一种面向图像处理的卷积神经网络垂直分割方法与流程
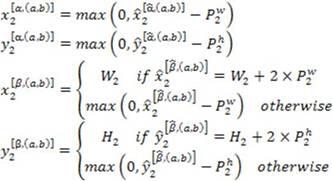
[0001]
本发明涉及深度学习以及分布式计算领域,具体涉及一种面向图像处理的卷积神经网络垂直分割方法。
背景技术:
[0002]
随着计算机硬件的发展,应用数据量的激增,深度学习模型的能力得以逐渐释放。深度学习模型处理数据后所取得的结果准确性高,因此它被广泛应用于各类数据处理程序中。在这些数据处理程序中值得一提的是图像处理程序。其中所采用的卷积神经网络,大幅度地提高了图像处理的准确度,使得高精度的影像识别、视频分析等程序成为可能。但卷积神经网络当中的卷积层所需要的卷积运算需要大量的算力,在一些资源受限的计算节点中,卷积层推理成为整个推理过程的瓶颈。
[0003]
鉴于此,现有技术考虑采用分布式计算的模型,并行地处理卷积层的输入特征图。目前流行的技术主要采用通道分割和空间分割两种方式。通道分割把每一个卷积层的输入特征图的通道分割为多个子通道,对每个子通道进行卷积运算。空间分割把每一个卷积层的输入特征图在二维平面上分割为多个子特征图,并对每个子特征图进行卷积运算。
[0004]
然而现有技术存在如下问题:1.当前通道分割方法在对每个子通道进行卷积运算后,存在一个结果拼接过程,拼接后的结果再作为下一个卷积层的输入特征图,该方法存在大量的数据传输冗余,且结果的多次拼接过程造成了不必要的计算开销。
[0005]
2.现有空间分割方法没有充分考虑输入特征图填充过程,存在精度损失,造成模型推理结果不准确。
[0006]
3.现有空间分割方法没有正确考虑卷积运算的反向推导过程,导致单链路上的连续卷积层的子特征图对应关系不准确,存在精度损失,造成模型推理结果不准确。
技术实现要素:
[0007]
本发明的目的在于针对现有技术的不足,提供了一种面向图像处理的卷积神经网络垂直分割方法,该方法对于资源受限的计算节点,提供一种分布式并行处理连续卷积层的方法;通过考虑输入特征图填充过程,准确计算卷积运算的反向推导,提供一种无精度损失的并行处理方法;取消特征图分割处理后的结果融合过程,减少数据传输冗余和结果拼接开销的并行处理方法。
[0008]
本发明的目的是通过以下技术方案来实现的:一种面向图像处理的卷积神经网络垂直分割方法,包括以下步骤:(1)对于图像处理中的卷积神经网络上的连续卷积层,领导者节点获取每一个卷积层的参数和超参数、卷积层之间的池化层的超参数、卷积层之间的批标准化层和线性整流函数层的超参数,所述领导者节点将上述参数和超参数以多播通信形式分发给计算节点;(2)获取连续卷积层中的最后一层卷积层的输入特征图,并将其分割为连续的子特征
图,并为所有子特征图标注坐标;(3)根据每个子特征图的坐标和每个卷积层或池化层的超参数,反推上一层对应的子特征图的坐标,直至获得第一个卷积层的子特征图的坐标;(4)依据步骤(3)获得的第一个卷积层的子特征图的坐标,对第一层的输入特征图进行分割,并将分割后的第一层的子特征图分配给步骤(1)中的计算节点;(5)每个计算节点根据连续的卷积层、卷积层之间的池化层、卷积层之间的批标准化层和线性整流函数层的参数和超参数,对分配给该计算节点的子特征图,进行无精度损失的推理;(6)当所有计算节点均产生最后一个卷积层的输出子特征图后,领导者节点对所有的输出子特征图进行汇总,生成最终的输出特征图。
[0009]
进一步地,所述领导者节点通过以下方式获得:对于资源受限的计算节点,当其被分配图像处理中的卷积神经网络推理任务之后,通过多播通信形式,向计算节点发送所述资源受限的计算节点成为领导者节点的通知。
[0010]
进一步地,步骤(2)包括如下子步骤:(2.1)获取连续卷积层中的最后一层卷积层的输入特征图,根据计算节点的数量,将最后一层卷积层的输入特征图分割为与计算节点数量相同的子特征图;(2.2)对于上述子特征图所在的输入特征图,以左上角为原点,上边为轴,左边为轴,建立二维笛卡尔坐标系,原输入特征图中的每个像素点占一个坐标;(2.3)依据原特征图中各像素点的坐标,对子特征图的左上角和右下角进行坐标标注。
[0011]
进一步地,步骤(3)中反推的方法为卷积过程的逆过程,所述卷积过程包括输入特征图填充和卷积计算。
[0012]
进一步地,步骤(6)包括如下子步骤:(6.1)领导者节点监听计算各计算节点的推理情况,当所有计算节点均产生最后一个卷积层的输出子特征图后,该领导者节点发送收集子特征图指令,各计算节点收到指令后,将子特征图发送给领导者节点;(6.2)领导者节点收到所述各个子特征图后,将子特征图的坐标进行汇总,生成最终的输出特征图。
[0013]
与现有技术相比,本发明具有如下有益效果:单链路连续卷积层的推理过程需要大量的计算资源,采用对输入特征图分割后分布式并行处理的方法,能够有效缓解性能瓶颈,加速推理过程;在分布式并行推理过程中,每个计算节点使用被分配的子输入特征图进行推理,在整个单链路连续卷积层的推理过程不需要交换任何中间计算结果,减缓了通信开销;在计算单链路连续卷积层第一层的输入特征图分割坐标时,充分考虑了卷积运算过程和特征图填充过程,使得分布式并行运算结果汇总后的结果和单节点推理后所产生的运算结果相同,整个运算过程没有对特征图进行剪枝或压缩,因而没有精度损失。
附图说明
[0014]
图1为本发明方法的流程图。
[0015]
图2为本发明方法中计算第一个卷积层的输入子特征图坐标的示意图。
具体实施方式
[0016]
为了使本发明的目的、技术方案及优点更加明白清楚,结合附图和实施例, 对本发明进一步的详细说明,应当理解,此处所描述的具体实施例仅仅用以解释本发明,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人 员在没有做出创造性劳动前提下所获得的所有其他实施例,均在本发明保护范围。
[0017]
如图1所示,本发明所提供的一种面向图像处理的卷积神经网络垂直分割方法,包含以下步骤:(1)对于图像处理中的卷积神经网络上的连续卷积层,领导者节点获取每一个卷积层的参数和超参数、卷积层之间的池化层的超参数、卷积层之间的批标准化层和线性整流函数层的超参数,所述领导者节点将上述参数和超参数以多播通信形式分发给计算节点;所述卷积神经网络包括单链路卷积神经网络和多链路卷积神经网络,对于多链路卷积神经网络,所述领导者节点将其中的每一条单链路卷积神经网络单独进行所述参数与超参数的获取和分发操作。
[0018]
(1.1)对于一个资源受限的计算节点,当其被分配了一个图像处理中的卷积神经网络推理任务之后,该资源受限的计算节点为了加速推理过程,通过多播通信形式,向计算节点发送该资源受限的计算节点成为一个领导者节点的通知。
[0019]
(1.2)领导者节点根据推理时延需求,依据各个卷积层的处理时间,挑选出需要分布式协同推理的单链路连续卷积层。该领导节点收集单链路连续卷积层中每一个卷积层的参数和超参数、卷积层之间的池化层的超参数、卷积层之间的批标准化层和线性整流函数层的超参数,并将这些信息以如下表1数据格式通过分布式系统网络,以多播通信形式分发给分布式系统中的计算节点。
[0020]
表1.模型层的参数格式(2)获取连续卷积层中的最后一层卷积层的输入特征图,并将其分割为连续的子特征图,并为所有子特征图标注坐标;包括如下子步骤:(2.1)获取连续卷积层中的最后一层卷积层的输入特征图,根据计算节点的数量,将最后一层卷积层的输入特征图分割为与计算节点数量相同的子特征图;(2.2)对于上述子特征图所在的输入特征图,以左上角为原点(0,0), 以输入特征图的上边为x轴,以左边为y轴,建立二维笛卡尔坐标系,原输入特征图中的每个像素点占一个坐标。
[0021]
(2.3)依据原特征图中各像素点的坐标,对子特征图的左上角和右下角进行坐标标注。
[0022]
具体地,如图2所示,将模型层id为3的最后一层的大小为的输入特征图沿x轴和y轴,分割为2
×
2个子特征图,其中的结果为分布式系统内计算节点的数量,即分
布式系统内有4个计算节点。使用子特征图的左上角和右下角坐标来标定一个子特征图,表示为且,其中(a,b)坐标定位了一个子特征图,a为横坐标,b为纵坐标;为一个子特征图的左上角像素点在原输入特征图中的坐标,为一个子特征图的右下角像素点在原输入特征图中的坐标。把位于原输入特征图左上角的子特征图标定为。
[0023]
对于上述步骤中的子特征图的左上角坐标,用来表示。对于上述步骤中的子特征图的右下角坐标,用来表示。
[0024]
(3)根据每个子特征图的坐标和每个卷积层或池化层的超参数,反推上一层对应的子特征图的坐标,直至获得第一个卷积层的子特征图的坐标;如图2所示,包括如下子步骤:(3.1)对于id为3的最后一个卷积层,其上一层id为2的模型层是卷积层或池化层,则领导者节点反推计算每个子特征图所对应的id为2的模型层的输入子特征图,所述id为2的模型层的参数如下表2:表2:id为2的卷积层或池化层的参数(3.2)领导者节点根据如下公式,计算出id为2的模型层对应的包含填充的输入子特征图的坐标,其中,:
(3.3)id为2的模型层的输入特征图大小为:,领导者节点对id为2的模型层中包含填充的输入子特征图,进行如下坐标变换,获得id为2的模型层的输入子特征图坐标:(3.4)id为2的模型层的上一层不是卷积层或池化层,则继续获取上一层模型的类型。
[0025]
(3.5)领导者节点从id为3的最后一个卷积层的子特征图开始,重复步骤(3.2)、(3.3),逐层反向推算上一卷积层或池化层的输入子特征图坐标,直到获得这几个卷积层中的第一个卷积层的子特征图的坐标。
[0026]
(4)依据步骤(3)获得的第一个卷积层的子特征图的坐标,对第一层的输入特征图进行分割,并将分割后的第一层的子特征图分配给步骤一中的计算节点;包括以下子步骤:(4.1)领导者节点根据计算出的第一层的a
×
b 个输入子特征图坐标,将第一层的输入特征图分割为a
×
b个子特征图。
[0027]
(4.2)领导者节点将这些子特征图分配给a
×
b个计算节点。
[0028]
(5)每个计算节点根据连续的卷积层、卷积层之间的池化层、卷积层之间的批标准化层和线性整流函数层的参数和超参数,对分配给该计算节点的子特征图,进行无精度损失的推理,具体过程为:a
×
b个计算节点分别以被分配的子特征图为输入,通过步骤(1)中获得的卷积层、卷积层之间的池化层、卷积层之间的批标准化层和线性整流函数层,计算出id为的模型层的子特征图。
[0029]
(6)当所有计算节点均产生最后一个卷积层的输出子特征图后,领导者节点对所有的输出子特征图进行汇总,生成最终的输出特征图;包括以下子步骤:(6.1)领导者节点监听分布式系统内各计算节点的推理情况,当所有计算节点均产生最后一个卷积层的输出子特征图后,该领导者节发送一个收集子特征图指令,各计算节点收到指令后,将推理产生的id为的模型层的子特征图发送给领导者节点,所述发送内容包括该子特征图的参数和坐标。
[0030]
(6.2)领导者节点收到所述各个子特征图后,将子特征图依所述坐标合并成id为的模型层的最终的输出特征图。
[0031]
通过对比现在被广泛应用的inception v4卷积神经网络的分割,本发明的分割方法在降低推理时延的同时降保证了没有精度损失,这是由于本发明中的分布式并行运算结果汇总后的结果和单节点推理后所产生的运算结果相同,整个运算过程没有对特征图进行剪枝或压缩,且对特征图采取的运算过程完全是原卷积神经网络的运算或其逆运算,因而没有精度损失。在拥有4个计算节点的分布式系统中,与inception v4卷积神经网络的推理比较,时延降低为原来的27.3%。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1