一种基于电力大数据的茶叶产量预测新方法与流程
本发明属于数据挖掘领域,具体涉及一种基于电力大数据的茶叶产量预测新方法。
背景技术:
随着物质生活水平的日益提高,人们对于茶叶需求量逐渐增多,茶叶已经打出国门走向世界,成为了世界三大最受欢迎的饮品之一。根据2019年年底的不完全统计,国内已有20多个省份进行产茶,有红茶、绿茶、普洱等6大系列的茶叶,全国茶农数量也高达到8千万之多,是名副其实的茶叶生产大国和消费大国。我国茶叶生产地主要集中在亚热带地区,环境因素对于茶叶产量影响较大。但除了受到如光照、雨水、温度、湿度等自然因素的影响,非自然因素同样对茶叶产量具有一定的影响,例如制茶过程中的做青、烘茶操作、城镇居民对茶叶消费价格指数、城镇居民人均可支配收入指数等人为因素等也影响了当年的茶叶产量。因此,对茶叶产量的预测研究,不仅关系到茶农的收入,也关系到我国的茶叶贸易的变化,特别是对于个别产茶大省应对茶叶市场的变化,及时调整茶叶种植规模和销售渠道具有积极的意义。
随着计算机硬件及机器学习的快速发展,各领域的预测模型受到了学者专家的关注。对茶叶产量的预测已有文献主要集中在基于统计模型的方法和基于小样本数据的建模预测方法。刘春涛等通过崂山地区茶叶产量年景资料分析入手,通过“歉年”与气象因素的关系,构建二元逻辑归回茶产量年景预报模型;高洁煌等根据武夷山市的年茶叶产量数据建立灰色模型,对武夷山市的茶叶产量在2014-2020年将保持稳步增长趋势;朱秀红等从统计的角度对影响茶叶产量的气候因子进行分析,建立了多元回归模型,对日照茶叶产量进行预测;胡克满等基于灰色系统理论可以通过部分已知条件进行分析,对茶产量构建bp神经网络模型进行预测。
对于统计模型和小样本建模方法来说,统计模型注重统计特征的分析,小样本则利用数据自身的数字规律特征建模。这2种方法存在2个局限性:一是对于统计模型建模来说,需要知道足够多的数据,再对数据进行统计特征分析,利用分析的数据特征选择模型。该方法在实际应用中会遇到数据量不够的难题,造成建模困难及准确度不高;二是小样本建模方法仅仅考虑数据的数字规律,忽视了数据类型的统计特征,会造成模型精度较差的问题出现。
技术实现要素:
本发明的目的在于提供一种基于电力大数据的茶叶产量预测新方法,在既保留数据统计特征又兼顾数据本身规律的前提下,通过研究改进建模方式不足的情况下,采用融合的方式将具有统计特征的多元时间序列模型与具有数据特征的灰色模型结合起来,结合电力数据,建立残差融合的灰色和多元时间序列模型模型,如此达到较好的预测效果。
为实现上述目的,本发明的技术方案是:一种基于电力大数据的茶叶产量预测新方法,包括:
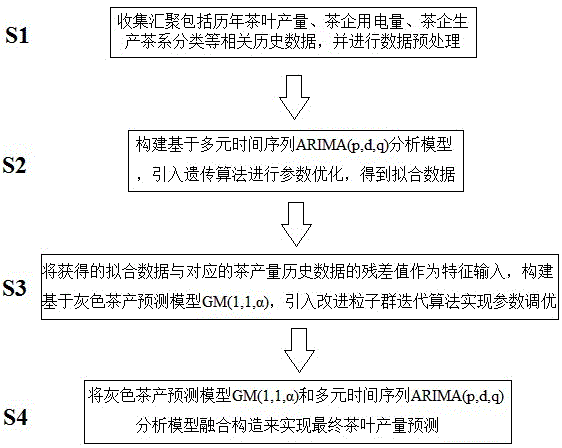
步骤s1、收集汇聚包括历年茶叶产量、茶企用电量、茶企生产茶系分类等相关历史数据,并进行数据预处理;
步骤s2、构建基于多元时间序列arima(p,d,q)分析模型,引入遗传算法进行参数优化,得到拟合数据;
步骤s3、将获得的拟合数据与对应的茶产量历史数据的残差值作为特征输入,构建基于灰色茶产预测模型gm(1,1,α),引入改进粒子群迭代算法实现参数调优;
步骤s4、将灰色茶产预测模型gm(1,1,α)和多元时间序列arima(p,d,q)分析模型融合构造来实现最终茶叶产量预测。
在本发明一实施例中,所述步骤s1中对历史数据进行数据预处理过程,即对各业务系统提供的历史数据进行整理,具体即:清洗重复、不完整的不可用数据,修正突变异常数据、补全缺失数据,对多源系统间数据进行关联匹配、计算。
在本发明一实施例中,所述步骤s2具体实现如下:
平稳性检验:通过单位根检验法adf检验判断从灰色茶产预测模型gm(1,1,α)得出的茶产量时间序列数据的平稳性,如果通过adf检验可确定茶产量时间序列不具有平稳性,则进行平稳化处理,即差分定阶;反之若茶产量时间序列具有平稳性,序列不需要经过处理,并且确定多元时间序列arima(p,d,q)分析模型中参数d的值为0;
差分定阶:茶产量时间序列不具有平稳性需要对其进行差分运算,采用差分的方式实现序列平稳化,差分运算如下所示:
▽pxt=▽p-1xt-▽p-1xt-1(1)
其中▽为差分算子,▽p表示经过p阶差分;
根据延迟算子的定义可得:xt-1=bxt,xt-2=b2xt,···,xt-p=bpxt,则
▽dxt=(1-b)dxt(2)
非平稳性的茶产量时间序列经过d阶差分后变成平稳的时间序列时,可记为:
yt=(1-b)dxt(3)
经过差分定阶后的茶产量时间序列后可确定多元时间序列arima(p,d,q)分析模型中参数d的取值,即为经过d阶差分定阶的阶数值;
自相关系数p和偏相关系数q定值:
输入具有平稳性的茶产量时间序列,通过自相关函数求出相应的自相关系数p,具体的自相关函数曲线和置信区间上边线的交点横坐标为多元时间序列arima(p,d,q)分析模型中参数p的值;
输入具有平稳性的茶产量时间序列,通过偏相关函数求出相应的自相关系数q,具体的自相关函数曲线和置信区间上边线的交点横坐标为多元时间序列arima(p,d,q)分析模型中参数q的值;
模型检验:模型的检验分为两部分,一部分是对模型的显著性检验,即茶产量残差序列是否为白噪声序列,如果是则说明提取的序列信息比较完成,如果不是说明茶产量残差序列当中仍然存在有效信息,应该继续提取;另一部分是对参数的显著性检验,即看每个参数是否显著为零,是的话则将参数对应自变量剔除,考虑在不引入过多虚假参数的前提下,使得残差平方和尽量小,因此引入以下aic准则函数:
其中n,m对应的多元时间序列arima(p,d,q)分析模型中自相关项数p和偏相关项数q;
参数估计:多元时间序列arima(p,d,q)分析模型的多项式项数确定后,使用改进遗传算法应用多元时间序列arima(p,d,q)分析模型正的参数估计,将多项式系数采用实数编码方式,组成初始类染色体,其中每一串多项式系数为染色体内的一个基因片段,通过该方式生成大量染色体组成初始种群,种群中根据适应度,选择基因组合最优的染色体,向下一迭代周期的染色体个体进行遗传,同时采用变异机制使种群中的基因发生变化;通过大量染色体不断的遗传变异,逐步在空间中得到基因组合最优的染色体,即最合适的p+q个多项式系数。
在本发明一实施例中,所述步骤s2中,引入遗传算法进行参数优化的实现方式如下:
1)初始化操作,随机生成n组由多元时间序列arima(p,d,q)分析模型多项式系数的染色体,其中该染色体由多元时间序列arima(p,d,q)分析模型中p+q项数对应系数的基因组成,作为遗传算法中的初始群体,同时设置代数计数器t,并设置最大遗传进化代数t;
2)对每个初始个体采用竞标赛适应度函数进行计算,并将测试后适应值按照从大到小的顺序进行排序;
3)对初始种群的茶产量系数个体进行选择,然后从保留下来优质父体中选择随机的两个体进行交叉、变异遗传运算,生成子代个体;其中变异策略使用的是如下式所示的二点轮转交换变异策略,提高最优茶产量系数组合搜索性能;
其中,0、1代表的茶产基因串排序,对于其中的三个基因个体按照以上公式进行分组交换,即增强变异强度;
4)设置阈值ε为判断条件,当种群中排序的最大适应值与最小适应值之差大于阈值ε则将前三个适应度大的个体进行复制,加入到建立的第二群体中;小于阈值时则两个群体内同时两两进行交叉、变异遗传运算,产生优质子代个体,并且将不同种群的优质个体进行群间交换,保持茶产量系数种群的优质性,避免陷入局部最优解;
5)算法终结条件:当两个茶产量系数种群符合收敛条件时,获得多元时间序列arima(p,d,q)分析模型中p+q项数对应系数的最优解,则结束算法,否则跳转到步骤3)。
在本发明一实施例中,所述步骤s3中,灰色茶产预测模型gm(1,1,α)的实现方式如下:
构建原始茶产量时间序列为:
x(0)=x(0)(1),x(0)(2),···,x(0)(n)(6)
其中x(0)(1),x(0)(2),...,x(0)(n)表示每个采用周期对象的茶产量估值;
对上述序列进行1-ago操作,使其序列平稳化,生成的新序列为:
x(1)=x(1)(1),x(1)(2),···,x(1)(n)(7)
其中,
接下来构建一阶单变量线性灰色微分方程,并进行白化运算可得:
其中,u表示灰色作用量,体现茶产量时间序列的变化值,v表示灰色系数,体现茶产量时间序列的变化速度;
将微分项
为了提升模型的精准度,使用下式方法对背景值x(1)进行选取:
其中x(1)(k)表示为白色背景值,x(1)(k+1)为灰色导数值;
式中,将参数u和v进行最小二乘法进行求解
其中使用
利用式子(7)进行累减还原,得到原始茶叶产量时间序列预测模型:
由于构建基于灰色茶产预测模型gm(1,1,α)中默认了x(1)(0)=x(0)(0)=1,而实际的茶叶产量受到外部因素影响,导致实际假设存在偏差;为了适应假设条件,引入向量α对公式(10)中背景值进行重新计算,从而得出灰色茶产预测模型gm(1,1,α),公式如下所示:
其中通过上述公式13和公式14进行联立可以得到α值:
在本发明一实施例中,所述步骤s3中,引入改进粒子群迭代算法实现参数调优的实现方式如下:
目标函数构建:针对灰色茶产预测模型gm(1,1,α)采用pmo粒子群算法进行参数调优,模型参数
v(u)为茶产量时间序列下经过灰色模型拟合的预测值,v为实际的茶产量值;e(t)为灰色模型的误差值,t′指的是稳态时间;目标函数j值越小说明参数值越优;
粒子位置更新:初始化各个粒子在解空间中的位置,同时初始化迭代次数;根据优化函数对每个粒子的适应值进行计算;
其中ξl为缩放因子,用来平衡全局搜索和局部搜索能力;α1,α2分别表示认知学习速率和社会学习速率;s1、s2为学习因子;ωl为惯性系数,用来控制速度矢量增长;
自适应惯性系数更新:惯性系数ωl用来控制速度矢量v的趋势,系数小则更体现算法的局部搜索能力,大则体现算法的全局搜索能力;为了权衡,使得粒子群算法的收敛性和搜索范围,使用下列公式对惯性系数ωl进行更新:
ωl=ωmax-(ωmax-ωmin)(h-havg)/hmax-hmin(17)
式中,hmax、hmin分别表示粒子群中粒子最大和最小适配值,ωmax、ωmin分别表示惯性系数的最大值和最小值;havg表示每代粒子的适配平均值。
相较于现有技术,本发明具有以下有益效果:
本申请提案首先通过采用时间序列模型对数据进行初预测,保留了获得数据的统计特征,之后通过灰色理论模型来修正受到非自然因素影响而无法基于统计特征获得的误差数据,通过残差融合的方式获得更为精准的茶叶产量预测;针对模型参数可能陷入局部最优解、收敛速度慢等问题,分别对两个模型采用了粒子群算法和遗传算法,加快对模型参数的迭代更新,使得模型更容易获得更优解和更快的收敛速度。
附图说明
图1为本发明方法流程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本发明提供了一种基于电力大数据的茶叶产量预测新方法,包括:
(1)收集汇聚包括历年茶叶产量、茶企用电量、茶企生产茶系分类等相关历史数据,并进行数据预处理;
(2)构建基于多元时间序列arima(p,d,q)分析模型,引入遗传算法进行参数优化,得到拟合数据;
(3)将获得的拟合数据与对应的茶产量历史数据的残差值作为特征输入,构建基于灰色茶产预测模型gm(1,1,α),引入改进粒子群迭代算法实现参数调优;
(4)将灰色茶产预测模型gm(1,1,α)和多元时间序列arima(p,d,q)分析模型融合构造来实现最终茶叶产量预测。
所述(1)中对历史数据进行数据预处理,其中包括对各业务系统提供的历史数据进行整理,包括清洗重复、不完整等不可用数据,修正突变异常数据、补全缺失数据,对多源系统间数据进行关联匹配、计算。
所述(2)中构建基于多元时间序列arima(p,d,q)分析模型的算法运行步骤如下所述:
由于茶产量预测的突变型和非平稳性遗留在gm(1,1,α)模型中,因此以该时间序列样本的自相关函数和偏相关函数往往难以实现收敛,实际值与预测值之间存在一定的误差,因此采用多元时间序列模型arima(p,d,q)实现对灰色gm(1,1,α)模型预测的误差进行校正,实现精准预测。
平稳性检验:通过单位根检验法adf检验判断从gm(1,1,α)灰色模型得出的茶产量时间序列数据的平稳性,如果通过adf检验可确定茶产量时间序列不具有平稳性,则进行平稳化处理(差分定阶);反之茶产量时间序列具有平稳性,序列不需要经过处理,并且确定arima(p,d,q)模型中参数d的值为0。
非平稳性序列的平稳化处理(差分定阶):对于较为复杂的茶产量时间序列数据来说,其包含着某种趋势性或周期性的特征,不满足于平稳性,因此需要对其进行差分运算,采用差分的方式实现序列平稳化,差分运算如下所示:
▽pxt=▽p-1xt-▽p-1xt-1(1)
其中▽为差分算子,▽p表示经过p阶差分;
根据延迟算子的定义可得:xt-1=bxt,xt-2=b2xt,···,xt-p=bpxt,则
▽dxt=(1-b)dxt(2)
非平稳性的茶产量时间序列经过d阶差分后变成平稳的时间序列时,可记为:
yt=(1-b)dxt(3)
经过平稳化处理(差分定阶)后的序列后可确定arima(p,d,q)模型中参数d的取值,即为经过d阶差分定阶的阶数值。
自相关系数p和偏相关系数q定值:
输入具有平稳性的茶产量时间序列,通过自相关函数求出相应的自相关系数p,具体的自相关函数曲线和置信区间上边线的交点横坐标为多元时间序列arima(p,d,q)分析模型中参数p的值;
输入具有平稳性的茶产量时间序列,通过偏相关函数求出相应的自相关系数q,具体的自相关函数曲线和置信区间上边线的交点横坐标为多元时间序列arima(p,d,q)分析模型中参数q的值;
模型检验:模型的检验主要分为两部分,一部分是对模型的显著性检验,即茶产量残差序列是否为白噪声序列,如果算是则说明提取的序列信息比较完成,如果不是说明茶产量残差序列当中仍然存在有效信息,应该继续提取。另一部分是对参数的显著性检验,即看每个参数是否显著为零,是的话则将参数对应自变量剔除。如何考虑在不引入过多虚假参数的前提下,使得残差平方和尽量小,因此引入以下aic准则函数:
其中n,m对应的多元时间序列arima(p,d,q)分析模型中自相关项数p和偏相关项数q;
参数估计:arima(p,d,q)的多项式项数确定后,对应的多项式系数成为了模型预测精度的关键。茶产量活动中常出现波动的情况,采用传统的矩估计法、最小二乘估计法和极大似然估计法将导致得到的多元时间序列模型存在较大的误差。使用改进遗传算法应用于arima(p,d,q)模型正的参数估计,将多项式系数采用实数编码方式,组成初始类染色体,其中每一串多项式系数为染色体内的一个基因片段,通过该方式生成大量染色体组成初始种群,种群中根据适应度(即目标函数),选择基因组合最优的染色体,向下一迭代周期的染色体个体进行遗传,同时采用变异机制使种群中的基因发生变化。通过大量染色体不断的遗传变异,逐步在空间中得到基因组合最优的染色体,即最合适的p+q个多项式系数。
所述(2)中引入遗传算法实现参数调优,具体算法运行步骤如下所述:
1)初始化操作,随机生成n组由多元时间序列arima(p,d,q)分析模型多项式系数的染色体,其中该染色体由多元时间序列arima(p,d,q)分析模型中p+q项数对应系数的基因组成,作为遗传算法中的初始群体,同时设置代数计数器t,并设置最大遗传进化代数t;
2)对每个初始个体采用竞标赛适应度函数进行计算,并将测试后适应值按照从大到小的顺序进行排序;
3)对初始种群的茶产量系数个体进行选择,然后从保留下来优质父体中选择随机的两个体进行交叉、变异遗传运算,生成子代个体;其中变异策略使用的是如下式所示的二点轮转交换变异策略,提高最优茶产量系数组合搜索性能;
其中,0、1代表的茶产基因串排序,对于其中的三个基因个体按照以上公式进行分组交换,即增强变异强度;
4)设置阈值ε为判断条件,当种群中排序的最大适应值与最小适应值之差大于阈值ε则将前三个适应度大的个体进行复制,加入到建立的第二群体中;小于阈值时则两个群体内同时两两进行交叉、变异遗传运算,产生优质子代个体,并且将不同种群的优质个体进行群间交换,保持茶产量系数种群的优质性,避免陷入局部最优解;
5)算法终结条件:当两个茶产量系数种群符合收敛条件时,获得多元时间序列arima(p,d,q)分析模型中p+q项数对应系数的最优解,则结束算法,否则跳转到步骤3)。
所述(3)中,灰色茶产预测模型gm(1,1,α)算法流程描述如下:
构建原始茶产量时间序列为:
x(0)=x(0)(1),x(0)(2),···,x(0)(n)(6)
其中x(0)(1),x(0)(2),...,x(0)(n)表示每个采用周期对象的茶产量估值;
为更准确刻画茶产量的周期规律,防止其他因素对茶产量时间序列变化规律分析的影响,对上述序列进行1-ago操作,使其序列平稳化,生成的新序列为:
x(1)=x(1)(1),x(1)(2),···,x(1)(n)(7)
其中,
接下来构建一阶单变量线性灰色微分方程,并进行白化运算可得:
其中,u表示灰色作用量,体现茶产量时间序列的变化值,v表示灰色系数,体现茶产量时间序列的变化速度;
将微分项
为了提升模型的精准度,使用下式方法对背景值x(1)进行选取:
其中x(1)(k)表示为白色背景值,x(1)(k+1)为灰色导数值;
式中,将参数u和v进行最小二乘法进行求解
其中使用
利用式子(7)进行累减还原,得到原始茶叶产量时间序列预测模型:
由于构建基于灰色茶产预测模型gm(1,1,α)中默认了x(1)(0)=x(0)(0)=1,而实际的茶叶产量受到外部因素(如环境因素、人为因素等)影响,导致实际假设存在偏差;为了适应假设条件,引入向量α对公式(10)中背景值进行重新计算,从而得出灰色茶产预测模型gm(1,1,α),公式如下所示:
其中通过上述公式13和公式14进行联立可以得到α值:
所述(3)中,引入改进粒子群迭代算法实现参数调优,具体算法解析如下所述:
目标函数构建:针对灰色茶产预测模型gm(1,1,α)采用pmo粒子群算法进行参数调优,模型参数
v(u)为茶产量时间序列下经过灰色模型拟合的预测值,v为实际的茶产量值;e(t)为灰色模型的误差值,t′指的是稳态时间;目标函数j值越小说明参数值越优;
粒子位置更新:初始化各个粒子在解空间中的位置,同时初始化迭代次数;根据优化函数对每个粒子的适应值进行计算;
其中ξl为缩放因子,用来平衡全局搜索和局部搜索能力;α1,α2分别表示认知学习速率和社会学习速率;s1、s2为学习因子;ωl为惯性系数,用来控制速度矢量增长;
自适应惯性系数更新:惯性系数ωl用来控制速度矢量v的趋势,系数小则更体现算法的局部搜索能力,大则体现算法的全局搜索能力;为了权衡,使得粒子群算法的收敛性和搜索范围,使用下列公式对惯性系数ωl进行更新:
ωl=ωmax-(ωmax-ωmin)(h-havg)/hmax-hmin(17)
式中,hmax、hmin分别表示粒子群中粒子最大和最小适配值,ωmax、ωmin分别表示惯性系数的最大值和最小值;havg表示每代粒子的适配平均值。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!