基于多条件时间序列的农机监测数据清洗方法与装置
本发明涉及农业工程技术领域,具体涉及一种基于多条件时间序列的农机监测数据清洗方法与装置。
背景技术:
在我国北方地区,秸秆还田免耕播种是一项普遍应用的培肥地力的保护性耕作技术,在免耕播种机上安装监测设备,可以借助高清摄像头抓拍田间秸秆覆盖情况,并进行秸秆覆盖率定量计算。2020年,吉林省农业机械化远程精准作业平台中保护性耕作的监测面积约为120万公顷,获取了大约720万张抓拍图像。但由于播种机在农田地头间做往返运动,两端掉头或长时间停车占据了大量的耕作时间,使得抓拍图像中监测范围位于农田有效区域的不足40%。这些无效图像若不及时清除,不仅会占用网络传输通道和服务器内存,还将与有效图像一同作为秸秆覆盖率识别的样本基础和秸秆还田补贴的重要依据,大大降低对地块秸秆覆盖率计算的准确性。数据清洗是降低数据冗余和提高数据质量的关键步骤,也是减轻监测设备缓存压力和网络传输拥堵的有效环节。因此,准确高效的数据清洗方法对推进智能化监测系统和推广秸秆还田技术具有重要作用。
目前,在单维度时间序列清洗方面,主要是基于平滑、统计或约束的方法;针对多维时间序列,更多的使用机器学习方法处理多维度信息。但单一维度关系型数据的清洗方法较为系统,只有部分可以直接作用于时间序列数据,但图像抓拍系统中无效数据占比较大,单一维度的时间序列无法实现较高拟合精度,而现有的多维时间序列方法没有很好利用序列间的物理特质,例如车速与时间约束了面积数据,电压会影响电流的大小等。
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种基于多条件时间序列的农机监测数据清洗方法与装置,以期部分地解决上述技术问题中的至少之一。
为了实现上述目的,作为本发明的一方面,提供了一种基于多条件时间序列的农机监测数据清洗方法,所述方法包括:
获取监测车辆在当前地块内的作业工况数据和图像抓拍数据;
对所述作业工况数据进行预处理,将数据划分为训练集和测试集;
将工况时间序列输入多条件的时序模型中进行特征提取,获得多维度的时空特征;
将所述多维度的时空特征按照通道进行融合,获得工况状态预测信息;
将所述测试集中抓拍时间对应的工况信息输入到训练好的模型中,获得车辆当前时刻抓拍图像清洗状态预测结果。
其中,所述对所述作业工况数据进行预处理包括对工况对应时刻的状态真值进行标注。
其中,所述将工况时间序列输入多条件的时序模型中进行特征提取,获得多维度的时空特征的步骤,包括:
将工况信息在时间维度上展开,每类工况时间序列分别为单个长短时记忆网络的输入,工况类别包括车速、播种量和瞬时面积;
将多类工况序列划分为多个子序列,每一个时刻对应一个时间单元,即组成深层的时间特征提取模型,并将多类工况信息提取为隐藏层特征序列输出。
其中,所述将所述多维度的时空特征按照通道进行融合,获得工况状态预测信息的步骤,包括:
多类工况序列分别通过lstm的时空特征提取后,得到的最后一个时刻的特征输出作为整个工况参数时间序列信息的融合;
将各类特征输出在融合前乘以一个权重系数,用于提高不同条件的区分度;
将加权后的各类特征输出进行通道融合;
将融合后特征输入神经网络中进行预测,得到工况状态预测结果。
其中,所述多条件的时序模型由至少三个单独的lstm网络模型组成,每个网络模型的特征输出的激活函数为tanh激活函数。
其中,在特征融合后引入batchnormalization和dropout方法,其中:
通过batchnormalization使得网络中每个批次的特征输入保持较为标准的正态分布,但等比例的变化和偏移后不会造成信息缺失;
通过dropout使得整个训练过程随着批次和迭代次数的增加更加复杂多样,但最后的输出结果取平均后,能够在一定程度上减轻整体网络的过拟合。
作为本发明的另一方面,提供了一种基于多条件时间序列的农机监测数据清洗装置,包括:
数据获取及预处理模块,用于获取监测车辆在当前地块内的作业工况数据和图像抓拍数据;及对所述作业工况数据进行预处理,将数据划分为训练集和测试集;
模型训练模块,用于将工况时间序列输入多条件的时序模型中进行特征提取,获得多维度的时空特征;及将所述多维度的时空特征按照通道进行融合,获得工况状态预测信息;
预测模块,将所述测试集中抓拍时间对应的工况信息输入到训练好的模型中,获得车辆当前时刻抓拍图像清洗状态预测结果。
其中,所述将工况时间序列输入多条件的时序模型中进行特征提取,获得多维度的时空特征包括:
将工况信息在时间维度上展开,每类工况时间序列分别为单个长短时记忆网络的输入,工况类别包括车速、播种量和瞬时面积;
将多类工况序列划分为多个子序列,每一个时刻对应一个时间单元,即组成深层的时间特征提取模型,并将多类工况信息提取为隐藏层特征序列输出。
其中,所述将所述多维度的时空特征按照通道进行融合,获得工况状态预测信息包括:
多类工况序列分别通过lstm的时空特征提取后,得到的最后一个时刻的特征输出作为整个工况参数时间序列信息的融合;
将各类特征输出在融合前乘以一个权重系数,用于提高不同条件的区分度;
将加权后的各类特征输出进行通道融合;
将融合后特征输入神经网络中进行预测,得到工况状态预测结果。
作为本发明的再一方面,提供了一种电子设备,包括:
至少一个处理器、与所述至少一个处理器通信连接的计算机可读存储介质以及执行处理器指令的传感器;其中,所述存储介质有可被所述至少一个处理器执行的指令,所述指令被程序设置为执行权利要求1-6任一所述的基于多条件时间序列的监测数据清洗方法。
本发明提供一种基于多条件时间序列的农机监测数据清洗方法与装置,其目的在于通过预测工况参数时间序列和工况状态的对应关系,使用训练完毕的状态预测模型,利用当前的工况状态代替抓拍时刻的清洗状态,由此解决农机监测条件下对抓拍图像清洗状态进行判断的技术问题,从而解决了保护性耕作秸秆覆盖率计算干扰和监测设备的存储冗余和传输拥堵问题,提高了数据质量和数据利用率;降低对后续地块作业质量评价的准确性的影响,减轻数据并发带来的网络压力。
附图说明
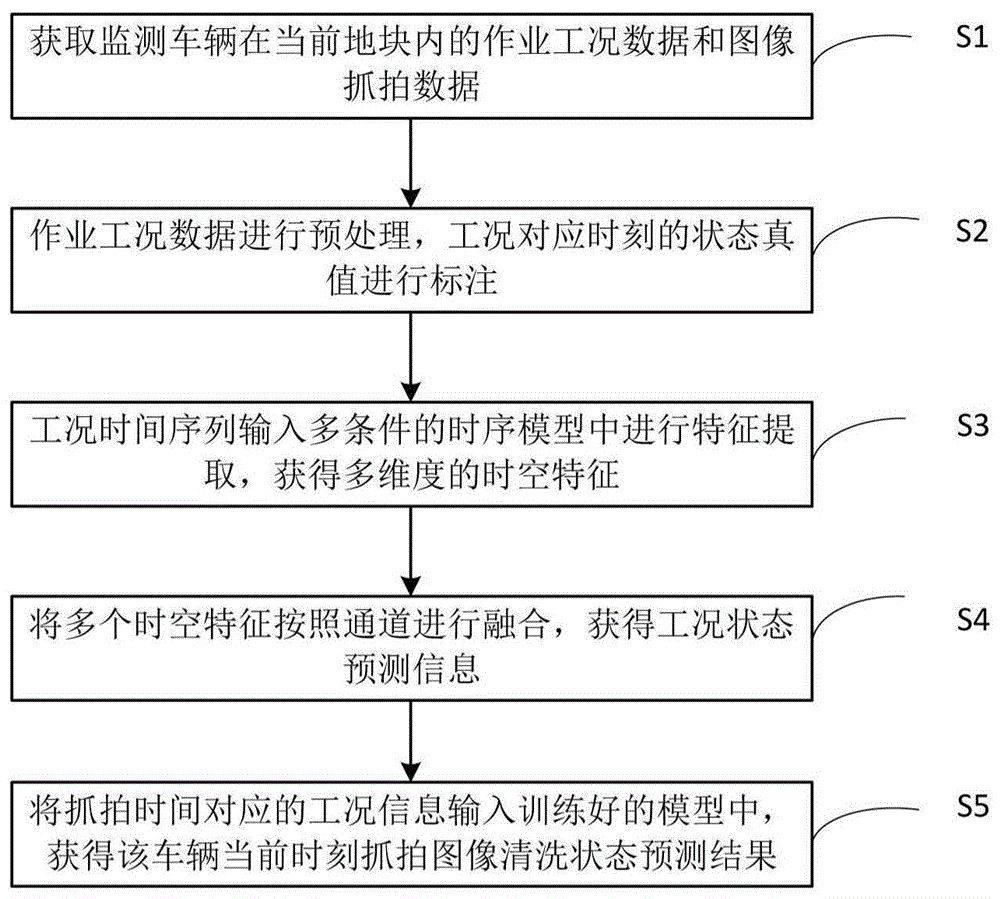
图1是发明实施例中基于多条件时间序列的农机监测数据清洗方法流程图;
图2是本发明实施例中免耕播种监测数据分布和工况样本示意图;
图3是本发明实施例中单个工况时间序列的特征提取结构图;
图4是本发明实施例中多条件工况预测和数据清洗流程图;
图5是本发明实施例中的电子设备的示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
保护性耕作监测设备在作业过程中每3分钟就会传回一张田间监测照片,每5秒采集一次工况参数,免耕播种机在田间往返作业时,工况参数幅值会随时间呈周期性变化,而在无效区间内的数据又可分为边界和静止两种状态表现。其中,处于边界状态时车速和瞬时面积会在20-30秒(即4-6个采集点)的范围内突然逐渐降低至零或缓慢增至正常车速,而静止状态时工况参数较长时间保持不变。车辆掉头会占用大量时间,使得图像的抓拍位置通常位于地块两端、田间或地头静止。
这类无效数据往往实时生成并实时传输,无法预先通过农田边界进行判定,若不及时清除会占用大量内存,并影响后续地块秸秆覆盖质量评价的准确性,为了解决这个问题,本实施例提供一种基于多条件时间序列的农机监测数据清洗方法,针对某时刻免耕播种机工况参数的状态预测来间接实现图像清洗。如图1所示,该方法包括以下步骤:
s1,获取监测车辆在当前地块内的作业工况数据和图像抓拍数据。
如图2所示,大安市保护性耕作免耕播种机作业工况参数信息通过不同类型传感器每间隔5秒采集得到,包括免耕播种机车速、瞬时面积、播种量,秸秆图像是由车载摄像头每3分钟定时抓拍获取的,覆盖了不同位置的农田场景。包含了15000多条免耕播种机作业真实的工况参数信息和50000多张秸秆覆盖图片。在本实施例中,随机选取5条包含3000个连续采集点的工况参数数据和在该时段内抓拍的265张图像作为模型驱动的基础。
s2,作业工况数据进行预处理,工况对应时刻的状态真值进行标注;
在本实施例中,由于数据量较庞大,模型训练需要大量人工标注工作,随机选取5条包含3000个连续采集点的工况参数数据和在该时段内抓拍的265张图像作为模型驱动的基础,对工况参数时间序列中每一个时刻的工况状态进行标注,并分为60%的测试集和40%的训练集。
s3,工况时间序列输入多条件的时序模型中进行特征提取,获得多维度的时空特征。
如图3所示,以播种机工况参数中的车速时间序列为例,假设车速的时间序列样本为a={x1,x2,…,xn},样本标签为y={y1,y2,…,ym},其中某一批次的子序列样本为x={x1,x2,…,xm}(m远小于n),则在t时刻的lstm时间单元输入有:该单元的子序列输入信息xt,t-1时刻lstm单元的输出信息ht-1,t-1时刻lstm单元的融合信息ct-1;该单元的输出包括:t时刻lstm单元的输出信息ht,t时刻lstm单元的融合信息ct。其车速样本xt前向推到过程包括以下步骤:
经过t-1时刻丢弃部分信息ft=σ(wfhht-1+wfxxt+bf);
经过t时刻输入部分信息it=σ(wihht-1+wixxt+bi);
经过t-1时刻和t时刻融合信息ct=ftct-1+ittanh(wchht-1+wcxxt+bc);
经过t时刻输出信息ot=σ(wohht-1+woxxt+bo);
经过t时刻特征信息ht=ottanh(ct);
其中,w为区间[0,1]d的权重参数,w为0代表完全舍弃,w为1代表全部保留,b为空间映射中的偏移常量(bias),σ为sigmoid激活函数,tanh为tanh激活函数。
由前向推到过程可以看出,t时刻输出的车速信息包含了前一时刻车速信息以及当前时刻的新输入,而且模型对信息的选择具有随机性。而权重参数w的更新与目前大部分深度神经网络的训练都使用后向传播算法,由于输入车速样本x具有时序特性,则该方法演变为随时间的反向传播算法。t时刻的两个残差分别为δct和δht,jt是以均方误差定义的损失函数,
将lstm的时间单元在时间维度上展开,输入车速样本x={x1,x2,…,xm}的每一个时刻对应一个时间单元,即可以组成m层的lstm特征提取模型,随着子序列步长m的变化,网络的层数可以无限深,经过激活函数softmax参数优化后,在最后一层得到特征输出序列h={h1,h2,…,hm}。
s4,将多个时空特征按照通道进行融合,获得工况状态预测信息。
其中,车速、播种量和瞬时面积分别通过lstm的时空特征提取后,得到的最后一个时刻的特征输出可以作为整个工况参数时间序列信息的融合。由于车速、播种量和瞬时面积对工况状态的响应各有不同,在融合前将每个特征乘以一个权重系数,可以提高不同条件的区分度,分别反映三种条件对预测结果的重要性。之后对三类特征进行通道融合,因为加减运算或平均求和的特征融合方法,都会使信息丢失,因此此处并不适合特征叠加。
其中,多特征通道融合后使得特征间干扰降低,批量标准化(batchnormalization,bn)可以使得网络中每个批次的特征输入保持较为标准的正态分布,但等比例的变化和偏移后不会造成信息缺失。由于,本实验用到播种机的工况参数均在较短周期内循环,使得步长设定不宜过大,在特征提取之前加入bn层容易阻碍信息传播,因此bn更适合放在特征融合之后。
其中,针对特征融合后的单一模型过拟合问题,需要在bn之后加入dropout层,使得整个训练过程随着批次和迭代次数的增加更加复杂多样。在单次迭代中,某些网络可能会出现过拟合现象,但最后的输出结果取平均后,可以在一定程度上减轻整体网络的过拟合问题。
s5,将抓拍时间对应的工况信息输入训练好的模型中,获得该车辆当前时刻抓拍图像清洗状态预测结果。
如图4所示,为多条件工况预测和数据清洗的流程图。
上述实施例的各工况特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个工况特征所有可能的组合都进行描述,然而,只要这些工况特征在时序上存在周期性,并对工况状态有一定响应,都应当认为是本说明书记载的范围。
本发明还公开了一种基于多条件时间序列的农机监测数据清洗装置,用于执行上述基于多条件时间序列的农机监测数据清洗方法,在此不再赘述。
如图5所示,本发明实施例还提供一种电子设备,其使用方法如上所述基于多条件时间序列的农机监测数据清洗方法,包括:
计算机可读存储介质,存储有可执行指令,该可执行指令用于执行多条件时间序列的农机监测数据清洗方法;
传感器为多种类型包括摄像头、卫星导航传感、车速传感、播种量监测传感等,分别与处理器连接,用于分别采集农机工况数据以及农田监测数据并提供给处理器;
处理器与传感器连接以获取特征数据,并调用计算机可读存储介质中的可执行指令,对特征数据处理以进行农机工况状态与抓拍图像状态预测。
本发明提出一种基于多条件时间序列的农机监测数据清洗方法及装置,融合了多条件的lstm特征提取和特征通道融合结构,通过预测免耕播种机工况状态,间接实现了抓拍图像清洗。与现有技术相比,该技术填补了抓拍图像数据清洗内容的空白,具有很高的应用价值,为免耕播种监测数据清洗及秸秆覆盖率的定量计算提供了技术支撑。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!