自动化机器学习方法及其装置与流程
本公开(disclosure)的技术思想涉及一种自动化机器学习方法以及装置。
背景技术:
1、机器学习(machine learning)作为人工智能(ai)的一个领域,以数据为基础,是开发能够使计算机进行学习的算法和技术的领域,作为图像处理、影像识别、语音识别、网络检索等各个领域的核心技术,在预测(prediction)、对象检测(detection)、对象分类(classification)、对象分割(segmentation)和异常检测(anomaly detection)中表现出卓越的性能。
2、为了通过上述机器学习推导出具有目标性能的学习模型,需要适当地选择用于机器学习的神经网络(neural network)。然而,由于神经网络的选择没有绝对的标准,因此选择符合待应用的领域或输入数据的特性的神经网络不可避免地成为一个难题。
3、例如,根据数据集的种类,深层的网络可能具有更好的性能,但也可能存在即使没有深层也能获得足够性能的情况,尤其是生产企业,有时会非常看重推理时间(inferencetime),因此可能不适合深度网络。
4、并且,学习模型的性能受用户设置的多个超参数(hyper parameter)的影响,因此设置超参数使其适合输入数据等的特性是机器学习的一个重要课题。
5、然而,由于机器学习的黑盒特性,为了得到适合输入数据集的超参数,需要对所有可能的情况进行非常费力的实验过程,尤其是非专业人士,还存在难以推测哪种超参数可以带来有意义的变化的问题。
技术实现思路
1、要解决的技术问题
2、根据本公开的技术思想的自动化机器学习方法及其装置要解决的技术问题在于,提供一种自动化机器学习方法以及装置,能够快速地自动优化网络函数及其参数以使其适合输入数据等的特性。
3、根据本公开的技术思想的方法及用于其的装置要解决的技术问题并不局限于以上提及的问题,本领域的技术人员可以通过下文的记载明确理解未提及的其他问题。
4、用于解决问题的手段
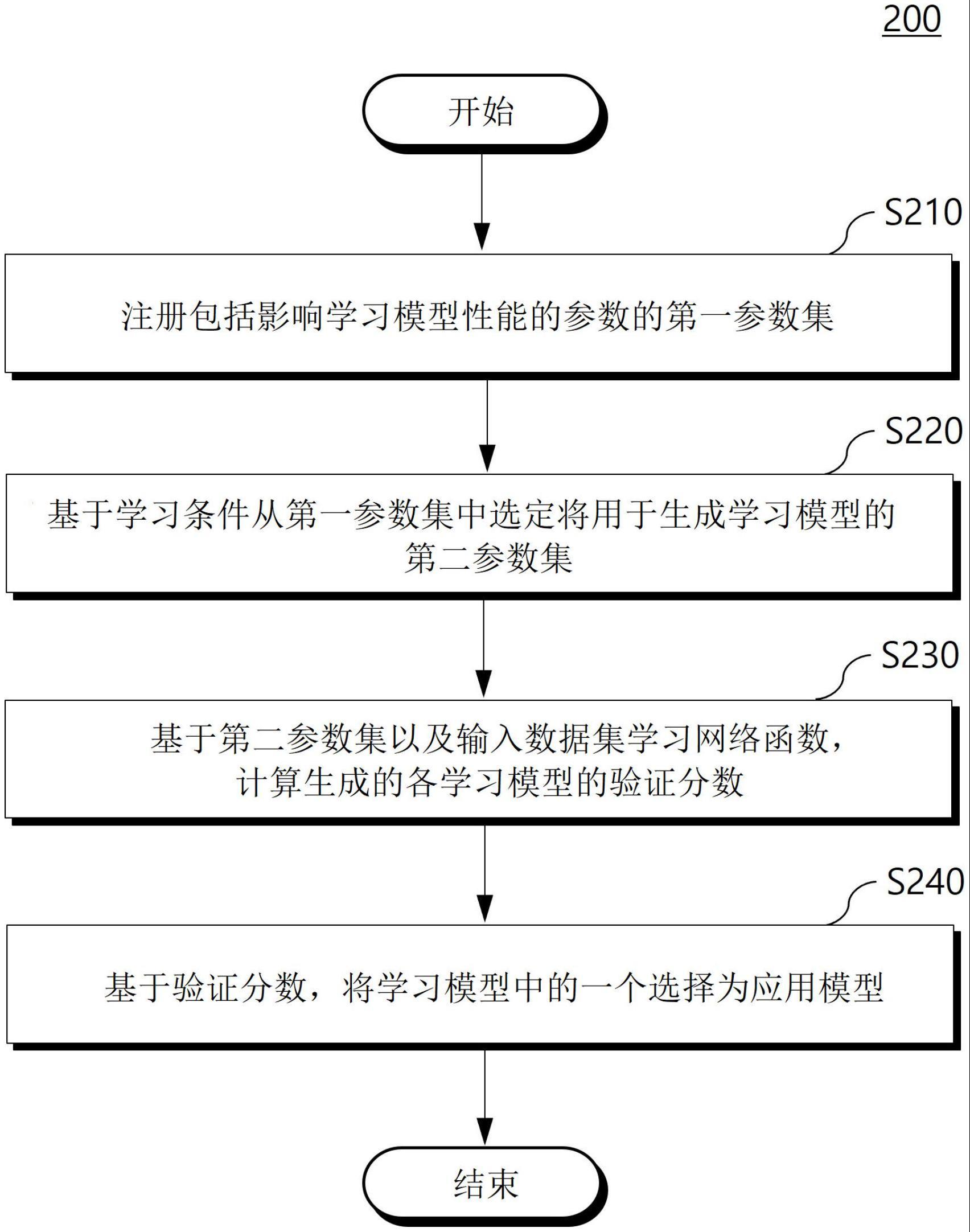
5、根据本公开的技术思想的一实施例,自动化机器学习方法可以包括如下步骤:注册至少一个第一参数集,其包括影响学习模型性能的至少一个参数的不同设置数据的组合;基于输入的学习条件,从所述第一参数集中选定将用于生成所述学习模型的至少一个第二参数集;基于所述第二参数集以及预定的输入数据集学习网络函数,从而生成与各所述第二参数集对应的所述学习模型,计算各所述学习模型的验证分数(validationscore);以及基于所述验证分数,将生成的所述学习模型中的一个选择为应用模型。
6、根据示例性实施例,注册所述第一参数集的步骤可以包括如下步骤:对所述至少一个参数进行不同设置数据的组合,从而生成多个候选参数集;通过第一数据集分别对各所述候选参数集进行所述网络函数的学习,执行交叉验证;以及根据所述交叉验证的结果,将所述候选参数集中至少一个确定为所述第一参数集。
7、根据示例性实施例,可以基于与所述第一数据集不同的至少一个第二数据集,反复执行所述交叉验证的步骤和确定为所述第一参数集的步骤。
8、根据示例性实施例,所述交叉验证的结果包括计算的各所述候选参数集的所述交叉验证的验证分数的平均及标准偏差,在确定为所述第一参数集的步骤中,基于所述验证分数的平均及标准偏差执行统计学比较,从而将具有高于预定的基准值(baseline)的性能的所述候选参数集确定为所述第一参数集。
9、根据示例性实施例,所述第一参数集可以包括与网络函数种类、优化器(optimizer)、学习速度(learning rate)以及数据增强(data augmentation)中至少一个相关的参数的设置数据。
10、根据示例性实施例,所述学习条件可以包括与学习环境、推理速度(inferencespeed)以及检索范围中至少一个相关的条件。
11、根据示例性实施例,选定所述第二参数的步骤包括如下步骤:基于架构(architecture)以及所述推理速度中至少一个排列所述第一参数集;以及根据输入的所述学习条件,将排列的所述第一参数集中靠前的预定比率选定为所述第二参数集。
12、根据示例性实施例,基于召回率(recall)、精确率(precision)、准确率(accuracy)以及它们的组合中至少一个计算所述验证分数。
13、根据本公开的技术思想的一实施例,自动化机器学习装置可以包括:存储器,存储用于自动化机器学习的程序;处理器,通过运行所述程序,注册至少一个第一参数集,其中所述第一参数集包括影响学习模型性能的至少一个参数的不同设置数据的组合,然后基于输入的学习条件,从所述第一参数集中选定将用于生成所述学习模型的至少一个第二参数集,基于所述第二参数集以及预定的输入数据集学习网络函数,从而生成与各所述第二参数集对应的所述学习模型,计算各所述学习模型的验证分数,基于所述验证分数,进行控制以将生成的所述学习模型中的一个选择为应用模型。
14、根据示例性实施例,所述处理器可以通过对所述至少一个参数进行不同设置数据的组合,从而生成多个候选参数集,通过第一数据集对各所述候选参数集进行网络函数的学习以执行交叉验证,根据所述交叉验证的结果,进行控制以将所述候选参数集中至少一个确定为所述第一参数集。
15、根据示例性实施例,所述处理器可以基于与所述第一数据集不同的至少一个第二数据集,进行控制以反复执行所述交叉验证以及根据所述交叉验证的结果的所述第一参数集的确定。
16、根据示例性实施例,所述处理器可以计算各所述候选参数集的交叉验证的验证分数的平均及标准偏差,基于所述验证分数的平均及标准偏差执行统计学比较,从而进行控制以将具有高于预定的基准值(baseline)的性能的所述候选参数集确定为所述第一参数集。
17、根据示例性实施例,所述第一参数集可以包括与网络函数种类、优化器(optimizer)、学习速度(learning rate)以及数据增强(data augmentation)中至少一个相关的参数的设置数据。
18、根据示例性实施例,所述学习条件可以包括与学习环境、推理速度(inferencespeed)以及检索范围中至少一个相关的条件。
19、根据示例性实施例,所述处理器可以基于架构(architecture)及推理速度中至少一个来排列所述第一参数集,然后根据输入的所述学习条件,进行控制以将排列的所述第一参数集中靠前的预定比例选定为所述第二参数集。
20、根据示例性实施例,基于召回率(recall)、精确率(precision)、准确率(accuracy)以及它们的组合中至少一个计算所述验证分数。
21、发明效果
22、根据本公开的技术思想的实施例的自动化机器学习方法及用于其的装置,用户仅通过输入学习条件和输入数据等即能实现自动选择合适的网络函数和优化超参数,从而即使是非专业人员也可以轻松地生成和使用学习模型。
23、此外,根据本公开的技术思想的实施例的自动化机器学习方法及用于其的装置,通过对具有高于特定基准值的性能的有意义的超参数组合的预先搜索和注册,可以最小化优化超参数所需的检索范围和时间。
24、根据本公开的技术思想的方法及用于其的装置可以获得的效果并不局限于上述的效果,本公开所属技术领域的普通技术人员通过下面的记载可以清楚理解其他未言及的效果。
- 还没有人留言评论。精彩留言会获得点赞!