一种基于视角引导多重对抗注意力的行人重识别方法
本发明属于监控视频检索技术领域,具体地涉及一种基于视角引导多重对抗注意力的行人重识别方法。
背景技术:
近些年,行人重识别广泛应用于行人追踪和刑侦搜索等方面。行人重识别技术就是在跨摄像头的条件下,将不同地点,不同时间出现的相同的行人联系起来。行人重识别方法主要结合计算机视觉技术对行人进行特征学习,并设计合适的度量进行特征匹配。
学习鲁棒的特征对提升行人重识别算法的性能十分重要,而行人的姿态变化,摄像头视角变化,背景遮挡,光照变化以及图像分辨率变化等都会造成特征失真。因此,如何学习强健的能够抗各种变化的特征是目前行人重识别问题的研究热点。
目前主流的行人重识别算法都基于深度学习网络框架,深度学习将行人特征学习与度量结合形成端到端的网络,大幅提升了行人重识别算法的性能。深度卷积神经网络的基本训练和测试步骤如下:
1、准备数据,将数据集分为训练集和测试集。
2、将训练集的数据放入深度卷积神经网络进行训练,其中包括,基础网络的构建,三元组的构建,损失优化等。
3、使用训练好的模型对query集和测试集的图片进行特征提取和特征匹配。
对抗学习使用生成器和判别器来形成对抗的模型,生成器希望尽可能生成逼真的样本从而不能被判别器区分,而判别器希望尽可能将生成的样本和真实样本区分开,从而通过对抗的方式使生成样本尽可能接近真实样本。
注意力机制能突出信息区域,抑制噪声模式。按照注意力机制的作用域,可以分为三类:1)空间域注意力通过空间转换来提取关键信息。2)通道域注意力考虑通道间的依赖性并相应的调整通道权重。3)混合域注意力是空间域和通道域注意力的结合,它同时关注特征的空间信息和通道信息。
目前注意力机制也逐渐在行人重识别领域变得火热,基于注意力机制的方法也取得了不错的性能。但是目前的方法存在两点局限性:1)现有的注意力机制只在与特征进行结合后的最终阶段被监督。注意力图的学习缺少直接的监督,因而难以判别学习到的注意力图对最后的表达是否是有益的。2)现存的注意力策略关注设计复杂的结构同时忽略了重要的摄像头id信息,使学习到的特征表达对视角变化敏感。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的技术问题就是对现有的基于注意力机制的行人重识别方法进行改进。提出了一种基于视角引导多重对抗注意力的行人重识别方法,借用对抗学习的思想,将视角信息引入注意力机制,对注意力机制的学习进行直接监督并考虑其是否能抓取有信息量且视角无关的部位。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括:
步骤1、构建深度神经网络
深度卷积神经网络主要包括特征学习模块,多重对抗模块,视角引导注意力机制模块,所述的特征学习模块采用多种基于resnet50网络的基础模型,输入行人图片进行特征学习得到特征;所述的多重对抗模块在基础resnet50的每个残差块后接一个全局池化层和视角鉴别器;所述的视角引导注意力机制模块主要为注意力图生成器和视角鉴别器;
步骤2、深度卷积神经网络的训练
1)、数据的准备:准备行人图片,输入行人图片和对应的id标签,将其划分为两部分作为训练图片和测试图片;
2)、将训练图片送入深度卷积神经网络进行训练
本步骤包括特征学习,多重对抗模块学习,视角引导注意力机制学习。
所述特征学习为:将训练图片输入搭建好的深度卷积神经网络,输出为特征的深度特征表达。该部分使用三元组损失以及分类损失进行监督。
所述多重对抗模块学习为:在原始特征学习网络的每一个残差块上加入全局池化得到每一个低层,中层,高层特征,使用视角鉴别器对这些特征进行监督,使最后得到的深度特征表达更强健。该部分使用视角分类损失对特征进行监督。
所述视角引导注意力机制为:在原有深度特征学习网络的基础上加入注意力机制,并对注意力机制的学习进行监督,使生成的注意力图更能抓取语义信息丰富且能对抗视角变化的区域。该部分使用视角分类损失对注意力图进行监督。
3)、网络优化及参数更新
更新包括前向传播和反向传播两部分,前向传播通过网络计算输出与损失大小,然后再反向传播过程中反传损失的梯度,从而对网络进行更新。
步骤3、深度卷积神经网络的测试
使用训练好的网络对测试图片进行特征提取,使用欧式距离对query与gallery中的图片进行特征匹配。
本发明的技术效果是:
1.将对抗学习用于行人重识别网络,对各个阶段的特征进行监督,增强了特征的视角不变性,使最终学习到的全局特征更加强健。
2.提出的视角注意力机制对传统的注意力机制进行改进,对注意力机制学习进行直接的监督同时关注注意力图抓取的区域是否能抵抗视角变化,提升了注意力机制的性能。
本发明的优点是:1)对注意力机制的学习进行直接监督,提高了注意力机制的性能。2)易于集成到各种基础模型且能对这些模型进行性能优化。
附图说明
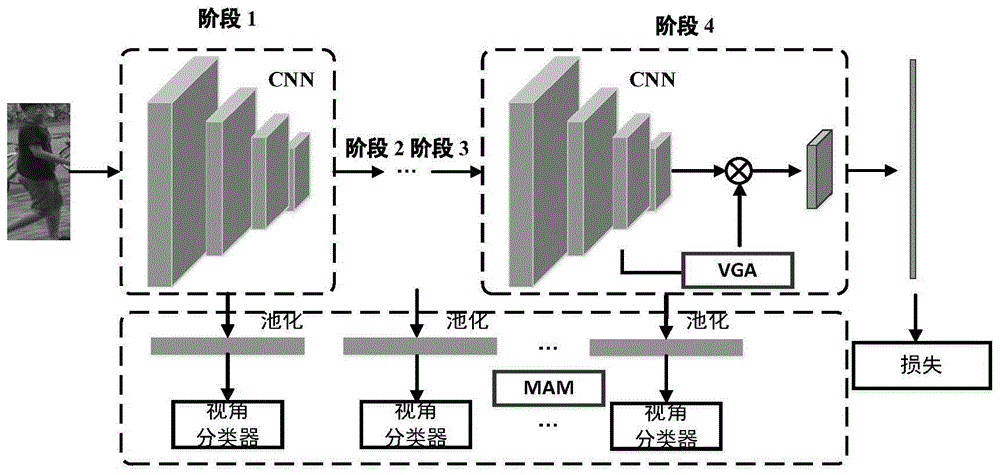
图1为本发明提出的深度卷积神经网络的模型图;
图2为本发明使用的特征图生成器的模型图;
图3为本发明提出的视角引导的注意力机制的模型图;
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
术语解释:query集:待搜索目标行人图片集
gallery集:所有行人图片集
softmax:一种归一化指数函数
rank1和map:行人重识别领域的两种评价指标
本发明以对抗的方式构建一个与视角信息监督的注意力机制结合的网络。针对当前注意力机制存在的局限性,采用摄像头id信息对注意力机制的学习进行引导,筛选具有显著性和视角不变性的区域(显著性是指:行人图片中最具有信息量,可以用于区分的区域);还采用对抗的方式在网络各层对学习到的特征进行监督,借此特征的视角不变性能够进一步的加强。
本发明的视角引导多重对抗注意力机制的行人重识别方法包括以下步骤:
步骤1、构建深度卷积神经网络
本发明的网络结构搭建主要基于pytorch平台,基础网络搭建采用最基本的resnet50结构。层的添加与定义遵从pytorch内部的各种操作。构建的模型如图1所示,主要包括特征学习,多重对抗模块与视角引导注意力机制模块:
特征学习模块使用三个基础模型进行特征生成。(1)ide/pcb模型“beyondpartmodels:personretrievalwithrefinedpartpooling(andastrongconvolutionalbaseline),sun,y.,zheng,l.,yang,y.,tian,q.,wang,s.proceedingsoftheeuropeanconferenceoncomputervision(eccv).2018:480-496.”(超越局部模型:使用精细局部池化的行人搜索。郑良等,欧洲计算机视觉会议,2018,480-496)。该模型对特征图进行精细局部池化,生成兼顾局部特性和全局特性的行人特征。(2)agw模型“deeplearningforpersonre-identification:asurveyandoutlook,m.ye,j.shen,g.lin,t.xiang,l.shao,ands.c.hoi,arxivpreprintarxiv:2001.04193,2020.”(用于行人重识别的深度学习:总结与展望。叶芒等,arxivpreprintarxiv:2001.04193,2020)。该模型结合非局部注意力模块,泛化平均池化以及加权正则三元组提出新的行人重识别基础网络。
(3)fast-reid模型“fastreid:apytorchtoolboxforgeneralinstancere-identification,l.he,x.liao,w.liu,x.liu,p.cheng,andt.mei,arxivpreprintarxiv:2006.02631,2020.”(fastreid:一个用于通常实例再识别的pytorch工具箱,何凌霄等,arxivpreprintarxiv:2006.02631,2020)。京东ai研究院将现有行人重识别基础模型进行整理,对常用的技巧也进行整合形成一个重识别工具箱。这三个基础模型都使用原模型中常用的三元组损失和分类损失进行身份监督。
如图1所示,多重对抗模块(mam)和视角引导注意力机制模块(vga)作用在基础模型上,对特征的学习进行加强,希望学习更加强健且更具有判别性的特征。
多重对抗模块作用在各个阶段的残差块,对各个阶段的特征进行监督,使用视角信息对池化后的特征进行分类,希望学习到的池化特征不能被区分到具体的视角。其中主要包括各个阶段的分类损失监督,分类器希望将特征区分到具体的视角,而特征生成器希望生成的特征不能被区分到具体的视角。
视角引导注意力机制模块以对抗的思路对注意力图的学习进行引导,注意图与最后一个阶段的特征图进行点乘加权,然后池化得到全局特征。注意力图的生成器如图2所示,其中包括三种类型的注意力机制:(1)空间注意力机制(sa)对注意图的空间位置进行变换。(2)通道注意力机制(ca)参考se-net“squeeze-and-excitationnetworks,j.hu,l.shen,s.albanie,g.sun,ande.wu,ieeetpami,2019pp.1–1.”(挤压与激励网络,胡杰等,ieeetpami,2019)对通道间的相关性进行建模。(3)混合注意力机制(ma)将两种进行以一种串行的方式进行结合,同时进行空间域和通道域的变换。这三种注意力机制分别使用的,无先后顺序。
图3给出了视角引导注意力机制模块的示意图,其中主要包括对注意力图的分类损失监督,分类器希望将注意力图区分到具体的视角,而注意力图生成器希望生成的特征不能被区分到具体的视角。
步骤2、深度卷积神经网络的训练
1)数据的准备:准备行人图片和标签(包括行人身份标签以及摄像头标签),作为训练和测试图片。训练过程中,按批输入图片数据,图片的像素大小都设置为(384,192),批的大小设置为32。
2)把训练图片送入深度卷积神经网络进行训练
本步骤主要包括基础模型,多重对抗模块和视角引导注意力机制模块的学习。
基础模型特征学习:参考ide/pcb模型,agw模型与fastreid模型搭建基础网络模型,使用与对应模型相同的损失(行人身份分类损失lcls)进行监督,网络的输出为2048维的特征向量(一个批次n张图片输出n*2048的矩阵)。
多重对抗模块:对于多个阶段的特征提取器,本发明通过视角分类器衡量生成特征的视角不变性,输入行人样本x,特征求解器的参数为θf,视角分类器的参数为θd,视角分类器的损失可以表示为式(1):
其中yi表示第i个行人的视角标签,
视角引导注意力模块:注意力图生成器如图2所示,视角引导注意力模块(vga)的示意图如图3所示。视角分类器希望将注意力图分到不同的视角,输入注意力图x,注意力图生成器的参数为θg,注意力图分类器的参数为θad分类损失可以表示为式(3)
其中yi和pi分别表示第i个注意力图的视角标签和softmax概率向量。n是注意力图的数目。我们同样希望生成的注意力图不能被判定为具体的视角,也就是判定为每个视角的概率相当,c的选取与式(2)中相同,于是此模块的对抗损失可以写为:
整个模型:整个模型由基础模型的特征学习,多重对抗模块以及视角引导注意力模块组成,整个模型的损失求解可以表示为式(5)。
3)网络优化及参数更新
网络的更新主要包括前向传播和反向更新两部分,搭建的网络模型主要通过前向传播过程计算各项损失,然后反向传播损失的梯度来更新网络。值得注意的是在求解对抗网络是加入了梯度反转操作。在对抗学习中,生成器参数和判别器参数的更新可以定义为式(6)
步骤3、深度卷积神经网络的测试
在测试阶段,不进行网络的训练以及参数更新,主要是使用训练好的模型对测试图片进行特征提取和特征匹配。行人图片通过模型得到基础模型的特征图输出,经过设计的注意力机制得到注意力图,使用注意力图对特征图进行加权,池化得到最终的全局特征。之后按欧式距离进行特征匹配,在gallery中寻找与query距离最近的图片,如果query图片的行人身份与在gallery中找到的图片行人身份一致,则认为匹配成功。
实施例:
1.数据集
本发明使用market1501和dukemtmc-reid数据集。market1501数据集采集于校园场景并于2015年发布,包含1501个行人身份,由6个摄像机拍摄。其中,751个行人身份的12936张图片作为训练集,750个行人身份的19732张图片作为测试集。dukemtmc-reid数据集是dukemtmc数据集的一个子集。其中,702个行人身份的16522张图片作为训练集,702个行人身份的17661张图片作为测试集。
2.实验设置
网络的学习率,学习策略等都与3个对应的基础模型设置相同。这里主要介绍损失函数的权重设置,在实验中,设置λma=0.1,λvga=0.1。
3.训练和测试方法
训练阶段:按批输入行人图像,前向传播计算各项损失,反向传播更新网络参数,经过多次迭代得到最终的网络模型。
测试阶段:使用训练好的网络模型对测试图片进行特征提取,进行特征匹配,并计算rank1和map指标。
4.识别准确率比较
为了验证本发明的有效性,将本发明与现有的行人重识别方法进行对比,现有的行人重识别方法主要有:
(1)mnh-6:b.chen,w.deng,andj.hu,“mixedhigh-orderattentionnetworkforpersonre-identification,”iniccv,2019,pp.371–381.
(2)abd-net:t.chen,s.ding,j.xie,y.yuan,w.chen,y.yang,z.ren,andz.wang,“abd-net:attentivebutdiversepersonre-identification,”iniccv,2019,pp.8351–8361.
(3)bfe:z.dai,m.chen,x.gu,s.zhu,andp.tan,“batchdropblocknetworkforpersonre-identificationandbeyond,”iniccv,2019,pp.3691–3701.
(4)scsn:x.chen,c.fu,y.zhao,f.zheng,j.song,r.ji,andy.yang,
“salience-guidedcascadedsuppressionnetworkforpersonreidentification,”incvpr,2020,pp.3300–3310.
(5)agw:m.ye,j.shen,g.lin,t.xiang,l.shao,ands.c.hoi,“deeplearningforpersonre-identification:asurveyandoutlook,”arxivpreprintarxiv:2001.04193,2020.
(6)isp:k.zhu,h.guo,z.liu,m.tang,andj.wang,“identity-guidedhumansemanticparsingforpersonre-identification,”eccv,pp.0–0,2020.
(7)fastreid:l.he,x.liao,w.liu,x.liu,p.cheng,andt.mei,“fastreid:apytorchtoolboxforgeneralinstancere-identification,”arxivpreprintarxiv:2006.02631,2020.测试结果见表1:
表1
从表1可以看出:本发明非常容易集成到现有的模型对其进行改进并取得更优的效果,同时本发明取得的指标比现有方法都高,识别率明显提高。主要因为两点原因:1.本发明使用的多重对抗模块对各阶段的特征都进行优化,从而最终取得更好的特征表达。2.本发明使用的视角引导注意力机制对注意力进改进,从而优化了整个模型的性能。
- 还没有人留言评论。精彩留言会获得点赞!