傅里叶变换处理方法和处理器、终端、芯片及存储介质与流程
1.本发明涉及通信技术领域,尤其涉及一种傅里叶变换处理方法和处理器、终端、芯片及存储介质。
背景技术:
2.随着数字信号处理技术和大规模集成电路的发展,傅里叶变换算法广泛的应用在通信领域中。例如,移动通信系统长期演进(long term evolution,lte)下行采用正交频分复用(orthogonal frequency division multiplexing,ofdm)调制方式;具体的,基站和终端分别采用快速傅里叶反变换(inverse fast fourier transform,ifft)算法进行调制和快速傅里叶变换(fast fourier transform,fft)算法进行解调。而lte上行采用单载波频分多址(single carrier frequency division multiple access,sc
‑
fdma)调制方式;具体的,基带信号在经ifft算法调制前先基于离散傅里叶变换(discrete fourier transform,dft)进行扩展,且该调制方式也应用于新空口(new radio,nr),被称为dft
‑
s
‑
ofdm。可见,傅里叶变换算法在通信领域中的重要性不言而喻。
3.目前,在各种各样的傅里叶变换处理器中,相关技术通常采用流水线结构和基于存储器的结构来实现对数据的处理。然而,流水线结构在数据量过大的情况下,需占用更多的硬件资源,进而导致面积和功耗增加的缺陷;而基于存储器的结构,虽然能够克服硬件开销大的缺陷,但由于存储器地址在读写时面临一定的冲突,因此,相比于流水线结构数据处理时间上存在一定的局限性,吞吐率较低。
4.鉴于此,如何在减少硬件开销的同时有效避免数据吞吐速率的下降,成为一个亟待解决的技术问题。
技术实现要素:
5.本申请实施例提供了一种傅里叶变换处理方法和处理器、终端、芯片及存储介质,能够在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高。
6.本申请实施例的技术方案是这样实现的:
7.第一方面,本申请实施例提供了一种傅里叶变换处理方法,所述方法包括:
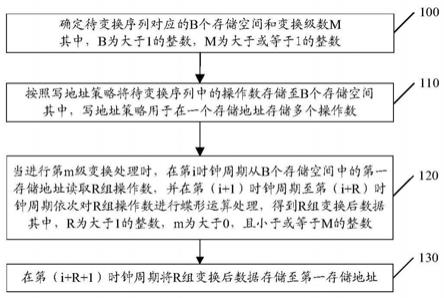
8.确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;
9.按照写地址策略将所述待变换序列中的操作数存储至所述b个存储空间;其中,所述写地址策略用于在一个存储地址存储多个操作数;
10.当进行第m级变换处理时,在第i时钟周期从所述b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
11.在第(i+r+1)时钟周期将所述r组变换后数据存储至所述第一存储地址。
12.第二方面,本申请实施例提供了一种傅里叶变换处理器,所述傅里叶变换处理器包括地址管理模块、蝶形运算模块以及存储模块,
13.所述地址管理模块,用于确定待变换序列对应的b个存储空间和变换级数m,以及按照写地址策略将所述待变换序列中的操作数存储至所述存储模块中的所述b个存储空间;其中,b为大于1的整数,m为大于或等于1的整数;所述写地址策略用于在所述存储模块中的一个存储地址存储多个操作数;
14.所述地址管理模块,还用于当进行第m级变换处理时,在第i时钟周期从所述存储模块中的所述b个存储空间中的第一存储地址读取r组操作数;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
15.所述蝶形运算模块,用于在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;
16.所述地址管理模块,用于在第(i+r+1)时钟周期将所述r组变换后数据存储至所述存储模块中的所述第一存储地址。
17.第三方面,本申请实施例提供了一种傅里叶变换处理器,所述傅里叶变换处理器包括确定单元、存储单元、读取单元以及运算单元,
18.所述确定单元,用于确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;
19.所述存储单元,用于按照写地址策略将所述待变换序列中的操作数存储至所述b个存储空间;其中,所述写地址策略用于在一个存储地址存储多个操作数;
20.所述读取单元,用于当进行第m级变换处理时,在第i时钟周期从所述b个存储空间中的第一存储地址读取r组操作数;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
21.所述运算单元,用于在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;
22.所述存储单元,用于在第(i+r+1)时钟周期将所述r组变换后数据存储至所述第一存储地址。
23.第四方面,本申请实施例提供了一种终端,所述终端包括傅里叶变换处理器、存储有所述傅里叶变换处理器可执行指令的存储器,所述傅里叶变换处理器包括地址管理模块、蝶形运算模块以及存储模块,当所述指令被所述傅里叶变换处理器执行时,实现如上所述的傅里叶变换处理方法。
24.第五方面,本申请实施例提供了一种芯片,所述芯片包括傅里叶变换处理器和接口,所述傅里叶变换处理器包括地址管理模块、蝶形运算模块以及存储模块,所述傅里叶变换处理器通过所述接口获取程序指令,所述傅里叶处理器用于运行所述程序指令,实现如上所述的傅里叶变换处理方法。
25.第六方面,本申请实施例提供了一种计算机可读存储介质,其上存储有程序,所述程序被傅里叶变换处理器执行时,实现如上所述的傅里叶变换处理方法。
26.本申请实施例提供了一种傅里叶变换处理方法和处理器、终端、芯片及存储介质,傅里叶变换处理器可以确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;按照写地址策略将待变换序列中的操作数存储至b个存储
空间;其中,写地址策略用于在一个存储地址存储多个操作数;当进行第m级变换处理时,在第i时钟周期从b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,得到r组变换后数据;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;在第(i+r+1)时钟周期将r组变换后数据存储至第一存储地址。也就是说,在本申请的实施例中,傅里叶变换处理器在确定出待变换序列对应的b个存储空间和变换级数m之后,便可以将待变换序列按照一个存储地址存储多个操作数的写地址策略将待变换序列成功存储至b个存储空间中;进一步的,在进行待变换序列每一级变换处理时,傅里叶变换处理器便可以在一个时钟周期里从目标存储地址同时读取多组操作数,并在接下来的多个时钟周期中分别依次对其进行蝶形运算处理,其中,一个时钟周期运算一组操作数,进而将获得的多组变换后操作数在下一个时期按照原址方式写入原来的目标存储地址。
27.可见,在本申请的实施例中,一方面,由于傅里叶变换处理器的读写操作是按照原址方式进行的,即始终基于同一存储模块执行数据的读写操作,因此,避免了硬件资源的消耗;另一方面,基于傅里叶变换处理器中的一个存储地址能够存储多个操作数的特性,每次在一个时钟周期该傅里叶变换处理器能够同时读取在接下来的多个时钟周期待进行运算处理的多组操作数,能够始终保证蝶形运算处理的满负荷运行,极大的提高了傅里叶变换处理过程中数据吞吐率。综上所述,本申请傅里叶变换处理器能够在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高。
附图说明
28.图1为相关技术中基于流水线结构的傅里叶变换处理器结构示意图;
29.图2为相关技术中基于存储器结构的傅里叶变换处理器结构示意图;
30.图3为本申请实施例适用的无线通信系统架构示意图;
31.图4为终端ue侧与接入网gnb侧无线协议架构示意图;
32.图5为本申请实施例提出的傅里叶变换处理方法的实现流程示意图一;
33.图6为本申请实施例提出的傅里叶变换处理方法的实现流程示意图二;
34.图7为本申请实施例提出的傅里叶变换处理方法的实现流程示意图三;
35.图8为本申请实施例提出的傅里叶变换处理方法的实现流程示意图四;
36.图9为本申请实施例提出的傅里叶变换处理方法的实现流程示意图五;
37.图10为本申请实施例提出的傅里叶变换处理方法的实现流程示意图六;
38.图11为本申请实施例提出的傅里叶变换处理方法的实现流程示意图七;
39.图12为本申请实施例提出的傅里叶变换处理方法的实现流程示意图八;
40.图13为本申请实施例提出的傅里叶变换处理方法的实现流程示意图九;
41.图14为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十;
42.图15为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十一;
43.图16为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十二;
44.图17为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十三;
45.图18为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十四;
46.图19为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十五
47.图20为本申请实施例提出的傅里叶变换处理器的组成结构示意图一;
48.图21为本申请实施例提出的傅里叶变换处理器的架构示意图;
49.图22为本申请实施例提出的傅里叶变换装置的组成结构示意图二;
50.图23为本申请实施例提出的终端组成结构示意图。
具体实施方式
51.下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。可以理解的是,此处所描述的具体实施例仅用于解释相关申请,而非对该申请的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关申请相关的部分。
52.随着数字信号处理技术和大规模集成电路的发展,傅里叶变换算法广泛的应用在通信领域中。例如,一方面,移动通信系统lte下行采用ofdm调制方式;具体的,基站和终端分别采用快速傅里叶反变换ifft算法进行调制和fft算法进行解调。另一方面,lte上行采用sc
‑
fdma调制方式;具体的,基带信号在经ifft算法调制前先基于dft进行扩展,且该调制方式也应用于第五代移动通信网络(5th generation mobile networks,5g)nr中,被称为dft
‑
s
‑
ofdm。可见,傅里叶变换算法在通信领域中的重要性不言而喻。目前,在各种各样的傅里叶变换处理器中,相关技术通常采用流水线结构和基于存储器的结构来实现对数据的处理。
53.示例性的,图1为相关技术中基于流水线结构的傅里叶变换处理器结构示意图,bfi为蝶形运算单元、mem为存储单元,如图1所示,流水线结构为单路径反馈,每级蝶形运算单元与一个输入存储单元相连,除最后一级蝶形运算单元以外的每级蝶形运算单元与下一级蝶形运算单元之间连接有乘法器。
54.具体的,将上一级输出数据先储至mem中,利用bfi对mem中的数据做蝶形运算,对该运算结果通过乘法器乘以旋转因子γ便得到一级输出,之后对该输出结果继续进行下一级运算,以此类推。每级经蝶形运算单元、乘法器完整运算的输出数据将作为下一级运算的完整输入。
55.可见,流水线结构能够连续的处理数据和传输数据,不仅能够在一个时钟周期为下一级运算输入数据、同时能够读入前一级运算结果并进行当前级的蝶形运算。基于流水线结构的傅里叶变换处理器中,一组蝶形运算单元执行运算处理的时间可以等效为一个时钟周期,数据吞吐率高。
56.然而,虽然流水线结构可以实现较高的数据吞吐率,但是在数据量过大的情况下,所需的蝶形运算单元bfi的数目越多,需占用更多的硬件资源,进而导致了处理器面积和功耗增加的缺陷。进一步的,为了能够克服流水线结构所导致的硬件开销过大的缺陷,相关技术提出了一种基于存储器结构的傅里叶变换处理器。
57.示例性的,图2为相关技术中基于存储器结构的傅里叶变换处理器结构示意图,bfi为蝶形运算单元、mem为存储单元,如图2所示,存储器结构只采用一个普通位宽存储器,该普通位宽存储器作为存储单元,可以被配置为l个存储空间bank,每个bank的深度为d,每个地址位宽为b比特。该存储器的输入、输出端口分别通过切换开关switch与多个蝶形单元进行连接,多个蝶形单元之间并行连接;其中,切换开关用于对采样序列的输入和运算时中间数据的写入进行选择控制。
58.具体的,基于普通位宽存储器的傅里叶变换处理器可以从不同bank中同时读取多个数据作为一个或多个蝶形运算单元的输入,然后把一个或多个蝶形运算单元的输出按照原址方式又写回存储器的不同bank中,通过重复不断的读写存储器以完成傅里叶变换时的多级运算处理。
59.虽然基于普通位宽存储器结构的傅里叶变换处理器相比于流水线机构降低了硬件开销,但由于单一存储器地址读写时面临一定的冲突,读和写需要在两个不同的时钟周期完成,在将处理过程中的中间数据按照原址方式写入存储器时,会影响紧接着的并行数据的读取。
60.表1为基于普通位宽存储器结构的傅里叶变换处理器的数据处理流程;其中,数字编号代表输入/输出数据的组号。
61.表1
62.时钟编号012345678读地址01 2 3 4 蝶形运算 0 1 2 3 写地址
ꢀꢀ
0 1 2 3
63.基于表1可知,由于基于普通位宽存储器结构的傅里叶变换处理器一个时钟周期不能同时进行读和写操作,在一组数据完全读入之后进行蝶形运算、计算完成后进行数据输出以及计算过程中无法输出数据结算结果,其一组蝶形运算需要多个时钟周期才能处理完成,相比于流水线结构数据吞吐率低,无法保证傅里叶变换蝶形运算时的连续性和有效性。
64.另一方面,为了提升基于普通位宽存储器结构的傅里叶变换处理器的吞吐率,相关技术中进一步采用增加一块同样大小的存储器的方式来实现。具体的,从第一存储器先读取数据,并进行蝶形运算,计算完成后将中间数据写入第二存储器;之后在下一级,重新从第二存储器中进行数据读取并运算,以及运算完成后又重新写入第一存储器,不断地循环往复,以避免吞吐率的降低,即非原址方式进行数据读写。表2为采用两个普通位宽存储器结构的傅里叶变换处理器的数据处理流程;其中,括号中的数字编号代表存储器的编号。
65.表2
[0066][0067]
基于表2可知,采用两个存储器结构的傅里叶变换处理器,一个时钟周期能够同时完成进行读和写操作,数据的读取、数据的蝶形运算以及结算结果的输出,相比于一个存储器结构的傅里叶变换处理器避免了吞吐率的下降。然而,该方式虽然能够保证傅里叶变换蝶形运算时的连续性和有效性,但是需要额外提供一块存储器,也就是说,避免吞吐率下降的同时也增加硬件资源的消耗和存储器的面积。
[0068]
鉴于此,如何在减少硬件开销的同时有效避免数据吞吐速率的下降,成为一个亟待解决的技术问题。
[0069]
为了解决现有的傅里叶变换处理器结构中存在的问题,本申请实施例提供了一种傅里叶变换处理方法和处理器,终端,芯片及存储介质,具体地,傅里叶变换处理器可以傅里叶变换处理器在确定出待变换序列对应的b个存储空间和变换级数m之后,便可以将待变换序列按照一个存储地址存储多个操作数的写地址策略将待变换序列成功存储至b个存储空间中;进一步的,在进行待变换序列每一级变换处理时,傅里叶变换处理器便可以在一个时钟周期里从目标存储地址同时读取多组操作数,并在接下来的多个时钟周期中分别依次对其进行蝶形运算处理,其中,一个时钟周期运算一组操作数,进而将获得的多组变换后操作数在下一个时期按照原址方式写入原来的目标存储地址。
[0070]
可见,在本申请的实施例中,一方面,由于傅里叶变换处理器的读写操作是按照原址方式进行的,即始终基于同一存储模块执行数据的读写操作,因此,避免了硬件资源的消耗;另一方面,基于傅里叶变换处理器中的一个存储地址能够存储多个操作数的特性,每次在一个时钟周期该傅里叶变换处理器能够同时读写多个时钟周期进行运算处理的多组操作数,能够始终保证蝶形运算处理的满负荷运行,极大的提高了傅里叶变换处理过程中数据吞吐率。综上所述,本申请傅里叶变换处理器能够在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高。
[0071]
应理解,本发明实施例的技术方案本申请实施例的技术方案可以应用第五代移动通信网络(5th generation mobile networks,5g)通信系统或未来的通信系统,也可以用于其他各种无线通信系统,例如:全球移动通讯(gsm,global system of mobil ecommunication)系统、码分多址(cdma,code division multiple access)系统、宽带码分多址(wcdma,wideband code division multiple access)系统、通用分组无线业务(gprs,general packet radio service)、长期演进(lte,long term evolution)系统、lte频分双工(fdd,frequency division duplex)系统、lte时分双工(tdd,time division duplex)、通用移动通信系统(umts,universal mobile telecommunication system)等。
[0072]
示例性的,图3为本申请实施例适用的无线通信系统架构示意图,如图3所示,本申请实施例适用的无线通信系统可以包括终端100和基站200。其中,终端100可以在下行对基站200使用ifft算法调制后的信号通过fft算法进行解调;终端100也可以在上行对发送至基站200的信号通过dft算法和ifft算法进行调制。
[0073]
应理解,基站200可以是gsm系统或cdma系统中的基站(base transceiverstation,bts),也可以是wcdma系统中的基站(nodeb,nb),还可以是lte系统中的演进型基站(evolutional nodeb,enb),还可以是云无线接入网络(cloud radio access network,cran)场景下的无线控制器,或者还可以为中继站、接入点以及5g网络中的网络设备等,本申请实施例对此不作限定。
[0074]
应理解,终端100可以是用户设备(user equipment,ue)、用户单元、用户站、移动站、移动台、远方站、远程终端设备、移动设备、用户终端设备、终端设备、无线通信设备、用户代理或用户装置,终端还可以是蜂窝电话、无绳电话、会话启动协议(session initiation protocol,sip)电话、无线本地环路(wireless local loop,wll)站、个人数字处理(personal digital assistant,pda)、具有无线通信功能的手持设备、计算设备或连接到无线调制解调器的其它处理设备、车载设备、可穿戴设备、5g网络中的终端设备或者未来演进的公共陆地移动网(public land mobile network,plmn)中的终端设备等。
[0075]
应理解,在5g新空口技术中,无线接口为终端与接入网之间的接口,ue与接入网之间的通信,需要遵守接收的规范。其中,无线接口协议栈主要包括物理层、数据链路层以及网络层,具体的,物理层(physical,phy)位于无线接口最底层,提供物理介质中比特流传输所需要的所有功能,主要用于为介质访问控制层(media access control,mac)层和高层提供信息传输的服务。数据链路层主要包括mac、无线链路控制(radio link control,rlc)、分组数据汇聚协议(packet data convergence protocol,pdcp)以及服务数据调整协议(servicedataadaptationprotocol,sdap)4个子层,sdap子层位于用户面、而其他3个子层位于同时位于用户面和控制面,数据链路层介乎于物理层和网络层之间,可以在物理层提供的服务的基础上向网络层提供服务;网络层是指无线资源控制(radio resource control,rrc,rrc)层,位于接入网的控制平面,负责完成接入网与终端之间交互的所有信令处理。
[0076]
示例性的,图4为终端ue侧与接入网gnb侧无线协议架构示意图,如图4所示,针对终端ue侧与接入网gnb侧的无线协议架构包括三层和两面,其中,三层为物理层、数据链路层以及网络层,而两面则包括控制面和用户面,在5g协议栈中,控制面包括物理层、mac层、rlc层、pdcp层以及rrc层;而用户面除包含有与控制面相同的物理层、mac层、rlc层、pdcp层之外,5g协议架构中的用户面新增加了一个sdap层,可见,sdap层只用于用户面,而控制面协议栈不包含sdap层。具体的,无线协议架构中:(1)物理层向mac层提供传输信道;(2)mac层向rlc层提供逻辑信道;(3)rlc层提供给pdcp层rlc信道;(4)pdcp层向sdap层或者rrc层提供无限承载;(5)rrc层为网络高层,主要负责获取无线资源(即pdcp层提供的无线承载),并且负责使用终端ue侧与接入网gnb侧之间的rrc信令来配置rrc以下的较低层。
[0077]
需要说明的是,在本申请的实施例中,终端通过傅里叶变换处理器执行傅里叶变换处理方法的过程主要涉及物理层,傅里叶变换处理器可以通过各种硬件逻辑电路配合软件代码以在物理层通过执行傅里叶变换处理方法来实现对信号的调制/解调功能。
[0078]
具体的,在物理层执行傅里叶变换处理过程中,傅里叶变换处理器可以接收待变换序列,并将该序列先按照一定的写地址策略存储至存储模块,然后通过蝶形运算模块按照读地址策略从存储模块中的目标存储地址中读取数据并进行蝶形运算,之后将运算结果按照原址方式重新写回原来的目标存储地址,重复循环处理,直至经过多级蝶形运算处理得到该序列对应的傅里叶变换后数据,并将该傅里叶变换后数据按照一定的并行度进行输出。
[0079]
需要说明的是,在本申请的实施例中,傅里叶变化处理方法不限制于dft、ifft以及fft,该方法可应用于上行/下行信号的调制和解调过程。
[0080]
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。
[0081]
本申请一实施例提供了一种傅里叶变换处理方法,图5为本申请实施例提出的傅里叶变换处理方法的实现流程示意图一,如图5所示,在本申请的实施例中,傅里叶变换处理器执行傅里叶变换处理方法可以包括以下步骤:
[0082]
步骤100、确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数。
[0083]
在本申请的实施例中,傅里叶变换处理器可以先确定待变换序列对应的b个存储
空间以及变换级数m。
[0084]
应理解,存储空间指对完整的存储模块进行空间划分处理之后,获得的用于对待变换序列中的操作数进行存储的空间,即上述bank。在本申请的实施例中,通过对一个存储模块进行空间划分处理,便可以得到b个bank,其中b为大于1的整数。
[0085]
应理解,变换级数m指对待变换序列进行蝶形运算的总级数。一般情况下,傅里叶变换处理器需要进行至少一级的蝶形运算处理,以实现待变换序列的傅里叶变换。
[0086]
需要说明的是,在本申请的实施例中,傅里叶变化处理器可以先通过待变换序列对应的采样点数即傅里叶点数,来实现存储空间的划分以及变换级数的确定。
[0087]
具体的,在本申请的实施例中,图6为本申请实施例提出的傅里叶变换处理方法的实现流程示意图二,如图6所示,傅里叶变换处理器确定待变换序列对应的b个存储空间和变换级数m的方法包括:
[0088]
步骤101、获取待变换序列的采样点数。
[0089]
步骤102、根据采样点数确定至少一个基数,和至少一个基数对应的至少一个幂指数;其中,一个基数对应一个幂指数。
[0090]
步骤103、基于至少一个基数中的最大基数确定b个存储空间。
[0091]
步骤104、基于至少一个幂指数确定m。
[0092]
这里,待变换序列的采样点数不限制于fft下的单一基数,例如采样点数n=2α。其中,基数为2,级数m=幂指数α。
[0093]
可选的,待变换序列的采样点数不限制于dft下的混合基数,例如其中,基数包括2、3、4、5,级数m=幂指数之和(α1+α2+α3+α4)。
[0094]
应理解,在本申请的实施例中,基数为进行蝶形运算时一个蝶形运算单元的计算单位;需要说明的是,在本申请的实施例中,至少一个基数中的每一个基数为以下整数中的任意一个:2k,3k,4k,5k;其中,所述2k,3k,4k,5k均为大于1且小于16的整数。例如,如果待变换序列仅包含一种基数2,那么k可以为大于1、且小于或等于8的整数;如果待变换序列包含3种基数3、4、5,那么k为大于1、且小于或等于3的整数。
[0095]
应理解,如果基数为2k,k=2时,那么蝶形运算单元以4为计算单位,此时一个蝶形单元可从存储模块中并行读取4个操作数,并实现该4个操作数的计算处理。为了保证傅里叶变换处理器在执行待变换序列的傅里叶变换处理方法时,能够从存储模块中的多个存储空间并行读出与最大基数相同的多个操作数,傅里叶变换处理器至少保证存储空间的个数等于或者大于最大基数。在本申请的实施例中,傅里叶变换处理装置可以预先根据最大基数确定存储空间对应的空间个数b,并按照空间个数b对存储模块进行划分处理,以获得b个存储空间。
[0096]
需要说明的是,在本申请的实施例中,存储空间的划分处理还与傅里叶变换处理器当前存储地址模式相关,因此,在确定b个存储空间之前,傅里叶变换处理器需要对当前存储地址模式进行确定,进而结合存储地址模式以及最大基数确定出b个存储空间。
[0097]
需要说明的是,在本申请的实施例中,可在划分存储空间之前确定总级数m,即步骤103位于步骤104之后;也可步骤103位于步骤104之前,或者同时进行。
[0098]
具体的,图7为本申请实施例提出的傅里叶变换处理方法的实现流程示意图三,如图7所示,傅里叶变换处理器基于至少一个基数中的最大基数确定b个存储空间的方法包括
以下步骤:
[0099]
步骤103a、根据当前存储地址模式和最大基数确定空间个数b。
[0100]
步骤103b、基于空间个数b执行存储空间的划分处理,获得b个存储空间。
[0101]
可选的,存储地址模式至少包括相邻存储地址模式和间隔存储地址模式。
[0102]
可以理解的是,待变换序列是由依次排列的多个操作数构成,那么将每个操作数对应的顺序确定为该操作数对应的序号。在待变换序列中的操作数按顺序输入傅里叶变换处理器时,相邻存储模式表征将对应相邻序号的多个操作数存储至相同的存储地址,间隔存储模式则表征将对应相邻序号的操作数分别存储至不同的存储地址。
[0103]
例如,采样点数为n即待变换序列包括n个操作数,0/1同址方式则表示将对应相邻序号0和1的两个操作数存储至同一地址,而同址方式则表示将对应不同序号0和的两个操作数存储至同一地址,相应的,对应相邻序号0和1的两个操作数便不能存储至同一地址。
[0104]
需要说明的是,在本申请的实施例中,傅里叶变换处理器在结合当前存储地址模式和最大基数确定存储空间对应的划分个数时,不同的存储地址模式下,确定存储空间个数b的规则并不相同。
[0105]
具体的,图8为傅里叶变换处理方法的实现流程示意图四,如图8所示,傅里叶变化处理器根据当前存储地址模式和最大基数确定空间个数b的方法包括以下步骤:
[0106]
步骤103a1、当当前存储地址模式为相邻存储模式时,若最大基数为偶数,则将最大基数确定为空间个数b,或者,若所述最大基数为奇数,则对最大基数执行加一运算,获得空间个数b。
[0107]
步骤103a2、当当前存储地址模式为间隔存储模式时,将最大基数确定为空间个数b。
[0108]
这里,相邻存储地址模式下,如果最大基数为偶数,那么傅里叶变换处理器便可以确定按照最大基数对存储模块执行存储空间的划分处理,进而划分出与最大基数相同的b个存储空间。如果最大基数为奇数,那么傅里叶变换处理器便可以对最大基数进行加1运算,并基于求和结果执行存储空间的划分处理,进而划分出与该求和结果相同的b个存储空间。
[0109]
这里,间隔存储地址模式下,无需考虑最大基数的奇偶性,傅里叶变换处理器可以直接按照最大基数执行存储空间的划分处理,进而划分出与最大基数相同的b个存储空间。
[0110]
进一步的,在本申请的实施例中,傅里叶变换处理器在确定出待变换序列对应的b个存储空间以及蝶形运算级数m之后,可以进一步按照写策略执行待变换序列的存储。
[0111]
步骤110、按照写地址策略将待变换序列中的操作数存储至b个存储空间;其中,写地址策略用于在一个存储地址存储多个操作数。
[0112]
在本申请的实施例中,傅里叶变换处理器在确定出待变换序列对应的b个存储空间以及蝶形运算级数m之后,傅里叶变换处理器可以进一步按照写地址策略将待变换序列中的操作数存储至该b个存储空间。
[0113]
应理解,写地址策略指对待变换序列中的操作数进行存储的方式,主要包括两个方面,一方面是“写多少”,即一个时钟周期写地址的单位量,一个时钟周期能够向b个存储空间中存储多少操作数;另外一个方面是“写到哪”,即将待变换序列中的操作数写入b个存储空间中的哪一个地址。
[0114]
需要说明的是,在本申请的实施例中,傅里叶变换处理器采用的存储模块为多倍位宽存储器;不限制于双倍位宽存储器、三倍位宽存储器以及四倍位宽存储器等等。例如,相比于上述普通位宽存储器,采用双倍位宽存储器其存储空间深度为d/2,每个地址位宽为双倍位宽,即2b比特,高低位分别存储一个不同的b比特操作数。
[0115]
进一步的,在本申请的实施例中,结合多倍位宽存储器的存储能力,傅里叶变换处理器可以按照对应的存储策略执行待变换序列的存储。具体的,基于多倍位宽存储器对应的多倍地址位宽,傅里叶变换处理器可以在其b个存储空间中的任意一个地址存储至少两个操作数。
[0116]
需要说明的是,在本申请的实施例的陈述中,均以双倍位宽存储器为示例对傅里叶变换处理方法的具体过程进行阐述。
[0117]
进一步的,傅里叶变换处理器在按照预设存储策略将待变换序列中的操作数存储至b个存储空间之后,可以进一步执行操作数的读取处理和运算处理。
[0118]
步骤120、当进行第m级变换处理时,在第i时钟周期从b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,得到r组变换后数据;其中,r为大于1的整数,m为大于0,且小于或等于m的整数。
[0119]
在本申请的实施例中,傅里叶变换处理器在按照预设存储策略将待变换序列中的操作数存储至b个存储空间之后,傅里叶变化处理器可以在进行第m级变换处理时,先在第i时钟周期从b个存储空间中的第一存储地址读取r组操作数,然后在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,进而获得r组变换后数据。
[0120]
可以理解的是,在将待变换序列对应的全部操作数存储至b个存储空间之后,接下来傅里叶变换处理器将对该全部的操作数,执行与级数和至少一个基数相对应的蝶形运算处理。由于进行某一基数对应的该级蝶形运算时,可能经一次蝶形运算处理并不能完成全部操作数的蝶形运算,需要一部分一部分流水的执行运算处理,从而进一步完成全部操作数的该级蝶形运算。
[0121]
具体的,在本申请的实施例中,傅里叶变换处理器在进行第m级蝶形运算处理时,可以在第i时钟周期先从b个存储空间中的第一存储地址中读取r组操作数。这里,第一存储地址即为b个存储空间中的部分存储地址,r组操作数即为待变换序列中的全部操作数中的任意一部分数据。
[0122]
进一步地,在本申请地实施例中,傅里叶变换处理器便可以在接下来地r个时钟周期分别对读取的r组操作数进行r次蝶形运算处理,进而得到r组变换后数据。也即是说,傅里叶变换处理器不再是每一个时钟周期仅读取能够在一个时钟周期进行蝶形运算处理的一组操作数,而是可以在一个时钟周期同时读取多个时钟周期进行蝶形运算的多组操作数。
[0123]
可以理解的是,由于傅里叶变换处理器中蝶形运算单元的运算能力是有限的,那么从双倍位宽存储器中同时读取到的两组待运算数据将会在接下来的两个时钟周期作为两组蝶形运算单元的输入,即一个时钟周期仅对一组操作数进行运算处理。那么在预先从第一存储地址同时读取出多个时钟周期运算的多组操作数之后,傅里叶变换处理器可以先将多组操作数进行缓存,然后一组一组按照时钟周期流水的进行蝶形运算。
[0124]
需要说明的是,在本申请的实施例中,傅里叶变换处理器一个时钟周期读取的操
作数的组数是与存储模块的存储能力相关的。如双倍位宽存储器可以在其b个存储空间中的任意一个地址存储两个操作数,那么基于双倍位宽存储器的傅里叶变换处理器在一个时钟周期便可以读取两组操作数。
[0125]
进一步地,在本申请地实施例中,傅里叶变换处理器在进行第m级变换处理,在第i时钟周期从b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,得到r组变换后数据之后,便可以进一步对变换后的数据进行存储。
[0126]
步骤130、在第(i+r+1)时钟周期将r组变换后数据存储至第一存储地址。
[0127]
在本申请的实施例中,傅里叶变换处理器在第i时钟周期从b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,得到r组变换后数据之后,傅里叶变换处理器便可以进一步将第(i+r+1)时钟周期将r组变换后数据存储至第一存储地址。
[0128]
需要说明的是,在本申请的实施例中,傅里叶变换处理器对蝶形运算处理后的中间数据按照原址方案进行存储。具体的,傅里叶变换处理器对从第一存储地址读取的操作数进行变换处理得到变换后的中间数据之后,便将该中间数据又存储回原来的第一存储地址中。也就是说,傅里叶变换处理器不会为运算处理后的中间数据分配新的存储空间,也不会将其中间数据存储至其他存储模块,而是会通过该地址运算后的中间数据替换掉原先运算前的历史数据。示例性的,表3为基于双倍位宽存储器结构的傅里叶变换处理器的数据处理流程;其中,数字编号代表输入/输出数据的组号。
[0129]
表3
[0130]
时钟编号012345678读地址0,1 2,3 4,5 6,7 8,9蝶形运算 01234567写地址
ꢀꢀꢀ
0,1 2,3 4,5 [0131]
基于表3可知,由于双倍位宽存储器相比于普通位宽存储器的地址线宽加倍,那么每次可以读写的数据为普通位宽存储器读写数据的两倍,进而在一个时钟周期,便可以从该存储模块的目标地址中同时读取两组待运算数据,作为在接下来两个时钟周期进行蝶形运算处理的两组待运算数据,并在运算完成后将变换后的两组数据在一个时钟周期同时将两组变换后数据又存储至原来的目标地址。
[0132]
本申请实施例提供了一种傅里叶变换处理方法,傅里叶变换处理器在确定出待变换序列对应的b个存储空间和变换级数m之后,便可以将待变换序列按照一个存储地址存储多个操作数的写地址策略将待变换序列成功存储至b个存储空间中;进一步的,在进行待变换序列每一级变换处理时,傅里叶变换处理器便可以在一个时钟周期里从目标存储地址同时读取多组操作数,并在接下来的多个时钟周期中分别依次对其进行蝶形运算处理,其中,一个时钟周期运算一组操作数,进而将获得的多组变换后操作数在下一个时期按照原址方式写入原来的目标存储地址。
[0133]
可见,在本申请中,一方面,由于傅里叶变换处理器的读写操作是按照原址方式进行的,即始终基于同一存储模块执行数据的读写操作,因此,避免了硬件资源的消耗;另一方面,基于傅里叶变换处理器中的一个存储地址能够存储多个操作数的特性,每次在一个
时钟周期该傅里叶变换处理器能够同时读写多个时钟周期进行运算处理的多组操作数,能够始终保证蝶形运算处理的满负荷运行,极大的提高了傅里叶变换处理过程中数据吞吐率。综上所述,本申请傅里叶变换处理器能够在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高。
[0134]
基于上述实施例,在本申请的再一实施例中,图9为本申请实施例提出的傅里叶变换处理方法的实现流程示意图五,如图9所示,在本申请的实施例中,若当前存储模式为相邻存储模式,傅里叶变换处理器按照写地址策略将待变换序列中的操作数存储至b个存储空间的方法还可以包括以下步骤:
[0135]
步骤111、根据最大基数和预设存储参数确定第一写地址并行度;其中,预设存储参数表征存储模块的存储能力。
[0136]
应理解,写地址并行度指傅里叶变换处理器在进行待变换序列的存储时,一个时钟周期写入存储地址中的操作数的个数,也就是写地址个数。
[0137]
应理解,预设存储参数指存储模块一个地址中能够写入的操作数个数,即单位地址存储个数,表征了该存储模块的存储能力。
[0138]
具体的,当存储模式为相邻存储地址模式时,在待变换序列按顺序输入的过程中,存储至同一存储地址高低位的两个相邻的操作数可以同时进行存储,此时,傅里叶变换处理器一次写地址操作可以写入两个操作数。具体的,在本申请的实施例中,傅里叶变换处理器可以计算最大基数与预设存储参数的求积结果,并在一个时钟周期并行写入与该求积结果相同的操作数。
[0139]
示例性的,假定待变换序列对应的最大基数为16,用于表征双倍位宽存储器存储能力的存储参数为2,那么相邻存储模式时,一次写操作可以同时存储序号k和序号(k+1)对应的操作数,那么基于双倍位宽存储器的傅里叶变换处理器其写地址并行度为32,也就是说一个时钟周期可以将32个操作数写入双倍位宽存储器中。
[0140]
步骤112、根据待变换序列中的操作数的序号和m,在b个存储空间中确定第一写地址。
[0141]
应理解,写地址指傅里叶变换处理器在进行待变换序列的存储时,每个操作数对应的存储地址。
[0142]
需要说明的是,在本申请的实施例中,傅里叶变换处理装置可以结合待变换序列中的每个操作数的排列序号以及级数m对每个操作数进行相应的地址参数分解处理,进而基于分解后的地址参数进一步确定写地址。
[0143]
具体的,在本申请的实施例中,图10为本申请实施例提出的傅里叶变换处理方法的实现流程示意图六,如图10所示,傅里叶变换处理器根据待变换序列中的操作数的序号和m,在b个存储空间中确定第一写地址的方法可以包括以下步骤:
[0144]
步骤112a、将待变换序列中的操作数的序号分解成m个,获得m个参数。
[0145]
步骤112b、根据m个参数和空间个数b,从b个存储空间中确定第一目标存储空间。
[0146]
步骤112c、根据m个参数和至少一个基数从第一目标存储空间中确定第一目标存储地址。
[0147]
步骤112d、根据m个参数中的第m个参数从第一目标存储地址中确定第一写地址。
[0148]
这里,傅里叶变换处理器可以先按照预设地址分解算法将每个操作数对应的序号
分解为与级数m相同的m个地址参数,具体运算方式如公式(1)所示:
[0149][0150]
其中,n表示序号,(n0,n1,
…
,n
m
‑1)表示分解后的m个地址参数,n
m
表示第m位参数,n
j
表示第j级的基数。
[0151]
进一步的,获得每个操作数对应的m个地址参数之后,傅里叶变换处理器可以先确定m个参数中第m个参数,即n
m
‑1的奇偶性。
[0152]
一方面,如果n
m
‑1为偶数,那么傅里叶变换处理器可以计算m个地址参数的求和结果,并基于求和结果对最大基数进行取模运算操作,从而根据得到的取模结果便可以确定出操作数应存储至哪一个bank,也就是哪一个存储空间。具体运算方式如公式(2)所示:
[0153]
bi=<n0+n1+
…
+n
m
‑1>
b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0154]
其中,bi表示存储空间的具体位置,b表示存储空间的总个数。
[0155]
另一方面,如果n
m
‑1为奇数,那么傅里叶变换处理器可以先对第m个参数,即n
m
‑1进行减一运算,获得差值;然后计算该差值与前m
‑
1个地址参数的求和结果,进而基于该求和结果对最大基数进行取模运算操作,从而根据得到的取模结果便可以确定出操作数应存储至哪一个bank,也就是哪一个存储空间。具体运算方式如公式(3)所示:
[0156]
bi=<n0+n1+
…
+(n
m
‑1‑
1)>
b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0157]
应理解,由于存储模块中,一个bank包括多个偏移地址位,因此,在确定出操作数对应的存储空间之后,傅里叶变换处理器还需要继续确定操作数在存储空间中的具体偏移位置,也就是从存储空间中确定出存储地址。在本申请的实施例中,傅里叶变换处理器可以继续结合m个参数和至少一个基数以在存储空间中确定存储地址,具体运算公式如公式(4)所示:
[0158][0159]
其中,a表示存储地址的具体位置。
[0160]
需要说明的是,在本申请的实施例中,由于存储模块为双倍位宽存储器,即在一个存储地址可以存储两个操作数,分别存储至高位和低位,因此,傅里叶变换处理器在写地址的过程中,还需确定数据是存储至地址高位还是地址地位。
[0161]
具体的,图11为本申请实施例提出的傅里叶变换处理方法的实现流程示意图七,如图11所示,傅里叶变换处理器根据m个参数中的第m个参数从第一目标存储地址中确定第一写地址的方法可以包括以下步骤:
[0162]
步骤112d1、若第m个参数为偶数,则确定第一写地址为第一目标存储地址中的高位地址。
[0163]
步骤112d2、若第m个参数为奇数,则确定第一写地址为第一目标存储地址中的低位地址。
[0164]
详细的,在本申请的实施例中,傅里叶变换处理器可以根据每个操作数对应的m个参数中的第m个参数确定当前操作数存储至高位还是低位。可选的,当第m个参数为偶数,此时,标志位msb=0,将操作数存储至地址高位;当第m个参数为奇数,此时,标志位msb=1,将操作数存储至地址低位。
[0165]
需要说明的是,在本申请的实施例中,步骤112不限定于步骤111之后,步骤112也
可以在步骤111之前,步骤112也可以与步骤111同步进行。
[0166]
步骤113、基于第一写地址并行度将待变换序列中的操作数存储至第一写地址。
[0167]
这里,傅里叶变换处理器在确定出写地址并行度和操作数对应的写地址之后,便可以按照写地址并行度将相应的操作数写入对应的地址中,以完成操作数的存储。
[0168]
基于上述实施例,在本申请的再一实施例中,图12为本申请实施例提出的傅里叶变换处理方法的实现流程示意图八,如图12所示,在本申请的实施例中,若当前存储模式为间隔存储模式,傅里叶变换处理器按照写地址策略将待变换序列中的操作数存储至b个存储空间的方法还可以包括以下步骤:
[0169]
步骤114、将最大基数确定为第二写地址并行度。
[0170]
应理解,在本申请的实施例中,当存储模式为间隔存储地址模式时,在待变换序列按顺序输入的过程中,存储至同一存储地址高低位的两个操作数无法同时进行存储,此时,傅里叶变换处理器一次写地址操作只能写入一个操作数,也就是写入地址高位的操作数或者写入地址低位的操作数。具体的,在本申请的实施例中,傅里叶变换处理器可以在一个时钟周期并行写入与最大基数相同的操作数。
[0171]
示例性的,假定待变换序列对应的最大基数为16,用于表征双倍位宽存储器存储能力的存储参数为2,那么间隔存储模式时,存储于同一地址的序号k和序号(n/2+k)无法同时存储,此时,基于双倍位宽存储器的傅里叶变换处理器其写地址并行度仍然为16,也就是说一个时钟周期可以将16个操作数写入双倍位宽存储器中。
[0172]
步骤115、根据待变换序列中的操作数的序号和m,在b个存储空间中确定第二写地址。
[0173]
需要说明的是,在本申请的实施例中,傅里叶变换处理装置可以结合待变换序列中的每个操作数的排列序号以及级数m对每个操作数进行相应的地址参数分解处理,进而基于分解后的地址参数进一步确定写地址,地址分解公式如公式(1)所示。
[0174]
具体的,在本申请的实施例中,图13为本申请实施例提出的傅里叶变换处理方法的实现流程示意图九,如图13所示,傅里叶变换处理器根据待变换序列中的操作数的序号和m,在b个存储空间中确定第二写地址的方法可以包括以下步骤:
[0175]
步骤115a、将待变换序列中的操作数的序号分解成m个,获得m个参数。
[0176]
步骤115b、根据m个参数、空间个数b和至少一个基数中的第一个基数,从b个存储空间中确定第二目标存储空间。
[0177]
步骤115c、根据m个参数、至少一个基数和第一个基数从第二目标存储空间中确定第二目标存储地址。
[0178]
步骤115d、根据m个参数中的第1个参数从第二目标存储地址中确定第二写地址。
[0179]
这里,傅里叶变换处理器基于公式(1)先将每个操作数对应的序号分别分解为m个地址参数,获得每个操作数对应的m个地址参数之后,傅里叶变换处理器可以先计算至少一个基数中的最小基与2的求商结果,并采用m个参数中的第一个参数对该求商结果进行取模操作,具体运算方式如公式(5)所示:
[0180][0181]
其中,n
′0表示取模运算结果,n0表示m个地址分解参数中的第一个参数,至少一个基数中的最小基与2的求商结果。
[0182]
进一步的,傅里叶变换处理器可以先计算n
′0与剩余(m
‑
1)个地址参数的求和结果,并基于求和结果对最大基数进行取模运算操作,从而根据得到的取模运算结果便可以确定出操作数应存储至哪一个bank,也就是哪一个存储空间。具体运算方式如公式(6)所示:
[0183]
bi=<n
′0+n1+
…
+n
m
‑1>
b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0184]
其中,bi表示存储空间的具体位置,b表示存储空间的总个数。
[0185]
应理解,由于存储模块中,一个bank包括多个偏移地址位,因此,在确定出操作数对应的存储空间之后,傅里叶变换处理器还需要继续确定操作数在存储空间中的具体偏移位置,也就是从存储空间中确定出存储地址。在本申请的实施例中,傅里叶变换处理器可以继续结合m个参数和至少一个基数以在存储空间中确定存储地址,具体运算公式如公式(7)所示。
[0186][0187]
其中,a表示存储地址的具体位置。
[0188]
需要说明的是,在本申请的实施例中,由于存储模块为双倍位宽存储器,即在一个存储地址可以存储两个操作数,分别存储至高位和低位,因此,傅里叶变换处理器在写地址的过程中,还需确定数据是存储至地址高位还是地址地位。
[0189]
具体的,图14为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十,如图14所示,傅里叶变换处理器根据m个参数中的第1个参数从第二目标存储地址中确定第二写地址的方法可以包括以下步骤:
[0190]
步骤115d1、计算第一个基数与2的求商结果。
[0191]
步骤115d2、若第1个参数大于或等于求商结果,则确定第二写地址为第二目标存储地址中的高位地址。
[0192]
步骤115d3、若第1个参数小于求商结果,则确定第二写地址为第二目标存储地址中的低位地址。
[0193]
详细的,在本申请的实施例中,傅里叶变换处理器可以根据每个操作数对应的m个参数中的第1个参数确定当前操作数存储至高位还是低位。具体的,傅里叶变换处理器可以先至少一个基数中的最小基与2的求商结果,当第1个参数大于或者等于该求商结果时,此时将操作数存储至地址高位;当第1个参数小于该求商结果时,此时将操作数存储至地址低位。
[0194]
需要说明的是,在本申请的实施例中,当第1个参数大于或者等于该求商结果时,此时将操作数存储至地址低位;当第1个参数小于该求商结果时,此时将操作数存储至地址高位。
[0195]
需要说明的是,在本申请的实施例中,步骤115不限定于步骤114之后,步骤115也可以在步骤114之前,步骤115也可以与步骤114同步进行。
[0196]
步骤116、基于第二写地址并行度将待变换序列中的操作数存储至第二写地址。
[0197]
这里,傅里叶变换处理器在确定出写地址并行度和操作数对应的写地址之后,便可以按照写地址并行度将相应的操作数写入对应的地址中,以完成操作数的存储。
[0198]
本申请实施例提供了一种傅里叶变换处理方法,傅里叶变换处理器在确定出待变换序列对应的b个存储空间和变换级数m之后,便可以将待变换序列按照一个存储地址存储
多个操作数的写地址策略将待变换序列成功存储至b个存储空间中,极大的提高了傅里叶变换处理过程中数据吞吐率,智能性更高。
[0199]
基于上述实施例,在本申请的再一实施例中,图15为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十一,如图15所示,在本申请的实施例中,若当前存储模式为相邻存储模式,傅里叶变换处理器在第i个时钟周期从所述b个存储空间中的第一存储地址读取r组操作数(步骤120a)的方法还可以包括以下步骤:
[0200]
步骤120a1、当进行第m级变换处理时,若m大于0且小于m,则根据当前基数和空间个数b确定第一运算并行度;其中,运算并行度表征一个时钟周期进行多组蝶形运算。
[0201]
步骤120a2、根据空间个数b、当前基数以及第一运算并行度,确定第一运算并行步长;其中,运算并行步长表征多组蝶形运算中、相邻两组蝶形运算对应的存储空间间隔值。
[0202]
步骤120a3、按照第一运算并行度和第一运算并行步长,从第一存储地址读取r组操作数。
[0203]
应理解,相关技术中,傅里叶点数为n点,当第m级变换处理对应的当前基数为n
m
时,所需的蝶形基运算次数为在运算处理不做并行的情况下,所需的流水线时钟周期也约为导致在傅里叶点数较大时,数据处理过程存在很高的延时。因此,在本申请的实施例中,为了降低傅里叶变换处理的延时,傅里叶变换处理器采用蝶形运算并行处理的方案。
[0204]
这里,运算并行度表征傅里叶变换处理器每一个时钟周期能够同时进行多组蝶形运算处理。在本申请的实施例中,傅里叶变换处理器可以并行读取多个蝶形运算单元的多个输入数据,进而在一个时钟周期并行处理多个输入数据。
[0205]
需要说明的是,在本申请的实施例中,蝶形运算处理的并行度与当前级数m相关。具体的,当存储模式为相邻存储模式时,傅里叶变换处理器可以判断当前级数m是否等于m,进而根据判断结果确定蝶形运算的并行度。
[0206]
具体的,在本申请的实施例中,当当前级数m小于m时,傅里叶变换处理器可以结合存储空间的个数b以及当前第m级蝶形运算处理的基数n
m
进一步确定蝶形运算处理的并行度,具体运算公式如公式(8)所示:
[0207]
p
m
*n
m
≤b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0208]
其中,p
m
为第m级蝶形运算处理的并行度,n
m
为第m级运算处理的基数。
[0209]
需要说明的是,在本申请的实施例中,不同基数对应的蝶形运算的并行度不同。
[0210]
可见,相比于相关技术中每次仅读取一个蝶形运算单元的输入数据的方案,本申请傅里叶变换处理器并行蝶形运算处理的数据吞吐率更高,处理速度更快。
[0211]
应理解,蝶形运算的并行步长表征傅里叶变换处理器每一个时钟周期同时进行多组蝶形运算处理时,每相邻两组操作数中的第一个操作数所对应的存储空间的间隔差值。具体运算公式如公式(9)和公式(10)所示:
[0212]
s
m
≥n
m
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0213]
p
m
s
m
≤b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0214]
其中,s
m
为第m级蝶形运算处理的并行步长。
[0215]
例如,存储空间个数b=12,第m级基数n
m
=4,那么傅里叶变换处理器可以确定蝶形运算的并行度p
m
=3,并行步长s
m
=4;对于存储空间个数b=12,如果第m级基数n
m
=3,那
么蝶形运算的并行度p
m
=4,并行步长s
m
=3。
[0216]
进一步的,在本申请的实施例中,确定出运算并行度和运算并行步长止之后,傅里叶变换处理器便可以进一步基于该运算并行度和步长从第一存储地址中进行r组操作数的读取,并在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理,得到r组变换后数据(120b)。
[0217]
需要说明的是,在本申请的实施例中,当m小于m时,如果存储模块为双倍位宽存储器时,那么傅里叶变换处理器确定运算并行度为p
m
,且傅里叶变换处理器可以在一个时钟周期读取2p
m
n
m
个操作数,此时r等于2;如果存储模块为k倍位宽存储器时,那么傅里叶变换处理器确定运算并行度为p
m
,且可以在一个时钟周期读取kp
m
n
m
个操作数,此时r=k。
[0218]
进一步的,傅里叶变换处理器便可以按照并行步长和运算并行度对r组操作数中的每一组操作数按照蝶形运算单元的计算单位,即n
m
进行操作数的分组并行运算,以在r个时钟周期完成r组蝶形运算处理。
[0219]
基于上述实施例,在本申请的再一实施例中,图16为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十二,如图16所示,在本申请的实施例中,若当前存储模式为相邻存储模式,傅里叶变换处理器在第i个时钟周期从所述b个存储空间中的第一存储地址读取r组操作数的方法还可以包括以下步骤:
[0220]
步骤120a4、当进行第m级变换处理时,若m等于m,则按照最大基数和预设存储参数从第一存储地址读取r组操作数。
[0221]
具体的,当傅里叶变换处理进行最后一级蝶形运算处理时,也就是m等于m时,傅里叶变换处理器此时不再需要进行蝶形运算的并行处理,无需确定运算并行度和并行步长,可以计算最大基数和上述存储参数的求积结果,并在一个时钟周期读取与该求积结果等同的操作数,进而在接下来的r个时钟周期进行蝶形运算处理。
[0222]
基于上述实施例,在本申请的再一实施例中,图17为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十三,如图17所示,在本申请的实施例中,若当前存储模式为间隔存储模式,傅里叶变换处理器在第i个时钟周期从所述b个存储空间中的第一存储地址读取r组操作数的方法还可以包括以下步骤:
[0223]
步骤120a5、当进行第m级变换处理时,若m等于1,则根据求商结果和b确定第二运算并行度。
[0224]
步骤120a6、根据b、求商结果以及第二运算并行度,确定第二运算并行步长。
[0225]
步骤120a7、根据第二运算并行度和第二运算并行步长,从第一存储地址读取r组操作数。
[0226]
需要说明的是,在本申请的实施例中,蝶形运算处理的并行度与当前级数m相关。具体的,当存储模式为间隔存储模式时,傅里叶变换处理器可以判断当前级数m是否等于1,进而根据判断结果确定蝶形运算的并行度。
[0227]
具体的,在本申请的实施例中,当当前级数m等于1时,傅里叶变换处理器可以先计算至少一个基数中的第一个基数和2的求商结果,然后结合存储空间的个数b以及该求商结果进一步确定蝶形运算处理的并行度,具体运算公式如公式(11)所示:
[0228][0229]
其中,p1为第1级蝶形运算处理的并行度,n0为第一个基数。
[0230]
具体的,并行步长的运算公式如公式(12)和公式(13)所示:
[0231][0232]
p1s1≤b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0233]
其中,s1为第1级蝶形运算处理时的并行步长。
[0234]
进一步的,在本申请的实施例中,确定出运算并行度和运算并行步长止之后,傅里叶变换处理器便可以进一步基于该运算并行度和步长在一个时钟周期从第一存储地址读取r组操作数。
[0235]
需要说明的是,在本申请的实施例中,当m等于1时,若存储模块为双倍位宽存储器,则傅里叶变换处理器可以确定运算并行度为p1,傅里叶变换处理器便可以在一个时钟周期读取p1n1个操作数,并按照并行步长和运算并行度对r组操作数中的每一组操作数进行分组并行运算,以在r个时钟周期完成r组蝶形运算处理。
[0236]
基于上述实施例,在本申请的再一实施例中,图18为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十三,如图18所示,在本申请的实施例中,若当前存储模式为间隔存储模式,傅里叶变换处理器在第i个时钟周期从所述b个存储空间中的第一存储地址读取r组操作数的方法还可以包括以下步骤:
[0237]
步骤120a8、当进行第m级变换处理时,若m大于1、且小于或等于m,则根据当前基数和b确定第二运算并行度。
[0238]
步骤120a9、根据b、当前基数以及第二运算并行度,确定第二运算并行步长。
[0239]
步骤120a10、按照第二运算并行度和第二运算并行步长,从第一存储地址读取r组操作数。
[0240]
具体的,在本申请的实施例中,当当前级数m大于1、且小于或等于m时,傅里叶变换处理器可以结合存储空间的个数b以及当前第m级蝶形运算处理的基数进一步确定蝶形运算处理的并行度,以及进一步确定运算并行步长。具体运算公式如公式(8)、公式(9)以及公式(10)所示。
[0241]
需要说明的是,在本申请的实施例中,当m大于1、且小于或等于m时,如果存储模块为双倍位宽存储器时,那么傅里叶变换处理器确定运算并行度为p
m
,且傅里叶变换处理器可以在一个时钟周期读取2p
m
n
m
个操作数,此时r等于2;如果存储模块为k倍位宽存储器时,那么傅里叶变换处理器确定运算并行度为p
m
,且可以在一个时钟周期读取kp
m
n
m
个操作数,此时r=k。
[0242]
进一步的,傅里叶变换处理器便可以按照并行步长和运算并行度对r组操作数中的每一组操作数按照蝶形运算单元的计算单位,即n
m
进行操作数的分组并行运算,以在r个时钟周期完成r组蝶形运算处理。
[0243]
本申请实施例提供了一种傅里叶变换处理方法,傅里叶变换处理器在进行待变换序列每一级变换处理时,傅里叶变换处理器便可以在一个时钟周期里从目标存储地址同时读取多组操作数,并在接下来的多个时钟周期中分别依次对其进行蝶形运算处理,其中,一个时钟周期运算一组操作数,进而将获得的多组变换后操作数在下一个时期按照原址方式写入原来的目标存储地址。傅里叶变换处理器能够同时读写多个时钟周期进行运算处理的多组操作数的特性,能够始终保证蝶形运算处理的满负荷运行,有效保证上下行数据吞吐速率,智能性更高。
[0244]
基于上述实施例,在本申请的再一实施例中,图19为本申请实施例提出的傅里叶变换处理方法的实现流程示意图十五,如图19所示,在本申请的实施例中,傅里叶变换处理器执行傅里叶变换处理的方法还可以包括以下步骤:
[0245]
步骤140、在第(i+r)个时钟周期从第二存储地址继续读取r组操作数;其中,第二存储地址为b个存储空间中、第一存储地址以外的地址。
[0246]
步骤150、继续在第(i+r+1)时钟周期至第(i+2r)时钟周期依次执行r组操作数的蝶形运算处理,并在第(i+2r+1)时钟周期执行r组变换后数据的存储处理。
[0247]
步骤160、重复上述步骤,直至将第m级中待变换序列对应的全部变换后数据存储至b个存储空间。
[0248]
具体的,在本申请的实施例中,傅里叶变换处理器在第(i+1)时钟周期至第(i+r)时钟周期依次对r组操作数进行蝶形运算处理的过程中,当运算处理执行至第(i+r)时钟周期时,傅里叶变换处理器便可以在第(i+r)时钟周期执行最后一组操作数的蝶形运算处理的同时,进行下一轮r组操作数的读取处理,那么在接下来的第(i+r+1)时钟周期至第(i+2r)时钟周期可以保证蝶形运算处理的满负荷运行。
[0249]
应理解,傅里叶变换处理器可以在第(i+r)时钟周期从存储空间中、与第一存储地址不同的第二存储地址中继续读取待变换序列中的其他r组操作数。
[0250]
进一步的,傅里叶变换处理器可以重复上述步骤,在运算处理执行至第(i+2r)时钟周期时,从不同于第一存储地址、第二存储地址的第三存储地址中继续读取p组操作数,并在接下来的第(i+2r+1)时钟周期至第(i+3r)时钟周期进行蝶形运算处理,以始终保证蝶形运算处理的满负荷运行。
[0251]
可见,傅里叶变换处理器在每间隔r个时钟周期,依次处理一轮r组操作数的运算处理的过程中,在处理每一轮r组操作数中的最后一组操作数的同时,都会读取下一轮运算处理的r组操作数,持续进行蝶形运算处理,从而始终保持蝶形运算处理的满负荷运行。
[0252]
应理解,傅里叶变换处理器在r个时钟周期完成每一轮r组操作数的蝶形运算处理之后,便会在下一个时钟周期将获得的r组变换后数据按照原址方式进行存储,循环往复,直至将第m级中待变换序列对应的全部变换后数据存储至b个存储空间。
[0253]
进一步地,在本申请的实施例中,傅里叶变换处理器在完成待变换序列的第m级变换处理之后,傅里叶变换处理器可以按照上述同样的数据读取以及原址存储方式,继续执行待变换序列的第(m+1)级变换处理,直至完成第m级变换处理,并将得到待变换序列对应的目标变换后数据存储至b个存储空间。
[0254]
应理解,傅里叶变换处理器将获得的目标变换后数据存储至b个存储空间之后,便可以将变换后数据按照预设输出规则进行输出。可选的,预设输出规则可以是按照以至少一个基数中的第一个基数作为输出并行度对目标变换后数据进行输出。
[0255]
本申请实施例提供了一种傅里叶变换处理方法,其傅里叶变换处理器按照原址方式执行数据的读写操作,并且每次在一个时钟周期,该傅里叶变换处理器能够同时读写多个时钟周期进行运算处理的多组操作数,能够始终保证蝶形运算处理的满负荷运行,极大的提高了傅里叶变换处理过程中数据吞吐率。实现了在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高。
[0256]
基于上述实施例,在本申请的再一实施例中,图20为本申请实施例提出的傅里叶
变换处理器的组成结构示意图一,如图20所示,本申请实施例提出的傅里叶变换处理器10可以包括地址管理模块11、蝶形运算模块12以及存储模块13,
[0257]
所述地址管理模块11,用于确定待变换序列对应的b个存储空间和变换级数m,以及按照写地址策略将所述待变换序列中的操作数存储至所述存储模块13中的所述b个存储空间;其中,b为大于1的整数,m为大于或等于1的整数;所述写地址策略用于在所述存储模块13中的一个存储地址存储多个操作数;
[0258]
所述地址管理模块11,还用于当进行第m级变换处理时,在第i时钟周期从所述存储模块13中的所述b个存储空间中的第一存储地址读取r组操作数;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
[0259]
所述蝶形运算模块12,用于在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;
[0260]
所述地址管理模块11,用于在第(i+r+1)时钟周期将所述r组变换后数据存储至所述存储模块13中的所述第一存储地址。
[0261]
基于上述实施例,在本申请的再一实施例中,图21为本申请实施例提出的傅里叶变换处理器的架构示意图,如图21所示,首先,傅里叶变换处理器控制复用器switcha为第一状态,此时傅里叶变换处理器经由地址管理模块先将待变换序列中的操作数按照写地址并行度全部存储至存储模块中的b个存储空间中,然后控制复用器switcha为第二状态,switchb为第一状态,此时不再进行新的操作数的输入,开始进行数据蝶形运算处理流程。具体的,当前在进行待变换序列中操作数的每一级的蝶形运算处理时,傅里叶变换处理器先经由地址管理模块按照读地址并行度从存储模块中b个存储空间中的特定地址中读取特定操作数,并输入蝶形运算模块进行运算处理,并将获得的特定变换后数据按照原址方式存储回存储模块中,直到全部输入数据被遍历,完成一级运算处理。继续进行其他级的运算处理,循环往复,直至完成最后一级蝶形运算处理之后,傅里叶变换处理器便可以获得待变换序列对应的傅里叶目标变换后数据,傅里叶变换处理器控制复用器switchb为第二状态,不再从存储模块读取数据输入至蝶形运算模块,而是按照输出并行度将目标变换后数据从存储模块中的b个存储空间进行输出。
[0262]
本申请实施例提供了一种方法,基于上述实施例,在本申请的另一实施例中,图22为本申请实施例提出的傅里叶变换装置的组成结构示意图二,如图22示,本申请实施例提出的傅里叶变换处理器10可以包括确定单元14、存储单元15、读取单元16、运算单元17、获取单元18、处理单元19以及输出单元110,
[0263]
所述确定单元14,用于确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;
[0264]
所述存储单元15,用于按照写地址策略将所述待变换序列中的操作数存储至所述b个存储空间;其中,所述写地址策略用于在一个存储地址存储多个操作数;
[0265]
所述读取单元16,用于当进行第m级变换处理时,在第i时钟周期从所述b个存储空间中的第一存储地址读取r组操作数;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
[0266]
所述运算单元17,用于在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;
[0267]
所述存储单元15,还用于在第(i+r+1)时钟周期将所述r组变换后数据存储至所述第一存储地址。
[0268]
进一步地,在本申请的实施例中,所述确定单元14,具体用于获取所述待变换序列的采样点数;以及根据所述采样点数确定至少一个基数,和所述至少一个基数对应的至少一个幂指数;其中,一个基数对应一个幂指数;以及基于所述至少一个基数中的最大基数确定所述b个存储空间;以及基于所述至少一个幂指数确定所述m。
[0269]
进一步地,在本申请的实施例中,所述至少一个基数中的每一个基数为以下整数中的任意一个:2k,3k,4k,5k;其中,所述2k,3k,4k,5k均为大于1且小于16的整数。
[0270]
进一步地,在本申请的实施例中,所述确定单元14,还具体用于根据所述当前存储地址模式和所述最大基数确定空间个数b;其中,所述当前存储地址模式包括相邻存储模式和间隔存储模式,所述相邻存储模式下相邻序号的多个操作数存储至相同的存储地址,所述间隔存储模式下相邻序号的操作数分别存储至不同的存储地址;以及基于所述空间个数b执行存储空间的划分处理,获得所述b个存储空间。
[0271]
进一步地,在本申请的实施例中,当所述当前存储地址模式为所述相邻存储模式时,所述确定单元14,还具体用于若所述最大基数为偶数,则将所述最大基数确定为所述空间个数b;以及若所述最大基数为奇数,则对所述最大基数执行加一运算,获得所述空间个数b。
[0272]
进一步地,在本申请的实施例中,当所述当前存储地址模式为所述间隔存储模式时,所述确定单元14,还具体用于将所述最大基数确定为所述空间个数b。
[0273]
进一步地,在本申请的实施例中,所述存储单元15,具体用于根据所述最大基数和预设存储参数确定第一写地址并行度;其中,所述预设存储参数表征存储模块的存储能力;以及根据所述待变换序列中的操作数的序号和所述m,在所述b个存储空间中确定第一写地址;以及基于所述第一写地址并行度将所述待变换序列中的操作数存储至所述第一写地址。
[0274]
所述存储单元15,还具体用于将所述待变换序列中的操作数的序号分解成m个,获得m个参数;以及根据所述m个参数和所述空间个数b,从所述b个存储空间中确定第一目标存储空间;以及根据所述m个参数和所述至少一个基数从所述第一目标存储空间中确定第一目标存储地址;以及根据所述m个参数中的第m个参数从所述第一目标存储地址中确定所述第一写地址。
[0275]
所述存储单元15,还具体用于若所述第m个参数为偶数,则确定所述第一写地址为所述第一目标存储地址中的高位地址;以及若所述第m个参数为奇数,则确定所述第一写地址为所述第一目标存储地址中的低位地址。
[0276]
进一步地,在本申请的实施例中,所述存储单元15,还具体用于将所述最大基数确定为第二写地址并行度;以及根据所述待变换序列中的操作数的序号和所述m,在所述b个存储空间中确定第二写地址;以及基于所述第二写地址并行度将所述待变换序列中的操作数存储至所述第二写地址。
[0277]
所述存储单元15,还具体用于将所述待变换序列中的操作数的序号分解成m个,获得m个参数;以及根据所述m个参数、所述空间个数b和所述至少一个基数中的第一个基数,从所述b个存储空间中确定第二目标存储空间;以及根据所述m个参数、所述至少一个基数
和所述第一个基数从所述第二目标存储空间中确定第二目标存储地址;以及根据所述m个参数中的第1个参数从所述第二目标存储地址中确定所述第二写地址。
[0278]
所述存储单元15,还具体用于计算所述第一个基数与2的求商结果;以及若所述第1个参数大于或等于所述求商结果,则确定所述第二写地址为所述第二目标存储地址中的高位地址;以及若所述第1个参数小于所述求商结果,则确定所述第二写地址为所述第二目标存储地址中的低位地址。
[0279]
进一步地,在本申请的实施例中,所述读取单元16,具体用于当所述m大于0且小于所述m时,根据所述当前基数和所述空间个数b确定第一运算并行度;其中,运算并行度表征一个时钟周期进行多组蝶形运算;以及根据所述空间个数b、所述当前基数以及所述第一运算并行度,确定所述第一运算并行步长;其中,运算并行步长表征所述多组蝶形运算中、相邻两组蝶形运算对应的存储空间间隔值;以及按照所述第一运算并行度和所述第一运算并行步长,从所述第一存储地址读取所述r组操作数。
[0280]
进一步地,在本申请的实施例中,所述读取单元16,还具体用于当所述m等于m时,按照所述最大基数和所述预设存储参数,从所述第一存储地址读取所述r组操作数。
[0281]
进一步地,在本申请的实施例中,所述读取单元16,还具体用于当所述m等于1时,根据所述求商结果和所述空间个数b确定第二运算并行度;以及根据所述空间个数b、所述求商结果以及所述第二运算并行度,确定第二运算并行步长;以及按照所述第二运算并行度和所述第二运算并行步长,从所述第一存储地址读取所述r组操作数。
[0282]
进一步地,在本申请的实施例中,所述读取单元16,还具体用于当所述m大于1、且小于或等于所述m时,根据所述当前基数和所述空间个数b确定第二运算并行度;以及根据所述空间个数b、所述当前基数以及所述第二运算并行度,确定第二运算并行步长;以及按照所述第二运算并行度和所述第二运算并行步长,从所述第一存储地址读取所述r组操作数。
[0283]
进一步地,在本申请的实施例中,所述读取单元16,还用于在所述第(i+r)个时钟周期从第二存储地址继续读取r组操作数;其中,所述第二存储地址为所述b个存储空间中、所述第一存储地址以外的地址。
[0284]
进一步地,在本申请的实施例中,所述运算单元17,还用于继续在第(i+r+1)时钟周期至第(i+2r)时钟周期依次执行r组操作数的蝶形运算处理。
[0285]
进一步地,在本申请的实施例中,所述存储单元15,还用于在第(i+2r+1)时钟周期执行r组变换后数据的存储处理;以及直至将所述第m级中待变换序列对应的全部变换后数据存储至所述b个存储空间。
[0286]
进一步地,在本申请的实施例中,所述处理单元19,用于在直至将所述第m级中待变换序列对应的全部变换后数据存储至所述b个存储空间之后,继续对所述第m级中待变换序列对应的全部变换后数据执行第(m+1)级变换处理,直至完成第m级变换处理。
[0287]
所述存储单元15,还用于将所述第m级中待变换序列对应的目标变换后数据存储至所述b个存储空间。
[0288]
所述输出单元110,用于按照所述至少一个基数中的第一个基数对所述目标变换后数据进行输出。
[0289]
在本申请的实施例中,进一步地,图23为本申请实施例提出的终端组成结构示意
memory,rom)、随机存取存储器(rabdom access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0297]
本申请实施例提供了一种终端,该终端配置傅里叶变换处理器,由于傅里叶变换处理器的读写操作是按照原址方式进行的,即始终基于同一存储模块执行数据的读写操作,因此,避免了硬件资源的消耗;并且每次在一个时钟周期该傅里叶变换处理器能够同时读写多个时钟周期进行运算处理的多组操作数,能够始终保证蝶形运算处理的满负荷运行,极大的提高了傅里叶变换处理过程中数据吞吐率。可见,本申请傅里叶变换处理器能够在减少硬件开销,降低硬件资源消耗的同时,有效保证上下行数据吞吐速率,智能性更高
[0298]
本申请实施例提供一种计算机可读存储介质,其上存储有程序,该程序被傅里叶变换处理器执行时实现如上所述的傅里叶变换处理方法。
[0299]
具体来讲,本实施例中的一种傅里叶变换处理方法对应的程序指令可以被存储在光盘,硬盘,u盘等存储介质上,当存储介质中的与一种傅里叶变换处理方法对应的程序指令被一电子设备读取或被执行时,包括如下步骤:
[0300]
确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;
[0301]
按照写地址策略将所述待变换序列中的操作数存储至所述b个存储空间;其中,所述写地址策略用于在一个存储地址存储多个操作数;
[0302]
当进行第m级变换处理时,在第i时钟周期从所述b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
[0303]
在第(i+r+1)时钟周期将所述r组变换后数据存储至所述第一存储地址。
[0304]
本申请实施例提供一种芯片,其包括傅里叶变换处理器和接口,所述傅里叶变换处理器包括地址管理模块、蝶形运算模块以及存储模块,所述傅里叶变换处理器通过所述接口获取程序指令,所述傅里叶变换处理器用于运行所述程序指令,实现如上所述的傅里叶变换处理方法。具体地,所述傅里叶变换处理方法,包括以下步骤:
[0305]
确定待变换序列对应的b个存储空间和变换级数m;其中,b为大于1的整数,m为大于或等于1的整数;
[0306]
按照写地址策略将所述待变换序列中的操作数存储至所述b个存储空间;其中,所述写地址策略用于在一个存储地址存储多个操作数;
[0307]
当进行第m级变换处理时,在第i时钟周期从所述b个存储空间中的第一存储地址读取r组操作数,并在第(i+1)时钟周期至第(i+r)时钟周期依次对所述r组操作数进行蝶形运算处理,得到r组变换后数据;其中,r为大于1的整数,m为大于0,且小于或等于m的整数;
[0308]
在第(i+r+1)时钟周期将所述r组变换后数据存储至所述第一存储地址。
[0309]
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
[0310]
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的实现流程示意图和/或方框图来描述的。应理解可由计算机程序指令实现流程示意图和/或方框
图中的每一流程和/或方框、以及实现流程示意图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0311]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0312]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在实现流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0313]
以上所述,仅为本申请的较佳实施例而已,并非用于限定本申请的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1