基于数据血缘分析的数据追踪方法、系统及存储介质与流程
1.本发明涉及数据治理领域,尤其涉及基于数据血缘分析的数据追踪方法、系统及存储介质。
背景技术:
2.在人类社会中,血缘关系是指由婚姻或生育而产生的人际关系,是最早形成的一种社会关系。今天,人类进入了大数据时代。每天,世界上都有海量的,各种类型的,关系复杂的数据在快速产生。这些庞大复杂的数据汇聚又产生新的数据。数据在产生、融合、流转,消亡过程中形成一种逻辑关系。我们借鉴人类社会中的血缘关系来表达数据之间的这种关系,称之为数据的血缘关系。
3.数据治理里经常提到的一个词就是血缘分析,血缘分析是保证数据融合(聚合)的一个手段,通过血缘分析能够实现数据融合处理的可追溯。当今缺少一种较为系统有效的数据血缘分析方法,无法满足企事业单位的数据治理需求。
技术实现要素:
4.本发明的目的是为了至少解决现有技术的不足之一,提供基于数据血缘分析的数据追踪方法、系统及存储介质。
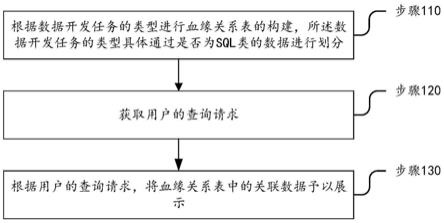
5.为了实现上述目的,本发明采用以下的技术方案:具体的,提出基于数据血缘分析的数据追踪方法,包括以下:根据数据开发任务的类型进行血缘关系表的构建,所述数据开发任务的类型具体通过是否为sql类的数据进行划分;获取用户的查询请求;根据用户的查询请求,将血缘关系表中的关联数据予以展示。
6.进一步,所述根据数据开发任务的类型进行血缘关系表的构建具体包括以下,当判断为非sql类的数据开发任务时,扫描运行环境中的同步任务配置信息,根据所述同步任务配置信息中的任务的输入以及输出确定当前任务中相关数据表的血缘关系,并将血缘关系写入血缘关系数据表中以更新血缘关系数据表;当判断为sql类的数据开发任务时,将当前任务执行的命令打包写入消息队列,从消息队列中获取数据,利用sql的ast语法确定当前任务中的相关数据表的读、写属性并进行标记,通过sql中的数据源信息确定是否已经存在有关相关数据表已建立的存储对象,如果已经存在,则根据sql语法中的单语句读写关系,确定数据血缘流向,如果不存在,则为相关数据表建立对应的存储对象,再根据sql语法中的单语句读写关系,确定数据血缘流向,最终根据确定的血缘数据流向更新血缘关系数据表;最终根据以上两种数据开发任务的类型所更新的血缘关系数据表,完成血缘关系表的构件。
7.进一步,上述根据用户的查询请求,将血缘关系表中的关联数据予以展示具体包
括以下,根据用户的查询请求,获取血缘关系表中的关联数据,并对所述关联数据进行数据清洗得到清洗后的数据;对清洗后的数据进行词法分析,生成抽象语法树,遍历抽象语法树对数据中的语句进行句法解析;对句法解析后的抽象语法树,根据血缘关系分析结果绘制基于语句的数据血缘关系图,最终进行可视化展示。
8.进一步,上述数据清洗过程具体包括,获取含有sql代码的脚本文件,并寻找sql代码的标志位,利用标志位过滤脚本文件中的无关内容,保留得到规则化的sql代码语句;上述词法分析过程具体包括,对规则化的sql语句进行词法分析,根据语法规则对规则化的 sql语句进行关键词划分,并对每个关键词进行标签标识,并将每个标识后的sql语句作为一个节点,生成为一棵抽象语法树,遍历抽象语法树,为每个标签对应的sql语句赋予句法意义,实现对sql语句的句法解析;上述遍历抽象语法树对数据中的语句进行句法解析具体包括,处理抽象语法树中标识出的节点数据,将源数据表和源数据字段作为节点数据的输入集合,将目标数据表和目标数据字段作为节点数据的输出集合,对节点数据的来源和去向分别进行映射,得到血缘关系分析结果;上述可视化展示具体包括,绘制数据血缘关系图中数据表和字段节点,并根据血缘关系分析结果,关联数据血缘关系图中的节点并绘制箭头指向连线,将绘制好的数据血缘关系图发送至用户终端进行可视化显示。
9.本发明还提出基于数据血缘分析的数据追踪系统,包括,血缘关系表构建模块,用于根据数据开发任务的类型进行血缘关系表的构建,所述数据开发任务的类型具体通过是否为sql类的数据进行划分;查询请求获取模块,用于获取用户的查询请求;根据用户的查询请求,将血缘关系表中的关联数据予以展示。
10.进一步,所述血缘关系表构建模块具体包括非sql类的数据开发任务处理子单元以及sql类的数据开发任务处理子单元,所述非sql类的数据开发任务处理子单元,用于当判断为非sql类的数据开发任务时,扫描运行环境中的同步任务配置信息,根据所述同步任务配置信息中的任务的输入以及输出确定当前任务中相关数据表的血缘关系,并将血缘关系写入血缘关系数据表中以更新血缘关系数据表;所述sql类的数据开发任务处理子单元,用于当判断为sql类的数据开发任务时,将当前任务执行的命令打包写入消息队列,从消息队列中获取数据,利用sql的ast语法确定当前任务中的相关数据表的读、写属性并进行标记,通过sql中的数据源信息确定是否已经存在有关相关数据表已建立的存储对象,如果已经存在,则根据sql语法中的单语句读写关系,确定数据血缘流向,如果不存在,则为相关数据表建立对应的存储对象,再根据sql语法中的单语句读写关系,确定数据血缘流向,最终根据确定的血缘数据流向更新血缘关系数据表。
11.本发明还提出一种计算机可读存储的介质,所述计算机可读存储的介质存储有计
算机程序,所述计算机程序被处理器执行时实现如权利要求1
‑
4中任一项所述方法的步骤。
12.本发明的有益效果为:本发明提出基于数据血缘分析的数据追踪方法,通过根据是否为sql类的数据开发任务进行血缘关系表的构建,最终根据血缘关系表按照用户的查询请求;将血缘关系表中的关联数据展示给用户,整个方案系统有效,能够满足企事业单位的数据治理需求。
附图说明
13.为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
14.图1所示为本发明基于数据血缘分析的数据追踪方法流程图;图2所示为本发明基于数据血缘分析的数据追踪方法的血缘关系表的建立流程图。
具体实施方式
15.以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本发明的目的、方案和效果。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。附图中各处使用的相同的附图标记指示相同或相似的部分。
16.参照图1以及图2,实施例1,本发明提出基于数据血缘分析的数据追踪方法,包括以下:根据数据开发任务的类型进行血缘关系表的构建,所述数据开发任务的类型具体通过是否为sql类的数据进行划分;获取用户的查询请求;根据用户的查询请求,将血缘关系表中的关联数据予以展示。
17.作为本发明的优选实施方式,所述根据数据开发任务的类型进行血缘关系表的构建具体包括以下,当判断为非sql类的数据开发任务时,扫描运行环境中的同步任务配置信息,根据所述同步任务配置信息中的任务的输入以及输出确定当前任务中相关数据表的血缘关系,并将血缘关系写入血缘关系数据表中以更新血缘关系数据表;当判断为sql类的数据开发任务时,将当前任务执行的命令打包写入消息队列,从消息队列中获取数据,利用sql的ast语法确定当前任务中的相关数据表的读、写属性并进行标记,通过sql中的数据源信息确定是否已经存在有关相关数据表已建立的存储对象,如果已经存在,则根据sql语法中的单语句读写关系,确定数据血缘流向,如果不存在,则为相关数据表建立对应的存储对象,再根据sql语法中的单语句读写关系,确定数据血缘流向,最终根据确定的血缘数据流向更新血缘关系数据表;最终根据以上两种数据开发任务的类型所更新的血缘关系数据表,完成血缘关系表的构件。
18.作为本发明的优选实施方式,上述根据用户的查询请求,将血缘关系表中的关联数据予以展示具体包括以下,根据用户的查询请求,获取血缘关系表中的关联数据,并对所述关联数据进行数据清洗得到清洗后的数据;对清洗后的数据进行词法分析,生成抽象语法树,遍历抽象语法树对数据中的语句进行句法解析;对句法解析后的抽象语法树,根据血缘关系分析结果绘制基于语句的数据血缘关系图,最终进行可视化展示。
19.作为本发明的优选实施方式,上述数据清洗过程具体包括,获取含有sql代码的脚本文件,并寻找sql代码的标志位,利用标志位过滤脚本文件中的无关内容,保留得到规则化的sql代码语句;上述词法分析过程具体包括,对规则化的sql语句进行词法分析,根据语法规则对规则化的 sql语句进行关键词划分,并对每个关键词进行标签标识,并将每个标识后的sql语句作为一个节点,生成为一棵抽象语法树,遍历抽象语法树,为每个标签对应的sql语句赋予句法意义,实现对sql语句的句法解析;上述遍历抽象语法树对数据中的语句进行句法解析具体包括,处理抽象语法树中标识出的节点数据,将源数据表和源数据字段作为节点数据的输入集合,将目标数据表和目标数据字段作为节点数据的输出集合,对节点数据的来源和去向分别进行映射,得到血缘关系分析结果;上述可视化展示具体包括,绘制数据血缘关系图中数据表和字段节点,并根据血缘关系分析结果,关联数据血缘关系图中的节点并绘制箭头指向连线,将绘制好的数据血缘关系图发送至用户终端进行可视化显示。
20.本发明还提出基于数据血缘分析的数据追踪系统,包括,血缘关系表构建模块,用于根据数据开发任务的类型进行血缘关系表的构建,所述数据开发任务的类型具体通过是否为sql类的数据进行划分;查询请求获取模块,用于获取用户的查询请求;根据用户的查询请求,将血缘关系表中的关联数据予以展示。
21.作为本发明的优选实施方式,所述血缘关系表构建模块具体包括非sql类的数据开发任务处理子单元以及sql类的数据开发任务处理子单元,所述非sql类的数据开发任务处理子单元,用于当判断为非sql类的数据开发任务时,扫描运行环境中的同步任务配置信息,根据所述同步任务配置信息中的任务的输入以及输出确定当前任务中相关数据表的血缘关系,并将血缘关系写入血缘关系数据表中以更新血缘关系数据表;所述sql类的数据开发任务处理子单元,用于当判断为sql类的数据开发任务时,将当前任务执行的命令打包写入消息队列,从消息队列中获取数据,利用sql的ast语法确定当前任务中的相关数据表的读、写属性并进行标记,通过sql中的数据源信息确定是否已经存在有关相关数据表已建立的存储对象,如果已经存在,则根据sql语法中的单语句读写关系,确定数据血缘流向,如果不存在,则为相关数据表建立对应的存储对象,再根据sql语法中的单语句读写关系,确定数据血缘流向,最终根据确定的血缘数据流向更新血缘关系
数据表。
22.本发明还提出一种计算机可读存储的介质,所述计算机可读存储的介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1
‑
4中任一项所述方法的步骤。
23.所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理模块,即可以位于一个地方,或者也可以分布到多个网络模块上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例中的方案的目的。
24.另外,在本发明各个实施例中的各功能模块可以集成在一个处理模块中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。
25.所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储的介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括是电载波信号和电信信号。
26.尽管本发明的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,而是应当将其视作是通过参考所附权利要求考虑到现有技术为这些权利要求提供广义的可能性解释,从而有效地涵盖本发明的预定范围。此外,上文以发明人可预见的实施例对本发明进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本发明的非实质性改动仍可代表本发明的等效改动。
27.以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。在本发明的保护范围内其技术方案和/或实施方式可以有各种不同的修改和变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1