一种智能会议记录系统及方法与流程
[0001]
本发明涉及语音、图像识别领域,特别是涉及一种智能会议记录系统及方法。
背景技术:
[0002]
会议记录用于记录会议中参会人员商讨的信息,为会议信息提供准确的依据,同时,也可以让相应的人员对会议信息进行回顾,避免会议中商讨的内容遗失或是忘记。
[0003]
现有的级别较高的会议室,一般都会配备自动会议记录的功能,即会议室内装有拾音设备,对演讲者的声音进行拾取,然后通过语音转化文字的功能,记录下会议的内容,这样会后就会形成会议记录供参会者使用;或者直接使用视频采集设备采集整个会议过程中的全部影响。
[0004]
但此类方式形成的会议记录比较粗糙,文字版的记录,不利于用户从中提取图像信息;视频版本的又存在,当需要对特定的内容(例如,特定人员的讲话内容,或参会人员针对特定主题的发言内容等)进行查看时,就需要对整段的视频进行浏览才能找到需要的内容,导致观看用户花费大量的时间和精力,降低了工作效率。
[0005]
同时现有的远程会议中,一般是直接通过固定的摄像头进行图像采集,实现方式比较僵化,存在会议体验感较差的问题。
技术实现要素:
[0006]
本发明的目的是提供一种智能会议记录系统及方法,用以结合文字与图像的各自特点,自动生成含有会议图像和发言文字信息的会议记录,提升远程会议的体验感。
[0007]
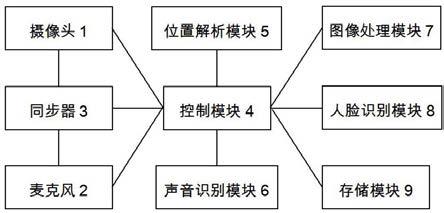
为实现上述目的,本发明提供了如下方案:一种智能会议记录系统,包括:摄像头,用于采集会议发生时的视频图像信息;麦克风,用于采集会议发生时的声音信息;同步器,分别与所述摄像头和所述麦克风连接,用于发出同步信号控制所述摄像头和所述麦克风同时工作;控制模块,分别与所述摄像头、所述麦克风以及所述同步器连接,用于控制同步器工作,以及用于收集所述视频图像信息和所述声音信息;位置解析模块,与所述控制模块连接,用于根据所述视频图像信息以及所述声音信息解析当前发言人的位置;声音识别模块,与所述控制模块连接,用于提取所述声音信息中的声音特征,并将提取到的声音特征与存储模块中存储的声音特征进行匹配,确定发言人的身份信息;所述声音识别模块还用于将所述声音信息转换为文字信息;人脸识别模块,与所述控制模块连接,用于根据所述视频图像信息进行人脸识别,并将识别到的人脸特征与存储模块中存储的人脸特征进行匹配,确定参会人员身份信息;图像处理模块,与所述控制模块以及所述声音识别模块连接,用于将多个摄像头采集
的视频图像信息进行拟合;所述拟合后的图像以统一的时间为基准插入到所述文字信息中,生成会议记录;存储模块,分别与所述控制模块、所述声音识别模块、所述图像处理模块、所述人脸识别模块连接,用于存储参会人员的声音特征、参会人员的人脸特征以及所述会议记录。
[0008]
可选地,所述根据所述视频图像信息以及所述声音信息解析当前发言人的位置的公式如下:公式如下:公式如下:其中,(xa、ya、za)、(xb、yb、zb)、(xc、yc、zc)、(xd、yd、zd)为麦克风a、b、c、d的坐标,tba为声音到达麦克风b、a的时间差,tca为声音到达麦克风c、a的时间差,tda为声音到达麦克风d、a的时间差,v是声音的传播速度,x、y表示人员位置坐标。
[0009]
可选地,所述摄像头在使用前要进行标定,所述标定包括内参标定和外参标定;所述内参标定为获取图像畸变参数,所述外参标定为获取所述摄像头的安装位置和角度,所述角度为所述摄像头的图像中心像素所在射线的角度。
[0010]
可选地,所述图像畸变参数通过标定板或棋盘板获取。
[0011]
可选地,所述安装位置通过全站仪类的测量设备获取,所述角度通过全站仪类测量设备和摄像头图像采集联合获取。
[0012]
可选地,所述图像处理模块包括:会议焦点提取单元,用于根据所述视频图像信息中当前参会人员的人脸朝向确定会议焦点;焦点图像拼接单元,与所述会议焦点提取单元连接,用于根据所述会议焦点对所述视频图像信息进行拼接。
[0013]
本发明还提供了一种智能会议记录方法,所述方法应用于上述智能会议记录系统,所述方法包括:采集会议发生时的视频图像信息;采集会议发生时的声音信息;根据所述视频图像信息以及所述声音信息解析当前发言人的位置;提取所述声音信息中的声音特征,并将提取到的声音特征与存储模块中存储的声音特征进行匹配,确定发言人的身份信息;将所述声音信息转换为文字信息;根据所述视频图像信息进行人脸识别,并将识别到的人脸特征与存储模块中存储的人脸特征进行匹配,确定参会人员身份信息;将多个摄像头采集的视频图像信息进行拟合;所述拟合后的图像以统一的时间为基准插入到所述文字信息中,生成会议记录。
[0014]
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明公开了一种智能会议记录系统及方法。该系统包括摄像头、麦克风、同步器、控
制模块、位置解析模块、声音识别模块、图像处理模块、人脸识别模块以及存储模块。本发明能够通过声音识别模块生成各个参会人员的发言文字记录;可以通过图像处理模块生成发言人的全景图片记录;最终形成文本图片混合的会议记录。当用作远程会议时,还可以通过全景图像的方式为对方提供视频信息,提升体验感。
附图说明
[0015]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0016]
图1为本发明实施例智能会议记录系统的结构框图。
具体实施方式
[0017]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0018]
本发明的目的是提供一种智能会议记录系统及方法,用以结合文字与图像的各自特点,自动生成含有会议图像和发言文字信息的会议记录,提升远程会议的体验感。
[0019]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0020]
如图1所示,本发明公开的智能会议记录系统包括:摄像头1,用于采集会议发生时的视频图像信息;所述摄像头1的数量至少为2个。采集到的视频图像信息将用于会议记录生成和远程会议。摄像头1在使用前需要进行标定,标定包括摄像头1内参标定和摄像头1外参标定。
[0021]
进一步的,所述内参标定主要为获取摄像头1镜头导致的图像畸变参数,使用标定板/棋盘板进行,此过程一般在摄像头1安装前完成,最终得到图像畸变参数和摄像头1视角。
[0022]
进一步的,所述外参标定为获取摄像头1的安装位置和角度,此过程需在摄像头1安装后完成。
[0023]
更进一步的,所述安装位置通过全站仪类的测量设备直接获取。
[0024]
更进一步的,所述角度定义为摄像头1图像中心像素所在射线(以下称法线a)的角度,需通过全站仪类测量设备和摄像头1图像采集联合获取。具体的,使用全站仪自带的激光器或额外的激光器,向摄像头1的正前方发射激光,并使得光斑打在摄像头1视角覆盖范围内的平面上。全站仪测量光斑的位置,称为第一光斑位置,摄像头1内部图像处理,提取光斑像素,生成该像素在图像中的像素坐标,称为第一像素位置。
[0025]
摄像头1需水平安装(采集到的图像下边缘与地面平行,翻滚角为0
°
),则使用安装位置、第一光斑位置、第一像素位置,获取摄像头1的偏航角和俯仰角。求解方法:
①
使用安装位置和第一光斑位置,获得有向线段b,第一像素位置在有向线段b上;
②
根据第一像素位
置和中心像素位置,获得有向线段b与法线a的角度关系;
③
根据角度关系,获得法线a的偏航角和俯仰角,即为摄像头1的安装角度。
[0026]
若摄像头1非水平安装,则重复以上过程,获取第二光斑位置和对应的第二像素位置。使用安装位置、第一光斑位置、第一像素位置、第二光斑位置、第二像素位置,获取摄像头1的偏航角、翻滚角和俯仰角。
[0027]
麦克风2,用于采集会议发生时的声音信息;所述麦克风2的数量至少为4个。采集到的声音信息将用于会议记录生成和远程会议。麦克风2在使用前需要进行标定,标定内容为麦克风2的安装位置,通过全站仪类的测量设备进行。麦克风2在采集声音信息时,还将标记该声音的到来时间。根据麦克风2编号(编号a、b、c、d等)的不同,标记为ta、tb、tc、td等,其中ta为信号到达编号a麦克风2的时间,其中tb为信号到达编号b麦克风2的时间,以此类比。
[0028]
麦克风2和摄像头1还可以是一个整体,同时具有视频采集和声音采集的功能。
[0029]
同步器3,分别与所述摄像头1和所述麦克风2连接,用于发出同步信号控制所述摄像头1和所述麦克风2同时工作。该同步信号将控制所有摄像头1和麦克风2,使其工作在同一个时钟体系下,并使得摄像头1和麦克风2数据采集时刻为同一时刻。
[0030]
控制模块4,分别与所述摄像头1、所述麦克风2以及所述同步器3连接,用于控制同步器3工作,以及用于收集所述视频图像信息和所述声音信息。并且当摄像头1具有旋转或移动功能时,还将控制摄像头1旋转和移动。
[0031]
位置解析模块5,与所述控制模块4连接,用于根据所述视频图像信息以及所述声音信息解析当前发言人的位置。位置解析方法如下:位置解析方法如下:位置解析方法如下:其中,(xa、ya、za)、(xb、yb、zb)、(xc、yc、zc)、(xd、yd、zd)为麦克风2a、b、c、d的坐标,tba为声音到达麦克风2b、a的时间差,tca为声音到达麦克风2c、a的时间差,tda为声音到达麦克风2d、a的时间差,v是声音的传播速度,x、y是最后的解算结果,即人员位置。
[0032]
声音识别模块6,与所述控制模块4连接,用于提取所述声音信息中的声音特征,并将提取到的声音特征与存储模块9中存储的声音特征进行匹配,确定发言人的身份信息;所述声音识别模块6还用于将所述声音信息转换为文字信息。
[0033]
声音识别模块6在声音转文字的过程中,还可以调用外部的语音转换资源(如开源的或付费的外部语音翻译软件),根据本次会议的参会人员的主要沟通交流语音,生成不同语音版本的会议记录。
[0034]
人脸识别模块8,与所述控制模块4连接,用于根据所述视频图像信息进行人脸识别,并将识别到的人脸特征与存储模块9中存储的人脸特征进行匹配,确定参会人员身份信息。根据参会人员身份信息生成参会人员名单,如有发言机会,还可根据位置信息生成相应的座次表。所述人脸识别模块8,还可以识别人脸的朝向。
[0035]
图像处理模块7,与所述控制模块4以及所述声音识别模块6连接,用于将多个摄像
头1采集的视频图像信息进行拟合;所述拟合后的图像以统一的时间为基准插入到所述文字信息中,生成会议记录。
[0036]
所述图像处理模块7包括会议焦点提取单元和焦点图像拼接单元,会议焦点提取单元用于根据所述视频图像信息中当前参会人员的人脸朝向确定会议焦点;焦点图像拼接单元,与所述会议焦点提取单元连接,用于根据所述会议焦点对所述视频图像信息进行拼接。
[0037]
所述的会议焦点提取,是先通过摄像头1采集会议人员信息,分析判断出当前参会人员的人脸朝向,根据多个参会人员的人脸朝向,延长并拟合出一个焦点,该焦点作为会议焦点。
[0038]
所述图像拼接与会议焦点提取结果关联,当所述焦点处于会议室外时,一般可认为参会人员正在观看ppt(或类似行为),所述图像处理模块7将拼接ppt屏幕上的图像,形成正视图的观看效果;当所述焦点在参会人员中间时,一般可认为参会人员在观看发言人发言或展示的物品,所述图像处理模块7生成拼接图像,所述图像为发言人的正视图。
[0039]
进一步的,为了提升图像处理效率,ppt屏幕可以提前标定出位置。进行具体拼接行为时,使用标定后的位置作为拼接的起始点,减少图像拼接时的运算量;同理,拼接发言人图像时,使用位置解析模块5中获取的发言人位置。
[0040]
进一步的,所述图像处理模块7生成的最终图像,将与声音识别模块6配合,以统一的时间为基准,把图像插入到文字信息中去。同时本实施例中,还遵循图像变化率的插入原则,即,在文字信息中,如果图像变化不明显,则插入图像数量少;如果图像变化明显,则插入图像数量多,表明其变化规律。
[0041]
额外的,当本系统用于远程会议时,沿用以上的图像处理中的会议焦点提取和焦点图像拼接,给远程提供视频数据。
[0042]
存储模块9分别与所述控制模块4、所述声音识别模块6、所述图像处理模块7、所述人脸识别模块8连接,用于存储参会人员的声音特征、参会人员的人脸特征以及所述会议记录。存储的特征是指在会议室使用前的初始化过程中,采集并提取的人员特征信息,包括声音信息和人脸信息,以及所对应的人员身份信息。
[0043]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
[0044]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1