基于字符嵌入的汉字编码方法
本发明涉及模式识别与计算机视觉领域,具体涉及一种基于字符嵌入的汉字编码方法。
背景技术:
语言是人类传播信息的主要方式之一,文字是书面的语言,也是人类通过视觉传递信息最广泛的方式之一。
随着人工智能、互联网等技术的迅速发展,使用计算机自动识别图像中的文本具有重要意义。对于字符识别任务,通常采用独热编码的方式对字符进行编码,这种编码方式忽略了相似字符之间的相关性,且较为稀疏,对于英文字符和数字的识别任务来说,由于类别数较少,适用性尚可。然而对于中文字符识别任务,由于汉字类别繁多,仅常见字符就有上千种,这导致使用独热编码的网络收敛较慢,且完全忽略了汉字之间的结构形状相似性,导致字符识别准确度低,效率低。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于字符嵌入的汉字编码方法,能有效降低汉字编码的维度,使得具有相似构成的汉字编码具有正相关性,有效提高字符识别效率。
为实现上述目的,本发明采用如下技术方案:
一种基于字符嵌入的汉字编码方法,包括以下步骤:
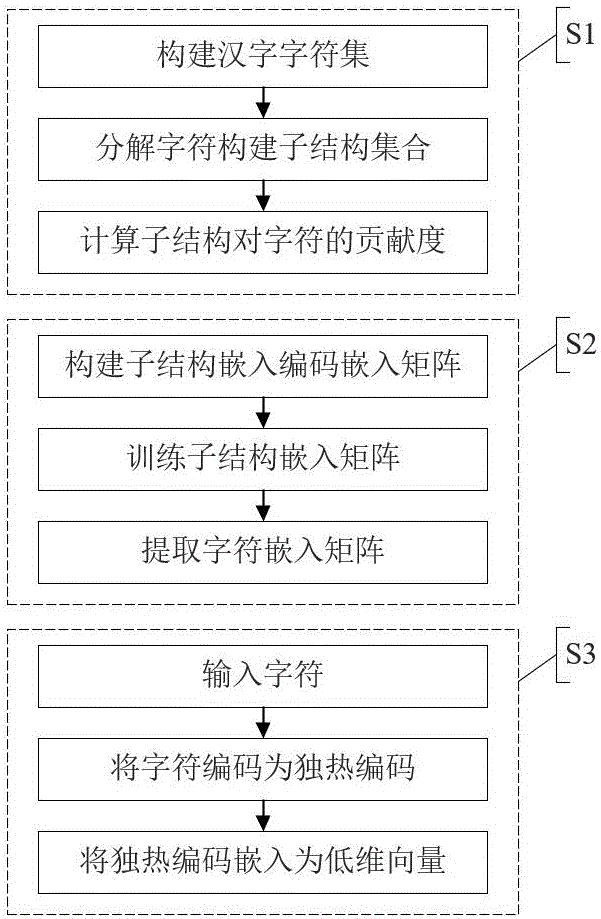
步骤s1:构建汉字字符集,将每个字符分解为若干个子结构,构建子结构集合,定义每个子结构对字符的贡献度,并根据子结构集合,构建子结构对每个字符贡献度矩阵;
步骤s2:根据得到的子结构集合和子结构对每个字符贡献度矩阵,构建子结构嵌入矩阵并训练,提取得到字符嵌入矩阵;
步骤s3:输入字符,通过字符嵌入矩阵获取字符嵌入。
进一步的,所述步骤s1具体为:
步骤s11:确定需要编码的字符集合,第ia个汉字为charia,共有nchars个需要嵌入的汉字,则字符集合为chars={charia|ia=1,2,...,nchars};
步骤s12:对chars中所有汉字进行拆分,得到所有的子结构parts={partib|ib=1,2,...,nparts},其中partib为第ib个子结构,nparts为parts的元素数量;
步骤s13:计算子结构频次表nfreqparts={nfreqib|ib=1,2,...,nparts},其中nfreqib表示partib是nfreqib个字符的子结构;
步骤s14:由于k=1时拆分结果为字符分身,chars是parts的子集,建立映射关系g,使得partib=partg(ia);
步骤s15:计算parts中每一个子结构对chars中每一个字符的贡献度,得到nparts行nchars列的贡献度矩阵charsparts。
进一步的,所述步骤s12具体为:
(1)预设每个汉字都能拆分为k个子结构;
(2)k为不小于1的整数,当k为1时拆分结果为字符本身;
(3)k的最大值为一个字符的笔画数或kmax,kmax为人工设定的最大拆分数;
按照(1)-(3)对chars中所有汉字进行拆分,得到所有的子结构parts={partib|ib=1,2,...,nparts},其中partib为第ib个子结构,nparts为parts的元素数量。
进一步的,所述步骤s15具体为:
(1)当一个汉字拆分为k部分时,拆分的子结构对字符的贡献度为
(2)当一个子结构同时出现在一个字符的多种拆分结果中时,取k最小的一种拆分方法计算贡献度;
(3)如果一个子结构无法构成某字符,则该子结构对该字符的贡献度为0;
按照(1)-(3)计算parts中每一个子结构对chars中每一个字符的贡献度,得到nparts行nchars列的贡献度矩阵charsparts。
进一步的,所述步骤s2具体为:
步骤s21:构建一对子结构嵌入矩阵embs1、embs2,embs1和embs2均为nparts行m列的矩阵,其中m为人工设定的嵌入得到的向量维度;
步骤s22:对parts中每个子结构进行独热编码,则partib的独热编码为ponehotib,则所有子结构的独热编码为ponehots={ponehotib|ib=1,2,…,nparts};
步骤s23:对于第ib个子结构,ponehotib有概率f(nfreqib)作为中心子结构,概率计算方法如下式:
其中min为最小值函数,α为人工设定的参数,然后设置大小为t的窗口,t为人工设定的正整数参数,通过charsparts的第ib行的分布作为字符的概率分布,抽取t个字符,并利用映射g将字符编号映射到子结构编号,放入窗口中,作为相关子结构,再随机抽取r个子结构作为无关子结构,r为人工设定的正整数参数;
步骤s24:通过子结构嵌入矩阵将独热编码嵌入到向量的计算如下式:
emb=ponehot×embsparts
其中embsparts为子结构嵌入矩阵,ponehot为子结构的独热编码,emb为嵌入后的向量,将中心子结构的独热编码通过embs1嵌入得到嵌入向量emb1;
步骤s25:将t个相关子结构的独热编码通过embs2嵌入得到t个嵌入向量emb2ps={emb2pic|ic=1,2,…,t},其中emb2pic为t个嵌入向量的第ic个;
步骤s26:将r个无关子结构的独热编码通过embs2嵌入得到t个嵌入向量emb2ns={emb2nid|id=1,2,...,r},其中emb2nid为r个嵌入向量的第id个;
步骤s27:使用下式计算损失loss,并优化网络:
其中∑ic表示遍历ic=1,2,...,t的求和符号,∑id表示遍历id=1,2,…,r的求和符号,
其中,x为自变量,e为自然常数,log为以e为底的对数函数;
步骤s28:基于步骤s23至s27,遍历ib=1,2,...,nparts若干次,直到网络收敛,将embs1作为训练好的子结构嵌入矩阵;
步骤s29:通过映射关系g从embs1提取字符嵌入矩阵embschar,其中embschar的第ia行对应embs1的g(ia)行,通过映射关系g从ponehots提取字符独热编码表conehots={conhotia|ia=1,2,...,nchars},其中conhotia=ponehotg(ia)。
进一步的,所述步骤s3具体为:
步骤s31:选取一个待编码的汉字;
步骤s32:使用conehots将待编码的汉字编码为独热编码;
步骤s33:使用embschar将独热编码嵌入为低维向量。
本发明与现有技术相比具有以下有益效果:
本发明能有效降低汉字编码的维度,使得具有相似构成的汉字编码具有正相关性,有效提高字符识别效率
附图说明
图1是本发明方法流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于字符嵌入的汉字编码方法,包括以下步骤:
步骤s1:构建汉字字符集,将每个字符分解为若干个子结构,构建子结构集合,定义每个子结构对字符的贡献度,并根据子结构集合,构建子结构对每个字符贡献度矩阵;
步骤s2:根据得到的子结构集合和子结构对每个字符贡献度矩阵,构建子结构嵌入矩阵并训练,提取得到字符嵌入矩阵;
步骤s3:输入字符,通过字符嵌入矩阵获取字符嵌入。
在本实施例中,所述步骤s1具体为:
步骤s11:确定需要编码的字符集合,第ia个汉字为charia,共有nchars个需要嵌入的汉字,则字符集合为chars={charia|ia=1,2,...,nchars};
步骤s12:(1)预设每个汉字都能拆分为k个子结构;
(2)k为不小于1的整数,当k为1时拆分结果为字符本身;
(3)k的最大值为一个字符的笔画数或kmax,kmax为人工设定的最大拆分数;
按照(1)-(3)对chars中所有汉字进行拆分,得到所有的子结构parts={partib|ib=1,2,...,nparts},其中partib为第ib个子结构,nparts为parts的元素数量。
步骤s13:计算子结构频次表nfreqparts={nfreqib|ib=1,2,...,nparts},其中nfreqib表示partib是nfreqib个字符的子结构;
步骤s14:由于k=1时拆分结果为字符分身,chars是parts的子集,建立映射关系g,使得partib=partg(ia);
步骤s15:(1)当一个汉字拆分为k部分时,拆分的子结构对字符的贡献度为
(2)当一个子结构同时出现在一个字符的多种拆分结果中时,取k最小的一种拆分方法计算贡献度;
(3)如果一个子结构无法构成某字符,则该子结构对该字符的贡献度为0;
按照(1)-(3)计算parts中每一个子结构对chars中每一个字符的贡献度,得到nparts行nchars列的贡献度矩阵charsparts。
在本实施例中,所述步骤s2具体为:
步骤s21:构建一对子结构嵌入矩阵embs1、embs2,embs1和embs2均为nparts行m列的矩阵,其中m为人工设定的嵌入得到的向量维度;
步骤s22:对parts中每个子结构进行独热编码,则partib的独热编码为ponehotib,则所有子结构的独热编码为ponehots={ponehotib|ib=1,2,...,nparts};
步骤s23:对于第ib个子结构,ponehotib有概率f(nfreqib)作为中心子结构,概率计算方法如下式:
其中min为最小值函数,α为人工设定的参数,然后设置大小为t的窗口,t为人工设定的正整数参数,通过charsparts的第ib行的分布作为字符的概率分布,抽取t个字符,并利用映射g将字符编号映射到子结构编号,放入窗口中,作为相关子结构,再随机抽取r个子结构作为无关子结构,r为人工设定的正整数参数;
步骤s24:通过子结构嵌入矩阵将独热编码嵌入到向量的计算如下式:
emb=ponehot×embsparts
其中embsparts为子结构嵌入矩阵,ponehot为子结构的独热编码,emb为嵌入后的向量,将中心子结构的独热编码通过embs1嵌入得到嵌入向量emb1;
步骤s25:将t个相关子结构的独热编码通过embs2嵌入得到t个嵌入向量emb2ps={emb2pic|ic=1,2,…,t},其中emb2pic为t个嵌入向量的第ic个;
步骤s26:将r个无关子结构的独热编码通过embs2嵌入得到t个嵌入向量emb2ns={emb2nid|id=1,2,...,r},其中emb2nid为r个嵌入向量的第id个;
步骤s27:使用下式计算损失loss,并优化网络:
其中∑ic表示遍历ic=1,2,...,t的求和符号,∑id表示遍历id=1,2,...,r的求和符号,
其中,x为自变量,e为自然常数,log为以e为底的对数函数;
步骤s28:基于步骤s23至s27,遍历ib=1,2,...,nparts若干次,直到网络收敛,将embs1作为训练好的子结构嵌入矩阵;
步骤s29:通过映射关系g从embs1提取字符嵌入矩阵embschar,其中embschar的第ia行对应embs1的g(ia)行,通过映射关系g从ponehots提取字符独热编码表conehots={conhotia|ia=1,2,...,nchars},其中conhotia=ponehotg(ia)。
在本实施例中,所述步骤s3具体为:
步骤s31:选取一个待编码的汉字;
步骤s32:使用conehots将待编码的汉字编码为独热编码;
步骤s33:使用embschar将独热编码嵌入为低维向量。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!