流域巨系统的有序度分析方法及装置
本公开涉及流域管理技术领域,尤其涉及一种基于黄河流域巨系统的有序度分析方法及装置。
背景技术:
目前,对于河流和河道的研究,均是对某一类自然或社会现象进行模拟和分析,系统范围存在局限性,并不包括自然、生态环境和人类社会发展的全部内容。
技术实现要素:
为克服相关技术中存在的问题,本公开提供一种流域巨系统的有序度分析方法及装置,建立流域综合性评价指标体系,并对指标数据进行采集和清洗,基于指标数据,计算信息熵值,并利用熵权法进行子系统和巨系统的熵值计算,根据熵值计算结果评价流域巨系统的发展的有序程度,从而为流域发展提供辅助决策工具。
根据本公开实施例的第一方面,提供一种流域巨系统的有序度分析方法,所述方法包括:
确定所述流域的巨系统的边界和结构,将所述流域的巨系统划分为河流子系统、生态环境子系统和人类经济子系统,并建立流域综合性评价指标体系,其中,所述各个子系统中均包括多个评价指标,所有评价指标构成所述流域巨系统的综合性评价指标体系;
分别采集并清洗预设时间段内所述综合性评价指标体系中所有评价指标的指标数据;
基于所述指标数据,利用熵权法分别计算各个子系统和所述巨系统的信息熵值,以根据所述信息熵值评估所述巨系统和各个子系统的有序程度。
在一个实施例中,优选地,基于所述指标数据,利用熵权法分别计算各个子系统和所述巨系统的信息熵值,以根据所述信息熵值评估所述巨系统和各个子系统的有序程度,包括:
确定各个评价指标发展的标准区间;
计算各个评价指标对与其对应的标准区间内不同标准区间的可能度函数,以确定每个评价指标取值的可能度函数分布;
根据每个评价指标取值的可能度函数分布,计算每个评价指标对应的信息熵值;
利用预设修正算法对所述信息熵值进行修正,以得到修正后的信息熵值;
根据评价指标的数目和各个评价指标的修正后的信息熵值进行计算,得到该评价指标对应的信息熵权重;
根据各子系统中各个评价指标的修正后的信息熵值和对应的信息熵权重进行加权求和,以得到该子系统对应的总熵值;
根据各个子系统的总熵值,评价各个子系统和所述巨系统的有序程度演变。
在一个实施例中,优选地,采用以下计算公式确定每个评价指标取值的可能度函数分布:
对于第1个标准区间:
对于第k个标准区间(k=2,3,…n-1):
对于第n个标准区间:
其中,x表示所述评价指标取值,levelk(k=1~n)代表各标准区间的临界值,level1<level2<……<leveln-1,coef=n。
在一个实施例中,优选地,采用以下第一计算公式计算所述信息熵值,
其中,
其中,n表示标准区间的个数,pk代表可能度函数值fk在所有值中的比重,fk表示评价指标k的可能度函数分布。
在一个实施例中,优选地,所述预设修正算法包括:
其中,x代表要修正的目标评价指标取值,s代表所述信息熵值,si代表所述修正后的信息熵值,xmid代表目标评价指标良和中两个标准的分界值,
在一个实施例中,优选地,采用以下第二计算公式计算所述信息熵权重,
其中,wi表示所述信息熵权重,n表示评价指标的数目,si表示评价指标i的修正后的信息熵值,其中,i=1,2,…,n。
在一个实施例中,优选地,采用以下第三计算公式评价各个子系统的有序程度演变:
其中,si表示评价指标i的修正后的信息熵值,wi表示所述信息熵权重,
在一个实施例中,优选地,所述河流子系统的评价指标包括以下至少一项:
年降水量、总水量、来沙量、主河槽过洪能力、总冲淤量和来水来沙协调度;
所述生态环境子系统的评价指标包括以下至少一项:
重要断面生态激流保证率、重要水功能区水质达标率、重要支流水质达到或优于ⅲ类河长比例、生境质量指数、植被覆盖指数、水网密度指数、土地胁迫指数、黄土高原水土流失治理面积、典型区域湿地面积变化率;
所述人类经济子系统的评价指标包括以下至少一项:
常住人口、城镇化率、城镇居民人均可支配收入、人均公园绿地面积、gdp增长率、人均gdp、第三产业占比、灌区面积、夜晚灯光数据、流域用水总量、万元工业增加值用水量。
根据本公开实施例的第二方面,提供一种流域巨系统的有序度分析装置,所述装置包括:
确定模块,用于确定所述流域的巨系统的边界和结构,将所述流域的巨系统划分为河流子系统、生态环境子系统和人类经济子系统,并建立流域综合性评价指标体系,其中,所述各个子系统中均包括多个评价指标,所有评价指标构成所述流域巨系统的综合性评价指标体系;
数据处理模块,用于分别采集并清洗预设时间段内所述综合性评价指标体系中所有评价指标的指标数据;
第一计算模块,用于基于所述指标数据,利用熵权法分别计算各个子系统和所述巨系统的信息熵值;
评价模块,用于根据所述流域巨系统和各个子系统的信息熵值,评价所述各个子系统和流域巨系统的系统有序程度发展变化的趋势。
根据本公开实施例的第三方面,提供一种计算机可读存储介质,其上存储有计算机指令,所述指令被处理器执行时实现如第一方面实施例中任一项所述方法的步骤。
本公开的实施例提供的技术方案可以包括以下有益效果:
本发明实施例中,建立流域综合性评价指标体系,并对指标数据进行采集和清洗,基于指标数据,计算信息熵值,并利用熵权法进行子系统和巨系统的熵值计算,根据熵值计算结果评价流域巨系统的发展的有序程度,从而为流域发展提供辅助决策工具。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1是根据一示例性实施例示出的黄河流域巨系统的架构图。
图2是根据一示例性实施例示出的流域发展评价指标体系的示意图。
图3是根据一示例性实施例示出的流域巨系统的有序度分析方法的流程图。
图4是根据一示例性实施例示出的流域巨系统的有序度分析方法中步骤s302的流程图。
图5是根据一示例性实施例示出的流域巨系统的有序度分析方法中步骤s303的流程图。
图6是根据一示例性实施例示出的指数型可能度函数曲线的示意图。
图7是根据一示例性实施例示出的可能度函数及修正计算后的信息熵值曲线的示意图。
图8是根据一示例性实施例示出的黄河下游冲淤量信息熵计算结果的示意图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
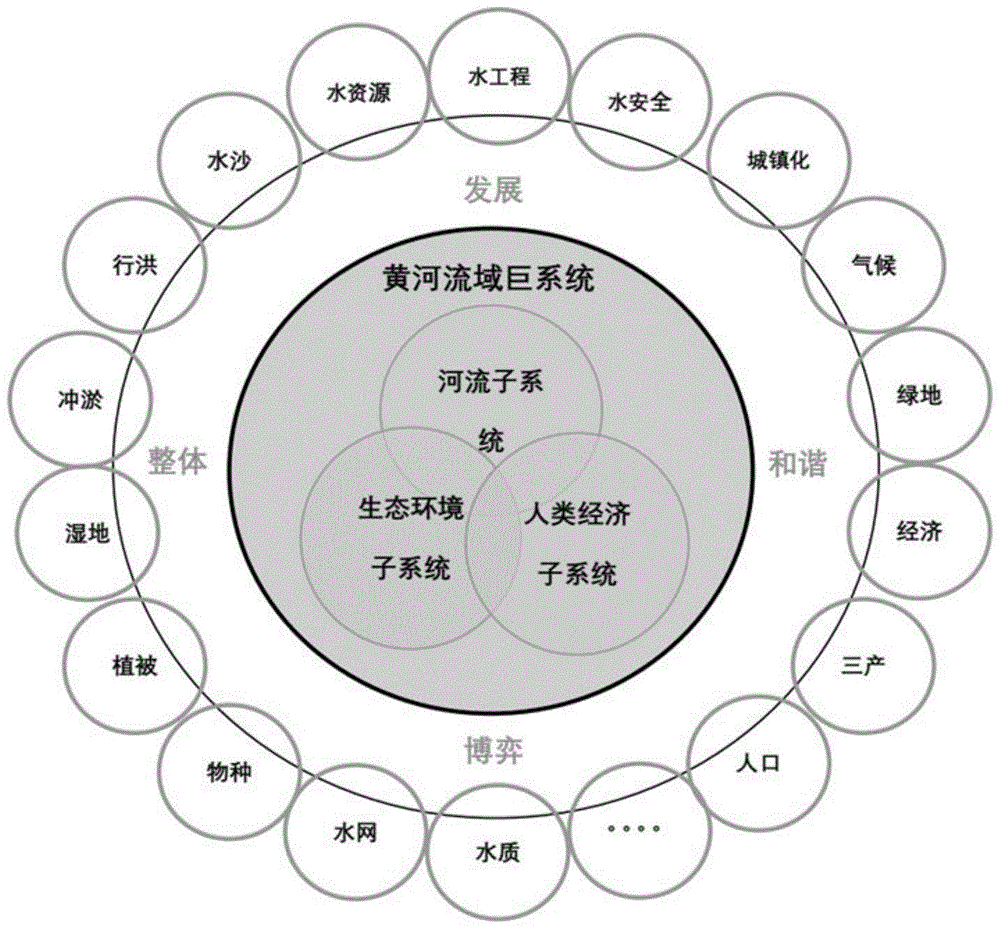
黄河是一个复杂的巨系统,治理黄河是一项复杂的系统工程。因此,无论黄河治理的整体战略、实施方案,还是不同河段的治理方略、工程布局,或是单一工程的具体设计、运行管理,在其全生命周期的各个阶段,都必须以系统论思想方法为统领,把黄河流域作为一个有机的复合系统,统筹考虑。黄河流域的系统治理要以河流基本功能维持、区域社会经济高质量发展、流域生态环境有效保护三维协同为整体治理目标,多维度研究黄河流域综合治理的整体布局及不同治理措施之间的博弈协同效应。
总体来讲,黄河流域系统功能可以从三个方面考虑:
1)从河流功能角度,黄河是一条自然条件复杂、河情极其特殊的河流,“水少沙多、水沙关系不协调”,上中游地区的干旱风沙、水土流失灾害和下游河道的泥沙淤积、洪水威胁,严重制约着流域及相关地区经济社会的可持续发展。另外,黄河是我国西北、华北地区的重要水源,水资源开发利用关系着国家经济安全、能源安全、粮食安全和西北、华北地区经济社会的可持续发展。
2)从生态环境功能角度,黄河流域是连接青藏高原、黄土高原、华北平原的生态廊道,拥有三江源、祁连山等多个国家公园和国家重点生态功能区。黄河流经黄土高原水土流失区、五大沙漠地,沿河两岸分布多个湿地。黄河流域构成了我国重要的生态屏障,黄河流域生态环境保护关系着流域及相关地区的生态安全。
3)从经济发展功能角度,黄河流域是我国重要的经济地带,黄淮海平原、汾渭平原、河套灌区是农产品主产区,流域土地资源、矿产资源特别是能源资源十分丰富,在全国占有极其重要的地位,被誉为我国的“能源流域”,是我国重要的能源、化工、原材料和基础工业基地,未来发展潜力巨大。更重要的是,黄河流域是多民族聚集区,由于历史和自然条件原因,黄河流域特别是上中游地区和下游滩区,经济社会发展相对落后。
因此,按照流域功能化分,黄河流域巨系统可以分为河流子系统、生态环境子系统、人类经济子系统,涉及要素众多,关系复杂,既相互联系又相互制约,因此如何既保障黄河流域水安全,又能实现黄河流域生态保护,同时推进黄河流域高质量发展是非常复杂的重大问题。黄河流域巨系统架构如图1所示。
河流子系统以河道治理为重点,主要涉及行洪、水沙、水资源、水工程等多方面的要素。黄河的泥沙问题世界罕见,“二级悬河”问题突出,防洪一直是治黄的首要任务,黄河的河道治理是涉及多方面要素的复杂问题。rhi(riverhealthindex,河流健康指数)从系统论的角度出发,考虑水资源、洪水、泥沙三个方面,选取年降水总量、总水量、主河槽过洪能力、来沙量、总淤积量、来水来沙协调度6个关键指标,通过信息熵和熵权法计算得到河流健康指数。
生态环境子系统以生态保护为重点,黄河流域包括森林、湿地、物种、水环境、水生态等多方面的要素,是我国重要的生态屏障,是连接青藏高原、黄土高原、华北平原的生态廊道,拥有三江源、祁连山等多个国家公园和国家重点生态功能区,同时黄河流经黄土高原水土流失区、五大沙漠沙地,沿河两岸分布有东平湖和乌梁素海等湖泊、湿地,河口三角洲湿地生物多样。生态环境是由生物群落及非生物自然因素组成的各种生态系统所构成的整体。长期以来,在自然因素和人为因素的共同作用下,生态环境以不同的时空尺度在发展演变。edi(environmentdevelopmentindex,环境演变指数)从生态环境保护角度出发,量化研究生境质量、植被覆盖、土地胁迫、水网湿地等相关因素,是基于系统理论、信息熵和熵权分析得到的用于评价流域生态环境发展质量的综合性指标。
人类经济子系统包括人口、产业、经济、文化等多方面的要素,是黄河流域经济高质量发展的重要问题,黄河流域是我国重要的经济地带。sdi(socialdevelopmentindex,社会发展指数)能够反映流域居民特征、衡量居民福祉,综合表征流域经济发展现状和增长活力,是流域社会经济研究中不可或缺的内容。从人口特征、居民生活质量、经济增长水平、地区产业结构等4个角度,选取12个社会经济特征指标,通过信息熵和熵权法计算得到社会发展指数,定量分析黄河流域近40年的社会发展演变特征。
rhi,edi和sdi为表征河流子系统、生态环境子系统、人类经济子系统发展质量提供参考依据,是治河决策理论的重要研究部分。
为了支持中观层和宏观层的数据分析工作,微观层的重点工作是构建黄河流域巨系统指标体系和收集指标数据。根据黄河流域巨系统的内涵,结合国内外关于河流发展评价的相关实践,针对黄河流域生态保护和高质量发展要求,构建流域发展评价指标体系见图2。
下面详细说明本发明的技术方案。
图3是根据一示例性实施例示出的流域巨系统的有序度分析方法的流程图。
本发明实施例中提供一种流域巨系统的有序度分析方法,如图3所示,所述方法包括:
步骤s301确定所述流域的巨系统的边界和结构,将所述流域的巨系统划分为河流子系统、生态环境子系统和人类经济子系统,并建立流域综合性评价指标体系,其中,所述各个子系统中均包括多个评价指标,所有评价指标构成所述流域巨系统的综合性评价指标体系;
在一个实施例中,优选地,所述河流子系统的评价指标包括以下至少一项:
年降水量、总水量、来沙量、主河槽过洪能力、总冲淤量和来水来沙协调度;
所述生态环境子系统的评价指标包括以下至少一项:
重要断面生态激流保证率、重要水功能区水质达标率、重要支流水质达到或优于ⅲ类河长比例、生境质量指数、植被覆盖指数、水网密度指数、土地胁迫指数、黄土高原水土流失治理面积、典型区域湿地面积变化率;
所述人类经济子系统的评价指标包括以下至少一项:
常住人口、城镇化率、城镇居民人均可支配收入、人均公园绿地面积、gdp增长率、人均gdp、第三产业占比、灌区面积、夜晚灯光数据、流域用水总量、万元工业增加值用水量。
步骤s302,分别采集并清洗预设时间段内综合性评价指标体系中所有评价指标的指标数据;
步骤s303,基于所述指标数据,利用熵权法分别计算各个子系统和所述巨系统的信息熵值,以根据所述信息熵值评估所述巨系统和各个子系统的有序程度。
在该实施例中,建立流域综合性评价指标体系,并对指标数据进行采集和清洗,基于指标数据,计算信息熵值,并利用熵权法进行子系统和巨系统的熵值计算,根据熵值计算结果评价流域巨系统的发展的有序程度,从而为流域发展提供辅助决策工具。
如图4所示,在一个实施例中,优选地,上述步骤s302包括:
步骤s401,按照时间序列,采用分区域或分河段的方法从各省资料库、水文站点和流域管理机构的数据库中获取预设时间段内多个评价指标的指标数据。
在该实施中,评价指标可以从时间和空间两个维度来获取。时间维度的信息构成时间序列数据,对于黄河流域发展指数的评价,将研究范围设定在近40年的时间尺度内,也就是从上世纪80年代开始。数据的颗粒度对所有的评价指标需要统一,受限于数据的可获取性,本发明采用年度平均数值。
空间维度上,采用分区域或分河段的方法来搜集数据,再将搜集到的数据化归到流域层级。流域共跨九省,对应的生态、环境数据可以从各省资料库中搜集,对于水文、泥沙等河流方面的专业数据,则来自于各水文站点及流域管理机构的内部数据,对不同区域的数据进行平均化处理、或以典型区域数据代表较大区域数据来逐层得到流域层面数据。
步骤s402,确定各个评价指标的指标数据的完整性;
步骤s403,根据所述完整性,采用对应的数据补齐方法对所述指标数据进行数据补齐,以得到完整的指标数据,其中,所述数据补齐方法包括:直线插值方法、样条插值方法、拉格朗插值方法和灰色预测方法。
在该实施例中,在数据收集阶段整理的数据是经过各行业专家的认定的成果。首先,应对收集到的指标数据进行预处理。比如对于黄河流域发展指数的评价,要求的数据是近40年的历史年度数据。对于有空间差异的指标,同样要求数据在每个空间或区域内也有完整的时间序列。对系统演变的评价是基于指标按照时间的变化规律。在建立了所有指标数据的完整时间序列之后,进行指标间的加和集成,一步一步构成大巨系统的评价指标。由于各种原因,时间序列数据存在一定的缺失现象,对于缺失的年份,应该根据不同的情况,采取不同的补齐策略:
(1)整片的指标数据缺失。一般近年的数据相对完备,而早年的数据缺失更为严重,有时会出现大片数据的缺失。这时候应该基于该指标的一般变化规律和波动情况,再结合历史上发生过的重要影响事件或颁布的重大治河策略,来进行一定的推测,最好给出几个年份的数据作为控制点。在此基础上,基于已有的时间序列,向前回溯,推测历史年份的数据。
(2)缺少逐年数据,只有每几年(一般是5年)出现的数据。某些指标没有每年测量统计,而是每隔一定时间统计一次,这种情况就可以按照上一种情况中给出控制点的情形来处理。
(3)零星缺少某些年份数据。这种情况相对容易处理,在整个时间序列中,如果缺少某一年的数据,一般可以直接用相邻两年份数据的均值来代替缺失数据,不会对系统评估结果产生较大的影响。
(4)少数情况下,会缺少最后一年的数据。这应该是因为最新的统计数据尚未出炉,可以利用近些年的数据加以预测得出最新年份的数据。
对于缺失数据的补齐,主要用到的数据处理方法有直线插值、样条插值、拉格朗插值及灰色预测法等方法。
其中,在专家审查数据的基础上,对于极个别异常数据(即数据噪点),在确定了异常原因之后,考虑影响该指标的各方面因素,结合专家经验综合判断,对其进行针对性处理,给出修正的数据。
图5是根据一示例性实施例示出的流域巨系统的有序度分析方法中步骤s303的流程图。
如图5所示,在一个实施例中,优选地,上述步骤s303包括:
步骤s501,确定各个评价指标发展的标准区间;
步骤s502,计算各个评价指标对与其对应的标准区间内不同标准区间的可能度函数,以确定每个评价指标取值的可能度函数分布;
根据灰色系统理论,灰数是取值信息不明确的一类数值,可以通过可能度函数(possibilityfunction)来描述其取不同数值区间的“可能性”的大小。对于一个评价指标体系,指标取值的区间可以分为几个等级,每个等级都代表着该指标不同的发展水平。本发明中,根据国家标准、规范规程、国际认可的指标标准以及类似研究的最新成果,将各指标发展质量划分为优、良、中、差四个等级,进而计算指标标准的可能度函数。
利用可能度函数,对于每个评价指标取值,可以求出该值对不同标准区间的可能度函数,基于这些函数取值,就可以计算反映该要素指标发展状况的信息熵值。本发明采用了针对标准型可能度函数的改进版本――指数型可能度函数,具体计算如下:
对于第1个标准区间:
对于第k个标准区间(k=2,3,…n-1):
对于第n个标准区间:
其中,x表示所述评价指标取值,levelk(k=1~n)代表各标准区间的临界值,level1<level2<……<leveln-1,coef=n。
对于所有的标准区间,有level1<level2<……<leveln-1,取coef=n,由于n>1,使得可能度函数在取值区间之外区域快速减小,这符合可能性函数概念的本意。对于已确立的优、良、中、差四个标准,对于指标的全部(理论)取值范围,可以绘制指数型可能度函数曲线,如图6中所示。
图6中四种不同标号的曲线分别代表该指标值对四个标准区间的可能度函数。可能度函数的优点在于,对于某一指标取值,可以借助设置的区间,来充分挖掘指标取值所蕴含的信息,这些信息共同刻画出该最小系统单元的发展情况。
步骤s503,根据每个评价指标取值的可能度函数分布,计算每个评价指标对应的信息熵值;
本发明中,基于每个评价指标取值的可能度函数分布,信息熵值由式4和式5计算得到。
式4和式5中,n代表评价指标值标准区间的个数,pk代表各标准可能度函数值在所有值中的比重。根据指标值计算的可能度函数和对应的熵值计算结果见图6。从可能度函数计算结果中不难发现,在取值较大或较小时,随着取值远离中间标准区域,几个指标等级对应的可能度函数值将向更集中的趋势演变,直接导致熵值的减小。
根据这一发现,考虑到熵值减小对系统的有益性,结合指标的越大越优或越大越劣的性质,本发明提出新型信息熵计算方法,将熵值的计算过程做相应的修正,即根据指标极性,修正较差指标值所对应的熵值计算过程。对于越大越优的指标,可以将取值小于良、中两个标准的分界值的指标取值所对应的熵值修正,计算方法见式6。对于负极性的指标,用类似方法,相应翻转较大取值(右侧)区间即可,修正后的熵值曲线总体单调递增。对所有的熵值统一做上述修正,不会影响利用熵值的变化规律来衡量系统发展的优劣。
步骤s504,利用预设修正算法对所述信息熵值进行修正,以得到修正后的信息熵值。
在一个实施例中,优选地,所述预设修正算法包括:
其中,x代表要修正的目标评价指标取值,s代表所述信息熵值,si代表所述修正后的信息熵值,xmid代表目标评价指标良和中两个标准的分界值,
修正后的熵值曲线总体单调递减,见图7。
图8中展示了“黄河下游冲淤量”这一指标的熵值计算结果。冲淤量的计量单位为亿立方米,取值可正可负,正值代表泥沙淤积,负值代表泥沙被冲刷,所以对于泥沙问题,冲淤量取值带有负极性,即越小越优,该系统单元也越有序。从图中可以看出,随着原始值的减小,信息熵值也随之减小,并且两条曲线的趋势十分接近,也就是说用该指标的熵值度量其发展质量具有科学依据。
用上述方法修正后得到的熵值曲线,不管对于原始数值越大越优,还是越大越劣的指标,其优秀取值范围所对应的信息熵值均较小。这样一来,就在指标值的优劣性和对系统产生熵增熵减的效应之间,建立了直接相关的联系。信息熵就可以作为一个当量,像一把尺子一样,统一系统中所有指标的量纲和单位,直接量化每个指标对系统发展产生的影响。
步骤s505,根据评价指标的数目和各个评价指标的修正后的信息熵值进行计算,得到该评价指标对应的信息熵权重;
步骤s506,根据各子系统中各个评价指标的修正后的信息熵值和对应的信息熵权重进行加权求和,以得到该子系统对应的总熵值;
指标的信息熵权重用式7求得,利用各指标的熵值和权重,经过对某系统内指标熵值进行加权求和,可以计算得出该系统总熵,如式8中所示。
式7和8中,n代表需要加权的评价指标的数目,si和wi分别代表评价指标的修正后的信息熵值和对应的信息熵权重,ssys代表系统的总熵值。
步骤s507,根据各个子系统的总熵值,评评价各个子系统和所述巨系统的有序程度演变。
根据式8可以计算各子系统的总熵值,进一步地,将取值区间设定在[0,100],可以根据式9-11计算三个子系统的发展指数:
式9-11中,si和wi分别代表三个子系统所下辖各评价指标的信息熵值熵权,n代表各子系统下辖指标的数目。
在该实施例中,针对整个复杂巨系统或者其中的任意子系统,都可以算出每一个指标的信息熵权重,进而判断流域巨系统中哪一个或几个指标对系统有序的贡献最大,即最重要。信息熵是信息量和不确定性的度量,某指标带来的信息量越大,熵值越低,不确定性就越低,也就可以赋予其较大的权重。利用这种方法计算指标权重更为科学,避免了不同专家主观判断权重带来的差异。熵权法更大的意义在于,随着各指标信息熵值的变化,每个指标在系统中的权重也随之变化,这些指标相互作用,动态互动,熵权法就可以实时监测指标在系统中的相对重要性的实时变化,这和系统治理的观点十分契合。在指导流域治理或管理中,改善权重较大的指标即可转变为主要措施或工程论证予以考虑。
根据本公开实施例的第二方面,提供一种流域巨系统的有序度分析装置,所述装置包括:
确定模块,用于确定所述流域的巨系统的边界和结构,将所述流域的巨系统划分为河流子系统、生态环境子系统和人类经济子系统,并建立流域综合性评价指标体系,其中,所述各个子系统中均包括多个评价指标,所有评价指标构成所述流域巨系统的综合性评价指标体系;
数据处理模块,用于分别采集并清洗预设时间段内所述综合性评价指标体系中所有评价指标的指标数据;
第一计算模块,用于基于所述指标数据,利用熵权法分别计算各个子系统和所述巨系统的信息熵值;
评价模块,用于根据所述流域巨系统和各个子系统的信息熵值,评价所述各个子系统和流域巨系统的系统有序程度发展变化的趋势。
根据本公开实施例的第三方面,提供一种计算机可读存储介质,其上存储有计算机指令,所述指令被处理器执行时实现如第一方面实施例中任一项所述方法的步骤。
进一步可以理解的是,本公开中“多个”是指两个或两个以上,其它量词与之类似。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。
进一步可以理解的是,术语“第一”、“第二”等用于描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开,并不表示特定的顺序或者重要程度。实际上,“第一”、“第二”等表述完全可以互换使用。例如,在不脱离本公开范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。
进一步可以理解的是,本公开实施例中尽管在附图中以特定的顺序描述操作,但是不应将其理解为要求按照所示的特定顺序或是串行顺序来执行这些操作,或是要求执行全部所示的操作以得到期望的结果。在特定环境中,多任务和并行处理可能是有利的。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!