一种基于试题库的自动进化组卷方法及系统与流程
本发明涉及数字信息处理技术领域,具体的说是一种基于试题库的自动进化组卷方法及系统。
背景技术:
目前各类笔试试卷的组卷工作基本上都是人工完成。通常,在某项正式考试出卷时,相应的考试组织邀请各领域专家根据考试人群和考试目标进行分析,封闭集中进行出题。然后,再根据实际需要选择所需组卷的章节、知识点以及题型,手工完成组卷的全过程,致使组卷工作资源投入多、成本高、工作量大、知识点覆盖不全面和出卷用时较长等问题。由此运用信息处理技术从试题库中自动选择试题组成试卷的自动组卷应运而生。
随着计算机及数据存储技术发展,通过数据库存储试题的信息并通过算法实现试题的自动组卷成为非常可行的一种方案。现有的组卷方法普遍采用传统优化算法和传统搜索算法,其中,传统优化算法是从单个初始值迭代求最优解的,因此容易误入局部最优解,传统搜索算法都是单点搜索算法,容易陷入局部的最优解,而局部最优相对试卷整体而言,可能某一知识点考查的最为全面,造成整个试卷不合理的情况发生。因此,如何即快速又高质量的抽出一套最符合考试要求的试卷,是现在需要解决的问题。
技术实现要素:
本发明针对目前技术发展的需求和不足之处,提供一种基于试题库的自动进化组卷方法及系统。
首先,本发明提供一种基于试题库的自动进化组卷方法,解决上述技术问题采用的技术方案如下:
一种基于试题库的自动进化组卷方法,该方法的实现基于试题库,试题库的试题标记有从题型、难易度、知识点三个维度设置的权重值,该方法的实现内容包括随机组卷和组卷进化两部分;
在随机组卷部分,通过获取组卷策略,随机选取试题库的试题,完成组卷并组成试卷集;
在组卷进化部分,首先根据试卷在题型、难易度、知识点三个维度上的占比,计算试卷的适应度值,随后按照适应度值排序试卷,并选取试卷循环执行遗传算法的选择、交叉、变异操作,得到满足组卷策略的最终最优卷。
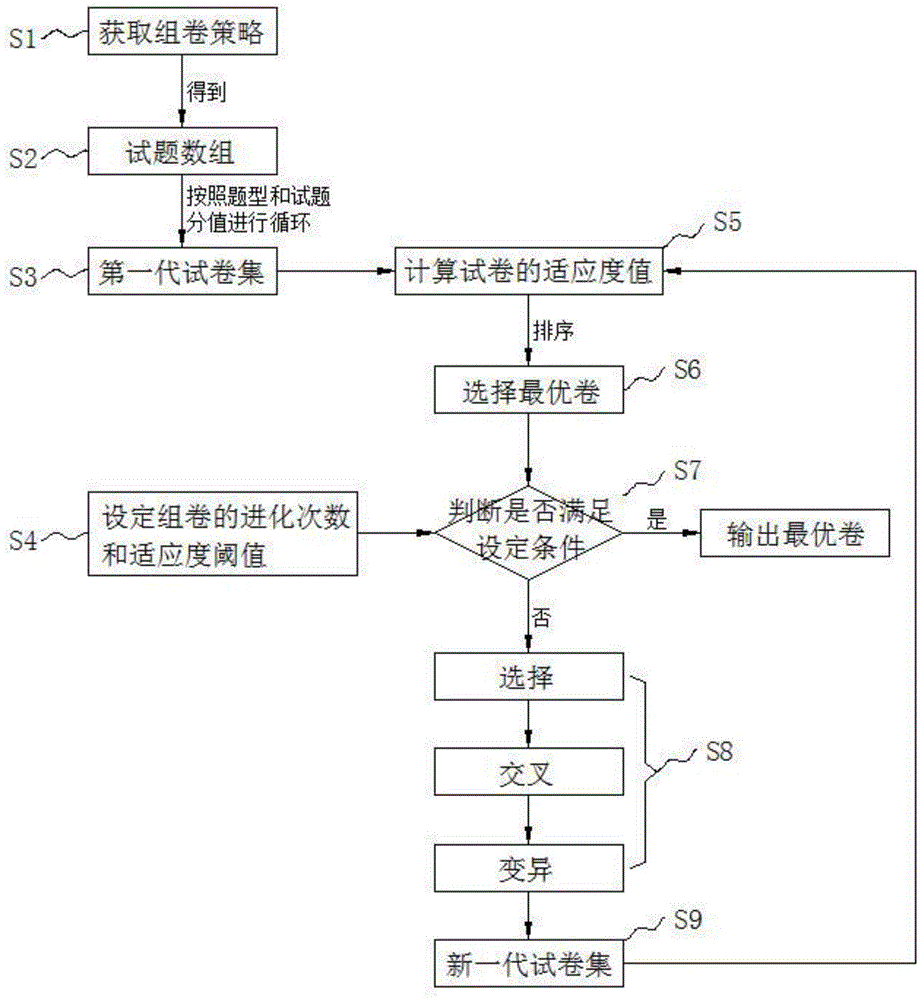
具体的,实现自动进化组卷方法的操作流程包括:
步骤s1、获取组卷策略,根据组卷策略定义“知识点数组”;
步骤s2、根据定义的“知识点数组”从试题库中选取试题,得到“试题数组”;
步骤s3、按照题型和试题分值对“试题数组”进行循环,并通过随机选取的方式组成多套试卷,多套试卷存储于第一代试卷集;
步骤s4、设定组卷的进化次数和适应度阈值;
步骤s5、根据本代试卷集中每套试卷在题型、难易度、知识点三个维度上的占比,计算试卷在三个维度上的对应值并相加,得到试卷的适应度值;
步骤s6、按照适应度值从大到小的变化,排序本代试卷集的多套试卷,并选择排序第一的试卷作为本代试卷集的最优卷;
步骤s7、判断组卷的进化代数是否达到设定次数,或者,判断本代试卷集的最优卷的适应度值是否达到设定的适应度阈值,
(a)如果达到,组卷结束,本代试卷集的最优卷即为最终最优卷,
(b)如果未达到,继续执行步骤s8;
步骤s8、按照适应度值从大到小的变化,排序试卷集的多套试卷,并选择前n套试卷组成新试卷集a;对新试卷集a的任两套试卷所对应的试题进行交换,实现任两套试卷的交叉,得到新的n套试卷并组成新试卷集b;从新试卷集a和新试卷集b的试卷中随机选取试题,与试题库的试题进行交换,实现试卷的变异,变异后的试卷组成新试卷集c;
步骤s9、新试卷集a、新试卷集b、新试卷集c三者组成下一代试卷集,返回执行步骤s5。
进一步的,执行步骤s6时,按照适应度值从大到小的变化,排序本代试卷集的多套试卷,具体过程为:
采用冒泡算法,对本代试卷集中前后相邻两套试卷的适应度值进行比较,
如果后面的试卷适应度值高,则交换两者位置,
如果前面的试卷适应度值,则保持两者位置不变,
直至本代试卷集中任意前后相邻两套试卷的适应度值都比较完毕,此时,本代试卷集的所有试卷按照适应度值从大到小排列。
进一步的,执行步骤s8的过程中,
(i)n不小于试卷集所包含试卷套数的三分之一;
(ii)对新试卷集a的任两套试卷所对应的试题进行交换时,交换的试题数量不能超过总试题数量的三分之一;
(iii)实现变异的试卷套数不低于新试卷集a和新试卷集b中所有试卷套数的三分之一;
(iiii)针对新试卷集a和新试卷集b中的试卷,随机选取m道试题与试题库的试题进行交换,m不超过试卷所包含试题数量的三分之一。
更进一步的,一次进化过程中,在两套试卷交叉操作过程中进行交换的试题不在试卷变异操作中继续进行交换。
优选的,试题库选用通用关系型数据库。
其次,本发明提供一种基于试题库的自动进化组卷系统,解决上述技术问题采用的技术方案如下:
一种基于试题库的自动进化组卷系统,其结构框架包括:
试题库,存储有多道试题,且每道试题都标记有从题型、难易度、知识点三个维度设置的权重值;
获取模块,用于获取用户设置的组卷策略;
随机模块,用于根据组卷策略随机选取试题库的试题,完成组卷并组成试卷集;
自定义模块,用于自定义设置组卷的进化次数和适应度阈值;
计算模块,用于计算组卷的次数,还用于根据试卷集中每套试卷在题型、难易度、知识点三个维度上的占比,计算试卷在三个维度上的对应值并相加,得到试卷的适应度值;
判断模块,用于判断组卷次数是否达到设定的进化次数,或者,用户判断试卷的适应度值是否达到设定的适应度阈值,并在判断结果为是时,输出最优卷;
排序模块,在判断模块的判断结果为否时,用于按照适应度值从大到小的变化,排序试卷集的多套试卷;
遗传算法模块,用于对排序完成的试卷执行选择、交叉、变异操作,组成新的试卷集。
具体的,所涉及排序模块采用冒泡算法对试卷集中前后相邻两套试卷的适应度值进行比较及位置交换,完成试卷集中所有试卷按照适应度值从大到小的排列。
具体的,所涉及遗传算法模块对排序完成的试卷执行选择、交叉、变异操作,具体操作内容包括:
首先,利用遗传算法模块选择前n套试卷组成新试卷集a;
其次,利用遗传算法模块对新试卷集a的任两套试卷所对应的试题进行交换,实现任两套试卷的交叉,得到新的n套试卷并组成新试卷集b;
最后,利用遗传算法模块从新试卷集a和新试卷集b的试卷中随机选取试题,与试题库的试题进行交换,实现试卷的变异,变异后的试卷组成新试卷集c。
具更体的,所涉及遗传算法模块对排序完成的试卷执行选择、交叉、变异操作的过程中,
(i)n不小于试卷集所包含试卷套数的三分之一;
(ii)对新试卷集a的任两套试卷所对应的试题进行交换时,交换的试题数量不能超过总试题数量的三分之一;
(iii)实现变异的试卷套数不低于新试卷集a和新试卷集b中所有试卷套数的三分之一;
(iiii)针对新试卷集a和新试卷集b中的试卷,随机选取m道试题与试题库的试题进行交换,m不超过试卷所包含试题数量的三分之一。
本发明的一种基于试题库的自动进化组卷方法及系统,与现有技术相比具有的有益效果是:
本发明通过组卷策略进行随机组卷,通过遗传算法对随机组卷执行选取、交叉和变异操作,并通过计算试卷的适应度值,得到符合组卷策略的最优卷,尤其可以满足在多维度多约束条件下的最优组卷。
附图说明
附图1是本发明实施例一的流程示意图;
附图2是本发明实施例二的连接框图。
附图中各标号信息表示:
1、试题库,2、获取模块,3、随机模块,4、自定义模块,5、计算模块,
6、判断模块,7、排序模块,8、遗传算法模块,9、试卷集。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
实施例一:
结合附图1,本实施例提出一种基于试题库的自动进化组卷方法,该方法的实现基于试题库,试题库的试题标记有从题型、难易度、知识点三个维度设置的权重值,该方法的实现内容包括随机组卷和组卷进化两部分。本实施例中试题库选用通用关系型数据库。
(一)在随机组卷部分,通过获取组卷策略,随机选取试题库的试题,完成组卷并组成试卷集,具体步骤为:
步骤s1、获取组卷策略,根据组卷策略定义“知识点数组”。
步骤s2、根据定义的“知识点数组”从试题库中选取试题,得到“试题数组”。这一过程中,根据“知识点数组”使用标准sql进行查询,伪sql为“select*from试题表where知识点in(“知识点数组”)”,具体伪代码如下:
将查询的结果放入变量“试题数组”即可。
步骤s3、执行如下伪代码:
按照题型和试题分值对“试题数组”进行循环,并通过随机选取的方式组成多套试卷,多套试卷存储于第一代试卷集。
(二)在组卷进化部分,首先根据试卷在题型、难易度、知识点三个维度上的占比,计算试卷的适应度值,随后按照适应度值排序试卷,并选取试卷循环执行遗传算法的选择、交叉、变异操作,得到满足组卷策略的最终最优卷。具体步骤为:
步骤s4、设定组卷的进化次数为100次,设定适应度阈值为80。
步骤s5、根据本代试卷集中每套试卷在题型、难易度、知识点三个维度上的占比,计算试卷在三个维度上的对应值并相加,得到试卷的适应度值。
步骤s6、采用冒泡算法,其伪代码如下:
对本代试卷集中前后相邻两套试卷的适应度值进行比较,如果后面的试卷适应度值高,则交换两者位置,如果前面的试卷适应度值,则保持两者位置不变,直至本代试卷集中任意前后相邻两套试卷的适应度值都比较完毕,此时,本代试卷集的所有试卷按照适应度值从大到小排列,选择排序第一的试卷作为本代试卷集的最优卷。
步骤s7、判断组卷的进化代数是否达到设定次数,或者,判断本代试卷集的最优卷的适应度值是否达到设定的适应度阈值,
(a)如果达到,组卷结束,本代试卷集的最优卷即为最终最优卷,
(b)如果未达到,继续执行步骤s8。
本步骤中,需要定义变量“比较结果”=“最优卷.适应度>=适应度阈值”,如果“比较结果”为“true”,则组卷结束,最优卷选取成功,如果“比较结果”为“false”,则继续执行步骤s8。实现本步骤的伪代码如下:
步骤s8、按照适应度值从大到小的变化,排序试卷集的多套试卷,并选择前n套试卷组成新试卷集a,即“新试卷集a”=“试卷集[0…n]”;
对新试卷集a的任两套试卷所对应的试题进行交换,每次交换首先定义变量“交换位置”为随机数,通过“试卷a[交换位置]”=“试卷b[交换位置]”进行试题交换,实现任两套试卷的交叉,交叉过程的伪代码如下:
从而得到新的n套试卷并组成新试卷集b,这时,本代试卷集的内容为“新试卷集a”+“新试卷集b”;
从新试卷集a和新试卷集b的试卷中随机选取试题,与试题库的试题进行交换,此时,需要定义变量“变异次数”=随机数,然后进行循环计算,定义变量“变异位置”=随机数,通过从试题库中随机选取某个试题,即“试卷[变异位置]”=“题库试题”,实现试卷的变异,变异过程的伪代码如下:
变异后的试卷组成新试卷集c,这时,本代试卷集内容为“新试卷集a”+“新试卷集b”+“新试卷集c”,这样最终构成了本代试卷集。
步骤s9、新试卷集a、新试卷集b、新试卷集c三者组成下一代试卷集,返回执行步骤s5。
本实施例中,执行步骤s8的过程中,
(i)n不小于试卷集所包含试卷套数的三分之一;
(ii)对新试卷集a的任两套试卷所对应的试题进行交换时,交换的试题数量不能超过总试题数量的三分之一;
(iii)实现变异的试卷套数不低于新试卷集a和新试卷集b中所有试卷套数的三分之一;
(iiii)针对新试卷集a和新试卷集b中的试卷,随机选取m道试题与试题库的试题进行交换,m不超过试卷所包含试题数量的三分之一。
需要补充的是:一次进化过程中,在两套试卷交叉操作过程中进行交换的试题不在试卷变异操作中继续进行交换。
实施例二:
结合附图2,本实施例提出一种基于试题库的自动进化组卷系统,其结构框架包括:
试题库1,存储有多道试题,且每道试题都标记有从题型、难易度、知识点三个维度设置的权重值;
获取模块2,用于获取用户设置的组卷策略;
随机模块3,用于根据组卷策略随机选取试题库1的试题,完成组卷并组成试卷集9;
自定义模块4,用于自定义设置组卷的进化次数和适应度阈值;
计算模块5,用于计算组卷的次数,还用于根据试卷集9中每套试卷在题型、难易度、知识点三个维度上的占比,计算试卷在三个维度上的对应值并相加,得到试卷的适应度值;
判断模块6,用于判断组卷次数是否达到设定的进化次数,或者,用户判断试卷的适应度值是否达到设定的适应度阈值,并在判断结果为是时,输出最优卷;
排序模块7,在判断模块6的判断结果为否时,用于按照适应度值从大到小的变化,排序试卷集9的多套试卷;
遗传算法模块8,用于对排序完成的试卷执行选择、交叉、变异操作,组成新的试卷集9。
本实施例中,所涉及排序模块7采用冒泡算法对试卷集9中前后相邻两套试卷的适应度值进行比较及位置交换,完成试卷集9中所有试卷按照适应度值从大到小的排列。
本实施例中,所涉及遗传算法模块8对排序完成的试卷执行选择、交叉、变异操作,具体操作内容包括:
首先,利用遗传算法模块8选择前n套试卷组成新试卷集a;
其次,利用遗传算法模块8对新试卷集a的任两套试卷所对应的试题进行交换,实现任两套试卷的交叉,得到新的n套试卷并组成新试卷集b;
最后,利用遗传算法模块8从新试卷集a和新试卷集b的试卷中随机选取试题,与试题库1的试题进行交换,实现试卷的变异,变异后的试卷组成新试卷集c。
本实施例中,所涉及遗传算法模块8对排序完成的试卷执行选择、交叉、变异操作的过程中,
(i)n不小于试卷集所包含试卷套数的三分之一;
(ii)对新试卷集a的任两套试卷所对应的试题进行交换时,交换的试题数量不能超过总试题数量的三分之一;
(iii)实现变异的试卷套数不低于新试卷集a和新试卷集b中所有试卷套数的三分之一;
(iiii)针对新试卷集a和新试卷集b中的试卷,随机选取m道试题与试题库1的试题进行交换,m不超过试卷所包含试题数量的三分之一。
综上可知,采用本发明的一种基于试题库的自动进化组卷方法及系统,通过组卷策略进行随机组卷,通过遗传算法对随机组卷执行选取、交叉和变异操作,并通过计算试卷的适应度值,得到符合组卷策略的最优卷,尤其可以满足在多维度多约束条件下的最优组卷。
以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
- 还没有人留言评论。精彩留言会获得点赞!