一种字符识别提取方法与流程
1.本发明涉及字符识别技术领域,尤其涉及一种字符识别提取方法。
背景技术:
2.随着科技的不断进步,pcb板在各个生产领域中得到广泛运用。pcb板上一般都刻画有字符,而目前针对pcb板的字符检测的方法,基本都是由人工手动完成,因此,需要大量的劳动力进行检测,检测成本高,且检测率低、主观性强、准确率低。
技术实现要素:
3.本发明的目的是提供一种字符识别提取方法,该方法基于机器视觉采集产品的图像信息,即可自动提取字符特征信息,可以提高字符提取识别的工作效率,同时,对采集的图像信息进行预处理,可使得图像清晰完整,进而提高字符识别的准确率,此外,由于其可自动化识别提取字符,进而可节省大量的人力资源,降低成本,同时也可避免由于人为主观因素造成的错判或误判,提高字符识别精度。
4.为实现上述目的,采用以下技术方案:
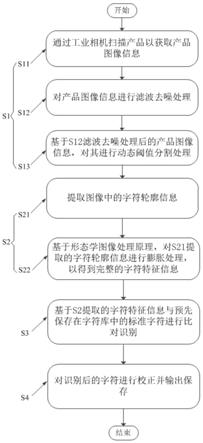
5.一种字符识别提取方法,包括以下步骤:
6.s1:采集产品的图像信息并对其进行预处理;
7.s2:基于s1预处理后的图像信息,提取图像中的字符特征信息;
8.s3:基于s2提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
9.s4:对识别后的字符进行校正并输出保存。
10.进一步地,所述s1包括以下步骤:
11.s11:通过工业相机扫描产品以获取产品图像信息;
12.s12:对产品图像信息进行滤波去噪处理;
13.s13:基于s12滤波去噪处理后的产品图像信息,对其进行动态阈值分割处理。
14.进一步地,所述s12包括以下步骤:
15.s121:在需要处理的像素点的周围选取若干个相邻的像素点,形成像素点云;
16.s122:计算像素点云中若干个像素点的灰度值的均值;
17.s123:设置第一阈值,并计算需要处理的像素点的灰度值与s122中得到的灰度值均值的差值,若差值大于第一阈值,则将该灰度值均值赋予s121中需要处理的像素点,若差值小于或等于第一阈值,则s121中需要处理的像素点的灰度值保持不变。
18.进一步地,所述s2包括以下步骤:
19.s21:提取图像中的字符轮廓信息;
20.s22:基于形态学图像处理原理,对s21提取的字符轮廓信息进行膨胀处理,以得到完整的字符特征信息。
21.进一步地,所述s3包括以下步骤:
22.s31:基于形状匹配算法将提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
23.s32:基于灰度匹配归一化算法将提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
24.s33:若s31与s32比对后的结果是同一个标准字符,则比对成功。
25.进一步地,所述s31包括以下步骤:
26.s311:设置第二阈值;
27.s312:在字符库中搜索标准字符图像,并计算s2中提取的字符特征信息的图像边缘的若干点与标准字符图像边缘的若干点之间的距离的均值;
28.s313:若均值小于第二阈值,则保存该标准字符的信息。
29.采用上述方案,本发明的有益效果是:
30.该方法基于机器视觉采集产品的图像信息,即可自动提取字符特征信息,可以提高字符提取识别的工作效率,同时,对采集的图像信息进行预处理,可使得图像清晰完整,进而提高字符识别的准确率,此外,由于其可自动化识别提取字符,进而可节省大量的人力资源,降低成本,同时也可避免由于人为主观因素造成的错判或误判,提高字符识别精度。
附图说明
31.图1为本发明的流程性框图;
32.图2为本发明的其中一实施例中,预处理后的字符图;
33.图3为本发明的其中一实施例中,对图2进行膨胀处理后的图。
具体实施方式
34.以下结合附图和具体实施例,对本发明进行详细说明。
35.参照图1至3所示,本发明提供一种字符识别提取方法,包括以下步骤:
36.s1:采集产品的图像信息并对其进行预处理;
37.s2:基于s1预处理后的图像信息,提取图像中的字符特征信息;
38.s3:基于s2提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
39.s4:对识别后的字符进行校正并输出保存。
40.其中,所述s1包括以下步骤:
41.s11:通过工业相机扫描产品以获取产品图像信息;
42.s12:对产品图像信息进行滤波去噪处理;
43.s13:基于s12滤波去噪处理后的产品图像信息,对其进行动态阈值分割处理。
44.所述s12包括以下步骤:
45.s121:在需要处理的像素点的周围选取若干个相邻的像素点,形成像素点云;
46.s122:计算像素点云中若干个像素点的灰度值的均值;
47.s123:设置第一阈值,并计算需要处理的像素点的灰度值与s122中得到的灰度值均值的差值,若差值大于第一阈值,则将该灰度值均值赋予s121中需要处理的像素点,若差值小于或等于第一阈值,则s121中需要处理的像素点的灰度值保持不变。
48.所述s2包括以下步骤:
49.s21:提取图像中的字符轮廓信息;
50.s22:基于形态学图像处理原理,对s21提取的字符轮廓信息进行膨胀处理,以得到完整的字符特征信息。
51.所述s3包括以下步骤:
52.s31:基于形状匹配算法将提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
53.s32:基于灰度匹配归一化算法将提取的字符特征信息与预先保存在字符库中的标准字符进行比对识别;
54.s33:若s31与s32比对后的结果是同一个标准字符,则比对成功。
55.所述s31包括以下步骤:
56.s311:设置第二阈值;
57.s312:在字符库中搜索标准字符图像,并计算s2中提取的字符特征信息的图像边缘的若干点与标准字符图像边缘的若干点之间的距离的均值;
58.s313:若均值小于第二阈值,则保存该标准字符的信息。
59.本发明工作原理:
60.本实施例中,应用该字符识别提取方法的检测装置框架可包括工业相机、镜头、光源、pc机、治具以及人机交互界面,工作时,将产品放置于治具上,并通过工业相机采集产品图像信息,在对图像信息进行预处理后,提取图像中的字符特征信息,然后将其与保存在字符库中的标准字符进行比对,比对成功后,将其保存输出至人机交互界面上即可。
61.采集产品图像信息时,可通过各种光学输入方式(如工业相机等)将产品(如pcb等)上的字符转化为图像信息到后台设备,如使用工业相机,可将欲识别的产品先行扫描成图像格式文件,扫描的分辨率越高,越有利于字符的识别工作;采集的产品图像信息的表面可能有造成失真的现象,或者存在一些污点或独立点,这样会影响到字符的正确识别,因此,在字符识别前,先对获取的产品图像信息进行图像预处理以清除图像上的污点或独立点,具体地:
62.首先可对产品图像信息进行滤波去噪处理,其是在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,不损害图像的轮廓及边缘等重要信息,使图像清晰,视觉效果好,其处理效果将直接影响后续的字符特征提取的有效性和可靠性;可首先在需要处理的像素点的周围选取若干个相邻的像素点(邻域),形成像素点云(通常邻域的选取依据4领域或者8领域),然后通过下式计算像素点云中若干个像素点的灰度值的均值:
[0063][0064]
其中,s表示待处理的像素点的邻域(像素点云),m是像素点的总数量,g(i,j)表示图像在(i,j)处的像素数值,f(x,y)表示经过处理后的该像素点的像素值。
[0065]
在上述公式中,可通过选取不同的邻域来抑制噪声,但当邻域增大后,图像也会更加模糊化。为了解决这个问题,设置第一阈值r(非封闭值),并通过下式计算要处理的像素点的灰度值与通过上式得到的灰度值均值的差值,若差值大于第一阈值,则将该灰度值均值赋予需要处理的像素点,若差值小于或等于第一阈值,则需要处理的像素点的灰度值保
持不变,利用这种方式就可以减少图像模糊化的程度。
[0066][0067]
随后,对图像进行动态阈值分割处理,将图像与其局部背景进行比较的操作称为动态阈值分割处理,因此,可以用f
r,c
表示输入图像,用g
r,c
表示处理后的图像,则对亮的物体的动态阈值分割处理如下:
[0068]
s={(r,c)∈r|f
r,c
‑
g
r,c
≥gdiff},
[0069]
而对暗物体的动态阈值分割处理是:
[0070]
s={(r,c)∈r|f
r,c
‑
g
r,c
≥
‑
gdiff},
[0071]
这样,就可以使得图像中的字符比背景要明亮,进而便于字符特征提取。
[0072]
在对产品图像信息进行预处理后,就可提取图像中的字符特征信息,可首先提取字符轮廓,但提取后的字符轮廓可能出现断裂现象,如图2中,字符0的上部分与下部份之间断裂,并留有间隙,此时,可通过形态学处理原理对其进行膨胀处理,将缺陷部分进行填充或者将点状喷射字符隔离太远的区域进行连接,以得到完整的字符特征信息(如图3);膨胀是对两个向量进行与的操作,具体定义如下:
[0073]
设a,b是个集合,分别属于n维空间en,
[0074]
则a被b膨胀的定义:
[0075]
ab={c∈en:c=a+b,a∈a,b∈b},
[0076]
当提取字符特征后,必须有一比对字符库来进行比对识别,字符库的内容应包含所有欲识别的字符字集,以及根据与输入字符一样的特征抽取方法得到的特征群组,通过搜索字符库中原有字符进行对比,如果字体倾斜或者光照不清晰,可以通过学习字体,并保存在字符库中,下次检测如果字符和该字符相近,那么检测结果为学习的字体,字体编号可以随意命名,这里运用到形状和灰度双重匹配对字符进行识别,以提高字符识别的正确率。
[0077]
其中,可基于形状匹配相似度度量来对提取的字符特征信息与字符库中标准字符进行比对,形状匹配相似度度量是使字符特征图像的边缘点与离它最近的标准字符图像图像边缘点之间的均方距离最小,即是与标准字符图像边缘点之间的距离,而不需要知道哪个点是最近点,因此可以通过计算分割后搜索图像背景的距离变换来高效实现。如果字符特征图像的边缘点与标准字符边缘点之间的平均距离小于一个阈值,即可认为找到了一个相似的标准字符的实例,当然,为了得到字符的唯一位置,必须计算相似度量的局部最小值,其边缘距离的平均值sed表示如下:
[0078][0079]
其中,t表示字符特征图像中的边缘点,d(r,c)表示分割后搜索标准字符图像背景的距离变换。
[0080]
而基于灰度匹配归一化算法可以作为相似度衡量的一个标准,首先它是将字符特征图像和字符库中标准字符图像的灰度值作为输入参数进行统计计算,然后在通过相关的
归一化处理来反应两幅图像之间的匹配程度,其相关匹配算法可定义为:
[0081][0082]
式中,m
f
(r,c)是字符特征图像的平均灰度值,s
t2
是标准字符图像的像素点灰度值的方差,
[0083][0084][0085]
在归一化积相关的系数中应注意该匹配算法值的范围是在[
‑
1,1]中,如果ncc(r,c)=
±
1,则图像成一个线性比例的公式:
[0086][0087]
而当ncc(r,c)=
±
1时,字符特征图像与标准字符图像才会完全匹配。
[0088]
对字符的识别准确率是无法达到百分之百的,因此需要对其校正处理,可根据前后的识别字符找出最合乎逻辑的字符,作更正的功能,最后将其输出为需要的格式进行输出保存。
[0089]
以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1