图像处理方法、装置、系统、电子设备和计算机可读存储介质与流程
1.本发明涉及一种图像处理方法、装置、系统、电子设备和计算机可读存储介质。
背景技术:
2.近年来,通过摄像头等外界传感器获取车辆周围的外界信息且通过外界识别装置识别外界信息的外界识别系统已逐步开始普及使用,例如,在日本发明专利申请特愿2018-558842号中公开了以下技术,外界识别系统通过识别车辆周边的识别对象的位置来使车辆进行自动驾驶或者对车辆进行辅助驾驶。
3.此外,在日本发明专利公开公报特开2016-71577号中还公开了以下技术。通过设置在车厢内的摄像头来拍摄驾驶员的面部并根据在规定周期内的其表情的变化的次数来判定驾驶员是否处于漫不经心状态,由此,通过推定人的情感来提醒驾驶员的驾驶操作。
技术实现要素:
4.然而,在上述这样的现有技术中,摄像头只是用来拍摄车外的外界信息或用来拍摄车内人的表情变化,以进行自动驾驶辅助,摄像头本身的使用价值并没有实现最大化,从而需求摄像头等拍摄装置的进一步的开发利用。此外,现有技术中也有使用车外摄像头来拍摄车外景色来获得车辆外图像的技术,但该图像仅反映出车外景色,而缺乏趣味性及参与感。
5.本发明是考虑到这样的技术问题而完成的,其目的在于提供一种图像处理方法及其装置、系统等,能够将例如由车辆外摄像头拍摄到的车辆外的情景图像与例如由车辆内摄像头等拍摄到的车辆内图像关联在一起,得到用户想要的图像,由此使图像本身存在趣味性及参与感。
6.本发明的第一方面为,提供一种图像处理方法,在第一场景中获取第一原始图像,所述第一原始图像中包含第一对象,提取所述第一对象的第一关键点信息,并对所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值;在第一场景外的第二场景中获取第二原始图像,所述第二原始图像中包含第二对象,提取所述第二对象的第二关键点信息,并对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值;基于所述第一原始图像的所述第一权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重值。
7.根据本发明的第一方面,通过基于第一原始图像的第一权重值使所述第二原始图像的第二权重值增大,而使第二原始图像具有叠加权重值,能够将第一原始图像与第二原始图像关联在一起,得到用户想要的图像,由此使图像本身存在趣味性及参与感。
8.本发明的第二方面为,所述第二原始图像为与所述第一原始图像同时获取或基于所述第一原始图像中的所述第一关键点信息获取的图像。
9.根据本发明的第二方面,由于第二原始图像为与第一原始图像同时获取或基于所述第一原始图像中的所述第一关键点信息获取的图像,因此,能够获取贴合用户喜好的图
像。
10.本发明的第三方面为,所述第一原始图像是情感图像,所述第一关键点信息包括人脸图像、人的姿态和语音信息中的一种或多种,提取所述人脸图像的表情信息,对所述表情信息进行分类,并按表情类别设定第一权重值,提取所述人的姿态的姿态信息,对所述姿态进行分类,并按姿态类别设定第一权重值,提取所述语音信息中的关键词,对所述关键词进行分类,并按关键词类别设定第一权重值。
11.根据本发明的第三方面,由于通过人脸图像、人的姿态和语音信息中的一种或多种来设定第一原始图像的第一权重值,能够精准获取第一原始图像中人的感兴趣程度。
12.本发明的第四方面为,取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值。
13.本发明的第五方面为,在所述第一关键点信息中,当所述人脸图像的表情信息、所述人的姿态与所述关键词中的至少两者以上存在一致性时,增大该存在一致性的所述第一关键点信息的第一权重值。
14.根据本发明的第四、五方面,由于通过取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值,或者,增大该存在一致性的所述第一关键点信息的第一权重值,更能够精准获取第一原始图像中人的感兴趣程度。
15.本发明的第六方面为,所述第二原始图像是情景图像,所述情景图像包括人文图像、景色图像和场景图像,提取所述情景图像的特征作为所述第二关键点信息。
16.根据本发明的第六方面,由于第二原始图像为包括人文图像和景色图像的情景图像,因此,通过将第一原始图像中人的感兴趣程度与情景图像相结合,能够获得基于用户喜好的情景图像,进而获得基于用户喜好的图像。
17.本发明的第七方面为,所述第一场景为车辆内场景,所述第二场景为车辆外场景。
18.根据本发明的第七方面,由于第一场景为车辆内场景,第二场景为车辆外场景,因此,能够将车内的人的状态与车外的场景建立关联,而能够反映出乘车人对于车外场景的喜爱程度,从而能够获得基于乘车人喜好的包含乘车人在内的图像。
19.本发明的第八方面为,实施本发明的第一方面至第七方面任一项所述的图像处理方法,将所述第一原始图像和所述第二原始图像合成为合成图像,其中所述合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像;基于所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值。
20.根据本发明的第八方面,将所述第一原始图像和所述第二原始图像合成为合成图像,能够得到用户感兴趣的图像,此外,通过设置合成图像的合成图像权重值能够生成基于用户喜好的合成图像。
21.本发明的第九方面为,实施本发明的第八方面所述的图像合成方法;基于所述第一关键点信息生成对应于所述第一原始图像的第一标签;基于所述第二关键点信息生成对应于所述第二原始图像的第二标签;基于所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签。
22.根据本发明的第九方面,由于生成第一标签、第二标签和合成图像标签,因此,便于用户获得第一原始图像、第二原始图像以及合成图像。
23.本发明的第十方面为,提供一种图像整理方法,实施本发明的第九方面所述的图像标签生成方法;基于所述合成图像标签将所述合成图像归类;基于被归类的所述合成图像的合成图像权重值生成所述合成图像的序列。
24.根据本发明的第十方面,由于将所述合成图像归类,并基于被归类的合成图像的合成图像权重值生成合成图像的序列,因此,能够将用户喜好的合成图像排列在优先获取的位置,便于用户获取。
25.本发明的第十一方面为,提供一种图像输出方法,实施本发明的第十方面所述的图像整理方法;从所述合成图像的序列中选择并输出合成图像。
26.根据本发明的第十一方面,从所述合成图像的序列中选择并输出合成图像,因此,能够得到用户所希望得到的图像。
27.本发明的第十二方面为,提供一种图像修正方法,实施本发明的第十一方面所述的图像输出方法;基于针对所输出的合成图像的受众评价的反馈,来修正所述合成图像的合成图像权重值,进而调整所述合成图像的序列。
28.根据本发明的第十二方面,基于针对所输出的合成图像的受众评价的反馈,来修正合成图像的合成图像权重值,进而调整合成图像的序列,因此,能够优化合成图像的序列,提高用户的体验度。
29.本发明的第十三方面为,提供一种图像处理装置,包括:第一图像获取单元,其在第一场景中获取第一原始图像,所述第一原始图像中包含第一对象;第一关键点信息提取单元,其提取所述第一对象的第一关键点信息;第一图像权重设定单元,其对所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值;还包括:第二图像获取单元,其在第一场景外的第二场景中获取第二原始图像,所述第二原始图像中包含第二对象;第二关键点信息提取单元,其提取所述第二对象的第二关键点信息;第二图像权重设定单元,其对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值;所图像处理装置基于所述第一原始图像的所述第一权重值使所述第二原始图像第二权重值增大,而使所述第二原始图像具有叠加权重值。
30.本发明的第十四方面为,所述第二原始图像为与所述第一原始图像同时获取或基于所述第一原始图像中的所述第一关键点信息获取的图像。
31.本发明的第十五方面为,所述第一原始图像是情感图像,所述第一关键点信息包括人脸图像、人的姿态和语音信息中的一种或多种,当所述第一关键点信息提取单元提取所述人脸图像的表情信息时对所述表情信息进行分类,所述第一图像权重设定单元按表情类别设定第一权重值,当所述第一关键点信息提取单元提取所述人的姿态的姿态信息时对所述姿态进行分类,所述第一图像权重设定单元按姿态类别设定第一权重值,当所述第一关键点信息提取单元提取所述语音信息中的关键词时对所述关键词进行分类,所述第一图像权重设定单元按关键词类别设定第一权重值。
32.本发明的第十六方面为,所述第一图像权重设定单元取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值。
33.本发明的第十七方面为,在所述第一关键点信息中,当所述人脸图像的表情信息、所述人的姿态与所述关键词中的至少两者以上存在一致性时,所述第一图像权重设定单元增大该存在一致性的所述第一关键点信息的第一权重值。
34.本发明的第十八方面为,所述第二原始图像是情景图像,所述情景图像包括人文图像、景色图像和场景图像,所述第二关键点信息提取单元提取所述情景图像的特征作为所述第二关键点信息。
35.本发明的第十九方面为提供一种图像合成装置,其基于本发明的第十三方面-第十八方面中任一项所述的图像处理装置所进行的处理,将所述第一原始图像和所述第二原始图像合成为合成图像,其中所述合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像;并且基于所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值。
36.本发明的第二十方面为提供一种图像标签生成装置,其基于本发明的第十九方面所述的图像合成装置所进行的处理,按照所述第一关键点信息生成对应于所述第一原始图像的第一标签;按照所述第二关键点信息生成对应于所述第二原始图像的第二标签;按照所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签。
37.本发明的第二十一方面为提供一种图像整理装置,其基于本发明的第二十方面所述的图像合成装置所进行的处理,按照所述合成图像标签将所述合成图像归类;并按照被归类的所述合成图像的合成图像权重值生成所述合成图像的序列。
38.本发明的第二十二方面为提供一种图像输出装置,基于本发明的第二十一方面所述的图像整理装置所进行的处理,从所述合成图像的序列中选择并输出合成图像。
39.本发明的第二十三方面为提供一种图像修正装置,其基于本发明的第二十二方面所述的图像输出装置所进行的处理,根据针对所输出的合成图像的受众评价的反馈,来修正所述合成图像的合成图像权重值,进而调整所述合成图像的序列。
40.根据本发明的第十三方面-第二十三方面,通过设置图像处理装置、图像合成装置、图像标签生成装置、图像整理装置、图像输出装置和图像修正装置,能够生成基于用户喜好的合成图像。
41.本发明的第二十四方面为提供一种图像处理系统,包括图像处理模块、图像合成模块、图像标签生成模块、图像整理模块、图像输出模块和图像修正模块,在所述图像处理模块中,在第一场景中获取第一原始图像,所述第一原始图像中包含第一对象,提取所述第一对象的第一关键点信息,并对所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值;在第一场景外的第二场景中获取第二原始图像,所述第二原始图像中包含第二对象,提取所述第二对象的第二关键点信息,并对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值;基于所述第一原始图像的所述权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重值;在所述图像合成模块中,将所述第一原始图像和所述第二原始图像合成为合成图像,其中所述合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像,基于所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值;在所述图像标签生成模块中,基于所述第一关键点信息生成对应于所述第一原始图像的第一标签,基于所述第二关键点信息生成对应于所述第二原始图像的第二标签,基于所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签;在所述图像整理模块中,基于所述合成图像标签将所述合成图像归类,基于被归类的所述合成图像的合成图像权重值生成所述合成图像的序列;在所述
图像输出模块中,从所述合成图像的序列中选择并输出合成图像;在所述图像修正模块中,基于针对所输出的合成图像的受众评价的反馈,来修正所述合成图像的合成图像权重值,进而调整所述合成图像的序列。
42.根据本发明的第二十四方面,通过设置图像处理系统,能够生成基于用户喜好的合成图像。
43.本发明的第二十五方面为提供一种电子设备,所述电子设备包括:存储器,用于存储可执行指令;处理器,用于运行所述存储器存储的可执行指令时,实现本发明的第一方面至第七方面中任一项所述的图像处理方法,或者实现本发明的第八方面所述的图像合成方法,或者实现本发明的第九方面所述的图像标签生成方法,或者实现本发明的第十方面所述的图像整理方法,或者实现本发明的第十一方面所述的图像输出方法,或者实现本发明的第十二方面所述的图像修正方法。本发明的第二十六方面为,所述电子设备还包括显示器,所述显示器被划分为多个显示区域,分别用于显示第一原始图像、第二原始图像和合成图像。根据本发明的第二十五、二十六方面,通过设置电子设备,以及电子设备的显示器来显示第一原始图像、第二原始图像和合成图像,能够方便的进行基于用户喜好的合成图像的生成。
44.本发明的第二十七方面为一种计算机可读存储介质,存储有可执行程序,其特征在于,所述可执行程序被处理器执行时实现本发明的第一方面至第七方面中任一项所述的图像处理方法,或者实现本发明的第八方面所述的图像合成方法,或者实现本发明的第九方面所述的图像标签生成方法,或者实现本发明的第十方面所述的图像整理方法,或者实现本发明的第十一方面所述的图像输出方法,或者实现本发明的第十二方面所述的图像修正方法。
45.根据本发明的第二十七方面,通过设置存储有可执行程序的计算机可读存储介质,能够生成基于用户喜好的合成图像。
46.通过参照附图对以下实施方式所做的说明,上述的目的、特征及优点应易于被理解。
附图说明
47.图1是包括图像处理装置、图像合成装置、图像标签生成装置、图像整理装置、图像输出装置和图像修正装置的图像关联处理装置的结构框图。图2是表示图像处理装置的结构的框图。图3是包括图像处理步骤、图像合成步骤、图像标签生成步骤、图像整理步骤、图像输出步骤和图像修正步骤的图像关联处理方法的流程图。图4是图3中图像处理步骤的流程图。图5是图3中图像合成步骤的流程图。图6是图3中图像标签生成步骤的流程图。图7是图3中图像整理步骤的流程图。图8是图3中图像输出步骤的流程图。图9是图3中图像修正步骤的流程图。
图10是包括图像处理模块、图像合成模块、图像标签生成模块、图像整理模块、图像输出模块和图像修正模块的图像关联处理系统的结构框图。图11是表示合成图像的一例。图12是表示合成图像的另一例。
具体实施方式
48.下面,列举优选的实施方式,参照附图详细说明本发明所涉及的图像处理方法及其装置、系统、电子设备和计算机可读存储介质。
49.图1是包括图像处理装置、图像合成装置、图像标签生成装置、图像整理装置、图像输出装置和图像修正装置的图像关联处理装置1的结构框图。其中,结构框图中的箭头表示了处理后图像的输出流向,各装置的构成、功能可以由下面的说明明确。
50.[图像处理装置10]如图2所示,本技术的图像处理装置10包括:第一图像获取单元11,其在第一场景中获取第一原始图像,所述第一原始图像中包含第一对象;第一关键点信息提取单元12,其提取所述第一对象的第一关键点信息;和第一图像权重设定单元13,其对所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值。
[0051]
如图2所示,图像处理装置10还包括:第二图像获取单元14,其在第一场景外的第二场景中获取第二原始图像,所述第二原始图像中包含第二对象;第二关键点信息提取单元15,其提取所述第二对象的第二关键点信息;和第二图像权重设定单元16,其对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值。
[0052]
所述图像处理装置10基于所述第一原始图像的所述第一权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重值。
[0053]
所述第二原始图像为与所述第一原始图像同时获取或基于所述第一原始图像中的所述第一关键点信息获取的图像。
[0054]
所述第一原始图像是情感图像,所述第一关键点信息包括人脸图像、人的姿态和语音信息中的一种或多种,当所述第一关键点信息提取单元12提取所述人脸图像的表情信息时对所述表情信息进行分类,所述第一图像权重设定单元13按表情类别设定第一权重值,当所述第一关键点信息提取单元12提取所述人的姿态的姿态信息时对所述姿态进行分类,所述第一图像权重设定单元13按姿态类别设定第一权重值,当所述第一关键点信息提取单元12提取所述语音信息中的关键词时对所述关键词进行分类,所述第一图像权重设定单元13按关键词类别设定第一权重值。
[0055]
所述第一图像权重设定单元13取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值。
[0056]
或者,在所述第一关键点信息中,当所述人脸图像的表情信息、所述人的姿态与所述关键词中的至少两者以上存在一致性时,所述第一图像权重设定单元13增大该存在一致性的所述第一关键点信息的第一权重值。
[0057]
所述第二原始图像是情景图像,所述情景图像包括人文图像、景色图像和场景图像,
[0058]
所述第二关键点信息提取单元15提取所述情景图像的特征作为所述第二关键点
信息。
[0059]
[图像合成装置20]本技术的图像合成装置20在上述图像处理装置10执行的处理的基础上执行以下处理。
[0060]
图像合成装置20基于上述的图像处理装置10所进行的处理,将所述第一原始图像和所述第二原始图像合成为合成图像,其中所述合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像;并且按照所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值。
[0061]
[图像标签生成装置30]本技术的图像标签生成装置30在上述图像合成装置20执行的处理的基础上执行以下处理。
[0062]
图像标签生成装置30基于上述的图像合成装置20所进行的处理,按照所述第一关键点信息生成对应于所述第一原始图像的第一标签;按照所述第二关键点信息生成对应于所述第二原始图像的第二标签;按照所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签。
[0063]
具体而言,例如,在获取到情感图像中的关键点信息和情景图像中的关键点信息后,图像标签生成装置30按照预设的分类模型,确定情感的关键点信息对应的情感标签、情景的关键点信息对应的情景标签。其中,为了减轻gpu(graphics processing unit,图形处理器)负担,本实施例中可以采用基于cpu(central processing unit,中央处理器)的分类算法,如softmax分类算法、xgboost分类器、随机森林等分类算法。
[0064]
需要说明的是,由于情感标签和情景标签所属的属性不同,因此分别使用不同的分类模型进行分类识别,能够提高其精度,而且分类数量越少,分类器过度拟合的可能性会降低,从而提高分类的精度。
[0065]
以情景标签为例,采用上述分类算法中的任意一种构建一个分类器,该分类器以情景作为输入,情景标签作为输出。其中,情景标签可以有大海、高山、人群等。使用训练视频(图像)训练该分类器,确定模型参数。其中,可以通过模拟多种用户使用场景来采集车外视频并根据车外视频获取训练视频。此外,情景标签可以具有与图像内容对应的时间标签、内容标签和地理位置标签等,例如,2020年1月1日、人物、风景、动物、北京、上海等。
[0066]
对于情感标签来说,单独构建另外的分类器,该分类器的输入视频为情感特征,输出视频为情感标签。其中,情感标签有开心、兴奋、沮丧、悲伤、无聊、发呆等代表用户当前情感状态的信息。该分类器的训练方式与情景标签的第一分类器的训练方式相同。此外,情感标签也可以具有与图像内容对应的时间标签、内容标签和地理位置标签等,例如,2020年1月1日、开心、兴奋、沮丧、悲伤、无聊、发呆、北京、上海等。
[0067]
[图像整理装置40]本技术的图像整理装置40在上述图像标签生成装置30执行的处理的基础上执行以下处理。
[0068]
图像整理装置40基于上述图像标签生成装置30所进行的处理,按照所述合成图像标签将所述合成图像归类;并按照被归类的所述合成图像的合成图像权重值生成所述合成
图像的序列。这里,合成图像的标签可以是情感标签和情景标签的合集,合成图像的归类可以是属于情感标签或情景标签的类别,也可以是即属于情感标签又属于情景标签。
[0069]
[图像输出装置50]本技术的上述图像输出装置50在上述图像整理装置40执行的处理的基础上执行以下处理。
[0070]
图像输出装置50基于上述图像整理装置40所进行的处理,从所述合成图像的序列中选择并输出合成图像。
[0071]
本发明的上述图像处理装置、图像合成装置、图像标签生成装置、图像整理装置、图像输出装置中对于图像的处理以及由它们构成的图像关联处理装置的处理可在云端进行。
[0072]
[图像修正装置60]本技术的图像修正装置60在上述图像输出装置50执行的处理的基础上执行以下处理。
[0073]
图像修正装置60基于上述的图像输出装置50,按照针对所输出的合成图像的受众评价的反馈,来修正所述合成图像的合成图像权重值,进而调整所述合成图像的序列。
[0074]
本发明的图像修正装置可设置在后述的用户终端上的app上。
[0075]
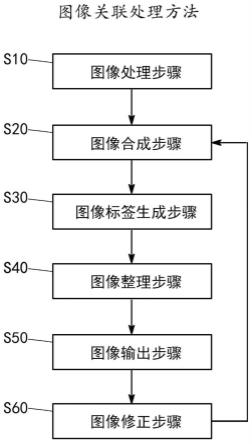
本技术还披露一种图像关联处理方法,图3是包括图像处理步骤、图像合成步骤、图像标签生成步骤、图像整理步骤、图像输出步骤和图像修正步骤的图像关联处理方法的流程图。
[0076]
如图3所示,图像关联处理方法包括图像处理步骤s10、图像合成步骤s20、图像标签生成步骤s30、图像整理步骤s40、图像输出步骤s50和图像修正步骤s60。以下对所述步骤分述如下。
[0077]
如图4所述,图像处理步骤s10由上述的图像处理装置10来执行。该图像处理步骤包括:步骤s101:通过第一图像获取单元11在第一场景中获取第一原始图像;步骤s102:通过第一关键点信息提取单元12提取所获取的第一原始图像中的第一对象的第一关键点信息;步骤s103:通过第一图像权重设定单元13对提取到的所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值;步骤s104:通过第二图像获取单元14在第一场景外的第二场景中获取第二原始图像;步骤s105:通过第二关键点信息提取单元15提取所获取的第二原始图像中的第二对象的第二关键点信息;步骤s106:通过第二图像权重设定单元16对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值;以及步骤s107:基于所述第一原始图像的所述第一权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重值。
[0078]
图5是图3中图像合成步骤s20的流程图。图像合成步骤基于上述的图像处理步骤s10的输出,由图像合成装置20来执行。
[0079]
在该图像合成步骤中包括:步骤s201:将在步骤s101和步骤s104中获取到的第一原始图像和第二原始图像合成为合成图像,该合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像;步骤s202:基于所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值。
[0080]
图6是图3中图像标签生成步骤s30的流程图。该图像标签生成步骤基于上述的图像合成步骤s20的输出,并由图像标签生成装置30来执行。
[0081]
在该图像标签生成步骤s30中包括:步骤s301:基于所述第一关键点信息生成对应于所述第一原始图像的第一标签;步骤s302:基于所述第二关键点信息生成对应于所述第二原始图像的第二标签;步骤s303:基于所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签。其中,标签的生成方法在前述的相应装置的描述中已经详述,再次不再赘述。这里,合成图像的标签可以是情感标签和情景标签的合集,合成图像的归类可以是属于情感标签或情景标签的类别,也可以是即属于情感标签又属于情景标签。
[0082]
图7是图3中图像整理步骤s40的流程图。该步骤基于上述的图像标签生成步骤s30的输出,由图像整理装置40来执行。
[0083]
在该图像整理步骤中包括:步骤s401:基于所述合成图像标签将所述合成图像归类;步骤s402:基于被归类的所述合成图像的合成图像权重值生成所述合成图像的序列。
[0084]
图8是图3中图像输出步骤s50的流程图。该图像输出步骤s50基于上述的图像整理步骤s40的输出,由图像输出装置50来执行。在该图像输出步骤中包括:步骤s501:从所述合成图像的序列中选择图像;步骤s502:输出所述选择图像。
[0085]
图9是图3中图像修正步骤s60的流程图。该图像修正步骤s60基于图像输出步骤s50的输出,由图像修正装置60来执行。
[0086]
该图像修正步骤s60包括:步骤s601:基于针对所输出的合成图像的反馈,修正合成图像的合成图像权重值;步骤s602:调整合成图像序列。
[0087]
上述步骤s101-步骤501中对于图像的处理可在云端上进行。
[0088]
上述步骤s601可在后述的用户终端上的app上进行。
[0089]
在步骤s101中,在第一场景中获取第一原始图像。第一场景可以为车辆内、船内、飞机内、房间内等,而第一原始图像为车辆内、船内、飞机内、房间内等的与人有关的图像。
[0090]
在步骤s104中,在第一场景外的第二场景中获取第二原始图像。与上述第一场景相对应,第二场景可以为车辆外、船外、飞机外、房间外等,而第二原始图像为车辆外、船外、飞机外、房间外等的情景图像,包括人文图像、景色图像和场景图像等。第二原始图像的获得与步骤s101中第一原始图像的获得同时进行,或者基于第一原始图像中的第一关键点信
息获取第二原始图像。
[0091]
在步骤s102中,提取所获取的第一原始图像中的第一对象的第一关键点信息,所述第一关键点信息包括人脸图像、人的姿态和语音信息中的一种或多种。当第一关键点信息为人脸图像时,提取所述人脸图像的表情信息;当第一关键点信息为人的姿态时,提取所述人的姿态的姿态信息;当第一关键点信息为语音信息时,提取所述语音信息中的关键词。
[0092]
在步骤s103中,对提取到的所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值。当在步骤s102中提取到人脸图像的表情信息时,对表情信息进行分类,并按表情类别设定第一权重值;当在步骤s102中提取到人的姿态的姿态信息时,对姿态进行分类,并按姿态类别设定第一权重值;当在步骤s102中提取到语音信息中的关键词时,对关键词进行分类,并按关键词类别设定第一权重值。并且取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值。或者,在所述第一关键点信息中,当所述人脸图像的表情信息、所述人的姿态与所述关键词中的至少两者以上存在一致性时,增大该存在一致性的所述第一关键点信息的第一权重值。
[0093]
在步骤s105中,提取所获取的第二原始图像中的第二对象的第二关键点信息。所述第二原始图像是情景图像,所述情景图像包括人文图像、景色图像和场景图像,提取所述情景图像的特征作为所述第二关键点信息。
[0094]
在步骤s106中,对在步骤s105中提取到的第二关键点信息设置权重值,来作为第二原始图像的第二权重值。
[0095]
在步骤s107中,基于在步骤s103中获得的第一原始图像的第一权重值使所述第二原始图像的第二权重值增大,即,使在步骤s106中设定的第二原始图像的第二权重值增加,而使所述第二原始图像具有叠加权重的叠加权重值。
[0096]
通过对第二原始图像设置第二权重值,并且基于所述第一原始图像的所述第一权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重的叠加权重值,能够将用户喜爱的图像排在优先选择的位置,从而能够使用户得到想要的图像。
[0097]
下面对上述装置并结合上述方法举例进行说明。
[0098]
首先,第一场景与第二场景为不同区域但彼此相互关联的场景。例如第一场景可以为车辆内、船内、飞机内、房间内等,与上述第一场景相对应,第二场景可以为车辆外、船外、飞机外、房间外等,而第一原始图像则为车辆内、船内、飞机内、房间内等的与人有关的图像,第二原始图像为车辆外、船外、飞机外、房间外等的情景图像,包括人文图像、景色图像和场景图像等,其中,人文图像为与人们的文化活动有关的图像,例如文化庙会等,景色图像为与景色有关图像,例如大海、高山等,场景图像为与社会活动有关的景象,例如人群的聚集等。
[0099]
下面,主要以第一场景为车辆的车辆内的场景,而第二场景为车辆的车辆外的场景为例对上述图像处理装置10进行说明。
[0100]
车辆可以是各种类型的车辆,例如,小汽车、货车、卡车、巴士等,该车辆可以是普通车辆,也可以是自动驾驶车辆、智能网联汽车等。在车辆内上设置有第一图像获取单元11。该第一图像获取单元11包括第一图像输入装置、语音输入装置。
[0101]
第一图像输入装置为设置在车辆的车厢内的1个或多个摄像头,拍摄乘员的脸部。摄像头也可以为红外线摄像头。在设置有1个摄像头的情况下,摄像头被配置在能够拍摄位
于车厢内的所有的乘员的脸的位置,例如,后视镜的附近。在设置有多个摄像头的情况下,摄像头被设置于每个座席。
[0102]
此外,第一图像输入装置还拍摄车内乘员的姿态(包括脸的移动、身体的倾斜、以及视线的转移等)。
[0103]
语音输入装置被设置在车厢内,该车内语音输入装置包括麦克风等语音组件,语音组件可以设置多个,并设置在车内乘员均能够清晰录入语音的位置,例如被设置在车内的仪表板或顶板上,也可以被设置于每个座席。
[0104]
在上述结构中将车内摄像头和语音组件分开设置,但不局限于此,也可以将车内摄像头和语音组件设置为一体。这样能够使车内视频获取装置简单化,且节省空间。
[0105]
另外,在车辆外设置有第二图像获取单元14。该第二图像获取单元14包括第二图像输入装置。第二图像输入装置为一个以上的摄像头,例如为设置在车外的四角以及车顶的多个摄像头。设置在车辆前侧两个角部的摄像头对车辆行驶方向前方的情景进行拍摄,设置在车辆后侧两个角部的摄像头对车辆行驶方向后方的情景进行拍摄,而设置在车顶的摄像头为立体拍摄摄像头,可以对在俯视时整个车辆平面的360
°
角度进行拍摄,而且还可以对天空进行拍摄。
[0106]
在步骤s101中,图像处理装置10通过第一图像获取单元11在车辆的车厢内获取车厢内图像作为第一原始图像。车厢内图像包括通过摄像头拍摄到的作为第一对象的车内乘员的人脸图像信息和人的姿态,还包括通过语音组件录入的语音信息。
[0107]
在执行步骤s101的同时,也执行步骤s104,在步骤s104中,图像处理装置10通过第二图像获取单元14使车外摄像头拍摄车厢外情景而获取车辆外图像信息作为第二原始图像。
[0108]
例如,当车辆在海边行驶时,开启车辆内外同时拍摄开关,此时,车内摄像头开启来对车内人的脸部表情、人的姿态以及视线的移动进行拍摄而形成人物图像,麦克风开启来输入车内人所谈论的内容而形成语音,同时车外摄像头开启来对车外大海的情景进行拍摄而形成景色图像,当驾驶员及同乘人员侧身或使视线转向一方侧注目到窗外的美景并表现出喜悦的表情,同时纷纷发出“夕阳下的大海好美呀”的赞叹时,车辆内摄像头获取到驾驶员及同乘人员侧身或使视线转向一方侧的姿态、所表现出喜悦的表情,以及通过麦克风获取到“夕阳下的大海好美呀”的语音,与此同时,通过车外摄像头获取到车窗外大海与夕阳的景色。此外,该车辆内外同时拍摄开关可以通过乘员的操作打开,也可以通过设定触发条件,例如提示音、提示手势、提示姿态、车辆所处的位置等来触发车辆内外同时拍摄开关启动,在通过触发条件启动车辆内外同时拍摄开关时,可先通过车辆系统给出拍摄确认指示并由乘员给出同意拍摄的反馈后开启车辆内外同时拍摄开关来进行拍摄。其中,以车辆所处的位置为触发条件是指,事先将用户喜欢的位置记录在系统中并由gps定位到车辆已行驶到该位置为触发条件。
[0109]
接着,在步骤s102中,通过第一关键点信息提取单元12提取在步骤s101中获取到的车厢内图像中的车内乘员的人脸图像即喜悦的表情、人的姿态即身体及视线朝向一方侧和语音信息中表示评价的语音信息中的一种或多种,并在步骤s105中,通过第二关键点信息提取单元15提取所获取的第二原始图像即车窗外美景中的第二对象即大海、夕阳的第二关键点信息即大海、夕阳。
[0110]
其中,在关键点信息的提取过程中可以通过过滤法、包装法、集成法等方法来进行。
[0111]
过滤法是指对提取到的关键点信息进行过滤,以删除冗余的特征视频。
[0112]
包装法用于对提取到的关键点信息进行筛选。
[0113]
集成法是指将多种关键点信息提取方法集成到一起,以构建一种更加高效、更加准确的关键点信息提取方法,用于提取关键点信息。
[0114]
在第一关键点信息中的人脸图像所表现出的情感特征的提取可以采用如下方式来进行。
[0115]
采用基于人脸关键点区域传统生物特征和人脸全局深度特征融合的表情识别方法,使用传统的局部二值模式特征、局部方向数特征等与深度神经网络特征分别训练人脸表情分类器,利用这些分类器投票,进行人脸识别。
[0116]
通过预先训练好的cnn(convolutional neuralnetworks,卷积神经网络)深度提取图像特征,作为情感特征。通过收集大量的表情数据训练深度神经网络提取低维的全局深度特征,并结合使用高维的关键点周围局部区域传统生物特征,进行多特征融合分类识别。该cnn模型可以设置多个卷积部和池化部,不设置全连接部,其输入视频为人脸图像,最后一个卷积部或者池化部的输出的视频作为模型的输出视频,其中,输出视频为脸部图像特征。通过网络收集非公开的人脸表情数据,将表情数据分为高兴、惊讶、悲伤、生气、厌恶、恐惧和中性等多种表情,使用dilb库中人脸关键点检测算法对人脸表情数据进行人脸关键点检测,每张人脸得到多个人脸关键点,利用该多个人脸关键点获取人脸区域,将人脸区域校准归一化为固定大小,利用关键点位置获取传统表情特征,所述传统表情特征包括人脸眉毛、眼睛、鼻子和嘴巴特征。人脸表情特征提取采用局部二值模式lbp特征、局部方向数ldn特征和曲波特征。根据所获得的人脸区域,训练一个深度神经网络来获取深度学习特征,所述深度学习特征是指把表情图像输入到训练好的神经网络,得到的卷积层或者全连接层的向量值。在识别技术中,使用该相量值作为图像的深度特征向量。在输入表情的3种传统特征和1种深度特征,都能得到一个分类结果,获取车内人的情感特征。
[0117]
此外,在第一关键点信息中的语音信息中的关键词的提取可以采用如下方式来进行。
[0118]
方式一:通过语音组件采集语音文件;根据音频特征提取算法将所述语音视频转换为频谱图;根据预设的自编码卷积神经网络和所述频谱图,生成所述语音视频的语义特征向量,将所述语义特征向量作为所述情感特征。其中,音频特征提取算法可以是mfcc(mel frequency cepstrum coefficient,梅尔频率倒谱系数)算法或者fft(fast fourier transformation,快速傅里叶变换)算法,通过音频特征提取算法将语音视频转换为频谱图,将频谱图作为自编码卷积神经网络的输入视频和输出视频,从网络中提取语义特征向量。与上述自编码循环神经网路类似,自编码卷积神经网络也是一种自编码器,其中,自编码卷积神经网络是使用卷积部构建自编码器,通过训练这种自编码器的输出视频与输入视频一致,以获取其中间隐藏部中有价值的信息。
[0119]
方式二:此外还可以将语音转化为文字进行存储,即通过对获取的语音进行预处理,获得与所述语音对应的语音特征,将所述语音特征存入数据库模型库中,并进行匹配处理,获得语音信号,将所述语音信号基于预设语言模型进行处理,确定与所述语音信号对应
的语音序列,基于预设声建模型对所述语音序列进行解码处理,获得与所述语音序列对应的文字信息。
[0120]
此外,在第一关键点信息中的人的姿态的提取可以采用如下方式来进行。
[0121]
在通过车辆内摄像头获取到车内车内乘员的图像后,将该图像传输至人体姿态识别模型中进行识别,并使所述人体姿态识别模型输出姿态动作识别结果,其中,所述人体姿态识别模型是基于神经网络构建的识别模型,用于识别输入图像中的人体姿态特征。在所述人体姿态识别模型对输入图像进行识别之前,还包括:对所述人体姿态识别模型进行训练;具体的训练过程为:获取训练样本并将所述训练样本传输至所述人体姿态识别模型中,对神经网络进行调整直到所述人体姿态识别模型训练完成。
[0122]
具体地,在构建上述人体姿态识别模型后,需要对网络架构进行训练。该步骤主要通过大量的样本输出至神经网络,对整个深度神经网络进行微调,使之达到能够快速识别车辆行驶过程中人体姿态的动作特征。此外,可以对预先建立的人体姿态识别模型进行模型训练及数据更新,若允许系统联网,则系统将更新服务器数据,服务器数据为该系统进行大量样件进行深度学习后的数据;更新该数据有利于系统更为准确识别动作,以及识别更多的动作;其中,获取的数据为人体姿态进行大量动作学习后的数据,更新该数据有利于系统更为精准的识别人体动作及姿态,以及识别更多的动作。例如,将姿态动作识别结果中的身体、脸部及视线朝向一方侧的人体姿态特征与所述人体姿态识别模型中的身体、脸部及视线的动作特征进行相似度对比,当相似度达到预设值时,确定所述姿态动作识别结果中的人体姿态特征为想要的特征,并作为第一关键点信息。此外,例如,也可以将姿态动作识别结果中的身体、脸部及视线朝向一方侧的人体姿态特征的持续时间或动作频率与所述人体姿态识别模型中的预设值比较,当达到该预设值时,确定所述姿态动作识别结果中的人体姿态特征为想要的特征,并作为第一关键点信息。
[0123]
在第二关键点信息中的情景图像的提取可以采用下述方式来进行。
[0124]
将车外情景图像拆解为图像特征、音频特征以及文本特征三部分,将所述车外情景图像的图像特征、音频特征和文本特征输入至已训练完成的预测模型中,利用门控语境算法对各个特征之间的相关性进行计算,再基于相关性的计算结果对输出所述车外情景图像中的各个特征的权重进行调整。增大相关性较强的特征的权重,降低相关性较弱的特征的权重。如果车外情景图像属于无声视频,则不提取音频特征。通过采用方向梯度直方图算法、线性预测分析算法以及词频-逆向文档频率算法分别对车外情景图像中的图像、音频、文本进行特征提取、获得特征提取结果。这样特征分析更精准,对车外情景图像的概括度也更高。例如当车外场景内容为:有禁捕标识牌的、夕阳下轻拍海岸的大海,海面上有很多的海鸥在飞翔和鸣叫。关键点信息可以提取为:“有海鸥、夕阳、轻拍海岸的声音的大海、处于禁捕期的大海”等。
[0125]
在完成上述对关键点信息的提取后,在步骤s103中,通过第一图像权重设定单元13对提取到的第一关键点信息即人脸图像的表情、人的姿态中身体及视线的朝向和语音信息中表示评价的语音信息分别设置第一权重值,在人脸图像的表情、人的姿态中身体及视线的朝向和语音信息中表示评价的语音信息这三者之间存在一致性,即车内乘员的所有举动均表明在车辆外出现了使其喜爱或厌恶的场景时,在步骤s103中,增大该存在一致性的第一关键点信息即人脸图像、人的姿态和语音信息的第一权重值。而如果人脸图像的表情、
人的姿态中身体及视线的朝向和语音信息这三者中任意两者之间不存在一致性时,在步骤s103中,第一图像权重设定单元13取得表情信息、人的姿态和关键词中至少二者的第一权重值的平均值作为第一关键点信息的第一权重值。该作为平均值的第一权重值小于上述由于存在一致性而增大的第一权重值。
[0126]
在对人脸图像的第一权重值进行设定时,可根据人脸的面部表情的上述表情数据来设置第一权重值,例如按照厌恶、不屑、淡然、微笑、惊喜、
…
来对人脸图像设置第一权重值-2、-1、0、1、2、
…
,在对人的姿态的第一权重值进行设定时,可根据人的姿态例如,一直没有朝向一侧的任何动作、身体朝向一侧看了一下之后回到正常姿势而不再向一侧看、身体朝向一侧看了一下之后回到正常姿势而后又向一侧看了一次、身体朝向一侧看了规定时间(例如一分钟)、身体朝向一侧超出了规定时间或身体朝向一侧的次数在规定时间(例如一分钟)内超过规定次数(例如6次)、
…
来对人的姿态设置第一权重值-2、-1、0、1、2、
…
,在对语音信息的第一权重值进行设定时,可根据语音信息中语义的评价程度例如很差、不好、一般、好、很好、
…
,来对语音信息设置第一权重值-2、-1、0、1、2、
…
。
[0127]
例如,当人的面部表情为不屑,则人脸图像的第一权重值设为-1,当人的身体朝向一侧超出了规定时间或身体朝向一侧的次数在规定时间内超过规定次数,则人的姿态的第一权重值设为2,当语音信息中的评价程度为好时,则语音信息的第一权重值设为1,若上述三者同时发生,则说明人脸图像的表情、人的姿态和语音信息这三者之间不存在一致性,此时可以取两者的权重值的平均值,例如人的姿态、语音信息的第一权重值的平均值为(1+2)/2=1.5,或者取三者的平均值为(-1+1+2)/3=0.67,此时第一关键点信息的权重值为1.5或0.67。当人的面部表情为惊喜,则人脸图像的第一权重值设为2,当人的身体朝向一侧超出了规定时间或身体朝向一侧的次数在规定时间内超过规定次数,则人的姿态的第一权重值设为2,当语音信息中的评价程度为很好时,则语音信息的第一权重值设为2,若上述三者同时发生,说明人脸图像的表情、人的姿态和语音信息这三者之间存在一致性,那么增大第一关键点信息的权重值,例如将三者的平均值乘以一个系数例如3,即(2+2+2)/3*3=6,此时增大后的第一关键点信息的权重值为6。
[0128]
上述例子是以一个乘员为例进行的说明,当车内为多个乘员时,可分别计算每个乘员的第一关键点信息的权重值,然后取多个乘员的第一关键点信息的平均值。
[0129]
在执行步骤s103的同时也执行步骤s106。
[0130]
在步骤s106中,第二图像权重设定单元16对第二关键点信息设置第二权重值,将该权重值作为第二原始图像的第二权重值。
[0131]
第二权重值的设定可以基于第二关键点信息中关键点信息的内容及数量来进行设定。关键点信息的内容是指,大众喜欢的场景例如大海、沙滩、星空等公认美丽的场景、或者大众讨厌的场景例如污水、垃圾、破败场景等公认让人厌恶的场景、或者对于大众而言无感的场景例如毫无特点的街道、树木等,当关键点信息的内容为大海、沙滩、星空等大众喜欢的场景时,对大海、沙滩、星空等分别设置一个正数值例如2;当关键点信息的内容为污水、垃圾、破败场景大众厌恶的场景时,对污水、垃圾、破败场景等分别设置一个负数值例如-2;当关键点信息的内容为毫无特点的街道、树木等对于大众而言无感的场景时,对该街道、树木等分别设置一个值例如0。关键点信息的数量是指,在第二原始图像中包含多个关
键点信息,例如在大海的场景中包含大海、沙滩、帆船、夕阳,此时,对每个关键点信息设置权重值,该各关键点信息的权重值的总和或平均值即为第二原始图像的第二权重值,在以下的说明中以各关键点信息的权重值的总和作为第二原始图像的第二权重值为例进行说明。
[0132]
上述第二权重值的设定按照大众的嗜好来进行,该大众的嗜好可根据针对包含第二原始图像的后述合成图像的、来自传播媒介受众评价的反馈来获得,而对于乘员而言,也可以将乘员的嗜好提前存储在车载系统或云处理单元中,由此根据该提前设定的乘员的嗜好来设定第二权重值。
[0133]
在通过乘员的嗜好来设定第二权重值时,可以在车厢内设置乘员识别单元,摄像头拍摄乘员的脸部,并将获取到的图像信息输出给乘员识别单元。
[0134]
乘员识别单元包括具有处理器的运算装置、存储装置、通信接口等。处理器执行一般的脸部识别算法,来识别乘员。存储装置将乘员的脸的图像信息与其乘员的个人信息(个人的识别信息)建立关联并存储在数据库中。乘员识别单元根据由摄像头获取的脸部图像信息和数据库的信息来识别乘员。乘员的个人信息包括乘员的嗜好等。
[0135]
接着,在步骤s107中,基于第一原始图像的第一权重值使第二原始图像的第二权重值增大,而使第二原始图像具有叠加权重值。当第一关键点信息即人脸图像的表情、人的姿态和语音信息中表示评价的语音信息所表现的行为存在一致性且乘员的语音信息中的关键词“夕阳”、“大海”,与第二原始图像中的图像信息存在一致性时,将上述因人脸图像的表情、人的姿态和语音信息中表示评价的语音信息的一致性设置系数3,使第二原始图像中的关键点信息“夕阳”、“大海”的各自的第二权重值的总和为4的第二原始图形的权重值增大为例如将第二权重值4乘以系数3,从而使第二原始图像的叠加权重值为12。
[0136]
增大第二权重值除了正向增大第二权重值之外,还包括反向增大第二权重值,第二原始图像的序列的优先顺序按照第二权重值从大到小的顺序排列,即,正向第二权重值越大在序列中的排序越靠前,从而越容易被用户搜索到并被选择,而反向第二权重值越大(数值越小)在序列中的排序越靠后,从而越不容易被用户搜索到。该反向第二权重值是因为在第一权重值中出现负数例如厌恶的表情、一直没有朝向一侧的任何动作的姿态、评价程度为很差的语音信息的情况下获得的。
[0137]
该增大第二权重值的方法可以是第二权重值加上或乘以第一权重值,或使得第二权重值乘以对应于第一权重值的系数等。第一权重值所对应的系数例如当人脸图像的表情、人的姿态和语音信息中表示评价的语音信息这三者实质上一致时,设为3,当其中两者一致时,设为2,当三者均不一致时,设为1。
[0138]
接着,在步骤s201中,通过图像合成装置将在步骤s101和步骤s104中由第一图像获取单元11获取到的第一原始图像和由第二图像获取单元14获取到的第二原始图像合成为合成图像,该合成图像为将第一原始图像的局部或全部与第二原始图像的局部或全部合成在一起的图像。例如该合成图像可以包括车辆内图像中人脸图像中喜悦的表情、人的姿态中身体及视线朝向一方侧和语音信息中表示评价的语音信息所表现出的所有的行为、以及车辆外图像中包括“夕阳”、“大海”“海鸥”的情景图像,而将“处于禁捕期的大海”这样的标识从图像中删除。
[0139]
此外,该合成图像可以是第一原始图像与第二原始图像彼此各自独立地显示在一
起的合成图像(参照图9),也可以是将第一原始图像与第二原始图像融合在一起的合成图像(参照图10)。
[0140]
接着,在步骤s202中,将第一原始图像中人脸图像、人的姿态和语音信息所对应的第一权重值与第二原始图像中的“夕阳”、“大海”、“海鸥”所对应的第二权重值例如相加而形成合成图像的合成图像权重值。
[0141]
例如在上述实施例中,人脸图像的表情、人的姿态和语音信息这三者之间存在一致性的第一原始图像的权重值为6,而第二原始图像的叠加后的叠加权重值为12,那么两者的合成图像的合成图像权重值则为6+12=18。
[0142]
此外,还通过图像标签生成装置对第一原始图像和第二原始图像执行以下的处理。
[0143]
在步骤s301中,基于第一关键点信息即人脸图像中喜悦的表情、人的姿态中身体及视线朝向一方侧和语音信息中表示评价的语音信息,生成对应于第一原始图像的第一标签“喜悦”。
[0144]
在执行步骤s301的同时,在步骤s302中,基于第二关键点信息即“夕阳”、“大海”“海鸥”,生成对应于第二原始图像的第二标签“大海”。
[0145]
接着,在步骤s303中,基于第一标签“喜悦”和第二标签“大海”,生成对应于合成图像的合成图像标签“心目中的大海”、或简单生成为“喜悦、大海”。
[0146]
接着,在步骤s401中,图像整理装置基于合成图像标签“心目中的大海”,将该合成图像归类到景色图像,更细分可以归类到大海。
[0147]
接着,在步骤s402中,基于被归类的合成图像的合成图像权重值生成合成图像的序列。该合成图像的序列可以按照时间排序,例如当该合成图像为大海时,该合成图像的序列可以按照该大海在一天的不同时段(清晨、上午、中午、下午、晚上等)中合成图像权重值的高低顺序排序,或者在一年的不同时期(1月、3月、5月、7月、9月等)中合成图像权重值的高低顺序排序;该合成图像的序列也可以按照地点排序,以大海为例,该合成图像的序列可以按照该大海在不同地点(大连、海南、日本镰仓等)的合成图像权重值的高低顺序排序,该不同地点的大海的场景可以是在同一时间发生的场景,也可以是在不同时间发生的场景;该合成图像的序列也可以按照情景排序,以大海为例,只要是与大海有关的图像均可按照情景排序,该大海的图像可以是现实中的图像,也可以是虚拟的图像(例如来自影视作品等),该大海的图像按照合成图像权重值的高低顺序排序。此外,合成图像的序列的长度可以由用户设定,例如为10个合成图像的排列长度。
[0148]
接着,在步骤s501中,图像输出装置从多个合成图像的序列中选择合成图像序列中排在最前的合成图像(权重最大的图像),并在步骤s502输出该合成图像。例如,当用户输入“心目中的大海”时,上述实施例中的合成图像能够被用户优先得到。在用户得到想要的该合成图像后,对该合成图像进行手动编辑或通过应用程序所自带的自动编辑功能进行自动编辑,并将编辑好的合成图像上传给传播媒介例如抖音等。
[0149]
接着,在步骤s601中,图像修正装置基于传播媒介中对于所上传视频的点击率或受赞程度及受众评价的反馈来修正合成图像的合成图像权重值,在步骤s602中合成图像的序列被调整。例如,对点击率较高、受赞程度较高的高反馈受众评价的合成图像的权重值增加权重值,由此使该高反馈受众评价的合成图像在图像的排队序列中排在更优先的位置。
如此反复进行,能够不断优化合成图像的合成质量,从而能够获得贴合用户的嗜好的合成图像。
[0150]
上述例子是以第二原始图像为景色图像为例进行的说明。下面也以人文图像和场景图像为例进行说明。对作为第二原始图像的人文图像和场景图像的处理,与上述对景色图像的处理实质上相同。
[0151]
当第二原始图像为人文图像例如文化庙会时,在步骤s105中,通过第二关键点信息提取单元15提取所获取的第二原始图像即车窗外文化庙会中的第二对象即人群、小吃、杂技等文化表演的第二关键点信息即人潮、美食、杂技等。并在步骤s106中,对该第二关键点信息设置权重值,将该权重值作为第二原始图像的第二权重值。若该第二关键点信息即人潮、美食、杂技为大众喜欢的场景,则分别设置一个正数值例如2,那么第二原始图像的第二权重值为2+2+2=6。
[0152]
此时,若在车辆内的乘员的面部表情为惊喜,则人脸图像的第一权重值设为2,当人的身体朝向一侧超出了规定时间或身体朝向一侧的次数在规定时间内超过规定次数,则人的姿态的第一权重值设为2,但当乘员语音信息中并没有涉及到人潮、美食、杂技等关键词,即,在乘员语音信息中没有提到第二原始图像中的第二关键点信息时,则语音信息的第一权重值设为0,则说明人脸图像的表情、人的姿态和语音信息这三者之间不存在一致性,此时可以取两者的权重值的平均值,例如人脸图像、人的姿态的第一权重值的平均值为(2+2)/2=2。由于人脸图像的表情、人的姿态和语音信息中表示评价的语音信息这三者中的两者一致,因此其系数为2。那么在步骤s107中,第二原始图像的叠加权重值为6*2=12。在步骤s202中,合成图像的合成图像权重值则为2+12=14。
[0153]
当第二原始图像为场景图像例如人群的聚集时,在步骤s105中,通过第二关键点信息提取单元15提取所获取的第二原始图像即车窗外人群聚集中的第二对象即人群、碰撞的车辆、交警等的第二关键点信息即车祸、车辆破损、违章等。并在步骤s106中,对该第二关键点信息设置权重值,将该权重值作为第二原始图像的第二权重值。若该第二关键点信息即车祸、车辆破损、违章中均不为大众喜欢的场景,则分别设置一个负数值例如-2,那么第二原始图像的第二权重值为-2-2-2=-6。
[0154]
此时,若在车辆内的乘员的面部表情为厌恶,则人脸图像的第一权重值设为-2,当人的身体朝向一侧超出了规定时间或身体朝向一侧的次数在规定时间内超过规定次数,则人的姿态的第一权重值设为2,当乘员语音信息中涉及到车祸、车辆破损、违章等关键词,即,在乘员语音信息中提到第二原始图像中的第二关键点信息时,则语音信息的第一权重值设为2,则说明人脸图像的表情、人的姿态和语音信息这三者之间不存在一致性,此时可以取三者的权重值的平均值,例如人脸图像、人的姿态、语音信息的第一权重值的平均值为(-2+2+2)/3=0.67。由于人脸图像的表情、人的姿态和语音信息中表示评价的语音信息这三者中的两者一致,因此其系数为2。那么在步骤s107中,第二原始图像的叠加权重值为-6*2=-12。在步骤s202中,合成图像的合成图像权重值则为0.67-12=-11.33。
当然,从吸引人群的关注的角度看,上述车祸等情形也可以增大其权重值。
[0155]
图8是图像处理模块、图像合成模块、图像标签生成模块、图像整理模块、图像输出模块和图像修正模块的流程图。本发明还涉及一种图像处理模块。在该图像处理模块中进行与上述图像处理装置及图像处理方法所执行的处理相同的处理。
[0156]
即,在图像处理模块中,在第一场景中获取第一原始图像,第一原始图像中包含第一对象,提取所述第一对象的第一关键点信息,并对所述第一关键点信息设置权重值,将该权重值作为所述第一原始图像的第一权重值;在第一场景外的第二场景中获取第二原始图像,所述第二原始图像中包含第二对象,提取所述第二对象的第二关键点信息,并对所述第二关键点信息设置权重值,将该权重值作为所述第二原始图像的第二权重值;基于所述第一原始图像的所述第一权重值使所述第二原始图像的第二权重值增大,而使所述第二原始图像具有叠加权重值。
[0157]
本发明还涉及一种图像合成模块。在该图像合成模块中进行与上述图像合成装置及图像合成方法所执行的处理相同的处理。即,在所述图像合成模块中,将所述第一原始图像和所述第二原始图像合成为合成图像,其中所述合成图像为将所述第一原始图像的局部或全部与所述第二原始图像的局部或全部合成在一起的图像,基于所述第一原始图像的所述第一权重值、所述第二原始图像的所述叠加权重值,设置所述合成图像的合成图像权重值。
[0158]
本发明还涉及一种图像标签生成模块。在该图像标签生成模块中进行与上述图像标签生成装置及图像标签生成方法所执行的处理相同的处理。即,在所述图像标签生成模块中,基于所述第一关键点信息生成对应于所述第一原始图像的第一标签,基于所述第二关键点信息生成对应于所述第二原始图像的第二标签,基于所述第一标签和所述第二标签生成对应于所述合成图像的合成图像标签。
[0159]
本发明还涉及一种图像整理模块。在该图像整理模块中进行与上述图像整理装置及图像整理方法所执行的处理相同的处理。即,在所述图像整理模块中,基于所述合成图像标签将所述合成图像归类,基于被归类的所述合成图像的合成图像权重值生成所述合成图像的序列。
[0160]
本发明还涉及一种图像输出模块。在该图像输出模块中进行与上述图像输出装置及图像输出方法所执行的处理相同的处理。即,在所述图像输出模块中,从所述合成图像的序列中选择并输出合成图像。
[0161]
本发明的上述图像处理模块、图像合成模块、图像标签生成模块、图像整理模块、图像输出模块可配置在云处理单元,而将对于图像的处理在云端中进行。
[0162]
本发明还涉及一种图像修正模块。在该图像修正模块中进行与上述图像修正装置及图像修正方法所执行的处理相同的处理。即,在所述图像修正模块中,基于针对所输出的合成图像的反馈,来修正所述合成图像的合成图像权重值,进而调整所述合成图像的序列。
[0163]
本发明的上述图像修正模块可设置在后述的用户终端上的app上。
[0164]
另外,本发明还提供一种电子设备,所述电子设备包括:存储器,用于存储可执行指令;处理器,用于运行所述存储器存储的可执行指令时,实现上述的图像处理方法、图像
合成方法、图像标签生成方法、图像整理方法、图像输出方法、图像修正方法中的一种方法或多种方法。所述电子设备还包括显示器,所述显示器被划分为多个显示区域,分别用于显示第一原始图像、第二原始图像和合成图像。
[0165]
所述显示器可以为用户终端。用户终端可以包括:智能手机、平板电脑、笔记本电脑、掌上电脑、移动互联网设备(mobile internet device,mid)等携带数据处理功能(例如,多媒体数据处理播放功能)的智能终端。
[0166]
用户通过安装在用户终端上的app(application,应用软件),通过在app上输入上述合成图像的标签来搜索合成图像,用户可以对下载到用户终端上的合成图像进行编辑,然后将编辑好的图像上传到传播媒介,例如抖音等。对合成图像的编辑可以通过一键自动生成的方式进行,也可以通过自己手动制作的方式进行。
[0167]
app会对用户上传到传播媒介的图像进行跟踪,来了解人们的喜好,当发现该上传的图像的受众评价的反馈程度较高例如点赞量每日剧增时,app自身会将该反馈程度高的图像的内容及形式等作为学习目标,优化自己的一键生成系统,该一键生成系统为用户不需要进行手动编辑就能够自动生成合成图像的系统。该一键生成系统在生成合成图像的时候,按照该反馈程度高的的图像的内容及形式进行视频生成,由此能够生成用户喜爱度高的合成图像,该图像的内容是指,点赞量较高的例如包含大海、红日、帆船及兴奋的乘员的图像,而对于反应平淡即点赞量寥寥无几的包含大海、岩石及面无表情的乘员的图像则不作为一键生成的内容;该形式是指,点赞量较高的例如将大海、红日、帆船及兴奋的乘员的图像通过内部编辑融为一体的图像形式,而对于反应平淡即点赞量寥寥无几的将大海、红日、帆船及兴奋的乘员的图像分隔显示的图像不作为一键生成的形式。此外,当用户选择手动生成时,向用户推送反馈程度高的的图像内容及形式来供用户将选择。由此反复,则能够通过传播媒介的反馈来不断提升视频制作的受欢迎程度,而且也节省了用户制作的时间,提高了制作效率。
[0168]
下面参照图9、图10对上述app进行说明。当用户想要开启安装在用户终端上的app而进行点击时,用户终端可以响应该用户针对该app的启动操作,来启动用户终端中的app,并进入app的首页。app的首页可以划分成以下三个区域。最下端区域:该区域设置关键词即标签输入框、一键生成、手动生成等控件,该手动生成例如包括时间控件、地点控件、情景控件等。其中,关键词输入框用于输入关键词来搜索相关的合成图像,一键生成控件用于将搜索到并选择的图像一键自动生成自己喜欢的图像形式,手动生成控件是用户通过手动来自己制作图像,在该手动操作过程中,可以使用时间控件、地点控件、情景控件等,时间控件是表示在时间上建立关联的图像,地点控件是在地点上建立关联的图像,情景控件是在情景上建立关联的图像,可以将默认显示设为在时间上建立关联的图像。中间区域:在中间区域设置左右两个显示区域,两个显示区域中的一方用于显示车辆内情感图像,而另一方显示车辆外情景图像,例如左侧区域显示车辆内情感图像,右侧区域显示车辆外情景图像。最上端区域:在最上端区域显示由车辆内情感图像与车辆外情景图像合成后的合成图像,在完成合成图像的合成之前显示为合成图像的控件,在完成合成图像之后,显示合成后的合成图像(参照图9、图10)。
[0169]
例如,当用户搜索大海时,在中间区域的左侧显示区域显示车内乘员兴奋的图像,而在右侧显示区域默认显示与该车内乘员兴奋的图像属于同一时间拍摄的车外大海夕阳的图像,若用户喜欢这两个在时间上关联为一致的图像,则点击最上端区域中合成图像的控件,随着点击而生成包括该车内乘员兴奋的图像及车外大海夕阳的图像的合成图像;若用户不喜欢右侧显示区域中所显示的大海夕阳的图像,则可以选择自己喜欢的图像,当点击时间控件时,右侧显示区域显示此处的大海在一天中不同时段的模样,或者在一年中不同时段的模样,当点击地点控件时,右侧显示区域显示不同地点的大海,例如大连的大海、海南的大海或者日本镰仓的大海等,该不同地点的大海的情景可以是在同一时间发生的情景,也可以是在不同时间发生的情景;当点击情景控件时,该大海的情景不局限于时间或地点上的关联,也可以是来自影视作品中虚拟的场景,例如是来自遥远星球的大海等。
[0170]
当用户通过选择上述时间控件、地点控件或情景控件而选择到自己喜欢的右侧显示区域中的图像后,点击最上端显示区域中的合成图像的控件来合成图像。该合成图像可以是将车内乘员兴奋的图像与大海的图像彼此各自独立地显示在一起的合成图像,例如图9所显示的图像,也可以是将车内乘员兴奋的图像与大海的图像融合在一起的合成图像,例如图10所显示的图像。
[0171]
另外,本发明还提供一种计算机可读存储介质,存储有可执行程序,所述可执行程序被处理器执行时实现上述的图像处理方法、图像合成方法、图像标签生成方法、图像整理方法、图像输出方法、图像修正方法中的一种方法或多种方法。
[0172]
[变形例]在上述实施例中对在同一时间生成的第一原始图像和第二原始图像进行合成而生成合成图像,但并不局限于此,也可以为将分别在不同时间生成的第一原始图像和第二原始图像进行合成而生成具有时间跨度的合成图像。
[0173]
例如,通过从车内乘员的语音中识别到的“去年”、“上周”等关于过去时间段的语句,来将“去年”、“上周”的车辆外图像与当前的车辆内图像彼此关联而制作成一个图像中事件在时间上不是在同一时间发生的事件的合成图像。同样,也可以从车内乘员的语音中识别到的不同于眼前的其他地理位置例如,当前的山为黄山时乘客提到了“泰山”,此时,也可以将“泰山”作为车辆外图像与当前的车辆内图像彼此关联而制作成一个图像中的事件在地理上不在同一地理区域的事件的合成图像。也就是说,只要车辆内图像与本车获得的车辆外图像之间存在某种关联,即可合成为一个合成图像。此外,车辆外图像不局限于现实中存在的情景图像,也可以是在影视作品等中出现的情景图像,例如,当车辆内乘员想要制作有趣的合成图像时,有意在语音谈论中加入一些虚幻场景一类的词语,比如“火山”、“侏罗纪公园”等,此时,车辆内图像可与基于从车内乘员的语音中识别到的“火山”、“侏罗纪公园”等关键点信息而得到的“火山”、“侏罗纪公园”等图像建立关联而生成图像中包含车内乘员自身和“火山”或“侏罗纪公园”的合成图像。显然,通过以如此方式生成的合成图像,能够增加趣味性。
[0174]
此外,本发明不限于上述实施方式,在不脱离本发明的主旨的情况下,当然可以采用各种结构。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1