素的着色位置可位于被确定为被图像中的图元覆盖的样点的质心处。被确定为被渲染像素中的图元覆盖的样点中的每一个可以对应于经渲染像素中的相同颜色,这是由每像素着色产生的。因此,像素可以仅被着色一次,并且结果仅被分配给由图元覆盖的样点。
24.处理器可以被配置为随后将存储在片上图块存储器中的上缩放表示写入系统存储器中的帧缓存。这可以允许图像被随后显示。
25.该系统可以被配置为实现应用编程接口。应用编程接口可以是vulkan或opengl es。可以使用其他合适的api。诸如vulkan等api的子遍次特征(或等效特征)可用于在片上图块存储器内执行自定义解析(从具有多个样点的像素到多个最终像素)。
26.在这些api中使用扩展可以允许样点位置被移动到像素内的常规网格位置。在vulkan中,一个渲染遍次可以拆分成多个子遍次,这允许在单个处理遍次中执行渲染和上缩放,而不需要修改gpu的硬件。
27.存储上缩放表示的步骤可以包括将渲染像素的样点中的一个和/或样点的着色值中的一个转换成在目标分辨率下的一个显示像素。这可以允许在上缩放到高分辨率之前在低分辨率下渲染像素。
28.目标分辨率可以是4k或8k。这可以允许该系统在当前的高分辨率消费电子产品中实现。可以使用其他目标分辨率。
29.根据第二方面,提供了一种用于在图像处理系统中处理图像的方法,该图像包括多个渲染像素,该系统被配置为将图像分成多个图块,每个图块包括图像的渲染像素的子集并且对应于多个显示像素,该方法针对图像中的至少一个渲染像素在处理遍次中包括:通过以下方式渲染渲染像素:确定样点集,每个样点在渲染像素中具有各自的位置,并且这些位置在渲染像素中共同具有采样密度;在第一分辨率下对渲染像素进行着色,以给出渲染像素的着色结果;并且基于着色结果将样点中的每一个的着色值写入片上图块存储器;以及通过根据该样点集的着色值确定在大于第一分辨率的目标分辨率下与渲染像素重叠的多个显示像素中的每一个的显示像素着色值,在片上图块存储器中存储经渲染的渲染像素的上缩放表示。
30.使用这种方法,渲染和上缩放两者都可以沿着gpu流水线仅在一个单渲染遍次中完成。这可以产生在高分辨率下的高质量最终图像。在一些实现方式中,可能没有尖突状的对象边缘,具有移动gpu上的非常低的渲染成本(由于低分辨率下的每像素着色)和低存储器带宽消耗。
31.该方法还可以包括:针对样点位置中的每一个,确定相应的样点位置是否被图像中的图元覆盖。具有被确定为被图元覆盖的位置的每个样点的着色值可以等于渲染像素的着色结果。这可能带来较低的渲染成本。
32.目标分辨率可以比第一分辨率大等于渲染像素的采样密度的因子。这可以允许从片上存储器中读取每个像素的样点的着色值,并逐个解析为片上图块存储器中的相应显示
像素(每显示像素一个样点着色值)。
33.采样密度可以对应于多重采样抗锯齿级别。这可以允许像素在被上缩放到目标分辨率之前在低分辨率下被渲染。
34.根据第三方面,提供了一种计算机程序,当由计算机执行时,该计算机程序使得计算机执行上面描述的方法。计算机程序可以在非暂时性计算机可读存储介质上提供。
附图说明
35.现在将参照附图通过举例的方式描述本发明。
36.在附图中:
37.图1显示了不同屏幕分辨率的要求。
38.图2示意性地示出了在降低的分辨率下进行渲染,然后上缩放。
39.图3示意性地示出了一种流水线,其中渲染和上缩放两者仅在一个单渲染遍次中完成。
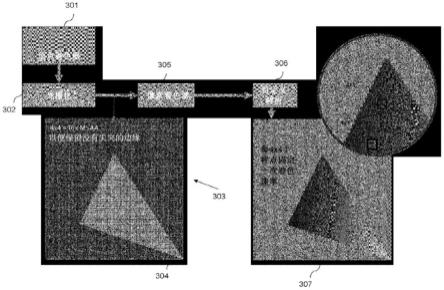
40.图4(a)和4(b)分别示意性地示出了无质心采样和有质心采样的渲染。
41.图5示意性地示出了将样点位置移动到像素内的常规网格位置。
42.图6示出了在输出到系统存储器之前gpu的图块缓存硬件块的修改。
43.图7示出了用于处理图像的方法的示例的流程图。
44.图8示出了图形处理系统的示例。
45.具体实现方式
46.本文中,渲染指的是生成可视图像的任何形式,例如用于在计算机屏幕上显示图像、打印或投影。
47.图3示出了由图形处理系统实施的渲染流水线。实现流水线的系统包括片上图块存储器和处理器。该系统实现基于图块的渲染,并且被配置为接收包括多个渲染像素的待渲染图像。该系统被配置为将图像分成多个图块,每个图块包括输入图像的渲染像素的子集,并且对应于多个显示像素。
48.如现在将描述的,处理器被配置为沿着移动gpu流水线在单遍次中执行图像的渲染和上缩放。
49.在渲染阶段,在301所示的顶点着色之后,图像被光栅化,如302所示。多重采样抗锯齿(msaa)用于减轻几何图形边缘的锯齿。使用多重采样缓存(渲染目标)有助于实现这一点。针对缓存的一些可能配置是2x、4x、8x、16x(即nx,其中“n”表示每像素分配的样点数量)。msaa作为流水线的光栅化阶段302的一部分而发生,并且在图3中通常以303示出。在图3所示的示例中,使用了16x msaa。然而,也可以使用其他msaa级别,例如4x。
50.msaa由硬件中的gpu支持,允许针对图元,仅对像素进行一次着色(即在像素着色器中计算rgb颜色),但将结果存储在针对该像素的多个样点中。在一个优选实现方式中,诸如图3中的三角形304之类的图元可以在“n”个采样点中的每一个上进行测试覆盖,从而建立一个16位(对于16x msaa)覆盖掩码,标识由三角形覆盖的像素部分。然后执行一次像素着色器305,并且像素的着色结果被分配给由覆盖掩码标识的样点。然后,固定功能gpu硬件将该多重采样缓存解析为针对帧缓存中的每个最终像素的单个颜色值,以解决边缘锯齿问题。
51.默认情况下,解析硬件可以计算这些多个样点的平均颜色,作为每个像素的最终颜色。例如,如果像素的前三个样点包含完全相同的着色(在4x msaa下),而第四个样点包含背景色,则对它们求平均会为对象边缘上的最后像素产生抗锯齿输出。然而,如将在下面更详细描述的,在本文描述的系统中,可以采用质心采样,并且对于图元,像素可以被着色一次,但是结果仅被分配给由图元覆盖的样点。
52.因此,使用msaa,流水线确定每像素一组n个样点,每个样点在像素中具有各自的位置,并且这些位置在像素中共同具有等于msaa级别的采样密度。在优选实现方式中,然后可以确定像素中的哪些样点被图像中的图元覆盖。
53.然后,执行像素着色器305来对每个渲染像素着色一次(逐像素着色),以针对每个像素给出着色结果。然后,基于像素的着色结果,将样点中的每一个的着色值写入片上图块存储器(即图块缓存)。在优选实现方式中,着色结果被分配给由系统确定为被图元覆盖的样点。在渲染之后,如306所示,然后对存储在片上图块存储器(图块缓存)中的经渲染像素的多个样点执行自定义解析。如下面将更详细描述的,在根据渲染像素的样点集的着色值确定与渲染像素重叠的每个显示像素的显示像素着色值之后,在片上图块存储器中存储经渲染像素的上缩放表示。该样点集的着色值中的一个被分配给一个显示像素,作为该显示像素在高分辨率图像中的着色值。
54.处理器可以被配置为随后在目标分辨率下将上缩放表示写入系统存储器中的帧缓存。一旦图像中的所有像素已经被渲染和上缩放并且被输出到系统存储器,最终图像307就可以被显示。
55.因此,图像的渲染(包括像素着色)和上缩放两者都仅在沿着流水线的一个单渲染遍次中完成。该流水线支持在低分辨率(lr)下进行渲染,同时通过在移动gpu上的单渲染遍次获得在高分辨率(hr)下的最终图像。
56.这是通过隐式利用硬件的msaa功能来实现的。可以启用上缩放功能,以便通过自定义解析操作来上缩放片段输出(来自像素着色器),该自定义解析操作将msaa样点颜色解析为移动gpu的片上图块存储器内的最终像素颜色。结果,在上缩放期间,中间msaa缓存不需要访问系统存储器。
57.因此,在完成所有其他片段操作(包括例如阿尔法混合)之后,自定义解析渲染像素的多个样点中的每一个,以产生单个显示像素颜色值,最终可以在hr下将其写入系统存储器中的相应颜色缓存。
58.在一个实现方式中,颜色缓存的写入可以被推迟到稍后的时间,彼时图块的所有像素都已经被渲染和上缩放,并且可以对应于图块成批地被输出到系统存储器。
59.在一个特定示例中,4x上缩放(对应于使用4x msaa级别进行渲染)的算法步骤如下。在打开4x msaa的情况下,执行到低分辨率帧缓存的3d渲染。在低分辨率下执行每像素着色,即,对每个像素(具有四个样点)着色一次,使得像素内由图元覆盖的所有样点将具有相同的共享颜色。
60.在本文描述的优选实现方式中,像素的着色位置位于片段的所有被覆盖样点位置的几何中心。图4(a)和4(b)分别示意性地示出了无质心采样和有质心采样的渲染。在图4(a)中,像素402的着色位置401位于所有样点403、404、405、406的中心,而不管这些样点是否被图元407覆盖。在图4(b)中,使用质心采样,像素402的着色位置408仅位于被覆盖样点
404、406的中心。因此,使用质心采样时,一个像素被着色一次,并且结果只被分配给被图元覆盖的样点。这可以通过将“质心”着色器限定符添加到所有片段着色器输入(用于变化的插值)来实现。
61.如上所述,在基于图块的渲染过程结束时,就在将图块缓存写入系统存储器(即,ddr中的帧缓存)之前,使用片上图块缓存内的自定义解析算法来执行自定义解析。使用4xmsaa,从lr图块缓存读取每个像素的四个样点,并且逐个解析为hr图块缓存中的2x2显示像素(每显示像素一个样点),然后可以将其写入系统存储器中的hr帧缓存进行显示。结果是hr帧缓存,其比lr帧缓存大4倍。
62.gpu可以实现应用编程接口,诸如vulkan或opengl es。
63.当api是opengl es时,可以使用api扩展gl_arb_sample_location(全局用户定义样点位置),以便可以将所有样点位置移动到像素内的常规网格位置(如图5(b)所示),而不是使用硬件默认位置,如图5(a)所示。图5(a)和(b)中所示的这些位置对应于针对帧缓存的所有像素的全局设置。
64.因此,样点位置可以从默认位置改变到渲染像素内的常规网格位置。这发生在上缩放步骤之前的渲染步骤期间。
65.当使用vulkan api时,可以类似地使用相应的api扩展vk_ext_sample_locations,以将样点位置移动到常规网格位置。
66.在另一个示例中,16x上缩放的算法步骤如下。渲染到lr帧缓存是在打开16x msaa的情况下执行的。在lr下执行每像素着色,对一个像素(具有16个样点)着色一次,使得像素内被图元覆盖的所有样点将具有相同的颜色。类似于图5(b)中所示的示例,通过针对所有片段着色器输入使用“质心”着色器限定符,片段的着色位置被移动到被图元覆盖的所有样点的位置的几何中心(用于变化插值)。
67.自定义解析在基于图块的渲染结束时执行(在将图块缓存写入ddr之前)。来自lr图块缓存的每个像素的16个样点被逐个解析为在最终的hr图块缓存中的4x4显示像素(每个显示像素仅有一个样点),其然后被写入ddr中的hr帧缓存以供显示。结果是hr帧缓存,其比lr帧缓存大16x。
68.可以使用用于opengl es的api扩展gl_arb_sample_location和用于vulkan的vk_ext_sample_locations(全局用户定义样点位置),从而可以将样点位置移动到像素内的常规网格位置,如图5(b)中的501b、502b、503b和504b所示,而不是使用图5(a)中所示的默认位置501a、502a、503a、504a。
69.可以使用如下伪代码在lr的像素粒度上实现自定义解析算法(每个像素包含多个样点,并且每个样点可以具有4字节的rgba颜色):
[0070][0071]
现在将描述在移动gpu上实现自定义解析算法的两个示例性解决方案。这些解决方案可以方便地利用移动gpu的片上图块存储器。一个解决方案是经由专用的固定功能硬件。另一个解决方案是经由vulkan api中的子遍次(subpass)特征。这两个解决方案都仅需要gpu进行一个单渲染遍次,就可以执行渲染和上缩放两者。
[0072]
在第一个解决方案中,如图6所示,需要修改硬件来将lr附件(attachment)解析为hr附件。专用的固定功能硬件在图块缓存单元601处实现自定义解析,图块缓存单元601仅访问片上存储器以用于解析。
[0073]
移动gpu 602上的图块缓存(片上图块存储器)601如下所述被修改。为了渲染图块,图块缓存模块在两种不同的分辨率下维护两个片上颜色缓存(用于图块):lr和hr。lr缓存需要高msaa级别(例如,4x或16x),而hr缓存要求每像素仅一个样点。
[0074]
如图6所示,图块缓存601在基于图块的渲染流水线的末端处(在将图块缓存写入ddr之前)执行自定义解析,使得lr缓存处的每个样点颜色可以被写入hr图块缓存中作为最终像素颜色,该最终像素颜色将最终被写入ddr 604中的显式帧缓存603中用于显示。
[0075]
由于两个图块缓存的存储器大小相同(尽管一个在lr,另一个在hr,并具有不同的msaa级别),所以可以通过仅分配图块缓存的一个副本来使用就地解析。例如,lr图块缓存的msaa级别可以是4或16,而hr图块缓存的msaa级别可以是1,每像素仅一个样点。
[0076]
对于4x上缩放,可以通过读入一个像素的多个(4x)样点的rgba值,然后将它们作为2x2像素块写入图块缓存内的相同地址来实现这种就地解析。因为在读入之后,不再需要像素的多个(4x)样点的rgba值,所以相同的存储器位置可以作为hr缓存被覆写。
[0077]
在第二个解决方案中,通过使用vulkan api的子遍次特征,无需修改硬件即可执行自定义解析。在这种实现方式中,不需要修改gpu驱动程序和硬件。
[0078]
对于移动gpu中的基于图块的渲染器,如果后续渲染操作在相同的分辨率下,并且如果需要当前正被渲染的相同像素位置的数据(访问不同的像素位置将需要访问当前图块之外的值,这会破坏这种优化),则先前渲染的结果可以有效地保留在片上。vulkan中的解决方案是将一个渲染遍次的渲染操作拆分为多个子遍次,这些子遍次共享相同的分辨率和图块排列,以便一个子遍次可以访问先前子遍次的结果。
[0079]
因此,在vulkan中,渲染遍次可以包括多个子遍次,并且一个子遍次可以访问在输出到系统存储器之前仍然存储在移动gpu的片上存储器中的图块的先前子遍次的渲染结果。
[0080]
该解决方案利用这一特征,通过使用两个子遍次来实现单遍次流水线,包括渲染和自定义解析两者。
[0081]
应当注意,在vulkan中,一个遍次的多个子遍次共享相同的唯一渲染分辨率,并且不能输出具有多个不同分辨率(例如lr和hr)的渲染目标。为了与vulkan规范保持一致,两个子遍次的渲染目标(颜色附件)都可以设置为lr。但是,只有第一子遍次的渲染目标可能会被实际使用,而第二子遍次可能不会输出其渲染目标。相反,第二子遍次可以输出在hr下的单独的存储图像(例如,使用glsl着色语言中的imagestore()函数),使得系统可以在任意像素位置输出任意分辨率。
[0082]
因此,该解决方案使用存储图像作为输出来补偿子遍次渲染,以便系统可以输出比渲染目标分辨率更高的分辨率。
[0083]
4x上缩放的算法步骤如下。在第一子遍次中:在打开4x msaa的情况下,像素在lr下被渲染到其渲染目标。第二子遍次执行自定义解析,这将渲染一个全屏四边形。在片段着色器中,针对每个像素从第一子遍次的渲染目标中读取四个样点(作为输入),但将解析的结果(即4个输出像素)写入在hr下的存储图像(即使用imagestore函数),而不是写入其自己的渲染目标。因此,第二子遍次可能不会向其自己的渲染目标输出任何内容。虽然它的渲染目标设置在lr,但它可能不会被使用。输入和输出的示例如下:
[0084]
输入:subpassload(gsubpassinputms subpass0,int sample);
[0085]
输出:imagestore到storage_image,使用vk_image_usage_storage_bit创建,使用这个着色器函数:
[0086]
imagestore(gimage2d image,ivec2 p,gvec4 data);
[0087]
在一个示例中,第二子遍次的着色器代码可以如下所示:
[0088]
[0089][0090]
上面描述的第二示例性解决方案的好处是不需要修改驱动程序或硬件。如下表所示,流水线还可以支持其他上缩放因子,其中msaa_level=xscale*yscale,其中(xscale,yscale)是沿x和y方向的上缩放值对。
[0091]
表1
[0092]
msaa_level可能的上缩放值对:(xscale,yscale)2x(1,2)或(2,1)4x(2,2)、(1,4)或(4,1)8x(2,4)、(4,2)、(1,8)或(8,1)16x(4,4)、(2,8)、(8,2)、(1,16)或(16,1)
[0093]
如果上缩放值对不是{1,1},则像素颜色值被渲染到在lr下的中间渲染缓存,其msaa级别大于1x,例如2x、4x、8x或16x。得到的最终图像的分辨率在hr下,是lr的msaa_level倍。
[0094]
上面描述的使用子遍次特征的解决方案也可以使用其他类似的3d api来实现,例如directx12或metel。可以使用具有子遍次特征的任何api,由此第一子遍次可以用于渲染像素,第二子遍次可以用于将像素上缩放到目标分辨率。对于opengl es api,子遍次解决方案可以类似地在gpu驱动程序中由图块结束(end-of-tile)着色器(也称为后帧着色器)实现,该着色器是对当前图块的像素进行后处理的片段着色器。这可以在图块被渲染到图块缓存后立即启动。
[0095]
在上面描述的示例中,msaa被用于为每个渲染像素确定样点集。然而,超级采样抗锯齿(supersampling anti-aliasing,ssaa)也基于上述原理操作,并且可以替代地使用。ssaa针对每个像素的所有被覆盖样点执行像素着色器。因此,ssaa的成本可能比msaa更高。msaa沿着几何边缘操作,而ssaa甚至在几何图形内部操作。这导致更高的视觉质量,但与msaa相比,性能成本更高。由于这个原因,优选使用msaa。
[0096]
图7示出了详细描述用于在图像处理系统中处理图像的方法的示例的流程图,该图像包括多个渲染像素,该系统被配置为将图像分成多个图块,每个图块包括图像的渲染像素的子集,并且对应于多个显示像素。该方法包括在处理遍次中针对图像中至少一个渲染像素的以下步骤。在步骤701至703中,渲染像素被渲染。在步骤701中,该方法包括确定样点集,每个样点在渲染像素中具有各自的位置,并且这些位置在渲染像素中共同具有采样密度。在步骤702,该方法包括在第一分辨率下对渲染像素进行着色,以给出渲染像素的着色结果。在步骤703,该方法包括基于着色结果将样点中的每一个的着色值写入片上图块存储器。在步骤704,通过根据该样点集的着色值确定在大于第一分辨率的目标分辨率下与渲染像素重叠的多个显示像素中的每一个的显示像素着色值,在片上图块存储器中存储经渲
染像素的上缩放表示来上缩放经渲染像素。
[0097]
图8是被配置为执行本文描述的方法的系统800的示意图。系统800可以在设备上实现,诸如膝上型电脑、平板电脑、智能电话、电视或要在其中处理图形数据的任何其他设备。该系统优选地由移动gpu实现。
[0098]
系统800包括被配置为处理数据的图形处理器801。例如,处理器801可以是gpu。可选地,处理器801可以被实现为运行在可编程设备上的计算机程序,诸如gpu或中央处理单元(cpu)。系统800包括片上存储器802,其被设置为与图形处理器801通信。该系统可以包括不止一个处理器和不止一个存储器。存储器可以存储可由处理器执行的数据。处理器可以被配置为根据以非暂时性形式存储在机器可读存储介质上的计算机程序来操作。计算机程序可以存储用于使处理器以本文描述的方式执行其方法的指令。处理器还可以将数据写入外部系统存储器(图8中未示出)。
[0099]
总之,在本文描述的gpu中,使用msaa在lr下执行渲染,并且在图块缓存(gpu的片上存储器)处执行自定义解析以产生hr图像。在lr下执行像素着色,对每个像素(具有n个样点)着色一次。优选地,被像素内的图元覆盖的所有样点将具有相同的颜色。在将上缩放的样点从图块缓存写入系统存储器之前,在图块缓存处执行自定义解析。例如,在使用16x msaa的情况下,来自lr的渲染像素的16个样点被输出到得到的hr图像中的4
×
4像素中(每像素一个样点)。因此,在打开msaa的情况下,在lr下渲染像素,然后在同一渲染流水线的末端处执行自定义解析操作,以产生hr(高分辨率)的最终图像,而不是在基于图块的移动gpu中使用硬件的默认行为进行msaa解析。
[0100]
因此,该系统被配置为在移动gpu上的单渲染遍次中执行渲染(包括像素着色)和上缩放。在一些实现方式中,与两遍次(即,一次针对渲染一次针对上缩放)方法相比,这可以导致显著更少的存储器和带宽消耗。
[0101]
这使得能够以非常低的着色成本在低分辨率下进行像素着色,并且可以产生没有尖突状对象边缘的高分辨率最终图像。这是通过隐式地利用硬件msaa功能并通过在同一渲染流水线的末端使用自定义解析解决方案来实现的。
[0102]
这对于各种渲染技术可能是有用的,在这些渲染技术中,期望以高效且廉价的方式为大屏幕产品生成没有尖突状边缘的高质量上缩放图像。
[0103]
在lr下可能有明显较低的片段着色成本,但可实现hr最终图像。从lr图像产生hr图像不需要显式的拉伸。在某些实现方式中,由于进行4x或16x msaa的光栅化,可能没有尖突状边缘。多边形的边缘(3d图形中最明显的锯齿来源)可能会抗锯齿。
[0104]
在一些实现方式中,本文描述的方法可以具有更高的带宽效率,因为基于图块的渲染流水线利用了移动gpu上的片上图块存储器,使得自定义解析仅访问用于中间渲染缓存的片上图块存储器(而不是系统存储器),以产生最终hr图像,并且需要处理器的单渲染遍次,而没有任何从lr到hr的图像拉伸。因此,该方法的存储器带宽效率可能要高得多,因此比传统方法更适合带宽有限的移动gpu。
[0105]
较低的gpu片段着色速率(在lr下)和较低的存储器和带宽消耗可以延长移动设备的电池寿命,并提高复杂和要求苛刻的游戏渲染的帧速率。
[0106]
申请人因此单独公开了本文描述的每个单独的特征以及两个或更多个这样的特征的任何组合,在某种程度上,这样的特征或组合能够根据本领域技术人员的公知常识基
于作为整体的本说明书来实现,而不管这样的特征或特征的组合是否解决了本文公开的任何问题,并且不限制权利要求的范围。申请人指出,本发明的各方面可以由任何这样的单独特征或特征的组合组成。鉴于前面的描述,对于本领域技术人员来说,显然可以在本发明的范围内进行各种修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1