基于置信度自适应和差分增强的视频显著物体检测方法
本发明属于视频图像检测研究技术领域,特别涉及一种基于置信度自适应和差分增强的视频显著物体检测方法。
技术背景
视频显著物体检测任务指的是通过分析输入的视频序列,从中定位出最吸引人注意的物体,即显著物体,并对其进行像素级的分割。该任务源自于认知研究中人类的视觉注意行为,即人类能够快速将注意力转移到视觉场景中信息量最大的区域。视频显著物体检测是计算机视觉领域的经典问题,被广泛应用于其他复杂任务,如视频压缩,视频描述和行人重识别。在视频序列中,显著物体的定位不仅受到表观颜色的影响,还受到运动快慢的影响。因此,视频显著物体检测任务不仅需要提取单张图片中的空间信息,还需要挖掘视频序列中的时间信息。传统的视频显著物体检测方法根据先验知识来融合空间信息和时间信息,例如时空背景先验和低秩一致性先验。但是,受制于手工提取的低层级特征,传统的视频显著物体检测方法性能较差。随着人工智能的快速发展,基于深度学习的视频显著物体检测方法性能大大提升。现有的基于深度学习的视频显著物体检测方法主要分为单流网络框架和双流网络框架。单流网络框架主要由一个空间特征提取器和一个记忆模块构成。空间特征提取器分别提取多张图片的空间特征,再将多张图片的空间特征输入到记忆模块中,由记忆模块提取时间信息,最后得到显著图。双流网络框架使用空间特征提取器和时间特征提取器分别提取来自单张图片的空间特征和来自光流的时间特征,并融合时间特征和空间特征来预测显著图。
基于单流网络框架的视频显著物体检测方法采用先提取空间信息后提取时间信息的流程,时间信息的提取依赖于先前得到的空间信息,这不仅导致了噪声的传递和误差的累积,降低模型的鲁棒性,也忽略了空间信息和时间信息的互补作用,未能充分挖掘具有判别性的信息,导致预测的显著物体图不完整。而基于双流网络框架的视频显著物体检测方法往往直接对空间信息和时间信息进行融合,未能考虑空间信息和时间信息中噪声对模型性能的影响。
技术实现要素:
鉴于现有技术的缺陷,本发明旨在于提供一种基于置信度自适应和差分增强的视频显著物体检测方法。通过本发明的方法能够自适应提取原图输入和光流图输入中有用的空间信息和时间信息。整个网络框架是一个双流结构,包括原图输入的空间信息流和光流图输入的时间信息流,可同时提取表示颜色显著性的空间特征和表示运动显著性的空间特征。
为了实现上述目的,本发明采用的技术方案如下:
基于置信度自适应和差分增强的视频显著物体检测方法,所述方法包括输入一对原图和光流图,编码器分别提取不同层级的空间特征和时间特征;提取到的同一层级的空间特征和时间特征被送入置信度自适应模块中进行重新校正,使得有用信息被传递,噪声信息被抑制;然后,差分信息增强模块利用差分信息对重新校正后的空间特征和时间特征进行互补增强并得到融合特征;在不同层级的融合特征经过解码器层层上采样,最终得到显著物体图。
优选的,所述置信度自适应模块分别由分割器和预测器构成,其中,所述分割器和所述预测器均由3层卷积核大小为3x3的卷积层串联而成;接收来自编码器的特征作为输入,所述分割器分割得到一张低分辨率的显著物体图;将所述分割器预测得到的所述显著物体图与原先的输入特征进行通道上的拼接后送入所述预测器;所述预测器通过分析所述显著物体图与所述输入特征,预测一个能够表示输入特征置信度的得分。
需要说明的是,所述置信度得分的计算公式如下:
其中,ei表示输入特征,fseg和fpred分别代表分割器和预测器。σ指的是sigmoid函数,用于将置信度得分限制在0到1之间。
需要进一步说明的是,在得到输入特征的所述置信度得分后,使用所述置信度得分对输入特征进行加权;置信度自适应模块的计算公式如下:
优选的,使用所述差分信息增强模块充分利用空间特征和时间特征之间的互补信息时,首先获得空间特征和时间特征之间的差,再通过一个卷积核大小为3x3的卷积层得到空间特征和时间特征的差分信息;将差分信息加回原来的空间特征和时间特征上,补充了原来的特征,起到特征增强的作用;最后,融合增强后的空间特征和时间特征以得到完整的显著性信息
需要说明的是,差分信息增强模块的计算公式如下:
其中,
本发明的有益效果在于,能够自适应提取原图输入和光流图输入中有用的空间信息和时间信息,得到完整的显著物体图。整个网络框架是一个双流结构,包括原图输入的空间信息流和光流图输入的时间信息流,可同时提取表示颜色显著性的空间特征和表示运动显著性的空间特征。本发明的框架包含2个主要模块,置信度自适应模块和差分信息增强模块,分别起到抑制噪声和补充信息的作用。提出的置信度自适应模块能够衡量输入空间信息和时间信息的置信度,既保持了高置信度的有用信息,也抑制了低置信度的噪声信息,有利于模型准确定位出显著物体。提出的差分信息增强模块通过提取差分信息增强了空间信息和时间信息完整表示显著物体的能力,有利于模型完整地分割出显著物体。并且通过实验结果证明,本发明能够准确且完整地预测显著物体图,且优于最好的现有技术。
附图说明
图1为本发明网络框架图;
图2为本发明置信度自适应模块示意图;
图3为本发明差分信息增强模块示意图;
图4为本发明与主流方法显著物体图比较结果。
具体实施例
以下将结合附图对本发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
本发明为一种基于置信度自适应和差分增强的视频显著物体检测方法,所述方法输入一对原图和光流图,编码器分别提取不同层级的空间特征和时间特征;提取到的同一层级的空间特征和时间特征被送入置信度自适应模块中进行重新校正,使得有用信息被传递,噪声信息被抑制;然后,差分信息增强模块利用差分信息对重新校正后的空间特征和时间特征进行互补增强并得到融合特征;在不同层级的融合特征经过解码器层层上采样,最终得到显著物体图。
优选的,所述置信度自适应模块分别由分割器和预测器构成,其中,所述分割器和所述预测器均由3层卷积核大小为3x3的卷积层串联而成;接收来自编码器的特征作为输入,所述分割器分割得到一张低分辨率的显著物体图;将所述分割器预测得到的所述显著物体图与原先的输入特征进行通道上的拼接后送入所述预测器;所述预测器通过分析所述显著物体图与所述输入特征,预测一个能够表示输入特征置信度的得分。
需要说明的是,所述置信度得分的计算公式如下:
其中,ei表示输入特征,fseg和fpred分别代表分割器和预测器。σ指的是sigmoid函数,用于将置信度得分限制在0到1之间。
需要进一步说明的是,在得到输入特征的所述置信度得分后,使用所述置信度得分对输入特征进行加权;置信度自适应模块的计算公式如下:
优选的,使用所述差分信息增强模块充分利用空间特征和时间特征之间的互补信息时,首先获得空间特征和时间特征之间的差,再通过一个卷积核大小为3x3的卷积层得到空间特征和时间特征的差分信息;将差分信息加回原来的空间特征和时间特征上,补充了原来的特征,起到特征增强的作用;最后,融合增强后的空间特征和时间特征以得到完整的显著性信息
需要说明的是,差分信息增强模块的计算公式如下:
其中,
实施例1
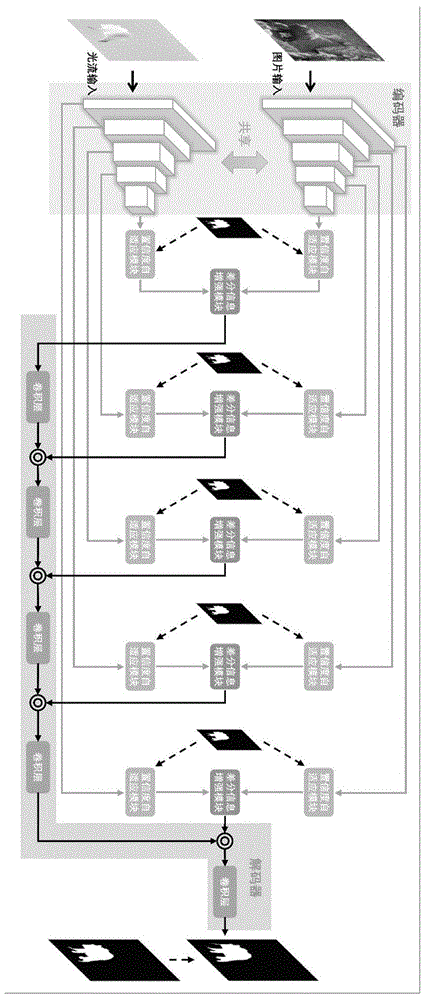
如图1所示,本发明的整个网络框架是一个双流结构,包括原图输入的空间信息流和光流图输入的时间信息流,可同时提取表示颜色显著性的空间特征和表示运动显著性的时间特征。显著物体图的预测基于编码器-解码器流程,主要为图片输入和光流输入共享的编码器,输出显著物体图的解码器,一系列置信度自适应模块和差分信息增强模块。对于编码器,本发明采用resnet-101网络结构。
进一步的,输入一对原图和光流图,编码器分别提取不同层级的空间特征和时间特征。提取到的同一层级的空间特征和时间特征被送入置信度自适应模块中进行重新校正,使得有用信息被传递,噪声信息被抑制。接着,差分信息增强模块利用差分信息对重新校正后的空间特征和时间特征进行互补增强并得到融合特征。最后,不同层级的融合特征经过解码器层层上采样,最终得到显著物体图。
在现实场景中,原图和光流图不可避免地包含不可靠的噪声信息,这些信息的传播与使用会严重降低模型的性能。所以,如何衡量信息的可靠性并抑制不可靠的噪声信息是至关重要的。为了解决这个问题,我们提出了置信度自适应模块,如图2所示。该模块主要由2个部分构成,分别是分割器和预测器。分割器和预测器都由3层卷积核大小为3x3的卷积层串联而成。接收来自编码器的特征作为输入,分割器分割得到一张低分辨率的显著物体图。为了得到准确的低分辨率显著物体图,使用下采样后的显著物体图标签来监督分割器的学习。接着,将分割器预测得到的显著物体图与原先的输入特征进行通道上的拼接后送入预测器。预测器通过分析显著物体图与输入特征,预测一个能够表示输入特征置信度的得分。为了显式表示特征的置信度,我们计算分割器预测得到的显著物体图和显著物体图标签的交并比,作为监督信号引导预测器的学习。置信度得分的计算公式如下:
其中,ei表示输入特征,fseg和fpred分别代表分割器和预测器。σ指的是sigmoid函数,用于将置信度得分限制在0到1之间。
在得到输入特征的置信度得分后,使用这个置信度得分对输入特征进行加权。通过这个操作,保持了高置信度的特征,抑制了低置信度的特征,起到自适应调整特征的作用。具体的说,置信度自适应模块的计算公式如下:
对于输入的空间特征和时间特征,置信度自适应模块能够预测出特征的置信度得分,作为特征可靠性的评判依据。对于置信度得分低的特征,置信度自适应模块能够对其进行抑制,降低对显著物体图预测的负面影响。对于置信度得分高的特征,置信度自适应模块允许其通过,保持其对显著物体预测的正面影响。
空间特征包含颜色显著性信息,时间特征包含运动显著性信息,视频显著物体检测任务需要综合考虑颜色显著性信息和运动显著性信息。因此,本发明需要综合考虑空间特征和时间特征来预测准确完整的显著物体图。为此,本发明提出了差分信息增强模块来充分利用空间特征和时间特征之间的互补信息,如图3所示。首先,以相减的方法计算空间特征和时间特征之间的差,再通过一个卷积核大小为3x3的卷积层得到空间特征和时间特征的差分信息。差分信息表示空间特征和时间特征之间差异的信息。接着,本发明将差分信息加回原来的空间特征和时间特征上,补充了原来的特征,起到特征增强的作用。最后,融合增强后的空间特征和时间特征以得到完整的显著性信息。差分信息增强模块的计算公式如下:
其中,
实施例2
本实施例通过实验对方法的效果进行说明,实验数据库选择davsod数据库、davis数据库、segv2数据库和fbms数据库。其中,davsod数据库包含226条视频序列,共计23938个视频帧,覆盖了多种复杂现实场景,是最具挑战性的大型视频显著物体检测数据库。davis数据库包含50条视频序列,共计3455个高质量标注的视频帧,其中的显著物体具有不同程度的遮挡和不规则边缘,是最广泛应用的视频显著物体检测数据库。segv2数据库包含13条视频序列,涉及多种动物、交通工具和人物。fbms数据库包含59条视频序列,该数据库采用稀疏标注,共有720个标注视频帧。实验评估指标采用f-measure(f)、s-measure(s)和平均绝对误差(mae)。
本实施例将本发明的方法与现有的一些主流的基于深度学习的方法进行了比较,在davsod数据库、davis数据库、segv2数据库和fbms数据库上的比较结果如表1所示。由表1结果可知,本发明在davsod数据库、davis数据库、segv2数据库和fbms数据库上分别达到了0.670、0.898、0.826、0.858的f-measure,0.762、0.906、0.865、0.870的s-measure,0.072、0.018、0.027、0.039的mae,领先于大部分视频显著物体检测主流方法,这表明了本发明在视频显著物体检测的效果已经达到领域先进水平。
表1本发明与主流方法比较结果
同时,为了直观地展示本发明的优越性,将本发明的方法与主流方法的显著物体图进行比较,如图4所示。由图4第1、5行结果可知,在多个运动物体的场景下,本发明能够减少噪声的影响,精确地定位出显著物体。由图4第2、3、4行结果可知,在杂乱的前景和背景的情况下,本发明能充分考虑空间信息和时间信息的互补作用,从而得到完整的显著物体图。
最后,本发明还在davsod数据库和davis数据库上验证置信度自适应模块和差分信息增强模块这两种模块的有效性,如表2所示。由表2可知,置信度自适应模块和差分信息模块都能不同程度的提高模型性能。而且,置信度自适应模块和差分信息增强模块这两者结合能达到最好的效果。
表2本发明各部分效果
对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的改变,而所有的这些改变,都应该包括在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!