一种超临界萃取过程中工艺参数的非解耦建模优化方法与流程
本发明涉及一种用二氧化碳超临界萃取生物活性成分的生产工艺过程,尤其是涉及一种超临界萃取过程中工艺参数的非解耦建模优化方法。
背景技术:
超临界萃取技术是基于超临界流体特有的性质对物质的分离、提取和纯化。相比于水蒸气蒸、减压蒸馏和溶剂萃取等传统的方法,超临界萃取过程调节灵活、可操作性强,特别适用于热敏天然产物;萃取效率高;萃取过程不添加有机溶剂,产品不会被溶剂污染,适用于对品质要求很高的食品和药品行业。特别是,使用二氧化碳作为萃取溶剂的超临界萃取技术被认为是“清洁化工”和“绿色化学”理念的代表。
虽然已有的研究表明超临界萃取过程中温度、压强和二氧化碳流速是导致萃取率波动的主要因素,但是其它因素客观上也在影响着萃取率的变化。特别是超临界萃取过程具有强耦合和强非线性特征,这表明这些因素是相互作用共同影响萃取率。因此,综合考虑各种因素对萃取率的影响,建立一个能够更好地学习出超临界萃取过程中复杂的输入输出关系的模型,对提高工艺参数优化的精确度和生产控制的效果十分重要。
就目前超临界萃取行业来说,研究者们主要使用单因素试验方法提取数据,分别分析超临界萃取过程中温度、压力和二氧化碳的流量等因素对萃取率的单一影响结果;例如,长春工业大学李晓朋硕士学位论文公开的《超临界萃取工艺及其测控技术的研究》中使用单因素分析方法,分别分析了萃取温度、压力和二氧化碳的流量等因素在二氧化碳超临界萃取五味子过程中的最佳临界值,再结合主成分分析方法和响应面优化法建立这些影响因素和萃取率的数学模型,以进一步获取最优的工艺参数。依据单个变量因素进行分析,本质上是一种对非线性系统进行“解耦”的近似方法,该方法在“解耦”的过程中不可避免地会产生误差,影响后续建模方法的效果。此外,由于试验数据的数据规模远小于实际生产的历史生产数据,所涵盖工艺参数的运行情况也远少于实际生产的历史生产数据所涵盖的运行情况,这限制了正交试验法、响应面分析法或者改进的响应面方法拟合出模型的精度,进而影响后续工艺参数的寻优准确度;更重要的是,正交试验法、响应面分析法或者改进的响应面方法受本身模型原理的约束难以有效地处理大批量数据。
技术实现要素:
本发明要解决的技术问题是:克服现有二氧化碳超临界萃取过程中基于“解耦”的建模优化方法的误差,提供一种基于大批量的历史生产数据,直接对超临界萃取过程中众多影响因素和萃取率之间的非线性函数关系进行建模的方法,并在此基础上,结合粒子群优化智能算法,获取最优的工艺参数,以提高二氧化碳超临界萃取率。
本发明解决其技术问题所采用的技术方案包括以下步骤:
s1:获取影响萃取率的n(n>3)个变量因素的历史生产数据,记录所述变量因素不同取值对应的萃取率,并从中提取出样本数据;
s2:使用深度极限学习机建立以所述n个变量因素作为输入域、萃取率作为输出的模型;深度极限学习机由多层堆叠自编码器和极限学习机组成,使用多层堆叠自编码器从样本数据中提取出上述n个变量因素之间的深层特征;再以所述深层特征作为输入、萃取率作为输出,使用极限学习机进行拟合,学习萃取过程中的非线性输入输出关系;
s3:使用粒子群智能优化算法实现对超临界萃取过程中工艺参数的优化,将s2中训练完成的模型作为粒子群智能优化过程中的适应度函数,计算每个粒子的适应度函数值,寻找最优工艺参数。
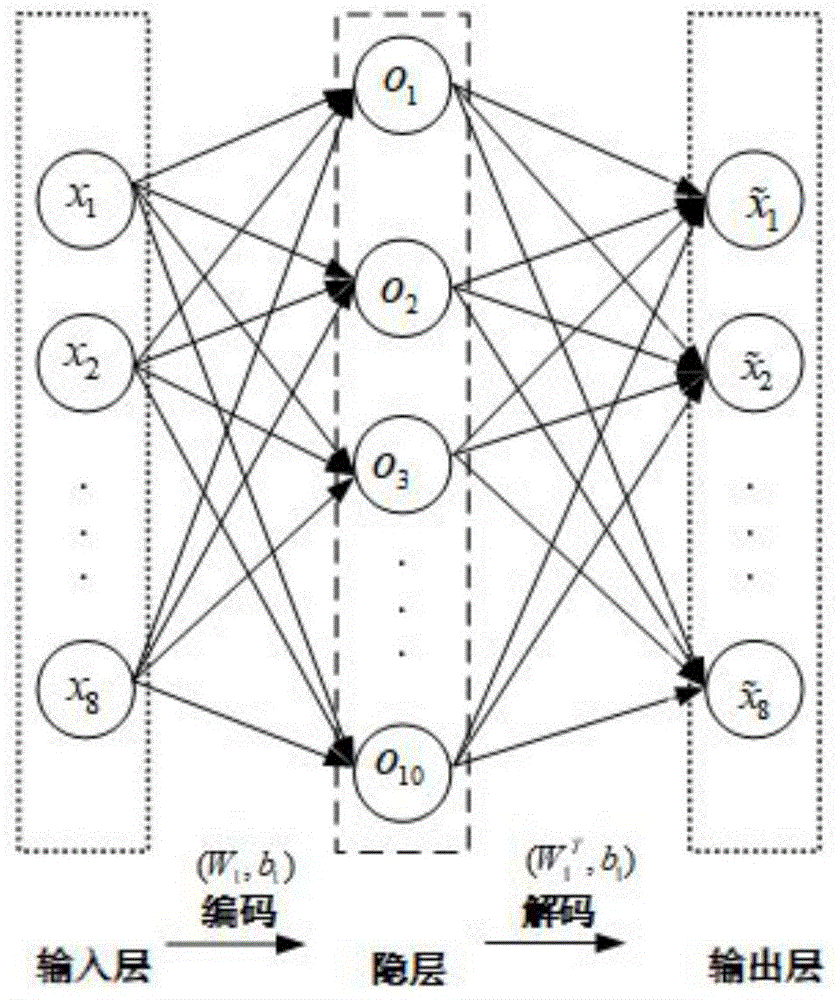
优选的,在步骤s2中,所述多层堆叠自编码器由多个单个自编码器堆叠而成;所述单个自编码器由输入层、隐层和输出层的神经网络结构组成;输入层的神经元个数等于系统输入变量的个数,输入层的n个神经元代表影响萃取率的n个变量因素,输出层和输入层结构相同,隐层有10个神经元;
自编码器包括两个部分:从输入层到隐层的映射关系是一个编码过程,通过映射函数将输入信号xi映射到隐层输出oj,即
oj=f(wij·xi+bi),i=1,...,8,j=1,...,10;
从隐层到输出层的映射关系是一个解码过程,通过映射把隐层输出oj映射到输出层
隐层和输出层神经元的激活函数都为sigmoid函数,即:
网络的损失函数为均方根误差:
优选的,在步骤s2中,所述极限学习机对应的网络表示为:
其中,qi表示模型的输入,由堆叠自编码器提取的深层特征;ωij表示第i个输入到第j个隐层神经元的输入权重;激活函数g(z)选择sigmoid函数;βj代表输出权重;bj代表第j个隐层神经元的偏置,随机初始化网络的输入权重ωij和偏置bj之后,确定隐层的输出,再使用最小二乘方法求解出输出权值,完成网络的训练。
优选的,所述变量因素为萃取温度、流入阀门开度、流出阀门开度、二氧化碳流速、萃取时间、样品颗粒密度、样品颗粒直径和超临界流体密度。
本发明的有益效果:
1.大量的超临界萃取过程的历史生产数据包含了更多的工艺参数运行情况和更充分的萃取过程的输入输出关系,因此本发明使用大量历史生产数据构建的模型会更加完备;
2.使用深度极限学习机对超临界萃取过程进行建模,利用堆叠自编码器能够逐层地学习原始数据的特征表达的能力,以获取影响萃取的变量因素之间深层的非线性特征;不仅能减少解耦方法带来的误差,而且能更好地学习出萃取过程中复杂的输入输出关系;并且基于此模型对萃取过程中工艺参数的设定值进行优化,以获取最优的生产工艺参数用于生产,最终能够将此方法进行推广应用,市场价值好。
附图说明
图1自编码器的结构图。
图2是用于提取原始数据深层特征的三层堆叠自编码器的结构图。
图3是极限学习机结构图。
图4是本发明使用粒子群智能优化算法寻优的流程图。
具体实施方式
如图1、图2、图3和图4所示,本发明的方法包括以下步骤:
s1:在本实施例中,选择萃取温度、流入阀门开度、流出阀门开度、二氧化碳流速、萃取时间、样品颗粒密度、样品颗粒直径和超临界流体(scf)密度这8个影响萃取率的因素,作为超临界萃取过程建模的输入变量。
s2:以广泛使用的750lx3二氧化碳超临界流体萃取设备为研究对象,从运行设备获取了大量的历史生产数据,并从中提取出多组数据用于后续训练深度极限学习机模型。
s3:使用深度极限学习机(deepextremelearningmachine,delm)建立以上述的8个因素作为输入域、萃取率作为输出的模型。深度极限学习机由堆叠自编码器和极限学习机两部分组成,使用三层的堆叠自编码器从大量的历史数据中提取出这些数据的高度非线性表达,即提取出上述8个变量之间的深层特征;再以这些深层特征作为输入、萃取率作为输出,使用极限学习机进行拟合,以学习出萃取过程中复杂的非线性输入输出关系。其中,为了能够快速地处理大批量历史生产数据,在具体操作中,联合使用keras和pytorch深度学习框架搭建深度极限学习机网络,并调用gpu进行加速运算。
本发明使用三层的堆叠自编码器,由三个自编码器堆叠而成。单个自编码器如图1所示,是一种只包含输入层、隐层和输出层的神经网络结构。在本发明中,输入层的神经元个数等于系统输入变量的个数,即输入层的8个神经元代表影响萃取率的8个因素;隐层有10个神经元;由于自编码器的功能是实现输出信号复现输入信号,故输出层和输入层结构相同。自编码器主要分为两个部分:从输入层到隐层的映射关系可以看作是一个编码过程,通过映射函数将输入信号xi映射到隐层输出oj,即
oj=f(wij·xi+bi),i=1,...,8,j=1,...,10;
从隐层到输出层的映射关系可以看作是一个解码过程,通过映射把隐层输出oj映射到输出层
隐层和输出层神经元的激活函数都为sigmoid函数,即
网络的损失函数为均方根误差:
由于自编码器的输出要“复现”输入,因此自编码器的价值在于中间的隐层。中间的隐层提供了原始输入数据的一种新特征的表达,即提取了原始输入数据新的特征。在此基础上,堆叠自编码器就是将上一个自编码器学习到的特征作为下一个自编码器的输入继续学习,多个自编码器这样堆叠就能够逐层地学习原始数据的特征,即每一层都是以前一层学习出的特征作为基础。这样随着层数的增加,提取的特征也越来越抽象越复杂,这就使得堆叠自编码器能够得到原始数据的高度非线性表达,即从原始数据中有效地提取出深层特征。本发明正是利用堆叠自编码器的这种功能从输入数据中提取出上述8种因素之间的深层特征,用于后续建模学习出萃取过程中复杂的非线性输入输出关系。
本发明使用的三层堆叠自编码器的结构如图2所示,堆叠自编码器是逐层采用反向传播算法训练网络,图1展示了第一层的训练,即自编码器的训练。第一个自编码器训练完成后,去掉解码过程并后接一个隐层(8个神经元)和输出层。此时第一个自编码器的隐层就变成了输入层,输出层要和第一个隐层结构相同,这样就得到了一个两层的堆叠自编码器,继续使用反向传播算法训练网络;训练完成后去掉解码过程并后接一个隐层(6个神经元)和输出层,同样输出层的结构要和第二个隐层结构相同,这样就得到了三层堆叠自编码器(如图2所示)。再次训练完之后,将第三个隐层的输出作为后续极限学习机建模的输入。
本发明使用的极限学习机的结构如图3所示,对应的网络可以表示为:
其中,qi表示模型的输入(即q1到q6),由堆叠自编码器提取的深层特征;ωij代表第i个输入到第j个隐层神经元的输入权重;综合模型精度和计算复杂度,隐层神经元的个数设置为100个,且激活函数g(z)选择sigmoid函数;βj代表输出权重;bj代表第j个隐层神经元的偏置。当随机初始化网络的输入权重ωij和偏置bj之后,隐层的输出就被确定了,即
s4:使用粒子群智能优化算法寻找出最优的工艺参数,以实现对超临界萃取过程中工艺参数的优化。其中,将s3中训练完成的模型作为粒子群智能优化过程中的适应度函数,用于计算每个粒子的适应度函数值,用于寻找全局最优位置,即最优的工艺参数。粒子群智能优化算法的流程图如图4所示。
以上仅是本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有前述各种技术特征的组合和变型,本领域的技术人员在不脱离本发明的精神和范围的前提下,对本发明的改进、变型、等同替换,或者将本发明的结构或方法用于其它领域以取得同样的效果,都属于本发明包括的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!