结合大数据和多维特征的数据溯源方法及大数据云服务器与流程
1.本申请涉及大数据分析技术领域,尤其涉及结合大数据和多维特征的数据溯源方法及大数据云服务器。
背景技术:
2.随着科技的发展,大数据时代悄然而至。大数据可以根据移动互联网、物联网、社交网络、数字家庭、电子商务等信息技术不同来源数据的转换,分析和优化,将各种结果交叉反馈到应用中,去改善用户的体验,来创造最大的商业价值,经济价值以及社会价值。合理有效地利用大数据,能够为人们创造更大的竞争力、价值和财富,以实现数据价值的最大化。
3.然而,随着数据业务规模的不断扩大,数据量也呈现激增状态,这会给大数据服务器造成巨大的存储压力,为了改善大数据服务器端的存储压力,需要对业务数据进行压缩存储。在对业务数据进行压缩存储的过程中难免会丢失一些数据,在后续对压缩存储的业务数据进行再使用时,需要对压缩存储的业务数据进行溯源。
技术实现要素:
4.本申请提供结合大数据和多维特征的数据溯源方法及大数据云服务器,以实现对数据进行溯源从而得到完整的原始业务数据。
5.根据本发明实施例的第一方面,提供一种结合大数据和多维特征的数据溯源方法,包括:根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列;对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息;对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数据的相关性数据特征集;对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集;根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值;按照所述目标索引值及其所述索引类别在预设数据库中查询与所述待溯源数据对应的目标配对数据,并根据目标溯源数据对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据。
6.在上述第一方面的基础上,所述根据预设的数据特征识别模型对待溯源数据进行多维特征识别之前,还包括:对所述待溯源数据进行业务数据标签提取,得到所述待溯源数据的业务处理标签;
其中,所述根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列,包括:根据所述预设的数据特征识别模型中的预存标签信息集,对所述待溯源数据的业务处理标签进行数据特征和业务处理标签的遍历匹配,得到与所述待溯源数据对应的多维数据特征队列。
7.在上述第一方面的基础上,所述根据所述预设的数据特征识别模型中的预存标签信息集,对所述待溯源数据的业务处理标签进行数据特征和业务处理标签的遍历匹配,得到与所述待溯源数据对应的多维数据特征队列,包括:根据所述预设的数据特征识别模型中的预存标签信息集、以及所述待溯源数据的业务处理标签,确定用于将所述业务处理标签转换为所述预存标签信息集的标签映射路径;根据所述标签映射路径对所述待溯源数据的业务处理标签进行路径节点分段映射,基于路径节点分段映射后得到的标签描述信息确定与所述待溯源数据对应的多维数据特征队列。
8.在上述第一方面的基础上,用于数据环境参数聚类的目标聚类模型包括聚类驱动线程和聚类校正线程;所述对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息,包括:通过所述聚类驱动线程对所述多维数据特征队列进行基于特征维度数量的数据环境参数聚类,得到所述待溯源数据的特征分布信息;所述对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数据的相关性数据特征集,包括:通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集校正,得到对应所述待溯源数据的相关性数据特征集;所述对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集,包括:通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于缺损曲线时序变化的聚类集校正,得到对应所述待溯源数据的缺损数据特征集。
9.在上述第一方面的基础上,所述聚类校正线程包括多个存在递进关系的校正路径;所述通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集校正,得到对应所述待溯源数据的相关性数据特征集,包括:通过所述多个存在递进关系的校正路径中的第一个校正路径,对所述待溯源数据的特征分布信息进行特征分布区间校正;将所述第一个校正路径的校正输出信息传入到基于所述递进关系所确定出的下一个校正路径,以在所述基于所述递进关系所确定出的下一个校正路径中继续进行特征分布区间校正和校正输出信息输出,直至输出到最后一个校正路径,并将所述最后一个校正路径输出的校正输出信息映射至聚类特征列表,并基于最后一个校正路径输出的校正输出信息在所述聚类特征列表中的聚类集中度对应的集中度权重队列确定对应所述待溯源数据的相关性数据特征集。
10.在上述第一方面的基础上,所述聚类驱动线程包括多个存在驱动干扰的驱动函数;所述通过所述聚类驱动线程对所述多维数据特征队列进行基于特征维度数量的数据环境参数聚类,得到所述待溯源数据的特征分布信息,包括:
通过所述多个存在驱动干扰的驱动函数中的具有最大干扰因子的驱动函数,对所述多维数据特征队列进行环境特征数据提取;将所述具有最大干扰因子的驱动函数的当前环境特征数据提取结果加载至所述多个存在驱动干扰的驱动函数中除最大干扰因子的驱动函数之外的具有第二大干扰因子的驱动函数,以基于所述多个存在驱动干扰的驱动函数中除最大干扰因子的驱动函数之外的具有第二大干扰因子的驱动函数中继续进行环境特征数据提取和当前环境特征数据提取结果的级联加载,直至级联加载到所述多个存在驱动干扰的驱动函数中具有最小干扰因子的驱动函数中;将所述多个存在驱动干扰的驱动函数中具有最小干扰因子的驱动函数输出的当前环境特征数据提取结果中具有目标维度数量的环境特征数据作为所述待溯源数据的特征分布信息。
11.在上述第一方面的基础上,当所述聚类校正线程包括多个存在递进关系的校正路径,且相邻的校正路径之间存在共用校正节点时,所述通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集校正,得到对应所述待溯源数据的相关性数据特征集,包括:通过所述多个存在递进关系的校正路径中的第一个校正路径,对所述待溯源数据的特征分布信息进行特征分布区间校正;将校正输出信息与所述第一个校正路径存在共用校正节点的目标校正路径对应的目标驱动函数输出的当前环境特征数据提取结果进行整合,将整合结果作为所述第一个校正路径的校正输出信息,并输出到基于所述递进关系所确定出的下一个校正路径,以在所述基于所述递进关系所确定出的下一个校正路径中继续进行特征分布区间校正、整合处理和校正输出信息输出,直至输出到最后一个校正路径;将所述最后一个校正路径输出的校正输出信息映射至聚类特征列表,并基于最后一个校正路径输出的校正输出信息在所述聚类特征列表中的聚类集中度对应的集中度权重队列确定对应所述待溯源数据的相关性数据特征集。
12.在上述第一方面的基础上,所述根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值,包括:针对所述缺损数据特征集中的每个缺损数据特征执行以下处理:将所述多维数据特征队列中对应所述缺损数据特征的缺损比率、与所述缺损数据特征集中所述缺损数据特征的缺损比率相乘,以得到所述缺损数据特征的第一缺损比率;对所述缺损数据特征集中所述缺损数据特征的缺损比率进行归一化处理,并将归一化处理结果与所述相关性数据特征集中对应所述缺损数据特征的缺损比率相乘,以得到所述缺损数据特征的第二缺损比率;将所述第一缺损比率与所述第二缺损比率进行加权求和,以得到所述缺损数据特征的缺损索引标签;对所述每个缺损数据特征的缺损索引标签进行缺损索引值提取,得到包括索引类别的目标索引值。
13.根据本发明实施例的第二方面,提供一种大数据云服务器,包括:处理器,以及与处理器连接的内存和网络接口;所述网络接口与大数据云服务器中的非易失性存储器连接;所述处理器在运行时通过所述网络接口从所述非易失性存储器中调取计算机程序,并
通过所述内存运行所述计算机程序,以执行上述的方法。
14.根据本发明实施例的第三方面,提供一种应用于计算机的可读存储介质,所述可读存储介质烧录有计算机程序,所述计算机程序在大数据云服务器的内存中运行时实现上述的方法。
15.应用本申请实施例结合大数据和多维特征的数据溯源方法及大数据云服务器时,首先对待溯源数据进行多维特征识别得到多维数据特征队列,其次对多维数据特征队列进行数据环境参数聚类得到特征分布信息并分别对特征分布信息进行特征相关性识别和数据交互缺损识别以得到相关性数据特征集和缺损数据特征集,然后根据缺损数据特征集对多维数据特征队列以及相关性数据特征集进行索引值提取得到包括索引类别的目标索引值,最后按照目标索引值及其索引类别在预设数据库中查询与待溯源数据对应的目标配对数据并根据目标溯源数据对待溯源数据进行溯源得到待溯源数据对应的原始业务数据。这样以来,能够将待溯源数据的多维数据特征考虑在内,进而深度挖掘待溯源数据的相关性数据特征集和缺损数据特征集,以准确确定目标索引值及其索引类别,从而实现对待溯源数据的完整、准确的溯源。
16.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
17.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
18.图1是本申请根据一示例性实施例示出的一种结合大数据和多维特征的数据溯源系统的系统架构示意图。
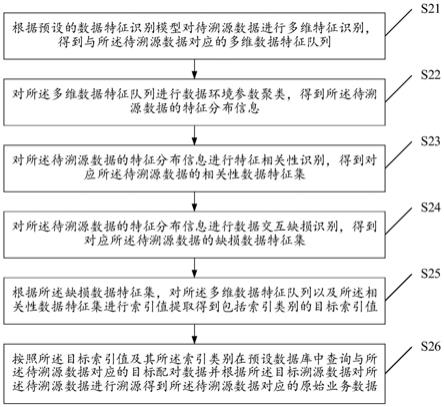
19.图2是本申请根据一示例性实施例示出的一种结合大数据和多维特征的数据溯源方法的流程图。
20.图3是本申请根据一示例性实施例示出的一种结合大数据和多维特征的数据溯源装置的一个实施例框图。
21.图4为本申请结合大数据和多维特征的数据溯源装置所在大数据云服务器的一种硬件结构图。
具体实施方式
22.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
23.在本申请使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本申请。在本申请和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
24.应当理解,尽管在本申请可能采用术语第一、第二、第三等来描述各种信息,但这
些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
25.发明人在研究和分析中发现,常见的对业务数据进行溯源的方法大多基于压缩路径进行数据还原,然而这样没有考虑业务数据在不同维度上的数据特征,从而忽略了业务数据的数据关联性和数据压缩时出现的缺损,这样难以实现对业务数据的完整溯源。
26.为改善上述技术问题,本发明实施例旨在提供结合大数据和多维特征的数据溯源方法及大数据云服务器。首先请参阅图1,提供了一种结合大数据和多维特征的数据溯源系统100的系统架构示意图。所述数据溯源系统100可以包括互相连接的大数据云服务器200以及业务终端400。其中,大数据云服务器200从所述业务终端400中采集业务数据并进行压缩存储,并在需要对压缩存储的业务数据进行溯源时进行业务数据的完整溯源。
27.在本实施例中,大数据云服务器200不仅可以应用于智慧城市,还可以应用于智慧医疗、智慧工业园区、智慧工业互联网,该数据溯源系统100可以应用于大数据、云计算以及边缘计算等场景中,包括但不限于新能源汽车系统管理、智能在线办公、智能在线教育、云游戏数据处理、电商直播带货处理、云上车联网处理、区块链数字金融货币服务、区块链供应链金融服务等,在此不作限定。可以理解,当应用于上述相应的领域时,业务数据的类型随之进行调整和进一步细化,在此不再一一列举。
28.在上述基础上,请结合参阅图2,提供了结合大数据和多维特征的数据溯源方法的流程示意图,所述方法可以应用于图1中的大数据云服务器200,具体可以包括以下步骤s21
‑
步骤s26所描述的内容。
29.步骤s21,根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列。
30.例如,待溯源数据是预先存储在大数据云服务器中的经过压缩的业务数据,该业务数据从业务终端中采集得到。
31.步骤s22,对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息。
32.例如,特征分布信息可以以图形、列表或其他形式进行展示,在此不作限定。
33.步骤s23,对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数据的相关性数据特征集。
34.步骤s24,对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集。
35.步骤s25,根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值。
36.例如,目标索引值可以为多个。
37.步骤s26,按照所述目标索引值及其所述索引类别在预设数据库中查询与所述待溯源数据对应的目标配对数据,并根据目标溯源数据对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据。
38.例如,预设数据库可以是关系型数据库例如mysql数据库或者hive数据库,在此不
作限定,目标配对数据可以为多组数据。
39.可以理解,通过执行上述步骤s21
‑
步骤s26所描述的内容,首先对待溯源数据进行多维特征识别得到多维数据特征队列,其次对多维数据特征队列进行数据环境参数聚类得到特征分布信息并分别对特征分布信息进行特征相关性识别和数据交互缺损识别以得到相关性数据特征集和缺损数据特征集,然后根据缺损数据特征集对多维数据特征队列以及相关性数据特征集进行索引值提取得到包括索引类别的目标索引值,最后按照目标索引值及其索引类别在预设数据库中查询与待溯源数据对应的目标配对数据并根据目标溯源数据对待溯源数据进行溯源得到待溯源数据对应的原始业务数据。这样以来,能够将待溯源数据的多维数据特征考虑在内,进而深度挖掘待溯源数据的相关性数据特征集和缺损数据特征集,以准确确定目标索引值及其索引类别,从而实现对待溯源数据的完整、准确的溯源。
40.在具体实施过程中,在步骤s21之间,还包括:对所述待溯源数据进行业务数据标签提取,得到所述待溯源数据的业务处理标签。进一步地,在上述基础上,所述根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列,包括:根据所述预设的数据特征识别模型中的预存标签信息集,对所述待溯源数据的业务处理标签进行数据特征和业务处理标签的遍历匹配,得到与所述待溯源数据对应的多维数据特征队列。如此,能够基于业务处理标签确保多维数据特征队列的全面性和准确性。
41.进一步地,在上述基础上,所述根据所述预设的数据特征识别模型中的预存标签信息集,对所述待溯源数据的业务处理标签进行数据特征和业务处理标签的遍历匹配,得到与所述待溯源数据对应的多维数据特征队列,详细包括以下步骤a和步骤b所描述的内容。
42.步骤a,根据所述预设的数据特征识别模型中的预存标签信息集、以及所述待溯源数据的业务处理标签,确定用于将所述业务处理标签转换为所述预存标签信息集的标签映射路径。
43.步骤b,根据所述标签映射路径对所述待溯源数据的业务处理标签进行路径节点分段映射,基于路径节点分段映射后得到的标签描述信息确定与所述待溯源数据对应的多维数据特征队列。
44.这样以来,能够基于上述步骤a
‑
步骤b实现精准的遍历匹配,从而确保多维数据特征队列的全面性和准确性。
45.在实际应用时,用于数据环境参数聚类的目标聚类模型可以包括聚类驱动线程和聚类校正线程。
46.在这一技术基础上,步骤s22所描述的对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息,示例性地可以包括:通过所述聚类驱动线程对所述多维数据特征队列进行基于特征维度数量的数据环境参数聚类,得到所述待溯源数据的特征分布信息。
47.在这一技术基础上,步骤s23所描述的对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数据的相关性数据特征集,示例性地可以包括:通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集
校正,得到对应所述待溯源数据的相关性数据特征集。
48.在这一技术基础上,步骤s24所描述的对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集,示例性地可以包括:通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于缺损曲线时序变化的聚类集校正,得到对应所述待溯源数据的缺损数据特征集。
49.这样以来能够确保特征分布信息、相关性数据特征集以及缺损数据特征集的置信度,确保后续数据溯源的有效性。
50.在上述基础上,所述聚类校正线程包括多个存在递进关系的校正路径;所述通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集校正,得到对应所述待溯源数据的相关性数据特征集,具体可以包括以下步骤所描述的内容:通过所述多个存在递进关系的校正路径中的第一个校正路径,对所述待溯源数据的特征分布信息进行特征分布区间校正;将所述第一个校正路径的校正输出信息传入到基于所述递进关系所确定出的下一个校正路径,以在所述基于所述递进关系所确定出的下一个校正路径中继续进行特征分布区间校正和校正输出信息输出,直至输出到最后一个校正路径,并将所述最后一个校正路径输出的校正输出信息映射至聚类特征列表,并基于最后一个校正路径输出的校正输出信息在所述聚类特征列表中的聚类集中度对应的集中度权重队列确定对应所述待溯源数据的相关性数据特征集。
51.如此以来,能够基于递进的校正路径实现对相关性数据特征集的准确统计。
52.进一步地,所述聚类驱动线程包括多个存在驱动干扰的驱动函数;所述通过所述聚类驱动线程对所述多维数据特征队列进行基于特征维度数量的数据环境参数聚类,得到所述待溯源数据的特征分布信息,包括:通过所述多个存在驱动干扰的驱动函数中的具有最大干扰因子的驱动函数,对所述多维数据特征队列进行环境特征数据提取;将所述具有最大干扰因子的驱动函数的当前环境特征数据提取结果加载至所述多个存在驱动干扰的驱动函数中除最大干扰因子的驱动函数之外的具有第二大干扰因子的驱动函数,以基于所述多个存在驱动干扰的驱动函数中除最大干扰因子的驱动函数之外的具有第二大干扰因子的驱动函数中继续进行环境特征数据提取和当前环境特征数据提取结果的级联加载,直至级联加载到所述多个存在驱动干扰的驱动函数中具有最小干扰因子的驱动函数中;将所述多个存在驱动干扰的驱动函数中具有最小干扰因子的驱动函数输出的当前环境特征数据提取结果中具有目标维度数量的环境特征数据作为所述待溯源数据的特征分布信息。
53.可以理解,基于对通过所述聚类驱动线程对所述多维数据特征队列进行基于特征维度数量的数据环境参数聚类,得到所述待溯源数据的特征分布信息的上述详细说明,能够确保特征分布信息之间的特征区分度和特征识别度。
54.在一个可以实现的实施方式中,当所述聚类校正线程包括多个存在递进关系的校正路径,且相邻的校正路径之间存在共用校正节点时,所述通过所述聚类校正线程对所述待溯源数据的特征分布信息进行基于聚类集集中度筛分的聚类集校正,得到对应所述待溯源数据的相关性数据特征集,包括:
通过所述多个存在递进关系的校正路径中的第一个校正路径,对所述待溯源数据的特征分布信息进行特征分布区间校正;将校正输出信息与所述第一个校正路径存在共用校正节点的目标校正路径对应的目标驱动函数输出的当前环境特征数据提取结果进行整合,将整合结果作为所述第一个校正路径的校正输出信息,并输出到基于所述递进关系所确定出的下一个校正路径,以在所述基于所述递进关系所确定出的下一个校正路径中继续进行特征分布区间校正、整合处理和校正输出信息输出,直至输出到最后一个校正路径;将所述最后一个校正路径输出的校正输出信息映射至聚类特征列表,并基于最后一个校正路径输出的校正输出信息在所述聚类特征列表中的聚类集中度对应的集中度权重队列确定对应所述待溯源数据的相关性数据特征集。
55.如此以来,能够实现对相关性数据特征集的精准筛分,确保相关性数据特征集的噪声率最小化。
56.在一个具体的实施方式中,为了实现目标索引值与关系型数据库的兼容性匹配,步骤s25所描述的根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值,具体可以包括以下步骤s251
‑
步骤s254所描述的内容。
57.步骤s251,针对所述缺损数据特征集中的每个缺损数据特征执行以下处理:将所述多维数据特征队列中对应所述缺损数据特征的缺损比率、与所述缺损数据特征集中所述缺损数据特征的缺损比率相乘,以得到所述缺损数据特征的第一缺损比率。
58.步骤s252,对所述缺损数据特征集中所述缺损数据特征的缺损比率进行归一化处理,并将归一化处理结果与所述相关性数据特征集中对应所述缺损数据特征的缺损比率相乘,以得到所述缺损数据特征的第二缺损比率。
59.步骤s253,将所述第一缺损比率与所述第二缺损比率进行加权求和,以得到所述缺损数据特征的缺损索引标签。
60.步骤s254,对所述每个缺损数据特征的缺损索引标签进行缺损索引值提取,得到包括索引类别的目标索引值。
61.在应用上述步骤s251
‑
步骤s254所描述的内容时,能够实现目标索引值与关系型数据库的兼容性匹配。
62.在一种可替换的实施方式中,为了确保目标配对数据的准确性和完整性,步骤s26所描述的按照所述目标索引值及其所述索引类别在预设数据库中查询与所述待溯源数据对应的目标配对数据,具体可以包括以下步骤s2611
‑
步骤s2615所描述的内容。
63.步骤s2611,生成所述目标索引值对应的索引值列表以及生成所述索引类别对应的索引类别列表,且所述索引值列表和所述索引类别列表分别包括多个不同索引有效系数的列表数据集。
64.步骤s2612,确定所述目标索引值在所述索引值列表的任一列表数据集的索引查询语句,将所述索引类别列表中具有最大索引有效系数的列表数据集确定为目标列表数据集。
65.步骤s2613,根据所述相关性数据特征集和和所述缺损数据特征集将所述索引查询语句编写到所述目标列表数据集以在所述目标列表数据集中得到与所述索引查询语句对应的索引匹配语句,并根据所述索引查询语句以及所述索引匹配语句之间的词向量相似
度构建所述目标索引值和所述索引类别之间的索引配对路径。
66.步骤s2614,以所述索引匹配语句为基准语句在所述目标列表数据集中获取关联索引语句并基于所述索引配对路径对应的逆索引配对路径,将所述关联索引语句编写到所述索引查询语句所在列表数据集,以在所述索引查询语句所在列表数据集中得到所述关联索引语句对应的数据库调用语句,并确定所述数据库调用语句的调用路径信息为数据抽取信息。
67.步骤s2615,获取所述索引查询语句编写到所述目标列表数据集中的查询时序信息;根据所述数据库调用语句与所述查询时序信息中的多个时序节点对应的时序延时权重之间的延迟修复置信度,在所述索引类别列表中遍历所述数据抽取信息对应的数据标识,直至获取到的所述数据标识所在列表数据集的溯源评价值与所述数据抽取信息在所述索引值列表中的溯源评价值一致;基于所述索引匹配语句从所述预设数据库中查询与所述数据标识对应的已存储数据作为所述待溯源数据对应的目标配对数据。
68.这样以来,通过上述步骤s2611
‑
步骤s2615所描述的内容,能够确保目标配对数据的准确性和完整性。
69.在另一个可替换的实施方式中,为了实现对原始业务数据的完整溯源,以确保后续业务进程的顺利开展,步骤s26中所描述的根据目标溯源数据对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据,进一步可以包括以下步骤s2621
‑
步骤s2625所描述的内容。
70.步骤s2621,确定所述目标溯源数据相对于所述待溯源数据的第一溯源轨迹曲线、第二溯源轨迹曲线以及第三溯源轨迹曲线;确定出所述第一溯源轨迹曲线对应的第一轨迹特征与所述第二溯源轨迹曲线对应的第二轨迹特征之间的第一余弦距离以及所述第二溯源轨迹曲线对应的第二轨迹特征与所述第三溯源轨迹曲线对应的第三轨迹特征之间的第二余弦距离。
71.步骤s2622,针对所述第一溯源轨迹曲线,以所述第一轨迹特征为基准按照所述第一余弦距离对所述第一溯源轨迹曲线进行曲线平滑处理得到第四溯源轨迹曲线;针对所述第二溯源轨迹曲线,以所述第二轨迹特征为基准按照所述第二余弦距离对所述第二溯源轨迹曲线进行曲线平滑处理得到第五溯源轨迹曲线。
72.步骤s2623,分别将所述第一溯源轨迹曲线和所述第二溯源轨迹曲线、所述第一溯源轨迹曲线和所述第四溯源轨迹曲线、所述第二溯源轨迹曲线和所述第三溯源轨迹曲线、以及所述第二溯源轨迹曲线和所述第五溯源轨迹曲线进行曲线拟合,得到第一拟合曲线、第二拟合曲线、第三拟合曲线和第四拟合曲线;确定出所述第一拟合曲线和所述第二拟合曲线之间的第一曲线离散度以及所述第三拟合曲线和所述第四拟合曲线之间的第二曲线离散度。
73.步骤s2624,判断所述第一曲线离散度和所述第二曲线离散度是否均与预设离散度相对应;若是,根据所述第一拟合曲线和所述第三拟合曲线确定出所述目标溯源数据的溯源泛化系数并按照所述溯源泛化系数对所述第一溯源轨迹曲线、所述第二溯源轨迹曲线和所述第三溯源轨迹曲线进行溯源数据整合得到数据整合结果;若否,分别确定出所述第一曲线离散度和所述第二曲线离散度与所述预设离散度之间的第一差异值和第二差异值;比较所述第一差异值和所述第二差异值的大小;在所述第一差异值小于所述第二差异值
时,根据所述第一拟合曲线和所述第二拟合曲线确定出所述目标溯源数据的溯源泛化系数并按照所述溯源泛化系数对所述第一溯源轨迹曲线、所述第二溯源轨迹曲线和所述第三溯源轨迹曲线进行溯源数据整合得到数据整合结果;在所述第一差异值大于所述第二差异值时,根据所述第三拟合曲线和所述第四拟合曲线确定出所述目标溯源数据的溯源泛化系数并按照所述溯源泛化系数对所述第一溯源轨迹曲线、所述第二溯源轨迹曲线和所述第三溯源轨迹曲线进行溯源数据整合得到数据整合结果。
74.步骤s2625,基于所述数据整合结果对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据。
75.在具体实施过程中,通过上述步骤s2621
‑
步骤s2625所描述的内容,可以实现对原始业务数据的完整溯源,以确保后续业务进程的顺利开展。
76.基于上述同样的发明构思,请结合参阅图3,提供了一种结合大数据和多维特征的数据溯源装置300,包括:队列获取模块310,用于根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列;参数聚类模块320,用于对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息;特征识别模块330,用于对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数据的相关性数据特征集;缺损识别模块340,用于对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集;索引提取模块350,用于根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值;数据溯源模块360,用于按照所述目标索引值及其所述索引类别在预设数据库中查询与所述待溯源数据对应的目标配对数据,并根据目标溯源数据对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据。
77.关于上述队列获取模块310、参数聚类模块320、特征识别模块330、缺损识别模块340、索引提取模块350和数据溯源模块360的说明请参阅对图2所示的方法的步骤以及子步骤的详细说明,在此不作赘述。
78.进一步地,在图1和图2的基础上,还提供一种结合大数据和多维特征的数据溯源系统,包括互相之间通信连接的大数据云服务器和业务终端;业务终端用于:向大数据云服务器发送数据调用请求;大数据云服务器用于:根据所述数据调用请求获取对应的待溯源数据;根据预设的数据特征识别模型对待溯源数据进行多维特征识别,得到与所述待溯源数据对应的多维数据特征队列;对所述多维数据特征队列进行数据环境参数聚类,得到所述待溯源数据的特征分布信息;对所述待溯源数据的特征分布信息进行特征相关性识别,得到对应所述待溯源数
据的相关性数据特征集;对所述待溯源数据的特征分布信息进行数据交互缺损识别,得到对应所述待溯源数据的缺损数据特征集;根据所述缺损数据特征集,对所述多维数据特征队列以及所述相关性数据特征集进行索引值提取,得到包括索引类别的目标索引值;按照所述目标索引值及其所述索引类别在预设数据库中查询与所述待溯源数据对应的目标配对数据,并根据目标溯源数据对所述待溯源数据进行溯源得到所述待溯源数据对应的原始业务数据;将所述原始业务数据反馈给所述业务终端。
79.在上述基础上,请结合参阅图4,提供一种大数据云服务器200,包括:处理器210,以及与处理器210连接的内存220和网络接口230;所述网络接口230与大数据云服务器200中的非易失性存储器240连接;所述处理器210在运行时通过所述网络接口230从所述非易失性存储器240中调取计算机程序,并通过所述内存220运行所述计算机程序,以执行上述的方法。
80.同样地,还提供一种应用于计算机的可读存储介质,所述可读存储介质烧录有计算机程序,所述计算机程序在大数据云服务器200的内存220中运行时实现上述的方法。
81.以上实施方式中的各种技术特征可以任意进行组合,只要特征之间的组合不存在冲突或矛盾,但是限于篇幅,未进行一一描述,因此上述实施方式中的各种技术特征的任意进行组合也属于本说明书公开的范围。
82.上述装置中各个模块的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
83.对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理模块,即可以位于一个地方,或者也可以分布到多个网络模块上。可以根据实际的需要选择其中的部分或者全部模块来实现本申请方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
84.本领域技术人员在考虑说明书及实践这里申请的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未申请的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。
85.综上,在应用上述方法、装置及系统时,首先对待溯源数据进行多维特征识别得到多维数据特征队列,其次对多维数据特征队列进行数据环境参数聚类得到特征分布信息并分别对特征分布信息进行特征相关性识别和数据交互缺损识别以得到相关性数据特征集和缺损数据特征集,然后根据缺损数据特征集对多维数据特征队列以及相关性数据特征集进行索引值提取得到包括索引类别的目标索引值,最后按照目标索引值及其索引类别在预设数据库中查询与待溯源数据对应的目标配对数据并根据目标溯源数据对待溯源数据进行溯源得到待溯源数据对应的原始业务数据。这样以来,能够将待溯源数据的多维数据特
征考虑在内,进而深度挖掘待溯源数据的相关性数据特征集和缺损数据特征集,以准确确定目标索引值及其索引类别,从而实现对待溯源数据的完整、准确的溯源。
86.应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1